이번 X-Review에서는 Temporal Action Localization(TAL) 논문을 소개해드리려고 합니다.

본 논문은 2022년 CVPR에 게재되었으며 제가 기존에 리뷰하던 Weakly-supervised Temporal Action Localization(WTAL)과 다르게 Fully-supervised 기반으로 Temporal Action Localization을 수행하는 방법론입니다.
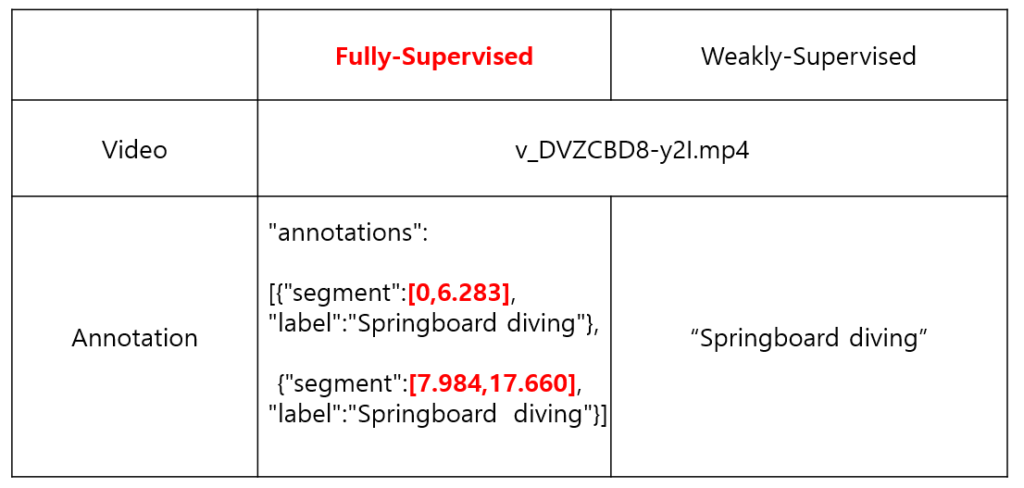
그림 1에서 왼쪽에 해당하는 task로 모델이 찾아야 하는 action 구간에 대한 temporal annotation을 가지고 학습을 수행합니다.
지금까지는 video-level label만을 가지고 action localization을 수행해야 하는 WTAL 방법론들을 많이 다루었었는데, temporal annotation을 학습 중에 활용할 수 있는 Fully-supervised Temporal Action Localization(TAL) 연구는 어떻게 진행되고 있는지 살펴보고자 이번에 소개해드릴 논문을 읽게 되었습니다.
방법론 자체가 간단하면서도 저자가 제안하는 아이디어와 그에 따라 보여주고자 하는 결과의 분석이 확실하고 풍부하다는 생각이 든 논문이었습니다.
그럼 논문 리뷰 시작하겠습니다.
1. Introduction
기존에 TAL task를 수행하는 방법론들은 기본적으로 아래와 같은 흐름을 따랐다고 합니다.
Two-stream I3D network를 통해 하나의 비디오에 대한 RGB feature와 Flow feature를 추출하고, max-pooling 등의 aggregation을 거쳐 snippet-level feature를 얻어냅니다. 물론 최근 방법론들은 단순 max-pooling보다는 복합적인 방식으로 후처리를 진행해주겠지만, 결국 뒷단에서 action 분류와 localization에 적합한 feature를 만드는 것이 공통의 목적일 것입니다.
저자가 위와 같은 절차를 간략히 소개한 이유는, Action Localization을 위한 feature를 추출할 때 기존 방법론들이 놓치고 있는 부분을 지적하기 위함이었습니다. 기존 방법론들이 생성해내는 snippet-level feature에는 untrimmed video의 두 가지 구성요소가 혼재되어 있다고 합니다. 바로 action component와 co-occurence component인데요, 편의 상 action과 co-occurence라고 칭하도록 하겠습니다.
우선 두 가지 구성요소가 무엇인지 대해 설명드리자면, 먼저 action은 해당 snippet에서 발생하고 있는 활동 자체를 의미합니다. 이 활동에는 지정된 action class에 맞게 움직이고 있는 사람의 motion pattern 뿐만 아니라, 여러 사람끼리의 상호 작용 또는 물체와의 상호 작용도 포함되어 있을 것입니다. 다음으로 co-occurence는 action에 직접적인 관여를 하는 것은 아니지만 co-occurence라는 단어 뜻 그대로 action과 자주 함께 등장하는 context 또는 뒷배경을 이루는 구성요소들을 뜻합니다.
