이번에 소개드릴 논문은 Facebook AI Research 팀에서 쓴 Masked Feature Prediction(MaskFeat)이라는 논문입니다. 해당 논문도 Masked Autoencoder(MAE)에 대한 방법론으로, 이 논문에서 다루고자하는 것은 Reconstruction하는 대상을 무엇으로 삼을 것인지 입니다. MAE 방법론들이 다 그렇듯 방법론 자체는 어렵지 않고 실험결과 위주로 풀어나가며, 해당 논문의 내용 역시 다들 한번쯤은 궁금했을 법한 내용들을 위주로 다루고 있으므로 가볍게 읽으시기 좋을 듯 합니다.
Intro
먼저 Self-supervised Learning으로 학습하는 Masked AutoEncoder의 학습 방식은 그림1 첫번째 열처럼 입력 영상에 일부분을 랜덤하게 선정하여 Masking을 한 후 Masking 되지 않은 패치만을 토대로 Masking된 패치들을 재복원하는 것입니다.
즉 사람들이 하나의 영상 내에서 보이는 부분들을 통해 가려진 부분들을 유추할 수 있는 것처럼, 실제 신경망 모델들도 영상의 의미론적인 것들을 잘 이해하였다면 가려진 부분을 잘 복원할 수 있을 것이다 라는 나름 단순하면서도 그럴 듯한 방법입니다.

기존의 Standard MAE는 모델이 복원하는 값이 입력 영상과 동일한 RGB Color pixel 값을 의미하죠. 하지만 과연 이렇게 pixel 값 자체를 복원하는 것이 유의미한 것일까요? 저자는 복원하는 대상을 무엇으로 하는 것이 좋은지에 대해 의문을 제기합니다.
사실 이렇게 전체 데이터에 대해서 보이는 부분을 통해 가려진 부분을 예측 및 복원하는 것은 NLP 분야에서 시작이되었습니다. 그리고 Vision 분야에서 관심을 끌기 시작한 것은 고작 1~2년 전이구요. 여기서 Vision과 NLP 분야는 활용하는 데이터 도메인의 차이부터 큰 차이가 발생합니다.
NLP는 문장 속 각 단어 하나하나가 가지는 의미적 파워가 상당한 반면, 영상의 경우에는 각 픽셀이 나타내는 값이 연속적이라고 볼 수 있으며, 영상 자체가 이루는 픽셀의 개수는 상당히 많기 때문에 마스킹된 데이터를 복원하는 것이 상당히 어렵고 모호한 문제에 해당합니다.
그럼 각각의 픽셀 혹은 패치들을 NLP에서 하듯이 시각적 어휘 토큰(code book같은 느낌인데 정확히는 카테고리화가 되어있는 이산 분포라고 생각하시면 됩니다.)으로 보고 이를 모델이 예측 및 복원하면 되지 않을까요? 물론 이 방식이 단순히 픽셀을 복원하는 것보다는 더 도움이 될 수 있지만, 저자는 이를 위해선 추가적인 tokenizer가 필요하고 이 것들은 연산량 측면에서 손해를 본다고 합니다.
따라서 저자는 Vision 분야에서 MAE가 어떤 feature를 복원하는 것이 영상을 이해하고 더 좋은 pretrained weight으로 쓸 수 있는가에 대해 다양한 실험들을 진행하며, 결론부터 말씀드리면 그림1의 2번째 열과 같이 Histogram of Gradient(HoG) feature를 복원하는 것이 성능과 효율성 측면을 모두 고려하였을 때 가장 우수하였다고 합니다.
이에 대한 디테일한 얘기들은 Method Section에서 다뤄보겠습니다.
MaskFeat pre-training
일단 본 논문에서 제안하는 방법론이 어떻게 학습하는지, 학습에 사용한 Feature들은 어떤 종류들이 있는지 등을 알아보겠습니다. 먼저 학습 방식은 기존 Standard MAE와 조금 다릅니다. 입력에 대하여 랜덤하게 Masking을 수행하는 것은 기존 MAE와 동일하지만, Masking이 되지 않은 영역을 ViT 기반 Encoder에 태워서 특징들을 추출하는 기존 방식과 달리 MaskFeat은 Encoder의 입력으로 Visible patch와 Masked patch를 모두 함께 입력으로 활용하죠.
