Before Review
arXiv에 올라온 preprint 이지만 CVPR format 이며, 연세대와 포스텍의 합작 논문이라 읽어보게 되었습니다.
제가 이전에 자주 리뷰하던 Temporal Action Localization에 대한 논문입니다.
전년도에 제가 했던 고민들에 대해서 해결책을 제시해줄 수 있는 논문입니다.
리뷰 시작하도록 하겠습니다.
Introduction
저희가 스마트폰을 사용할 때 빠질 수 없는 어플이 하나 있죠. 바로 YouTube 입니다. 다양한 콘텐츠를 담은 미디어 시장이 성장하면서 자연스레 비디오 데이터를 어떻게 효율적으로 처리할 지에 대한 연구도 관심을 받고 있습니다.
특히 사람의 행동을 분류하고 그 위치를 찾는 Temporal Action Localization (이하 TAL)은 무분별한 background frame 속에서 관심 있는 영역을 retrieve 하는 task로 computer vision 진영에서 많은 주목을 받고 있습니다.
그 중요함에도 불구하고 TAL task는 비디오 데이터라는 대용량의 large-scale input size로 인해 많은 어려움을 겪고 있습니다. 우리 모바일 장치에 몇 분 혹은 몇 시간이 넘어가는 비디오 데이터를 실시간으로 입력으로 받아 적당한 output을 만들어내기란 아직 까지는 불가능하죠.
이러한 상황을 고려하여 기존의 연구들은 크게 두 가지의 step으로 나뉩니다.
- Snippet Encoder를 large-scale의 action classification dataset으로 사전학습을 시킵니다.
- 위에서 사전학습된 Encoder를 freeze 하고 TAL를 위한 downstream head만을 finetuning 시킵니다.
이렇게 했던 이유는 Snippet Encoder 까지 다시 학습을 시키기에는 computation cost가 굉장히 크기 때문입니다.
실제로도 사전 학습된 Encoder를 가지고 TAL을 위한 downstream head만을 학습 시키면 GPU memory 4G 정도로도 2시간 만에 모든 학습을 끝낼 수 있습니다. 하지만 모든 과정을 다시 finetuning 시키면 GPU도 여러개 필요하며 학습 시간이 훨씬 더 오래 걸리게 되죠.
관습적으로 computation cost 때문에 이러한 구조로 연구가 진행되었지만 가장 큰 문제점이 하나 존재합니다.
바로 task discrepency 이죠. 사전 학습은 Classification으로 했는데 정작 down-stream task는 localization 입니다. 제가 이러한 문제를 다루는 연구들에 대해서는 이전에 리뷰한 적이 있습니다.
근데 사실 이전 연구들은 task discrepency 문제를 해결하기 위해 사전 학습 단계부터 다시 시작합니다. Localization을 위한 사전 학습을 다시 정의하는 것이죠. 이렇게 되면 사전 학습부터 다시 시작하게 되니 아무래도 시간이 오래 걸리긴 하겠네요. 하지만 상용화 관점에서는 사전 학습에 들어가는 비용은 저는 크게 중요하지 않다고 생각됩니다. 학습 시켜 놓고 배포하면 문제 없으니깐요.
그럼에도 기왕이면 추가적인 사전 학습 없이 기존의 방법을 고수하되 좀 더 효율적으로 task discrepency 문제를 해결하면 더욱 좋겠네요.
그런 관점에서 저자는 새로운 사전 학습 없이 action classification dataset으로 사전 학습된 Encoder와 Localization을 수행하는 TAL head 간의 discrepency를 완화 시킬 수 있는 module을 제안합니다.
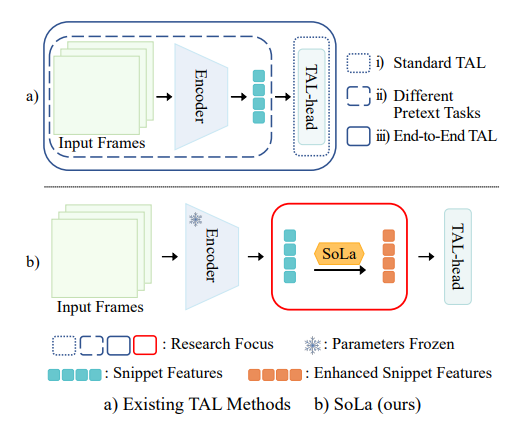
위의 그림을 보도록 하겠습니다. (a)의 경우 이전의 연구들의 상황을 요약해주고 있습니다.
