안녕하세요. 오늘은 video representation에 대한 논문을 가져왔습니다. 논문 이름이 참 자극적이죠? Arxiv이긴 하지만, Facebook AI 사람들이 저자에 많이 포함되어 있어 믿고 읽었습니다.
Introduction
우리가 흔히 생각했을 때, video에서 temporal 정보가 중요하다는 이야기를 많이 합니다. 근데, CSL에서는 과연 이 정보가 중요할까라는 질문과 그에 대한 해답이 논문의 주 내용입니다. (사실 ‘Can’이 아니라 ‘How’에 더 가깝긴 합니다.)
우선 Self-supervised 분야에서 다양한 pretext task를 정의해서 문제를 해결하는 방식이 꽤 효율적이었습니다. 하지만 하위 분야였던 Contrastive self-supervised learning (CSL)은 downstream task에서 더 좋은 일반화 성능을 보여서 더 주목을 받고있다고 합니다.
CSL에 대한 설명은 이정도로 하고, 많은 연구원 분들도 이제 아시겠지만 이미지와 비디오의 가장 큰 차이점은 temporal dimension(시간적인 정보가 있냐 없냐)의 존재 유무입니다. 이미지도 물론 3D가 있지만, 비디오 관점에서는 2D가 이미지고 3D는 비디오가 되죠.
그래서 많은 CSL 연구들은 비디오의 temporal 정보를 활용하는 pretext task(Pretext task는 self-supervised 연구에서 GT가 없으니, 학습 목표를 스스로 정의해서 학습하는 것이라고 보면 됩니다)를 정의해서 학습을 진행하고 있었지만, 정작 CSL에서 temporal 정보를 어떻게 활용할 것인지에 대한 논의는 진행되지 않았다고 합니다. 그래서 논문 저자들은 논문 제목과 동일한 질문 “Can temporal information help CSL?”이라는 질문을 던지고 해답을 찾아갑니다. 사실 질문이 더 많은데요 나열해보면 아래와 같습니다.
- Q1 : 기존 CSL 프레임워크에 temporal augmentation을 추가하는 것에만 의존할 수 있는가?
- Q2 : video CSL을 위해 temporal information을 모델링하고 학습할 수 있는 더 적절한 방법이 있는가?
- Q3 : 서로 다른 비디오 task끼리의 근본적인 관계가 있는가? 다중 비디오 task가 CSL을 어떻게 돕는가?
각각의 질문에 대한 답변을 해보자면… 먼저 첫번째로 VideoCSL에 적용해볼 수 있는 augmentation의 종류를 생각해볼 수 있습니다. 크게 3가지 (spatial augmentation, temporally consistent spatial augmentation, temporal augmentation)가 있는데요. 실험적인 결과를 통해 앞선 두가지는 성능 향상에 도움이 된다는 사실을 발견했지만, temporal augmentation을 그냥 적용하는 경우에는 제한적인 성능 향상만을 관찰할 수 있었다고 합니다. 이 말은 단순한 temporal transformation은 video CSL에 적절하지 않다는 것을 의미하고, 따라서 논문에서는 학습 도중 모델이 temporal relation을 파악할 수 있게 temporal transformation에 대해서 발견한 관찰 내용을 공유합니다.
두번째 질문에 대해서는 Temporal-aware Contrastive self-supervised learning(TaCo)를 제안합니다. TaCo가 기존의 CSL 방법론들과 가장 큰 차이점을 보이는 것은 각 task마다 추가되는 task head 입니다. 이러한 task head가 각각의 video task와 서로 다른 transformation이 적용된 video에 대응하여, 비디오에 대한 공통적인 지식을 학습합니다.
마지막 질문에 대해서는 조합에 대한 이야기입니다. 특정 pretext task는 특정 temporal augmentation의 조합과 학습 했을 경우 성능이 더 좋았다고 합니다. 그래서 하나의 pretext-task가 아니라 dual-task 관점에서 학습을 진행했을 때 보다 더 좋은 성능을 보였다고 합니다.
