이번 주 X-Review에서 제가 소개해드릴 논문은 올 해 WACV에 게재되었고 제목은 ‘Temporal Feature Enhancement Dilated Convolution Network for Weakly-supervised Temporal Action Localization’입니다.

마찬가지로 비디오에서 Weakly-supervised Temporal Action Localization task를 수행하는 방법론입니다. 직전에 리뷰하였던 논문에 비해 무엇보다 문제 정의가 명확하였고, 그것을 해결하고자 적용한 방법론도 굉장히 간단하며 높은 성능을 달성했기에 쉽게쉽게 읽을 수 있었던 논문이었습니다.
Task에 관하여도 익숙하실테니 바로 논문 내용으로 들어가보겠습니다.
1. Introduction

저자는 위 그림 1을 통해 이전 연구의 문제점을 우선 지적합니다. 2020년도 AAAI에 게재된 BaS-Net이라는 방법론의 정성적 결과인데요, 등장한 이후 많은 시간이 흘렀지만 아직도 많은 연구의 베이스라인 역할을 하고 있는 모습입니다.
GT와 BaS-Net이 예측한 구간의 차이를 보시면 빨간 점선 구간에서는 실제 action 구간을 너무 좁거나 넓게 예측하고 있고, 파란 점선 구간에서는 실제 action이 아님에도 꽤 길게 잘못된 예측을 하고 있는 모습을 볼 수 있습니다. 사실 베이스라인으로 삼기에는 오래된 논문이라는 생각이 들지만 저자는 근본적으로 action 구간의 부정확한 예측을 문제 삼고 있고, 이것이 왜 발생하는지와 어떻게 해결하고자 했는지에 대해 들어보겠습니다.
먼저 위와 같은 문제는 왜 발생하는 것일까요? 저자는 ‘insufficient use of temporal information’이 문제의 핵심 토픽이라고 이야기합니다. 하지만 WTAL task에서는 action의 시간 구간이 아닌 video-level label만을 가지고 학습하기에 핵심 토픽이 너무 막연하다고 받아들이실 수 있는데, 이 주장을 뒷받침할만한 두 가지 근거를 같이 알아보겠습니다.
- 하나의 snippet feature가 다루는 span에 비해 실제 찾아야하는 action은 상대적으로 너무 길다.
- Trimmed video의 분류 task로 사전학습된 backbone으로부터 얻는 video feature는 sub-optimal하다.
이를 설명드리기 위해 WTAL에서의 feature 추출 방식을 설명드리겠습니다. 전체 비디오 프레임 중 16개의 프레임씩 겹치지 않게 샘플링하여 한 snippet으로 만들어줍니다. 이 때 비디오마다 모두 길이가 다르기 때문에 snippet의 개수는 각 비디오 길이에 비례하여 얻을 수 있게 됩니다. 이후 데이터셋과 방법론에 따라 고정된 크기인 T개의 snippet을 샘플링하여 feature를 추출해주는데, 예시로 BaS-Net에서 THUMOS14 데이터셋은 T=750으로 지정해줍니다. 만약 한 비디오의 snippet 개수가 750보다 적다면 중복되는 snippet들이 시간 순서대로 750개를 채우게 되는 것입니다.
이러한 상황 속에서 첫 번째 문제를 다시 살펴보겠습니다. 만약 비디오가 30fps라면, 하나의 snippet은 16프레임으로 이루어졌으므로 약 0.5초 이상의 범위를 표현하게 됩니다. THUMOS14 testing 데이터셋의 경우 평균 action 길이가 4.49초에 해당한다고 합니다. 하나의 action instance에 대한 full-dynamics를 관찰하기엔 한 snippet feature가 담고 있는 정보가 너무나도 적다는 주장인 것입니다.
