원래 PointNet++을 리뷰하려고 했는데 PointNet++이 pointnet을 기반으로 하기 때문에 pointnet에 대한 이해가 필요하다고 생각하여 우선적으로 리뷰하게 되었다.
point cloud data는 irregular한 format을 가진다. 이미지의 경우 모든 공간의 픽셀값을 가지고 있지만 point cloud는 그렇지 않다. 이전에는 point cloud 데이터를 처리하기 위해 regular한 3D voxel grid형태로 변환하거나 images로 변환 처리하여 사용하였다. 본 논문에서는 point cloud를 input으로 받아 data transform이 필요없이 direct하게 사용할 수 있는 neural network인 PointNet을 제안하였고 좋은 performance를 보였다.

Introduction
본 논문에서는 3d geometric data인 point cloud를 활용할 수 있는 deep learning architecture인 pointnet을 제안한다. 기존 convolutional architectures는 regular한 input data format을 필요로 했다. 하지만 point cloud는 3차원 공간의 흩뿌려져 있기 때문에 regular한 형태로 분포하지 않는다. 따라서 기존에는 image grid로 변환하여 kernel을 씌워 사용하거나 3d voxel형태로 처리하여 regular한 형태로 사용하였다.

하지만 point cloud를 다른 형태의 data로 transform하게 되면서 quantization artifacts가 되기 때문에 기존의 natural한 data가 가지는 invariances를 잃을 수 있다. 어려운 표현인 것 같은데 이해한 바로 쉽게 풀어보자면 3d space의 흩뿌려진 points들이 voxel grid로 인해 연속적인 공간에서 이산적으로 바뀌기 때문에(quantization artifacts) 기존 data의 invariance가 방해받을 수 있다는 것이다.
이러한 이유로 인해 3D geometric 정보를 그대로 활용할 수 있는 방법을 모색하게 된다. point cloud는 voxel이나 이웃하는 점들을 고려해야하는 mesh에 비해 simple하기 때문에 학습에 다루기 더 쉽다. 하지만 point cloud는 단순히 points들을 조합한 것이기 때문에 permutation invariant하고 rigid motion에도 invariant해야한다. permutation invariant란 irregular한 points들을 회전시키거나 이동시키는 경우에서처럼, points들이 어떤 순서로 들어오든 같은 결과를 보여야한다는 것이다. rigid motion이란 transformation을 해도 point들 간의 distance와 방향은 그대로 유지되는 것을 의미한다.
PointNet은 raw point cloud를 사용하여 모든 input에 대해 class label을 output으로 한다. segmentation의 경우 segmentation하려는 points마다 label을 output결과로 반환한다. 모든 input points에 대해 class나 segmentation을 처리한다는 점에서 unified model이라고 주장한다. PointNet 방식의 key point는 symmetric function으로 max pooling을 사용한다는 것이다. max pooling을 사용하는 방식에 대해서는 아래에서 더 자세하게 알아보도록 하자. network는 interesting하거나 informative points를 찾는 방법을 학습하고, 그 중요한 points들을 찾은 근거를 encode하게 된다. network 마지막의 fully connected layers는 max pooling을 통과한 optimal values를 aggregate하여 global descriptor를 생성하고 이 global descriptor는 classification을 위한 전체적인 shape을 나타내거나 segmentation을 위한 per point labels를 예측하는데 사용된다. 그리고 pointnet을 통과시키기 전에 data를 일반화(canonicalize)하여 성능을 높이기 위해 spatial transformer network를 추가하였다.
network의 흥미로운 점 중 하나는 input point cloud를 sparse set of key points로 summarize 하는 것을 학습한다. 여기서 sparse set of key points는 시각화했을 때 skeleton에 해당하는 points들을 의미하며 max pooling을 통해 key points를 추출할 수 있다. 뒤에서 나오는 upper bound shape point나 criticial point들이 key points가 된다. 또한 PointNet은 outlier나 missing data와 같은 input point의 perturbation(작은 변화)에도 강인하다.
본 논문에서 제안하는 contribution은 아래와 같다.
– unordered 3d point set에 적합한 새로운 딥러닝 architecture 고안
– 3D shape classification, shape part segmentation, scene semantic parsing tasks에 적용 가능
– 제안하는 방법의 stability와 efficiency에 대한 경험적, 실험적 분석
– network가 선택한 3D features에 대한 illustration
Related Work
Point Cloud Features
기존의 point cloud features는 handcrafted방식으로 point의 특정 statistical한 특성을 encode하여 특정 transformations에 대해 invariant하게 design되었다. 예를 들어 intrinsic, extrinsic이나 global feature, local feature같은 경우이다.
Deep Learning on 3D Data
3D data는 다양한 representations로 사용되었다. Volumetric CNN은 voxel 형태로 3D convolutional neural network를 적용하였다. 해당 방식은 data sparsity와 computational cost가 많다는 문제가 존재하였다. FPNN과 Vote3D는 sparsity 문제를 해결하기 위해 제안되었다. 하지만 해당 모델들도 여전히 sparse한 volumn형태를 사용하였고 방대한 point cloud를 처리하는데 어려움이 있었다. Multiview CNN의 경우 3D point cloud를 2D images로 변환하여 2d convolution을 적용한 모델이다. 이 방식은 scene understanding에 어려움이 있고 point classification과 같은 3D task로 확장하는데 어려움이 있었다. 파장 영역을 활용한 Spectral CNN과 3D data를 vector로 변환하여 feature를 추출하는 Feature-based DNN의 경우도 input data의 representation방식이 feature extract을 할 때 제약이 되었다고 주장한다. point cloud를 그대로 사용하는 것이 좋다는 것을 강조하기 위한 설명이다.
Deep Learning on Unordered Sets
point cloud의 data structure는 unordered한 vectors라고 할 수 있다. 기존 deep learning에서는 sequence data나 images 혹은 3D voxel과 같은 regular한 input representation에 focus를 맞추었기 때문에 point set을 직접 활용하는 연구는 진행되지 않았다고 한다. 본 논문의 contribution이 의미있다는 것을 강조하는 부분이다.
Problem Statement
본 논문에서는 unordered point sets을 input으로 하여 direct하게 사용하는 새로운 방식의 deep learning framework를 제안한다. point cloud는 보통 3d points로 vector로 표현되는데, (x,y,z)의 coordinate뿐만 아니라 color, normal 등의 정보를 표현하는 extra feature channels로 구성된다. 하지만 본 논문에서 제안하는 모델은 간단하게 (x,y,z)의 coordinate 정보만을 사용한다.
classification task에서의 output은 모든 k개의 candidate classes들에 대한 k개의 score가 되고 그 중 max인 class로 분류하게 된다. semantic segmentation의 경우 input으로는 part region segmentation에서 얻은 single object나 object region segmentation으로 부터 얻은 3d scene에서의 sub-volume이 되고 output은 n x m의 scores가 된다. 이때 n은 points의 수이고 m은 semantic categories이다.
Deep Learning on Point Sets
Properties of Point Sets in Rn
3차원 point cloud를 딥러닝 에서 다루기 위해 필요한 조건들에 대해 크게 3가지 특성으로 정리하였다.
– Unordered
image의 pixel이나 voxel구조의 grid와는 다르게, point cloud는 순서(order)가 존재하지 않는 points들의 집합이다. 따라서 network는 N개의 3D point sets를 N!(factorial)만큼에 대해 permutation invariant해야한다. 위의 introduction에서 언급했듯이 permutation invariant란 points들이 어떤 순서로 들어오든 같은 결과를 보여야한다는 것을 의미한다.
– Interaction among points
points들운 일정한 distance를 간격으로하여 구분되어져 있는데, 이웃하고 있는 points사이에는 그 부분의 meaningful한 정보를 가지고있다. 따라서 model은 이러한 euclidean space상에서 근접한 points들끼리 가지는 local structure를 파악할 필요가 있다.
– Invariance under transformations
앞의 introduction에서 언급했던 것 처럼 rotation이나 translation과 같은 transformations에 대해 invariant해야한다. 쉽게 말해서 transformations로 인해 classification이나 segmentation결과가 바뀌면 안된다는 뜻이다.
PointNet Architecture
아래 Figure 2에서는 pointnet의 전체적인 architecture를 보여준다.

