안녕하세요. 다섯 번째 X-review입니다. 해당 논문은 ViT(Self-attention)를 Augmentation 에 적용한 방법론을 담은 논문으로, 단순히 ViT 관련 논문 서베이 중 제목이 끌려 읽게 되었습니다. 그럼 시작하겠습니다.
Introduction & Related work
Mixup을 기반으로 하는 augmentation 방법론 (대표적으로 Mixup, CutMix, PuzzleMix 등이 있습니다.)은 ViT(Vision Transformer) 모델에 효과적임을 보입니다. 이에 대한 스스로의 고찰을 하자면, ViT는 CNN에 비해 일반화된 능력을 가질 수 있도록 하는 Inductive bias가 낮기 때문에, Train 데이터에 편향적으로 학습할 수 있습니다. Inductive bias에 대해서는 일전의 세미나에서도 말씀드렸지만, 모델이 일반화된 능력을 갖도록 하는 일종의 장치와 같습니다. CNN이 고정된 크기의 커널 사이즈를 사용하는 것으로 Locality 정보에 집중할 수 있습니다. 하지만 ViT는 이미지를 특정 크기의 패치로 나눠 모든 패치에 대해 MSA(Multihead-Self-Attention)을 계산하기 때문에 CNN에 비해 Inductive bias가 낮을 수 밖에 없습니다. ViT의 Inductive bias에 관한 고찰은 임근택 연구원님의 ViT 리뷰에서 보다 수학적이고 상세하게 설명되어 있으니, 참고하신다면 좋을 것으로 보입니다.
그러면 기존 Mixup-based augmentation의 문제점은 어떤 것이 있을까요? Mixup 방법은 그렇다 치고, CutMix 방법을 보겠습니다. 아래의 Target 클래스인 고양이 (B)와 Source 클래스인 강아지 (A)가 있을 때, 두 사진을 augmentation한 CutMix 방법에서의 문제점은 고양이 사진에 Source 클래스인 강아지의 얼굴 부분 혹은 몸통 부분 등의 클래스 구별을 위한 의미론적인 부분이 잘려 담기는 것이 아닌 랜덤한 부분이 담기는 것 입니다. 물론 그렇다한들, 예를 들어 강아지 그림이 고양이 그림의 20%에 붙여진다면 분류 신뢰도는 고양이 0.8, 강아지 0.2와 같이 선형적으로 나타나겠지만, 해당 이미지가 갖는 augmentation 효과는 미미할 것 입니다. 이 때 중요한 점으로 강아지의 어떤 부분이 잘려 붙여지든 클래스 분류 신뢰도는 선형적으로 (CutMix된 부분 만큼) 반영될 것이라는 점 입니다. (CutMix 방법론 논문은 읽지 않았던 점에서, 이번에야 알게 되었네요ㅎㅎ)
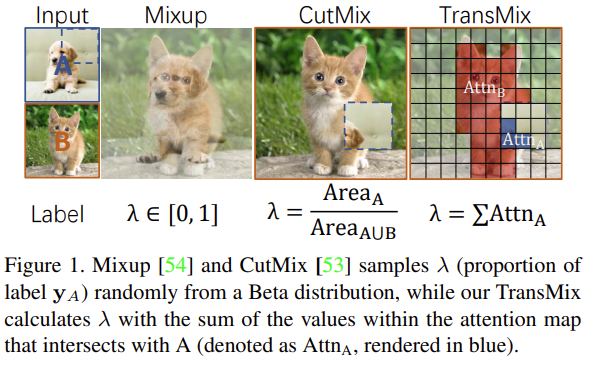
저자는 위의 점을 문제점으로 삼아 ViT의 attention map을 토대로 이미지를 섞는 방법을 소개합니다. 기존의 CutMix 방법론이 위의 예시에서와 같이 Label space를 선형적으로 가져가는 것과 달리, ViT의 attention map을 사용하면 패치마다의 Label space를 고려할 수 있어 이미지를 섞는 과정에서도 그리고 augmentation을 통한 학습에서도 효과적일 수 있다고 주장합니다. 당연한 말일 수 있지만 ViT 기반 방법론에서는 추가적인 연산 등이 필요없으며 해당 Augmentation 방법을 사용했을 때 ViT 모델 기반 ImageNet 분류 문제에서 좋은 성능을 보일 수 있다고 말합니다.

