논문의 주제가 Multi-level Feature를 이용하는 방법인데 Ln-iMAC을 주로 쓰는 저희 연구에도 적용할 수 있을 것 같아서 한번 읽어봤습니다.
Introduction
Computer Vision에서 video representation을 학습하는 것은 중요한 매우 중요한 일입니다. 당연히 지도학습이 더 좋은 성능을 보이지만, 라벨링 비용을 무시할 수 없어 많은 연구들이 비지도 학습을 시도하고 있습니다. (제가 최근 읽은 논문들에 비디오에서의 비지도학습 논문이 많으니 참고하실 분들은 참고해도 좋습니다.)
이러한 연구는 크게 두가지 흐름(Contrastive learning, Spatiotemporal augmentation)으로 수행이 되었습니다. 먼저 Contrastive learning은 동일한 sample에서 augmented된 sample들 끼리는 가까워지고 다른 sample들 끼리는 멀어지게 하는 방식을 통해서 표현력을 학습하는 방식입니다. 다음으로 Spatiotemporal augmentation은 motion 정보를 강화하기 위한 모델링 방법으로 constastive 페어를 구성하는 방식입니다.
대충 이런식으로 연구가 나뉘어진다고 정리했을 때, 기존 연구들의 문제점이 당연히 있었겠죠? 3가지가 있는데 정리하면 아래와 같습니다.
- instance와 semantic 분포 모두를 고려하는 학습이 없었다.
- high-level feature에 집중하는 것에 비해, low-level feature는 사용하지 않는다.
- Temporal augmentation을 너무 직접적으로 적용한다.
따라서 본 논문에서는 이러한 문제점을 해결하기 위해서, 좀 더 일반적인 표현력을 얻기 위해 unified multi-level view로 부터 feature를 최적화할 수 있는 프레임워크를 제안합니다.
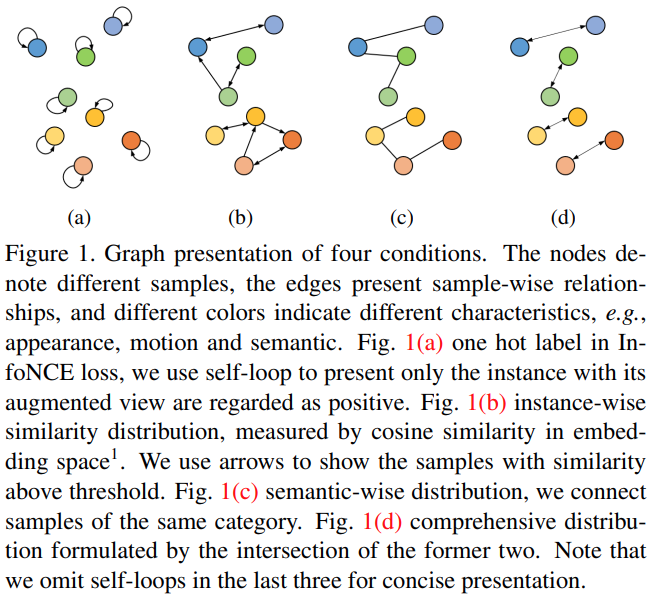
일반적으로 high-level feature의 경우에는 instance나 semantic한 표현력을 가질 수 있다고 여겨지지만, low-level feature는 구조적인 정보는 부족하지만 전이시키기 쉽고, temporal statistics에 민감하다고 여겨집니다. 이러한 맥락을 고려해서 본 논문에서는 High-level feature와 Low-level feature를 각각 최적화 시키는데요. 먼저 High-level feature 관점에서 보자면…
- 기존의 InfoNCE Loss를 통한 instance discrimination 학습
- 프로토타입 분기를 통한 semantic structure modeling을 통한 학습
을 수행한다고 한다고 합니다. “semantic structure modeling”이 사실 잘 이해가 가지 않을텐데요. [그림 1]을 보면 됩니다. 그림의 번호마다 각각의 예시가 들어있는데요. 이 논문에서는 최종적으로는 (d)로 학습한다고 생각하면 됩니다.