그 후에는 단순히 linear projection layer를 통과하여 마스킹된 패치와 연관있는 출력 토큰을 생성하게 됩니다. 만약 target으로 하는 feature가 RGB라면 패치 하나가 16×16 사이즈라고 했을 때 projection layer를 통해 생성되는 output은 3x16x16이 되겠네요.
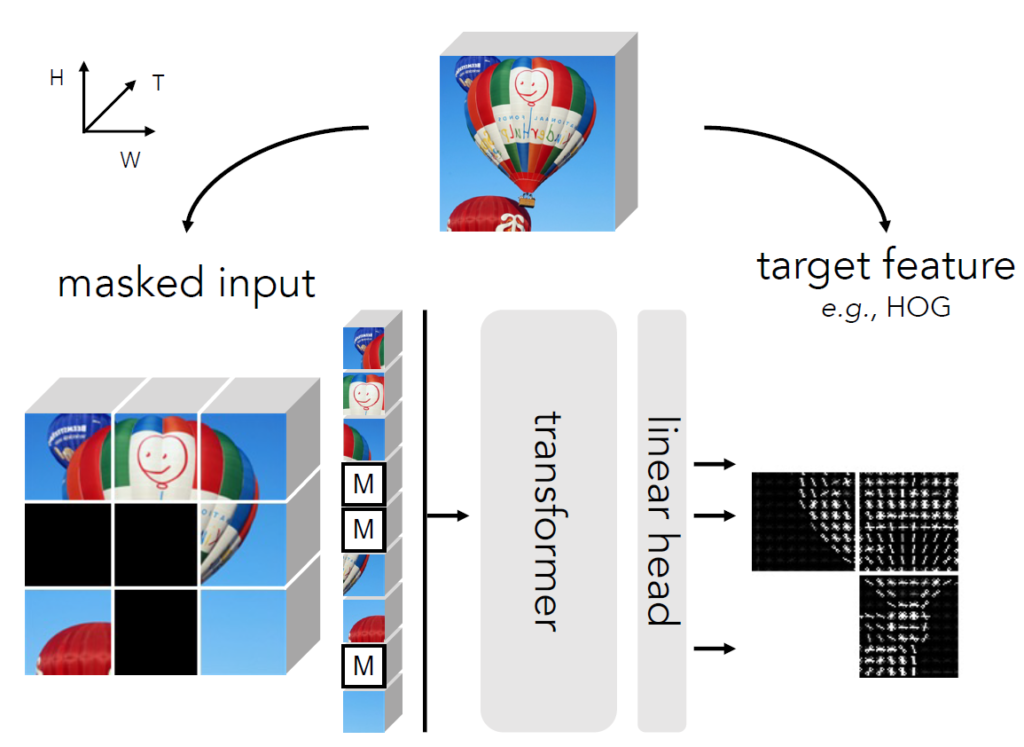
사실 이 논문은 Image 뿐만 아니라 Video Pretraining에 대한 실험도 진행합니다. 보다 정확하게는 Video data가 더 메인이고 Image는 부가적인 느낌이 더 강한 것 같아요. 그래서 실제 Pretraining 그림도 Image를 입력 데이터로 한 것이 아닌, Video를 입력 데이터로 예시한 그림입니다. 근데 사실 Video라고 해서 따로 추가적인 무언가가 있는 것이 아니고, 그냥 patch가 time축이 생긴 cube?로 바뀐 것 뿐이다라고 생각하시면 될 것 같습니다.
Target Feature
그럼 이제 본격적으로 해당 논문의 주요 관심사인, 어떤 특징들을 복원하는 것이 가장 효과적인가에 대한 실험 전에 어떤 특징들을 활용했는지 소개하도록 하겠습니다.
논문에서는 크게 one-stage target, two-stage target << 2가지로 타입을 나누고, 해당 타입 안에 각각 2개, 3개의 종류로 또 특징들이 나뉘게 됩니다. 먼저 one-stage target 내에는 standard MAE가 활용한 pixel color와 논문에서 최종적으로 채택한 HoG Feature로 구성이 되어있으며, two-stage target의 경우에는 사전 학습된 모델을 통해서 추출된 feature들이라고 이해하시면 되겠습니다.
