제가 이번에 리뷰 할 논문은 저번에 리뷰한 TransVLAD 논문이 활용한 L2LTR 방법론 입니다. 이 논문은 공중에서 촬영된 이미지와 땅에서 촬영된 두 이미지간의 매칭을 통해 위치를 찾는 geo-localization task 입니다.
Abstract
Geo-localization task는 땅에서 촬영된 이미지와 위치 정보가 태그된 공중 이미지를 매칭하여, 위치를 찾는 것입니다. 두 이미지의 차이가 심하기 때문에 어려운 태스크로, 이 논문은 L2LTR이라는 새로운 transformer 방법론을 제안하였다고 합니다. 우선 Transformer에 self-attention의 속성을 이용하여 global dependency를 모델링하여 cross-view(땅/공중에서 촬영된 영상)의 모호성을 줄였다고 합니다. 또한, positional encoding을 통해 땅/공중 이미지 사이의 기하학적 형태를 이해하고 일치시키는 것을 도왔다고 합니다. 이 논문에서 제안한 L2LTR은 기존의 SOTA들이 strong한 기하학적 지식을 이용하였다는 것과는 다르게, 학습의 목표를 통해 유연하게 기하학적 정보를 학습하여 실제 시나리오에 더욱 실용적이도록 만들었다고 합니다. 일반적인 transformer는 각 레이어의 이미지 패치 내에서 독립적으로 작용하여 다른 레이어들과의 상관 관계를 간과한다는 문제가 있었고, 이 논문에서는 학습된 표현력의 퀄리티를 높이기 위해 인접한 레이어의 global dependncy를 모델링하는 self-cross attention을 제안하였습니다. 제안한 self-cross attention을 통해 학습이 더욱 안정화되었고, 일반화 성능이 향상되었다고 합니다.
Introduction
서론은, cross-veiw geo-localization이 필요하지만, 땅에서 촬영된 이미지와 공중에서 촬영된 이미지간의 차이에 의해 어려운 task임을 이야기하며, 기존의 방법론들이 CNN을 이용한 NetVLAD 방식을 사용하는데, 이는 local한 정보만을 고려한다는 점에서 인간의 시각 시스템(가려지거나, 움직이는 물체가 있을 경우, local한 정보만을 고려하는 것이 아니라 global한 정보를 활용하여 장면을 이해한다.)과 차이가 있다고 합니다. transformer를 사용하는 이유에 대한 내용으로 이는 TransVLAD의 논문에서 이야기한 내용과 동일합니다.(참고로 이 논문이 먼저이고, TransVLAD논문이 이 논문의 서론을 이용한 것으로 보입니다.) 또한, 기존 방법론들이 기하학적 사전 지식을 활용하여 모호성을 줄이고자 하였으나 이는 사전에 정의된 정보에 너무 의존하거나, 제한된 가정을 만들어낸다는 점에서 문제가 있다고 주장합니다. 따라서 기존의 방법론들이 이용한 강한 정의는 활용성 측면에서 제한적이므로 본 논문에서는 유연하게 위치 정보를 알고 표현을 할 수 있는 방법을 고안하였다고 합니다.
이렇듯 해당 논문은 global한 상황 예측에 잘 작동하고, cross-view geo-localization에서 시각적 모호성을 줄일 수 있으며, positional encoding을 통해 위치 정보를 고려한 유연한 representation을 학습할 수 있도록 layer-to-layer Transformer(L2LTR)를 제안합니다.
이 논문의 contribution을 정리하면
- L2LTR은 cross-view geo-localization에서 Transformer를 이용한 첫번째 모델로, global한 맥락을 고려하여 효과적으로 시각적 모호성을 줄일 수 있고, positional encoding을 통해기하학적 정보를 주어 두 이미지가 기하학적으로 일치하지 않아 생기는 모호성을 줄일 수 있도록 함. 이는 기하학적 가정을 이용하는 기존의 SOTA 방법론들 보다 더 실용적임.
- self-cross attention 매커니즘을 제안하여 cross-layer 패치들간의 상호작용을 통해 효과적인 정보의 흐름을 보장. 이는 L2LTR의 표현력과 일반화 능력을 향상시킴.
