Facebook AI에서 19년도에 나온 VoteNet에 이어 ImVoteNet을 내놓았다. VoteNet은 3d geometry input만을 사용하여 indoor상황에서 다른 rgb-d input을 사용하는 모델보다 좋은 성능을 보였었다. 이때 ImVoteNet은 RGB image를 추가로 활용하여 Detection 성능을 끌어올리려고 했다.
Introduction
RGB image와 3d point cloud는 각각 상호보완적인 특징을 가진다. 먼저 RGB image는 depth image나 LiDAR point cloud보다 높은 resolution을 가지며 많은 texture 정보를 가진다. 또한 active sensor에서 표면에 반사되는 표면에 의해 blind되는 영역도 cover할 수 있다.
반대로 3d point cloud는 RGB image가 가지지 못하는 depth정보를 알 수 있다. 이렇게 RGB image와 3d point cloud의 장점을 모두 활용하는 방법을 고안하게 된다.
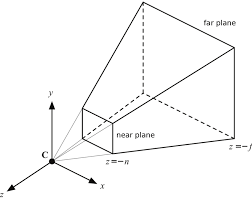
이제 2d image를 3d point cloud와 함께 사용하기 위한 pipeline을 효과적으로 설계하는 것을 고민하게 되는데 naive한 방법으로는 raw RGB값을 projection한 point cloud에 추가하는 방식을 적용할 수 있다. 하지만 3d point cloud의 sparse한 특성으로 인해 image domain에서 dense pattern을 잃어버릴 수 있다. 다른 방식으로는 제한된 frustum형태 공간에서 2d detecor로 proposal을 하는 방식이다. frustum은 아래 그림과 같은 형태로 카메라 시스템의 시야를 보는 것과 같다.
하지만 이런 방식은 3d detection성능이 2d detector 성능에 많이 의존하게 된다. 이후 좀 더 3d detection에 focus를 맞춘 방법이 2d image를 바로 localization에 사용하지 않고, 3d에서 detection을 하는데 보조하는 역할을 하는 방법이다.
본 논문에서는 기존 VoteNet을 활용하여 2d와 3d voting을 합친 3d object detection network인 ImVoteNet을 제안한다.
제안한 모델의 motivation은 2d image에 존재하는 semantic 정보와 texture 정보를 3d point cloud의 geometric한 정보와 함께 사용하는 것이다.
ImVoteNet에서는 2d detection만으로 object proposal을 하지 않는다. 우선 2d image에서 2d box 내에서 image pixel과 2d box center를 연결한 votes들을 생성한다. 그리고 2d votes를 geometric transformation을 통해(camera parameter, pixel depth 활용) 3d로 전달하여 pseudo 3D votes를 생성한다. 이렇게 생성한 3D votes들을 point cloud를 backbone에 태우고 나온 feature들과 concate한 후 3D Hough voting을 해서 object center를 찾고 aggregate하여 3d에서 object detection을 수행하게 된다. 또한 multi-towered network를 사용하여 2d와 3d feature 모두를 잘 활용하는 방법을 적용하였다.
본 논문에서 제안하는 contribution은 아래와 같다.
1. 2d object detection cues를 point cloud based 3d detection pipeline에 fuse하는 geometrical 방법 제안
2. SUN RGB-D에서 sota 달성
3. system을 이해하기 위한 많은 분석과 visualization
Related Work
본 논문에서 제안하는 ImVoteNet은 VoteNet을 기반으로 하여 제안한 voting기반의 방법론이다. VoteNet에 대해 요약해보자면, VoteNet 이전 3d object detector들은 2d image에서 2d detector를 사용해서 object를 localize하였는데 이 경우 geometric details를 잃어버릴 수 있고, 또한 detection 성능이 2d detector에 의존하게 된다는 단점이 존재한다. 따라서 VoteNet에서는 3d point cloud를 input으로 받아 direct하게 사용하여 정보 손실을 줄일 수 있도록한다. 하지만 3d point cloud는 object를 맞고 반사된 정보가 object의 표면에만 point가 나타나는 특징이 있다.
따라서 3d object의 중심 위치(centroid) 정보를 추정할 때 어려움을 겪게된다. 이 문제를 해결하기 위해 voting방식을 통해 object centroid를 효과적으로 찾는 방법을 제안하는 방법론이다. VoteNet리뷰는 지난 번 작성한 아래 글을 참고하면 도움이 될 것 같다.
이에 반해 본 논문에서 제안하는 ImVoteNet은 RGB-D 기반의 방법론이다. RGB-D는 컬러 정보와 Depth정보를 포함하는 데이터로 크게 2D-driven, 3D-driven, feature concatenation 3가지 방식으로 나누어 두 modality정보를 fusion하였다. 먼저 2D-driven의 경우 우선 2d image에서 object detection을 통해 3d space에서 object를 찾는데 guide하는 역할을 한다. 3D-driven의 경우에는 3D space에서 region proposal을 진행한 후, 정확한 prediction을 위해 2d features를 사용하게 된다. ImVoteNet에서는 2d feature와 3d feature를 fusion하는 방식을 사용하였는데, 기존에 fusion방식은 2d feature와 3d feature을 단순히 concatenate하는 방식이었다. 하지만 본 논문에서 제안하는 ImVoteNet의 fusion 방식은 2가지 측면에서 다르다고 할 수 있는데 먼저 2d detector에서 pseudo 3d vote형태로 변환하여 사용하는 방식을 제안하였고, multi-tower라는 architecture를 사용하여 단순히 두 modality feature를 concat하는 것보다 효율적으로 fusion하고자 하였다.