network는 크게 3가지의 key modules로 나뉘어진다. the max pooling layer as a symmetric function(aggregate information), local and global information combination structure, two joint alignment networks(align input points & point features) 이렇게 3가지로 나누어지고 이제 하나씩 살펴보도록 하자.
Symmetry Function for Unordered Input
model이 3d point cloud input에 대해 permutation invariant하게 하기위해 3가지 strategies가 존재한다.
1. Input을 canonical order로 정렬
해당 방식은 모든 input data를 canonical order로 정렬하는 방법이다. 여기서 canonical order란 정해진 순서로 정렬한다는 뜻이다. 설명이 부족하여 이해가 어려울 수 있으니 쉬운 예를 들어보겠다. 만약 ‘aewcb’라는 단어를 입력받았을 때 canonical order로 정렬한다고 하면 ‘abcew’라는 순서로 정렬하는 것이다. 알파벳 순서가 정해져있기 때문이다. 그럼 unordered한 3차원 point cloud를 canonical order로 정렬하려면 어떻게 정렬해야할까. 그렇다 나도 잘 모르겠다. 이처럼 stable한 order가 존재하지 않기 때문에 해당 방법은 적용을 고려하기가 어렵다.
2. input data를 sequence data로 여기고 RNN 적용. 단, 모든 permutation(작은 변화)에 대해 augmentation
해당 방법은 모든 permutations를 고려하면 RNN같은 모델은 permutation invariant할 수 있지만, 전체 N개의 points가 있다고 하면 총 N!가지의 orders가 생기기 때문에 costs가 너무 커지게 된다. 또한 이런 large scale의 RNN을 적용했을 때 성능이 보장되지 않는다는 것을 실험적으로 보였다고 한다.
3. simple symmetric function(max pooling) 사용
따라서 본 논문에서는 symmetric function을 적용하여 permutation invariance하도록 했고 maxpooling을 사용하였다. 여기서 symmetric function이란 교환법칙이 성립하는 ‘+’나 ‘x’가 대표적인 예시이다. symmetric은 대칭이라는 뜻으로 예를 들어보자면 2+3이나 3+2나 모두 5라는 같은 결과를 가진다. 곱셈의 경우에도 2×3 == 3×2 는 모두 6이라는 같은 결과 값을 보인다. 반면 뻴셈의 경우 2-3과 3-2의 결과가 다르다. 중요한 것은 순서에 관계없이(unordered) 같은 결과를 보인다는 것이다. maxpooling을 통해 전체 points들 중 global한 feature vector를 얻는 수식(1)은 아래와 같다. Figure 2의 전체 network 그림에서 maxpooling부분을 함께보면 이해하는데 도움이 될 것 같다.
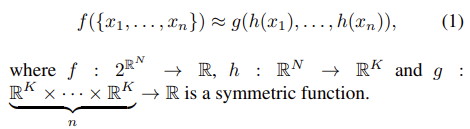
