[CVPR 2022] Contrastive Learning for Unsupervised Video Highlight Detection
오랫만에 video highlight 연구로 돌아왔습니다.
Introduction
이 분야 연구가 지도학습과 비지도학습 계열로 진행되고 있습니다. 하지만 공통적으로 데이터셋의 크기가 적어서 그에 해당되는 문제점이 계속해서 발생하고 있습니다. 이러한 문제 때문에 학습 데이터셋의 GT가 존재해야하는 지도학습에서의 연구가 한계를 보여서 비지도학습으로 연구가 많이 수행되고 있었고, 성능도 좋은 논문이 등장했습니다. [CVPR 2019] Less Is More: Learning Highlight Detection From Video Duration 제가 리뷰한 적도 있는 논문이니 궁금하신 분들은 보시면 됩니다. 하지만 이 연구는 비공개 데이터셋(Instagram에서 수집)으로 학습 후에 평가가 진행되어 공정한 평가는 아니었습니다. 이러한 맥락에서 추가 데이터를 이용하지 않고 학습을 잘 하기 위해서 contrastive learning을 이용하는 연구에 집중했고, 그 결과가 이 논문입니다.
연구실 여러분들은 SimCLR와 같은 self-supervised contrastive learning 방법론들에 대한 리뷰를 읽으셨을테니… 그 부분을 떠올리면서 생각을 해보면 visual transformation을 적용하면서 학습을 진행하는 것이 일반적이라고 딱 생각 나실겁니다. 하지만 대상이 이미지가 아니라 텍스트일 경우에는 이러한 변화를 주는 것이 모호해서, dropout만을 적용해도 성능이 오른다는 연구 결과가 있다고 합니다. 이미지(Visual)를 활용하는 이 연구에서는 오히려 텍스트 기반 연구에서 motivation을 얻어 변형된 transformer encoder layer에 dropout만 적용된 간단한 unsupervised 모델을 제안했습니다.
왜 visual transformation으로 하는것이 아니라, text에서 영감을 받아 dropout만을 적용하는지에 대한 개인적인 생각을 조금 붙이자면… 우선 학습 데이터가 매우 제한적입니다. 따라서 SimCLR와 같은 방법론처럼 다양한 transformation(augmentation)을 적용해도 그에 대응되는 비디오가 존재하지 않을 뿐더러, generalization이 더 잘 된다고 보기도 어렵다고 판단한 것 같습니다. (오히려 한정된 비디오만 잘 보면 되기 때문) 물론 visual transformation을 적용한 비교 실험이 없어서 알 수는 없지만 이런 맥락이 있지 않았을까 싶네요. (물론 VTW라는 데이터셋 실험에서도 성능이 오르긴 했습니다.)
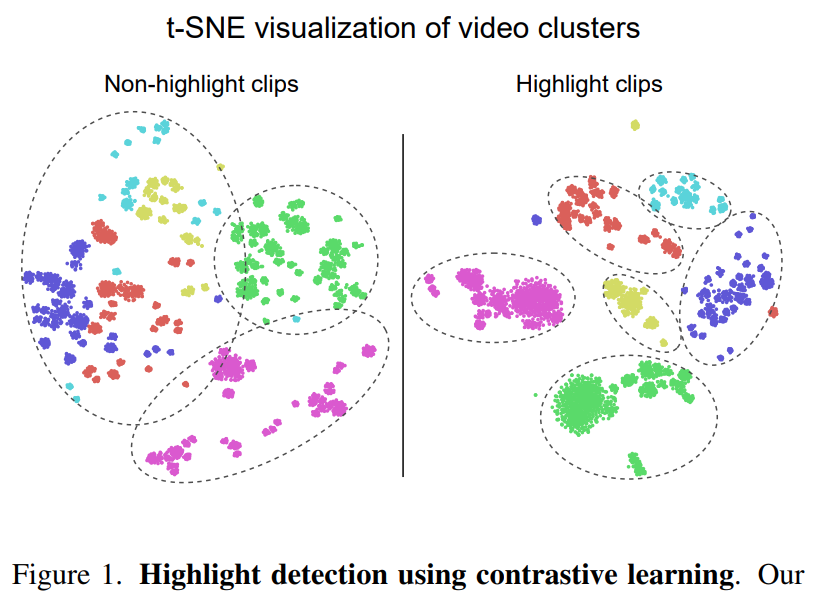
아무튼 다시 본론으로 돌아와서…. 이 논문에서는 비디오를 클립으로 나누고, 비디오에서 하이라이트인 클립을 고르면 되는데요. 저자들은 하이라이트 클립을 비디오 내에서 정보량이 더 많은 클립이라고 정의했습니다. [그림 1]은 하이라이트가 아닌 클립의 T-SNE와 하이라이트인 클립의 T-SNE를 보여주고 있습니다.