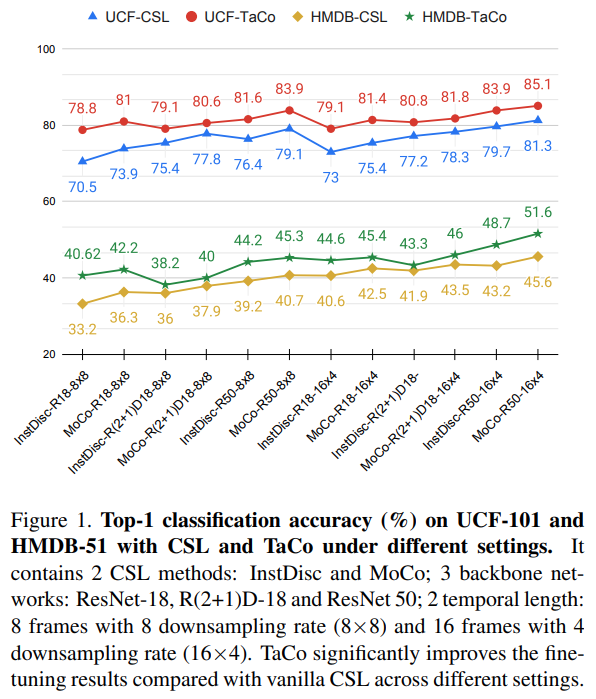
그래서 결론적으로 [그림 1]에서 보는 것과 같이 UCF와 HMDB 데이터셋에서 기존의 방법론 대비 좋은 성능을 보이는 것을 볼 수 있습니다. 이러한 결과와 분석들을 가지고 temporal information이 CSL에서 정말 도움이 된다는 것으로 결론을 내리고, 이러한 결론에서 가장 중요한 것은 temporal augmentation으로부터 추가적인 가이던스를 주는 것이 중요하다는 것으로 결론을 내립니다. 그래서 contribution을 정리해보면…
- Temporal 정보를 효율적으로 통합하는 CSL framework (TaCo) 제안
- 유연한 설계로 TaCo는 다양한 백본, CSL, temporal transformation을 적용할 수 있음
- TaCo를 기반으로 한 다양한 실험 결과 (CSL에서 Temporal information의 영향)
- 기존 work 대비 확실한 성능 개선
Methodology
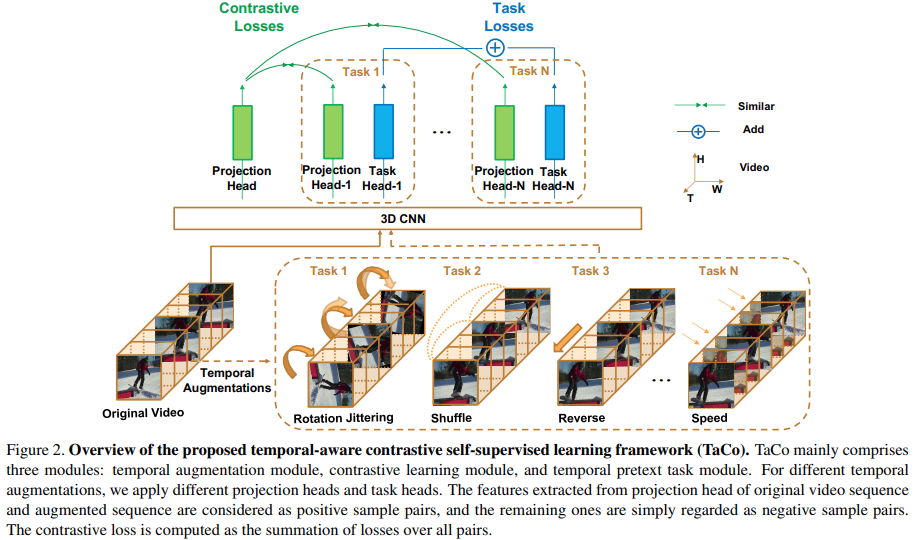
방법론은 [그림 2]에서 확인할 수 있습니다. TaCo는 3가지 모듈(Temporal augmentation module, Contrastive learning module, Temporal pretext task module)로 구성되어 있습니다. 먼저 원본 비디오가 주어졌을 때, 각각의 Task에 맞추어 temporal transformation을 적용한 augmented video set을 생성합니다. 원본 비디오로는 backbone + projection head로 feature를 추출하고, augmented 비디오에는 추가적으로 backbone + Task head를 적용해서 feature를 추출합니다. Projection head는 contrastive learning을 할 때 사용하고, Task head는 pretext task를 풀기 위해 사용하는 구조입니다. 단, 여기서 Pretext task를 여러개 한번에 학습할 수 있다는 점도 눈여겨 볼 부분입니다.
Temporal Augmentation Module
Temporal augmentation에 대한 분석 내용은 뒤에서 다루고, 정말 어떻게 적용했는지만 설명하는 섹션입니다. 비디오 셋 D = \{V_1, ..., V_K\}, K = |D|가 주어졌을 때, V_i \in \mathbb{R}^{T\times H\times W\times 3}와 같이 3차원 feature를 추출하게 됩니다. 이때 temporal augmentation set \tau = \{T_1, T_2,...,T_N\}, N=|\tau|와 같이 정의되고, 이걸 적용한 augmented video set \{V_i^{T_1},V_i^{T_2},...V_i^{T_N}\}은 이렇게 정의됩니다. 마지막으로 해당 논문에서 사용하는 augmentation의 종류는 rotation jittering, shuffle, speed와 reverse가 있습니다. (자세한 설명은 뒤에 또 등장)
Contrastive Learning Module
이 모듈은 우리가 이미 잘 알고 있는 contrastive learning을 수행하는 모듈입니다. base encoder f(\cdot)이 있을 때, average pooling layer(프레임 단위로 혹은 클립 단위로 feature를 뽑았다면 video-level feature를 만들기 위해 사용)를 적용했을 때 output은 h_V = f(V)라고 부릅니다.
