♞proposed
A fresh interpretation on the KullbackLeibler (KL) divergence term of the variational lower bound for Gaussian mean-field approximation. From this discovery, they proposed a new Bayesian online learning framework for continual learning dubbed Uncertainty-regularized Continual Learning (UCL).
♞prior knowledge
incremental/continual learning(이하, continual learning, CL)
새로운 태스크에 대한 연속적인 학습으로 기존의 지식을 보존하며 태스크 추가를 가능하게 하는 학습방법인 incremental, continual learning의 학습 방법론은 크게 3가지 방식으로 나뉜다: regularization-based, dynamic network architecture-based, dual memory system-based 그 중 regularization-based은 가장 대표적인 방법으로 네트워크의 업데이트에 제약을 주어 continual learning(CL)의 stability-plasticity dilemma*를 해결하는 접근법이다. 일반적으로 deep learning 모델이 overparameterlized되었다는 것은 잘 알려져 있다. 이러한 deep learning 모델의 맹점을 해소하기 위해 파라미터가 중복적이지 않고 하나의 파라미터가 유일한 작동을 하도록 설계를 돕는다는 관점에서 해당 방법론은 네트워크의 자원을 최대한으로 사용한다고 평가된다.
대표적인 방법론으로 2017년 IEEE에 발표된 LwF는 knowledge distillation 방법론을 통해 old tasks model에 대한 output 값을 유지하도록 학습한다. 이 외에도 정규화의 방법을 조절하려는 다양한 방법론이 많이 연구되었으나, 이러한 방법론은 1) 상당한 추가 메모리 비용이 발생한다, 2) new task에 대한 성능을 저해하지 않는 forgetting 대처 방법론의 부재한다는 두가지 문제점이 있다.
* stability-plasticity dilemma: continual learning에서 기학습 모델에 새로운 테스크를 추가하고자 학습을 시도할 때 새로운 도메인 지식에 대한 신경망 가소성과 기존 지식을 유지하려는 안정성 사이에 trade-off 문제를 지칭함
Variational inference
variational inference(변분추론)이란 사후확률을 예측하는 방법으로 딥러닝 모델을 학습하는 과정도 이에 속한다. 논문에서는 변분추론 방법론 중 standard Bayesian learning을 기준으로 하였고 우리가 잘 아는 back-propagation 기반 모델을 학습하는 방법도 이에 속합니다.
♞methods
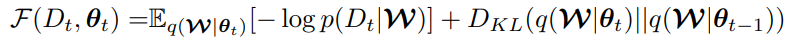
[수식1]은 continual learning setting을 의미합니다. t 태스크에 대해서 데이터셋 D_t를 기반으로 학습된 모델을 학습하는데, 이전 태스크에 대해 학습된 q(θ_(t-1))과 유사한 결과를 갖도록 둘째 term으로 KL을 사용합니다. 또한 현재 데이터인 D_t에 대한 분포를 반영하는 학습이 첫번째 tearm입니다. 논문은 위 수식에서 두가지 문제점을 발견했는데 다음과 같습니다. 1) 변수인 D, 데이터의 갯수에 따라 모델의 연산량이 증가합니다. 2) old model과 current model의 파라미터에 접근하면서 실질적으로는 실제 모델 사이즈의 2배 크기의 모델에 접근해야합니다.
실질적으로 정규화 역할을 하는 KL term(수식2의 두번째 term)이 특히 발견된 문제점을 심화하는데, 논문은 이에 대해 새로운 해석을 도입하여 이를 해결합니다.
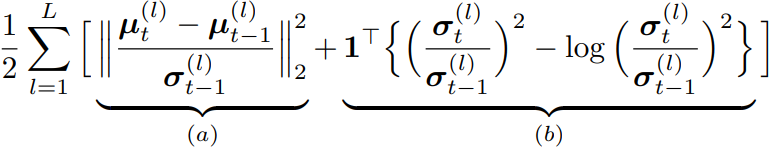
[수식2]는 일반적인 KL-divergence 식입니다. L은 layer의 갯수이며 µ(l)와 σ(l)는 각 레이어의 평균(µ)과 분산(σ)을 의미합니다. (a)는 이전 태스크모델과 현재 모델의 평균에 대한 Mahalanobis 거리를 의미하며 레이어 l의 파라미터의 평균값에 대한 정규화로 작동합니다. (b)는 σ of t와 σ of t−1가 같아질 때 최소화되는 term으로 레이어 파라미터의 분산값에 대한 정규화로 작동합니다. 위의 수식을 각 텀을 기준으로 개선합니다.