하이라이트가 아닌 클립들은 클러스터 형성 자체가 안되고 있습니다. 반면에 하이라이트인 클립들은 구분력을 가진 상태인 것을 확인할 수 있습니다. 논문 저자들은 이러한 시각화 결과에서 contrastive learning을 잘 수행하면, 모델이 하이라이트 클립을 잘 고르도록 학습할 수 있다고 주장합니다. 하지만 비디오 내에서는 하이라이트 클립과 하이라이트 클립이 공존하고 있는데, 따로따로 시각화한 결과가 올바른 분석인지 의구심이 들 수도 있는데요. 이 부분은 뒤에 [그림 2]의 설명과 분석 파트(”Why Does It Work?”)에서 자세하게 다룹니다.
Our Approach
우선 비디오를 클립(고정 크기)로 나눕니다. 각각의 클립은 v_i \in \R^d (C3D와 같은 백본을 사용하는데, 데이터셋에 따라 다르게 사용)으로 표현되고, 비디오는 V = \{v_1,...,v_N\}으로 정의됩니다. 이 TASK의 목적은 clip 단위의 하이라이트 스코어를 계산하는 것이고, 이 스코어는 S = \{s_1,...,s_N\}으로 정의됩니다. 그리고 스코어는 결국 attention score(Transformer에서 쓰는)를 쓰기 때문에, attention score \alpha = \{\alpha_1,...,\alpha_N\}가 스코어가 됩니다.
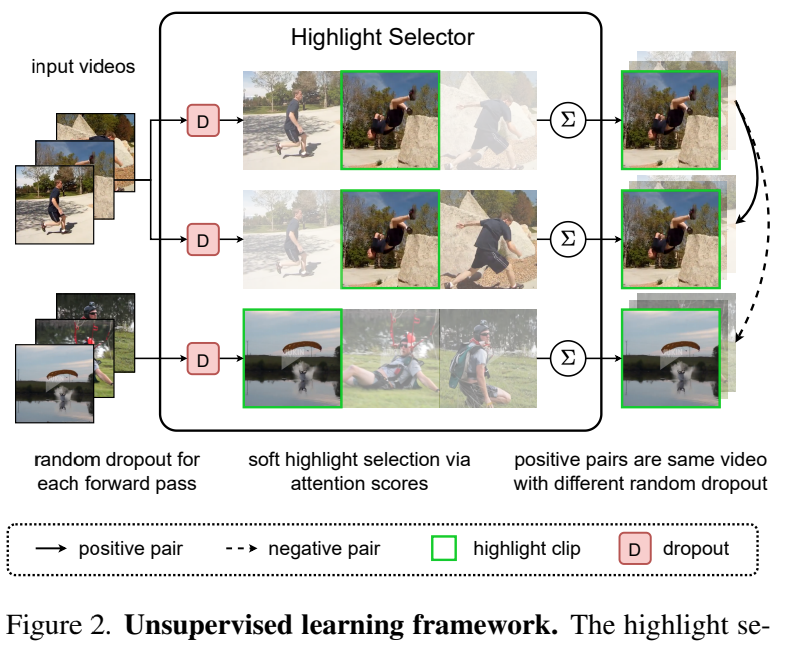
Notation은 이정도면 됬고, Contrastive learning framework를 수행하는 개략적인 과정은 [그림 2]를 통해 확인할 수 있습니다. Anchor와 Positive가 될 input video내에서 dropout을 거쳐는데요. Dropout은 비디오 내의 특정 클립을 랜덤으로 빼는 augmentation입니다. 이렇게 약간 서로 달라진 비디오에서 Highlight Selector에서 하이라이트 클립을 선정하고, (색이 흐린 정도가 Highlight 점수가 높고 낮음을 나타냅니다.) 최종적으로 Contrastive Learning은 이렇게 선정된 Highlight 클립 끼리 수행합니다. 결론적으로 학습은 구분력을 가질 수 밖에 없는 하이라이트 클립 끼리만 수행되기 때문에 [그림 1]과 같은 분석이 올바른 분석임을 알 수 있습니다.