- 확장 실험을 통해 여러 geo-localization task에서 L2LTR의 성능이 일관적으로 향상됨을 보이고, SOTA를 달성함.
Method
1. Problem Formulation and Objective
cross-view geo-localization은 땅에서 촬영된 쿼리 이미지와 위치정보가 태그된 공중 이미지를 매칭시키는 것으로, 이를 이전 연구들과 동일하게 식으로 정의하면 다음과 같습니다.
- 학습 데이터: D = \{ (g_1,a_1), ..., (g_N,a_N) \} (N개의 cross-view 이미지쌍, g는 땅에서 촬영된 이미지, a는 공중에서 촬영된 이미지를 의미)
- corss-view 이미지 쌍 (g_i,a_i) 에 대응되는 이미지 representation: (\mathbf{F}_i^g,\mathbf{F}_i^a)
- i^{th} 에 대한 weighted soft-margin triple loss(매칭쌍은 가까워지도록, 나머지는 멀어지도록 하기 위한 loss): L = log(1+e^{\alpha (d \mathbf{F}^g_i, \mathbf{F}^a_i) - d \mathbf{F}^g_i, \mathbf{F}^a_j) })
- 이때, i≠j이고, d(.,.)는 L2 distance, \alpha는 학습 속도 조절을 위한 하이퍼파라미터
2. Transformer for Cross-view Geo-localization
* Vision Transformer
기반이 되는 ViT에 대한 간단한 설명입니다. 이미지를 여러 패치로 분할한 뒤 linear projection된 임베딩 sequence \mathbf{x}∈\mathbb{R}^{N⨉D}(N: 패치 개수, D: 패치의 임베딩 크기)가 ViT의 입력으로 들어갑니다. L-layer Transformer 인코더에 들어가는 \mathbf{x}_0는 \mathbf{x}에 global representation \mathbf{x}_{global}∈\mathbb{R}^{D}를 붙이고 positional embedding \mathbf{x}_{pos}를 더하여 얻게 됩니다.(\mathbf{x}_0=[\mathbf{x}_{global};\mathbf{x}]+\mathbf{x}_{pos})
각 레이어는 Multihead Self-Attention(MSA)과 Feed Forward Networks(FFN), Layer Norm blocks(LN)로 구성되며, MSA는 여러 self-attention head와 linear projection block으로 이루어집니다. l 레이어의 입력으로 \mathbf{x}_{l-1}이 들어간다 했을 때 MSA는 아래와 같이 정의가 됩니다.