두 번째 문제는 이전 연구에서도 여러 번 언급되었는데, 바로 학습에 사용하는 snippet feature가 trimmed video를 대상으로 한 action recognition(classification) task로 사전학습한 backbone 모델(e.g. I3D)로부터 추출된다는 점입니다. 위와 같이 사전학습한 모델은 아무래도 비디오에서 background를 본 적이 없고, 분류 문제를 해결하는데에 맞추어져 있을 것입니다. 하지만 WTAL은 background가 포함된 untrimmed video에서 분류가 아닌 구간의 localization을 수행해야 하기 때문에 sub-optimal하다고 표현할 수 있는 것입니다.
이 때 기존 연구에서 계속 사용하던 snippet 추출 방식을 변화하는대신, 이미 추출된 feature로부터 dilated convolution 연산을 거치며 뒷단에서 얻는 feature의 receptive field를 다양하게 늘려주는 방식과 WTAL에 적합하지 않은 feature를 enhance 해줄 수 있는 방법을 찾아 잘 적용해준다면 두 문제를 해결할 수 있을 것입니다.
논문의 contribution을 정리한 뒤 자세한 방법론에 대해 알아보겠습니다.
- 각기 다른 dilation rate를 가진 convolution 연산을 반복적으로 적용하여 다양한 receptive field로부터 attention score를 얻을 수 있는 Temporal Feature Enhancement Dilated Convolution Module (TFE-DC)을 제안하였습니다.
- RGB, Optical flow 간 일관성을 유지하면서 기존의 sub-optimal 하였던 feature를 WTAL task에 맞게 re-calibrate 해주는 Modality Enhacement Module을 제안하였습니다.
2. Method
저자가 제안하는 전체 framework를 TFE-DCN이라 칭하고, input 단계부터 시작하여 어떤 특징을 가지고 task를 수행하는지 하나씩 살펴보겠습니다.
2.1 Problem Formulation
총 N개의 untrimmed video \{v_{n}\}_{n=1}^{N}이 존재한다면 각 비디오의 video-level label \{y_{n}\}_{n=1}^{N}도 마찬가지로 주어질 것입니다. 목표는 (t_{s}, t_{e}, c, \varphi{})를 얻는 것으로, 각각은 시작 지점, 끝 지점, 예측한 action 클래스, confidence score에 해당합니다.
2.2 Method Overview
2.2.1 Feature Extractor
앞서 Introduction에서 드린 설명과 동일하게 feature를 추출합니다. 각 비디오에서 16프레임 단위로 겹치지 않게 snippet을 추출한 뒤 고정된 T개 만큼 샘플링합니다. 이후 사전학습된 backbone network I3D로부터 RGB feature X_{n}^{RGB} = \{x_{n, i}^{RGB}\}_{i=1}^{T}와 flow feature X_{n}^{Flow} = \{x_{n, i}^{Flow}\}_{i=1}^{T}를 추출합니다. x_{n, i}^{RGB}, x_{n, i}^{Flow} \in{} \mathbb{R}^{D}는 i번째 snippet feature가 D차원임을 의미합니다.
2.2.2 Structure Overview
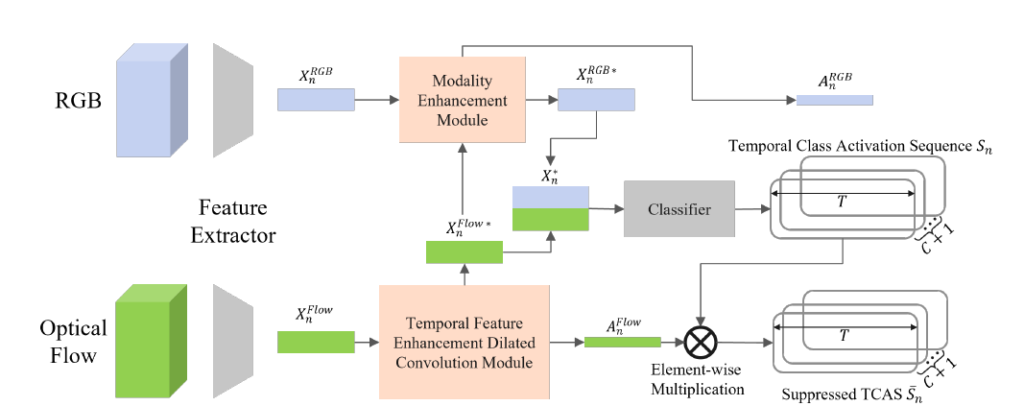
저자가 제안하는 TFE-DCN의 전체 구조는 그림 2에서 확인할 수 있는데, 전체 구조가 그리 복잡하지는 않습니다. 다만 중간에 분홍색 박스로 표현되어 있는 MEM과 TFE-DC 모듈이 각각 어떻게 동작하는지 살펴보는 것이 중요할 것 같네요.