그렇다면 기존의 MixUp, Cutout, CutMix augmentation을 살펴보겠습니다. 먼저 Mixup은 Source 이미지 (여기서는 고양이를 의미합니다)와 Target 이미지 (여기서는 강아지를 의미합니다)를 반반 섞으니, Label이 반반으로 변합니다. Cutout은 Source 이미지 없이, Target 이미지에 랜덤한 마스크를 생성하여 이미지의 일정 부분을 잘라내는 방식을 사용합니다. 하지만 이 방법은 Label의 Confidence score를 낮추지는 않습니다. CutMix는 Cutout과 동일하게 랜덤한 마스크를 생성하지만, 해당 마스크에 Source 이미지를 붙여 Confidence score를 선형적으로 변환시킵니다. (Source 이미지 내 Target 이미지의 비율을 따라갑니다).
해당 augmentation 방법론들은 overhead가 크지 않게 (실제로 #Params는 44.6M으로 모두 동일합니다) 성능 향상을 보여줘 좋은 방법론으로 소개되지만, 위에서 소개된 것과 같이 CutMix는 랜덤한 마스크 내 씌여진 Source 이미지 내 Object가 존재하는지에 상관없이 augmentation이 수행됩니다. 만약 위의 예시에서 고양이 부분이 하나도 없이 배경 부분만 씌였다 하더라도, Label은 선형적으로 변환되겠지만 입력 이미지는 고양이와 상관 없는 부분이 보여질 것이므로, 모델은 입력 이미지 내 고양이에 해당하는 부분에 대응하는 Label이 적절히 형성되지 않은 채 학습할 것이기 때문에 성능이 하락할 수 있습니다.
![PDF] SaliencyMix: A Saliency Guided Data Augmentation Strategy for Better Regularization | Semantic Scholar](https://d3i71xaburhd42.cloudfront.net/29e34b721a72357ab83717643c1566f977e6a761/4-Figure2-1.png)
이를 해결하고자, SaliencyMix와 같은 augmentation 방법론들이 소개되었습니다. SaliencyMix는 픽셀 값의 변화가 급격한 부분을 모은 Saliency Map을 통해 Object에 해당하는 부분을 CutMix의 Source 이미지로 잡는데, SaliencyMix 방법은 Target이미지 내 Object 영역에 대해 보다 정확히 잡을 수 있으므로 이전 CutMix 방법의 문제점을 해결할 수 있습니다. 하지만 이는 Saliency Map을 생성할 때 Backpropagation을 통한 Gradient를 활용하므로, Parameter의 증가로 인한 연산량의 증가를 불러온다는 단점이 존재합니다.

다음으로 소개할 PuzzleMix는 이미지를 패치로 나눠 Puzzle로 섞고, Saliency Map을 통해 Augmentation을 수행합니다. Saliency 정보를 보존하며 섞기 때문에, 위 이미지에서 뱁새의 모양에 Attention을 주면서 붙여진 것을 볼 수 있습니다. 이 또한 Saliency Map을 사용한다는 이유로 인하여, Forward & Backward 연산으로 인한 연산량의 증가를 문제점으로 꼽습니다.
3. TransMix
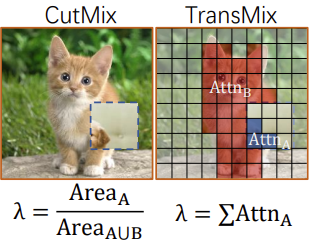
기존 CutMix 방법의 문제점을 개선한 TransMix는 ViT의 Attention map을 기반으로 동작합니다. 위 그림의 그리드는 ViT의 Image Patch이며, 마스크는 CutMix와 동일하게 랜덤한 비율로 생성되지만 각 패치가 Label에 미치는 영향을 고려하여 Mask의 Attention Map을 dot product해서, object가 존재한다고 생각되는 (Attention score가 높은) 마스크의 패치에 대해 Label에 가중치를 줍니다. 이렇다면 기존 CutMix에서 Source 이미지인 내 Object 영역에 해당하는 부분에 대해서는 높은 가중치를 받을 수 있어, SaliencyMix와 PuzzleMix의 장점을 가져갈 수 있을 뿐더러 ViT 방법론에서는 추가적인 연산이 필요없기 때문에 효과적으로 보입니다.
그렇다면 해당 방법은 어떻게 수학적으로 보일 수 있으며 Pseudocode는 어떻게 구현될까요? 아래를 살펴보겠습니다.
