
제가 오늘 리뷰할 논문 역시 Active Learning에 대한 논문입니다. 특징은 제가 지난주에 리뷰한 [ICCV 2019] Variational Adversarial Active Learning VAAL이라고 불리는 연구를 L-Loss 라는 또 다른 근본 AL 방법론과 결합하여 확장된 Task-Aware 한 VAAL을 제안했다는 점입니다. (참고로 L-Loss는 저희팀이 베이스라인으로 삼고 있는 AL의 근본 방법론 중 하나입니다.)
<Task-Aware Variational Adversarial Active Learning >

Background
제가 소개에서 본 논문은 Active Learning 의 근본 방법론 두 개를 합친 것이라고 설명하였는데요. 그럼 이 논문을 이해하기 위해서는 그 두 방법론을 알아야 합니다. 그 전에, Active Learning 은 동일한 개수의 데이터로 학습하더라도, 더 좋은 성능을 내는 지정된 개수의 데이터를 찾아내는 연구입니다. 따라서 Active Learning의 모델은 Unlabeled dataset에서 가령 100개의 데이터를 선별하면, 선별한 데이터에 Label 을 붙힌 뒤 Labeled dataset에 추가해서 다시 모델을 재학습시킵니다. 동일한 개수의 데이터를 선택하더라도, “어떤 데이터”를 선택하는지에 따라 모델 성능은 당연히 달라지겠죠? 그렇다면 제가 지금 설명하려는 2가지 방법론들은 라벨링할 데이터를 선별하는 기준을 어떻게 세웠는 지를 위주로 설명드리겠습니다.
#Learning Loss (참고: [CVPR 2019] Learning Loss for Active Learning – @조원 연구원의 리뷰)
Learning Loss(이하 L-Loss) 는 Loss가 높은 데이터를 라벨링할 것을 제안하였습니다. 왜냐하면 Loss란 모델이 어려워한다는 가장 객관적인 지표라고 할 수 있기 때문이죠. (모델이 어려워하는 데이터일수록 사람이 정확하게 라벨링을 해줘야만 성능 드랍을 막을 수 있으며, 높은 폭으로 성능을 올릴 수 있습니다.)
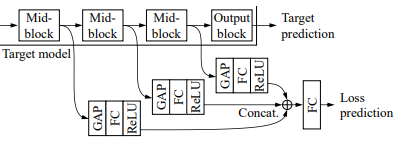
그렇다면 저자의 의도에 따라 Unlabeled dataset 들이 Loss를 반환해야할지 알아야합니다. 그래야 모든 Loss를 정렬한 뒤, Loss가 높은 데이터 K개를 골라서 라벨을 추가해야하니까요. 그러나 모두 아시다시피 Loss는 GT가 있어야 구할 수 있습니다. 따라서 이를 극복하기 위해 저자는 Classification, Segmentation과 같이 Downstream Task를 위한 네트워크에 branch로 Loss를 예측하는 모델을 추가하였습니다. 즉, 데이터의 Loss를 예측하는 모듈(Loss Prediction Module 이하 LPM)을 사용해서 Label이 없는 데이터의 Pseudo-Loss를 구한 것과 동일하다고 설명할 수 있겠네요. 상단의 이미지가 바로 LPM 구조입니다.
#VAAL (참고: [ICCV 2019] Variational Adversarial Active Learning – @저의 리뷰)
VAAL은 Discriminator가 예측하는 값에 대한 불확실성이 높은 데이터를 라벨링할 것을 제안하였습니다. 여기서의 특이점은 Discriminator의 예측값을 기반으로 데이터를 선별한다는 것입니다. 참고로, 예측에 대한 신뢰도가 높지 않다는 것은 모델은 해당 데이터가 어떤 클래스에 속할지 결정하기 애매하다고 해석될 수 있습니다. 보통 이런 데이터는 결정 경계 근처에 분포될 확률이 높죠. 어떤 데이터인지 불확실한 정도가 높으니 이런 데이터에 대해 정답을 알면 모델의 성능을 높일 수 있다는 것이 주장이죠. 사실 기존의 많은 연구들이 모델의 예측 신뢰도 기반의 불확실성을 데이터 선별 지표로 사용하였는데요. VAAL은 Downstream Task 모델의 출력값이 아닌 Discriminator의 예측 신뢰도를 사용하였다는 차별점이 있습니다.
