Abstract
continual learning, incremental learning이라고 불리는 deep learning 학습 기법은 자연지능의 중요한 특징입니다. incremental learning은 시나리오에 따라 크게: task-incremental, domain-incremental, class-incremental learning으로 나눌 수 있는데요, 비슷해보이지만 세 시나리오는 각기 특징이 있다고 합니다. 본 논문은 MNIST와 CIFAR-100 데이터를 이용해 각 시나리오의 특징등을 소개합니다.
Keyword introduction
incremental learning(=continual learning):
증가, 계속을 의미하는 increment, continual 학습법은 연속성 있는 학습 프로세스를 구현하기 위한 기술입니다. 인간지능, 혹은 자연지능에서는 새로운 정보를 지속적으로 습득하는것이 자연스럽습니다. 그러나 딥러닝은 일반적으로 실증 환경이 학습한 데이터셋과 동일하다는 I.I.D(independent and identically distribution) 세팅을 가정하고 있습니다. 즉 각 학습이 연속적이지 않고 일시적인것이 일반적입니다. incremental learning은 이러한 머신러닝기법의 한계를 해결하기 위해 테스크가 추가되는 상황에서 연속적으로 학습하여 머신이 수행하는 테스크의 수를 늘리는것을 목적으로 하는 분야입니다. 앞선 세미나 등에서도 소개했듯이 이전 테스크의 데이터를 보관해놓는 리허설 접근법과 기학습된 모델의 파라미터를 보존하거나 새로운 데이터에 대한 너무 빠른 적합을 지양하는 규제 접근법이 해당 태스크를 위한 대표적인 해결책입니다.
Three incremental learning scenarios
앞서 제가 소개드린 방법론은 대부분 특정한 데이터셋을 분할하여 분류를 수행할 수 있는 클래스 갯수를 증분시키도록 학습하는 실험을 포함했는데요, 이는 class-incremental learning 에 속합니다. 사실은 이외에도 incremental learning은 크게 세가지 방식으로 적용할 수 있습니다.
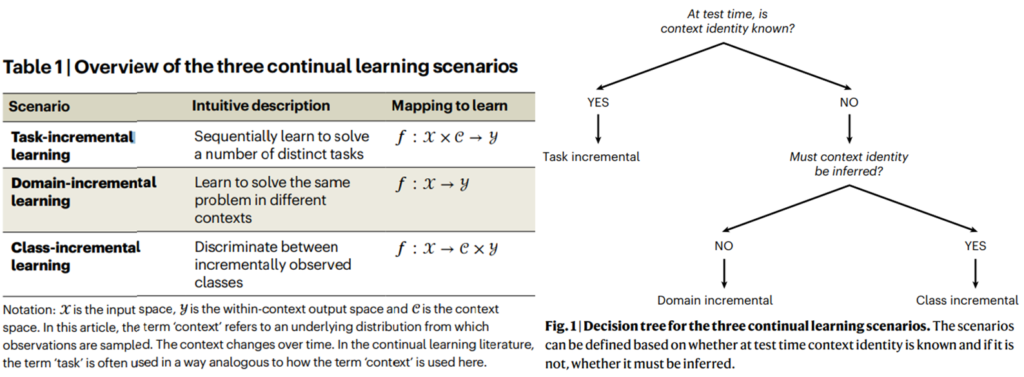
- Task-incremental learning
두 번째로 많이 접해보셨을 접근법입니다. 이는 수행하는 테스크가 증가하는 학습방식으로 학습 경험에 대한 구분이 가능합니다. 여기서 학습 경험을 episodes, contexts라 하며 active learning의 cycle과 유사한 개념으로 이해하시면 됩니다. - Domain-incremental learning
해당 방법론은 수행해야하는 context는 동일하나 데이터의 도메인이 변하는 경우입니다. 이해가 어렵다면 아래 MNIST 실험 세팅을 참고하시면 좋습니다. - Class-incremental learning
가장 많이 보셨을 접근법으로, 각 에피소드마다 수행할 수 있는 능력이 증가합니다. 분류문제에서 구분할 수 있는 클래스의 갯수가 증가하는것으로 이해하시면 됩니다.
