Abstract
continual learning은 기존의 경험을 보전해야한다는 문제와 동시에 새로운 정보를 받아들일 수 있어야한다는 문제를 해결해야합니다. 이러한 문제는 서로 반대되는 성격을 지니고 있어 stability-plasticity dilemma를 가진 문제라고 불립니다. 즉, continual learning은 주로 catastrophic forgetting 문제를 겪는다고 하는데, 새로운 정보를 받아드리려다 보니, 기존의 경험을 잊게되는 현상을 의미합니다.
Reinforccement learning(RL)이러한 문제를 해결하기 위해 방대한 자원을 사용하여 동시에 학습합니다. 이를 self-play RL, simulation이라고 하는데요 새로운 데이터를 필요에 따라 생성하는 학습법으로 이해하시면 됩니다. 이러한 접근법의 단점은 시간이 흐름에 따라 새로운 경험을 수집하는것에 비용이 많이 들며 연산 비용이 끝없이 증가한다는 점 입니다, RL 분야는 이를 해결하기 위해 continual learning을 접목하고자 하였지만 대부분의 방법론은 경험의 재생(Experience replay)방식을 고려하지 않았다고 합니다. 본 논문은 replay가 continual learning에서 얼마나 중요한지 보여주기 위해 간단한 forgetting 해결 방법론인 Continual Learning with Experience And Replay(CLEAR)을 제안합니다. 해당 방법론은 plasticity(가소성, 새로운 정보의 유입능력)을 위한 on-policy learning과 기존 경험을 보존하기 위한 off-policy learning을 결합한 특징을 갖습니다. 또 하나의 특징은 task에 대한 구별을 필요로 하지 않아 더욱 광범위한 적용을 할 수 있다는 것 입니다. 기존의 continual learning(CL)은 주로 task를 구분하는 parameter를 추가로 요구하곤 했는데 이러한 명확한 구분을 필요로 하지 않는다는 특징을 가집니다.
CLEAR Method
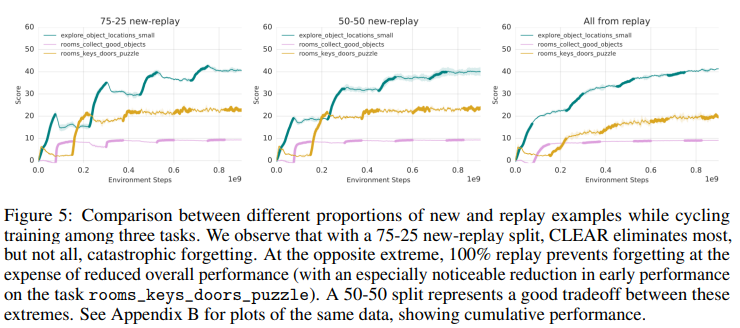
CLEAR은 RL에서 주로 사용되는 Actor-Critic 알고리즘을 기반으로 합니다. 이는 Actor와 Critic 네트워크를 각각 갖는 형태인데요 Actor는 상태를 입력으로 하며 이에 대한 에이전트의 행동을 결정하고, Critic은 에이전트가 처한 상태의 가치를 평가합니다. 이러한 알고리즘을 통해 과거 경험(replayed experiences)와 새로운 경험(new experiences)를 혼합한 경험들을 학습하게 됩니다. 이때 새로운 경험과 과거 경험은 50-50의 비율로 혼합되어 에이전트에 제공됩니다. 논문은 실험 결과 최종 성능은 이 비율에 민감하지 않다고 언급합니다(Figure5 참조).
안정성을 위한 보정전략으로는 V-trace라는 off-policy learning algorithm을 사용합니다. 이는 actor의 action 생성과 learner가 학습을 위한 gradient를 추정하는 과정을 두 네트워크로 분리하므로써 생기는 시간지연을 큐방식으로 보정하는 알고리즘입니다. 본 논문은 이러한 v-trace의 특징이 과거의 경험과 새로운 경험을 학습하는동안 발생하는 distribution shift를 보정하였다고 합니다. 학습에는 총 5가지 loss를 이용하였는데 Actor-Critic 알고리즘에서 주로 사용하는 loss 3가지와 replay experience를 위한 두가지 loss로 구성됩니다. 추가적인 두 loss에 대해 중심적으로 소개하겠습니다.