여기서 이 two-stage target들은 결국 사전 학습된 모델이기 때문에 모델 자체를 사전학습하는데에도 코스트가 들어가며, 실제 본 모델을 학습시키기 위한 target을 생성하는 것에도 코스트가 들어가기 때문에 활용성 측면에서는 단점이 존재하는구나 하고 이해하고 계시면 됩니다.
Pixel Color
가장 먼저 pixel color에 대해서 간략하게 설명하고 넘어가면, 논문에서는 데이터 셋의 평균과 표준편차를 통해 정규화된 RGB value 값을 복원하는 식으로 모델을 학습시켰다고 합니다. 모델 학습 때 활용한 목적 함수는 실제 GT RGB와 예측된 RGB 픽셀 값 사이에 L2 loss를 활용하였고요.
저자는 RGB color 자체를 복원하는 것이 상당히 단순하고 심플하다는 이점이 있지만, 결국 해당 값들을 target으로 선정하게 될 경우 명도나 대조의 변화와 같은 지역적 통계치 혹은 고주파 성분들과 같이 시각적 컨텐츠를 해석하는데 있어 그리 중요한 요소들이 아닌 것들에 모델이 과적합될 수도 있다는 단점을 언급합니다.
Hog Feature
그 다음은 Histogram of Oriented Gradients(HOG)를 reconstruction하는 것에 내용입니다. HOG는 컴퓨터비전 공부를 하셨다면 이름 정도는 한번쯤 들어보셨을 전통적인 hand-crafted feature로 간략하게 소개드리면 로컬 패치 내에 gradient 방향(즉 영상의 엣지 방향)들을 히스토그램 분포 형식으로 표현한 descriptor입니다.
HOG에 대해서 궁금하신 분들은 구글에 검색하면 상세하게 소개해주는 블로그 글들이 많으니 해당 글들을 참고하셔도 좋을 것 같습니다. 아무튼 이러한 HOG는 영상 전반에 걸쳐 각각의 그리드마다 촘촘하게 추출할 수가 있으며, 저자는 이렇게 촘촘하게 추출해야 랜덤하게 샘플링된 패치를 reconstruction할 때 유용하게 활용할 수 있다고 합니다.
논문의 결론이기도 합니다만, HOG를 복원하는 것이 pixel color를 복원하는 것보다 왜 더 좋은 pretext task로 볼 수 있을까요? 저자는 HOG에게 2가지 이점이 있어서 그렇다고 주장하는데, 먼저 첫번째는 평행이동과 회전등 기하학적인 변화에 강건성을 보이며 동시에 영상의 gradient를 기반으로 특징을 생성하는 기술자이기 때문에 pixel color에서 자주 발생하는 photometric change(illumination, contrast variation) 등이 HOG에서는 고려되지 않아도 된다고 합니다.
또한 HOG는 영상의 gradient만을 단순히 필터 연산을 통해 계산하면 되니 연산량 측면에서도 효율적이기 때문에 self-supervised learning을 하는데 있어서 그리 부담스럽지도 않다고 합니다. 저자는 랜덤하게 샘플링된 패치에 대해서만 HOG를 계산하는 것이 아닌, 영상 전체에 대해서 HOG feature map을 취득한 후 각각을 패치 단위로 쪼갰다고 합니다.
이는 HOG 자체도 cell 이라는 개념의 local patch 계산이 들어가다보니 각 바운더리에 padding 연산이 들어가게되는데, 이 때 패치 단위로 계산하게 되면 패치의 개수 별로 padding 연산이 반복적으로 들어가게 되어 이를 예방하고자 전체 영상에 대해서 HOG를 계산한 것이라고 합니다.
아무튼 이렇게 전체 영상에 대해 HOG feature를 만들고 그것을 패치로 쪼갠 뒤 마스킹된 영역에 해당되는 HOG feature patch들만 모아서 flatten and concatenation을 수행하여 target feature로 따로 보관을 해놓게 됩니다. 이렇게 보관해놓은 target feature들은 사전 학습을 할 모델의 예측 HOG feature와의 L2 distance 계산을 수행하는데 활용됩니다.