2.3 Temporal Feature Enhancement Dilated Convolution Module
TFE-DC 모듈의 목적은 multi-layer dilated convolution network를 활용하여 receptive field를 확대함으로써 snippet 간 long-range dependencies를 증가시키는 것입니다. 이를 통해 모델이 시간적인 정보를 더 많이 얻어갈 수 있게 되고, 하나의 snippet feature 정보가 담당하는 구간보다 실제 action 구간이 훨씬 넓다는 점을 감안했을 때 localization을 수행하는데에도 큰 도움이 될 것입니다.
이에 그치지 않고 TFE-DC 모듈은 flow feature도 enhance 해줍니다. 이유는 앞서 설명드렸듯 조금 더 WTAL에 최적화된 feature를 얻기 위함인데요, 방법론의 구조 상 TFE-DC에서 flow feature를 먼저 개선해주고 개선된 flow feature를 이용해 RGB feature를 개선해주게 됩니다. 각 stream이 담고 있는 정보의 특성이 다른 것은 맞지만 왜 이렇게 flow feature를 주도적으로 개선해주는 구조를 취했는지에 대한 이유가 나와있지 않았습니다.
개인적으로는 저자가 dilated convolution을 사용하는 이유도 temporal 정보를 폭넓게 얻고자 함인데, 두 stream 중 flow가 좀 더 시간적 정보를 모델링하는데 주도적 역할을 하기 때문에 위와 같은 구조로 설계하지 않았나 생각됩니다. 또한 이후 MEM에서 얻게 되는 RGB feature 기반의 attention score A_{n}^{RGB}는 CAS 생성에 직접적으로 관여하지 않고 loss 계산에만 사용되는 것으로 보아 저자는 action localization에서 RGB feature를 flow feature의 보조 역할 정도로 다루고 있음을 알 수 있었고, 왜 위와 같은 구조를 선택했는지 간접적으로 생각해볼 수 있었습니다.