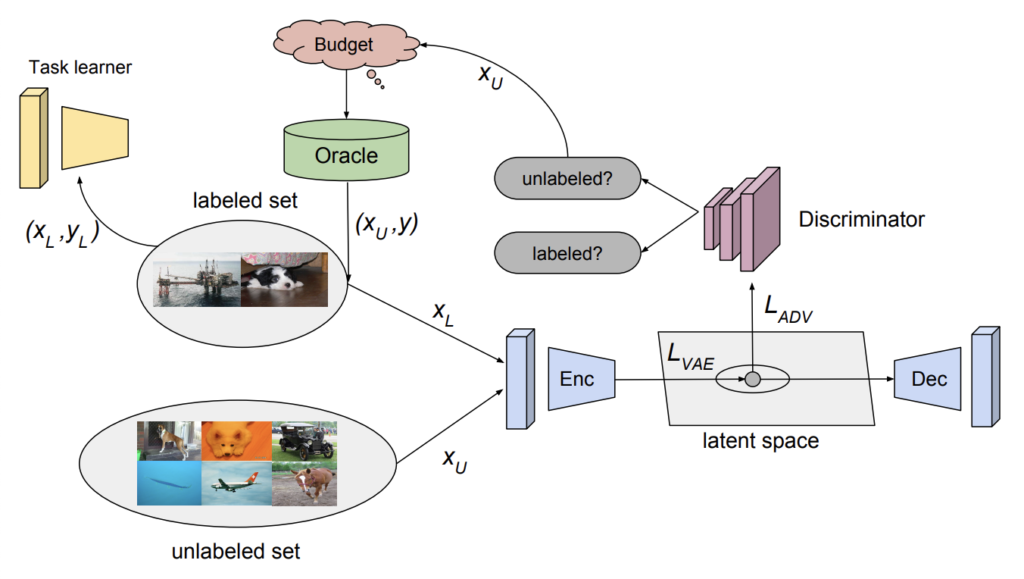
Discriminator는 그럼 어떤 것을 구분하느냐? 해당 데이터가 Labeled 에서 왔는지, Unlabeled 에서 왔는지를 구분하도록 학습됩니다. 이를 속이도록 Generative 계열의 모델로 VAE를 사용하였습니다. VAE는 Labeled 와 Unlabeled 를 구별하기 어려운 feature를 생성하도록 학습됩니다.
우선 각 방법론들이 어떻게 동작하는 지를 간단하게 살펴보았습니다. 각 방법론의 특/장점은 해당 리뷰에 넘어가시면 더욱 이해하시기 좋을 것 같습니다. 그럼 이제 저자는 그 두 방법론을 어떻게, 그리고 왜 합쳤는 지 그리고 특징은 어떤 점이 있는지 본격적인 리뷰에 들어가도록 하겠습니다.
Introduction
해당 논문의 제목은 Task-aware Variational Adversarial Active Learning 입니다. 뒤에 있는 Variational Adversarial Active Learning은 기존 연구인 VAAL인데, 그렇다면 앞에 있는 Task-aware는 무슨뜻일까요? 이것을 이해하기 위해서는 Task-aware vs Task-agnostic의 차이를 이해해야합니다.
agnostic을 영어 사전에 검색해보면 불가지론자라는 의미가 대부분일텐데요, 그 두번째 뜻인 ‘독단적 의견에 사로잡히지 않는’ 에 집중하시면 이해하기 좋을 것 같습니다. 이를 풀어서 이해해보자면 어디 하나에 사로잡히지 않다고 할 수 있고 >> Task-agnostic은 Task에 사고잡히지 않는 이라고 할 수 있겠죠. 정리하자면 Task-agnostic은 ‘task에 관계없이 동작하는/task에 구애받지 않는’ 으로 해석할 수 있습니다. 그럼 그 반대인 task-aware는 Task를 고려한 그 Task에 특화된 something 임을 알 수 있습니다.