x : point cloud
h : mlp layers
g : max pooling
f : global feature vector
Local and Global Information Aggregation
우리는 point cloud를 maxpooling을 통과시켜 [f1,…,fk]형태의 output vector를 얻게 되는데 이것은 point cloud set의 global features가 된다. 이렇게 얻은 global features를 SVM이나 mlp classifier를 통과시켜 classification을 할 수 있지만, segmentation의 경우에는 global 뿐만 아니라 local features도 추가로 얻어 local, global 정보를 합치는 것이 필요하다. 이러한 combination features를 얻기 위해 max pooling을 통과한 global feature vector와 max pooling을 통과하기 전 feature transformation을 통과한 feature vector를 붙이게(concatenate) 된다. 이렇게 얻은 새로운 vector를 segmentation branch의 input으로 입력하여 통과시키면 새로운 per point features를 얻게 되는데 이 features가 global + local한 정보를 가진 features라고 할 수 있겠다. per-point normals와 같은 modification을 해주면 local geotetry와 global semantic한 부분을 더 잘 볼 수 있다고 한다.
Joint Alignment Network
어떤 geometric transformation(rigit motion)을 거쳤을 때 point cloud의 semantic labeling을 할 때에도, transformation에 invariant해야한다고 위에서 언급했었다. 해당 파트는 translation에 invariant하기 위한 솔루션을 제안한다. 새로운 layer를 추가하는 방식은 아니고 두 개의 T-net이라는 mini-network를 추가하여 affine transformation을 수행하고 direct하게 input points들에 transformation을 적용해주었다. T-Net은 Spatial Transformer Network;STN를 의미한다. STN에 대해서는 간단하게만 찾아보았다.
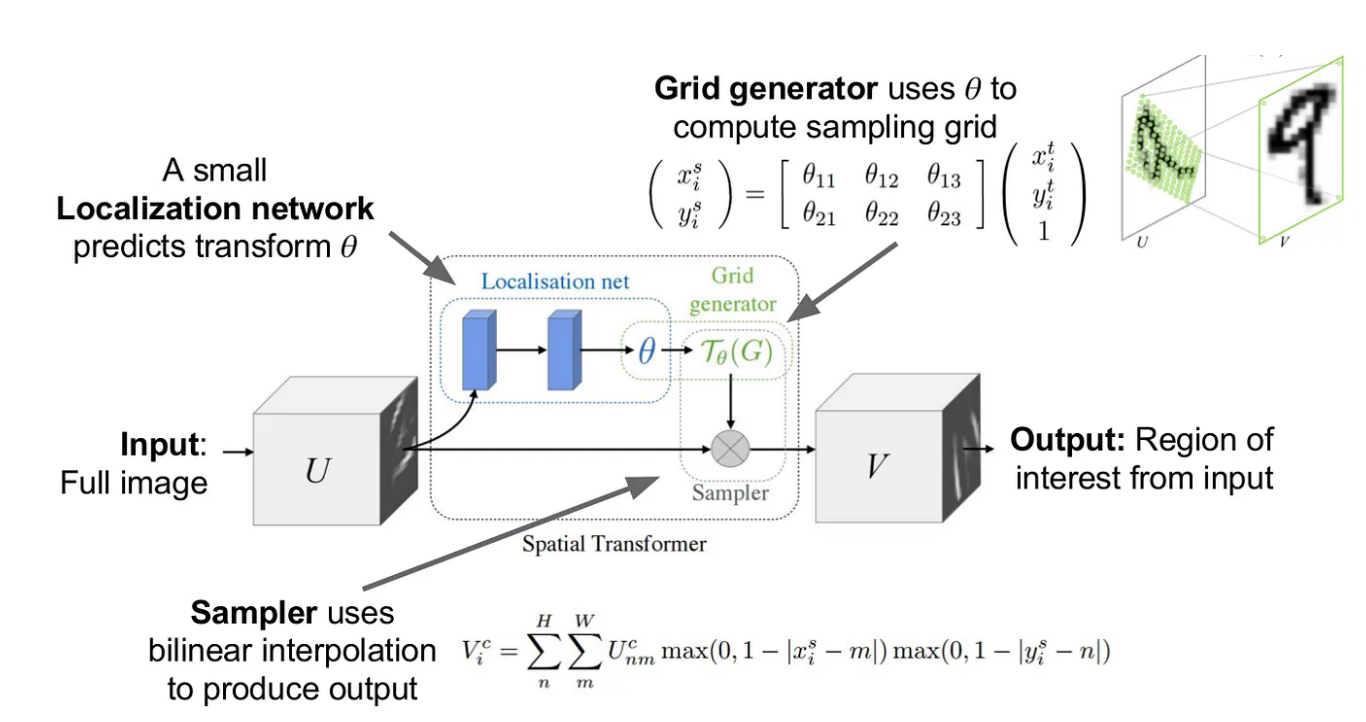
STN은 image에 대해 rigid motion invariant를 만족시키기 위해 image를 orthogonal하게 만든다고 한다. 다시 말하자면 rigid motion이란 transformation을 해도 point들 간의 distance와 방향은 그대로 유지되는 것을 의미한다고 하였다. 우선 Input image를 canonical space로 보내기 위해(== orthogonal하게 만들기 위해) 어떤 transformation이 적용되어야 하는지 계산한 후, 계산한 transformation을 기존의 input image와 곱하여 transformation이 일어나지 않은 output image를 만드는 과정으로 동작한다고 한다.