Low-level feature는 외향이나 움직임등의 유사한 semantic & instance 특징들을 찾을 수 있는 단서가 된다고 합니다. (일반화되는 지식을 보유하고 있다는 뜻) 그래서 temporal한 정보를 활용한 최적화 방식을 사용하여 학습을 수행한다고 합니다.
사실 Intro만 따로 정리를 해보면 좀 중구난방인 감이 있는데요. 뒤에 모델 설명을 읽다보면 아… 라는 느낌이 오는데 여기만 따로 정리하려니 쉽지가 않네요. 어쨋든 Contribution을 요약해보자면…
- Unsupervised video representation learning을 위한 multi-level feature optimization framework 제안
- multi-level augmentation을 이용한 간단하지만 효과적인 temporal modeling module 제안
- SOTA…?(라고는 하지만 좀 애매한 부분이 있는 성능)
라고 합니다.
Method
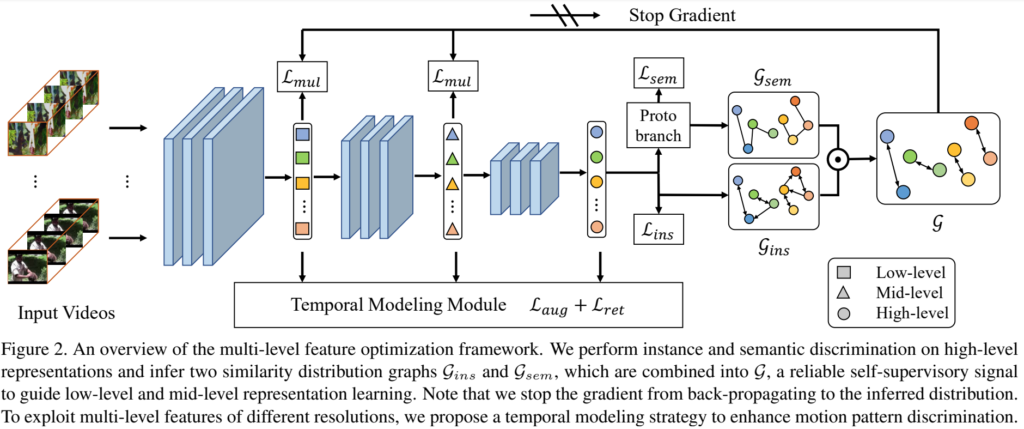
전반적인 모델은 [그림 2]와 같은 구조를 가지고 있습니다. 본 논문에서는 크게 3가지 구조를 가지고 있습니다.
- High-level represnetation이 instance(L_{ins})와 semanctic(L_{sem})한 구별력 보유
- Multi-level feature를 instance-wise and semantic-wise distribution graph를 통해서 최적화
- Temporal한 구별력을 향상시키이 위한 모델링
이라고 하는데, 각각의 섹션에서 순서대로 설명해보겠습니다.
Beyond Instance Discrimination
첫번째로 설명할 부분은 InfoNCE를 통해 instance에 대한 구분력을 학습하는 부분입니다. Self-supervised representation learning에서 constrastive learning을 통한 성능 향상은 이미 입증된 방법입니다.
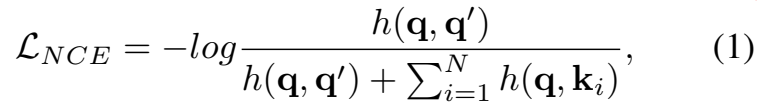
일반적으로 self-supervised 같은 경우에는 Label이 없기 때문에 [수식 1]과 같이 표현이 됩니다. q가 positive sample일 경우에, q'가 augmented positive sample이 되고 k가 negative samples가 되는 학습 방식이죠. (h(u,v) = exp(u^Tv/(\tau||u||_2||v||_2))) 이 방식의 문제점은 서로 다른 샘플간의 관계는 무시한다는 문제점이 있습니다. MoCo나 InfoNCE와 같은 방식들이 모두 가지고 있는 문제인데요. Negative samples에 negative에 해당하는 sample만 있는 것이 아니라는 겁니다. 많은 negative sample들을 쓰기 때문에 필연적으로 query랑 비슷한 샘플이 존재하는 것이죠.
