이번 리뷰도 감정 인식 관련한 리뷰 입니다. 제가 최근 emotion recognition in conversation에 흥미가 많이 가서 그 분야 쪽을 많이 읽었는데 이제 슬슬 제 코드의 성능을 어떻게 향상시킬까를 생각해야할 타이밍이 와서 emotion recognition 분야를 다시 읽어봤습니다. 제가 작성해놓고 발행하지 않은 글인 CoMPM이라는 논문에서도 사전 학습된 모델을 가져와 쓰는 부분이 많았는데 이 논문도 그렇네요. 그럼 리뷰 시작하겠습니다.
<introduction>
앞에서 말한것처럼 최근 연구는 사전 학습된 모델로부터 high-level embedding을 추출하여 사용하고 있습니다. 그런데 몇가지 이슈가 있다고 합니다.
- 발화의 감정이 대화의 문맥과 연결되어 있다는 것입니다. 하지만 대부분의 utterance-level feature 모델링 방법들은 이러한 문맥 정보를 잡지 못하고 있습니다.
- 단일 모달리티로만 감정인식을 하면 감정 인식을 충분히 할 수 없습니다. 이 때문에 이 논문에서는 멀티모달리티를 사용하여 감정인식을 진행합니다.
그래서 이 논문은 context-aware multimodal fusion framework를 제안합니다. 간단하게 framework를 설명드리자면 아래와 같습니다.
raw 오디오와 텍스트를 frame-level, token-level 임베딩으로 바꾸기 위해서 사전 학습된 모델로 WavLM과 BERT를 사용합니다. 그 다음 추출된 high-level feature는 Sqeeuze-and-Excitation (S&E) 블럭을 통과하고 이후 FC layer와 Layer Normalization을 수행합니다. 이를 통해서 두개의 모달리티를 같은 space로 맵핑합니다. 그 후에 context-aware Convolution block을 이용하여 context information을 취합니다.
그런 다음에 feature를 통합하기 위해 새로운 Multimodal Transformer (MMT) fusion module을 제안하였다. MMT의 핵심 구성 요소는 directional pairwise cross-modal attention 기반 Transformer (CMT)로, 모달리티 간의 상호 작용을 하도록 한다. MMT를 거친 후에 출력은 classifier에 들어가 최종적으로 감정을 예측한다.
<method>
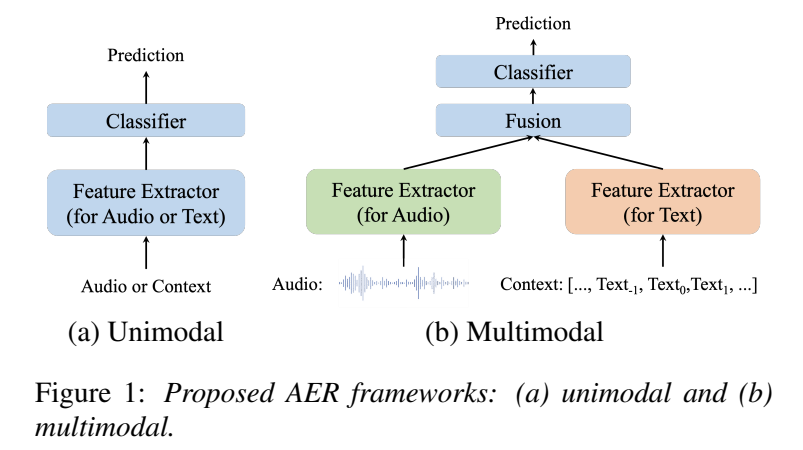
framework를 [그림 1]을 통해서 확인할 수 있는데, 3가지의 모듈로 구성되어 있습니다.
1. high-level feature extractor
2. cross-modal fusion module
3. classifer
앞으로 이 3가지에 대해서 자세히 알려드리고자 합니다.
<1. high-level feature extractor>
1) 오디오 모달리티
오디오 모달리티에서는 WavLM이라는 사전학습된 모델을 이용하여 feature를 추출하였습니다. WavLM에 대해서 간단히 소개하자면 24개의 Transformer encoder로 구성되어 있으며, 9만 4천 시간동안 학습되었다. 보통은 사전학습된 모델의 마지막 레이어만 사용하는데 여기서는 feature encoder와 모든 transformer encoder를 accoustic feature로 사용하였습니다. 이렇게 사용한 이유를 오디오 정보 누출을 방지하기 위해서라고 하는데 저는 이를 모든 오디오의 모든 정보를 다 사용하고 싶어서라고 이해했습니다.
그래서 최종적으로 얻는 feature map의 shape은 50*25*1025 입니다. 각각 time, layer, feature를 의미합니다.