그럼 정리해보면 저자는 Task-aware한 VAAL을 제안한 것으로 해석할 수 있겠네요. 그렇다면 뭔가 General 한 입장에서는 Task-agnostic 이 좋을 것 같은데, 정확히 Task-aware/agnostic은 무엇을 의미할까요? 정답은 데이터 선별 시 Unlabeled dataset 의 사용 여부로 결정됩니다. Task-agnostic은 모델 학습 시 Unlabeled 와 labeled 를 동시에 사용합니다. 그러나 Task-aware는 모델 학습 시 오로지 Labeled 만 사용합니다. 이에 따르면 Background에서 설명한 L-Loss는 Task-aware 한 모델입니다. Loss를 예측하는 모듈을 포함하여 downstream task를 위한 모델을 학습할 땐 오로지 Labeled dataset만 사용합니다. 그런데 VAAL은 Labeled 와 Unlabeled 데이터셋을 동시에 사용해서 해당 샘플이 어디에서 온 것인지를 구분하도록 모델을 학습합니다. 결국 Unlabeled 의 활용 여부로 aware인지, agnostic인지 그 구분이 결정됩니다.
사실 설명이 긴 이유는 제가 이 부분을 납득하고 이해하기 어려웠기에,,, 설명이 길었습니다. 조금 더 간단하게 정리해보면 Task-aware는 기존의 Uncertainty 기반의 연구이고, Task-agnostic은 Diversity 기반의 연구라고 할 수 있습니다. (Task-aware는 결정 경계 근처에 있는 모델이 어려워하는 데이터를 위주로 선별하는 것을 목적으로 하고, Task-agnostic은 데이터셋 전체를 함축할 수 있는 표현력을 가지는 서브셋을 선별하는 것을 목적으로 합니다. ) 완전히 그렇게 분류되지는 않지만, 해당 연구들이 선별하고자하는 기준을 중심으로 설명하자면 그렇습니다.
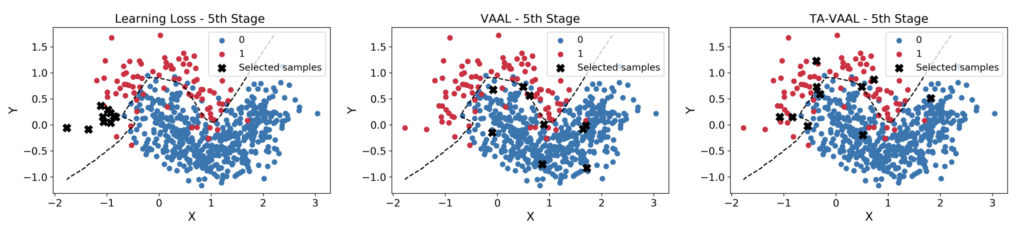
그렇다면 저자는 왜 Task-aware한 VAAL을 제안한 것일까요? 상단 TSNE를 보시면 조금 이해가 될 것 같습니다. 가장 왼쪽인 L-Loss는 Labeled dataset만 사용해서 학습하다보니, Unlabeled 중에서도 Labeled 에 치중한 결정 경계 근처에 잇는 데이터를 위주로 선별되는 것을 알 수 있습니다. 그에 반해 VAAL은 Unlabeled 를 동시에 학습에 사용해서 데이터 전체 분포를 고려한 데이터 선별을 할 수 있었습니다. 이는 K-means와 같이 주변의 데이터를 대표하는 Center 데이터샘플을 선별한 것이라고 볼 수 있습니다. 그러나 이런 데이터들은 결정경계 근처에서는 다소 떨어져 있어, 성능 향상에는 그렇게 큰 도움이 되지는 않을 수 있습니다. 따라서 저자는 이에 집중해서 Labeled/Unlabeled 를 동시에 고려하면서 결정 경계 근처에 있는 데이터를 선별하는 그런 방법론을 제안하고자 하였습니다.