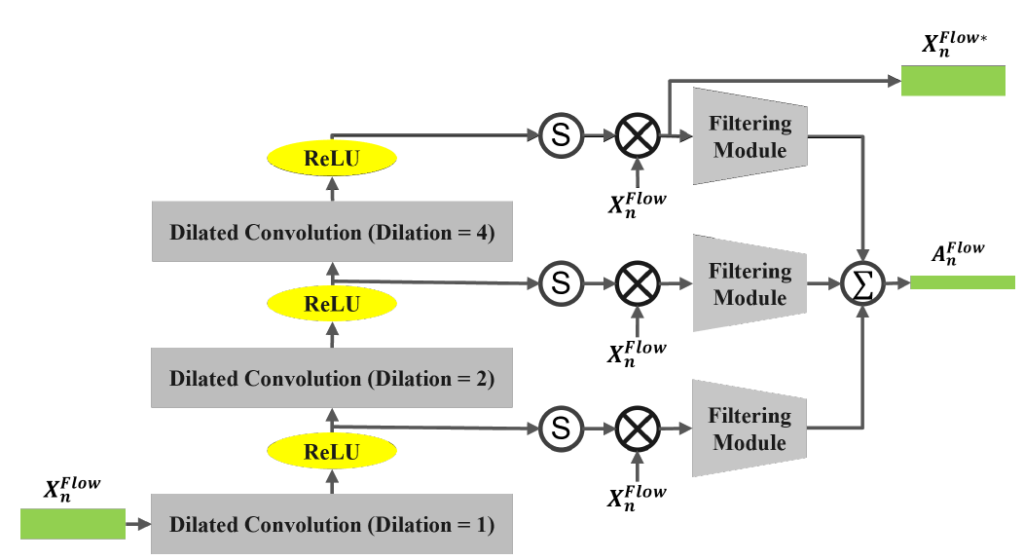
본격적으로 TFE-DC Module의 작동 과정에 대해 알아보겠습니다. 앞서 I3D로부터 얻은 flow feature X_{n}^{Flow}를 입력으로 받아 enhanced flow feature X_{n}^{Flow*}와 다양한 dilation rate를 적용한 뒤 종합하여 얻어낸 attention score A_{n}^{Flow}를 출력해줍니다.
총 K개의 dilated conv를 거치는데, 그림 3에서 K=3으로 지정되어 있는 것을 알 수 있습니다. 입력이 dilation value를 1로 갖는 첫 번째 convolution layer f_{dilated, 1}과 ReLU를 거칩니다. 이렇게 얻은 중간 feature를 M_{n, 1}이라 하면, k번째 feature는 아래와 같이 표현할 수 있습니다. f_{dilated, k}의 dilation value는 2^{k-1}입니다. (그림에서 1, 2, 4)
- M_{n, k} = ReLU(f_{dilated, k}(M_{n, k-1}, 2^{k-1}))
- k=1, \cdots{}, K
- M_{n, 0} = X_{n}^{Flow}
M_{n, k} \in{} \mathbb{R}^{D \times{} T}는 k번째 convolution layer의 출력이고 각 층을 거칠 때마다 receptive field는 2^{k+1}개 snippet으로 증가합니다.
최종적으로, 마지막 K번째 층의 출력 M_{n, K}에 sigmoid 연산을 거친 후 입력 flow feature에 element-wise 곱을 적용해주어 enhance된 flow feature X_{n}^{Flow*}를 얻습니다. 식으로 보면 아래와 같습니다.
- X_{n}^{Flow*} = \sigma{}(M_{n, K}) \otimes{} X_{n}^{Flow}
이제 TFE-DC Module의 두 가지 출력 중 하나는 얻었고 나머지 하나인 A_{n}^{Flow}를 얻는 과정을 보겠습니다. 각 convolution 층을 거칠 때마다 얻은 M_{n, k}에 sigmoid 연산을 적용해준 뒤, 원래 flow feature X_{n}^{Flow}에 element-wise 곱을 적용해줍니다. 그러면 총 K개의 feature를 얻을 수 있고 각각에 filtering module f_{att, k}을 적용해주면 A_{n, k}^{Flow} \in{} \mathbb{R}^{T}를 얻을 수 있습니다. 이 때 f_{att, k}는 3개의 1D Conv와 sigmoid에 해당합니다. 이후 각 A_{n, k}의 weighted average가 최종 attention score A_{n}^{Flow}가 됩니다.
위 과정을 수식으로 보면 아래와 같습니다.
- A_{n, k}^{Flow} = f_{att, k}(\sigma{}(M_{n, k}) \otimes{} X_{n}^{Flow}), k=1, \cdots{}, K
- A_{n}^{Flow} = \Sigma{}_{k=1}^{K}a_{k}A_{n, k}^{Flow}
- a_{k}는 합이 1이 되는 K개의 양수 값
최종적으로 enhanced feature X_{n}^{Flow*}는 다양하고 넓어진 receptive field를 고려한 flow feature에 해당하고, A_{n}^{Flow}도 마찬가지로 다양한 receptive field를 고려하여 action의 활성 정도를 표현하는 attention score에 해당합니다.
