Abstract
- Model distilation (Knowledge distilation)은 teacher에서 student로 전이 학습을 진행하는 효과적이고, 널리 사용되는 방법론이다. 기존 연구(KD)의 접근 방식은 전형적으로 다음과 같이 나타남: powerful, large 네트워크에서 small 네트워크로 전이 or 앙상블 시켜서 적은 메모리로도 목표 성능에 바르게 도달하게 만들었음
- 이 논문에서는 deep mutual learning을 제안함
- Mutual learning: student ↔ student 양방향 전이, 상호 학습 네트워크
- 여러 student network를 ensemble
- 실험
- 다양한 network 구조에서 유용함
- 기존 Teacher 기반의 distilation이상의 성능으로 teacher 구조가 필수적이지 않음을 증명
Introduction
- Knowledge distilation 등장 배경
- DNN은 많은 분야에서 sota의 성능을 내고 있다. 그러나 이러한 네트워크들은 넓고 깊거나 매우 많은 수의 파라미터를 가지고 있다. 때문에 사용하기에 느리거나 저장하기에 너무 커서 빠른 반응을 요구하거나 적은 메모리를 가진 환경에서는 사용하기 어렵다는 단점이 있다.
- 이에 더 작으면서도 정확한 모델을 만들기 위한 연구가 지속되어 왔는데, 크게 explicit frugal architecture design, model compression, pruning, binarisation, model distilation등이 있었다.
- Distilation based model compression
- distilation은 “small networks often have the same representation capacity as large networks”라는 기존 연구 결과에 motivation을 얻어 진행된 연구이다. 위의 내용을 다시 말하면 작은 모델로도 큰 모델만큼의 성능을 낼 수 있다는 것이다. 그러나 large 모델보다 small 모델이 원하는 결과를 얻기 위해 파라미터를 조정하는 과정이 더 어렵다.
- Mutual learning
- 이 논문에서는 distilation과 마찬가지로 small, powerful한 네트워크를 학습시키는 방법론인 mutual learning을 제안한다.
- 하지만 두 방법 사이에는 차이점이 있는데, Distilation은 large pretrained network인 teacher가 small untrained network인 student에 일방적인 knowledge transfer를 수행한다. 반면에 mutual learning에서는 untrained network인 student 여러 개를 동시적으로 학습시킨다.
- mutual learning에는 두 가지 loss가 사용된다. 하나는 conventional supervised learning loss이고, 다른 하나는 mimicry loss이다.
Related Work
Knowledge Distilation
두 종류의 네트워크를 사용하여 서로의 예측값을 비교하며 좋은 성능을 내는 방법은 이전에도 있었는데 대표적인 방법으로는 Knowledge Distilation이 있습니다. Knowledge distilation은 pre-trained된 teacher 모델의 지식을 그보다 작은 네트워크에 전달하여 더 작은 모델로 큰 네트워크와 비슷한 성능을 끌어내는 학습 방법론입니다.
Knowledge distilation을 간단하게 알아보자면, [그림 1]과 같습니다.