이제부터는 어떻게 두 방법론을 결합하였는지, 그리고 결합할 때 어떤 아이디어를 제안하였는지, 저자가 제안하는 TA-VAAL에 대해 설명드리겠습니다.
Method
[1] Task loss prediction module as “Ranker”
우선 저자는 L-Loss에서 사용한 Loss를 예측하는 Loss Prediction Module(이하 LPM)을 사용하였습니다. 일반적으로 Loss는 에포크가 커질수록(혹은 학습이 진행될수록) 점점 작아집니다. 그렇기 때문에 MSE를 사용하면 스케일링 문제가 발생하여, L-Loss의 저자는 이를 방지하기 위해 두 손실 차이를
저자는 LPM의 목표를 정확한 Loss값 예측에서 –> 정확한 Loss 순위 예측으로 변경하였습니다. Task와 직접적으로 연결되어 있는 Loss를 사용하되 그 Loss의 순위를 예측하는 식으로 완화한 것인데요. 이를 위해서 VAAL에 RankCGAN을 추가로 사용하여 LPM과 연결하였습니다. RankCGAN의 Ranker와 LPM은 모두 Loss에서 두 예측 Loss 사이의 값을 활용하지만, Ranker는 순위를 예측하는데 초점을 맞춥니다. 따라서 이제 순위에 대한 L_R은 다음과 같이 정의됩니다.
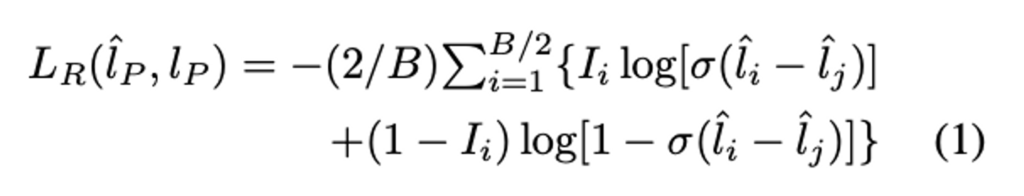
따라서 Ranker R을 가진 Task Model의 최종적인 Loss는 아래와 같이 표현됩니다.
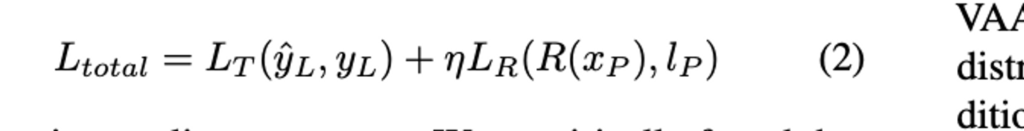
Proposed task-aware VAAL (TA-VAAL)
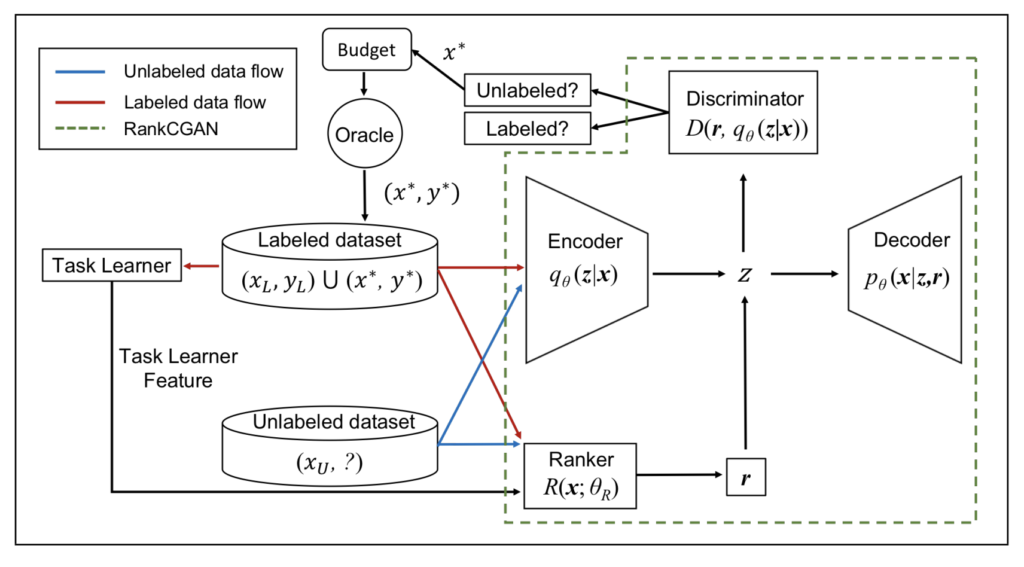