ImVoteNet Architecture
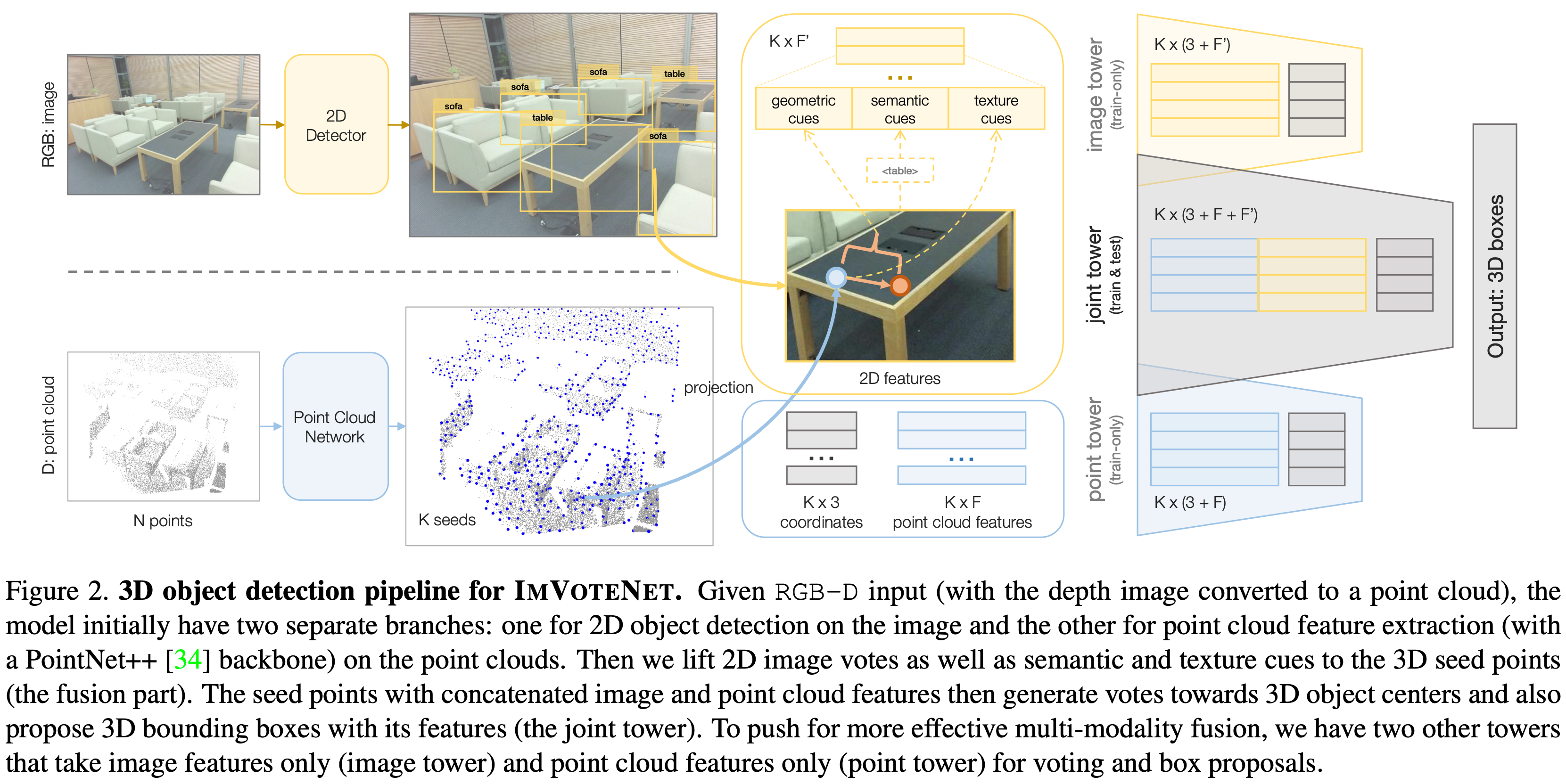
ImVoteNet은 RGB-D를 입력으로 하는 3D object dectection 방법이다. voting방식의 VoteNet을 기반으로 하였고 voting과정에서 geometric정보와 2d image에서의 semantic정보와 texture정보를 활용하였다. RGB-D를 입력으로 받아 각 modality별로 network를 통과시켜 feature 추출하고 2d feature와 3d feature를 fusion한다. 모델의 전체적인 파이프라인은 아래 그림과 같다.
Deep Hough Voting
기존 VoteNet은 3d point cloud를 입력으로 하는 3d object detection로 voting 방식을 제안한 네트워크이다. voting하는 과정은 우선 point cloud에서 의미 있는 points를 sampling하는 과정을 통해 scene points(seeds)를 추출한다. 전체 Nx3의 input points 중 Kx(3+F)의 seeds를 추출한다. 이때 K는 seed의 갯수이고 3은 coordinate값이며 F는 feature를 의미한다. 이렇게 추출된 feature들이 MLP(Multi-Layer Perceptron)을 통과하여 votes를 생성하게 된다. vote를 한다는 것은 3d space의 euclidean coordinates에서 object center와 가깝다고 판단되는 point를 선택하는 것과 해당 feature vector를 학습하는 것이며 모든 point에서 각각 하게된다. voting을 통해 object center에 가까운 point cloud끼리 cluster를 형성하게 되고 point cloud network를 통해 object proposal과 classification을 진행하게된다. 아래 그림은 votenet의 architecture이다.
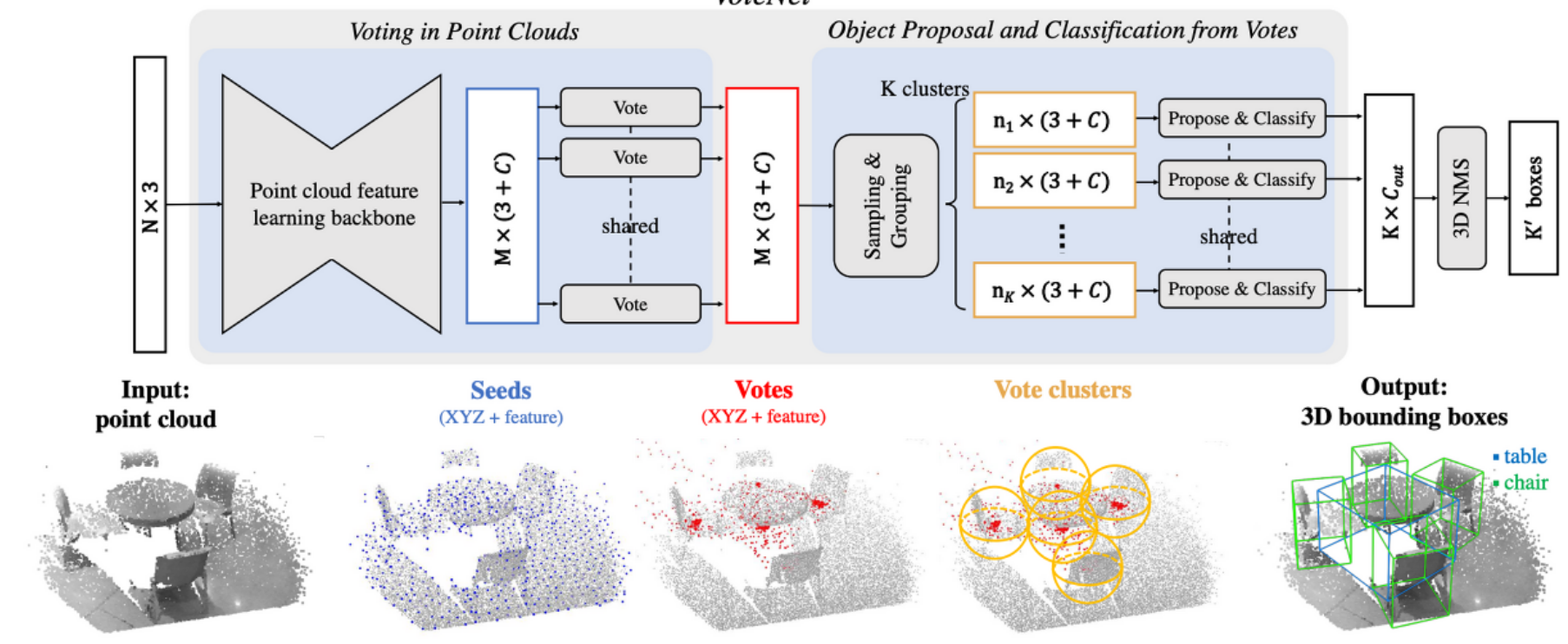
VoteNet은 RGB-D기반 indoor 3D object detection에서 SOTA를 달성했지만, point cloud만을 사용하기 때문에 image정보를 포함하지 않는다. ImVoteNet에서는 VoteNet의 방식을 적용하지만, voting시 image 정보도 추가하여 point cloud와 rgb image의 장점을 모두 활용하고 2d votes를 3d로 lifting하여 detection 성능을 향상시킬 수 있었다.