2.4 Modality Enhancement Module
앞서 TFE-DC 모듈을 통해 flow feature는 상대적으로 넓은 범위의 temporal 정보를 담게 되었고 이로써 조금 더 WTAL에 맞는 feature가 되었다고 볼 수 있습니다. 그렇다면 이렇게 향상된 flow feature를 통해 RGB feature도 enhance 시켜주는 과정이 필요할 것입니다. 아무리 저자가 flow feature를 중시하더라도 결국 task를 수행하기 위한 T-CAS를 만들때 각 stream이 담고 있는 정보를 모두 고려한다면 더욱 좋은 성능을 보인다는 점은 기존 연구에서부터 계속 증명되었던 사실이기 때문입니다.
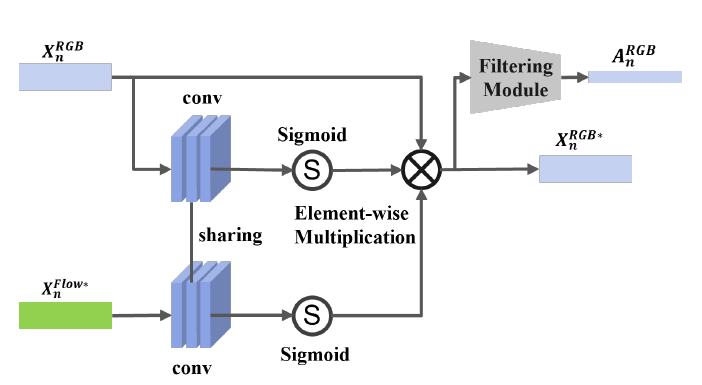
그림 4를 통해 Modality Enhancement Module의 작동 방식을 알 수 있습니다. 입력으로 앞서 TFE-DC에서 얻은 X_{n}^{Flow*}와 기존 RGB feature X_{n}^{RGB}를 넣어주면 마찬가지로 enhanced RGB feature X_{n}^{RGB*}와 A_{n}^{RGB}를 얻는 것이 목표입니다.
구조가 그리 복잡하지 않지만 주목할만한 점은 두 입력에 대해 가중치를 공유하는 convolution layer를 사용한다는 것입니다. 일단 가중치를 공유하는 목적 자체는 두 stream의 feature가 유사해지도록 만들어주는 것은 맞습니다. RGB, Flow 두 stream이 같은 frame에 대해 각각 spatial, temporal 정보를 나타내어 특성이 좀 다르다는 점은 사실이지만 feature-level에서는 두 stream이 서로의 정보를 고려하며 feature 분포가 유사해지도록 학습하는 consistency loss가 기존 연구에 존재하였습니다. 그러한 방식도 효과적이지만 애초에 같은 convolution layer를 거친다면 더욱 명시적으로 해당 효과를 누릴 수 있지 않을까 싶어 위와 같이 설계한 것이 아닌가 생각해보았습니다.
그럼 이러한 배경을 바탕으로 MEM의 작동 방식을 수식으로 알아보겠습니다.
- X_{n}^{RGB*} = X_{n}^{RGB} \otimes{} \sigma{}(f_{conv}(X_{n}^{RGB})) \otimes{} \sigma(f_{conv}(X_{n}^{Flow*}))
기존 RGB feature X_{n}^{RGB}와 enhanced flow feature X_{n}^{Flow*}에 같은 convolution layer \sigma{}(f_{conv()})를 거쳐 기존 feature와 동일한 shape의 attention mask를 만들어줍니다. 이렇게 얻은 2개의 attention mask를 원래 RGB feature X_{n}^{RGB}에 곱하여 enhance 된 RGB feature X_{n}^{RGB*}를 얻는 방식으로 작동하는 것입니다.