상단 그림이 바로 저자가 제안하는 TA-VAAL입니다. VAAL과의 차이점은 Task Learner 그리고 Ranker -> r 부분입니다. VAAL은 고려하지 못하던 결정 경계 부근을 추가하기 위한 절차라고 할 수 있습니다. Task와 직접적으로 관련있는 Loss를 사용하되, Loss의 ranker 를 예측하도록 완화한 것이죠. 따라서 그 랭커의 출력값인 순위 변수 r을 VAE의 latent space z를 수정하고, 이렇게 정규화된 loss rank 정보 r를 디코더와 Discriminator에 입력하여 Unlabeled 에서 데이터를 선별하는 것이 TA-VAAL입니다.
TA-VAAL에서는 RankCGAN을 사용하여 불확실성 기반의 방법론과 Diversity 기반을 결합한 것이라고 할 수 있습니다. 또한 학습에 Unlabeled를 동시에 사용하여 더 많은 표현력을 학습이 가능하다는 점에서 기존 Uncertainty 방법론과 차별점이 있음이 분명합니다. 아래는 TA-VAAL의 파이프라인을 정리한 수도코드 입니다.

Experimental Results
Image classification on balanced datasets
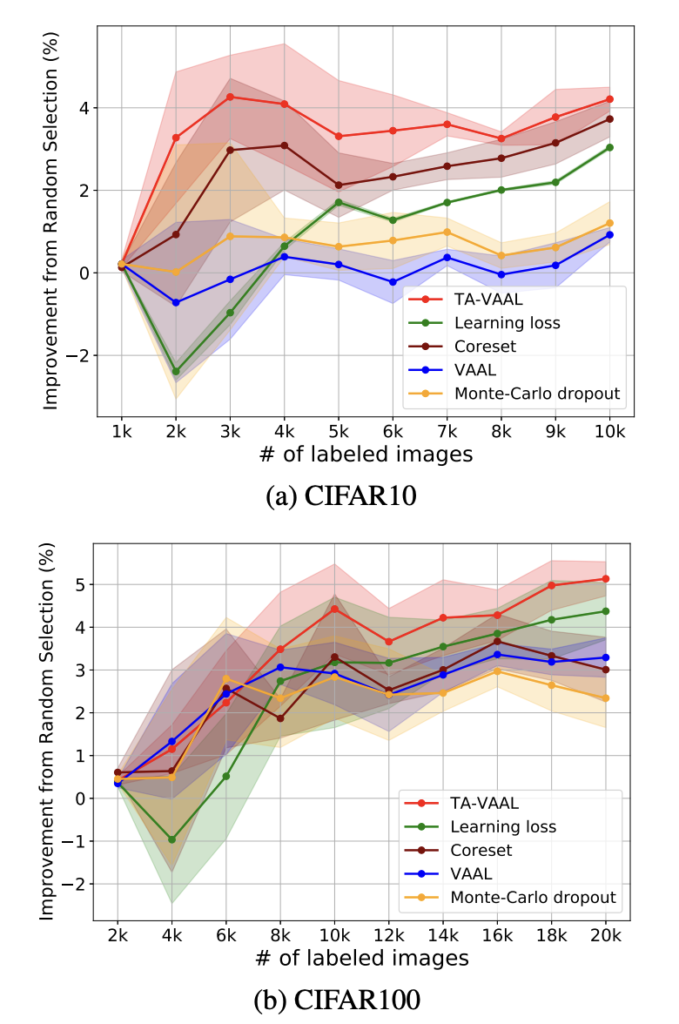
이제 모델 성능 측정으로 넘어가보겠습니다. 성능 측정의 setting은 L-Loss를 기반으로 진행하였습니다. CIFAR-10의 경우 Labeled set의 init-size는 1,000 그리고 add_data size 역시 1000으로 설정하였습니다. 상단 그림 중 (a)가 바로 CIFAR-10의 결과인데요. 우선 초기 단계에서 L-Loss는 모델의 불확실성을 포착하는 데에 Labeled 셋이 충분치 않아서 초기 단계에서는 다소 낮은 정확도를 보였습니다. 그러나 충분한 데이터가 보장되면 (5K) 성능이 향상되는 것을 확인할 수 있습니다. VAAL은 Unlabeled를 대량으로 사용하기 때문에 L-Loss보다 높은 성능을 달성했다고 저자가 주장합니다. 그리고 TA-VAAL은 기존 연구들을 크게 능가하여 SOTA를 달성할 수 있었습니다. CIFAR-100 역시 CIFAR-10과 유사한 경향을 보였습니다. TA-VAAL은 3K 이후 기존 방법론을 큰폭으로 능가한 결과를 보였습니다.