Image Votes from 2D Detection
2d image에서 image votes를 생성하게 되는데 image vote는 image pixel과 2d object bounding box와의 geometric 관계를 vector로 표현한 것이다. 각 image vote는 원래 pixel의 semantic cues와 texture cues 정보로 augmented된다.
rgb image에서 bounding box들을 얻기 위한 2d detector로 Faster R-CNN을 사용하였다. 물론 RGB-D dataset의 color channe에 대해 pre-trained시킨 모델이다. output으로는 총 M개의 bounding box와 각 box마다의 class를 반환한다. 그리고 bounding box내 각 모든 pixel마다 vote를 한다. 만약 여러 박스에 포함된 pixel이면 여러 번 voting을 하게된다. 만약 어느 박스에도 포함되어 있지 않은 pixel이면 zero padding시킨다.
이제 geometric cues, semantic cues, texture cures가 각각 무엇인지 알아보도록 하자.
Geometric cues : Lifting image votes to 3D
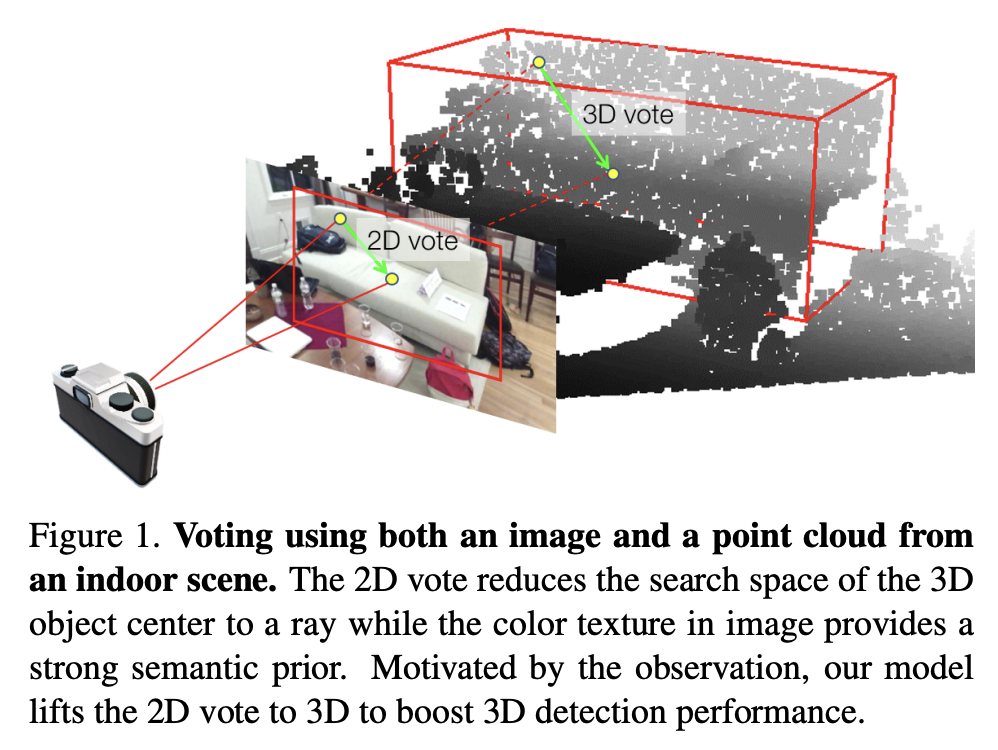
2D votes는 3D object localization을 위해 의미있는 geometric 정보를 전달한다. Figure 1에서 볼 수 있듯이 image plane의 2d object center에서 3d space의 3d object center와 camera optical center를 일직선에 놓이도록 하는 가상의 ray를 만든다. 이 ray정보가 seed point에 추가되면서 3d space에서의 center point를 1d에서 에서 찾을 수 있게 된다.
해당 과정에 대해 조금 더 자세히 이해해보도록 하자. 아래 Figure 3에 나타난 그림을 보면 3D space에서의 object와 2d image plane에서 2d bounding box가 나타나 있다. 3D object center는 대문자 C이고 image plane에 projection된 object center는 소문자c로 나타내었고, 점 P는 object surface에 있는 point이고 P가 image plane에 사영된 점은 p로 나타내었다. 앞에서 언급한 것처럼 3d object center(C)를 찾기 위해 3차원 space가 아니라 축소된 1차원 직선 공간 OC(ray)위에서 찾을 수 있다.