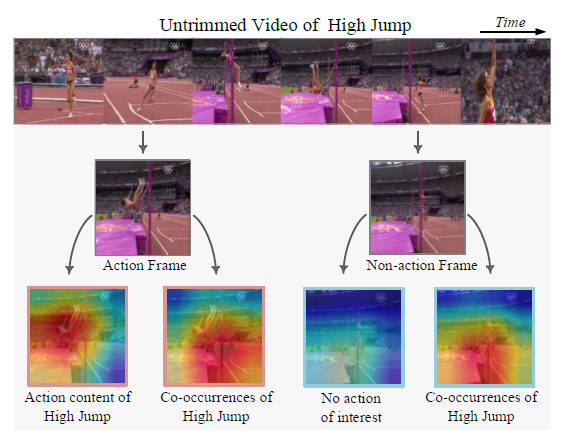
그림 2의 예시들을 통해 더욱 쉽게 이해할 수 있는데요, “높이 뛰기”를 포함하는 untrimmed video 하나가 있습니다. 저희는 현재 높이 뛰기가 언제 시작하고 끝나는지에 대한 temporal annotation을 가지고 있으므로 Action Frame과 Non-action Frame으로 나누는 것이 가능합니다. 이렇게 나누었을 때의 Action feature와 Co-occurence feature가 집중하는 부분(CAM)이 곧 저자가 강조하는 action과 co-occurence이기 때문에 이 부분을 좀 더 살펴보겠습니다.
왼쪽의 Action Frame에서 추출한 action은 실제 높이 뛰기를 수행하는 선수를 주목하고 있고, co-occurence는 선수가 높이 뛰기 동작을 취하기 위해 필요한 높이 뛰기 막대나 매트를 포함합니다. 반대로 Non-action Frame에서는 action이 수행되지 않으므로 action content는 당연히 찾을 수 없고, 반대로 직접 action에 관여하지 않지만 action과 거의 항상 공존하는 co-occurence에는 막대나 매트가 포함되어 있을 것입니다.
이전 방법론들이 방금 설명드린 두 가지 구성요소가 혼재하는 snippet-level feature를 사용한다는 점이 저자가 지적하는 문제입니다. Action 구간을 찾기 위해 co-occurence feature가 큰 도움을 줄 수 있는 것은 사실입니다. 만약 “높이 뛰기” 클래스와 “장대 높이 뛰기” 클래스를 분류해야 할 때, 선수의 동작만을 본다면 굉장히 유사할 것입니다. 그러나 co-occurence 정보를 활용하여 해당 동작 중 장대의 포함 여부(도움을 주는 co-occurence)를 고려한다면 두 action을 구분하는데에 큰 도움을 받을 수 있겠죠.
하지만 반대로 주어진 GT 구간에서 청중들이 많거나 모르는 사람이 임의로 돌아다닌다면(방해가 되는 co-occurence) 모델이 해당 action의 표현력을 학습하는데에 큰 걸림돌이 될 수도 있습니다. 결국 저자가 말하고 싶은 것은 비디오에서 action과 co-occurence 모두 중요한 정보이지만, 둘을 분리하여 서로가 서로에게 과의존하지 않으면서 적절히 도움받을 수 있는 상태의 feature를 만들어줘야 한다는 것입니다.
정리하자면 두 구성요소는 서로 완전히 다른 정보를 담고 있으면서 상호 보완적이라고 볼 수 있습니다. 이러한 상황 속에서 저자의 아이디어는 두 구성 요소가 혼재된 feature로부터 둘을 분리하고, 그 둘은 상호 보완적이므로 다시 균형을 맞춰 합쳐주는 feature refactoring 과정을 거쳐주겠다는 것입니다.
이러한 맥락 속에서 저자는 RefactorNet이라는 네트워크를 제안하고 이는 비디오로부터 action과 co-occurence 요소를 분리하는 feature decoupling module과 분리된 요소들을 다시 적절히 합치는 feature recombining module로 구성되어 있습니다. 자세한 내용은 방법론에서 아래 알아보도록 하겠습니다.
2. RefactorNet
저자가 제안하는 RefactorNet은 Feature embedding module과 Action detection module 사이에 위치합니다.