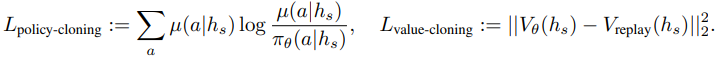
위 수식은 KL divergence를 통해 이전 policy의 분포와 현재 policy의 분포를 유사하게 하는 Lpolicy-cloning과 L2 norm을 통해 과거 value function과 현재 value function을 유사하게 하는 Lvalue-cloning 함수로 구성됩니다. 이때 policy는 어떤 상태에서 에이전트의 행동을 결정하는 정책함수를 의미하고 value는 해당 action을 시행했을 때 에이전트가 얻게되는 가치를 계산하는 함수로 전자는 actor 네트워크, 후자는 critic 네트워크와 관련있습니다.
실험
본 논문에서 실험은 continual learning이 집중하는 두개의 화두, *interference(서로 다른 테스크를 학습하므로써 발생하는 학습에 방해)와 catastrophic forgetting(잊음)을 구분하여 설계하였다고 합니다. 즉, 새로운 분포의 데이터를 학습하므로써 발생하는 성능 하락은 두가지 문제점이 있다는 것인데요, 새로운 분포의 데이터가 기존의 지식을 덮어버리는 catastrophic forgetting과, 서로다른 분포를 학습할때 발생하는 간섭현상인 interference를 각각 측정한 것입니다. 아래 Figure1은 각 테스크에 대해 개별적으로 학습하는 separately 방법론과 하나의 네트워크에 모든 테스크를 동시에 학습하는 simultaneously 방법, 하나의 네트워크에 모든 테스크를 sequentally 하게 학습하는 sequentally 방법을 비교했습니다. 실험에서 확인할 수 있듯이 separately 훈련과 simultaneously 방법론은 큰 차이가 없고 오히려 상호간섭(긍정적 간섭, 공유되는 지식을 의미)을 통해 약간의 성능향상을 보았음을 확인했습니다. 반면 sequentally 방법은 task가 전환될 때 큰 성능하락(catastrophic forgetting)을 보였다.
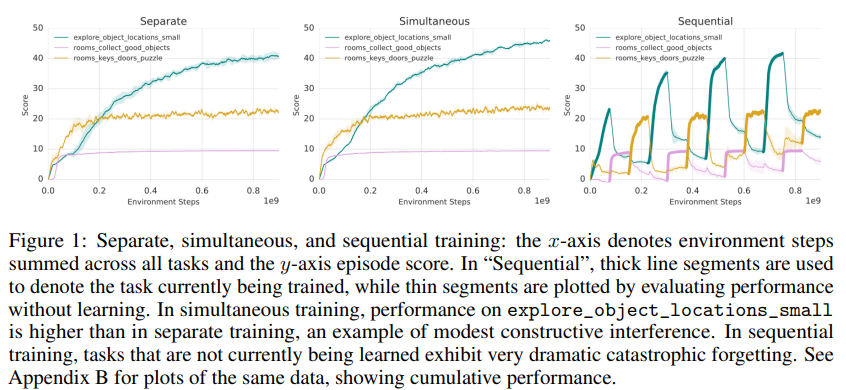
*interference: 몇 continual learning 연구에서는 이를 중심으로 다루며, 기존 지식의 gradient가 새로운 gradient와 충돌하는 문제를 다양한 방식으로 해결합니다. (ex 내적값 이용 or 그냥 평균을 이용..)