따라서 본 논문에서는 샘플들끼리의 관계를 모델링하기 위해, high-level feature vector들을 proejction하는 브랜치(논문에서는 Proto branch)를 이용합니다. Projection된 high-level feature의 i번째 샘플의 a번째 augmented sample을 z^a_i \in \R^C(C는 채널 dimension)라고 합시다.
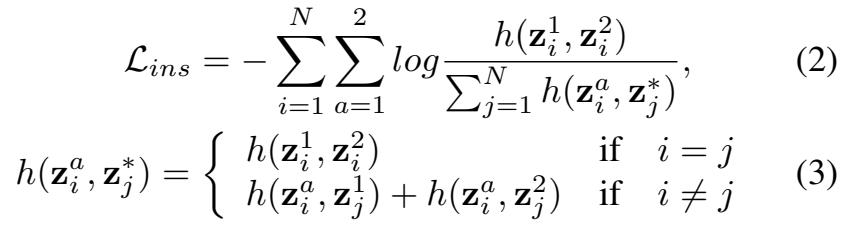
이 때, instance discrimination learning objective는 위와 같이 정의됩니다. 수식이 좀 복잡해 보이지만 feature를 나타내는 z위의 숫자는 서로 다른 augmentation이라는 것을 보여주기 위해 존재합니다. 그리고 N은 배치 내의 샘플 갯수니까, 해당 연산은 배치 내의 샘플들 끼리만 수행하는 것을 알 수 있습니다.
사실 이러한 학습 방식 샘플들 끼리의 관계를 모델링 하기 위한 방법론인데요. 이 아이디어 자체는 parametric classification이라는 방법론에서 영감을 얻었다고 합니다. 이 방법론에서는 learnable matrix P \in \R^{C\times K}를 정의해서, 일종의 pseudo category centers를 제공하도록 하는데요. K는 prototype의 숫자라고 정의되는데, 여기서는 학습하고자하는 클래스의 갯수로 정의됩니다. 하지만 self-supervised에서는 클래스의 갯수를 모르죠? 다행이도 semantic한 정보를 학습할 때는 적절하게 큰 숫자면 어느정도 학습이 되어서 이용할 수 있다고 합니다.
이 P는 feature z_i^a와 행렬 곱이 수행되어져서, softmax regression과 함께 semantic-wise distribution p_i^a \in \R^K를 생성하는데 쓰입니다. 사실 category label이 없이 이렇게 학습하면 semantic한 구별력이 부족해서 학습이 잘 안될 수 있는데, 이를 방지하기 위해서 운송 최적화 문제를 해결하는데 쓰이는 Sinkhorn-Knopp 알고리즘을 적용하여 \{p_1^a,p_2^a,...,p_N^a\}와 같은 distribution set을 s_i^a \in \R^K로 정의하는 category 정보를 균등하게 담고 있는 \{s_1^a,s_2^a,...,s_N^a\} 같은 soft target으로 변환합니다. (대략적으로 카테고리마다 N/K샘플이 존재) Soft-target은 저희가 자주 듣는 표현으로 생각하면 일종의 pseudo-label 같이 작동해서, 학습시에 라벨 정보가 없어서 발생하는 구분력 저하를 방지합니다.
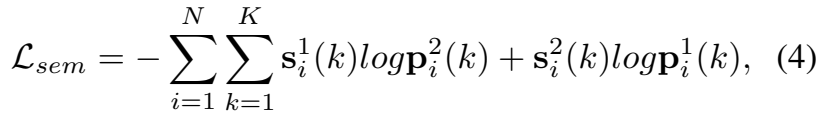
[수식 4]는 soft-target s_i^a와 probability distribution p_i^a간의 cross-entropy Loss를 정의한 수식입니다. K가 배치 사이즈(N)보다 무조건 크기 때문에, 이전 배치의 semantic-wise distribution들을 저장해놓는 큐를 하나 설계해서 함께 사용은 합니다. 물론 backward시에는 현재 배치의 gradient만 사용하고요. 이전 방식 대비 가장 큰 차이점은 학습 속도가 느려졌다(feature vector의 변화를 천천히 준다)는 것인데요. 좀 더 정교하게 학습을 한다고 생각하면 될 것 같습니다.