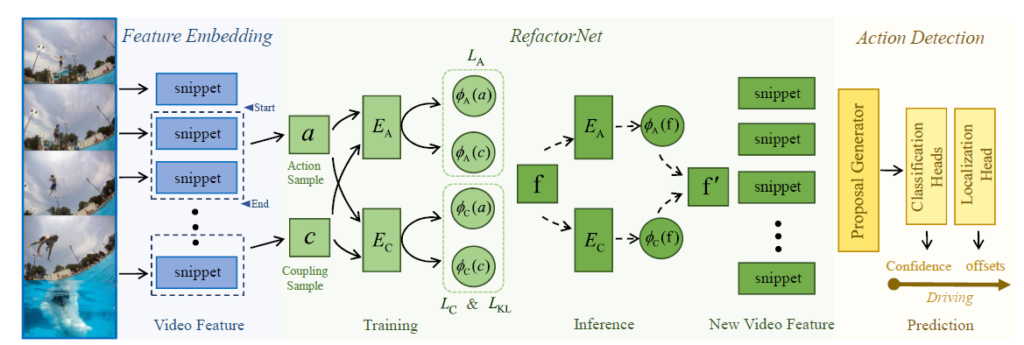
그림 3에서 파란 부분은 raw video를 입력받아 snippet으로 쪼갠 뒤 two-stream I3D network를 이용해 snippet-level feature를 추출하는 부분입니다. 여기서 얻은 feature가 바로 앞서 지적하였던 두 가지 구성 요소가 혼재되어 있는, 정제되지 않은 feature라고 볼 수 있는 것입니다.
이후 초록 부분에서 RefactorNet의 학습, 추론 과정 파이프라인이 간략히 소개되어 있습니다. 마지막으로 Action Detection 부분에서는 기존 Action Proposal 방법론 중 하나인 BSN을 통해 feature로부터 action 구간을 제안한 뒤 분류, 회귀를 통해 최종 구간을 예측하는 모습을 볼 수 있습니다.
2.1 Problem Setting
간단한 notation들을 정리하고 넘어가겠습니다.
주어진 raw untrimmed video의 한 snippet을 우선 C차원의 feature f로 추출합니다. 하나의 snippet은 16개의 프레임 묶음으로 이루어지고, 비디오의 길이에 따라 video feature는 F \in{} \mathbb{R}^{C \times{} L}로 표현할 수 있습니다.
우선 RefactorNet의 과정 설명은 snippet-level feature f \in{} \mathbb{R}^{C}를 주로 진행됩니다. TAL task를 수행하기 위한 GT \Psi{} = \{\varphi{}_{n} = (t_{s, n}, t_{e, n}, c_{n})\}_{n=1}^{N}로 표현되고 \varphi{}_{n}은 한 비디오 내 존재하는 n번째 action instance에 대한 시작 지점, 끝 지점, action 클래스를 포합니다. 하나의 비디오 안에 총 N개의 action instance가 존재하는 상황인 것입니다.
2.2 Motivation and Overview
RefactorNet 방법론의 과정에 대해 미리 한 번 짚고 넘어가겠습니다.
앞선 notation에 따르면 지금까지의 방법론은 단순히 action과 co-occurence가 혼재되어 있는 video feature F를 사용하고 있었습니다. Action과 co-occurence의 적절한 조화가 담겨있는 feature F'을 만들기 위해 우선 F로부터 둘을 분리한 후 다시 합치는 것이 RefactorNet의 역할 전부입니다.
이러한 관점에서 RefactorNet의 절차를 아래와 같이 세 단계로 나눌 수 있습니다.
- Collect action samples and their coupling samples.
- Explicitly decouple action and co-occurence components based on pairs of action samples and coupling samples.
- Effectively recombine these two components and synthesize new snippet features for video action detection.
계속 말씀드렸던 것과 같은 맥락이라 크게 어려운 점은 없고, 첫 단계에서 ‘coupling sample’이 무엇인지와 나머지 단계들의 세부 과정만 알아보면 될 것 같습니다.
2.3 Collecting action samples and coupling samples
리뷰 초반의 그림 2에서 저희가 action과 co-occurence를 이해하기 위해 Action Frame과 Non-action Frame이라는 두 가지 관점으로 나눠 생각했었습니다. 이번 절에서 설명할 coupling sample은 결국 특정 Action Frame에 상응하는 Non-action Frame의 집합을 의미하고, 어떻게 샘플링하는지 알아보겠습니다. Coupling sample을 얻어야 하는 이유는 그림 2에서처럼 Action sample과 Coupling sample에서의 action, co-occurence 존재 유무를 이용해 분리하기 위함입니다.