(i)는 Standard TAL로 그저 좋은 TAL-head만을 만드는 것이 목적입니다. 이렇게 되면 task discrepency가 발생하겠네요.
(ii)의 경우는 TSP, BSP, UP-TAL 와 같이 temporally-sensitive 한 pre-text task를 가지고 다시 사전 학습을 한 경우를 의미합니다. 이렇게 되면 task discrepency는 줄어들지만 computation cost는 굉장히 증가합니다.
(iii)의 경우는 완전한 end-to-end의 경우로 Encoder와 head를 연결하여 gradient가 처음부터 끝까지 다 흐르게 하는 경우를 의미합니다. 완전하게 finetuning을 하기 때문에 target dataset에서는 성능이 우수할 수 있지만 overfitting의 문제와 computation cost가 발생합니다.
(b)의 경우가 저자가 제안하는 방식입니다.
일단 Kinetics를 대체할 수 있을 만한 large-scale의 dataset은 없으니 Encoder 자체는 Classification을 가지고 사전 학습한 것을 사용합니다. 그리고 Encoder를 freeze 한 다음 바로 TAL-head로 가는 것이 아니라 Soft-Landing strategy를 활용하는 중간 module을 넣어 Encoder와 head간의 smooth한 connection을 생성합니다.
SoLa는 굉장히 가벼운 neural network로 구성되어 pretrained encoder와 downstream head간 task discrepency를 완화시킬 수 있는 module 입니다.
그럼 이제 이 간단하지만 나름 강력한 module에 대해서 알아보도록 하겠습니다.
Method
Overview of Soft-Landing Strategy
제안되는 SoLa 모듈의 목적은 결국 frozen encoder를 통해서 나온 즉, classification에 최적화된 사전학습 feature를 받아서 localization down-stream head에 넘겨주기 전에 feature level 단에서 temporal sensitivity를 가지기 위해서 전처리 느낌으로 feature를 enhancement 해주는 것 입니다. 아래 그림 처럼 SoLa에 들어가는 feature는 입력과 출력의 차원이 동일합니다.
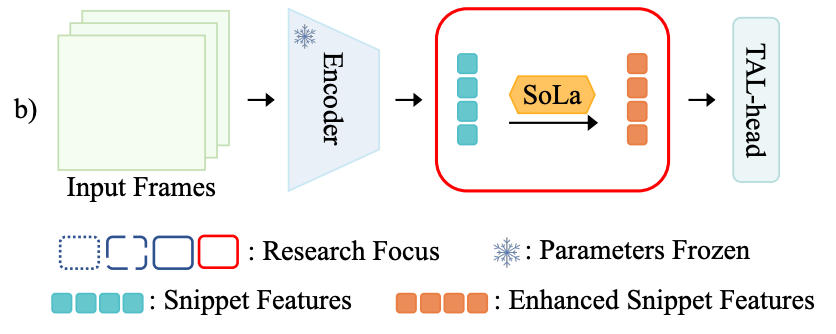
feature가 enhancement 된다고 해서 뭔가 복잡한 장치가 있는 것은 아니고 단순히 Linear Layer를 두번 태워 줍니다. 그런데 이 때 중요한 것은 이 Linear Layer를 그냥 넣어주는 것보다 무언가 목적 아래 방향성을 가지는 Loss가 있어야 Temporal sensitivity를 가질 수 있겠죠. 이를 위해 저자는 Similarity Matching을 제안합니다.
Similarity Matching
target dataset에 대해서 unlabeled 상황을 가정하기 때문에 SoLa 모듈을 학습 시키기 위해서는 self-supervised learning 기법이 필요합니다. 요즘에 많은 주목을 받고 있는 Self-Supervised Video Representation Learning은 RGB raw video frame을 가지고 crop 하거나 flip 하는 등, 입력 비디오 단에서 augmentation이 진행되기 때문에 사전학습 feature sequence를 가지고 진행하는 지금의 상황과는 맞지 않습니다.
그렇다고 feature level 단에서 augmentation을 하기 보다 저자는 temporal similarity structure를 이용하기로 합니다. 일반적인 비디오를 관통하는 특징은 인접한 frame 끼리는 similar하며 떨어진 frame끼리는 distinct 하다는 것입니다.