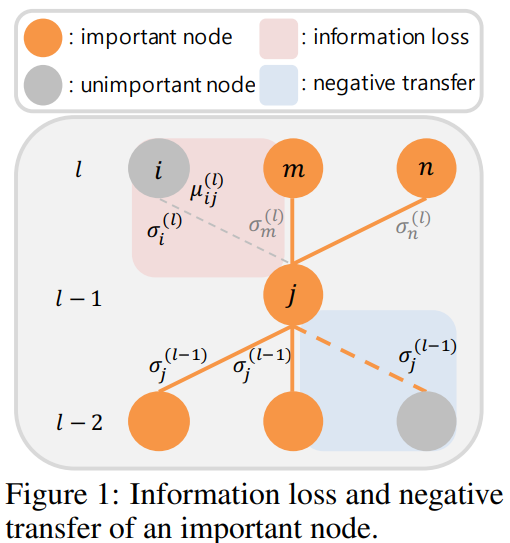
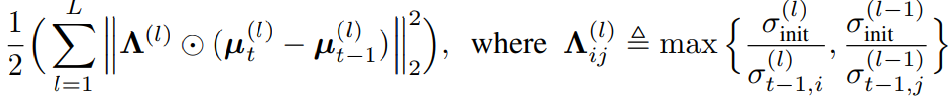
먼저 a 에 대한 개선은 [수식3]과 같습니다 each mean weight parameter가 아닌 a notion of uncertainty for each node of the network를 제안합니다. 이들은 파라미터 단위가 아닌 node 단위(즉 활성함수를 기준으로 나뉘는 단위라고 합니다)로 정규화 하는것이 연산량을 줄일뿐만 아니라 information에 대한 표현 unit의 직접적인 원소라는 점에서 일리있다고 합니다. 이를 수식3을 통해 구현했으며 node 단위로 보았을때 중요도가 낮은 figure1의 파란영역의 중요도를 낮추는 방식으로 하여 연산량을 줄였습니다. 수식을 보면 가중치 조절을 위해 분산값이 이용되는것을 알 수 있는데 연결된 두 노드의 가중치인 σ of t와 σ of t−1 중 큰 값을 기준으로 정규화의 중요도를 결정하게 됩니다. 분산값이 작을수록 모델은 낮은 불확실성을 갖는데 이때가 모델이 잘 학습된 것이므로, 파라미터 변화도가 작도록 높은 정규화 강도를 갖도록 고안한 것입니다.
위의 Λ 뿐만 아니라 µ의 크기(magnitude)별 가중치를 통해 노드의 중요도를 반영하기 위하여 아래의 수식도 (a)에 포함하였습니다. 이러한 수식은 기존 연구에서 영감을 받아 설계되었으며 µ/σ가 가 클수록 해당 weight가 보존되도록 합니다.
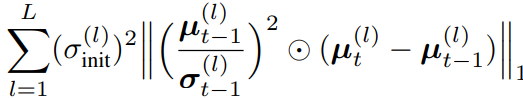
a term에 해당되는 정규화는 catastrophic forgetting 예방에 있어 직접적인 해결책입니다. 그러나 정보량이 적은 파라미터가 발생하는것을 막을 수는 없는데요 이를 해결하기 위해 두번째 term에 정규화 term을 추가하였으며 그 수식은 수식4와 같습니다. 이는 σ of t가 (√2)*σ of t−1가 되도록 하는 term이므로, 이전 태스크의 분산값보다 커지는, 모델의 확신도를 높이는 작업입니다. 노드의 uncertainty가 높으면(확신도가 낮은 불안정한 모델이면) 초기 표준편차는 일반적으로 작습니다. 따라서 제안하는 (6)term을 추가하여 node의 학습을 조금 더 actively 하게 작동되도록 합니다.
