오늘의 X-Review도 마찬가지로 Weakly-Supervised Temporal Action Localization(WTAL) 논문입니다.
본 논문은 22년 말 arXiv에 등록되었고 포맷이나 날짜를 보니 CVPR 2023에 투고된 것으로 추정됩니다. 22년 또는 그 이후에 나온 논문들보다도 압도적으로 성능이 높고, 아이디어도 참신하게 다가와 읽게 되었습니다.
Task에 대한 소개는 생략하고, 바로 리뷰 시작하겠습니다.
1. Introduction
우선 논문의 제목에서 알 수 있듯, 본 방법론은 점진적으로 complementary learning을 적용하며 WTAL을 수행합니다. 무엇에 대해 어떻게 점진적이고, WTAL에서 complement 성질을 어떻게 활용하였는지를 알아보기에 앞서 왜 이러한 아이디어가 등장했는지부터 살펴보겠습니다.
논문은 기존에 만연한 WTAL 방법론들을 되짚어보며 시작합니다. Untrimmed video에서 action 구간을 찾아내기 위해 가장 흔하고 많이 사용된 방식은 Multiple-Instance Learning(MIL) 입니다. MIL-based 방법론은 하나의 비디오를 균일하게 쪼개어 여러 개의 snippet sample로 만들고, snippet 단위로 자신들이 제안하는 temporal modeling 방법론을 적용하여 각 snippet이 특정 클래스에 속할 확률값 각각을 예측합니다. 이후 그 예측값들을 aggregate하여 action 분류와 localization을 수행하는 것입니다. 이 방식은 하나의 비디오를 ‘A labeled bag of snippet samples’로 취급한다고도 볼 수 있겠죠.
제가 지금까지 읽어온 WTAL 논문 중 거의 99%는 MIL-based 방법론으로 Temporal-Class Activation Map(T-CAM)을 생성하여 task를 수행하는데, 결국 T-CAM은 action 분류를 위해 가장 크게 기여한 snippet을 구간에 포함시키는 방식이기 때문에 완벽하다고 볼 수는 없습니다.
Task 연구 초반(2018~2020)까지는 단순한 MIL-based 방식이 성능도 높고 우세했지만 그 이후에는 위와 같은 자명한 단점을 보완하기 위한 다양한 방법론이 등장합니다. 1차적으로 proposal을 생성한 뒤 더 넓은 영역의 action 구간을 잡아내기 위해 생성된 구간은 제외하고 다시 proposal을 만들어내는 erasing-based 방식이나 feature 간 representation을 학습하는 metric-learning 방식들도 많이 제안되었습니다.
이후에도 다양한 방식들이 제안되었지만, 가장 효과적이었던 방법론은 pseudo-label based 방식입니다. 분류로부터 얻는 T-CAM의 점수를 활용하는게 아니라, 별도의 모듈을 두어 각 snippet에 대한 attention score를 추출하고 thresholding을 통해 믿을만한 pseudo-label을 만들어내어 직접적으로 localization을 학습하는 것입니다.
여기까지 저자의 introduction을 살펴봤을 때 개인적으로 조금 놀란 부분이 있었습니다. 보통 다른 논문들의 경우, 넓은 범위에서 general하게 문제를 정의(ex. 지금까지의 WTAL 방법론들은 ~)하거나 한 방식 내에 속하는 방법론들의 문제점을 지적(ex. erasing-based 방식 중 ~ 논문은 ~ 문제를 갖고 있다.)하기 마련입니다. 하지만 본 논문의 저자는 대표적 scheme들을 하나하나 지적하고 있는 모습입니다. 그 말인 즉, 이 모든 흐름이 저자가 WTAL 연구의 새로운 지평을 열 새로운 scheme을 제안하기 위한 밑그림인 것인가 예상해볼 수 있었습니다.
앞선 pseudo-label based 방식은 이전에 항상 지적받았던 ‘localization by classification'(MIL-based 방식의 T-CAM은 분류에 큰 역할을 하는 snippet에 큰 점수를 줌)이라는 문제를 어느정도 해결하며 최근에 큰 주목을 받았고, 성능도 우수했습니다. 그럼에도 불구하고 pseudo-label을 잘못 생성하는 순간 큰 성능 악화로 이어지게 됩니다. 예를 들어 “원반 던지기”와 “투포환” 클래스는 시각적으로 굉장히 유사합니다. 그렇기 때문에 만약 초반에 제대로 학습되지 않은 모델이 잘못된 pseudo-label을 할당한다면, 이후에 잘못된 분포를 학습하며 성능 저하로 이어질 수 밖에 없을 것입니다.
저자는 이 포인트에서 영감을 받아, 학습 중 snippet을 하나의 클래스로 특정짓는게 아니고 속하지 않는 클래스들을 하나하나 소거해가며 예측의 오류를 최소화하는 Progressive Complementary Learning (ProCL) 방식을 제안합니다.
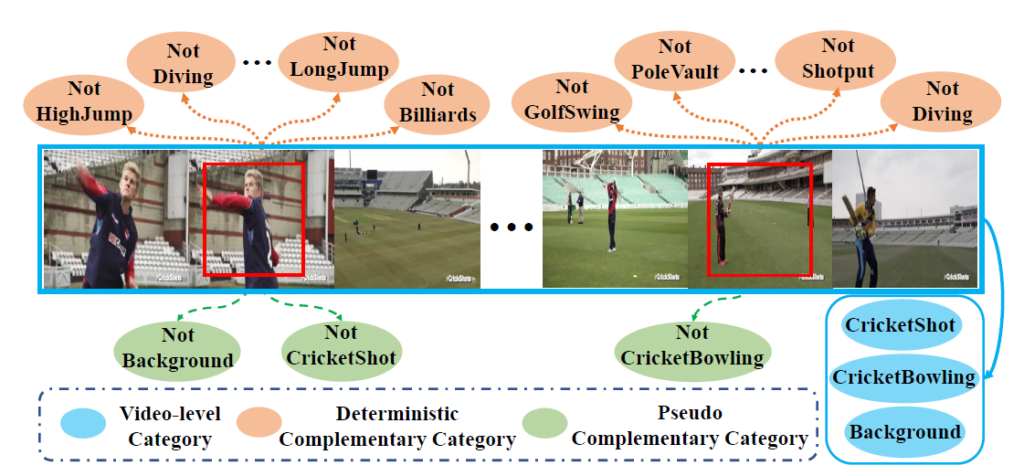
그림 1을 함께 보며 설명드리겠습니다.