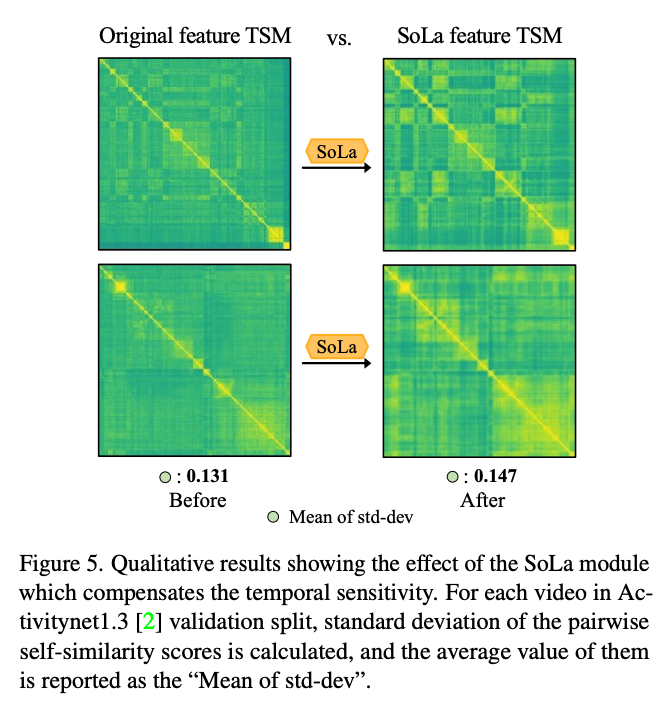
모든 비디오에 완벽히 들어맞는 observation은 아니지만 어느정도 일리 있는 말입니다. 왜냐하면 비디오의 fps가 높으면 인접한 프레임은 거의 중복된 정보를 담고 있기 때문입니다. 아래 그림을 확인 하면 back bone 상관 없이 어느 정도 일정한 패턴을 보여주고 있습니다.
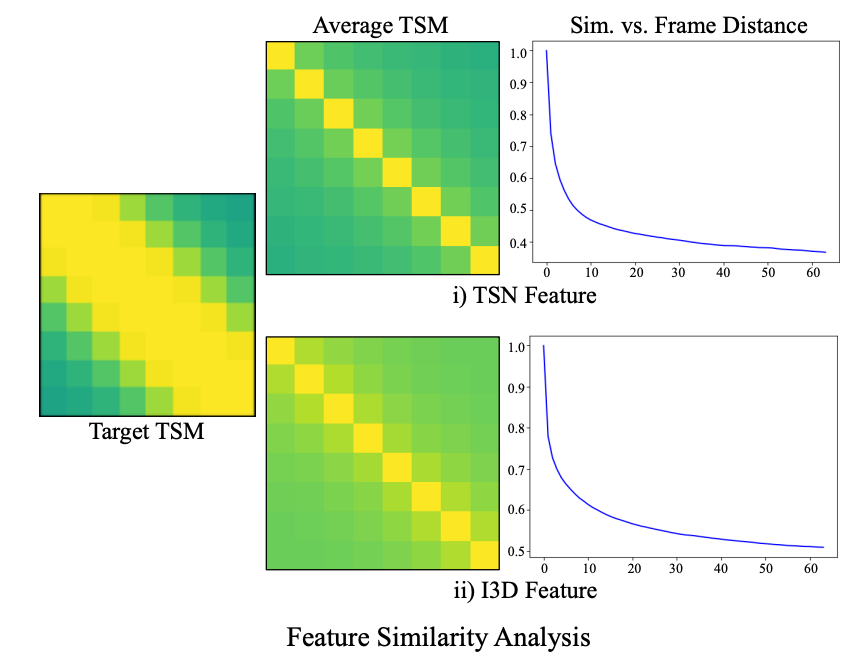
비디오 분야에서 자주 사용하는 self-similarity map 입니다. 대각 성분은 같은 위치에 해당하는 feature 끼리의 유사도 이기 때문에 1이 나오고 대각 성분이 아닌 위치를 중점적으로 보면 됩니다. 결국 인접한 feature 끼리 유사도가 높게 나오고 있습니다.
이는 TSN feature든, I3D feature든 상관 없이 비슷한 패턴을 보여줍니다.
이러한 패턴을 바탕으로 저자는 frame 간 Interval을 learning signal로 사용합니다.