Enhanced feature를 얻었다면 이를 바탕으로 attention score도 추출해야 하는데요, 단순히 X_{n}^{RGB*}에 3개의 1D Conv와 sigmoid로 이루어진 filtering module f_{att}를 거쳐 A_{n}^{RGB}를 얻을 수 있습니다. 앞서 말씀 드렸지만, 실제로 background가 suppress 된 T-CAS를 생성할 때 A_{n}^{RGB}는 사용되지 않고 A_{n}^{FLOW}만 사용된다는 점을 참고하시면 좋을 것 같습니다.
Classification and Localization
이제 주요 모듈에 대한 설명은 마쳤고 action localization과 classification은 어떻게 수행하는지 설명드리겠습니다.
저희가 지금까지 얻은 것들은, enhanced feature X_{n}^{RGB*}, X_{n}^{Flow*}, 그리고 attention score A_{n}^{RGB}, A_{n}^{Flow}로 정리할 수 있습니다.
Classification과 localization을 수행하기 위해서는 지금까지 얻은 것들을 잘 조합하여 T-CAS를 만들어내야 합니다. 먼저 X_{n}^{RGB*}와 X_{n}^{Flow*} 채널 축으로 concat하여 최종적으로 n번째 비디오를 표현하는 feature X_{n}^{*} \in{} \mathbb{R}^{2D \times{} T}을 얻을 수 있습니다.
이후 X_{n}을 classifier f_{cls}에 태워 TCAS S_{n} \in{} \mathbb{R}^{(C+1) \times{} T}을 만들어냅니다.
- S_{n} = f_{cls}(X_{n}^{*})
이후 앞서 얻은 A_{n}^{Flow}를 활용해 background suppressed T-CAS \bar{S}_{n} \in{} \mathbb{R}^{(C+1) \times{} T}도 만들어줍니다. BaS-Net의 흐름과 비슷하며 많은 연구가 위와 같은 방식을 사용하고 있는 추세입니다.
- \bar{S}_{n} = A_{n}^{Flow} \otimes{} S_{n}
Action 분류 시에는 S_{n}에서 top-k pooling 연산을 통해 video-level class를 예측하고, localization을 위해 A_{n}^{Flow}의 점수로 background에 해당하는 구간은 먼저 버려줍니다. 그렇게 action만 남은 구간 중 다시 S_{n}에서 연속되는 구간을 proposal로 만들어내고 proposal 구간에 대해 \bar{S}_{n}에서 OIC score를 계산한 뒤 NMS를 적용하여 최종 proposal을 만들어내는 것입니다.
2.5 Loss Functions
TFE-DCN의 학습에 사용되는 loss는 총 5가지이고, 하나하나 간단한 loss들이기 때문에 빠르게 살펴보고 실험 부분으로 넘어가겠습니다.
- \mathcal{L} = \mathcal{L}_{base} + \mathcal{L}_{supp} + \mathcal{L}_{norm} + \mathcal{L}_{guide} + \mathcal{L}_{ml}
\mathcal{L}_{base}, \mathcal{L}_{supp}은 앞서 얻은 T-CAS S_{n}, \bar{S}_{n}에서 video-level label을 예측한 뒤 저희가 가지고 있는 video-level label로 학습하는 CE Loss입니다. \mathcal{L}_{base}에서의 S_{n}은 background suppress 되어 있지 않으므로 GT값에 (background=1)로 들어가있고, 반대로 \mathcal{L}_{supp}에서의 \bar{S}_{n}은 suppress 되어 있으므로 (background=0)으로 지정되어 학습한다는 것이 둘의 차이점입니다.
다음으로 \mathcal{L}_{norm}은 아래 수식과 같이 각 attention score가 더욱 sparse 해지도록 학습하게 해줍니다.