Discrete variational autoencoder(dVAE)
인트로에도 간략하게 언급을 드리긴 했습니다만, NLP 분야에서는 문장이 아무리 길어도 한 문장이 수백~수천 단어로 구성될 수는 없지만, 영상의 경우는 픽셀 단위로만 놓고 보면 몇십만개 이상의 갑으로 분포되어 있습니다. 따라서 이러한 고차원의 시각 정보들을 NLP 분야처럼 압축된 정보 형식으로 표현하고자 DALL-E는 dVAE라는 코드북이라는 개념을 제안하였습니다. 즉 영상의 각각의 패치들은 dVAE라는 사전 학습된 모델을 통해 8192개의 값으로 이루어진 토큰으로 인코딩을 하였다는 것이죠.
이렇게 영상의 패치를 어떠한 코드북으로 해석하는 컨셉에 영감을 받아 저자는 self-supervised learning의 pretext task로 dVAE를 이용해 RGB 영상 패치를 codebook으로 만든 후, 사전 학습시킬 모델이 마스킹된 패치에 대해 올바른 codebook을 복원하도록 학습하는 실험을 진행하였습니다. 인코딩된 토큰은 위에서도 얘기했듯이 8192개의 값을 지닌 분포이기 때문에 cross-entropy loss를 목적함수로 학습을 시켰습니다. 하지만 해당 방법론의 아쉬운 점은 패치를 토큰으로 인코딩할 사전 학습된 dVAE 모델이 존재해야한다는 점이며, 둘째는 target feature를 생성하기 위해 모델을 사용한다는 점에서 연산량 및 메모리가 더 많이 소모되게 됩니다.
Deep Feature
해당 실험 역시도 바로 위에서 설명한 dVAE와 유사하게 deep learning feature를 활용하는 것입니다. 하지만 위와 조금 차이점이 있다면, dVAE의 경우에는 이산화된 분포를 가지는 feature vector였지만, 해당 실험에서는 그냥 continuous한 값들로 구성된 feature map이라는 점이죠.(즉 레이어를 통과해 계산된 feature 값을 그대로 활용한다는 것입니다.)
논문에서 활용한 Deep Learning 모델로는 크게 CNN과 ViT가 있으며 각각의 모델들은 모두 다른 사전학습 방법론(DINO, MOCO 등등)으로 사전 학습됐습니다. 지도 학습 기반의 방법론이 아닌 자기지도학습 기반으로 사전학습된 모델을 활용한 이유는, 이전의 연구들에서 밝혀진 내용이지만 지도학습 기반의 모델보다 자기지도학습 기반 방식으로 사전학습한 모델의 feature map이 훨씬 더 시각적인 디테일을 잘 살렸다는 결과들이 많이 있기 때문에 지도학습 기반 모델을 활용했다고 합니다.
해당 방식도 dVAE와 유사하게, 사전 학습된 모델을 활용한다는 점에서 학습 시 연산량과 메모리를 소모하게 된다는 단점이 존재로 합니다.
Experiments
자 그러면 본격적으로 실험 결과에 대해서 살펴보겠습니다. 해당 논문은 image뿐만 아니라 Kinetics-400과 같은 비디오 데이터 셋에 대한 top-1 accuracy 성능도 리포팅을 합니다만, 이번 리뷰에서는 이미지넷과 관련된 내용에 대해서만 다루도록 하겠습니다. 사실 비디오나 이미지나 경향성이 유사하게 나타나고 있어서 이미지넷 결과만 살펴보셔도 대략적인 유추는 가능하십니다.