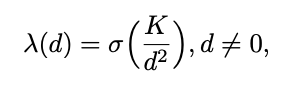
d는 실제 frame간 간격이며 K는 고정된 kernel size 입니다. \sigma는 시그모이드 함수 입니다. K는 고정된 상수이기 때문에 d에 따라서 출력 값이 달라집니다. 결국 프레임간 간격이 멀어질 수록 0에 가까운 값을 가지게 되고 d가 작아 간격이 가까운 경우에는 1에 가까운 값을 가지게 됩니다.
결국 간격이 가까운 프레임은 유사한 정보를 가지고 있을 확률이 높으니 cosine similarity를 1로 멀다면 0으로 조정하기 위한 pseudo label 이라 보시면 됩니다.

원래 cosine similarity는 -1~1 사이의 값을 가지고 있는데 위의 수식 처럼 rescaling 해주면 0~1 사이의 값으로 조정할 수 있습니다. 최종적으로 SoLa를 거쳐서 나온 enhance 된 feature를 가지고 Temporal Similarity Map(TSM)을 생성하고 위의 pseudo label과의 비교를 하는 binary cross entropy loss를 통해 feature들의 temporal sensitivity를 조절할 수 있습니다.
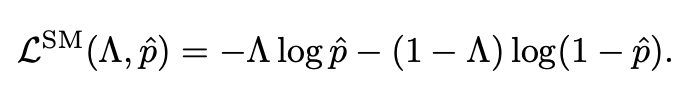
method는 이게 전부 입니다. Loss도 한가지만 BCE Loss가 전부이고요. 그럼 실험으로 넘어가도록 하겠습니다.
Experiments
Main Results
TAL Results
Classification과 Localization간의 task discrepency를 다룬 논문이기 때문에 정말로 SoLa를 통해 그 gap이 줄어들었는지 TAL task에서 확인을 해야겠죠.
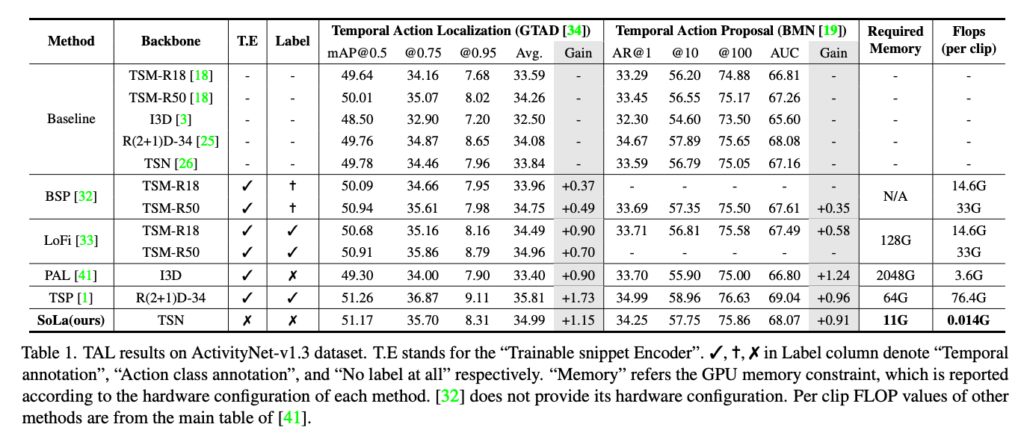
자 Baseline은 고정된 Backbone Feature 만을 가지고 down-stream head에 적용했을 때의 성능입니다.
BSP는 Copy and Paste 방식으로 data augmentation 으로 Untrimmed Video를 생성하고 classification 혹은 regression loss를 통해 task discrepency를 해결했습니다. BSP는 적어도 각 비디오가 어느 Class인지는 알아야 가능하기 때문에 제한조건이 붙으며 Clip당 Flops도 좋지 않습니다.
TSP는 완전히 지도학습으로 사전학습과 down-stream task이 동일한 데이터셋을 가지고 진행됩니다. 사실상 성능이 낮을 수가 없는 구조라 보시면 됩니다. 완전히 지도학습으로 진행 됐기 때문에 저자가 제안하는 SoLa 보다는 조금 높은 성능을 가져가지만 그 차이가 많이 나지 않을 뿐더러 완전한 annotation이 필요하다는 점, FLops가 굉장히 많이 필요하다는 점이 한계점입니다.
PAL은 완전한 비지도학습으로 pseudo action localization을 제안한 논문입니다. 사전학습 단계에서 Trimmed Video를 붙여 Untrimmed Video를 만들고 Localization Loss와 Contrastive Loss를 통해 Encoder 단부터 학습을 진행합니다. 따라서 필요한 GPU memory가 상당합니다.