논문에서는 이 T-Net 개념을 feature space의 alignment하는 것으로도 확장할 수 있다고 한다. mlp를 통과한 다른 input point cloud에서 나온 features와 align을 맞춰주기 위한 transform을 예측하는 network를 사용한다. 이것이 two joint alignment network인 이유이다. 하지만 feature space에서 transformation matrix는 spatial transformation matrix보다 higher dimension이기 때문에 optimization에 어려움이 있다고 한다. 따라서 feature transformtion matrix가 orthogonal matrix에 근사하도록 하는 regularization term을 training loss에 추가하였다.

A : feature alignment matrix(mini-network로 예측된 값)
수식(2)를 보면 직관적으로 feature alignment matrix A가 orthogonal matrix에 근사되도록 하는 수식인 것을 알 수 있다. transformation이 orthogonal해지면 input에 대한 정보를 많이 잃지 않을 수 있기 때문에(transformation이 줄어드는 방향이기 때문에) 더 stable하고 좋은 성능을 보일 수 있었다고 한다.
Experiment
experiments는 크게 4가지 파트로 구분된다. multiple 3D tasks(classification, segmentation)의 application 결과, network design의 효용성 입증 실험, visualization, time과 space complexity로 구성되며 하나씩 살펴보자.
Applications
3D Object Classification
논문에서는 model을 평가하기 위해 ModelNet40 dataset을 사용하였다. ModelNet40은 12,311개의 CAD model로 구성되어있고 이름에서처럼 40개의 object categories를 가지고 있다. 각각 9,843개와 2,468개의 training, test data로 나뉘게 된다.