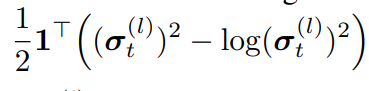
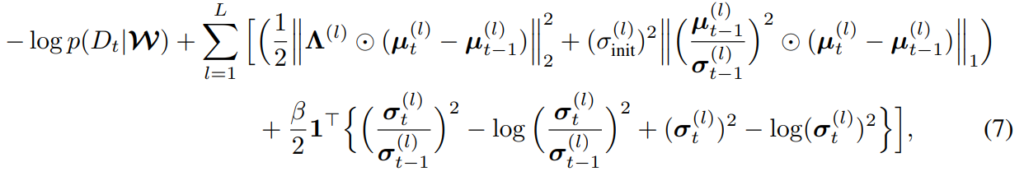
위를 반영한 최종 제안 수식은 수식5와 같습니다
♞evidence
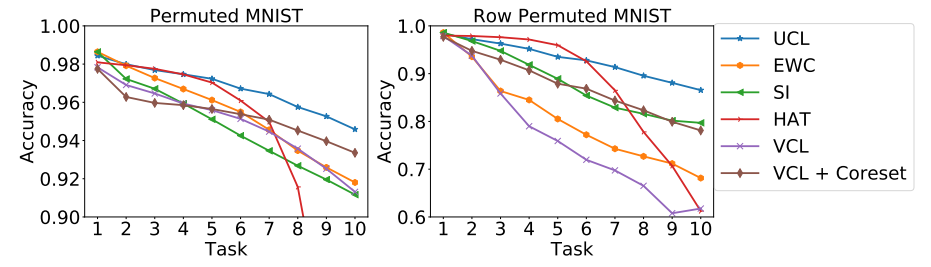
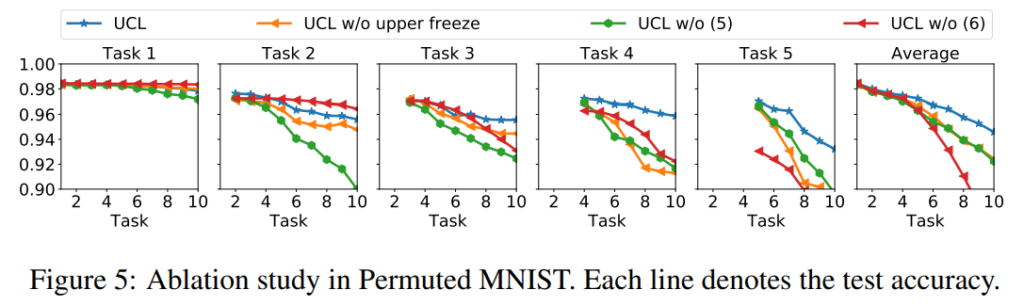
실험은 mnist로 진행하였으며 제안하는 방법론이 task 추가에 따른 성능하락이 완만하여 forgetting을 가장 효과적으로 예방함을 알 수 있습니다. 또한 같은 데이터셋으로 실험한 ablation study를 통해 제안하는 새로운 (a) term(5)과 (b) term이 효과적임을 확인하였습니다.
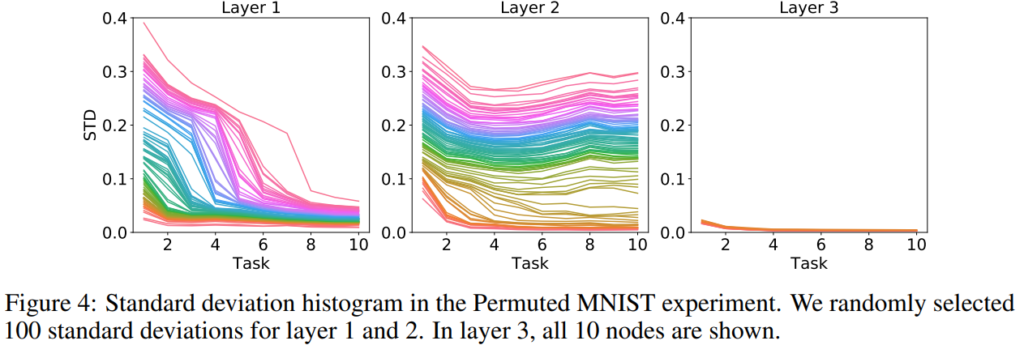
다음은 학습에 따른 node 별 표준편차를 나타낸 것이며 얕은 레이어일 수록 태스크 확장에 따른 표준편차 감소도가 높습니다. 이는 모델이 새로운 태스크에 적응하기 위해 태스크에 대한 확신도를 높이는 경향이 있다는것을 의미합니다. 즉 task spasific 해지도록 학습합니다. 그러나 layer2부터는 비교적 평탄하며 이는 그들이 특정 태스크에 속하지 않는다는것을 의미합니다.
안녕하세요 황유진 연구원님, 좋은 리뷰 감사합니다.
리뷰하신 논문은 그럼 3가지 방향으로 연구되고 있는 CL 중에서 regularization-based을 기반으로 개선시킨 방법론인 것 같습니다. 특히 기존에 정규화 방식으로 흔히 사용되는 KL term을 개선한 방법론인 것 같습니다. (맞나요? 제가 잘못 이해했다면 정정 부탁드립니다)
질문이 있는데요 (1) 비교실험에 사용된 EWC, SI, HAT, VCL, VCL+Coreset은 해당 연구와 동일하게 regularization-based 연구인가요?
(2) 그리고 두번째 해당 방법론이 마치 메모리를 적게 드는 것 같이 이해하였는데, 이 메모리가 적다는 건 어떻게 확인할 수 있을까요?
이해하신 방향이 맞습니다. 질문에 대해 답 드리겠습니다
(1) HAT를 제외하고는 regularization based 방법론으로 볼 수 있으며 HAT는 task에 대한 attention기반으로 합니다
(2) 메모리가 적다기보다는 연산시 연산량이 적다고 이해하시면 될것같습니다. 기존은 old model에 대한 inference를 학습에 사용하였지만 attention 등을 통해 중요 노드만 연산에 적용합니다.