Empirical comparison
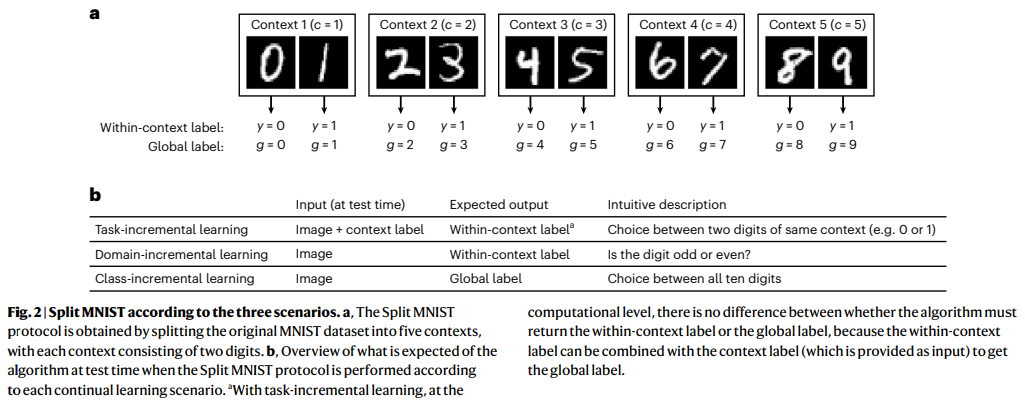
Fig2는 실험을 위한 MNIST 데이터의 세팅입니다. 먼저 Task-incremental learning은 0,1을 분류하는 과제, 2,3을 분류하는 과제, 4,5를 분류하는 과제가 추가되는 방식으로 incremental을 진행하게 됩니다. 그러나 class-incremental learning의 경우는 0,1을 분류, 0,1,2,3을 분류, 0,1,2,3,4,5를 분류 하는 방식으로 학습의 진행에 따라 구분할 수 있는 class의 갯수가 증가합니다. domain-incremental의 경우는 각 입력이 짝수인가 홀수인가? 를 구별한다는 문제는 동일하지만 데이터셋에서 짝수, 홀수를 대표하는 수의 도메인이 짝수0, 홀수1/짝수2, 홀수3 와 같은 방식으로 변경됩니다.
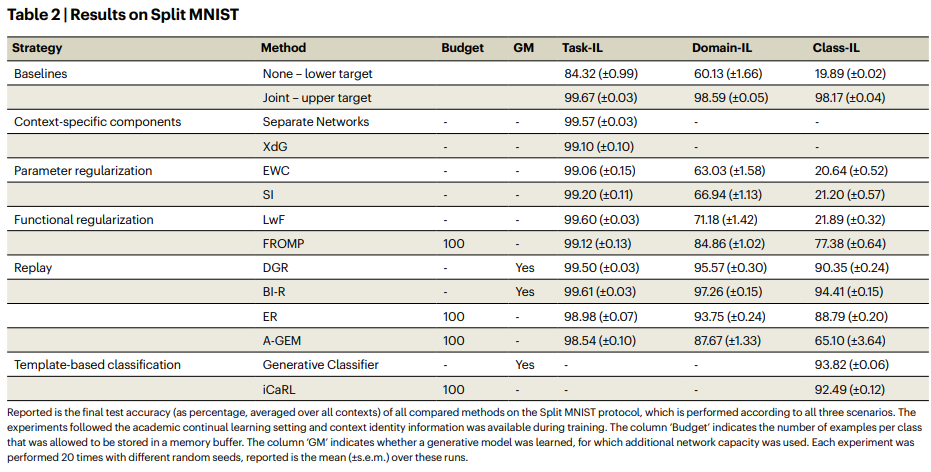
Table2는 MNIST 과제에 따른 실험결과입니다. 그동안 많이 봤던 LwF, iCaRL를 포함한 다양한 incremental learning 방법론으로 비교실험된것을 알 수 있습니다. 기학습 모델의 파라미터를 직접 저장하는 parameter regularization 방법론이 모든 타입의 incremental learning 에서 성능이 낮은데 task-incremental learning은 그나마 upper와 가까운 성능을 보임을 알 수 있습니다. 그러나 domain-incremental learning과 class-incremental learning에서 parameter regularization 방법론은 크게 힘을 발휘하지 못한 것을 확인할 수 있습니다. 