저희는 Weakly-supervised이기 때문에, 하나의 비디오에 들어있는 action label을 알고 있는 상태입니다. 그림 1의 비디오에는 “CricketShot”, “CricketBowling”, 그리고 untrimmed video이므로 “Background” 라벨까지 할당되어 있는 상태입니다. 여기서 pseudo-label 방식이 모듈을 통해 score를 추출하여 각 snippet이 셋 중 어디에 속할지 찾아나갔다면, 저자의 ProCL 방식은 우선 절대 속하지 않는 클래스의 score부터 줄이며 시작합니다.
그림 1에서 주어진 video-level label에 따르면 위 비디오의 모든 snippet은 절대 “High Jump”, “GolfSwing”, … 등의 클래스에 절대 속할 수가 없습니다. 저자는 절대 속하지 않는 클래스들을 deterministic complementary categories라고 칭합니다. 이후 남아있는 “CricketShot”, “CricketBowling”, “Background” 클래스 중에서도 하나를 뽑는게 아니라 확실히 아닌 것으로 예측한 클래스(pseudo complementary categories)부터 제외시키며 점점 후보를 줄여나가는 방식입니다. 이러한 방식으로 계속 학습하여 최종 예측값을 만들어내는 새로운 학습 방식 ProCL을 제안하였는데, 이제 세부 학습 방식에 대해 알아보겠습니다.
2. Progressive Complementary Learning
아래 그림 2는 ProCL의 pipeline overview입니다.
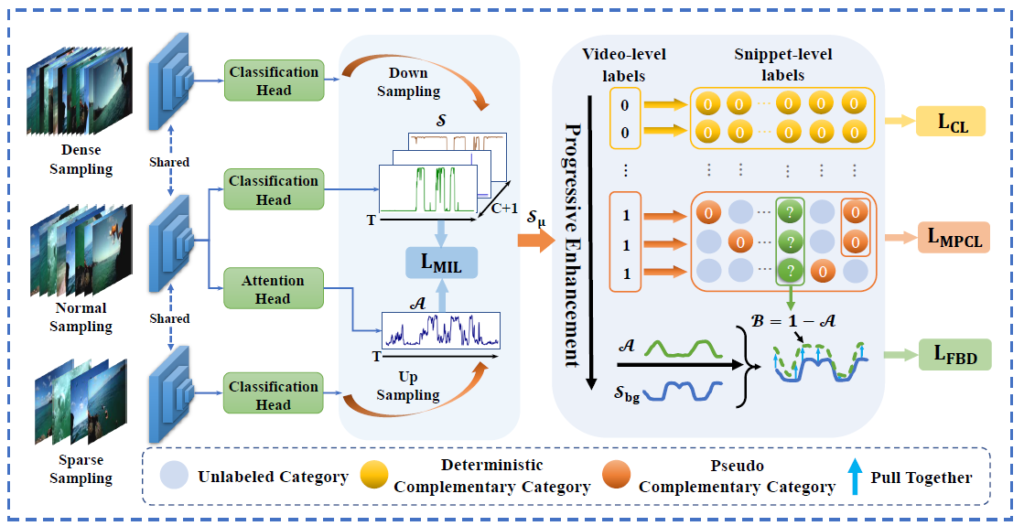
2.1 Problem Formulation and Model Overview
Problem Formulation
N개의 untrimmed video와 라벨 \{\mathcal{V}^{(i)}, Y^{(i)}\}_{i=1}^{N} 이 존재하고, 각 라벨은 video-level label에 해당합니다. 학습을 통해 \{(t_{s}, t_{e}, \psi{}, c)\} 을 얻는 것이 목표이고, 각각 action의 시작, 끝, confidence score, 예측 클래스에 해당합니다.
2.2 Multiple-Instance Learning for WSTAL
앞서 MIL-based 방식의 단점이 존재한다고는 하였지만, 모든 방법론들이 사실 MIL-based 방식의 CAS를 기본적으로 사용하고 있습니다. 2.2절은 사실 상 이전 방법론인 BaS-Net과 거의 대부분 동일하게 구성되기 때문에 아시는 분들은 넘어가셔도 좋을 것 같습니다. 먼저 하나의 비디오에 대해 각각 1024차원으로 이루어진 RGB feature, Flow feature를 합친 후 encode 하여 feature X \in{} \mathbb{R}^{T \times{} D}를 생성해냅니다.