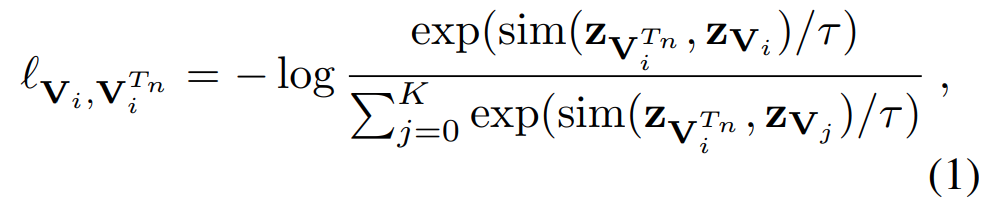
Contrastive Learning은 projection head의 output을 이용하여 학습이 수행됩니다. 이 projection head의 output을 z_V = g(h_V)와 같이 정의합니다. 이때 대표적인 contrastive loss 중 하나인 InfoNCE Loss를 [수식 1]과 같이 적용할 수 있습니다.
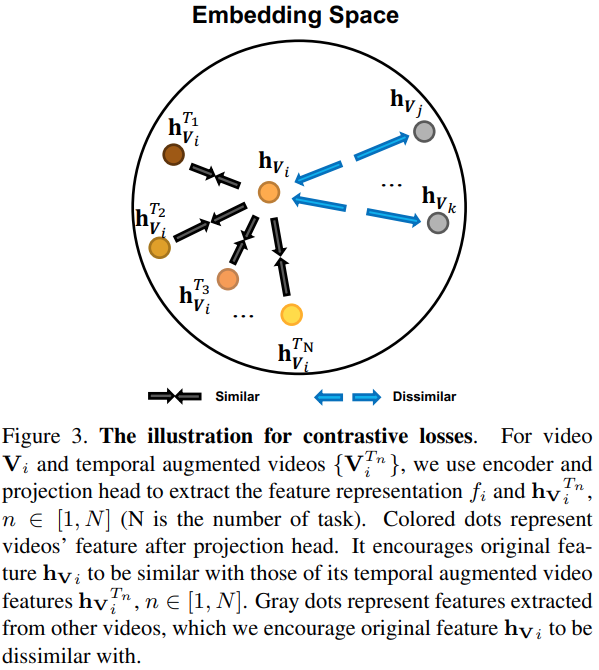
목표하는 학습에 대한 개략적인 그림은 [그림 3]을 통해 확인할 수 있습니다. 여기서 Positive는 notation을 잘 보면 알겠지만 같은 비디오인데 서로 다른 augmentation이 적용된 경우이고, negative는 나 자신을 제외한 나머지 모두 인데, 여기서 negative들은 전부 augmentation이 적용 안된 경우입니다. 문제는 그림만 그렇게 그려져 있는건지… [수식 1]을 보면 positive는 augmented와 원본 비디오 끼리의 페어의 유사도로 계산하고, negative도 augmented와 또다른 원본 비디오의 유사도로 계산합니다. 코드가 없어서 이 부분이 확실하지는 않네요.
Temporal Pretext Task Module
이 모듈은 CSL에서 정의한 pretext task를 풀기 위해 task head를 사용합니다. ([그림 2] 참고) 각 task에 따라 Loss가 정의되는 거라서… 사실 이 부분은 특별하게 설명하게 없네요. 다만 보통 classification이라서 t(h_V^{T_n})으로 softmax layer를 태우는 것으로 표현한다고는 합니다.
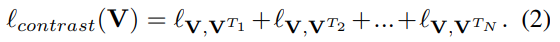
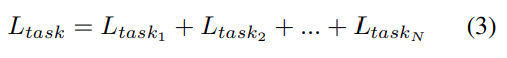
그리고 Contrastive Learning Module이든 Temporal Pretext Task Module에서도 페어가 여러개, task가 여러개이기 때문에 이렇게 모두 더해서 최종 Loss로 사용합니다.
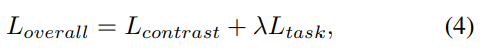
Final loss는 더하고, balancing용 \lambda만 추가적으로 사용합니다.
Experiments
Self-supervised Pretraining
백본은 SlowFast에서 Slow path를 차용해서 사용합니다. 이렇게 사용하면 2D인데, 여기서는 3D로 사용하기 위해서 2D→3D conv로 변경해서 사용하는 것 같습니다. 학습은 Kinetics 400에서 학습하고, 평가는 UCF-101 / HMDB-51에서 평가합니다. 특이한점은 따로 명시된 내용이 없으면 입력은 연속적으로 추출된 8프레임만을 하나의 클립으로 하여 사용합니다. Kinetics-400에서 비디오의 길이가 10초에 25프레임쯤 되서 전체 프레임이 250 프레임 정도인 것을 감안하면 되게 적게 쓰는 편입니다.