주어진 GT \varphi{}를 활용하여 한 비디오를 action과 non-action으로 나눌 수 있고, action 구간에 해당하는 feature를 a라고 칭하겠습니다. 물론 a가 어떤 action 클래스인지도 같이 알 수 있겠죠. 이후 non-action 구간의 feature 중 a와 cosine 유사도가 가장 높은 feature를 coupling sample로 지정하고 이를 c라고 칭하겠습니다. 이런 방식으로 모든 비디오에서 action, coupling sample을 만들어낼 수 있겠죠.
그림 4에서 노란 프레임들이 실제 주어진 action 구간일 때 해당 feature a와 cosine 유사도가 가장 높은 non-action 프레임들은 초록색 구간이고, 그 구간의 feature가 c가 되는 것입니다. a, c의 공통점과 차이점을 이용하면 action feature와 co-occurence feature를 각각 분리할 수 있을 것입니다.
2.4 Decoupling Action and Co-occurence Components
이제 혼재되어 있던 두 구성요소를 어떻게 분리해주는지 알아보겠습니다.
Action sample에는 action 요소와 co-occurence 요소가 둘 다 존재할 것입니다. 그리고 coupling sample은 GT 구간에 해당하지 않았으므로 action 요소가 존재하지 않지만, action sample과 cosine 유사도가 크므로 co-occurence 요소는 존재한다고 해석할 수 있습니다. 그림 3에서의 야구장, 골대처럼 action에 간접적으로 관여하는 부분을 feature로 담고 있다는 의미입니다.
이 때 두 가지 encoder \phi{}_{A}, \phi{}_{C}가 등장합니다. 둘의 구조는 같지만 가중치는 공유하지 않고, 각각은 입력된 feature로부터 action을 추출하는 인코더, co-occurence를 추출하는 인코더에 해당합니다. 일단 action과 co-occurence loss 수식부터 살펴보겠습니다.
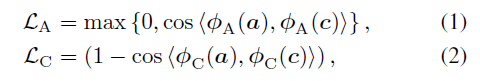
수식 (1)의 \mathcal{L}_{A}는 action 구간의 feature a에서 얻을 수 있는 action 요소 \phi_{A}(a)와 coupling 구간의 feature c에서 얻을 수 있는 action 요소 \phi_{A}(c) 사이의 cosine 유사도를 최소화하고 있습니다. a와 c는 action이 실제로 존재하는지 하지 않는지의 차이가 있으므로 둘 간의 코사인 유사도를 최소화한다면 \phi{}_{A}가 존재하는 action 요소를 잘 잡아내는 인코더로 학습될 것을 기대할 수 있습니다.
수식 (2)의 \mathcal{L}_{C}는 action 구간의 feature a에서 얻을 수 있는 co-occurence 요소 \phi_{C}(a)와 coupling 구간의 feature c에서 얻을 수 있는 co-occurence 요소 \phi_{C}(c) 간의 cosine 유사도를 최대화 하도록 설계되어 있는 것을 볼 수 있습니다. a와 c에는 co-occurence 요소가 공통적으로 포함되어 있으므로 둘 간의 유사도를 최대화함으로써 \phi{}_{C}가 co-occurence 요소를 잘 잡아내는 인코더로 학습되도록 기대할 수 있게 되는 것입니다.
두 인코더가 잘 학습되었다면 inference 과정에서 임의의 snippet feature f를 입력받았을 때 \phi{}_{A}(f)는 f의 action feature, \phi{}_{C}(f)는 f의 co-occurence feature라고 해석할 수 있을 것입니다. 저자의 목적대로 action과 co-occurence를 분리할 수 있게 된 것입니다.
2.5 Recombining Action and Co-occurence Components
앞선 절에서 두 인코더 \phi{}_{A}(f), \phi{}_{C}(f)를 통해 두 구성요소를 잘 분리했다면, 서로에게 과의존하지 않도록 적절히 합쳐주어 refactoring 된 feature f'을 생성하는 과정이 필요합니다. 이 때 \phi{}_{A}(f)가 주변 환경이 제거된, 정제된 action feature에 해당하므로 이것만을 feature로 사용하면 어떨까 생각해보았지만, 실제로 task를 수행할 때 co-occurence로부터 도움을 받는 부분도 많아서인지 무작정 제외해버린다고 높은 성능을 보이는 것은 아니었습니다. 이 부분에 대한 실험 결과는 뒤에서 다루도록 하겠습니다.