2) 텍스트 모달리티
텍스트 모달리티는 가장 유명한 BERT를 이용하여 featrue를 추출하였는데요. BERT는 토크나이저, 12개의 Transformer encoder로 구성되어 있습니다. 오디오 모달티티에서 모든 layer를 다 가져간 것처럼 여기도 마찬가지로 가져갔는데요. 그래서 feature map의 사이즈는 1*13*768 입니다.
위에서 설명한 바와 같이 두 가지 모달리티에 대해 WavLM 또는 BERT에서 추출된 raw feature는 모든 layer의 output을 사용하였기 때문에 크고 중복되는 것이 있을 수 있습니다. 이에 정보를 더 압축하기 위해 [그림 3]와 같이 두 가지 종류의 feature extractor를 제안합니다.
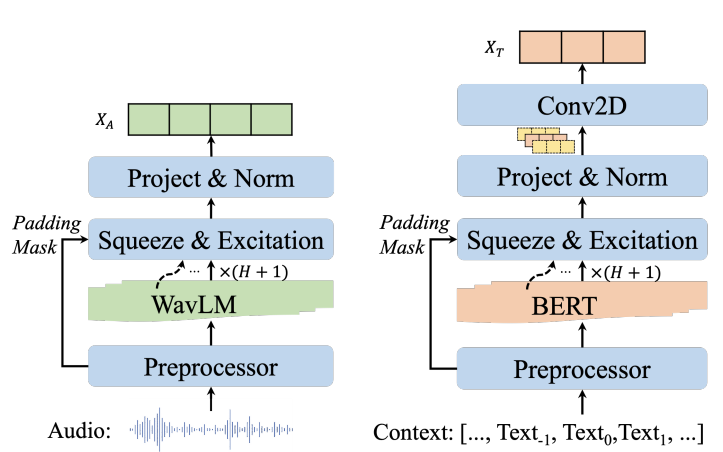
먼저, 훈련 가능한 S&E(Sqeeuze-and-Excitation) 블록을 통해 레이어별 feature를 adpatively하게 보정합니다. 여기서 감소 비율은 단순하게 해당 사전 훈련된 모델의 레이어 수로 가져갑니다. 그런 다음 보정된 feature을 16 차원으로 투영하여 클래스 내 변동성을 유지하면서 feature 중복성을 줄입니다. projector는 레이어 정규화 기능이 있는 MLP로, 오디오와 텍스트 모달리티를 동일한 차원 공간에 매핑하여 융합할 수도 있습니다.
또한, 각 발화의 감정이 대화의 맥락과 관련되어 있는 경우가 많다는 점을 고려하여 텍스트 모달리티의 연속 발화에서 여러 개의 임베딩을 추출합니다. 이러한 embedding은 stride가 1이고 kernel이 3인 컨볼루션 레이어를 사용하여 context-aware textual embedding으로 추가 집계됩니다.
<2. Cross-modal fusion>
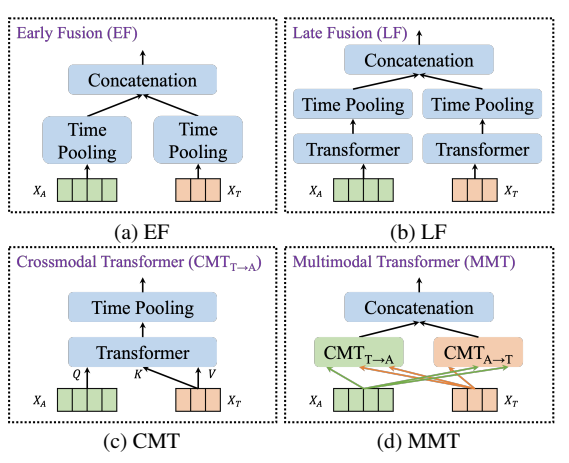
만약의 단일 모달리티인 경우, 위에서 얻은 feature를 classifier를 통해서 감정을 예측하는데요. 멀티 모달리티인 경우, feature를 합치기 위해서 여러 퓨전 방식을 제안하였습니다.
1) EF (Early Fussion)
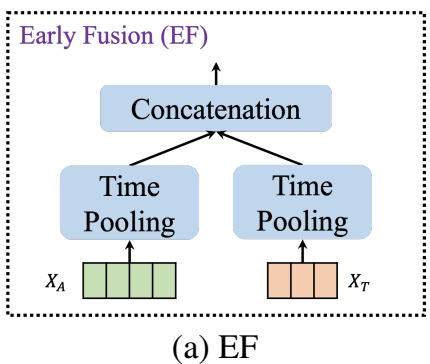
EF는 오디오, 텍스트 featre extractor에서 termoral pooled feature를 단순히 concat 하였습니다.