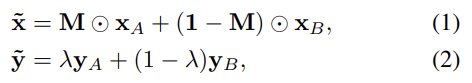
먼저 위의 수식 (1), (2)는 기존 CutMix를 나타냅니다. 수식 (1)에서 M은 H*W로 이미지의 크기지만 Binary 형태로, 즉 어느 부분은 Source 이미지가, 어느 부분은 Target 이미지가 사용되는지를 나타냅니다. 해당 M을 통해 그 비율을 따라 그대로 람다를 정하여 수식 (2)로 정해질 수 있는데, 이 때 y_A, y_B 는 각각 x_A와 x_B 이미지의 Label을 의미합니다. CutMix는 수학적으로 굉장히 간단하군요. 다음으로는 TransMix 입니다.
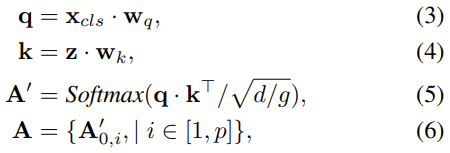
TransMix는 ViT 기반이므로, ViT의 Q, K 생성 과정을 알고 있다면 큰 어려움은 없습니다. 물론 Query에 대해서는 x_{cls} 를 W_q 에 곱하여 생성하며, Key는 Patch Embedding을 나타내며 W_k 와 곱해져 생성됩니다. Q, K를 이렇게 생성한 이유는 간단하게 이미지를 패치로 나눴을 때 패치 별 클래스 신뢰도를 나타낸다고 볼 수 있는데, 역시나 마찬가지로 이를 곱하고 ( q \cdot k^T ), dimension을 Multi-head 수인 g로 나눈 값으로 나누어 계산합니다. 이렇게 g로 나누는 이유는 A를 [0,1]으로 포함시킬 수 있다고 저자는 말합니다( 이 부분에 대해서는 후에 다시 내용을 보충하겠습니다 ). 마지막으로 수식 (6)의 A는 각 패치마다의 Attention의 집합으로 표현하여 이미지 패치 별 Attention Score를 계산합니다.

마지막으로 마스크 (M)에 위에서 구한 Attention(A)를 곱하는데, 이 때 nearest neighbor interpolation을 통해 downsampling하여 람다를 구한 후, 수식 (2)의 람다에 적용하면 완성됩니다.

논문에서는 Pseudocode를 통해 TransMix 구현 방법을 소개합니다. 잠깐 살펴보자면, CutMix된 이미지를 생성하고, 마스크를 다운 샘플링하고서 모델로부터 얻은 Attention Map(A)에 대해 matmul을 실행하여 람다를 정의하고, 레이블을 정의하고 있습니다.
4. Experiements
해당 논문은 방법론은 간단한 대신, 다양한 실험을 통해 모델의 효용성을 입증합니다.

먼저 정성적인 결과의 첫 번째 행을 살펴보자면 기존 Source Image인 Image A가 Target Image인 Image의 40%에 해당하여 기존 CutMix 방법에서는 Mixed Image의 Confidence score가 A는 40%, B는 60%인것에 비해, TransMix는 Attention Score를 기반으로 하기 때문에 Attention을 많이 받는 A 이미지에 대한 Confidence score가 80%로, 역전된 것을 볼 수 있습니다. 다른 결과에서도 단순히 그 비율 때문이 아닌, 이미지 내 Attention이 얼마나 높은지 (Object가 있다고 보여지는 부분이 얼마나 많은지)에 따라 그 비율이 달리되는 것이 흥미롭습니다.
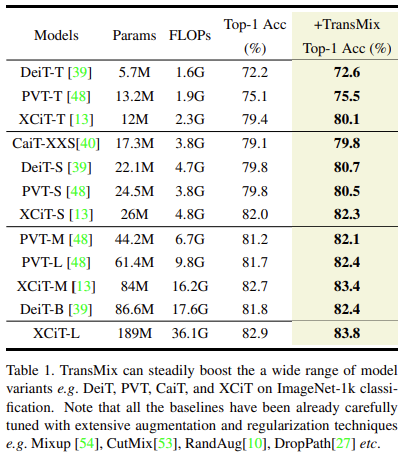
ImageNet-1K 에서의 성능 분석입니다. 당연히도 TransMix의 성능이 가장 좋다고 보여지며, 저자들은 각 모델들의 하이퍼파리미터들을 모두 튜닝하여 원복한 후 TransMix만을 적용했을 때, 사이즈 상관 없이 (패치 사이즈를 의미합니다 ) TransMix를 적용했을 때 괜찮은 성능 향상을 보입니다.