Temporal Pretext Tasks
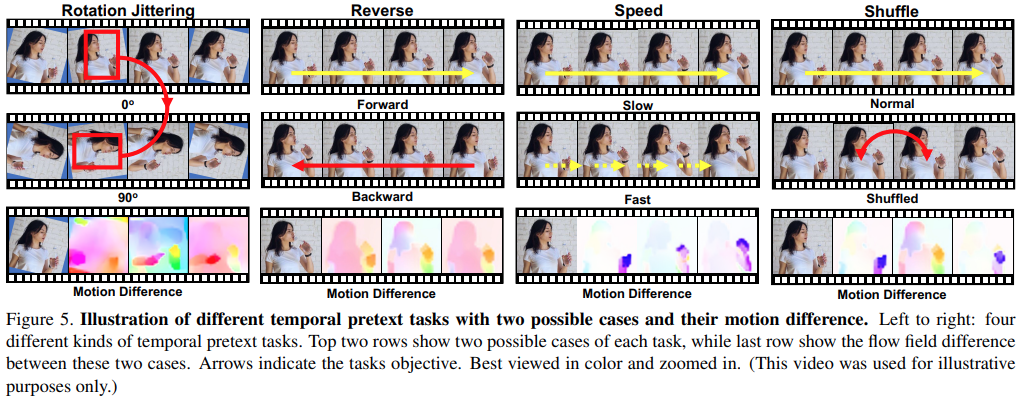
Temporal Augmentation Module 섹션에서 설명했던 각종 augmentation을 이용하는 pretext task에 대한 설명을 하는 섹션인데요. CSL에서 가장 중요한 것이 이 pretext task입니다. 여러가지 Pretext task가 있겠지만 여기서 선정한 Task들은 비디오에서 성능 향상에 의미가 있었던 것들을 적용했다고 합니다. Task에 해당하는 시각화 결과는 [그림 5]에 있으니 비교하면서 보시면 이해가 쉽습니다.
- Rotation Jittering Task
2D 이미지와는 다르게, temporal한 관계를 고려해서 이미지의 비틀림(회전) 정도를 인식하는 Task입니다. 기존의 2D에서 하던 방식과 다른 점은 temporal dimension에 대한 정보를 인식할 수 있게 합니다. 회전은 4가지 각도(0,90,180,270)도의 규격화된 비틈 정도를 가지는데요. 변환함에 있어서 단순하게 특정 각도로 회전하는 것이 아니라 3% 정도의 랜덤성을 가지고 회전을 수행합니다.
- Temporal Reverse Task
비디오가 현재 정방향 재생중인지 거꾸로 재생중인지를 파악하는 Task입니다. Temporal direction에 대한 정보를 학습하기 위해 사용합니다.
- Temporal Shuffle Task
t개의 비디오 프레임이 입력으로 들어왔을 때, 3t/2개의 프레임을 섞고, 어떤 프레임이 섞였는지를 예측하는 Task입니다.
- Temporal Speed Task
비디오의 sample rate를 변경해서 서로 다른 속도로 재생되는 비디오를 생성하고, 어떤 속도(sample rate)로 재생되는지 예측하는 Task입니다.
이렇게 4가지의 pretext task를 이용해서 학습을 수행합니다. 그리고 모델들에 대해 구현한 방식에 대한 설명도 있는데, 실험적인 부분이라 리뷰에서는 생략했습니다.
Supervised Classification
위의 파트까지가 Kinetics-400을 이용하여 Self-supervised learning으로 학습하는 방법이고, 여기서부터는 UCF/HMDB로 finetuning하는 과정에 대한 설명인데… 사실 특별한건 없고 학습할 때 지도학습으로 파인튜닝을 수행해준다는 점만 기억하면 될 것 같습니다.
Discussion
이제 본격적인 실험 단계로 넘어가겠습니다.
Can Temporal Augmentations help video CSL?
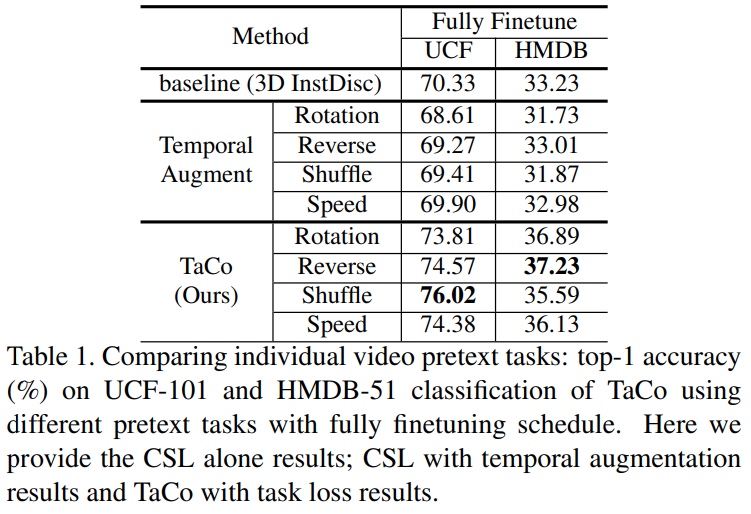
[표 1]에서 비교군으로 사용한 방법론은 PIRL이라고 이미지 기반의 CSL 방법론이니 감안하고 보시면 좋을 것 같습니다. 베이스라인 대비 성능이 떨어지는 것에 비해, 제안한 방법론(TaCo)는 성능이 오른 것을 볼 수 있습니다. 이것은 단순하게 temporal augmentation을 적용할 경우에는 성능 향상이 전혀 없다는 뜻을 의미합니다. 즉, temporal information이 CSL에 도움 되느냐에 대한 질문의 답은 되는 것은 맞지만, 비디오라는 특성을 고려해야한다는 결론이 나옵니다.