CLEAR의 안정성 (catastrophic forgetting의 해결 가능성)을 보이는 실험:
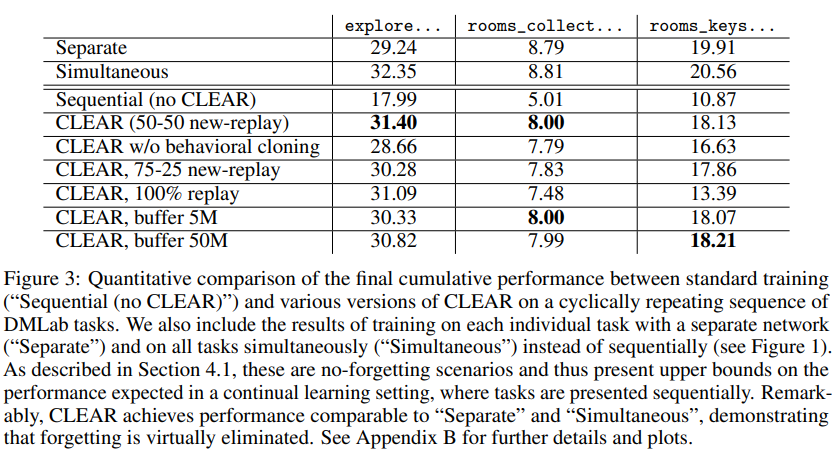
Figure3는 sequential(lower)과 simultaneous, separate(기본적인 학습전략, upper, 모든 테스크에 접근), CLEAR의 정량적 성능을 비교하였다. 이를 통해 제안하는 CLEAR이 효과적으로 catastrophic forgetting을 제거함을 확인하였다.
CLEAR의 가소성(Plasticity)을 보이는 실험:
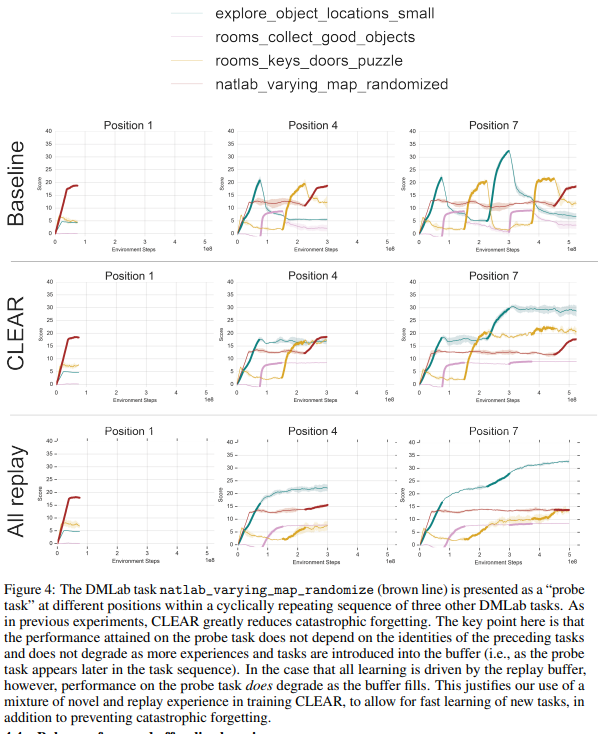
replayed data가 계속 buffer에 추가되면 새로운 데이터의 양이 줄어듭니다. 이는 모델의 가소성을 감소시킬 수 있는데, 해당 논문은 Figre4의 실험을 통해 CLEAR의 가소성이 학습의 진행에 따른 이러한 변화에 무관하게, 문제없이 새로운 데이터를 학습할 수 있다고 주장합니다. Figure4의 실험은 분홍색의 DMLab task (natlab_varying_map_randomized)를 지속적으로 추가하였는데, CLEAR은 새로운 테스크(분홍)에 대해 all replay방법론과 차이없이 성능향상이 있음을 보였습니다. 반면 baseline 방법론에서는 step이 진행되자 해당 테스크에 대한 성능이 크게 하락한것을 확인할 수 있으며 새로운 테스크를 학습하는 능력인 가소성이 step 진행에 따라 크게하락함을 확인하였습니다.
안녕하세요 황유진 연구원님. 좋은 리뷰 감사드립니다.
실험 부분에서 seperately와 sequentally방법에 대해 잘 이해가 가지 않습니다. 결국 continual learning은 하나의 모델에 여러 task를 학습시키는 것으로 알고 있는데 sequentally는 하나의 task로 학습을 완료한 후 다음 task를 학습시키는 것이라고 이해했는데 그럼 seperately 방법론은 어떻게 학습이 진행되는 것인가요? continual learning에서 두 방법의 차이가 궁금합니다.
sequentally는 하나의 모델에 여러 task를 순차적으로 학습하며
seperately는 여러 모델에 각 task를 하나씩 학습합니다.
두 방법론은 continual learning 과 비교시 upper(seperately), lower(sequentally)로 사용됩니다.