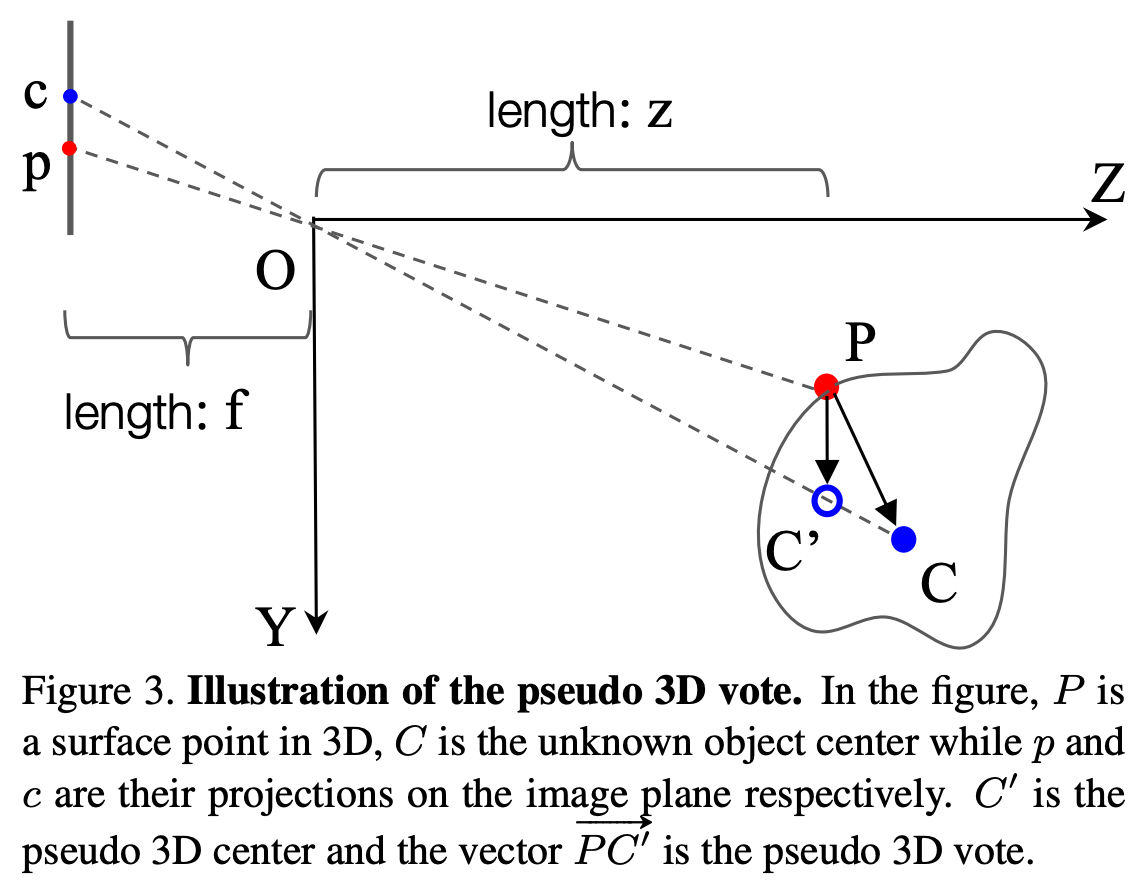
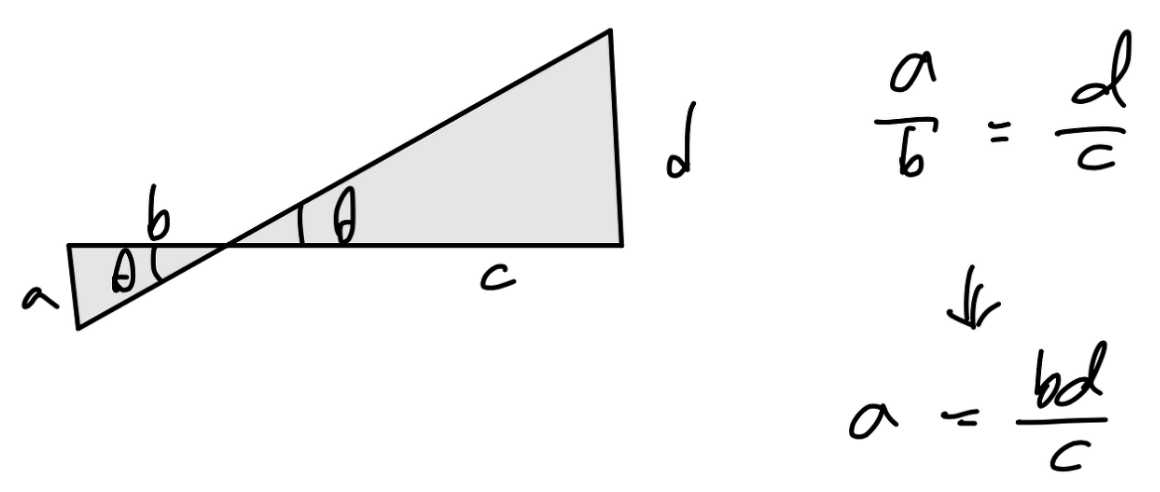
이제 수학적으로 어떻게 ray 정보를 계산할 수 있는 지 알아보자. 이에 앞서 pinhole camera에서 좌표 정보가 어떻게 표현될 수 있는지 간단하게 설명해보자면, 아래 원점 대칭모양의 두 삼각형을 보자. 두 삼각형의 삼각법(trigonometry)을 이용하며 삼각형의 높이 정보를 다른 변의 길이 정보로 나타낼 수 있다.
아래 그림은 pinhole camera에서 3d 좌표를 2d 좌표로 projection하는 과정이다. 3d에서 좌표 (x,y,z)는 위에서 설명한 삼각법을 통해 좌표 x,y값과 초점 거리인 focal length를 이용하여 간단하게 나타낼 수 있다. 또한 역과정으로 2d점을 3d로 변환할 수도 있다.

여기서도 3d에서 2d로 projection하는 계산 방법을 이용하여 좌표를 나타내게된다. 우선 점의 좌표에 대해 정의하자면 아래와 같다.
– P=(x1,y1,z1)로 camera coordinate에서 정의된 좌표
– p=(u1,v1), c=(u2,v2)로 image plane coordinate에서 정의된 좌표
그리고 3d bounding box의 좌표인 C=(x2,y2,z2)를 찾아가는 과정이다. C는 3d point P가 voting을 하는 target이 된다. 따라서 실제 맞춰야하는 정답 3d vote를 한 PC는 아래와 같은 vector로 표현될 수 있다.
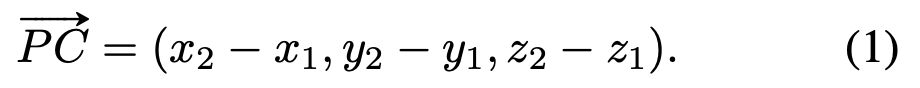
2d vote에서는 위에서 설명한 pinhole camera의 표현 방식을 통해, 간단하게 pc vector를 표현할 수 있다.