아무튼 입력 받은 임의의 snippet feature f를 \phi{}_{A}(f), \phi{}_{C}(f)로 분리한 뒤 다시 합치는 과정은 단순한 concatenation으로 수행됩니다. 뭔가 큰 연산이 있을 줄 알았는데 단순 concat만으로도 잘 동작한다는 점이 놀랍습니다.
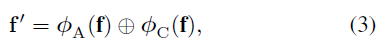
RefactorNet에서 action과 co-occurence feature를 분리한 이유는 task를 수행하는데에 있어 co-occurence에 매몰되지 않게 하기 위함이었습니다. 하지만 이렇게 분리하여 얻은 co-occurence feature를 단순 concat 해주는 것만으로는 매몰되지 않을 것이라는 보장을 하기 힘들겠죠. 그래서 저자는 co-occurence feature를 규제해줄 수 있는 loss \mathcal{L}_{KL}까지 붙여서 사용합니다.
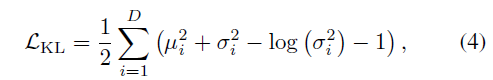
식 (4)에서 \mu{}와 \sigma{}는 co-occurence feature 분포의 평균과 표준편차를 의미하고, D는 feature 차원입니다. \mathcal{L}_{KL}을 통해 co-occurence feature의 분포를 정규분포에 다가가도록 만들어줌으로써 영향력을 줄일 수 있는 것입니다. 해당 식이 왜 feature의 분포를 정규분포에 가깝도록 만드는지에 대한 증명은 논문의 10페이지에 나와있으니 궁금하신 분들은 참고하시면 좋을 것 같습니다.
3. Training and Inference
3.1 Training
학습은 총 3 stage로 이루어집니다. 먼저 RefactorNet의 최종 loss \mathcal{L}_{\mathcal{R}}을 학습시켜주고, 이는 앞서 살펴본 3가지 loss로 구성됩니다.
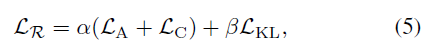
RefactorNet을 잘 학습시켜 정제된 feature를 얻었다면, 이를 BSN의 입력으로 주어 BSN을 학습시킵니다. 이 때의 loss \mathcal{L}_{\mathcal{P}}는 아래와 같습니다.
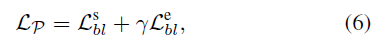
\mathcal{L}_{bl}은 BSN에서 사용되는 binary logistic regression loss로, 생성한 proposal에 대해 시작 지점과 끝 지점을 학습하게 됩니다.
마지막으로, 학습한 BSN이 제안하는 구간들을 아래 loss \mathcal{L}_{\mathcal{D}}를 통해 refine 해줍니다.
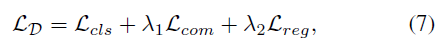
먼저 BSN이 제안한 구간의 feature를 3개의 MLP에 태우는데, 하나는 구간의 action을 분류하기 위한 classification head, 또 하나는 구간이 실제 action에 비해 넘치거나 부족한지 따지는 completeness head, 마지막은 localization을 위한 boundary regression head입니다.
각 head의 출력값은 매칭된 GT 구간과 유사해지도록 학습하게 됩니다. 이 때 \mathcal{L}_{com}는 본문에 정확히 수식이 나와 있지 않은데, 다른 논문들을 참고해보니 GT와의 tIoU를 최대화하도록 학습하는 것으로 추정됩니다.
3.2 Inference
Inference 단계에서는 학습된 RefactorNet이 feature F를 입력받아 F'을 내뱉게 됩니다. 이후 F'이 BSN의 입력으로 들어가 proposal을 생성하고, 3개의 MLP head를 통해 각 proposal의 offset, 클래스와 confidence score, completeness score를 얻게 됩니다. 이후 confidence score와 completeness score를 곱한 최종 score와 클래스를 이용해 soft-NMS 과정을 거쳐 최종 proposal을 만들어냅니다.