Generic Attention Layer
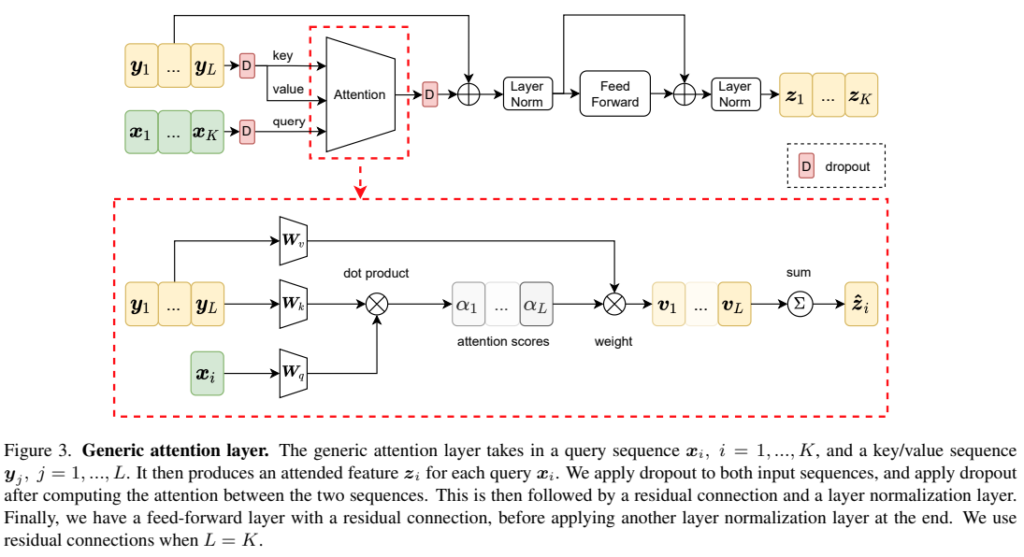
Generic attention layer는 Transformer Encoder Layer라고 보시면 됩니다. 차이점은 Dropout 레이어의 차이만 있는데요. [그림 3]을 보면 입력 데이터를 처리하는 Dropout 하나, 그리고 Attention 레이어를 거친 데이터에 Dropout이 하나 추가되어 있습니다. 입력 데이터 X, Y에 적용되는 Dropout은 각각 Multi-head attention 레이어의 Query, Key, Value로 사용됩니다. 이때 Key, Value에 적용되는 Dropout은 서로 다른 Dropout이 적용됩니다.
사실 그림에서 전반적인 구조가 모두 그려져 있어 따로 설명하는건 불필요 할 것 같고, Multi-head attention 레이어에서 attention score를 계산할 때 \alpha_{ij}=softmax(q_i\cdot{}k_j)라는 것만 빠져있어서 그 부분만 참고하면 될 것 같습니다. 마지막으로 그림을 보면 residual connection이 있는 곳을 찾을 수 있는데 비디오의 길이가 다를 경우에 이 구조는 사용하지 않았다고 합니다.
Highlight Selector
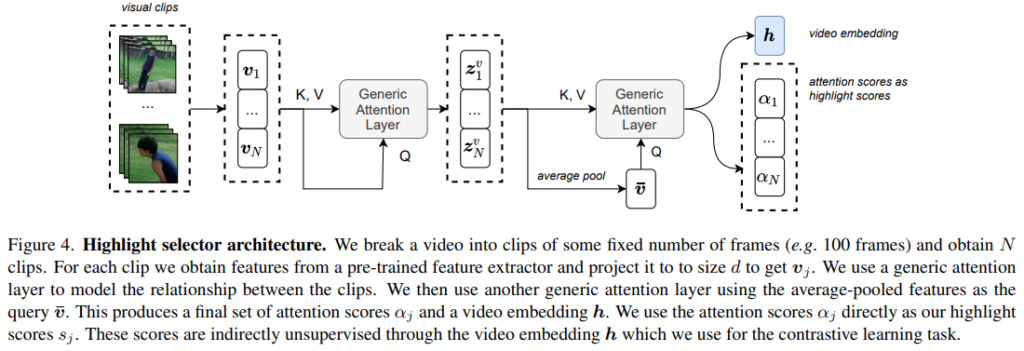
Highlight Selector가 앞서 설명한 Generic Attention Layer를 사용하는 이 논문에서 제안하는 모델이라고 보시면 되는데요. 이 highlight Selector는 video embedding h와 attention(highlight) score를 반환합니다.