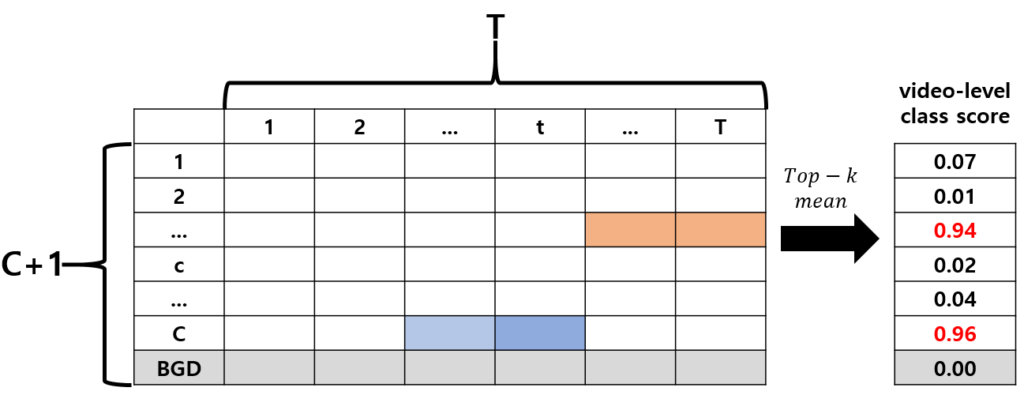
이후 X는 여러 개의 temporal convolution으로 구성된 Classification head를 거쳐 Class Activation Sequence(CAS) \mathcal{S} = \{s_{t, c}\}^{T, C+1}를 만들어 냅니다. 그림 3에서 볼 수 있는 CAS는 introduction에서 언급했던 T-CAM과 같은 것으로 논문에 따라 T-CAS, T-CAM, CAS 등으로 불리기도 합니다. 여러 번 설명드렸듯 하나의 snippet이 각 클래스에 해당할 확률을 담고 있는 matrix였죠. 본 논문에서도 관례를 따라 CAS에 top-k mean pooling을 거쳐 video-level class score를 만들어 냅니다.
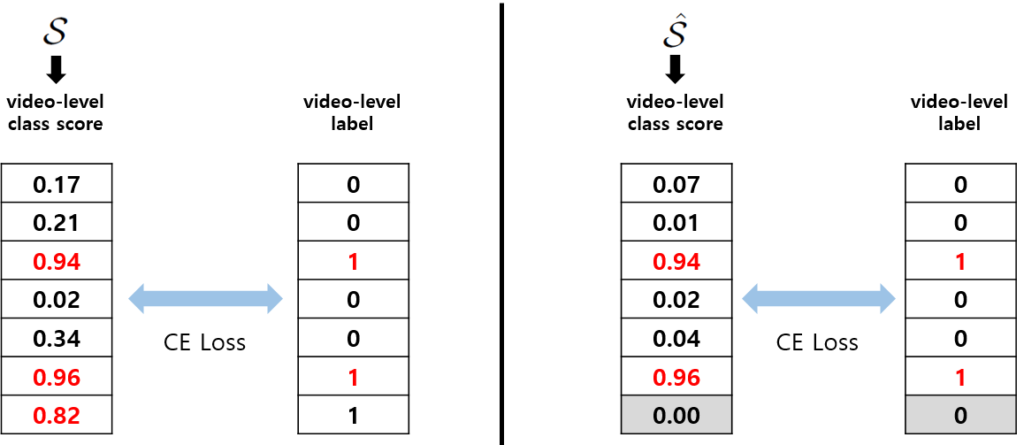
방금 얻은 CAS \mathcal{S}는 untrimmed video feature에 아무런 전처리 없이 생성한 것이므로 video-level class score 중 background class의 확률값은 높아져야 할 것입니다. \tilde{Y} = [y_{1}, \cdots{}, y_{C}, 1] \in \mathbb{R}^{C+1}, 즉 마지막 칸인 background의 라벨이 1로 지정된 GT로 학습하게 되는 것입니다.
다시 앞으로 돌아가서, video feature X를 attention head에 태워 actionness score \mathcal{A} = \{a_{t}\}^{T}를 얻을 수 있습니다. \mathcal{A}는 CAS의 개념과는 조금 다르게 어떤 action인지 관계 없이 하나의 snippet이 action일 확률이 얼마인지를 의미합니다. 앞서 얻은 \mathcal{S}에 \mathcal{A}를 snippet 별로 곱하면 background suppressed CAS \hat{\mathcal{S}} \in \mathbb{R}^{T \times{} (C+1)}을 얻을 수 있고 같은 방식으로 학습하되 GT의 background class는 0으로 지정해주고 top-k pooling을 통해 얻은 video-level class score들을 학습합니다.
수식은 아래와 같고 \mathit{\Gamma}는 top-k pooling, \Phi{}는 softmax 함수를 의미합니다.
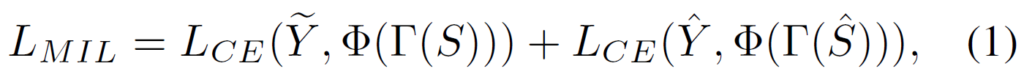
위 과정은 그림 4를 보시면 조금 더 쉽게 이해하실 수 있으실 겁니다.
2.3 Complementary Learning
여기는 1차적으로 주어진 video-level label을 활용하여 자명하게 포함되지 않는 deterministic complementary categories들을 제외시켜주는 과정입니다. 앞서 얻은 CAS \mathcal{S}에 대해 category-wise softmax를 거쳐 snippet-level classification scores \mathcal{P} = \{p_{t, c}\}^{T, C+1} \in \mathbb{R}^{T \times{}(C+1)}를 얻을 수 있습니다. 이에 대해 Complementary Learning (CL) loss는 아래의 식과 같습니다.