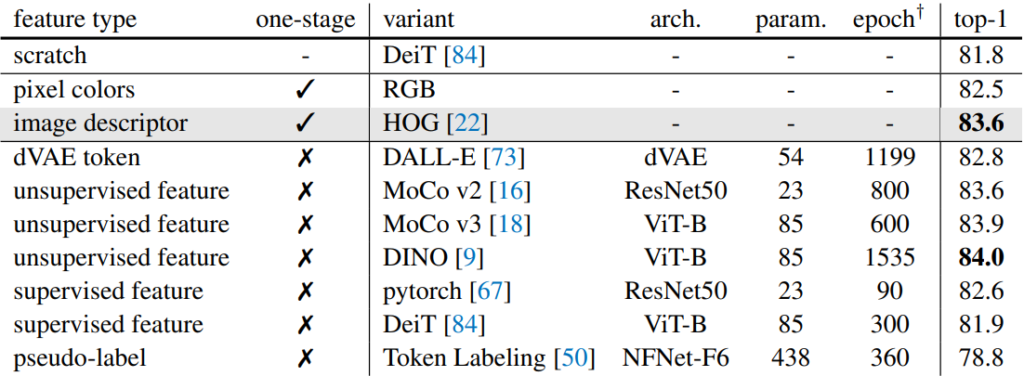
위에 표는 ImageNet1K에 대하여 300에포크 pretraining을 수행한 후 100에포크에 대해 fine-tuning한 결과를 나타냅니다. 위에 스크레치의 경우에는 마땅히 pretraining을 하지 않았을 때의 성능을 의미하며 차례대로 pixel color와 HOG는 deep learning 모델을 활용하지 않는 방법론들(one-stage), 그리고 dVAE token, unsupervised feature(MOCO나 DINO 같은 자기지도학습 기반 모델), supervised feature(지도 학습한 모델을 활용) 등으로 존재합니다.
위에 표에 대한 설명을 간략히 하면, 아무래도 스크래치 레벨로 바로 학습하는 것보다는, pixel color등을 복원하는 자기지도학습을 먼저 진행하는 것이 imaeg classification 성능 향상에 도움이 된다는 것이며, 두번째는 pixel color보다 image descriptor 즉 HOG를 복원하는 것이 1.1% 더 좋은 성능을 보여준다는 점입니다.
게다가 이 HOG feature를 활용한 것은 MOCO v2로 학습한 ResNet50의 feature map을 target feature로 활용하는 2-stage 기반 방법과 동일한 성능을 달성함으로써, 학습에 사용되는 메모리나 학습 과정 등의 간소화를 가질 수 있다는 장점 역시 확인할 수 있습니다. 이와 비슷한 관점에서 DINO로 학습한 VIT-B의 경우 더 좋은 top-1 accuracy를 보여주긴 하지만, 사전 학습에 필요로 하는 epoch가 1535에포크며 동시에 실제 본 모델을 pretraining할 때에도 ViT-B를 teacher model로 활용해야 한다는 점에서 효율성이 떨어진다고 볼 수 있습니다.
그리고 한가지 더 재밌는 점은 supervised feature를 활용하게 되면, 사람이 직접 annotation한 정보를 받았음에도 불구하고, 오히려 pixel color를 복원하는 pretext task보다 더 떨어지는 성능을 보여주게 됩니다. 저자는 실제로 지도 학습 기반 모델의 feature를 target feature로 활용한 모델이 fine-tuning을 할 때, 심한 over-fitting이 발생하였음을 확인했으며, 이를 토대로 해당 토큰들을 복원하는 식의 학습 방향은 적합하지 않다고 주장합니다.
물론 그 이유에 대해서는 명확하게 증명하기가 어렵지만, label을 통한 supervisd learning은 동일 객체에 대하여 texture나 local shape등에 대해 그리 큰 연관성이 없기 때문에 이러한 supervised learning을 통해 학습된 모델의 feature map을 target feature로 삼는 행위는 사전 학습을 시키기 위한 모델이 물체 내부의 구조 등을 파악하기 어렵게 한다는 가정을 내세웁니다.
Ablation for Image Recognition
자 그러면 image recognition에 대한 ablation study에 대해서 간략하게 살펴보겠습니다.