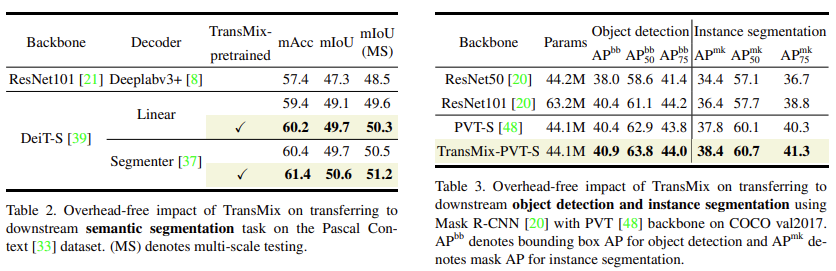
다음은 downstream task(semantic segmentation, object detection) 시의 성능 비교입니다. 저자들은 TransMix가 Attention Map을 기반으로 Label space를 잘 구성하고 있기 때문에, Semantic한 정보를 잘 학습할 수 있을 것이라고 기대했고, 따라서 downstream task에서의 성능 향상을 기대했습니다. Pascal Context dataset을 사용한 Segmentation과 COCO dataset을 사용한 Object detection에서 이전과 같이 일반화된 성능 향상을 보입니다.
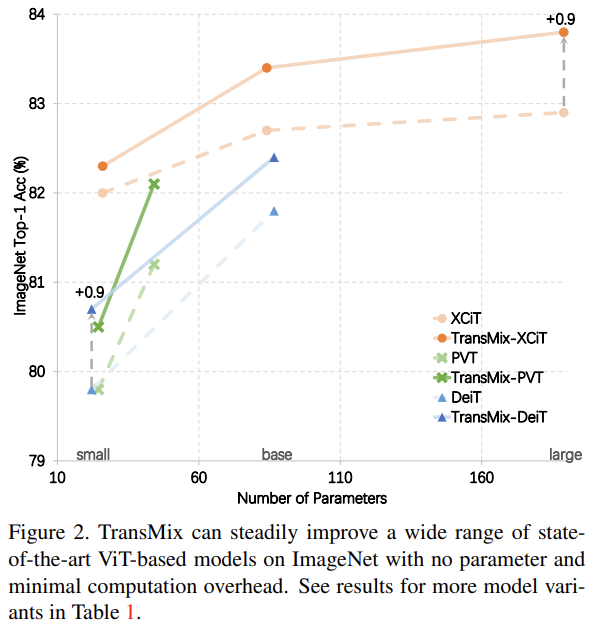
마지막으로, 위의 그림을 보면 XCIT, PVT, DEiT에서 모델의 종류와 상관 없이 꾸준한 성능 향상을 보입니다.
5. Conclusion
저자의 한계점에 대한 고찰을 보자면, TransMix의 Query는 결국 class token이기 때문에, Swin Transformer와 같이 백본이 Class token을 사용하지 않는다면 TransMix를 사용하기 쉽지 않습니다. 또한 Attention Map이 Spatially하게 aligned 되어야하며, CutMix를 통해 이미지의 Sharpness가 커질 것이고, 따라서 해당 마스킹된 부분에 대해 ViT가 Attention과는 상관 없이 (그렇게 안하고자 설계를 했음에도 불구하고) 집중해버릴 수 있다는 문제입니다.
저는 이와는 별개로 결국 ViT 방법론이 아니라면 못 쓰는 방법이 아닌가 생각이 들지만, 그래도 이번 논문을 읽으며 주목한 점으로는 ViT의 Attention을 토대로 Augmentation 방법론에 추가하는 것은 지금 생각해보면 간단한 아이디어임에도, 그것을 잘 구현하여 CVPR에 붙은 정도로 봐서는 … 아이디어는 멀리 있지 않은 것 같습니다. 금일 세미나에서 조금 더 자세히 살펴보도록하고, 여기서 마치도록 하겠습니다.
리뷰 잘 읽었습니다.
리뷰를 읽으며 헷갈리는 부분이 있는데, 그럼 이 TransMix라는 것은 ViT 기반 pretrained model을 활용하는 방식이 아니라, 지금 학습시키고자 하는 ViT 모델에 한해서 학습 진행 과정동안 augmentation 용 Attention map을 따로 생성한다고 이해하면 되는 것인가요?
그리고 논문에는 해당 방법론을 적용하면 학습 시간 또는 GPU 메모리 증가가 얼마나 일어나는지 등은 없나요? 그리고 테이블 1이 다른 augmentation과의 비교 실험이라고 볼 수 있는 것인가요? 그냥 TransMix가 적용되냐 안되냐의 차이를 결과로 보인 것 같은데, 리뷰 글에서는 table1에 대한 설명을 할 때 다른 augmentation 기법들 보다 TransMix가 가장 좋은 성능을 보인다는 식으로 설명이 되어있어서요.