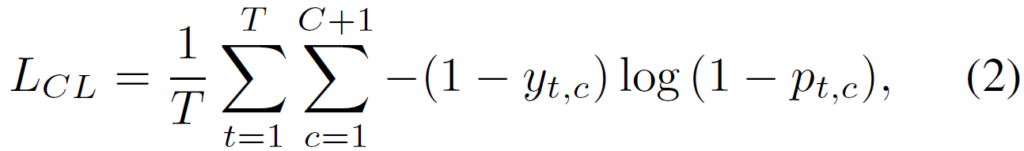
우선 y_{t, c}는 t번 snippet이 c번 클래스 해당 여부에 대한 0, 1 값이고 p_{t, c}는 \mathcal{P}의 같은 위치 원소값입니다. 이에 따라 L_{CL} 수식을 해석해보자면 없는 클래스의 \mathcal{P} score 값을 낮추도록 학습하게 되네요. 적어도 여기까지의 과정은 noise가 전혀 존재하지 않는 정확한 pseudo-label이라고 볼 수 있을 것입니다.
2.4 Pseudo Complementary Learning
이번 단계에서는 존재할 수도 있는 클래스들에 대해 학습해야 합니다. 비디오에 할당된 라벨이 하나라면 2.3절까지의 과정만으로도 꽤 많은 학습을 하였겠지만 다수의 라벨이 할당되어 있는 비디오가 굉장히 많기 때문에 추가적인 작업이 필요하다는 것입니다. 여기서도 하나의 action으로 특정하려고 하기보단, complementary learning의 컨셉을 유지하며 없다고 확신하는 클래스를 제외해나가는 Pseudo Complementary Learning 방식으로 학습합니다. 그렇다면 방금 말씀드린 ‘확신’의 기준을 무엇으로 삼을지 정해야 할 것입니다.
Ambiguity Identification by Information Entropy
각 snippet의 ‘ambiguity’를 정량화하기 위해 \mathcal{S}에 대한 정보 엔트로피 값 h_{t} 사용합니다.
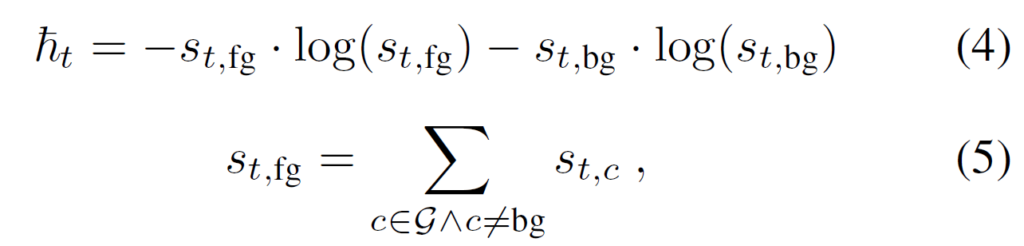
s_{t, fg}는 video-level label \mathcal{G}에 속하는 action class의 \mathcal{S} 값 총합이고, s_{t, bg}는 \mathcal{S}에서 background score 값을 의미합니다. 이를 종합해보면 h_{t}는 둘 간의 정보 엔트로피 식에 해당하고, 당연히 값이 클수록 ambigious, 작을수록 less ambiguous 하다고 해석할 수 있습니다. 현재의 모델이 action과 background를 헷갈려하고 있는지 여부를 의미하는 것입니다.
그러면 아래와 같이 사전에 정의한 threshold 값 \theta{}에 따라 ambiguity indicator F = \{f_{t}\}^{T} \in{} \mathbb{R}^{T}를 지정해줍니다. 수식 (3)에 따르면 h_{t}가 작을수록 1로 지정된다고 하는데, h_{t}의 의미와 본문 뒷부분의 전개를 보았을 때 부등호 방향이 반대로 되어야 맞을 것 같습니다. \theta{}값이라도 알려주었다면 오타인지 아닌지 정하기 수월하였을 것 같은데, appendix도 없고 다른 추가 정보가 없어 일단은 본문의 부등호가 오타라고 가정하고 설명드리겠습니다.
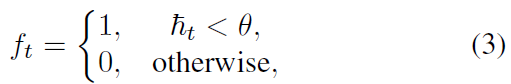
요약하자면 앞으로 f_{t}가 1이면 정보 엔트로피 값이 커 ambiguous한 snippet이고, 0이면 반대로 less ambiguous 한 snippet이라고 보시면 됩니다.
Background-aware Pseudo Complementary Labeling
정보 엔트로피값을 토대로 각 snippet이 ambiguous인지 아닌지를 나타내는 라벨 f_{t}를 붙여주었었습니다. 여기서부터는 이를 이용하여 특정 snippet에 확실히 없다고 판단되는 클래스 score를 줄여주는 방향으로 학습하는 것이 목표입니다.
먼저 snippet-level pseudo complementary labels \mathcal{R} = \{r_{t, c}\}^{T, C+1}을 아래 조건에 따라 할당해줍니다.
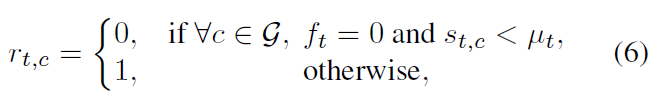
\mu{}_{t}는 video-level label에 속하는 클래스들의 평균 CAS score(bgd도 포함)를 의미하고, f_{t} = 0은 모델이 꽤 확신하고 있다는 것을 의미합니다. 따라서 t번째 snippet에 클래스 c가 없다고 확신할 때 r_{t, c} = 0으로 지정해준다고 이해할 수 있습니다.
이렇게 식 (6)의 과정을 통해 소거해 줄 클래스를 지정하고 나서도 하나 이상의 action과 background가 동시에 살아있을 수 있는데, 실질적으로 한 snippet이 action이면서 background일 수는 없으므로 둘 중 낮은 점수의 클래스도 소거 대상으로 지정해준다고 합니다.
이번 단계에서 학습하는 Pseudo Complementary Learning (PCL) loss L_{PCL}은 수식 (7)과 같습니다.