전반적인 과정은 Generic Attention Layer 두개를 붙인 구조고, 작동 원리야… 위에서 설명이 되어 있으니 참고하면 좋을 것 같습니다. 다만, 두번째 Generic Attention Layer의 Query의 입력이 다릅니다. 첫번째 Generic Attention Layer는 Negative의 역할을 하는 비디오가 Query였지만, 두번째 레이어에서는 그럴 수가 없으니, \bar{v} = \frac{1}{N}\sum_{i=1}^{N}{z_i^v}와 같이 average pooling을 적용해서 일종의 video-level feature로 만들어서 Query로 사용합니다.
사실 논문에 디테일이 너무 없어서… 코드를 좀 보고싶은데 코드 공개가 아직도 안되어있네요. 최종 video embedding h는 contrastive learning에 사용하고, attention score \alpha는 예측 스코어로 활용합니다.
Contrastive Learning
학습 자체는 SimCSE 프레임워크(텍스트 기반 contrastive learning 방법) 기반으로 수행됩니다. Transformation은 Dropout만 적용합니다. Positive video에는 서로 다른 마스크의 dropout 레이어를 적용하기 때문에 두개의 dropout mask m_l, m_l^{'}가 존재합니다. 이렇게 서로 다른 dropout mask가 적용된 positive pair가 \{h_l^{m_l}, h_l^{m'_l}\}라고 할 때, negative video는 h_k라고 정의됩니다.
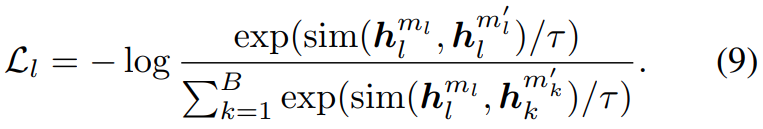
이 때 [수식 9]와 같은 Loss를 사용합니다. 유사도는 cosine similarity를 사용하고, 당연히 positive 끼리는 유사도가 높아지고, negative와는 줄어드는 방향으로 학습을 수행합니다.
Why Does It Work?
원래는 이 파트가 실험 이후에 등장하는데, 방법론도 간단한데 어떻게 CVPR에 붙었을까 고려해봤을때 분석 내용이 많은 기여를 했다고 생각해서 여기서 설명하고 실험으로 가겠습니다. 간단한 구조로 “왜”라는 부분을 설명하기 위해서 Generic Attention Layer를 한개만 가진 모델을 2개 설계했습니다.
- Highlight만 찾는 모델
- Non-Highlight만 찾는 모델
이 두 모델을 가지고 각각 분류 실험을 수행합니다. 이 학습에서 보고자 하는 것은 contrastive learning을 통한 highlight detection이 과연 잘 작동하는지에 대한 가능성을 보고자 했는데요. 만약 학습이 잘 되었다면, embedding된 video-level feature가 intra-cluster에서는 거리가 작아지고, inter-cluster에서는 거리가 멀어져야 한다는 결과를 얻을 수 있습니다.
[그림 1]의 정량적인 실험버전이라고 보시면 되는데요. 이러한 논리에 따라 Intra-distance와 Inter-distance를 정의하여 실험을 수행합니다.
- Intra-cluster distance
- k:\bar{h_k} = \frac{1}{N}\sum_{i=1}^{N}h_{ik}
- intra-cluster ⇒ \frac{1}{N}\sum_{i=1}^{N}dist(h_{ik}, \bar{h_{k}})
수식으로는 위와 같습니다. 클러스터가 얼마나 조밀하게 모여있는지를 측정하는데요. (작을수록 좋음) k가 이제 클러스터의 중심점(평균)을 계산한 값이고, 이 중심점과 나머지들의 거리를 계산해서 intra-cluster를 계산합니다.