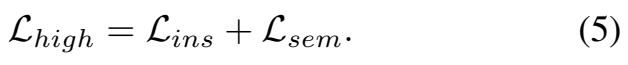
최종적으로는 instance discrimination을 위한 [수식 3]과 semantic discrimination을 위한 [수식 4]를 더해서 high-level representation을 학습하기 위한 Loss로 사용합니다.
Graph Constraint for Multi-level Features
High-level feature가 instance와 semantic한 정보량을 많이 가지고 있다는 것은 맞는 말입니다. 하지만 실제로 사전학습된 모델에서 downstream task를 수행할 때 전달되는 정보들은 주로 low-level feature라고 합니다. 그래서 이 논문에서는 low-level 정보도 활용하는 것이 downstream task에서 중요하다는 맥락에서 이 모듈을 사용합니다.
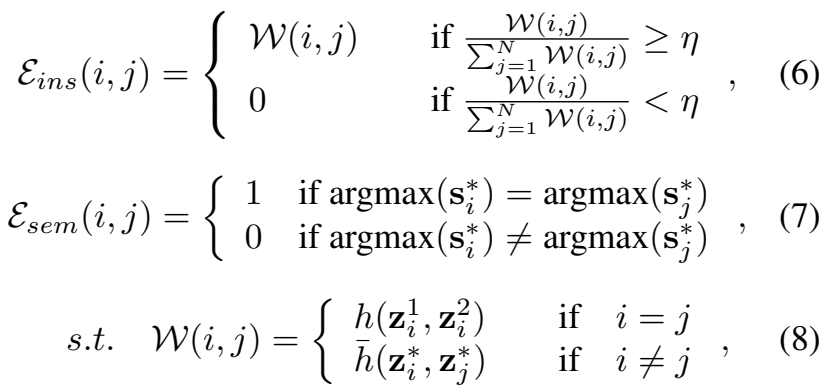
[그림 1]과 [그림 2]를 잘 생각하면서 수식을 보면 좋은데요. 먼저 instance-wise similarity distribution를 가지는 directed graph를 g_{ins}라고 합니다. 그리고 semantic-wise distribution을 가지는 undirected graph를 g_{sem}라고 합니다. 그래프기 때문에 노드를 가지고, 여기서 노드는 배치 내의 샘플이고, 연산은 배치 내의 모든 노드끼리 수행되기 때문에 N^2개의 노드 갯수를 가지는데요. 이때 각각의 그래프에서 edge(\varepsilon)를 계산하는 수식이 위에 보이는 수식입니다.
h(-)에 대한 설명은 앞선 섹션에서 설명이 나오는데, 여기서 \bar{h}(-)가 새로 등장하죠? \bar{h}(z^*_i,z^*_j) = \frac{1}{4}\sum_{m=1}^{2}\sum_{n=1}^{2}h(z^m_i, z^n_j), s^*_i=s^1_i+s^2_i 입니다. 풀어서 좀 설명하면… i랑 j가 다를때만 \bar{h(-)}를 적용해주는데요. 이렇게 적용하면 m과 n에 따라 4개의 샘플의 유사도를 계산해서 평균을 사용하는 것을 볼 수 있습니다. \varepsilon{ins}(i,j)자체가 샘플들끼리의 관계를 학습하기 위해 사용하기 때문에, 같은 샘플일 경우에는 augmenation으로 변형된 정도의 차이를 이용하여 관계를 학습하고 아닐 경우에는 아예 주변 샘플들을 보면서 학습하도록 구성된 것 같네요.