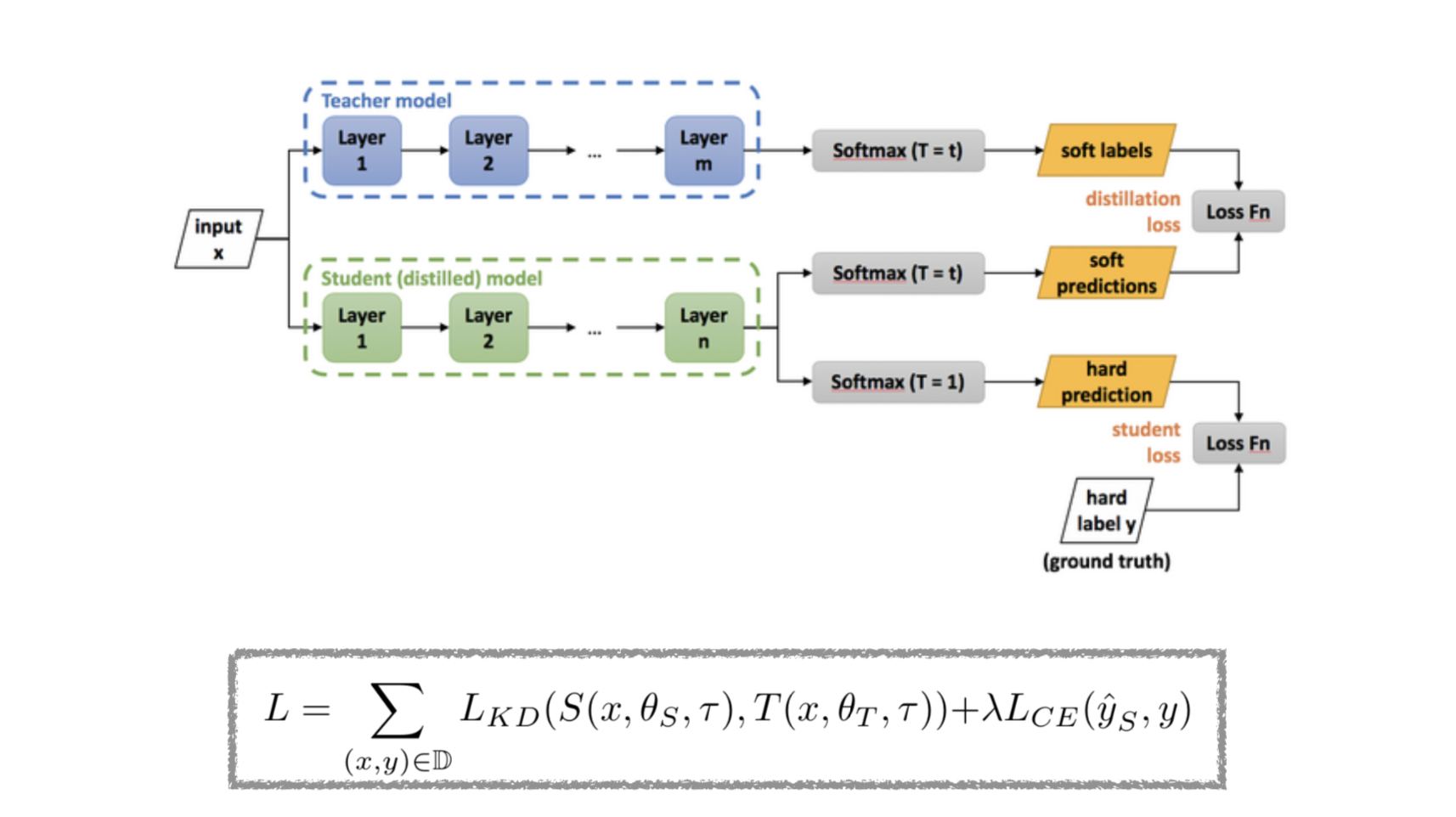
large pre-trained 모델인 Teacher와 small untrained모델인 student가 있을 때, student를 GT를 이용하여 학습시키면서, student의 soft prediction을 teacher의 prediction과 비교하며 Student가 Teacher에 가까워지도록 학습하는 것입니다.