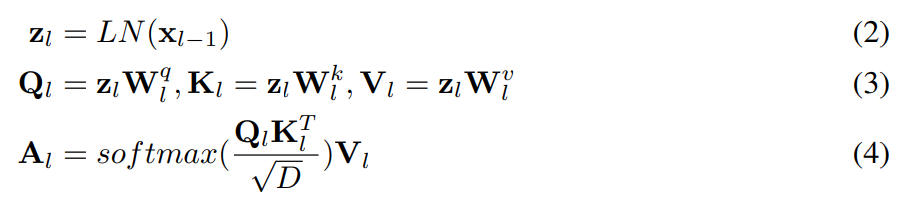
Domain-specific Transformer
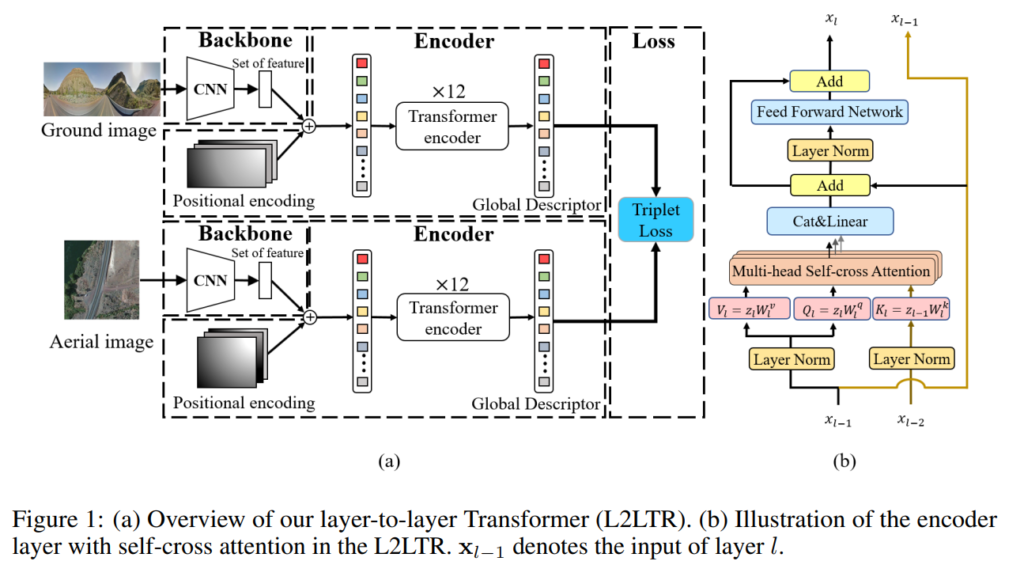
땅과 공중에서 촬영된 영상의 domain gap으로 인해 매칭이 어렵다는 문제를 해결하기 위해, 동일한 구조인 두개의 브랜치가 독립적으로 있는 domain-specific Siamese-like architecture를 이용하였다고 합니다. 두 브랜치는 땅과 공중에서 촬영된 이미지를 각각 표현하도록 학습되며 그림1의 (a)에 해당합니다. 그림을 보면 CNN(이 논문은 resnet을 이용)을 백본으로 이용하여 feature를 추출한 뒤, global한 상황을 모델링 하였다고 합니다. 이후 ViT를 적용합니다.
Learnable positional embedding
이 논문은 기하학적 규제를 주는 대신, 효과적이고 융통성 있는 방식으로 기하학적 정보를 주기 위해 학습 가능한 1D positional embedding를 이용합니다. positional embedding을 패치에 줌으로써, feature는 위치 정보를 포함하게 되며, 학습 과정에 위치에 대한 가정을 주지 않고 위치정보를 학습할 수 있다고 합니다. 이는 활용 측면에서 실용적(기하학적 가정이 없으므로 여러 시나리오에 적용 가능하다는 의미)이라 합니다.
3. Self-cross Attention
저자들은 기본적인 ViT는 각 레이어들이 독립적으로 attention map을 연산하지만, 이러한 독립적인 학습 방식은 모델의 표현 능력을 방해한다고 주장하며, 표현의 품질을 향상시키기 위해 인접한 레이어들이 상호작용하는 새로운 self-cross attention매카니즘을 제안합니다. L2LTR은 그림1의 (b)에 해당하며, l 레이어의 attention map이 \mathbf{x}_{l-1}뿐만 아니라 \mathbf{x}_{l-2}도 이용하며, 아래의 식과 같이 정의가 됩니다.
How self-cross attention affects feature learning.
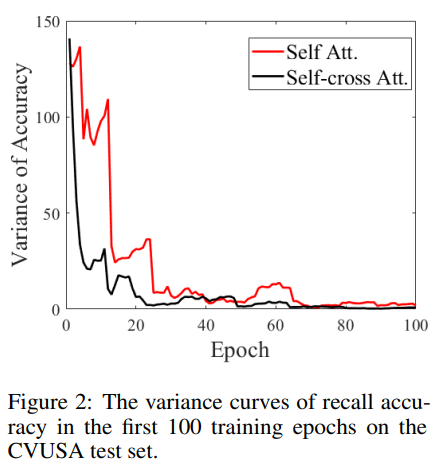
위의 그림2는 self-attention(ViT)과 self-cross attention(L2LTR)를 비교한 결과로, CVUSA 테스트 데이터(땅/공중에서 촬영한 이미지 쌍에 대한 데이터셋)에 대한 recall 정확도의 분산을 나타낸 것이라 합니다. 분산이 작을수록 리콜 정확도의 변동이 적고 학습이 안정적이라는 것을 의미한다고 합니다. 그림2를 통해 self-cross attention이 초반에는 조금 변동성이 있지만, self-attention에 비해 더욱 안정적으로 학습이 진행된다는 것을 알 수 있습니다.