Temporal pretext task as self-supervision?
두번째로 실험에서 볼 부분은 결론적으로 성능이 향상되었다는 부분입니다. 제안된 Pretext-task와 각각의 Task-loss가 temporal 정보를 통합하는데 도움이 되어 보다 좋은 video representation을 만들 수 있었다는 결론에 도달할 수 있습니다.
또한, 데이터셋마다 성능이 오르는 pretext task도 다른 것을 확인할 수 있습니다. UCF에서는 Shuffle이, HMDB에서는 Reverse가 가장 좋은 성능을 보였는데요. 사실 temporal information을 학습하기 위해서 몇가지 pretext-task를 더 실험했었는데 일부는 성능이 오르지 않았다고 하네요. 따라서 일반적으로 비디오에 적용해볼 수 있는 모든 pretext task가 CSL에 도움이 되는 것도 아니라고 합니다.
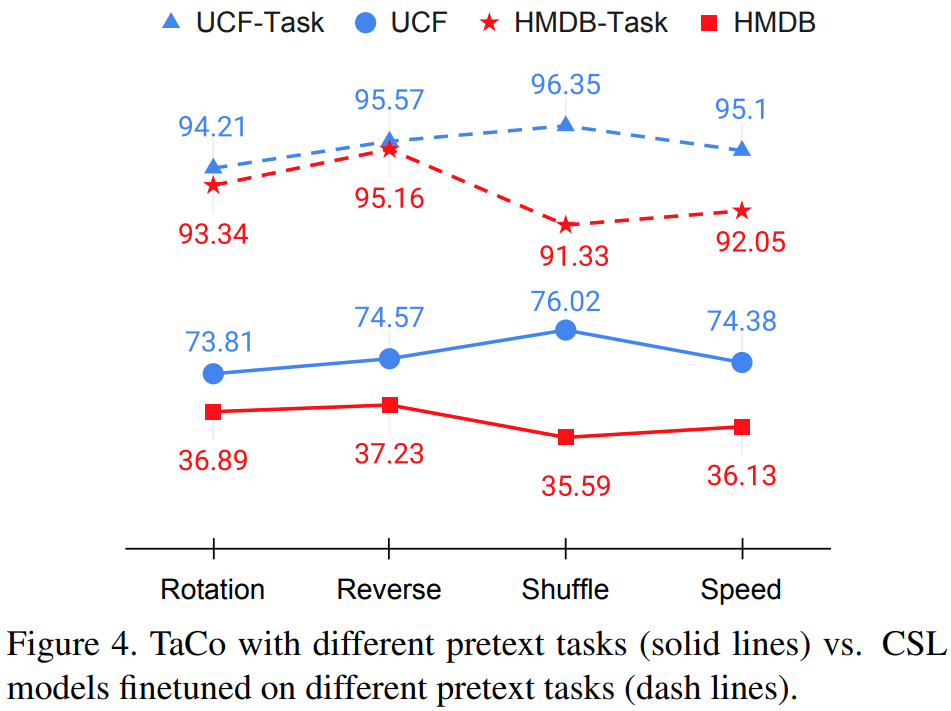
그럼 어떤 pretext task가 비디오 CSL에 적합한지는 어떻게 파악할 수 있을까요? 이걸 위해서 contrastive learning으로만 학습한 성능과 pretext task로 finetuning을 수행한 성능을 비교해서 상관 관계를 분석합니다. 그 결과가 [그림 4]에 있는데요. 점선의 경우에는 3D InstDisc로 pretraining 된 모델을 finetuning한 결과이고, 실선은 TaCo 자체 성능입니다.
논문의 분석에 따르면, finetuning 성능이 더 좋으면 contrastive learning도 그만큼 더 잘 학습이 된다는 것을 보여주려고 이 실험 결과를 가져왔습니다. 예를 들어서 UCF finetuning에서 Shuffle이 성능이 제일 좋았다면 CSL에서도 Suffle pretext task로 학습하는게 좋은 성능을 보이니까 이 결과를 바탕으로 CSL에서 사용할 pretext task를 선정할 수 있다는 건데요. 이 성능을 보려면 GT가 있다는 전제가 있어야 하는데, 이 성능을 바탕으로 CSL에서 사용할 pretext task를 선정하는게, CSL의 목적상 적합한 분석인지 의문은 듭니다.