Deep Mutual Learning
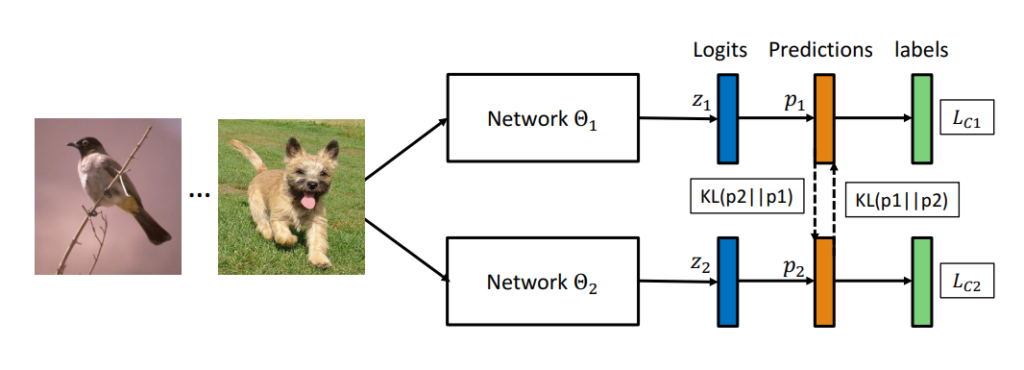
논문의 저자들은 teacher와 student로 이루어진 KD와 달리 Student로만 이루어진 Deep Mutual Learning을 제안하였습니다. KD에서는 Teacher의 지식을 Student로 전이하는 방식을 사용한 반면, mutual learning은 tudent 끼리 상호 협력적인 학습을 진행합니다.
Formulation
Mutual Learning을 수식으로 나타내면 다음과 같이 나타낼 수 있습니다. 각 기호와 수식들의 의미를 살펴 보면, M개의 클레스를 가진 데이터셋에서 N개의 샘플을 뽑은 경우를 X=\{x_i\}^N_{i=1}, X와 매칭되는 label을 Y=\{y_i\}^N_{i=1}라고 합니다. 이때, Neural Network \Theta_1에서 샘플 x_i에 대한 class m의 확률은 [식 1]과 같습니다.
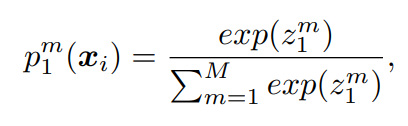
z^m은 네트워크 \Theta_1에 존재하는 softmax레이어의 출력값을 의미합니다.
Multi-class classification에서는, \Theta_1을 학습시키는 목적함수가 예측값과 정답 label의 Cross Entropy error로 정의됩니다. 수식으로 나타내면 [식 2]와 같고, 이를 supervised loss라 합니다.
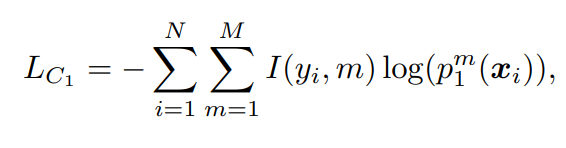
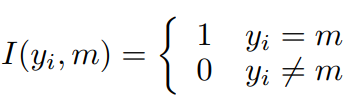
위의 Cross Entropy loss는 전형적인 supervised loss로 모델의 예측값이 GT와 같아지도록 학습합니다. 추가로, 저자들은 \Theta_1의 generalization performance를 향상시키기 위해 또 다른 peer network인 \Theta_2를 사용했습니다. \Theta_1, \Theta_2의 예측 결과를 p_1, p_2라 할 때, p_1과 p_2의 를 정량화하기 위해 Kullback Leibler(KL) Divergence를 사용하며, [식 4]와 같이 계산됩니다.
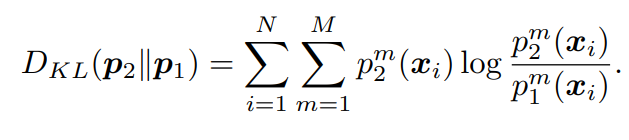
최종적으로 \Theta_1, \Theta_2의 Loss는 [식 5, 6]과 같습니다.
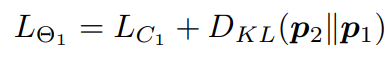
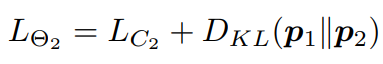
loss는 cross entropy와 KL Divergence의 합으로 이루어져 있습니다. 이를 통해 정답 label에 대한 예측 뿐 아니라 두 모델 간의 예측값도 함께 고려하여 학습을 진행합니다.
Optimization
KD와 DML의 가장 중요한 차이점은 DML은 두 모델이 협력적으로 연대하며 최적화된다는 것입니다. 두 모델을 학습할 때, mini-batch단위로 파라미터를 업데이트하며, 모든 과정에서 업데이트는 동시적으로 진행됩니다. 학습은 여러 GPU를 사용하여 병렬적으로 수행하였다고 합니다.