2) LF (Late Fusion)]
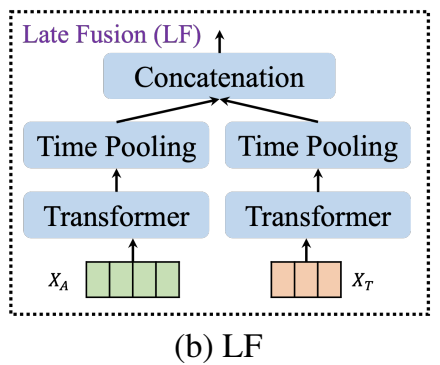
LF는 feature를 추가로 조정하기 위해서 transformer block을 추가로 해주었습니다.
3) CMT (cross-modal Transformer)
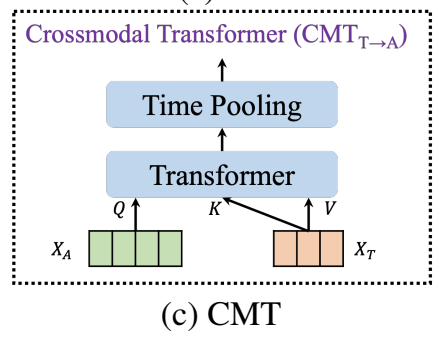
MMT(Multimodal Transformer)에서는 LF보다 더 정교하게 합치기 위해서 cross-modal Transformer (CMT)를 적용하였는데요. CMT의 backbone은 순정 Transformer와 같지만 쿼리와 키-값을 다른 모달리티로부터 가져옵니다.
수식으로 더 자세히 말씀드리겠습니다.
두가지 모달리티에서 source s, target t가 있습니다. 각각에 시퀀스는 X_s\in{\mathbb{R}}^{T_s\times{d_s}} , X_t\in{\mathbb{R}}^{T_t\times{d_t}} 로 표시합니다. T(.), d(.)는 시퀀스 길이, feature 차원을 나타냅니다.
- query Q_t = X_tW{Q_t}
- key K_s = X_sW{K_s}
- value V_s = X_sW{V_s}
- W_{Q_t}\in{\mathbb{R}^{d_t\times{d_k}}}, W_{K_s}\in{\mathbb{R}^{d_s\times{d_k}}}, W_{V_s}\in{\mathbb{R}^{d_s\times{d_v}}}
전체적인 수식은 아래와 같습니다.
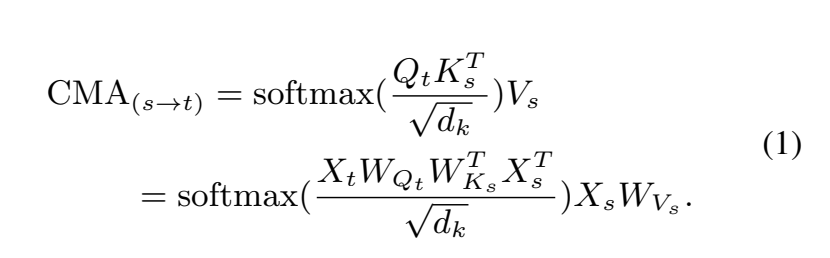
cross-modal Transformer는 하나의 모달리티가 다른 모달리티의 정보를 받을 수 있도록 하는데요. 오디오와 텍스트 모달리티를 이용하여 CMT(audio->text), CMT(text->audio)를 계산하여 융합합니다.
4) MMT (multimodal Transformer)
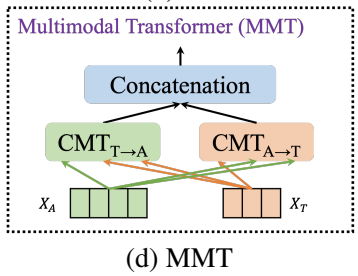
MMT는 두가지의 CMT를 concat하여 output을 얻습니다. 이후 FC layer를 통과하여 최종적으로 감정을 분류합니다.
<3. classifier>
멀티 모달리티의 경우, FC layer로 구성된 간단한 MLP를 classifier로 사용하였습니다. 단일 모달리티의 경우, feature extractor로부터 얻은 feature가 바로 classifier에 들어갑니다.
멀티 모달리티에 사용된 간단한 MLP classifier 외에도 trnaformer를 베이스로한 퓨전 모듈 멀티 모달리티와 비교하기 위해서 더 복잡한 Transformer Encoder(TE)로도 실험을 진행했다고 합니다.