Multiple pretext tasks?
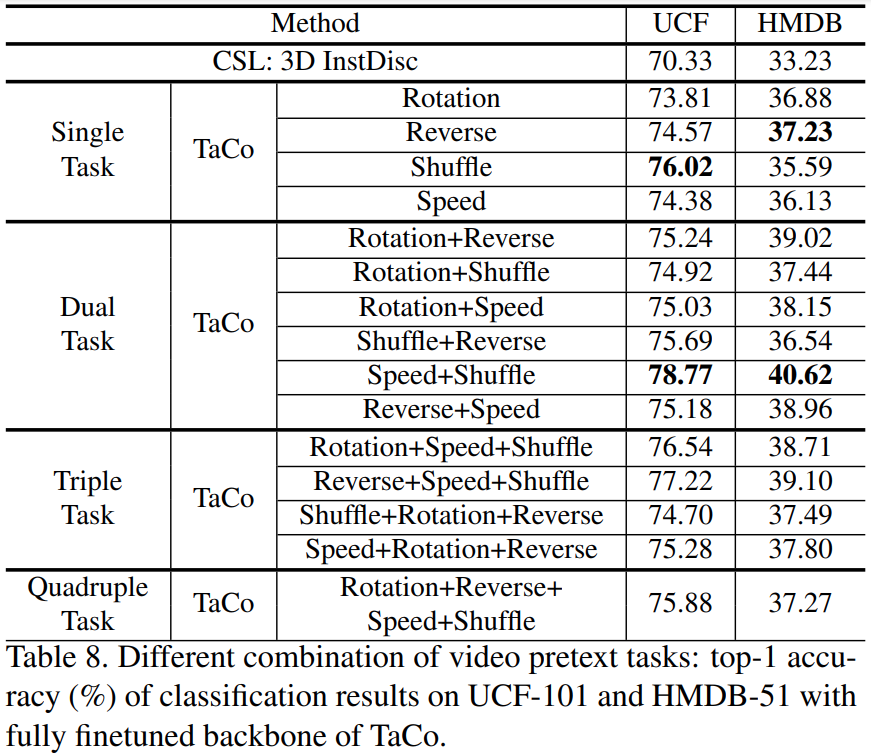
논문 그림에서 여러개의 pretext task를 한번에 학습하는 것을 볼 수 있었는데요. 이 섹션은 해당 내용에 대한 실험입니다. 최대 4개까지의 pretext task를 조합해서 실험을 수행해본 결과, speed+shuffle의 조합이 가장 성능이 좋았다고 합니다. 결과를 잘 보면 single task에서는 Reverse와 Shuffle이 각각 성능이 제일 좋았던 것을 고려하면 약간 의외인 부분인데요. 논문 저자들이 판단했을 때는 shuffle과 speed는 local한 정보(모션의 변화)에 집중하는 반면에, rotation jittering과 reverse는 보다 global한 정보에 집중하여 이러한 경향성을 보인다고 합니다. 비디오 자체가 Action이기 때문에 미세한 움직임의 변화가 성능에 더 좋은 영향을 보이는 경향성이 있었던 것 같습니다.
Experimental Results
Generalization
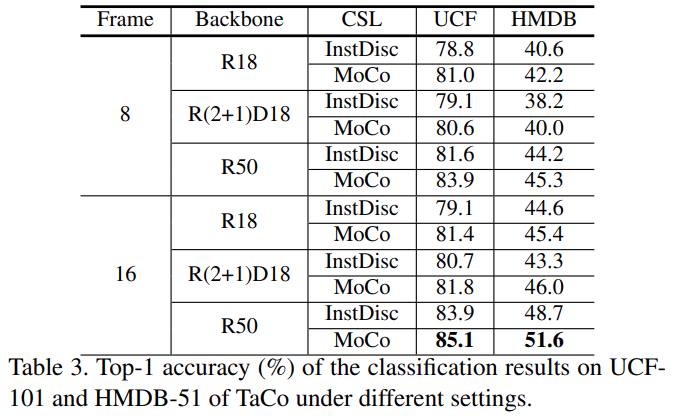
Contrastive 학습의 비교군으로 두가지 방법론을 가져왔는데요. MoCo는 리뷰에서 다뤄졌던 적이 있는 방법론이라 다들 아실 것 같은데, 추가적으로 InstDisc라는 방법론도 사용합니다. 논문에서 깊은 설명을 다루지는 않아서… InfoNCE를 기반으로 하는 학습 방법론이라고만 생각하면 될 것 같습니다. Contrastive learning을 각각의 방법론으로 대체하고, 프레임을 조금 더 많이 쓰고 백본도 바꿔보는 실험을 수행했을 때의 결과는 [표 3]에서 확인할 수 있습니다. 논문 저자가 주장하는게 일반적으로 적용해볼 수 있는 방법이라는 것을 강조하는데요. 이를 입증하듯이 베이스라인으로 설정했던 성능 보다는 훨씬 높은 성능을 보이는 것을 확인할 수 있습니다.