Extention to Larger Student Cohorts
DML은 student모델간의 상호 협력적인 학습을 진행하는 것으로, 저자는 student network의 개수를 증가시켜 학습을 진행하였습니다. K개의 네트워크 \Theta_1,\Theta_2,..., \Theta_K(K\geq2)가 있을 때, 각각의 목적 함수는 [식 10]과 같이 나타낼 수 있습니다.
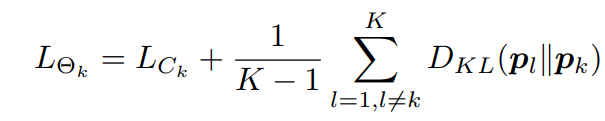
2개의 네트워크를 사용하던 [식 5]와 비교하면, [식 10]은 \Theta_K를 제외한 나머지 네트워크와의 KL Divergence의 평균을 사용합니다.
Experiments
실험을 위한 네트워로는 [표1]과 같이 다양한 크기의 모델을 사용하였습니다.

Results on CIFAR-100
[표 2]는 Cifar-100에 대한 결과로, 2개의 네트워크를 각각 학습시킨 결과(Independent), DML로 학습시킨 결과, 두 결과의 차이를 나타냅니다.
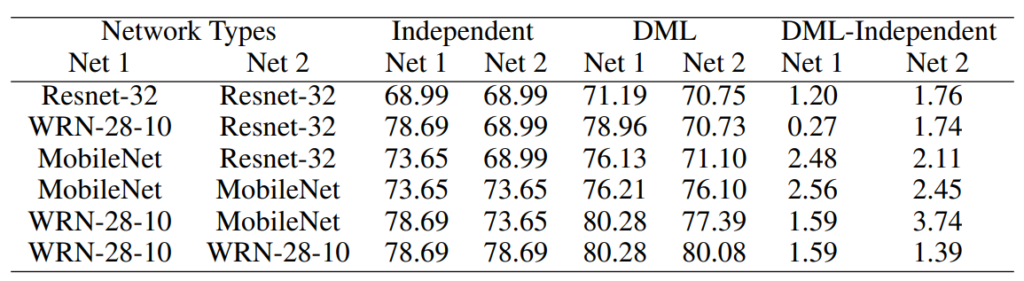
[표2]를 보면 모든 경우에서 독립적으로 학습시킨 것 보다 DML을 사용하는 것이 성능이 더 좋은 것을 확인할 수 있습니다. 특히, 작은 모델 크기을 갖는 ResNet-32나 MobileNet의 경우 DML에서 더 많은 향상을 이루었음을 확인할 수 있습니다.
Comparison with Distilation
[표3]은 DML과 KD의 성능을 비교한 결과입니다.

[표3]에는 CIFAR-100, Market-1501에 대해 두 모델을 independent, disdilation, DML로 학습한 결과를 나타내고 있는데, 각각 별도로 학습시킨 결과에 비해 KD의 성능이 높고, KD의 성능보다 DML의 결과로 나온 두 모델의 성능이 더 좋은 것을 확인할 수 있습니다.
DML with Larger Student Cohorts
앞서 설명드린 실험 결과들은 2 개의 student cohort로 진행된 실험의 결과들입니다. 논문에서는 더 많은 수의 학생 모델을 사용한 실험또한 진행하였습니다.