제안되는 SoLa의 성능이 상당히 인상적입니다. SoLa는 두개의 Linear Layer만을 사용하기 때문에 추가적으로 발생하는 cost가 거의 없으며 간단한 구조 덕분에 어느 방법에나 접목이 가능하다는 장점이 존재합니다. Memory와 FLops 관점에서 굉장히 낮고 down-stream task에서의 성능이 골고루 높은 점을 보아 SoLa가 간단하지만 classification과 localization 간의 task discrepency를 어느정도 해소해주는 것을 확인할 수 있었습니다.
Qualitative Results
아래의 그림을 보면 기존 TSM보다 SoLa를 통해 enhance된 TSM이 더 다양한 패턴을 보여주고 있습니다. 적어도 인접한 애들끼리 비슷한 representation을 가져가니 down-stream level에서는 temporally sensitive한 feature를 통해 task discrepency를 줄이는 모양입니다.
Linear Evaluation
Representation Learning 기반의 연구에서 주로 하는 평가 방법이 하나 있죠. 바로 Linear evaluation 입니다. Feature extractor는 고정시키고 마지막에 linear layer만 하나 추가하여 down-stream task를 수행하는 것 입니다. 정말 좋은 feature representation이라면 linearly seperable 해야 한다는 소리 입니다.
여기서 주로 다루는 task는 localization task 이므로 완전하게 linear evaluation 하기는 어렵습니다. 고로 저자는 각 snippet이 foreground인지 background인지 구분하는 binary classification을 통해 linear evaluation을 진행했다고 합니다.
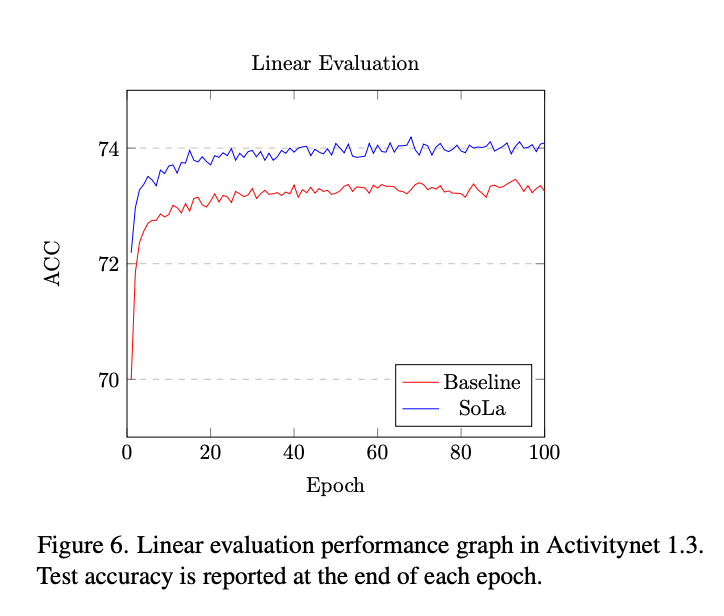
SoLa를 통해 enhance된 feature들이 linear evaluation에서도 더 좋은 모습을 보여줍니다.
한가지 아쉬운 것은 foreground->background 혹은 background->foreground 처럼 바뀌는 경계 부근에서의 정확도를 reporting 해줬으면 정말로 temporally sensitive한 feature라는 것이 더 와닿았을 것 같은데 그런 실험은 없네요.
Ablation Study
저자는 SoLa 모듈에 대한 ablation 실험을 G-TAD라는 action localization down-stream head에 대해서 진행하였습니다.
세가지 측면에서 ablation을 수행하였습니다. 1) receptive field, 2) unified training, 3) different snippet encoder
SoLa module은 1D convolution layer로 구성되어 있기 때문에 적절한 kernel size를 찾는 것은 중요한 design choice 입니다. 다음으로 SoLa의 학습은 따로 진행한 다음에 down-stream으로 넘어간다고 하였습니다. 그럼 unified framework에서의 학습이랑 비교도 해봐야겠지요. 마지막으로 SoLa의 generality를 확인하기 위해 RGB only 만을 사용하는 feature와 two-stream(RGB + flow)를 사용하는 feature간의 비교를 진행하였습니다.