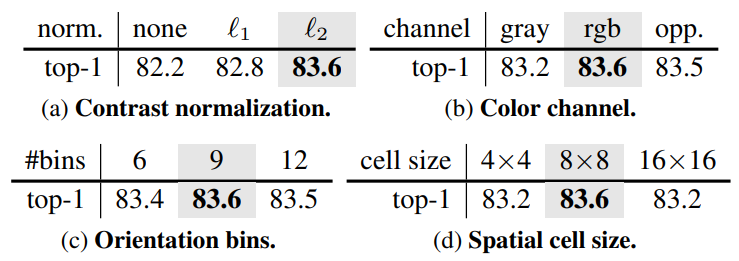
먼저 첫번째 실험은 HOG feature에 대한 hyper paramter, 세부 구현 등등에 대한 실험들입니다. (a)부터 살펴보면 contrast normalization이 상당히 중요하다는 것인데요, 여기서 말하는 contrast normalization이란 계산된 HOG feature를 계산할 때, 8×8 local pixel cell의 histogram vector들 각각에 대해 정규화를 했는지를 의미합니다.
저자는 l1 보다 l2를 했을 때 더 좋은 성능을 보여주었으며, 정규화를 전혀 하지 않은 경우에는 l2 정규화와 비교하여 성능이 무려 1.4%나 떨어지는 것을 확인할 수 있었습니다. 저자는 이 normalization이 로컬 패치에 대한 illumination change에 강인성을 지닐 수 있도록 해주기 때문에 모델이 객체를 인식하기 더 좋은 방향으로 학습이 된다고 합니다.
그 외에도 이제 HOG feature를 RGB 각 채널별로 추출할지, gray 1ch에서 추출할지에 대한 내용이나 HOG Feuatre의 hyper parameter 격인 orientation bin, cell size 등의 크기에 따른 결과가 각각 테이블에서 나타내고 있습니다.
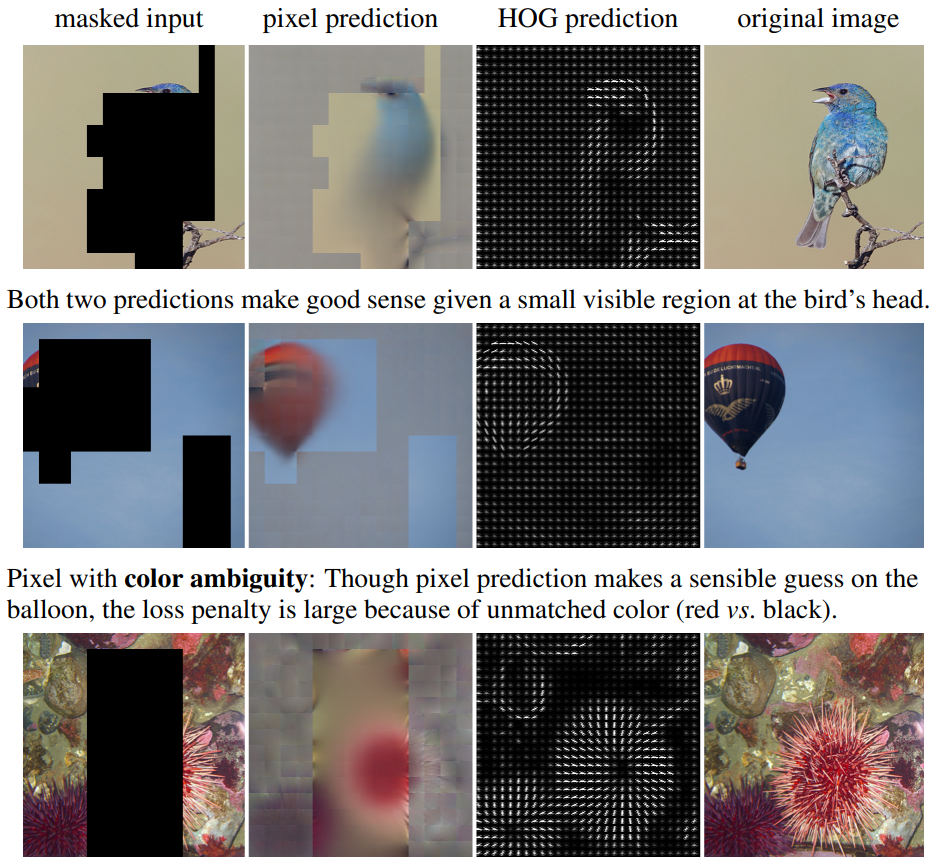
그 다음으로, 위에 그림은 마스킹된 영상에 대하여 모델이 RGB, HOG feature에 대해 복원한 결과와 그에 대한 original image를 나타낸 것입니다. 논문에서 말하는 pixel prediction의 문제점은 바로 모호함이라는 것입니다. 실제로 2번째 열을 살펴보면, 원본 영상 속 열기구는 검정색이지만, 예측된 열기구는 붉은색으로 생성한 모습입니다.