4. Experiments
WTAL에서 설명드리던 실험 부분과 같이 TAL에서도 THUMOS14와 ActivityNet v1.3 데이터셋에 대해 벤치마킹을 진행하였는데, 성능을 알아보겠습니다.
4.1 Comparison with State-of-the-art Methods
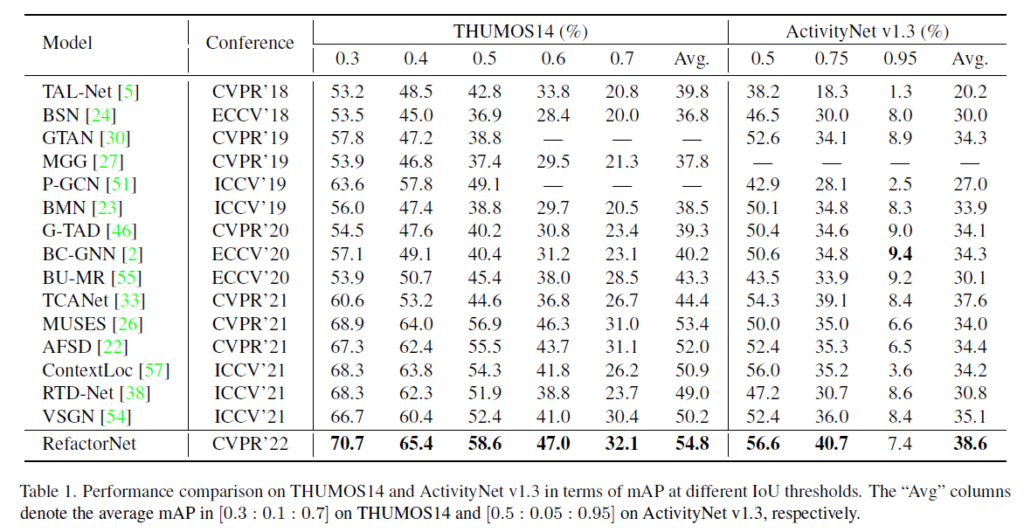
방법론이 굉장히 간단함에도 불구하고 높은 성능 향상을 이뤄냈습니다. 저자도 벤치마크에서 성능 향상에 대한 분석은 따로 하고 있지 않고, 뒤쪽에 ablation study에 많은 분석이 있으니 넘어가보도록 하겠습니다.
4.2 Ablation Study
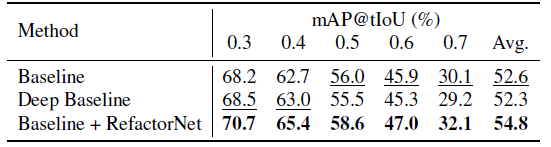
표 2는 베이스라인 대비 향상된 성능 폭을 보여주고 있습니다. 베이스라인은 I3D로부터 추출한 feature를 하나의 1D Conv에 태워 BSN으로 넘겨주는 방식을 의미합니다. 그리고 RefactorNet에서는 1D Conv가 한 층이 아니고 여러 층을 사용하는데, 단순히 층이 많아져서 성능이 오른 것이 아님을 증명하기 위해 베이스라인의 층 개수를 RefactorNet과 같도록 늘린 Deep Baseline 성능을 측정하였습니다. 이를 통해 성능 향상이 action과 co-occurence라는 두 구성요소의 적절한 조화로부터 온 것이라는 것을 알 수 있었습니다.
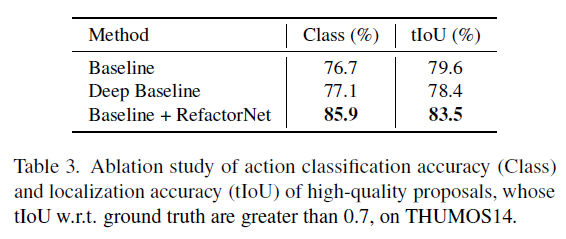
다음으로 표 3은 제안된 proposal의 action 클래스 분류 성능을 보여주고 있습니다. WTAL에서 분석을 보여줄 때 보통 mAP만을 리포팅 하는 경우가 대다수인데 분류에 대한 정확도를 보여주는 점이 인상깊었습니다. WTAL 방법론들을 학습하다보면 학습 중의 분류 정확도는 수렴하는 경우 99%가 넘어가는데, 생각해보니 test 데이터에 대한 분류 정확도를 주의 깊게 살펴본 적이 없는 것 같습니다. 분류 정확도가 TAL에서 이정도이니 WTAL에서는 생각보다 더욱 낮겠네요. 아무튼 action 클래스에 대한 정확도도 유의미하게 오른 점을 확인할 수 있었습니다.