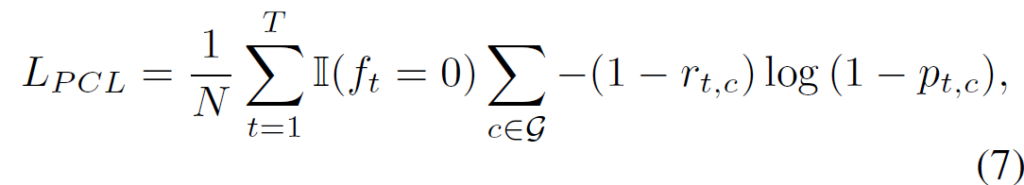
우선 f_{t} = 0인, 즉 결과값에 대해 확신하는 snippet들만 L_{PCL}에 관여합니다. 뒷부분은 r_{t, c} = 0인 경우 p_{t, c} = 0가 0에 가까워지도록 하는 꼴로 구성되어 있는데, 이를 해석해보면 해당 snippet에 없다고 확신하는 클래스의 CAS score값을 0으로 만들어주는것이 되겠네요.
Disambiguation between Foreground and Background
거듭되는 학습에서 애매하지 않다고 지정된 snippet들을 이용하여 소거하는 것도 중요하겠지만, 지금까지 다루지 않았던 애매한 snippet들을 disambiguate하는 과정도 반드시 필요합니다. 결국 action 구간 proposal에 대해 마지막에는 하나의 예측 클래스를 붙여줘야 하는 task이기 때문입니다.
이를 위해서 애매하다고 지정(f_{t} = 1)된 snippet들을 attention branch에 태워 추출한 Actionness score \mathcal{A} \in \mathbb{R}^{T}와 CAS \mathcal{P}의 마지막 행인 \mathcal{P}_{bg} = \mathcal{P}_{C+1}을 활용합니다.
\mathcal{A}는 각 snippet이 클래스 관계 없이 action일 확률을 의미하고, 여기서 \mathcal{B} = 1 - \mathcal{A}는 각 snippet이 background일 확률 또는 attention score로서의 의미를 가지게 될 것입니다. 해당 \mathcal{B}와 \mathcal{P}_{bg}는 같은 의미를 담고 있는 값들이므로 유사해져야겠죠. 그러한 관점에서 저자는 Foreground-Background Discrimination (FBD) loss를 제안하여 애매한 snippet들이 action인지 background인지부터 갈피를 잡을 수 있도록 해줍니다. 수식은 아래와 같습니다.
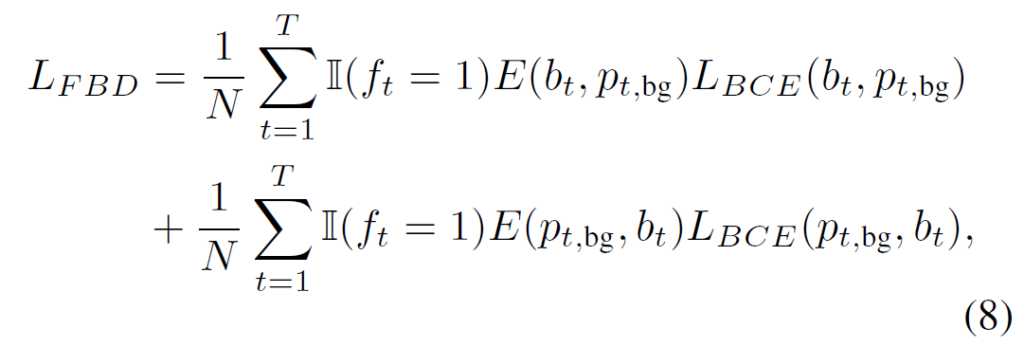
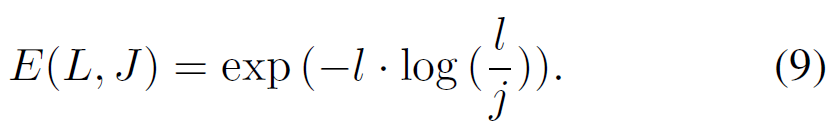
수식 (8), (9)에서 E는 KL-divergence를 의미하고 KL-divergence의 최소화는 log-likeligood의 최대화와 같으므로 결국 L_{FBD}는 두 값이 서로 같아지도록 학습하는 것을 목표로 한다고 볼 수 있습니다.
2.5 Multi-Scale Complementary Labeling
이해를 돕기 위해 먼저 한 가지만 짚고 넘어가겠습니다. 2.4절에서 설명드린대로 학습하면 L_{PCL}을 사용하는 방식에 해당하는 것이고, 여러 scale의 CAS를 이용하여 2.5절에서 설명드릴 내용대로 학습하면 L_{MPCL}을 사용하는 방식에 해당하는 것입니다. 둘은 양립할 수 없다는 점을 알고 넘어가시면 뒷부분을 이해하기 수월하실 것 같아 적어두었습니다.
이전까지의 과정은 비디오를 통일된 T개의 snippet으로 분할하여 다루었었는데요, 실제 action의 경우 같은 클래스에 속하더라도 시간 구간의 스케일이 다를 수도 있습니다. 저자의 예시에 따르면, “Diving”의 경우 샘플마다 어느 정도 높이에서 뛰어내리는지가 다르고 높이에 따라 action 구간 길이가 달라지게 된다고 합니다.