이전 voxel이나 multi-view images를 사용한 방법론들과 다르게 pointnet이 최초로 raw point cloud를 사용한 방법론이다. mesh 표면에서 1024개의 uniform한 points를 sampling하고 normalize하여 point cloud를 생성하였다. training시 random하게 rotating을 주고 gaussian noise도 추가하였다.
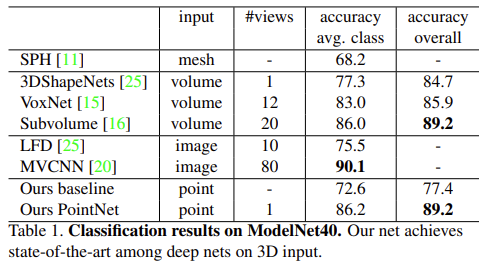
Table 1을 보면 이전 3D input 방법론들과의 비교 결과를 알 수 있다. baseline은 고전적인 feature extraction을 사용하여 MLP를 적용한 방법으로 설정했다. 우선 전반적인 성능을 보면 pointnet이 다른 sota모델들과 비교했을 때 월등히 좋은 성능을 보이는 것이 아니라 조금 더 좋거나 오히려 조금 더 낮은 성능을 보이는 것을 알 수 있다. 하지만 여기서 중요하다고 생각한 점은 다른 방법론들은 3d point cloud를 voxel이나 mesh 또는 image로 변환하여 사용하는 전처리과정이 필요한 방법론들 이었기 때문에, raw point cloud를 direct로 사용하여 다른 이전 방법론들과 견줄만한 성능을 보였다는 것 차제 만으로도 충분한 contribution이 되지 않았나 생각된다. 논문의 저자는 MVCNN과 성능 차이가 많이 나지 않는다는 점을 언급하면서 multi view로 rendering된 image가 fine geometry details를 더 잘 catch해서 그런것 같다고 설명하였다.
3D Object Part Segmentation
part segmentation은 object의 일부분에 해당하는 category lables(의자의 다리 부분, 컵의 손잡이 부분 등)을 예측해야 하기 때문에 3D task중 어려운 부분에 속한다. 평가를 위해 ShapeNet part data를 사용하였다. 16개의 categories를 가지며 16,881개의 shape이 존재하고 전체 ㅊategories에 대해 50개의 part로 구성되어있다.