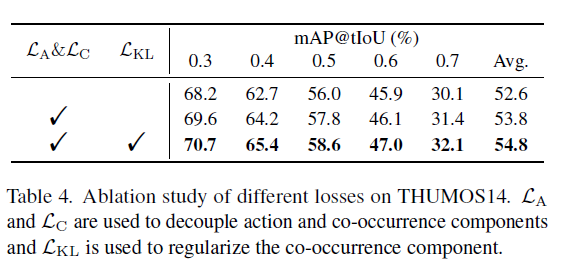
표 4는 loss에 대한 ablation 실험입니다. \mathcal{L}_{KL}을 붙여 co-occurence feature의 개입력을 억제하여 최종 feature를 만드는 경우 성능이 오르는 점으로 보아 기존에 co-occurence 요소들에 매몰되는 경우가 많았다는 점을 증명한 것이 개인적으로 인상깊었습니다.

그림 5는 RefactorNet이 찾아낸 구성 요소의 feature가 실제 의도대로 추출되었는지 CAM을 통해 보여주고 있습니다. 물론 잘 뽑힌 결과만을 가져왔을 수도 있겠지만 보여주는 그림 상으로는 완벽하게 의도대로 feature가 보아야 하는 부분들을 잘 보고있는 것을 볼 수 있습니다.
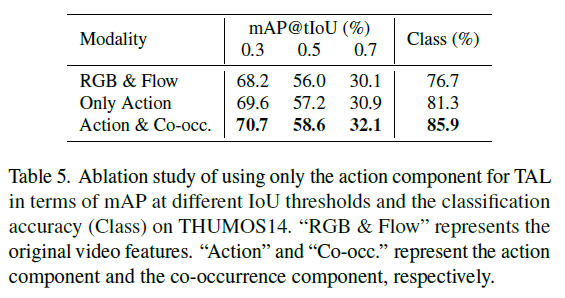
다음으로 표 5는 아까 2.5절에서 말씀드린 대로, 분리한 action feature만을 사용하는 경우의 성능을 리포팅하고 있습니다. Action만을 사용하게 되면 기존 baseline보다는 성능이 오르긴 하지만, 억제된 co-occurence를 함께 활용하는 것이 확실히 localization과 분류에 큰 도움이 된다는 점을 표 5를 통해 확인할 수 있었습니다.
이외에도 논문에 정성적 결과가 리포팅되어 있으니 궁금하신 분들은 찾아보시면 좋을 것 같습니다.
5. Conclusion
저자가 주장하는 아이디어가 Action Localization을 위해서는 중요하게 여겨져야 하는 것들을 다루고 있고, 이것이 잘 동작한다는 점을 다양한 분석을 통해 밝혔기 때문에 납득하기 쉬운 논문이었습니다. 개인적으로 WTAL을 잘 수행하기 위해 어떤 단서들을 수집할 수 있을까에 대한 통찰력을 얻기 위해 읽은 논문인데, 무조건 복잡한 모듈을 붙이는게 전부가 아니라는 것을 다시 한 번 깨닫게 해준 논문이었습니다.
리뷰 마치겠습니다.
안녕하세요. 김현우 연구원님 리뷰 잘 읽었습니다.
리뷰 내용을 보니 결국은 프레임 내에서 action과 background의 구분을 잘 하는 것의 중요성에 대해서 언급하는 것 같습니다. 학습 과정에서도 이에 대한 언급을 위주로 진행하고 있고요. 다만, supervised에서 가능한 방법이고 weakly supervised에서는 적용하기 어려보일 것 같습니다. 이 부분에 대해서 생각해두신 적용 방안이 있나요?
추가적으로 Action/Co-occ 실험을 보니… Co-occ만 있을 경우의 실험 결과를 보고싶은데 혹시 있을까요?
1)
Weakly-supervised 방식에서 본 논문과 같이 하나의 비디오를 action과 co-occurence로 나눠 모델링하는 것은 말씀해주신대로 쉽지 않을 것이라고 생각합니다. 만약 본 방법론을 Weakly-supervised 상황에서 적용해야 한다면 pseudo label을 만들어 action 구간을 임시적으로 정한 뒤 해당 라벨을 action/non-action frame으로 보고 위 방법론을 적용해도 유효하지 않을까 생각하고 있습니다.