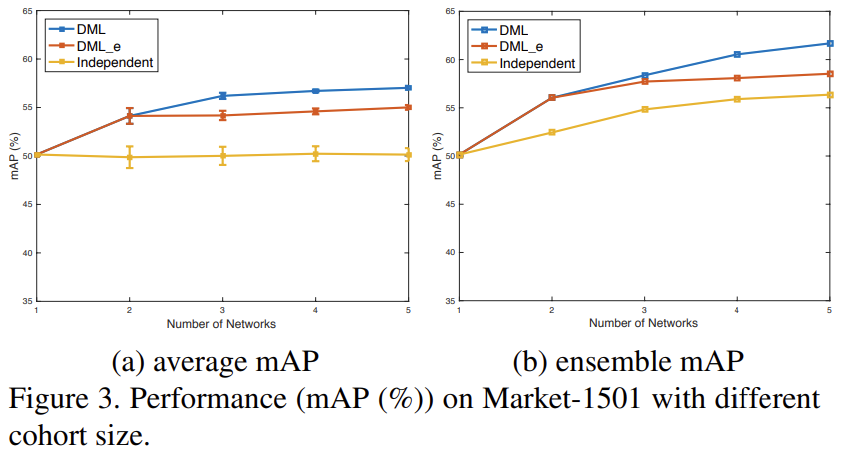
[그림 3(a)]는 student로 사용된 MobileNet의 개수가 증가함에 따라 DML의 성능을 나타낸 결과들입니다. [그림 3(a)]는 각 student 모델의 평균 mAP를, [그림 3(b)]는 student들을 앙상블하여 예측을 수행하였을 때 mAP를 나타낸 결과입니다.
[그림 3]에서 확인할 수 있듯, DML은 사용되는 모델의 수가 증가함에 따라 더 좋은 성능을 보이는 경향이 있습니다. 또한, DML을 통해 학습된 모델들에 앙상블 기법을 사용하면 더 좋은 성능을 끌어낼 수 있습니다.
리뷰 잘 읽었습니다.
Mutual Learning을 제 실험에 적용 중인지라 제목을 보고 들어오게 되었습니다.
질문이 몇가지 있습니다.
1) DML의 최종 loss가 cross-entropy 와 KL_Divergence loss의 결합으로 보입니다. 개인적인 궁금증인데 두 loss의 가중치를 다르게 두어서 실험 한 결과는 없었나요??? 단순 1:1 비율의 결합인가요?
2) ‘Larger Student Cohorts’ 에 대한 질문입니다. 2명의 student가 DML을 하는 방식에서 뭔가 더 많은 student들이 DML을 수행하는 부분이여서 확장성에 대해 볼 수 있는 부분인 거 같습니다. 개인적으로 여러 student 끼리의 DML에 대해선 처음 들어본 지라 성능 향상 폭이라던가 실험적인 내용이 궁금했는데, 방식만 설명을 해 주시고 실험적인 결과나 분석이 없어서 조금 아쉽네요. 추가적인 답변 가능하실까요??
감사합니다.
1) 실험에 사용된 loss는 [식 5]와 같은 형태로 CE와 KLD의 1:1결합으로 이루어져 있으며, 별도로 두 loss의 가중치를 변경한 실험은 없습니다.
2) 달아주신 댓글을 참고하여 본문 하단에 ‘DML with Larger Student Cohorts’ 실험 결과를 추가하였습니다. 각각 1~5개의 student를 사용하여 independent, DML, 앙상블로 실험을 수행한 결과입니다.
리뷰 잘 읽었습니다
Knowledge distilation에 대해서는 얕게 알고 있었는데, student-student 사이의 학습이라는 내용이 흥미로웠습니다.
DML 방법에 대해 간단한 궁금증이 있는데, 그렇다면 도메인이 같은 태스크에 대해서가 아닌 다른 태스크에 대해서도 해당 방법론이 사용될 수 있나요? 간단히는 같은 태스크라면 굳이 저렇게 두 방식을 사용해야하나 싶은데, 그림에서는L_c1과 L_c2가 간순히 분류 문제같아 보여서, 정확히 해당 모델은 어떤 태스크를 위함인지 궁금합니다
저자가 주장하는 Deep Mutual Learning은 같은 종류의 모델이 서로의 지식을 학습하는 방식입니다. 동일한 모델, 동일한 GT, 동일한 Loss를 사용하되, 초기 조건이 다른 두 모델은 결국 서로 다른 표현을 나타내게 되고, 이것이 다른 모델의 학습에 사용되어 작은 모델에서도 보다 폭넓은 사고를 하게 됩니다. 이것이 확장되어 같은 task를 여러 종류의 student가 학습하게 되었습니다. 따라서 모델간의 학습에 다른 도메인의 데이터가 사용되는 것은 DML의 개념에는 맞지 않는다고 생각합니다. 논문에서 해당 방법론은 image classification, instance recognition에 사용되었으나, 더 다양한 task로 확장이 가능할 것으로 보입니다.