이러한 세가지 시나리오에 대한 학습 경향은 functional regularization methods(새로운 데이터에 대한 과적합, 빠른 적합을 규제하는 학습방식)에서도 유사함을 확인할 수 있으나 FROMP 방법론에서는 덜 영향을 미침을 알 수 있습니다. 한편 이전 에피소드에 사용되었던 데이터를 재사용하는 replay-based methods는 세가지 시나리오에 대해 안정적으로 incremental learning 을 진행할 수 있음을 알 수 있으나 이전 데이터를 저장할 수 있는 메모리의 크기(저장할 수 있는 샘플 수)에따라 성능편차가 큰것이 일반적입니다(실험에서는 100개의 샘플을 사용하도록 통일).
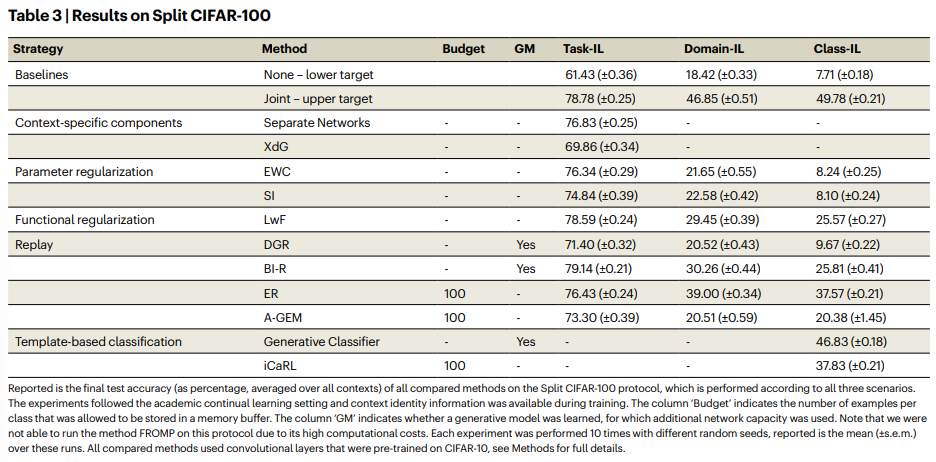
Table3는 동일한 실험을 CIFAR-100에서 진행한 결과입니다. MNIST에서 확인한 결과와 유사한 경향을 띄는것을 알 수 있습니다. 정리하자면 task-incremental learning에 대해서는 연구된 방법론들이 대부분 none이나 joint baseline 보다 효과가 있었습니다 그러나 domain, class-incremental learning 시나리오에서는 제안하는 방법론이 효과가 없다고 판단되는 수준으로 성능이 떨어졌습니다. 이러한 특징은 특히 parameter regularization 기반의 접근법에서 두드러졌습니다.
안녕하세요 황유진 연구원님 좋은 리뷰 감사합니다.
3가지의 Incremental learning 방법론을 소개하고 정리한 논문 같습니다. (그나저나 Nature가 제가 아는 그 Nature가 맞나요…?)
황유진 연구원이 지금 AL에 도입하려는 Incremental Learning 은 어떤 방법론에 속하는 것인지, 왜 그걸 택했는지 알 수 있을까요? 감사합니다
nature machine intelligence에 게재된 논문입니다
AL에는 입력과 출력의 형식이 유사한 domain-task incremental learning이 적합하지 않을까 생각합니다.