이렇게 가변적인 action 길이에 대응하기 위해 dense feature X^{D} \in{} \mathbb{R}^{2T \times{} D}와 sparse feature X^{S} \in{} \mathbb{R}^{\frac{T}{2} \times{} D}를 추출합니다. 맨 처음 과정과 똑같이 수행하여 각각의 CAS \mathcal{S}^{D} \in{} \mathbb{R}^{2T \times{} (C+1)}, \mathcal{S}^{S} \in{} \mathbb{R}^{\frac{T}{2} \times{} (C+1)}를 얻을 수 있습니다. 다시 둘을 T \times{} (C+1)로 샘플링하여 이제는 동일한 shape의 CAS 3개를 얻을 수 있고, 각 위치의 score값에 대한 평균 \mathcal{S}^{\mu{}} \in{} \mathbb{R}^{T \times{} (C+1)}과 표준편차 \mathcal{S}^{\sigma{}} \in{} \mathbb{R}^{T \times{} (C+1)}도 쉽게 계산할 수 있습니다. 특히 \mathcal{S}^{\sigma{}}의 특정 위치 값이 크다면 scale에 따른 편차가 크다는것이므로 예측값은 불안정하다고 볼 수 있겠네요.
Multi-scale information을 담은 \mathcal{S}^{\mu{}}에 대해 앞선 2.4절의 방식을 동일하게 적용하면 ambiguous indicator \ddot{\mathcal{F}}와 pseudo complementary labels \ddot{\mathcal{R}}을 얻을 수 있습니다. 이후 아래와 같은 Multi-scale Pseudo Complementary Learning (MPCL) loss로 학습하게 됩니다.
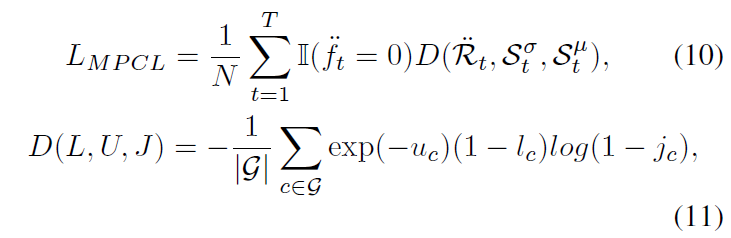
L_{MPCL}에서도 확실한 snippet들만 관여하게 됩니다. 수식 (11)에 따라 해석해보면 \ddot{r}_{t,c}가 0인, 즉 확실히 없다고 판단되면 \mathcal{S}^{\mu{}}에서 해당 위치의 score값이 줄어들게 학습합니다. 다만 주목할 점은 앞에 exp(-\ddot{s}^{\sigma{}}_{t, c}) 값이 붙어있다는 것입니다. 이는 편차가 클수록 확신의 여부 자체가 불확실함으로 그 지점 값이 loss에 미치는 영향을 줄이도록 설계했다고 이해하였습니다.
일반 scale의 \mathcal{S}만으로는 가변적인 action 길이에 대응하기 부족하였을텐데, L_{MPCL}을 통해 이에 조금 더 강인한 모델이 될 수 있었다고 생각합니다. 추가로 이 부분을 이해하는데에 조금 어려움이 있었기 때문에 혹시나 제가 잘못 설명한 부분이 있는 경우 댓글을 통해 지적해주시면 감사드리겠습니다.
2.6 Overall Training Objective and Inference
학습의 최종 Loss는 아래와 같습니다.
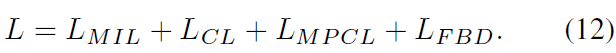
Inference 시에는 actionness score \mathcal{A}와 background suppressed CAS \hat{S}를 활용합니다. 먼저 \hat{S}에 top-k pooling을 거쳐 video-level class score를 만들고 thresholding하여 비디오에 존재하는 action들을 추려냅니다. 이후 \mathcal{A}를 이용해 class-agnostic action proposal 구간을 생성하여 각 proposal의 action을 분류하는 순서로 진행됩니다.
이제 방법론에 대한 설명은 모두 마쳤고, 실험 부분으로 넘어가겠습니다.
3. Experiments
3.1 Comparison with State-of-the-Arts
다른 논문들과 동일하게 THUMOS14, ActivityNet v1.3 데이터셋에 대한 벤치마크 성능(threshold 별 mAP)을 보여주고 있습니다.
THUMOS14
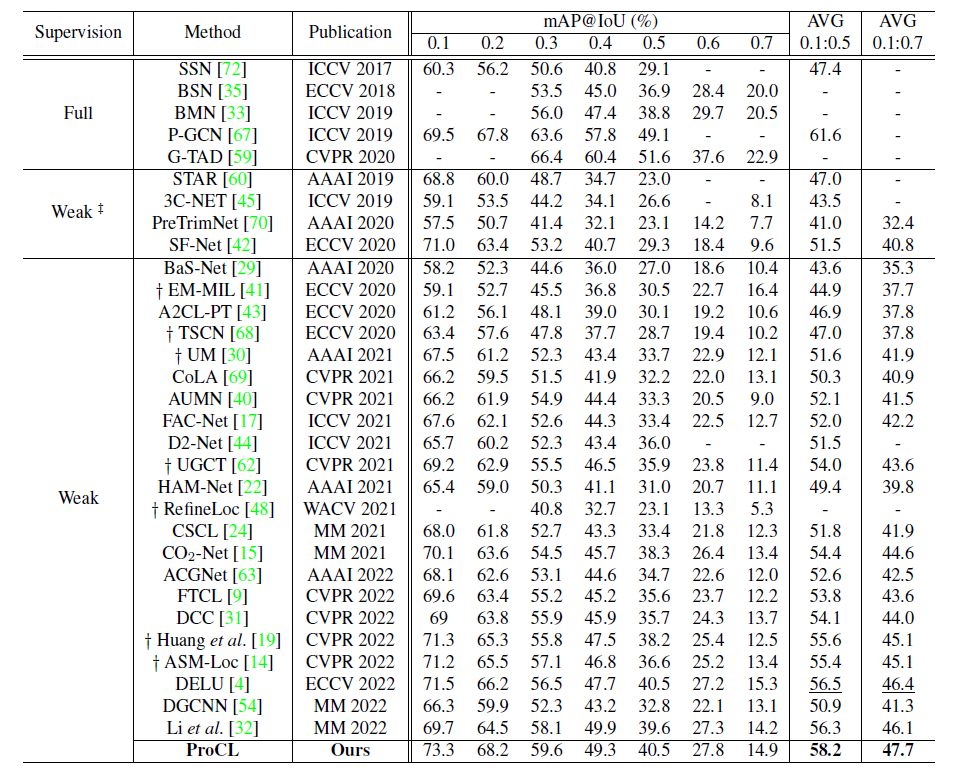
22년도 SOTA들을 포함하여 굉장히 많은 방법론들의 성능을 함께 리포팅하고 있는데요, 그들 중에서도 크게 향상된 성능을 보이고 있습니다. 물론 해가 넘어갈 때마다 성능이 꽤 크게 향상되는 경향이 있는 것은 사실이지만, 이전에 리뷰했던 WACV 2023, TMM 2023 등 비슷한 시기에 등장한 논문들보다도 더 큰 향상폭을 보이는 점이 놀랍습니다. 참신한 방법론을 제안했기 때문에 더욱 높아보이는 것 같기도 하네요.