- Inter-cluster distance
- inter-cluster ⇒ \frac{1}{M}\sum_{j=1, j\neq k}^{M}dist(\bar{h_{k}}, \bar{h_{j}})
Inter-cluster는 각 클래스별로 서로 얼마나 떨어져 있는지 측정하는데요. (클수록 좋음) 각 클러스터의 중심점끼리의 거리를 측정합니다.

해당 실험 결과가 [표 6]입니다. 성능을 보면 모든 데이터셋에서 하이라이트를 예측하는 모델이 더 좋은 성능을 보이는 것을 확인할 수 있습니다. 이런 분석과 [그림 1]을 함께 고려해보면 결국 모델은 하이라이트를 찾으려고 노력하기 때문에, contrastive learning이 가능하다는 것을 증빙합니다.
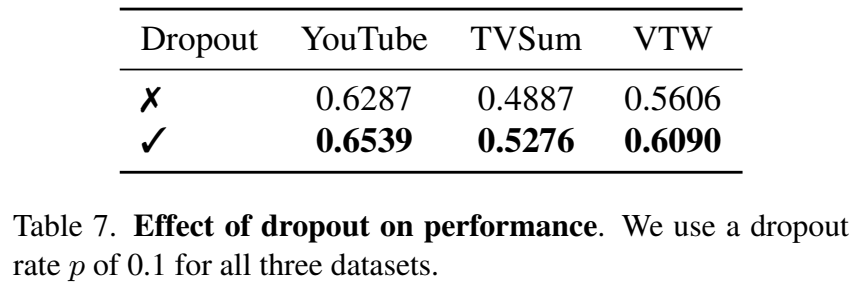
그리고 Dropout에 대한 실험도 확인해볼 수 있는데요. 모든 경우에서 Dropout이 있는 경우 성능이 크게 증가하는 것을 확인할 수 있습니다.
Experiments
실험에서는 3가지 데이터셋을 사용합니다. YouTube 데이터셋과 TVSum 데이터셋, 그리고 마지막으로 VTW(Video Titles in the Wild) 데이터셋입니다. 다른 데이터셋은 비교적 많이 사용되는데 VTW 데이터셋은 비디오 캡셔닝 데이터셋(?)입니다. 사실 저도 처음봐서 이걸 왜 쓰는지는 모르겠는데 비교적 대용량에 구간 정보가 있기는 해서 사용하는 것 같네요.
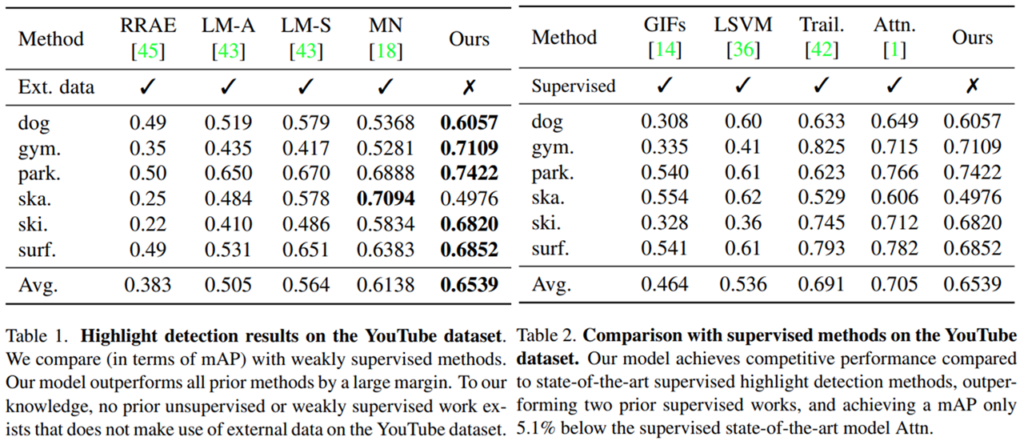
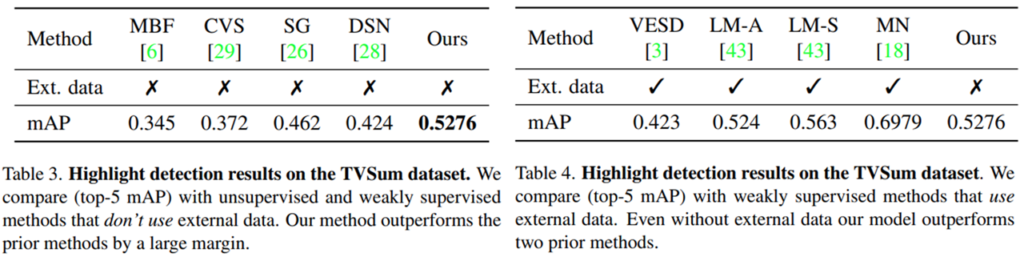
두가지 데이터셋에서의 실험 결과를 보면 위와 같습니다. Unsupervised에서 보게 되면 모든 경우에서 높은 성능을 보입니다. 심지어 추가 데이터셋으로 학습하는 방법론들보다 훨씬 더 높은 성능을 보이는 것을 확인할 수 있습니다. 지도학습에서는 성능이 떨어지지만… 그래도 추가 학습 데이터셋이 없는 비지도학습 계열의 높은 성능이 방법론의 참신함을 증명하는 것 같습니다.