여기서는 part segmentation task를 per-point classification 문제로 고려하였다. 평가 지표는 mIoU를 point마다 사용하였다. mIoU란 mean intersection over union의 약자로 segmentation task에서 사용하는 대표적인 성능 측정 방법이라고 한다. segmentation에서 mIoU계산하는 법을 간단하게 알아보자면 우선 실제 class와 예측한 class에 대한 matrix를 각각 구하고 confusion matrix를 생성한 다음 각 class 별 IoU를 계산한다.
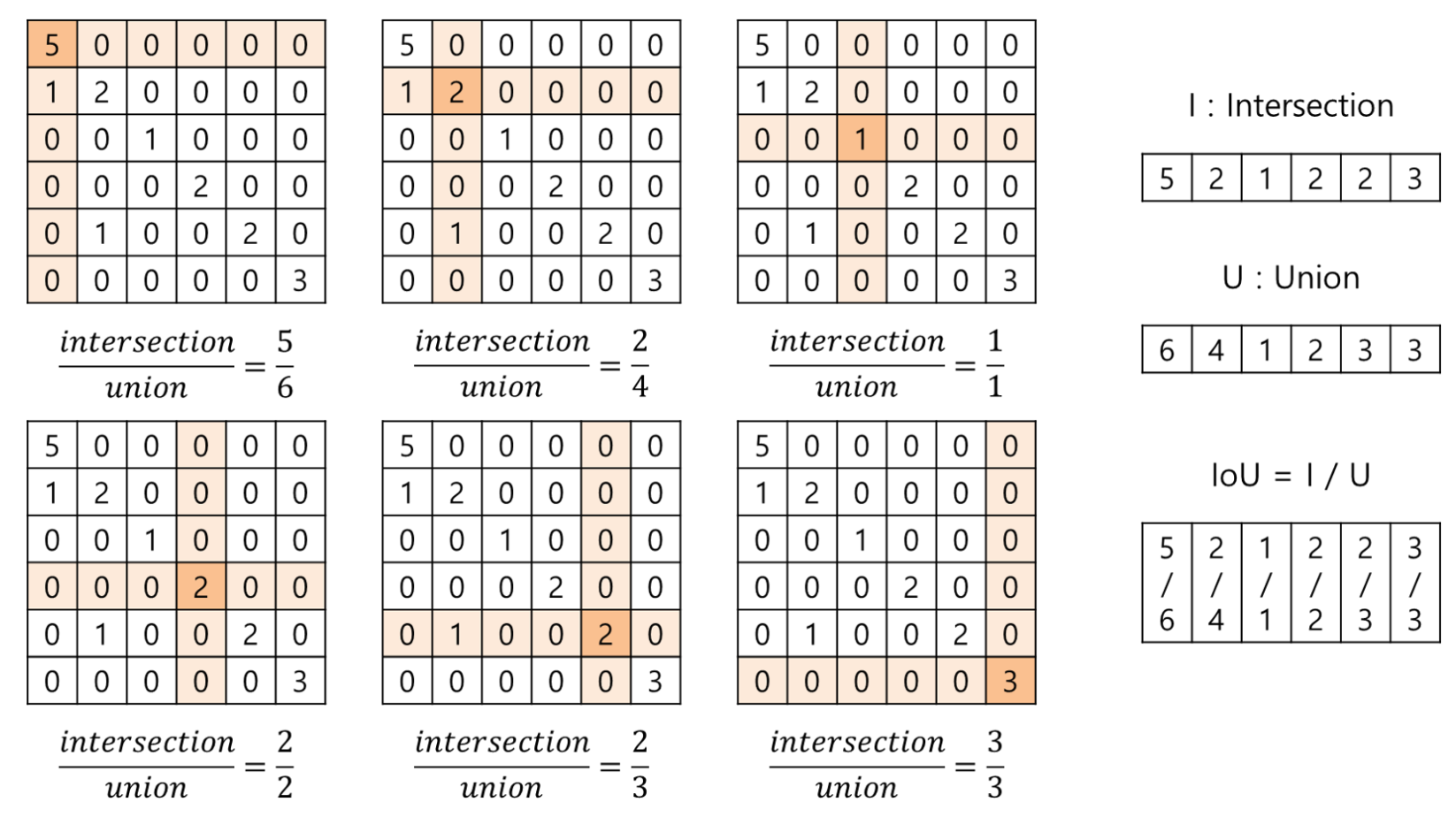
이렇게 구한 클래스 별 IoU 결과를 평균내면 mIoU를 구할 수 있다.

Table 2를 보면 segmentation을 수행한 pointnet과 기존 traditional한 방법론 2개(Wu, Yi)와 비교하였다. 3DCNN은 단순히 3D convolution을 쌓은 모델로 baseline으로 잡은 네트워크이다. 대부분의 categories에서 좋은 결과를 보이는 것을 알 수 있다.
또한 Kinect scan에서도 모델 성능의 robust함을 확인하기 위해 simulate 해보았다고 한다. 6개의 random한 viewpoints에서 incomplete한 point coud를 생성하여 사용하였다. 그 결과 mIoU가 5.3%정도의 하락만 있었다고 한다.
아래 Figure 3에서 complete/incomplete data의 결과를 비교해볼 수 있다. 상대적으로 partial(incomplete) data가 더 segmentation에서 어려움을 보이는 것을 확인할 수 있다.

Semantic Segmentation in Scenes
본 실험에서는 Stanford 3D semantic parsing dataset(S3SIS)을 사용하였다. 6개 areas에 존재하는 271개 rooms에 대해 3d scan한 데이터 셋이고 각 point마다 13개 categories(chair, table, floor, wall etc.)에 대해 semantic labels가 annotation되어있다.

각 points는 9-dimension vector로 x,y,z coordinate정보 말고도 r,g,b정보와 방에서의 normalized location 정보(0~1사이 값)를 추가로 사용한다. baseline network는 hand-crafted point features를 사용한 방법으로 비교하였고 baseline에서는 9-dimension vector에 추가적으로 local point density, local curvature(곡률), normal 정보를 추가하여 12-dimension vector를 사용하였다. classifier로는 일반적인 MLP를 사용하였다.
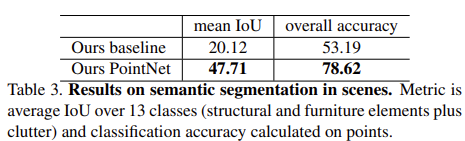
Table 3에서 보면 hand-crafted 기반의 baseline보다 각 class에 대한 mean IoU와 정확도에서 모두 우월한 성능을 보였다.