물론 그렇다고 해서 붉은색 열기구가 틀린 것은 아닙니다. 검정색 줄무늬가 그려진 붉은색 열기구로 그렸다고 해서 전혀 어색할 것은 없죠. 하지만 학습 방식이 결국 원본 영상과 복원 영상간에 MSE loss로 계산이 되다보니 잘못된 색상은 큰 loss penalty를 제공하게 됩니다.
또한 아래 성게?에 경우에는 텍스쳐가 풍부하지만, MSE loss의 특성상 예측된 결과물은 상당히 블러하고 텍스쳐도 많이 손상된 것을 볼 수 있습니다. 물론 기존의 MAE 논문에서는 reconstruction을 얼마나 더 잘했는지가 더 좋은 pretrain weight으로 이어지지는 않는다고 하긴 했으나. 논문에서는 그래도 RGB의 prediction 값이 모호하게 생성되는 것이 문제라고 생각하는 듯 합니다.
그래서 실제로 모델이 예측한 HOG Feature를 보면 열기구에 대하여 올바른 gradient 성분들을 잘 표현하고 있으며 아래 텍스쳐가 풍부한 영역에 대해서도 큰 이상 없이 자연스러운 방향성을 나타내고 있습니다. 즉 HOG prediction은 모호성에 대한 리스크를 크게 줄임으로써 더 좋은 feature representation을 할 수 있도록 도와준다고 합니다.
Multi-task learning
마지막으로 pixel prediction과 HOG prediction을 동시에 수행하는 Multi-task learning을 해보면 어떨까?에 대한 실험 결과입니다.

결론부터 살펴보시면 한쪽 도메인에 대해서 예측하는 것보다 더 떨어지는 성능을 보여주고 있습니다. 물론 위에 실험에서는 단순히 pixel prediction에서의 loss와 HOG prediction에서의 loss를 반반 섞어서 평균을 낸거이기 때문에, loss 비율을 어떤 식으로 줄지 튜닝을 한다면 또 다른 결과가 나올 수 있을지 모르겠습니다만, 일단 휴리스틱하게 접근하였을 때는 두 모달리티에 대한 정보들이 서로에게 도움이 되지 않는다는 결론을 낼 수 있겠습니다.
이것은 어찌보면 당연한 것이, multi-task learning의 경우 두 task가 서로 유사성을 지니면서 서로의 지식이 서로를 이해하는데 더 큰 도움이 되어야하지만 이 둘은 서로 명확한 차이점으로 인해 오히려 학습이 방해된다고 볼 수 있습니다. 조금 더 구체적으로 pixel prediction의 경우 local brightness 변화에 강하게 영향을 받지만, HOG feature의 경우에는 normalize를 통해 해당 특성에 대하여 강인함을 보이기 때문이죠.
결론
MAE 자체가 단순히 Color information을 복원하는 것으로 수행되었기 때문에, RGB 대신 다른 특징들을 복원하는 것이 더 좋지 않을까? 라는 생각을 누구나 했을 법 한데, 이미 1년도 넘게 FAIR에서 실험을 진행했더군요. 덕분에 머리속으로만 생각하던 궁금증이 조금은 해결된 것 같아서 재밌었던 논문입니다.
안녕하세요 신정민 연구원님 리뷰 잘 읽었습니다.
리뷰 내용을 읽어보니 결국은 이미지의 style을 잘 보는 것이 vision에서 중요하지 않을까 라는 생각이 들었습니다. 리뷰에는 질문드릴 내용이 없어 개인적인 궁금함을 질문드리자면, 이 논문에서도 HOG 대신 http://server.rcv.sejong.ac.kr:8080/2022/11/27/cvpr2021-reducing-domain-gap-by-reducing-style-bias/ 신정민 연구원님이 리뷰하셨던 이 논문의 방법론들을 좀 채용해서 스타일에 집중하게 한다면 이 논문에서 HOG로 실험한 것과 비슷한 효과가 나올까요?