다음으로 \varepsilon_{sem}(i,j)같은 경우에는 생성한 pseudo categories 카테고리를 이용하는데요. 이게 instance-wise 정보와 high-level semantic 정보를 이용해서 low-level & mid-level feature에 대한 self-supervision 성능을 높여준다고 하는데… L_{sem}의 원리랑 비슷하게 단독으로는 의미가 없고
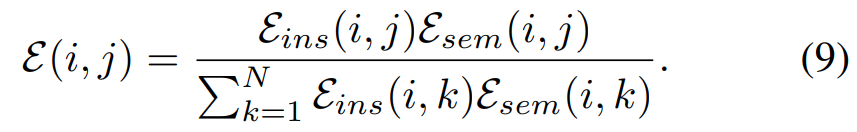
최종적인 Edge를 계산할 때의 [수식 9]를 보면 알겠지만, \varepsilon_{ins}(i,j)와 곱해지면서 일종의 라벨 역할을 한다고 보면 좋을 것 같습니다.
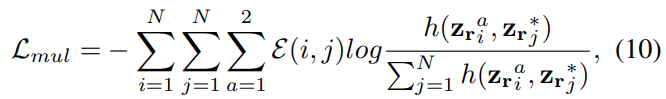
그래서 이렇게 계산해낸 edge값을 이용해서 [수식 10]과 같이 Edge의 값과 feature간의 유사도의 cross-entropy Loss를 계산하는 과정을 통해서 low-level feature를 최적화 하는데요. 최적화의 목표는 knowledge transfer에 최적화된 low-level feature를 생성하는 겁니다.
Temporal Modeling
Multi-level feature를 사용하는 본 모델에서 각 단계의 feature는 서로 다른 temporal 정보를 가지기 때문에, 비디오 전체적인 temporal한 정보를 이용하는 것도 고려해볼 수 있는 부분입니다. 기존의 비디오에서 temporal한 정보를 보는 것의 이점과 그 결과는… 지난주에 작성한 논문 리뷰([Arxiv 2020] Can Temporal Information Help with Contrastive Self-Supervised Learning?)와 겹치는 내용이라 결론만 적겠습니다.
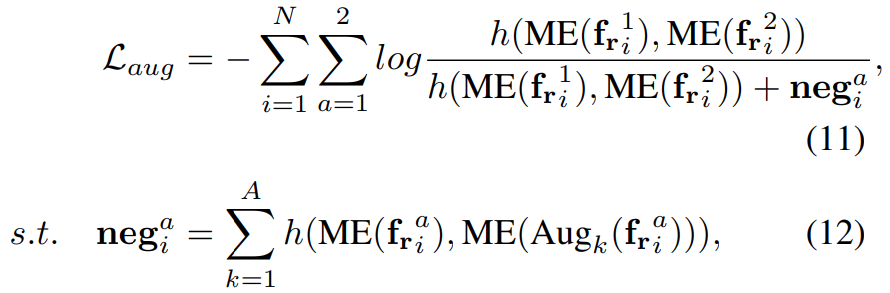
Spatiotemporal average pooling과 두개의 multi-layer perception (MLP)로 구성된 ME(Motion Excitation) 모듈을 이용하여, 백본 네트워크에서 모션 패턴을 추출하고 이 정보를 이용하여 InfoNCE Loss를 적용했다고 보면 됩니다. 이건 이제 움직임의 차이를 이용한 방식이고…
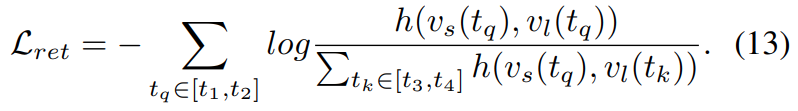
다음으로는 시간에 따라 변하는 카메라 화각에 따른 정보의 일반화를 위하여 서로 다른 길이의 비디오(sequence)에서 특정 타임스탬프의 feature끼리의 매칭을 수행하는 Loss가 있습니다.
- short sequence v_s → [t_1, t_2]
- long sequence v_l → [t_3, t_4]
와 같이 두개의 비디오가 있고 각각의 시간대가 정해져 있을 때… 순서가 3→1→2→4라고 정의할 때, long sequence의 feature들에서 short sequence의 timestamp에 해당하는 feature를 찾는 것이 목표인 Task를 정의할 수 있습니다. 이게 [수식 13]의 L_{ret}입니다. (ret == retreival) 이 Task의 목적은 서로 다른 각도로 촬영되는 비디오의 특성을 고려하여 시간대가 달라짐에도 불구하고 같은 정보를 가진 feature들 끼리는 유사해지도록 학습하는 것이 목표라고 생각하면 됩니다. 최종적으로는 Temporal한 정보를 학습하기 위해서는 이 두 Loss를 더해서 사용합니다.