Fig 4에서는 segmentation의 qualitative한 결과를 보여준다.

Table 4에서는 기존 sota 방법과 비교하였다. 평가 지표는 3D volume에서 0.5 IoU를 임계값으로 한 AP이다. 비교 대상 모델의 경우 sliding shape 방법으로 voxel grid내에서 local, global한 feature에 대해 SVM을 적용한 모델이라고 하는데 정확히 이해가 되지 않았다. sofa를 제외하고는 furniture category에서 좋은 성능을 보였다. furniture category에 대해서만 성능 리포팅을 한 점은 의문이 든다.
Architecture Design Analysis
해당 파트는 다양한 방법론을 적용했을 때의 결과를 비교한 부분이다. ModelNet40 shape classification problem을 기반으로 비교하였다. Figure 5에서는 max pooling을 사용하는 것이 가장 좋은 성능을 보여주면서 자신들이 max pooling을 사용한 것의 합당성을 증명한다.

unsort한 것과 sort한(maxpooling 사용) input의 성능을 비교해보면 sort한 MLP모델의 성능이 더 좋은 것을 확인할 수 있다. input points를 sequence로 하는 LSTM의 경우 위의 “Symmetry Function for Unordered Input”에서 언급했던 것 처럼 성능은 준수하지만 적용하기가 어렵다는 것을 알 수 있다. 가로선 아래는 symmetric function의 비교이다. attention sum, average pooling, max pooling 중 max pooling을 적용하였을 때 가장 높은 성능을 보인 것을 알 수 있다. attention sum방법은 각 point feature에서 scalar scores를 구하여 softmax를 통해 score를 normalize하는 방법이라고 한다.

Table 5에서는 input과 feature transformation과의 alignment에 대한 효과 분석이다. 주목할만한 점은 basic한 architecture(none)도 resonable한 성능을 보였다는 것이다. input transformation과 regularization을 모두 적용하였을 때 input point cloud의 rigid motion invariance를 보장하기 때문에 가장 좋은 성능을 보이는 것을 확인할 수 있다.
Figure 6은 model의 robustness를 보인다. Figure 5의 architevture를 사용하였다. 제일 왼쪽을 보면 random하게 1024개의 point를 sampling하는 것보다 furthest하게 선택하는 것이 조금 더 좋은 성능을 보인다. 가운데에서는 x,y,z와 point density정보를 추가한 경우, outlier가 많이 포함될수록 오히려 성능이 하락하는 것을 알 수 있다. outlier가 적을 때 효과를 볼 수 있다. 마지막 오른쪽은 network가 point perturbation에 강인하다는 것을 보인다.

Visualizing PointNet

Figure 7에서는 object의 critical points를 시각화하여 보여준다. 모든 points가 의미있다기 보다는 가운데 행의 점들을 보면 몇 개의 점들 뿐이지만 대략적으로 물체가 무엇인지 파악할 수 있을 것이다. 이처럼 max pooling을 통해 이런 의미있는 중요한 points(critical points)들은 잘 추출하여 물체의 skeleton을 찾은 것을 시각화하여 보여주고 있다.
Time and Space Complexity Analysis