\dagger{} 표시된 방법론들이 pseudo-label based 방식입니다. ProCL이 완벽하진 않지만 상대적으로 이전보다는 더욱 정확하고 믿을만한 pseudo-label을 만들어낸다는 것을 정량적 결과를 통해 증명하였습니다. 추가로 22년도 ECCV의 DELU라는 방법론의 성능도 굉장히 높은데, 다음에 기회가 되면 리뷰해보겠습니다.
ActivityNet v1.3
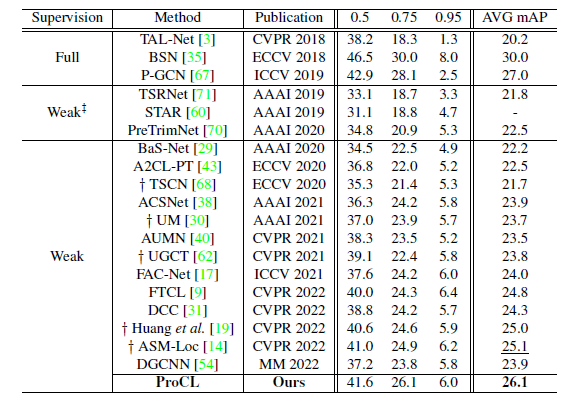
ActivityNet v1.3 데이터셋에 대해서도 굉장히 큰 차이로 SOTA를 달성하고 있습니다.
3.2 Ablation Studies
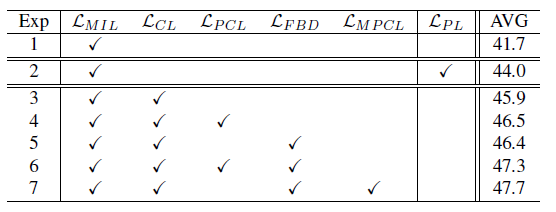
각 loss에 대한 ablation 성능입니다. 앞서 방법론 부분에서도 설명드렸듯 어떤 CAS를 사용하여 PCL을 수행하는지에 따라 둘 중 하나로 정해지기 때문에 L_{PCL}과 L_{MPCL}은 양립할 수 없습니다. 이 점을 참고했을 때 ProCL에서 제안한 모든 loss들이 붙일 때마다 성능이 오르는 것을 볼 수 있습니다.
주목할만한 점은, 기타 loss를 붙이지 않았을 때를 기준으로 기존의 pseudo-label based 방법론(ASM-Loc) 성능보다 L_{CL}만을 사용할 때가 성능이 더욱 높았다는 것입니다. L_{CL}만을 사용한 경우에도 벌써 성능이 웬만한 22년도 방법론들의 성능보다 높다는 것이 놀랍습니다.
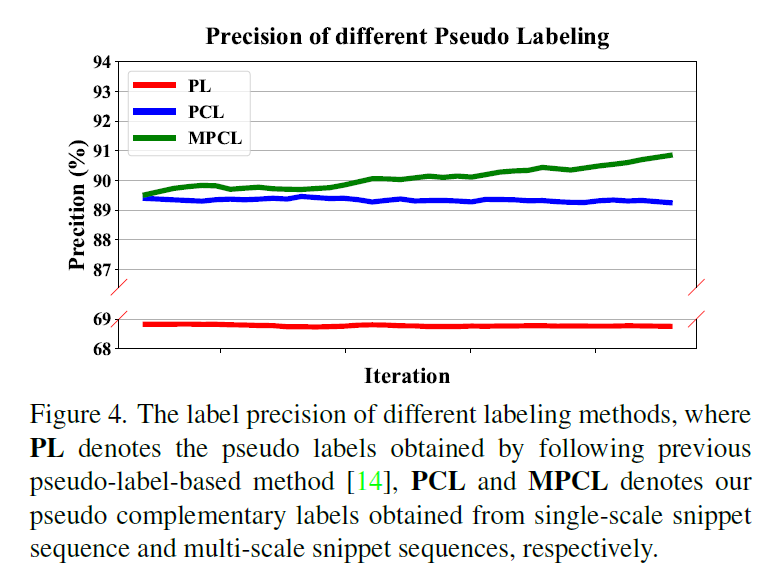
위 그림은 기존 pseudo-label based 방법론인 ASM-Loc와 ProCL이 iteration 별로 생성하는 pseudo label, pseudo complementary label의 precision을 각각 측정한 것입니다. Snippet 단위로 생성하였던 r 값에 대한 precision을 측정한 것으로 보이는데 기존의 pseudo label보다 훨씬 더 높은 precision을 보여주는 것을 알 수 있었습니다. 사실 둘은 애초에 다른 개념이기 때문에 complementary label의 성능이 막연히 좋다라기보다는 그만큼 적은 noise로 올바른 supervision을 제공하는 안정적인 학습방식이라는 것을 증명하는 결과라고 생각하면 좋을 것 같습니다.