Experiment
Dataset and Evaluation Protocol
널리 사용되는 밴치마크 CVUSA와 CVACT(CVACT_val &CVACT_test)를 이용하여 실험을 진행합니다.
- CVUSA dataset
- 35,532쌍의 학습 데이터와 8,884쌍의 테스트 데이터
- CVACT dataset
- 35,532쌍의 학습 데이터와 8,884쌍의 validation 데이터 (CVACT_val)
- 92,802쌍의 정확한 위치정보가 포함된 test 데이터(CVACT_test)
CVUSA test 셋과 CVACT_val은 정확하게 매칭되는 쌍이 positive 이며, CVACT_test는 거리가 5m 안에 있는 것이 positive라 합니다.
평가는 top-K에 대한 recall로 나타내며, r@1%는 테스트 데이터셋의 1%에 해당하는 이미지를 이용하여 recall 성능을 구한 것입니다.
Comparing L2LTR with SOTA models
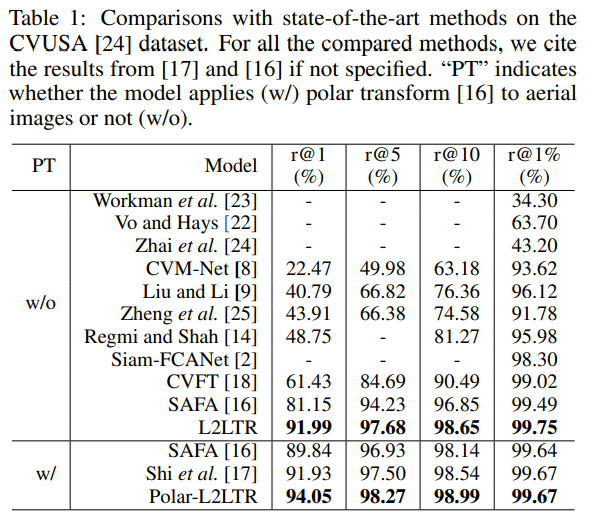
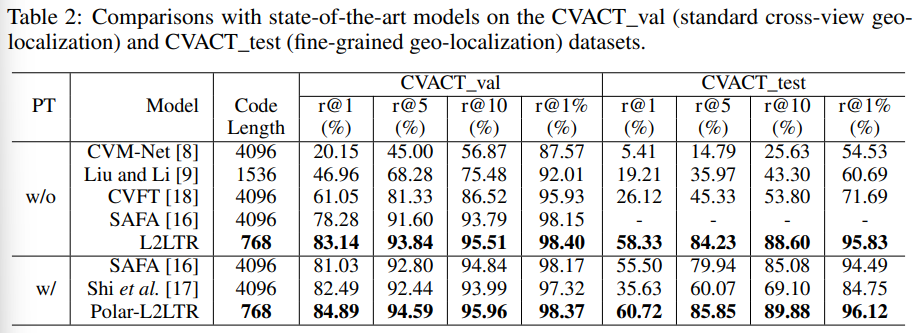
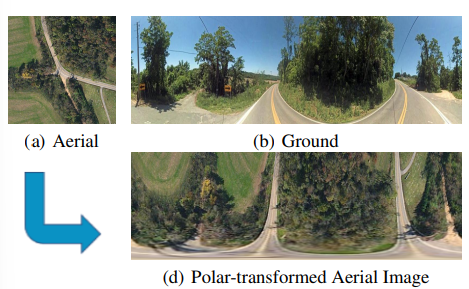
다른 SOTA 방법론들과의 성능 비교로, CNN에 의존하는 다른 방법론들과 비교했을 때 L2LTR이 전체적으로 가장 높은 정확도를 보였다. 이때 Polar는 데이터 전처리 알고리즘인 polar transform을 이용한 것으로, 아래의 그림처럼 공중에서 촬영된 영상을 ground영상처럼 왜곡(전처리)하는 것을 의미합니다.