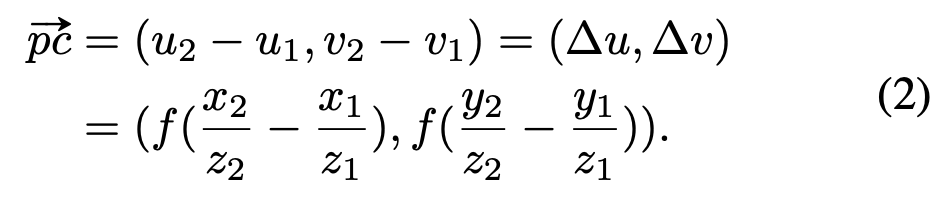
그리고 3d object 표면에 있는 점 P에 대한 depth를 추정해야하는데, 이 값은 center point C와 비슷하기 때문에 같다고 가정한다. caemra로부터 멀리 떨어진 점들의 경우 보통 이러한 방식을 사용한다. 그래서 3d object에서의 voting을 아래와 같은 식의 pseudo 3D vote로 표현할 수 있다. C’는 pseudo 3D vote로, 직선(ray) OC위에 있는 점으로 실제 3d object center인 C와 가까운 점이다. C’은 object 표면의 점 P에 대해 3D center가 어느 위치에 있는지를 포함하는 정보이다.
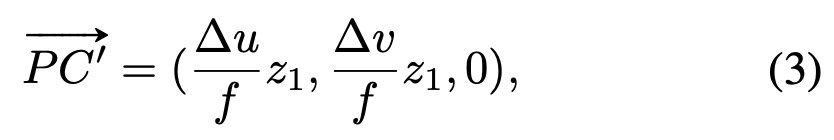
위에서 depth approximation을 할 때 P와 C의 depth를 비슷하기 때문에 같다고 가정하였는데, 이에 대한 오차가 발생할 수 있다. 이 오차로 발생할 수 있는 error를 줄이기 위해 P와 C의 ray의 방향 정보를 추가하였다. 아래의 식은 x축에 대한 error를 나타낸다.
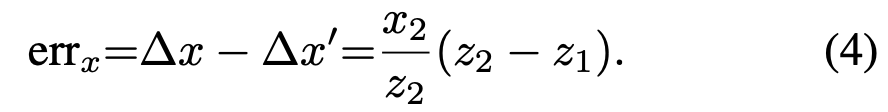
우리는 정확한 3d object center인 C의 값을 모르기 때문에, OC와 같은 방향을 가지는 OC’ ray의 vector를 사용하게 된다. 아래 식과 같이 표면의 점 P와 pseudo 3d vote인 C’를 이용해 OC’을 표현할 수 있다.
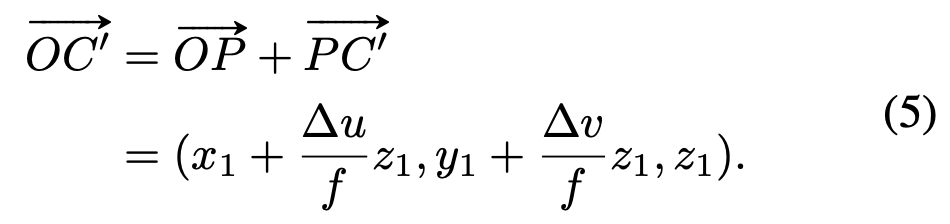
이후 normalize된 아래와 같은 image의 geometric feature가 seed point P로 전달된다.
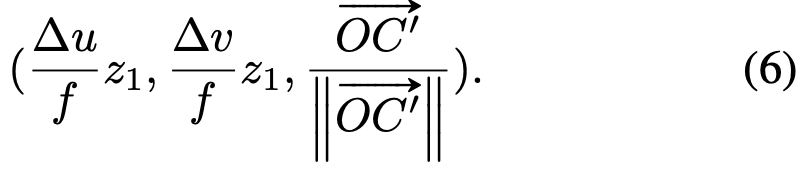
Semantic cues
RGB image에서 box안에 어떤 object가 있는지 semantic한 정보를 얻을 수 있다. 이 정보를 통해 3D point cloud에서 어떤 object를 학습해야하는 지 알 수 있고, geometric정보가 유사한 objects의 class를 구별하는데 도움이 될 수 있다. 예를 들어 table과 desk, nightstand와 dresser의 경우 아래 그림처럼 구별하기가 어렵다.


따라서 bounding box마다 region-level feature를 추출하여 semantic cue로 정보를 3d point cloud에다가 추가한다. 여기서 semantic cues는 2d backbone으로 사용된 faster RCNN에서 ROI를 할 때 box의 one-hot class vector이다.
Texture cues
3d space에서 sparse한 정보와는 다르게, RGB image에서는 dense하고 pixel level의 high resolution 정보를 포함하고 있다. 따라서 간단한 mapping을 통해 3d seed points로 high resolution 정보를 줄 수 있다. texture cues는 3d space의 point가 2d projection되었을 때 해당하는 pixel의 pixel feature를 의미한다. raw한 RGB pixel값을 direct하게 texture feature로 사용하는 것이다.
Feature Fusion and Multi-tower Training
앞선 파이프라인을 간단하게 다시 이해해보자면, 우선 image votes를 3d로 lift하고 semantic, texture 정보들(Figure 1에서 K x F’)이 K x F의 point cloud feature와 함께 모든 seed point마다 3D votes를 생성하게 되고 aggregate하여 3D bounding boxes를 propose하게 된다. 그리고 두 modality의 cues를 모두 효과적으로 활용하기 위해 network를 optimize하는 과정이 추가된다. 이 과정이 없다면, multi-modal training시 서로 다른 두 modality가 다른 rate로 학습되기 때문에 하나의 feature에 dominant한 학습이 되거나 overfitting이 되어 single-modality training 방식보다 오히려 더 낮은 성능을 보일 수 있다고 한다. 따라서 여기서는 modality towers에서 서로 다른 modality의 weight에 가중치를 부여하는 gradient blending 방식을 적용한다. 처음에는 blendingd을 하는 새로운 방식이 있는 것인줄 알았는데, Attention을 주는 방식으로 이해하면 될 것 같다.
Figure 2에 표현되어 있는 것 처럼 총 3개의 towers로 구성되어 seed points를 입력으로 받는다. image tower에서 image feature하나만으로는 3d object의 localization을 예측할 수 없기 때문에 object surface point의 geometric정보와 camera intrinsic정보를 통한 pseudo 3D votes의 geometric정보를 함께 활용한다. image tower는 3d vote와 image feature를 입력으로 하고 point tower는 3d feature와 3d vote를 입력으로 하고 joint tower는 모두 사용한다. image tower와 point tower는 trainig시에만 사용하고 joint tower는 training과 inference 모두 사용한다. 각 towers는 각각 voting을 하고 box proposal하는 network의 parameter를 사용하고 loss도 따로 계산한다. total training loss는 각 lossfmf weighted sum하여 사용하며 아래와 같다.