특이한점은 진짜 3D 백본보다 2D 백본이 더 높은 성능을 보이는 것인데요. 분석이 있으면 좋을 것 같은데, 없어서 좀 아쉽네요. 개인적으로 생각해보면 3D 백본이 Temporal한 정보를 더 많이 볼것이라고 생각하지만, implicit/explicit한 학습 방법에 따라 차이가 있을 수 있어서 이런 결과가 나왔다고 생각이 됩니다.
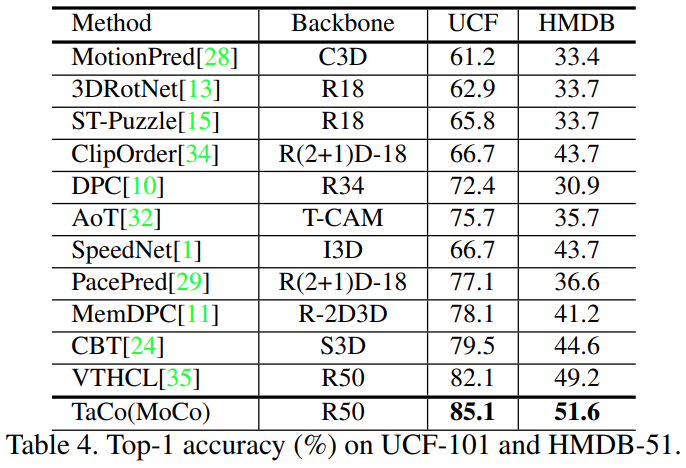
Comparison with other self-supervised methods
다른 방법론들과의 비교는 [표 4]로 확인할 수 있습니다. MoCo를 적용했던 결과가 성능이 제일 좋았어서 이를 기준으로 비교를 해보면 기존 SOTA 대비 더 높은 성능을 보이는 것을 확인할 수 있습니다.
Ablation Study
Pre-training using task losses only
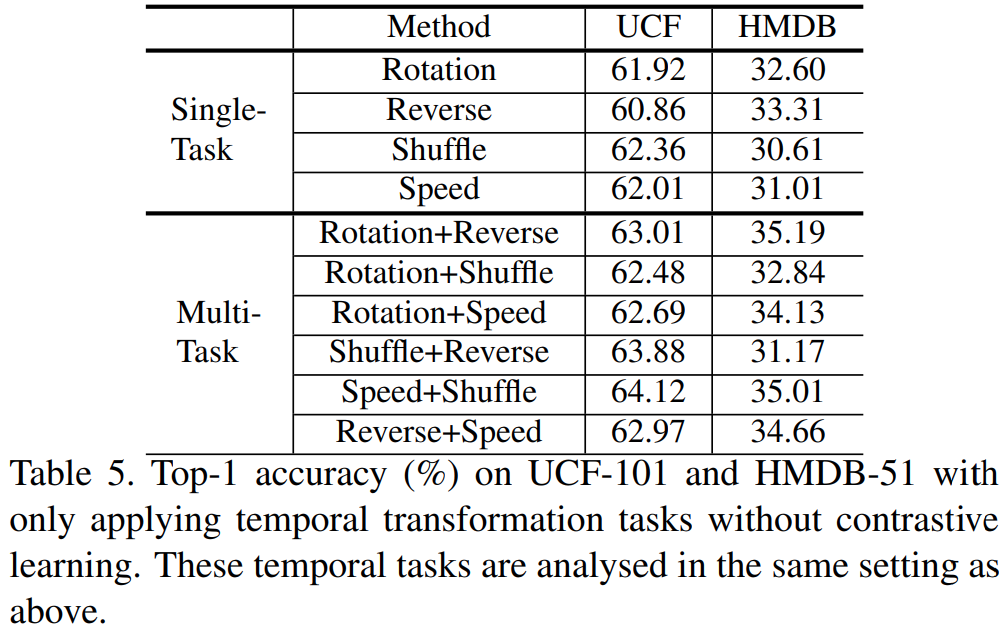
그럼 contrastive learning은 여기서 어떤 역할을 수행할까요? Contrastive loss없이 학습한 결과를 [표 5]를 통해 확인할 수 있습니다. 전반적으로 성능이 크게 하락한 것을 볼 수 있는데요. 이러한 실험을 통해 pretext task와 contrastive loss 모두 CSL에서 중요함을 보입니다.
The importance of \lambda
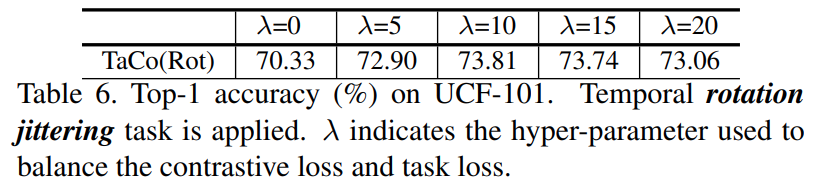
또한 여러개의 pretext task를 가지고 학습할 때, balancing용 \lambda의 값에 따라서도 성능이 약간 달라졌는데요. 일반적으로 10일때가 가장 좋았다고 합니다.