- \mathcal{L}_{norm} = \frac{1}{2}(||A_{n}^{Flow}||_{1}+||A_{n}^{RGB}||_{1})
\mathcal{L}_{guide}도 마찬가지로 이전 논문에서 제안된 loss로, 각 attention score와 S_{n}에서 background class score 값 중 한 쪽이 커지면 다른 한쪽은 작아지도록 학습합니다. 다시 말해 하나의 snippet에 대해 action score와 background score가 동시에 커지거나 동시에 작아지는 것을 방지해줍니다.
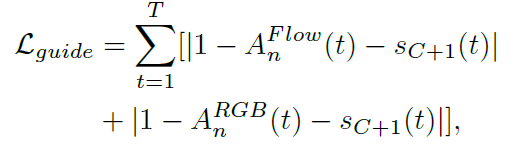
마지막으로 \mathcal{L}_{ml}은 mutual learning loss로 각 attention score가 서로의 pseudo label이 되어주며 유사해지도록 학습하는 loss입니다.
- \mathcal{L}_{ml} = MSE(A^{RGB}, \phi{}(A^{FLOW})) + MSE(A^{FLOW}, \phi{}(A^{RGB}))
3. Experiments
4.1 Comparison with SOTA Methods
THUMOS14 데이터셋과 ActivityNet v1.3 데이터셋에 대한 벤치마크 성능을 먼저 살펴보겠습니다.
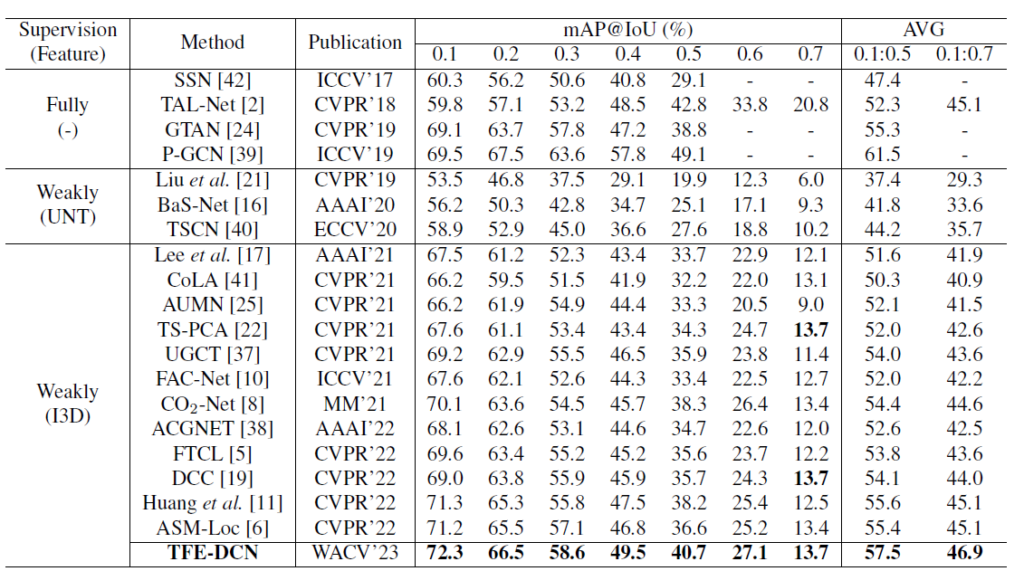
기존 방법론 대비 TFE-DCN이 전체 평균 mAP에서 최소 1.8% 이상의 큰 성능 향상을 보여주었습니다. 낮은 IoU threshold 기준으로는 거의 19년도 쯤의 Fully-supervised 방법론과도 유사한 성능을 내는 것을 알 수 있습니다. 직전 리뷰에서 다룬 TMM’23 논문보다도 더욱 높은 성능을 보여주고 있습니다.