Coreset은 CIFAR-10에서 TA-VAAL과 비슷한 성능을 보였지만, 코어셋은 TA-VAAL보다 샘플 당 7.5배 더많은 계산 시간이 필요하다는 단점이 있습니다. (이 방법론은 데이터의 분포를 고려하기에, 모든 샘플 사이의 거리를 계산해야해서 그런 것 같습니다) VAAL에서는 (5,000/2,500) 설정으로 실험한 결과를 리포팅하였으나, 해당 연구에서는 훨씬 작은 init_size인 (1,000/1,000) 설정을 사용하였습니다. 훨씬 작은 설정을 사용한 경우 VAAL은 성능이 떨어지는 반면 TA-vAAL은 높은 성능을 보였습니다.
Empirical Analyses
Ablation studies
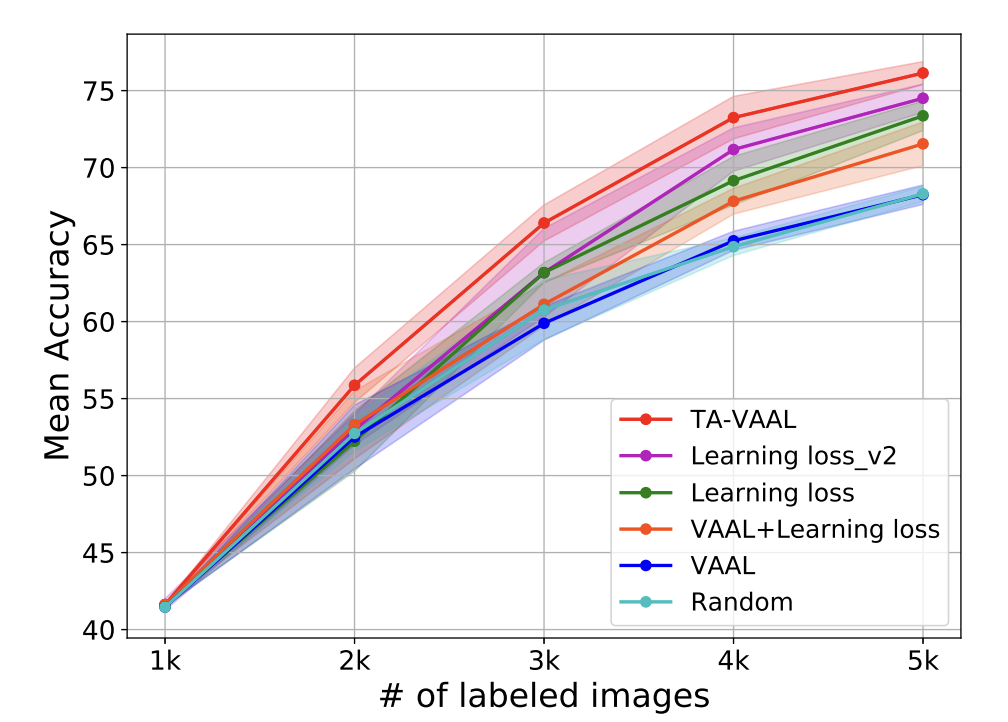
아래 그림은 다른 방법론들과 비교한 Ablation study 입니다. 아래 테이블에서 실선과 주변 부의 연하게 칠해진 것이 5번 실험한 결과에 대한 평균과 표준편차를 나타낸 것이죠. Learning Loss_v2는 L-Loss의 LPM을 Rank loss로 변경한 것입니다. 이를 통해 Rank Loss가 얼마나 효과적인지를 판단하고자 하였습니다. 보라색 실선이 바로 그 결과인데, 이를 통해 L-Loss 비해 훨씬 좋은 성능을 나타낸 것을 알 수 있었습니다. 또한 정확한 Loss를 직접 예측하는 것보다 순위를 간접적으로 예측하는 것이 유리하였다는 것을 알 수 있었다고 합니다. 이외에도 VAAL에 L-Loss를 변형하지 않고 직접 붙히는 것을 비교하엿을 때 제안하는 TA-VAAL이 가장 좋은 결과를 산출하느 것을 알 수 있었다고 합니다.
Conclusion