Experiments
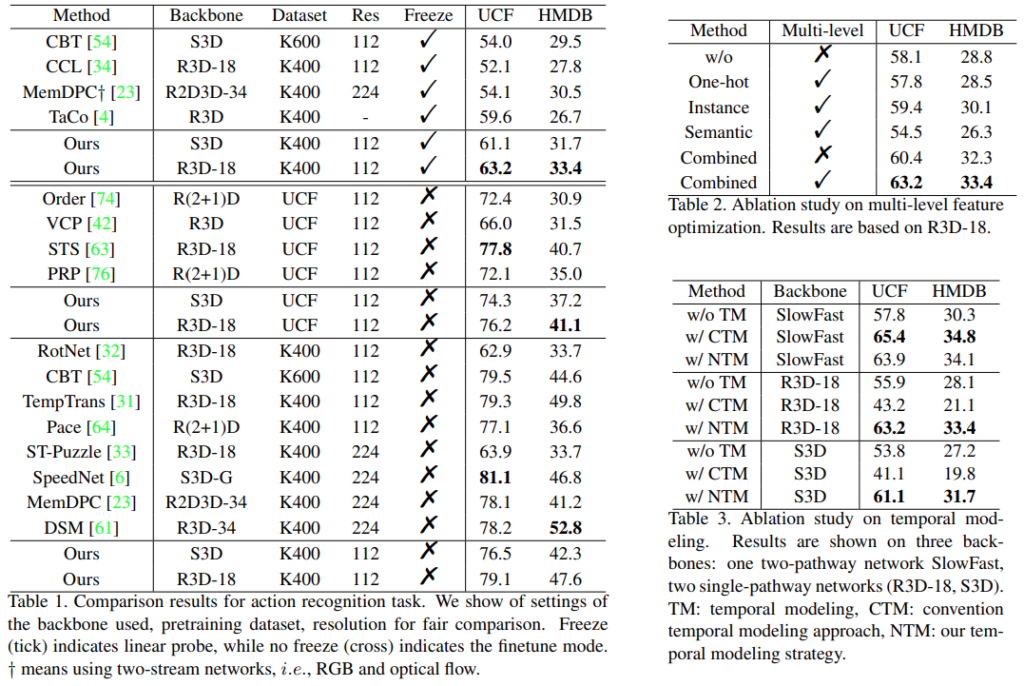
표가 좀 많은데 우선 벤치마크 테이블인 [표 1]부터 봅시다. 표가 좀 복잡한데, Freeze 유무(Linear probe evaluation)의 차이와 학습 데이터셋이 가장 큰 차이니 그 부분을 위주로 보면 좋을 것 같습니다. Linear prove 세팅에서는 다른 방법론들에 비해 크게 높은 성능을 보였습니다. 하지만 end-to-end finetune 세팅에서는 그렇지는 못했는데요. SOTA는 UCF에서 아니더라도 STS라는 복잡한 방법론과 비슷한 성능을 보임으로써 temporal한 정보를 그만큼 잘 활용하고 있음을 보였습니다. 그리고 Kinetics로 학습하는 경우에서는 컴퓨팅 파워의 한계로 인해 더 적은 해상도와 더 적은 학습 시간을 가져서 그렇다고는 설명하고 있는데요. 과연 그럴지… 개인적으로 판단해보면 논문에서 설명하기를 end-to-end 학습에서 단순하게 low-level feature를 쓰면 안된다는 설명이 있는데, 본 논문에서도 똑같은 문제를 겪은것이라고 생각합니다. Ablation study를 진행한 [표 2]와 [표 3]의 경우에는 모듈의 차이니까… 관심 있으신 분들은 그냥 한번씩 보시는 것이 좋을 것 같으니 넘어가겠습니다.