Ablation Study
positional embedding과 self-cross attention의 효과를 확인하기 위해 ablation 연구를 진행하였다고 합니다.
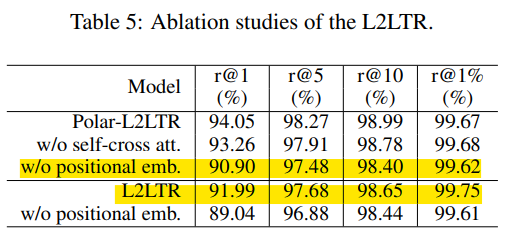
- Positional encoding
- positional embedding을 제거할 경우 top-1에 대한 성능이 크게 하락하는 것을 확인할 수 있습니다.
- (노란 형광팬)polar-L2LTR에 positional embedding을 적용하지 않은 결과와 L2LTR의 비교를 통해, polar transform을 positional embedding이 보완할 수 있다고 이야기합니다.
- Self-cross attention
- 표5를 통해 self-attention을 self-cross attention이 대채함으로써 성능이 향상되는 것을 확인할 수 있다.
실험 결과가 모든 지표에서 가장 좋은 성능을 나타낸 것이 인상적입니다.
좋은 논문 리뷰 감사합니다.
이미 TransVLAD를 이용한 방법론이 있었네요.
같은 저자인가요?
근데 해당 방법에서 크로스 모달리티를 위한 별다른 기법이 제안되지 않은 것 같단 생각이 드네요.
이승현 연구원의 생각은 어떠신가요?
해당 방법론은 TransVLAD가 활용한 방법론으로, 중복되는 저자는 없었습니다. 아무래도 TransVLAD가 L2LTR을 NetVLAD로 발전킨 것 같습니다.
해당 논문이 크로스 모달리티를 위해 새로운 것을 제안했다기보다, Transformer가 cross-view(여기서는 땅과 공중에서 촬영된 이미지)에 적합함을 이야기하며, positional embedding을 통해 기하학적 제약을 강하게 주지 않고도 기하학적인 정보를 학습할 수 있다는 것을 보인 것으로 보입니다. 실험이 Table5에 리포팅 되어있는 “Polar-L2LTR w/o positional emb.”와 “L2LTR” 의 결과 비교를 통해서도 확인할 수 있습니다.
안녕하세요 이승현 연구원님 좋은 리뷰 감사합니다.
근데 전에 발표하신 TransVLAD는 다른 방법론인가요? 지금 리뷰하시는 논문이 먼저고 TransVLAD가 서론을 비슷하게 가져간 것이라고 해서… 저는 TransVLAD가 2021년부터 빛을 보지 못한 채 게재되지 않고 있다 이번 WACV 에 게재된 것으로 이해했는데 그게 아닌가보네요. 둘이 다른 방법론이라면 차이점이 있나요?
우선 TransVLAD와 이번에 리뷰한 L2LTR은 서로 다른 논문으로, 2021년에 L2LTR이 발표되었고, 2023년 WACV에 TransVLAD가 발표된 것입니다. 두 방법론의 차이라면 L2LTR은 인접한 레이어를 연결하여 self-cross attention을 수행한 것이고, TransVLAD는 이러한 L2LTR의 self-cross attention 방법론을 이용하여 NetVLAD를 Transformer 형태로 적용한 것이라는 차이가 있습니다.
좋은 리뷰 감사합ㄴ디ㅏ.
저번 세미나에서 발표해주신 내용과 비슷해서 이해하는데 도움이 되었습니다.
간단한 질문 하나만 하자면 혹시 평가부분에서 recall@1%가 데이터셋의 1%에 해당하는 이미지를 이용하였다고 하셨는데 이때 이미지를 선택하는 기준이 있을까요? 랜덤인가요?
recall@1%는 랜덤하게 선택하는 것이 아닌, 쿼리 이미지에 대해 유사한 top-k개를 고를 때, test 데이터셋의 1%로, CVUSA를 예로든다면 약88개의 top-k이미지를 이용하는 것입니다.