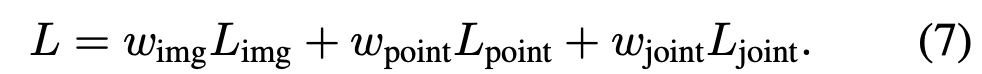
Experiments
평가는 indoor Benchmark dataset인 SUN RGB-D로 진행하였다. SUN RGB-D는 single view의 RGB-D dataset으로 되어있고 indoor 3D scene으로 구성되어있다. 총 37개 categories가 있으며 3d bounding box annotation이 되어있다. 여기서는 10개 categories에 대해서만 학습을 진행했고 데이터를 point cloud backbone에 넣기 위해 depth image를 point cloud로 바꾸었다.
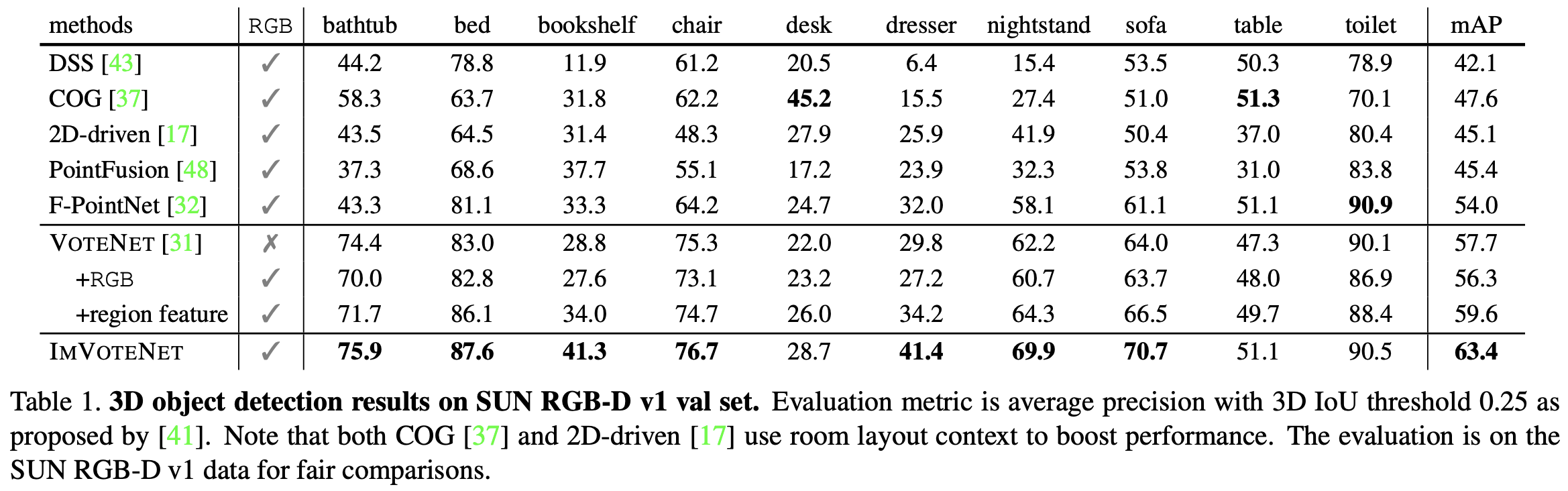
Table 1은 기존 RGB와 point cloud를 활용한 모델들과 SUN RGB-D로 비교한 결과이다. 기존 VoteNet의 경우에는 point cloud만을 입력으로 한다. Table 1에서 VoteNet은 두 가지로 나누어져있는데, +RGB는 RGB값을 3차원 vector형태의 point cloud feature로 사용한 것이고 +region feature는 ImVoteNet처럼 pre-trained된 faster RCNN을 통해 region-level의 one-hot class feature를 뽑아 seed point에 함께 사용한 것이다.2D-driven, PointFusion, F-PointNet은 2d detector로 3d proposal을 생성하는 모델이고, DSS(Deep Sliding Shapes)는 voxel기반의 3d cnn network로 proposal하는 모델이며, COG는 DSS를 기반으로 3D HoG feature를 사용한 모델이다. ImVoteNet의 결과를 보면 다른 모델들보다 높은 성능을 보이는 것을 확인할 수 있다. 특히 당시 sota이던 VoteNet보다 5.7mAP가 높은 성능을 보이면서 2d image vote를 함께 사용한 것의 효용성을 보였다.
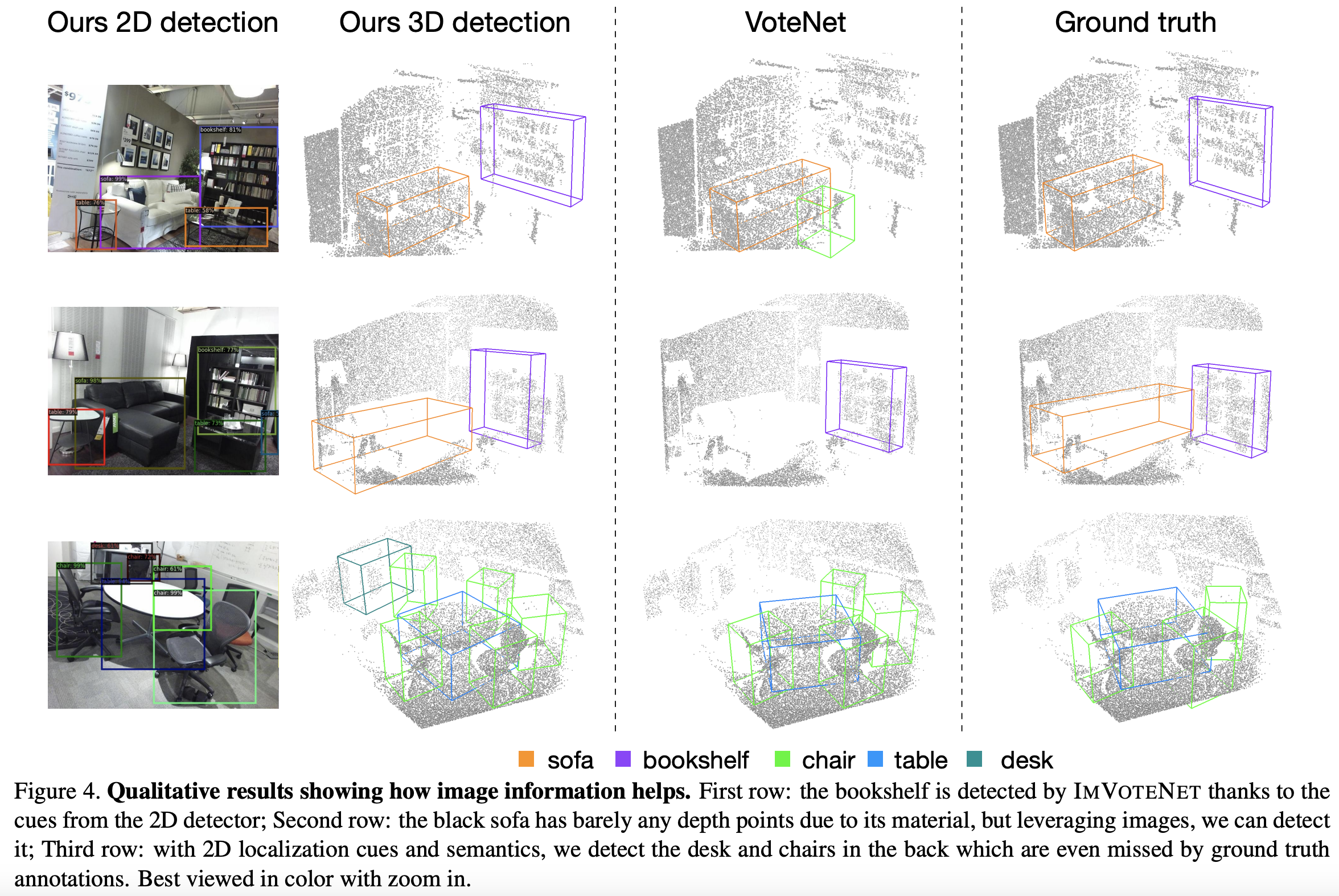