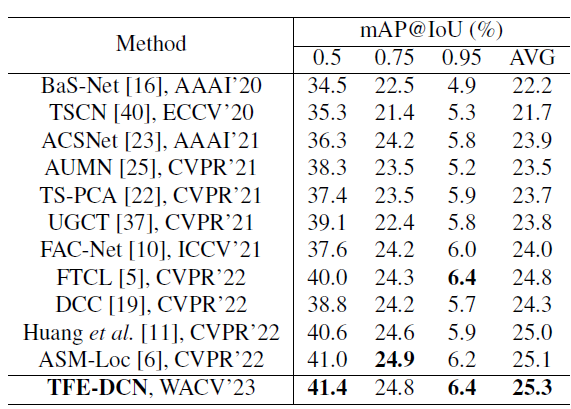
ActivityNet v1.3 데이터셋에 대한 벤치마크 성능입니다. 데이터셋 자체가 더 어렵기도 하고 높은 IoU threshold만을 기준으로 삼다보니 상대적으로 성능 향상 폭이 THUMOS 데이터셋보다 적음을 감안했을 때, 0.2% 정도면 유의미한 성능 향상으로 생각됩니다.
4.2 Ablation Study
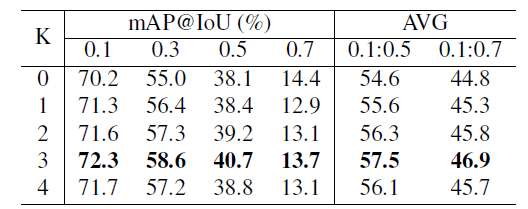
Dilated convolution의 개수 K를 몇으로 지정할 것인지에 대한 ablation입니다. K=3인 경우 가장 성능이 높았다고 합니다. TFE-DC 모듈은 결국 receptive field를 늘려주기 위해 설계된 것이므로 TFE-DC의 최종 output feature가 어느 정도 범위의 receptive field를 담당하는지 살펴보는 것도 유의미 할 것입니다.
앞서 말씀드린 대로 THUMOS 데이터셋의 평균 action 길이는 4.49초입니다. 학습 시 snippet sampling 방식과 K=3인 경우의 최종 feature의 temporal receptive field를 고려하면 약 5.76초에 해당하는데, K가 3보다 작거나 큰 경우 temporal receptive field도 마찬가지로 작거나 커지게 되므로 K=3인 경우에서 가장 좋은 성능을 얻었다는 것이 설명 가능하게 됩니다.
논문에 정성적 결과와 여러 세부사항들이 포함되어 있으니 궁금하신 분들은 참고하시기 바랍니다.
이상으로 리뷰 마치겠습니다.
안녕하세요.
좋은 리뷰 감사합니다.
논문의 주된 내용과는 어쩌면 거리가 있을 수도 있지만, mAP 성능이 기존 모델에 비하여 0.2 상승하였다고 하는데, 0.2라 하면 어찌보면 그렇게 크지 않은 성능 향상이라는 느낌도 드는 것 같습니다.
아마 task나 데이터셋마다 기준이 다를 것 같다는 생각이 드는데, 혹시 논문을 분석하거나 작성할 때, 이 기준을 어떻게 잡을 수 있을지 궁굼합니다!
mAP 기준으로 2%정도면 굉장히 큰 성능향상이라고 생각합니다. 말씀해주신 0.2가 100 중 0.2라면 그리 큰 성능 향상이 아니라고 생각되기도 하는데, 사실 그보다 중요한 것은 저자가 정의한 문제점과 그 문제를 어떻게 해결했는지라고 생각합니다.
또한 성능은 기존과 유사하지만 메모리 효율성이나 빠른 추론 속도를 가진다면 또 그것으로도 유의미할 수 있다고 생각합니다.
정리하자면 저자가 정의한 문제점과 그것을 해결하고자 하는 방식이 유의미하며 그 방식으로 문제가 잘 해결되었다면 좋은 논문이라고 생각하고, 성능까지 많이 오른다면 더욱 완벽한 논문이 되는 것이라고 개인적으로 생각합니다.