해당 연구가 마치 제가 가야할 길의 중간 스텝과 같아 보였습니다. Unlabeled 를 동시에 고려하는 방법 말이죠. 다만 저는 Self-learning 에서 활용하는 기법을 접목시키려고 하기에 해당 논문과는 다소 차이가 있다고 할 수 있습니다. 그러나 기존 근본 Active Leanring 방법론을 잘 섞었다고 할 수 있기에 결합하는 부분에 있어 새로운 인사이트를 얻는 포인트에서 훌륭하였습니다. 그리고 해당 논문 코드 정리가 깔끔해서,, 아마 코드적인 부분에서 많이 참고할 수 있지 않을까 싶습니다. 이상 리뷰 마치도록 하게씁니다.
안녕하세요.
리뷰 중간 내용이 빠진 것 같은데 리뷰 내용 중 “우선 저자는 L-Loss에서 사용한 Loss를 예측하는 Loss Prediction Module(이하 LPM)을 사용하였습니다. 일반적으로 Loss는 에포크가 커질수록(혹은 학습이 진행될수록) 점점 작아집니다. 그렇기 때문에 MSE를 사용하면 스케일링 문제가 발생하여, L-Loss의 저자는 이를 방지하기 위해 두 손실 차이를
저자는 LPM의 목표를 정확한 Loss값 예측에서 –> 정확한 Loss 순위 예측으로 변경하였습니다. ”
에서 이를 방지하기 위해 두 손실 차이를 ~ 다음에 내용이 무엇인가요?
그리고 위에 내용이 짤려서 그런 것인지 잘 모르겠지만.. LPM 모듈에 대해서 더 구체적인 설명이 가능하실까요? LPM 모듈이라는 개념을 처음 접해서 그러는데, 기존의 LPM 모듈은 정확한 loss를 측정하는 모듈이고 지금 리뷰해주신 논문에서는 이 LPM 모듈을 정확한 loss 순위 예측으로 변경했다는 것인가요?
그럼 여기서 정확한 loss를 측정한다는 것이 무엇을 의미하나요? label 없는 데이터에 대하여 얼마나 어려운지 uncertainty 같은 것을 계산한다고 보면 되는 것인가요?
그리고 loss 순위 예측이라는 개념은 무엇을 의미하나요? regression이 아닌 classification과 같은 category 형식으로 예측을 했다는 의미인가요?