Figure 4에서는 VoteNet과 본 논문에서 제안한 ImVoteNet과의 detection 성능을 비교하였다. VoteNet에서 찾지 못한 bookshelf나 sofa를 ImVoteNet에서는 찾아낸 결과를 확인할 수 있다. 흥미로운 점은, 마지막 행에서 GT에 없는 뒤에 가려져있는 desk와 chair를 검출해냈다는 점이다. 저자는 결과를 통해 image cues가 3d detection결과에 긍정적인 영향을 미쳤다고 주장한다.

Table 2는 2d cues에 대한 ablation study이다.
(a)에서는 geometric cues를 실험하였고 2d votes와 ray angle을 모두 포함시켰을 때 pseudo 3D votes에 정확한 cue정보를 제공하게 되어 가장 좋은 성능을 보였다.
(b)에서는 semantic cues를 실험하였고 one-hot class score vector로 간단히 표현한 정보가 가장 좋은 결과를 보였다. Faster R-CNN에서 RoI feature를 1024 그대로 사용하였을 때, high dimension feature와 다른 point feature를 fusion할 때 optimization문제로 인해 낮은 성능을 보였고 64 dimension으로 줄였을때도 one-hot score feature보다 낮은 성능을 보였다.
(c)에서는 texture cues를 실험하였고 raw RGB feature가 다른 CNN feature들보다 좋은 성능을 보인다는 것을 실험적으로 입증하였다. CNN feature들은 network를 통과하면서 over fitting되어 성능 하락한 것으로 보인다.
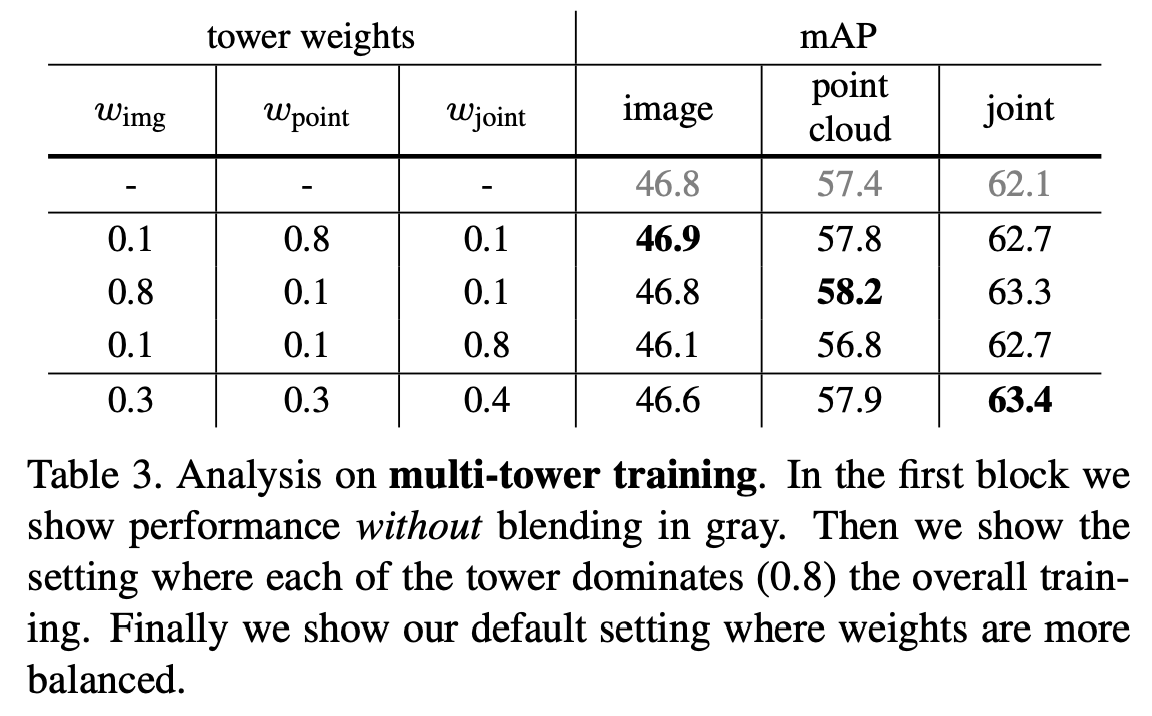
Table 3에서는 Multi-tower training에 대한 실험 결과를 보여준다. 첫 행은 single tower로 학습한 결과이고, 2~4행은 weight를 변경하면서 실험한 결과이고 마지막 행은 최적의 weight 설정 결과이다. 첫 행의 single tower의 image결과(46.8)를 Table 1의 다른 모델들과 비교했을 때 이미 더 좋은 성능을 보이는 것을 미루어보아, fusion방식과 voting방식이 효과적이라는 것을 알 수 있다. 위의 식 7에서 image tower, point tower, joint tower의 loss마다 weight를 각각 0.3, 0.3, 0.4로 하였을 때 가장 좋은 성능을 보인다.