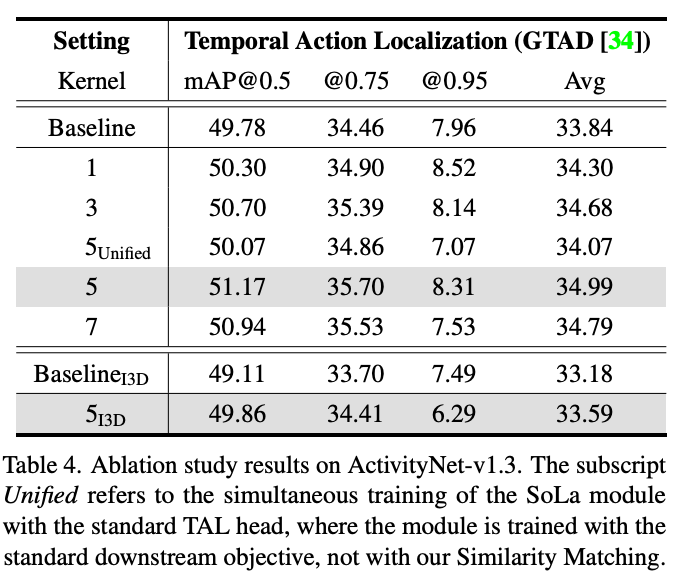
사실 Kernel size는 크게 의미가 없으니 넘어가고 Unified 와 아닌 경우 대해서 비교하면 따로 학습 하는 것이 더 좋은 성능을 보여줍니다. 그런데 여기서 Unified는 SoLa로 feature를 transformation 만 진행하고 Similarity Matching은 수행하지 않았다고 했는데 왜 이렇게 했는지 조금 의아하네요.
Unified framework 상황에서 Similarity Matching 없이 비교 하는게 큰 의미가 있는지 의아하네요.
마지막으로 5_{I3D}와 Baseline_{I3D}간의 비교 인데 5_{I3D}는 RGB only이고 Baseline_{I3D}는 RGB + flow 입니다.
SoLa가 RGB only에서 더 좋은 성능을 보여준다고 해서 generality를 가진다는 것은 조금 의문이 드네요. 정말 general 하려면 two-stream에서도 baseline 대비 더 좋은 성능을 보여줘야 할 거 같은데 조금 애매하네요.
Conclusion
굉장히 단순하고 확장하기 용이한 구조를 제안한 논문인 것 같습니다. 하지만 frame의 Interval만을 learning signal로 사용한다는 것이 너무 간단하고 trivial하지 않나 라는 아쉬움도 들게 하는 논문이네요.
코드가 공개 안되어 있는데 이정도는 원복할 수 있을 것 같습니다.
CVPR format이던데 2023 CVPR에 accept 되어 코드와 더 자세한 설명이 담긴 supple도 공개가 되었으면 좋겠습니다.
리뷰 마치도록 하겠습니다.
안녕하세요 좋은 리뷰 감사합니다.
항상 고민하시던 부분이 최신 연구로 등장한다는 점이 놀랍네요.
혹시 table 4의 가장 마지막 비교에서 Baseline_I3D는 RGB만 사용한 것 아닌가요?
I3D 표시와 성능 수치 상 RGB feature만 사용한 것 같은데 리뷰에 RGB+flow라 적어주신 것이 혼동되어 질문 드립니다.
감사합니다.
안녕하세요 임근택 연구원님 리뷰 잘 읽었습니다.
간단한데 성능이 좋다니 눈여겨볼만한 방법론인것 같습니다. 꼭 TAL이 아니라 다른 TASK에도 적용할법한 아이디어고요.
제가 이해했을 때는 SoLa는 feature refinement module의 역할을 수행하는 것으로 이해했습니다. 기존의 TAL 방법론들의 TAL-head에는 이런 SoLa와 같은 refinement를 수행하는 모듈이 없나요?
추가적으로 SoLa는 TAL-head와 별개로 학습을 하는것으로 보이는데요. self-similarity를 이용한 Loss를 TAL-head에 포함시켜서 학습시킬 경우에도 따로 학습한 SoLa와 비슷한 효과를 얻을 수 있을까요?
안녕하세요 좋은 리뷰 감사합니다.
SoLa는 classification 으로 학습된 encoder가 결국은 localization 정보를 내제하고 있다는 가정하에 작동하는 것인가요? 혹은 SoLa가 해당 class의 다양한 표현력을 배워서 이를 더해주는것인가요? 어느 방향이든 흥미롭습니다. 혹시 이런 방식의 feature enhancement 예시를 더 아시나요?
감사합니다