Table 6에서는 시간(FLOPs)과 공간(network의 parameter 수) 복잡도에 대한 분석 결과이다. 기존 방법론들과 비교했을 때 pointnet은 raw 3d point cloud를 사용하기 때문에 시간도 적게 걸리고 parameter 수도 훨씬 많이 차이나는 것을 알 수 있다. PointNet(vanila)는 classification에서 input transformation과 feature transformation을 하지 않은 모델이다.
Conclusion
본 논문에서는 point cloud를 direct하게 사용하는 새로운 deep neural network인 PointNet을 소개하였다. object classification과 part segmentation, semantic segmentation까지 다양한 3d recognition tasks를 할 수 있고 좋은 성능도 보였다. 당시 point cloud를 직접 사용할 수 없었기 때문에 본 논문의 파급력이 대단했을 것 같고 현재도 PointNet을 많은 backbone으로 사용하고 있는 것으로 알고있다.
안녕하세요 도경님. 이전에 PointNet에 대해 리뷰했었는데, 다시 읽어보니 이해가 안되었던 부분에 대해 이해를 도운 부분이 있어 잘 읽었습니다.
우선 간단히 T-net의 내용 중 orthogonal하게 만든다는 것이 결국 일정한 순서가 보장된 canonical space로 보낸다는 말과 같은 의미일까요? 같은 의미로 보이나, 수학적으로 조금 더 이해가 되었으면 하는 바램에 질문합니다.
두 번째로는, PointNet에서는 (x,y,z)의 3D information만으로 Classification, Segmentation 등을 진행한다고 합니다. 하지만 특정 태스크에 대해서는 Color 등의 추가적인 정보가 필요하지 않을까하는 생각이 드는데, 이에 대해서는 어떻게 생각하시나요?
좋은 리뷰 감사합니다.
댓글 감사합니다.
우선 T-Net에서 orthgonal하게 만든다는 표현에서 canonical space가 명확하게 무엇인지 나타나지는 않지만, object가 똑바로 서있는 올바른 위치에 오도록 하기위해 어떤 transformation이 적용되었는지 파악하기 위함으로 사용되기 때문에 canonical space를 일정한 순서가 보장되었다기보다 일반적인 형태의 coordinate형태로 이해하는게 직관적으로 받아들일 수 있을 것 같습니다.
두번째로는 위에서 언급하기로 해당 모델이 (x,y,z)값 만을 사용한다고 하였습니다. 그리고 classification과 segmentation에 대해 나누어 서술하였는데요, 일반적으로 3d point cloud에서 다양한 정보들이 있지만 여기서는 x,y,z값 만을 사용한다고 하였습니다. 그리고 나중에 experiments에서 semantic segmentation을 한 부분에서는 x,y,z외에 r,g,b정보와 방에서의 normalized location정보를 추가로 활용했다고 합니다. semantic segmentation에서는 x,y,z외에 다른 정보를 추가로 사용한 것으로 보입니다.
좋은 리뷰 감사합니다.
기존 방법론들과는 다르게 색이나 기타 정보를 포함하지 않는다고 하셨는데, 실험 결과를 보았을 때, Figure 4의 의자같은 경우를 잘 구분하는 게 신기하네요. 상인님의 의견처럼 segmentation과 같은 task에는 색상 정보가 추가되어야 하는 것은 아닐지 궁금합니다.
또한, 3D object part segmentation에 대한 실험 결과가 Table2에 리포팅되어있는데, 제목 행에 있는 카테고리들이 오브젝트 단위인 것 같은데, part segmentation 결과를 object 단위로 평균낸것인가요??
마지막으로 symmetric function(max pooling)는 결국, 포인트들을 이용하여 한번에 feature를 추출할 수 있는 global feature vector(f)를 학습하는 것을 목표로 한다고 이해하면 되나요??
댓글 감사합니다.
위에서 답변드린 것 처럼 semantic segmentation의 경우 r,g,b 색상 정보와 room localized location정보도 포함하는 것으로 이해했습니다.
Table 2의 reporting 결과는 말씀하신 내용이 맞습니다. 해당 category에 대한 모든 part types에 대해 IoU를 구하고 평균 냅니다.
마지막에도 말씀하신대로 symmetric function인 max pooling을 이용하여 수많은 input points들 중 object shape에 중요하다고 생각되는 key points를 추출하기위해 global feature vector를 학습하는 것을 이해하는 것이 맞습니다.
안녕하세요, 좋은 리뷰 감사합니다.
3D object detection의 한 방법으로 사용되고 있는 PointNet에 대해서 전반적인 내용이 저에게는 낯선 내용들이라 이해하는데 시간이 오래 걸렸으나, 자세하게 설명을 잘 해주신 덕분에 마지막까지 잘 읽었습니다.
Table4를 설명한 부분에서 SVM을 적용한 부분이 전체 architecture 마지막 부분의 classifier에 대해서 SVM을 적용한 게 맞는지 궁금합니다.
만약, 맞다면 왜 MLP가 아닌 SVM을 적용한 건지에 대해서도 해당 논문에 설명이 되어있는지 궁금합니다.
SVM을 적용하여 좀 더 좋은 결과가 나와서 적용한 걸로 이해해도 되는지 궁금합니다.
댓글 감사합니다.
해당 내용은 “3D Semantic Parsing of Large-Scale Indoor Spaces”라는 2016년 논문에 내용이라고 reference가 되어있네요. 말씀하신 것처럼 classifier에 대해 SVM을 적용한 것이 맞습니다. 논문에 svm과 mlp를 사용한 비교 실험결과는 포함되어있지 않습니다. 아마 예전 논문이다보니 hand-craft기법을 적용한 것이 아닌가 하는 생각이 듭니다.
감사합니다.