실제로는 이미 mixup, cutmix 등의 augmentation이 들어간 방법론들에 대해 TransMix만을 더 추가로 붙여서 학습시킨 것 같은데, 실제로 augmentation 효과를 비교하기 위해서는 CutMix, TransMix, Mix up 등등을 따로 적용해서 성능 평가를 비교해야하는 것이 아닐까요?
먼저 리뷰 읽어주시고 질문 남겨주셔서 감사합니다.
첫 번째 질문에 답변드리자면, 생각해봤을 때 일반적인 ViT 기반 pretrained model을 활용하는 방식도 가능할 것으로 보입니다. 하지만 그렇다면 Pretrained된 모델을 활용하여 Attention map을 생성해야 하는 과정 즉, 추가적인 연산량 증가로 인해 “우리 방법은 ViT 모델에서 어짜피 생성되는 Attention map을 augmentation에 적절히 활용할 수 있기에 연산량 증가도 없는 유용하고 적합한 방법이다”라는 저자의 주장이 퇴색될까봐 해당 언급이 없지 않았을까하는 생각이 듭니다. 그러므로 지금 학습시키고자하는 모델이 ViT 기반 모델일때, 모델에서 나오는 X_cls와 Patch Embedding을 그대로 활용할 수 있기에 ViT 모델에 한해 augmentation용 Attention map을 생성한다고 보는 것이 더 적합하지 않을까 싶습니다. 논문을 읽은 기억에서는 없었지만, 이에 대해 논문을 다시 한번 살펴보고 다시 답변드리도록 하겠습니다.
두 번째 질문에 대해서는, Params는 DeiT와 비교했을 떄 22M으로 동일합니다. 해당 표를 다시 첨부하여 수정하겠습니다만, 미리 살펴보자면 CutMix 기반 방법론이기 때문에 위에서 소개해드린 CutMix, SaliencyMix, Puzzle-Mix와 비교했으며 모두 22M으로 파라미터 수는 동일하지만, 성능은 TransMix가 다른 방법론 대비 최대 0.9% 높은 것을 알 수 있습니다. 저도 해당 표가 중요하다고 생각이 들었는데, 내용에서 빠트려 먹은 것 같네요.. 또한 해당 표는 학습 시간으로 비교를 진행하는데, 표를 보면 TransMix의 방법론은 Baseline인 DeiT와 동일하게 322 (im/sec)인 것을 확인할 수 있습니다.
좋은 질문 감사합니다. 빠트린 내용에 대해서는 세미나 준비하며 다시 체크해보도록 하겠습니다.
안녕하세요. 좋은 리뷰 감사합니다.
Mixup을 기반으로 하는 augmentation 방법론은 ViT 모델에 효과적임을 보인다는 이유로,
ViT가 CNN에 비해 일반화된 능력을 가질 수 있도록 하는 Inductive bias가 낮기 때문에
Train 데이터에 편향적으로 학습할 수 있기 때문이라고 하셨는데, 사실 Inductive bias가 낮은 것이
왜 Mixup기반 augmentation 방법론이 ViT 모델에 효과적인 이유가 되는지 이해를 잘 못했습니다.
ViT 모델이 입력 이미지를 패치 단위로 처리하는데, Mixup을 적용하여 새로운 이미지를 생성하면 그 이미지는 패치 위치나 크기는 바뀌지 않고 패치 내부 값만 바뀌게 되기 때문에 ViT가 Mixup 기반
augmentation 방법론에 민감하게 반응한다고 이해해도 괜찮을까요 ?
감히 보충 설명을 부탁 드리겠습니다.
감사합니다.
우선적으로, MixUp 기반 Augmentation 방법론과 Inductive Bias의 상관성에 대해 말씀해주셨는데, 이는 CNN의 특징을 토대로 살펴보면 좋을 것 같습니다. 단순히 Cut-Mix와 같이 이미지의 패치를 붙이는 방식은 CNN에서 Class의 Confidence Score가 Linear한 차이를 보입니다. 따라서 Mixup 방법의 Agumentation이 CNN보다 ViT 기반 모델에서 효과적일 수 있다고 생각합니다.
윤서님의 의문에 대해 충분히 이해가 되며, 밑단의 이해가 논문 전체적으로 옳은 이해입니다.