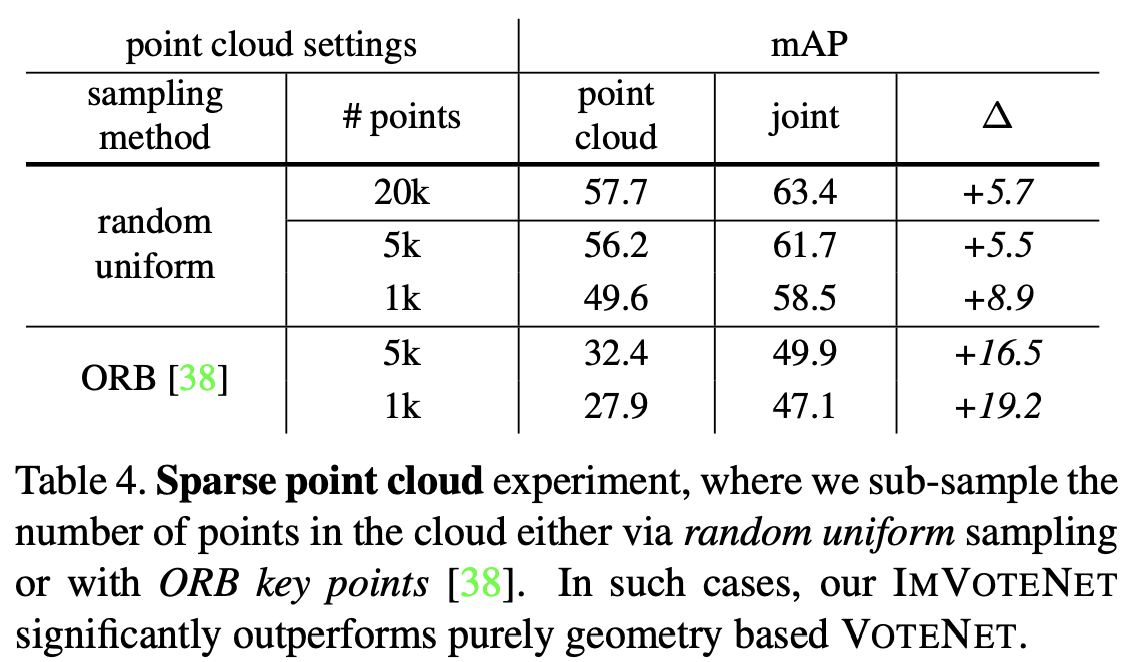
Table 4에서는 더 sparse한 point cloud 환경을 모사하여 이런 환경에서 joint방식이 얼마나 개선된 성능을 보이는 지 분석한 결과이다. sparse한 환경을 모사하기 위해 2가지 방법으로 sampling하였는데, uniformly random sampling방법과 ORB key-point 기반 sub-sampling(3d point를 2d로 projection했을 때 ORB 2d key point와 가까운 point만 sampling)을 사용하였다. sampling된 points가 많을 수록 좋은 성능을 보였고 joint방식이 더 좋은 결과를 보인 것을 알 수 있다. 특히 ORB sampling을 한 경우에 성능 향상폭이 크게 나타났다.

Conclusion
ImVoteNet은 image data가 voting방식을 기반으로 한 3d detection pipeline에서 어떻게 효율적으로 사용할 지 개선한 모델이다. image detector를 사용하여 geometric 정보와 semantic/texture 정보를 함께 포함하도록 하여 3d voting pipeline을 개선하여 3d object detection 성능을 올릴 수 있었다. 물론 faster RCNN과 같은 2d detector 성능에 영향을 받겠지만 point cloud기반 방식보다 fusion방식에서 더 좋은 성능을 보였다는 점에서 fusion방식의 성능 개선 방향을 제시한 좋은 방법론이라고 생각한다. 앞으로도 3d detection 관련한 논문들을 survey하면서 리뷰하도록 하려고 한다.
좋은 리뷰 감사합니다.
기존의 3D point를 이용한 VotNet은 디테일한 외관적 정보를 놓친다는 문제가 있어 이미지를 이용하여 이를 보완한 것이 ImVoteNet이라고 이해하였습니다.
방법론을 읽어보다보니, Geometric cues : Lifting image votes to 3D파트에서 객체의 중심점과 픽셀이 일직선상에 오도록 하여 가상의 ray를 만든다고 하셨는데, 이때 2D와 3D의 중심점들은 모두 예측한 값인가요?? 또한 pseudo 3D vote인 C’을 이용하는 이유가 잘 이해가 되지 않는 데 설명해주실 수 있나요??
댓글 감사합니다.
2d detector에서 detect한 bounding box내의 pixel마다 해당 object center point에 voting을 하는 것이 2d vote로, 중심점은 실제 gt인 것으로 이해했습니다. 2d object에서의 2d vote를 3d차원으로 lift해야하는데 3차원 공간에서 object surface에 존재하는 point가 해당 object center에 vote를 하는데, 이때 가상의 ray위의 점을 향한 vector형태로 pseudo 3D vote인 C’을 사용하여 voting하게 됩니다.
안녕하세요 좋은 리뷰 감사합니다.
table 1에서 votenet+region feature와 ImVoteNet 모두 pre-trained된 faster RCNN을 통해 region-level의 one-hot class feature를 뽑아 seed point에 함께 사용한 것이라고 하셨는데, 그렇다면 두 모델의 가장 큰 차이점이 무엇인가요?
그리고 +Region feature 모델은 Votenet+Region feature, votenet+rgb+region feature중 어느 것인가요? 혹시 전자라면 rgb의 3d point cloud feature와 region feature를 함께 사용한 결과는 없나요?
댓글 감사합니다.
먼저 votenet + region feature에서는 단순히 one-hot class score vector를 seed points에 concat한 것이고, ImVoteNet에서는 multi-tower training과정을 통해 image vote를 systematical하게 사용한 것이 가장 큰 차이점입니다.
+Region feature 모델에서 rgb를 사용하여 region feature를 추출하기 때문에 votenet+rgb+region feature라고도 할 수 있겠네요. 그치만 rgb의 pixel level feature를 사용하지는 않았기 때문에 votenet+region으로 나타낸 것으로 보입니다. 말씀하신 rgb의 3d point cloud feature는 무슨 의미인지 모르겠는데 아마 rgb의 region feature와 3d point cloud feature를 함께 사용한 votenet+rgb+region feature를 말씀하신 걸로 이해합니다. 정확히 말하자면 votenet+region feature를 사용한 것이기 때문에 해당 방식에 대한 리포팅 결과는 없습니다.