그리고 RankgerGCN에 대해서도 처음 접해봐서 그런지 “RankCGAN의 Ranker와 LPM은 모두 Loss에서 두 예측 Loss 사이의 값을 활용하지만, Ranker는 순위를 예측하는데 초점을 맞춥니다.” << 의 내용이 쉽게 와닿지 않는데 Rankger와 LPM이 모두 Loss에서 두 예측 loss 사이의 값을 활용한다..? 가 무엇이죠..? 앞에 나오는 loss와 두 예측 loss 이 것들이 각각 무엇을 맵핑하는지 잘 모르겠어서 알려주시면 좋겠습니다리
1. 진짜 ;;; 날라갔네요;;; 이 부분이 빠졌으면 이해하기가 쉽지 않았을텐데 혼동을 드려 죄송합니다.
2-3. Loss를 ranking loss로 변형함으로써 직접적인 Loss를 예측하는 것이아닌 그 상대적인 Loss의 차이 혹은 순위를 예측하는 것입니다. L-Loss에서는 해당 데이터 샘플의 Loss “값”이 무엇인지 집중해서 값을 맞추려고 했다면, 저자가 제안하는 LPM은 Loss 간의 상대적인 순위를 예측하는 것으로 변경되는 것이죠. 이럴 경우 모델이 예측하는 데에 테스크가 쉬워진다는 연구 결과들이 있습니다. 더 많은 이점들이 있지만 실제로 L-Loss에서 LPM을 저자가 제안하는 LPM으로 변경하여 성능 향상을 가져온 것 (ablation study 참고) 을 통해 설득력있는 결과라고 할 수 있을 것 같습니다.
4. 이 부분은 리뷰를 통해 설명을 드리도록 하겠습니다.
4.
안녕하세요 홍주영 연구원님 리뷰 잘 읽었습니다.
질문이 몇가지가 있는데요.
첫번째로 TSNE 시각화 결과를 보게되면 라벨링 여부가 0/1인것 같은데요. 여기서 말하는 결정경계에서 멀리 뽑으면 성능 향상에 도움이 되지 않는다는 것이 이해가 되지 않습니다. 해당 모델은 라벨링 유무를 판단하는 것이지, active learning에서 흔하게 말하는 불확실성에 대해서 이야기 하는 것이 아닌 것 같은데요. 라벨링 유무와 모델의 정확도의 관계에 대한 실험이나 기존의 이론이 따로 존재하나요?
두번째로 Active learning 리뷰를 읽을 때 마다, 랜덤성에 대한 문제를 계속해서 읽었습니다. 해당 방법론이 Labeled와 가까운 데이터를 선별하는 방법이라면 랜덤에 대한 문제가 유독 더 심할 것 같다고 생각이 되는데요. (결정경계가 랜덤에 따라 결정되기 때문) 관련 실험이 있나요?
세번째로 Loss에 notation 달아주시면 이해가 쉬울 것 같습니다.
감사합니다.
1. 일반적으로 성능을 가장 떨어뜨리는 샘플들은 대개 결정경계 근처에 있다는 연구들이 있습니다. 이를 근거로 결정 경계 근처에 있는 샘플을 더 많이 선별할 수 있도록 VAAL을 확장한 것이 해당 연구라고 볼 수 있습니다.
2. 안타깝게도 랜덤성을 다루지는 않았습니다. 제가 최근에 많은 논문에서 랜덤성 혹은 Reliable한 평가와 관련하여 다뤘었습니다. 그러나 제가 오늘 리뷰한 것과 같이 AL 방법론을 제안하는 연구들은 대개 5번 실험 돌린 평균과 표준 편차를 그래프에 표현하는 정도가 전부라고 할 수 있습니다. 이런 연구들이 많아지는 탓에 그런 랜덤성과 같은 이슈들을 다룬 논문들이 발표되고 있습니다.
3. 좋은 피드백 감사합니다. 반영해두겠습니다