또한 실험이 모든 iteration에 대해 측정한 것인지는 나와있지 않지만, 어느정도 학습이 수행됨에 따라 pseudo complementary label은 점점 개선된다는 것도 주목할만한 것으로 보입니다.
나머지 실험들은 위 loss ablation에 대한 정성적 결과 또는 다른 방법론과의 정성적 비교라서 큰 의미가 없다고 판단되어 제외하였고, 궁금하신 분들은 찾아보시면 좋을 것 같습니다.
4. Conclusion
아직은 arXiv 버전이라 중간중간 오류도 있었고 detail이 부족하여 이해하기 어려운 부분도 많았습니다. 하지만 아이디어도 굉장히 참신하고 성능도 높아 추후에 만약 accept 되어 정식으로 게재되고 appendix도 공개된다면 반드시 다시 한 번 깔끔하게 정리해두도록 하겠습니다.
다른 도메인에서의 task를 수행하시는 연구원분들도 위와 같은 Complementary Learning의 아이디어를 차용해 가신다면 좋은 결과가 있지 않을까 생각하는 마음으로 리뷰를 작성하였습니다.
이상으로 리뷰 마치겠습니다. 감사합니다.
리뷰 잘 읽었습니다.
‘pseudo-label을 잘못 생성하는 순간 큰 성능 악화로 이어진다’ 라는 말을 곱씹어서 보니 기존에 pseudo-label에 대해 너무 당연히 gt와 유사한 것처럼 사용하고 있었다는 생각이 드네요. 사실 pseudo-label 은 특정 모델이 예측한 ‘정답에 유사한’것일 뿐인데요. …
pseudo-label에 대한 이 당연하지만 치명적인 문제 정의는 본 논문에서 처음 제시 한 것인가요? 아니면 citation을 걸었나요?? 정말 직관적이고 간단한 문제점이지만, 꼭 필요한 문제 정의를 통해 문제를 해결 해 나가는 본 논문이 참 대단하다는 생각이 드네요.
나중에 가능하다면 제 실험에도 이러한 방식을 적용 해 보고 싶네요.
잘 읽었습니다. 감사합니다 ㅎㅎ
pseudo-label의 문제점을 지적하는 방법론은 많았습니다.
하지만 이를 해결하는 방식이 더 나은 pseudo-label을 만들기 위해 K-Means 군집화를 이용하는 등 denoising 위주로 진행되었습니다.
하지만 제가 본 논문이 참신하다고 생각하는 이유는 그에 대한 해결 방식이 pseudo-label denoising이 아닌 새로운 학습 방식, Complementary learning이었기 때문입니다.
리뷰 잘 읽었습니다. introduction부분이 참신해서 덕분에 계속 흥미를 가지고 읽을 수 있게 된거 같습니다. 감사합니다. 저도 한 분야의 논문을 계속 읽으니 introduction이 대분류에 속하는 문제를 비슷하게 지적하는 부분이 많았는데 이 논문은 세세하게 지적한 것을 보니 저자가 발전 가능성이 높은 분인거 같습니다.
궁금한 점이 실험 파트에서 supervision이 3가지로 나눠있는데 이것들의 차이는 무엇일까요?
가장 위 ‘Full’은 WTAL에서 사용하는 video-level label 뿐만 아니라 temporal annotation까지 활용하는 방식입니다.
중간 Weak는 temporal annotation 없이 video-level label을 사용하되 추가적인 정보를 같이 사용하는 것입니다. 예를 들어, 가장 아래 Weak는 이 비디오에 어디인진 모르겠지만 ‘GolfSwing이 있다’고 알려주는 것이라면 중간 Weak는 ‘GolfSwing’이 비디오에 3개 있다 등 추가 정보를 제공하여 학습하는 것입니다.
가장 아래 Weak는 계속 제가 보고 있는 WTAL인 video-level label만을 제공받아 학습하는 것입니다.
complementary learning이라는 용어는 처음 들어보네요. 이전에 스터디를 할 때 개념적으로 설명을 들었지만 후에 세미나를 할 때 관련 내용을 더 보충해주면 좋을 것 같습니다.
소거한다는 아이디어가 굉장히 인상적입니다. 코드는 공개가 되어 있나요?
궁금한건 Clasification loss만을 사용한 경우에도 벌써 성능이 웬만한 22년도 방법론들의 성능보다 높다고 했는데 이유가 뭔가요? 저 실험은 THUMOS 기준인가요? ActivityNet인가요? 베이스라인 부터가 이미 다른 SoTA 방법론을 넘어서는 경우라면 뭔가 fair comparison이 아닌 것 같은데 어떻게 생각하시나요?
코드를 공개한다는 이야기가 아직 없어 아쉽습니다.
아래 loss ablation은 THUMOS 기준 0.1:0.1:0.7 평균 mAP인데, baseline인 Exp.1에 대해
“Exp.1 is the baseline only trained with L_MIL”이라고만 적혀 있고 추가 정보를 알 수가 없었습니다.
metric learning을 포함하는 CoLA보다 성능이 높은 것이 확실히 이상하다고는 생각이 들어서, 이 부분은 Appendix가 공개된 뒤 확인해봐야 할 것 같습니다.