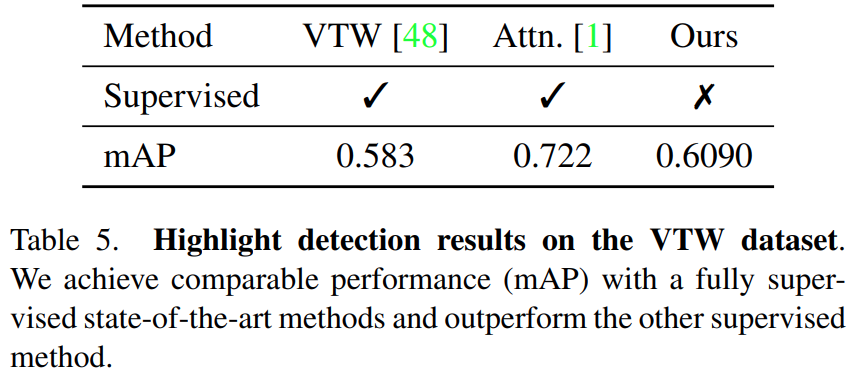
VTW에서는 비교군이 많이 없어서 지도학습과 비지도학습을 한번에 비교할 수 밖에 없었는데요. VTW가 사람들이 개인 장치를 이용해서 촬영해서 다양성이 매우 높습니다. 이런 상황에서도 데이터셋이 베이스라인 모델 대비 성능이 올랐다는 점에서 일반화 능력이 있긴 하다는 점을 보입니다.

정성적 결과는 위와 같습니다. 참고용으로 보면 좋을 것 같습니다.
Conclusion
모델이 간단하지만, 해당 분야에서 새로운 방향 제시를 했다는 점에서 높은 점수를 받은 것 같습니다.
좋은 리뷰 감사합니다.
비디오에서 클립 단위의 dropout만을 적용하여 contrastive learning을 수행함으로써 highlight의 표현력을 학습하는 것으로 이해했습니다.
표 7의 실험에서 dropout을 적용하지 않는 경우의 성능도 리포팅하고 있는데, 이 때의 dropout은 positive pair를 생성해낼 때의 dropout을 의미하는 것인가요?
Positive pair / Negative Pair 양쪽 모두의 Dropout 미적용시의 성능입니다.
좋은 리뷰 감사합니다.
혹시 비디오의 길이가 다를 경우에 residual connection 구조를 사용하지 않는 이유를 설명해주실 수 있나요? 또한, residual connection이 이 논문에서 제안된 구조라면 사용 여부(비디오 길이가 같을 경우에)로 실험한 결과는 없는지도 궁금합니다.
여기서 residual connection을 못쓰는 것에서 길이가 다르다는 말은 positive 비디오와 negative 비디오의 길이가 다른 경우를 말합니다. (정확하게는 key – query 길이 다른 경우) 왜 안되는 것은 비디오의 길이가 다를 때, attention 연산을 거치고 나면 길이가 달라져서 잔차를 계산할 수 없어서 그렇습니다. 그리고 Residual connection은 Transformer에 원래 있어서 이 논문에서 제안한건 아니라 해당 실험 결과는 없습니다.