<Experiments>
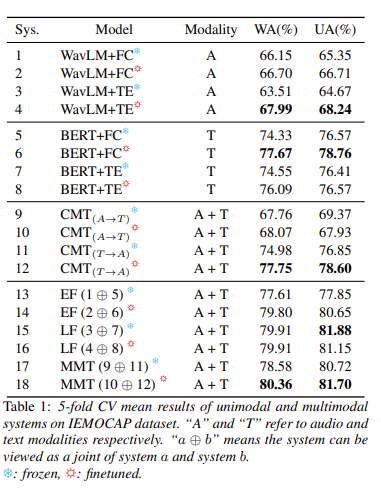
데이터셋 IEMOCAP에서 실험한 결과를 [그림 9]를 통해서 확인할 수 있습니다. 5-fold CV의 평균을 결과로 하여 성능을 측정하였다고 합니다. 여기서 A는 오디오 모달리티만, T는 텍스트 모달리티만 사용하여 성능을 측정한 것입니다. Sys에 적혀있는 것은 시스템의 번호라고 생각하시면 되는데요 13번의 EF(1+5)는 1번인 오디오 모달리티에 frozen한 WavLM+FC 모델과 5번인 텍스트 모달리티에 frozen한 WavLM+FC 모델을 Early Fussion을 통해 합쳤을 때를 의미합니다.
역시나 최고 성능은 파인 튜닝했을 때 + 저자가 제안한 방법인 MMT를 적용했을 때 나오는 군요.
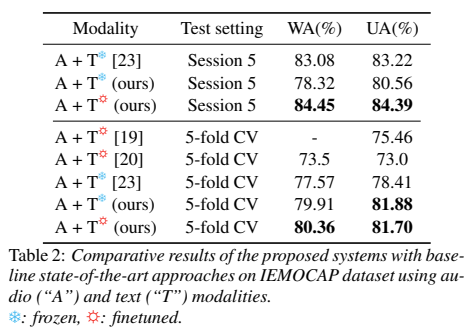
[그림 10]을 통해서 논문에서 제안한 방법론이 가장 높은 성능을 보이는 것을 확인할 수 있습니다.
논문을 읽으면서 제 코드에도 적용시킬 수 있을 만한 방법론이라 생각하고 읽었습니다. 오디오 모달리티에서도 유명한 사전학습모델이 나오면서 대부분의 논문들이 이것들을 사용하는 방향으로 가고 있는 것 같습니다. 저도 질 수 없지요. 유행은 따라가는 법….. 언젠가 유행을 선도해가는 사람이 되고자 목표하며 리뷰 마치겠습니다.
안녕하세요 김주연 연구원님 리뷰 잘 읽었습니다.
우선 논문 내용을 보면 time pooling이 feautre를 생성하기 위해 중요한 역할을 하는 것으로 보이는데, 이에 대한 설명이 없어서 어떻게 수행하는지 궁금합니다.
추가적으로 Wavelm 사전학습 모델을 적용해서 좋아지는 것에 대한 증명이 부족한 것 같습니다. wavelm말고 다른 방식으로 오디오 feature를 추출하고 실험한 결과는 없을까요?
1) 더 자세히 말씀드리면 average time pooling layer이며, 이는 제가 추론한바로 time 축으로 average pooling을 하는 layer를 의미하는 것은 아닌가 합니다.
2) WaveLM말고 다른 방식으로 추출한 것에 대한 실험 결과가 존재하지 않아 저도 아쉽다고 생각합니다.
안녕하요 김주연 연구원님 좋은 리뷰 감사합니다.
* 그림 3에서 모든 레이어의 feature를 가져와서 S&E를 수행해 준다는 것은 SENet의 channel wise attention처럼 레이어 별 가중치를 부여하는 것으로 이해하면 될까요?
* 또한 그림 3을 보면 텍스트 모달리티에서만 Context-aware textual embedding을 수행한다고 하셨는데, 그렇다면 텍스트 정보가 담긴 X_r은 여러 발화에 해당하는 텍스트가 담긴 것인 듯 합니다. 그러면 이때의 X_A는 발화 단위의 embedded audio일 텐데 어떻게 X_r과 X_A를 매핑시키나요?
1) 네 맞습니다
2) audio도 한문장, context의 text는 저는 단어를 토크나이저 한 것으로 이해하였습니다. 때문에 utterance 하나가 입력으로 들어간다고 생각하시면 될 듯 합니다. (이렇게 되면 매핑 문제도 해결되지요)
리뷰 감사합니다.
혹시 time pooling은 어떤 역할을 하는 것이며, 어떤 방식으로 동작하는지 설명해주실 수 있을까요?
더 자세히 말씀드리면 average time pooling layer이며, 이는 제가 추론한바로 time 축으로 average pooling을 하는 layer를 의미하는 것은 아닌가 합니다.