Last layer finetuning
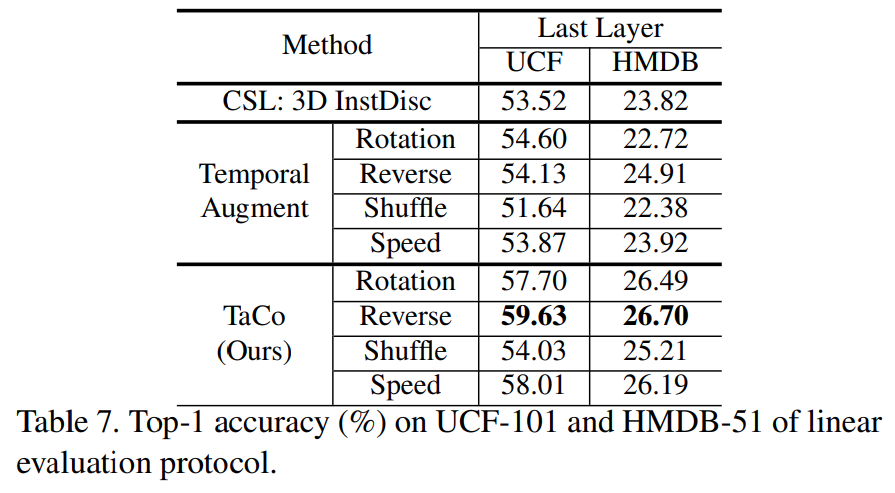
[표 7]은 이제 마지막 layer만 finetuning하는 linear evaluation 방식에 따라서 평가를 수행한 결과인데요. 여기서는 [표 1]과는 다른 결과가 나오는 것을 확인할 수 있습니다. 그래도 TaCo가 경향성만 다르지 더 성능이 좋은 것을 통해 확실한 성능 개선을 이루는 방법임을 증명합니다.
Conclusion
아카이브 논문이긴 하지만… Facebook 소속 연구진이 많이 포함되어 있어 읽어봤는데요. 잘못 표기된 부분이 논문에 있고 살짝 설명이 부족하다던가 하는 부분이 있어서 살짝 아쉽네요. 성능도 이정도면 준수하고, 좀더 다듬었으면 어딘가엔 들어갔을 것 같은데 왜 아카이브일까… 최소한 표 순서좀 맞춰줬으면 보기 좋았을 것 같습니다. 심하면 Supple 표 까지 갔다와야해서… 아무튼 논문 제목에 걸맞는 분석들이 있어서 괜찮았던 것 같습니다. 요즘 이런 분석 논문들 위주로 골라 읽고있는데 확실히 당연하다고 생각한 것들을 증명하는게 중요하다는 생각이 드네요.
후에 temporal augmentation에 관하여 실험을 돌려야할 때 참고할만한 내용이 있는 것 같습니다.
다만 실험에 사용되는 비디오의 구성이 모두 Trimmed로 구성이 되어있는데 ActivityNet과 같은 복잡한 Untrimmed Video에서도 비슷한 경향성을 나타낼 수 있을지 궁금하네요. 이와 관련하여 future work나 limitation 혹은 supple에 내용이 있을까요?
시각화 결과를 보시면 아시겠지만, 결국은 “Motion difference”에 집중하는 방식이라 ActivityNet 정도의 Untrimmed라면 작동은 할 것 같다고 생각은 합니다. 저도 사실 궁금했던 부분인데 CSL 연구들 전반적인 성능이 낮아서 아직 UCF/HMDB에서만 평가를 진행하더라고요. 그래서 관련된 실험은 없습니다. 아마 연구가 더 되야지 진행될 것 같습니다.
안녕하세요 좋은리뷰감사합니다.
기존 연구에서 temporal augmentation이 제한적인 성능향상을 보인것에 대해 적절하게 augmentation을 적용하는 방법등을 분석한 논문으로 이해하였습니다. 모든 temporal augmentaion이 단독적용시 실질적 성능 향상이 없다는 점이 놀랍네요.
질문이 하나 있습니다 백본으로는 slowfast의 slow path의 일부를 이용하였다고 하는데, slowfast를 통째로 사용하는것이 아닌 일부 모듈만 사용하는것이 일반적인지 궁금하네요
감사합니다.
사실 실험 베이스라인을 왜 slow pathway만 썻을까 의문이 드는것으로 봐서 일반적이지는 않은 것 같습니다. 제가 생각했을 때는 그만큼 적게 샘플링된 프레임만으로도 모델이 잘 작동한다는 점을 강조하고 싶어서 채용한 것 같습니다.