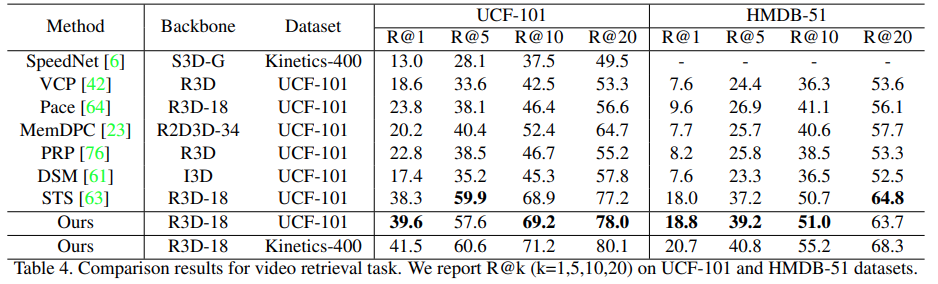
검색 성능 벤치마크인 [표 4]에서는 그래도 해당 방법론이 좋은 성능을 보입니다. 전반적으로 더 정교한 성능을 보이는데요. DSM이나 STS와 가장 큰 차이점으로 downstream task를 겨냥한 knowledge transfer 기능이 좋은 성능 향상을 불러 일으켰다고 판단하고 있고, 이는 multi-level feature optimization이 실제로 효율적이었음을 보입니다.
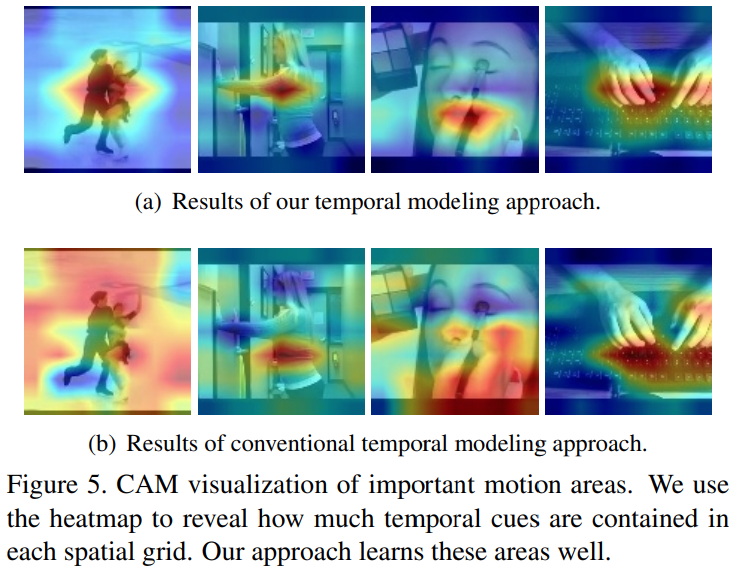
CAM 결과에서도 모션 정보를 잘 감지하는 것을 볼 수 있는데요. 대조군으로 무엇을 썻는지는 잘 모르겠는데, Temporal modeling에서 motion feature를 따로 추출하는데… RGB 쓰는 모델과 motion feature를 쓰는 본 논문의 모듈간의 비교인 것 같긴 하지만, 아무튼 motion 정보를 잘 보는 것이 성능 향상의 주요한 원인 중에 하나라는 것을 보여줍니다.
Conclusion
검색 성능이 좋아졌다는 부분에서 저희 방법론에도 적용해볼 수 있는 여지가 충분히 있는 것 같습니다. 비디오 검색에서 사용하는 Ln-iMAC도 이와 비슷하게 여러 레이어에서 feature를 추출하고 하나로 만들어서 쓰는데… 비슷한 논리로 접근할 수 있지 않을까 싶네요.
리뷰 감사합니다. 그래프로 모델링하는 것이 인상 깊습니다.
예전부터 궁금했는데 가끔 어떤 논문들을 보면 prototype이라는 용어를 자주 사용하는 것을 봤습니다. 저는 대충 cluster랑 관련이 있다고 알고 있었는데 정확히 어떤 용어인지 설명 가능하실까요?
저도 가끔 보는 정도라 논문마다 지칭하는게 동일한지는 잘 모르겠지만, 이 논문에서는 클래스(클러스터)를 의미한다고 보시면 될 것 같습니다.