감사합니다.
그 당시 사정이 있었는지..? 답변을 못드렸었네요.
뒤늦게 답변을 달아보면, 먼저 영상의 style을 잘 보는 것이 vision에서 중요하다는 것에 대해 저는 오히려 반대의 입장으로 style보다는 content가 중요하다는 편이여서.. 먼저 위에 리뷰를 통해 왜 그렇게 생각하셨는지 조금 궁금하네요.
저의 예전부터의 생각은 사람은 물체를 인식하고 파악할 때 스타일보다는 content를 더 집중한다는 것, 그래서 영상에 노이즈 혹은 domain shift가 발생하더라도 사람은 쉽게 동일 카테고리 대상을 인지하지만 CNN 기반 방법론들은 그것이 어렵다는 점을 종종 관련 논문 리뷰를 통해서 언급했었습니다.
해당 논문의 경우에도 영상의 픽셀레벨에 곧바로 접근하는 방식은 photometric한 성분 즉 style 성분이 많이 관여되는 것이기 때문에 그런 것들보다는 영상의 content에 해당하는 edge histogram 등으로 reconstruction을 해서 강인하게 가져가보자가 컨셉인지라.. 굳이 style과 content로 구분 짓는다면 이 논문은 이미지의 content를 더 잘보는 것이 중요하다가 아닐까 생각합니다.
안녕하세요. 연구원님의 리뷰 잘 읽었습니다.
MAE에 대해 들어보기만 했을 뿐, 알아보지 않았었는데 리뷰를 읽으며 기본적인 개념을 알게 되었습니다.
리뷰 글에 대해 읽다보니 하나 궁금했던 부분이 실험 파트에 나와있어 궁금증이 들었는데,
HOG Feature로 reconstruction 시 Pixel을 활용했을 시에 비해 장점을 갖고자 한다면 저자의 의도대로라면, 또한 글에 쓰여있듯이 그리드 셀이 촘촘해야 Pixel을 활용했을 시와 유사한 효과를 내며 HOG를 활용했을 때의 이점 (예를 들면 글에 쓰여진 것과 같이 photometric invariance 등)을 살릴 수 있을 것으로 보이는데, 실험 파트에서는 cell size가 8×8일 때의 성능이 더 좋은 것으로 보입니다.
그 차이가 크진 않지만, 제 생각에서는 cell size가 좁을 수록 local한 특징을 더욱 잘 학습할 것으로 생각을 했는데, 제 이해가 잘못된 것일까요? 아니면 단순한 실험의 결과이고 저자의 이러한 이유에 대한 다른 고찰이 있을까요?
MAE에 대해 들어보기만 했을 뿐인데, 신정민 연구원님의 리뷰를 읽다보니 재밌어서 이전의 리뷰들도 함께 봐야할 것 같습니다. 좋은 리뷰 감사합니다.
안녕하세요, 먼저 답변이 늦어진 점 미안합니다. 논문 리뷰 재밌게 봐주셔서 고맙네요:)
질문에 대한 답변을 먼저 드리면, 제가 리뷰에서 말했던 촘촘이란 완전 픽셀 하나하나 까지의 의미는 아니긴 했습니다. 사실 영상에서 pixel 하나하나가 가지는 의미는 그리 크지 않기 때문에 더 작을수록 항상 유의미한 것은 아니라고 말씀드리고 싶어요(물론 제 개인적 생각입니다.)
다만 제가 리뷰에서 말했던 촘촘이란 의미는 결국 기존 MAE처럼 masking된 영역들을 복원을 해야하는데 이때 일정 비율에 맞추어 랜덤하게 마스킹하게 되더라도 영상 전반에 걸쳐 촘촘하게 HOG feature가 계산되어 있으면 코드 구현 관점에서 크게 문제가 되지 않는다는 것이죠.
그래서 4×4보다 8×8이 더 좋다는 것은 데이터 셋에 따라 달라질 수도 있지만, 8×8정도 크기의 패치가 영상의 정보를 잘 담으면서 동시에 dense한 레벨까지 잘 담고있는 가장 최적의 size가 아닌가 싶습니다.