왜냐하면 복잡한 방법론이 난무하는 TAL 가운데에서 비디오의 구성 요소를 잘 다루는 것만으로도 크게 성능이 오를 수 있다는 것을 증명했기 때문입니다.
물론 결과는 실험을 해봐야지만 알 수 있을 것 같습니다..
2)
Co-occ 만을 사용하는 경우의 성능은 리포팅하고 있지 않습니다. 논문에서도 계속해서 action이 메인이고 co-occurence는 적절히 도움을 주는 역할을 한다고 말하는 것으로 보아 성능이 높지는 않을 것으로 예상됩니다.
안녕하세요. 좋은 리뷰 감사합니다.
coupling sample은 결국 특정 Action Frame에 상응하는 Non-action Frame의 집합을 의미한다고 하셨는데, 제 이해 부족으로 ‘ 특정 Action frame에 상응하는 non-action frame이라는 것’이 잘 와 닿지가 않습니다. 높이 뛰기 액션 프레임이 있을때 관중들만 있는 frmae이 액션 프레임에 상응하는 논 액션 프레임 일까요?
감사합니다.
리뷰 2.3절을 보시면 이해하기 쉬우실 것 같습니다.
저희가 temporal annotation은 가지고 있다는 것은 각 프레임이 action인지 non-action인지 알 수 있다는 것입니다.
질문해주신 ‘특정 Action frame에 상응하는 non-action frame이라는 것’의 관점에서 보았을 때 coupling sample이란, non action frame 중에서 action frame과 feature의 코사인 유사도가 가장 높은 구간을 의미합니다. coupling sample은 non-action임이 자명하므로 action은 존재하지 않으면서 action frame과 코사인 유사도가 가장 높기 때문에 co-occurence 요소들이 존재할것이라고 가정하고 학습을 하는 것입니다.
리뷰 잘 읽었습니다. Co-occurence라는 insight가 흥미롭습니다.
지도학습의 TAL 경우 detector 부분에서 보통 TSN의 파이프라인을 그대로 사용하나요? 다른 방법론도 그렇게 진행하는 지 궁급합니다.
저도 질문해주신 부분이 궁금하여 Benchmark 표에 있는 최근 SOTA 방법론 몇 가지를 살펴보았습니다.
결과적으로 본 논문처럼 자신들만의 방법론으로 좋은 feature를 생성한 뒤 BSN에 던져 proposal을 받는 논문도 있었고, 일부는 feature 생성 후 action proposal과 classification 과정까지 제안하는 논문들도 있어 반반 정도라고 생각하시면 좋을 것 같습니다.
안녕하세요. Action Localization을 처음 접하는데도 아주 이해하기 쉽게 깔끔하게 정리된 리뷰같습니다. 좋은 리뷰 감사합니다.
리뷰를 읽고 의문이 드는 부분은,
1)KL loss를 이용하여 co-occurence feature를 정규분포에 가깝게 만든다는 것이 어떤 것을 의미하는 것인지(시각화를 보니 한 프레임 안에서 정규분포의 형태를 갖는 것 같은데 이렇게 feature map형태를 정규분포로 만드는 것인지, 아니면 batch나 전체 데이터에 대하여 feature들이 특정한 값을 갖도록 만드는 것인지)
2) co-occurence feature를 정규분포로 만드는 것이 어떻게 a, c 두 feature를 적절하게 모두 활용하는 것으로 이어지는지
궁굼합니다!
감사합니다 ?
본 task에서는 결국 action을 찾는 것이 주요 목적이고 co-occurence는 이를 보조해주는 정도로 생각해볼 수 있습니다. co-occurence feature는 어떤 action에 붙어있는지에 따라도 다양하겠지만, 심지어는 하나의 action 클래스에 붙어있는 co-occurence들 끼리도 굉장히 다양할 수 있습니다.
이렇게 제각기 다른 feature의 분포를 정규분포로 만들어줌으로써 action에 붙였을 때 co-occurence 때문에 action이 매몰되는 현상을 방지(일종의 normalization)하는 것으로 이해하시면 좋을 것 같습니다.
한 비디오에서 추출한 coupling sample에 속하는 co-occurence feature 하나마다 평균이 0, 표준편차가 1인 정규분포에 가까워지도록 학습합니다.