리뷰 잘 읽었습니다.
fig 1.에 soft prediction과 hard prediction의 차이가 무엇일까요? student의 soft prediction과 teacher의 soft prediction을 비교하고, hard prediction은 knowledge distilation을 적용하고자 하는 task를 위한 prediction이라 생각하면 되는 걸까요?
hard label은 우리가 일반적으로 알고 있는 모델의 예측값으로 classification에서 모델의 softmax의 output을 의미합니다. 수식으로 나타내면 [latex]p_i = {exp(z_i)\over\Sigma_jexp(z_j)}[/latex]와 같습니다. 이때, p는 softmax에 의해 정답값이나 정답에 유사한 클래스를 제외한 정보들이 거의 소실됩니다. 때문에 softmax에 T값을 추가하여 출력값의 분포를 soft하게 만들어준 것이 soft prediction입니다. 수식으로는 [latex]p_i = {exp(z_i/T)\over\Sigma_jexp(z_j/T)}[/latex]와 같이 나타낼 수 있습니다. 예를 들어 다시 설명하자면, 총 클래스의 개수가 3개인 분류 문제에서 hard label y는 [0, 1, 0], hard prediction은 [10^{-9}, 0.9, 0.1], soft prediction은 [0.1, 0.6, 0.3]과 같이 나타날 수 있습니다.
해당 링크에 더 자세한 설명이 있으니 참고하셔도 좋을 것 같습니다.
리뷰 감사합니다.
우선 수식에 번호가 있었으면 더 보기 좋았을 것 같다고 생각합니다!
그리고 extension to larger student cohorts에서 두 개 이상의 student networks를 사용할 때의 objective function이 있는데 2개 이상의 네트워크를 사용했을때의 실험결과는 혹시 포함되어 있지 않나요?
피드백 감사합니다. 각 수식에 번호는 추가하도록 하겠습니다. 그리고 2개 이상의 네크워크를 사용했을 때의 실험 결과는 본문의 ‘DML with Larger Student Cohorts’부분에 추가해 두었습니다.
안녕하세요. 좋은 리뷰 감사합니다.
small이 large 모델보다 원하는 결과를 얻기 위해 파라미터를 조정하는 과정이 더 어렵기 때문에 작은 모델로도 큰 모델만큼의 성능을 낼 수 있다는 문장이 잘 이해가 가지 않습니다 . . . 상관 관계가 어떻게 되는지 설명해 주실 수 있을까요 ?
또한, KD 과 DML의 가장 중요한 차이점으로, DML은 student 모델들이 서로 상호 협력하면서 최적화된다고 하셨는데 이러한 특징은 KD에 비해 어떠한 이점이 있는 건지 궁금합니다.
감사합니다.
– 우선 첫 번째 질문은 일반적으로는 large model이 small 모델보다 더 풍부한 표현이 가능하기에 더 좋은 성능을 내는 것은 맞지만, 파라미터 튜닝과 모델 설계를 통해 small 모델로도 large 모델에 버금가는 성능을 도출할 수 있다고 합니다. 그러나 그 과정이 어렵다는 것을 의미합니다. 잘못된 표현으로 혼란을 드린 점 죄송합니다… 해당 부분은 수정했습니다…
– 가장 큰 차이점으로는 pretrained의 유무라고 할 수 있습니다. KD는 teacher-student, DML은 student-student간의 학습입니다. 우선 KD는 teacher로 학습을 시키는 만큼 memory cost가 크고, pretrained된 모델이 필요하지만 DML은 small student끼리 학습해도 KD만큼의 성능을 기대할 수 있다는 이점이 있습니다.