
오늘은 다소 예전 논문을 가져왔습니다. 제가 이번에 리뷰하려는 방법론은 Active Learning 의 대표 방법론 중 하나인데요. 그동안 막연하게 어떤 방법론인지만 이해했을 뿐 디테일한 이해와 리뷰가 없었던 지라 한번 정리해보고자 합니다. 우선, 해당 페이퍼는 ICCV 2019 에서의 Oral Paper 입니다. 그만큼 Active Learning 분야에서도 대표적인 방법론으로 여겨지고 있기도 합니다. 이를 개선한 방법론 역시 CVPR에 게재되기도 하였습니다. 그럼 어떤 방식의 AL 을 제안하였을지 리뷰해보도록 하겠습니다.
<Variational Adversarial Active Learning >

- Paper: ICCV 2019 [ 바로가기 ]
- Supplemental: [ 바로가기 ]
- Author Video: [ YouTube ]
- Code: GitHub
[1] Introduction
해당 논문에서는 VAE와 Discriminator를 사용하여 가치 있는 데이터를 선별합니다. VAE와 Discriminator는 GAN에서 가짜 데이터를 만드는 Generator와 진짜/가짜 데이터를 구별해내는 Discriminator과 같은 역할을 합니다. VAE는 output이 labeled 인지 unlabeled 인지 구별하기 어렵도록 학습되고, Discriminator는 그 둘을 구분해내도록 학습됩니다. 저자가 VAE를 사용한 이유는 활발하게 연구되고 있던 데다가 Adversarial 에서도 좋은 성능을 보여서 라고 합니다. (특별한 철학 없이 단순하게 VAE를 썼음에도 ICCV에 게재된 것은 이렇게 Labeled/Unlabeled 구분할 수 없도록 학습하는 AL 프레임워크를 처음 제안해서 그런게 아닌가 라는 생각이 들기도 합니다)
그럼 이제 해당 방법론의 프레임워크는 감이 오실겁니다. 그렇게 VAE와 Discriminator를 학습하는 건 알겠는데, 가치 있는 데이터는 어떻게 판단하느냐? 즉, 라벨링이 필요한 데이터 Sampling Criteria는 무엇이냐 라는 질문이 생깁니다. 이를 위해 Discriminator를 사용하였습니다. Labeled/Unlabeled를 구분하도록 학습된 Discriminator의 출력값에 대해 이에 대한 불확실성을 이용하였다고 합니다.
정리하자면 저자가 제안하는 VAAL(Variational Adversarial Active Learning) 는 다음과 같습니다: VAE는 Labeled/Unlabeled를 구별하기 어려운 feature를 만들고, Discriminator는 이를 구분해내도록 학습됩니다. 이렇게 학습된 Discriminator의 출력은 각 샘플이 어디서 왔는지를 나타내는 확률값이 됩니다. 그 확률값은 곧 Labeled/Unlabeled를 대표하는 신뢰성을 나타낼 수 있다고 할 수 있겠죠. 따라서 이 확률값을 기반으로 높은 불확실성을 산출하는 샘플을 선택하는 방법론을 제안하였습니다.
[2] Method: Adversarial Learning of Variational Autoencoders for Active Learning
아래는 저자가 제안하는 VAAL의 프레임워크입니다. 이제는 많은 분들이 아시겠지만 Active Learning이란 동일한 개수의 데이터로 모델을 학습하더라도 더 좋은 성능을 낼 수 있는 데이터를 선별하는 연구입니다. 따라서 어떤 feature로 만들지 그리고 그 feature를 기준으로 어떤 기준으로 데이터를 선별할 지 이 두 개의 파트가 주된 연구 분야입니다.
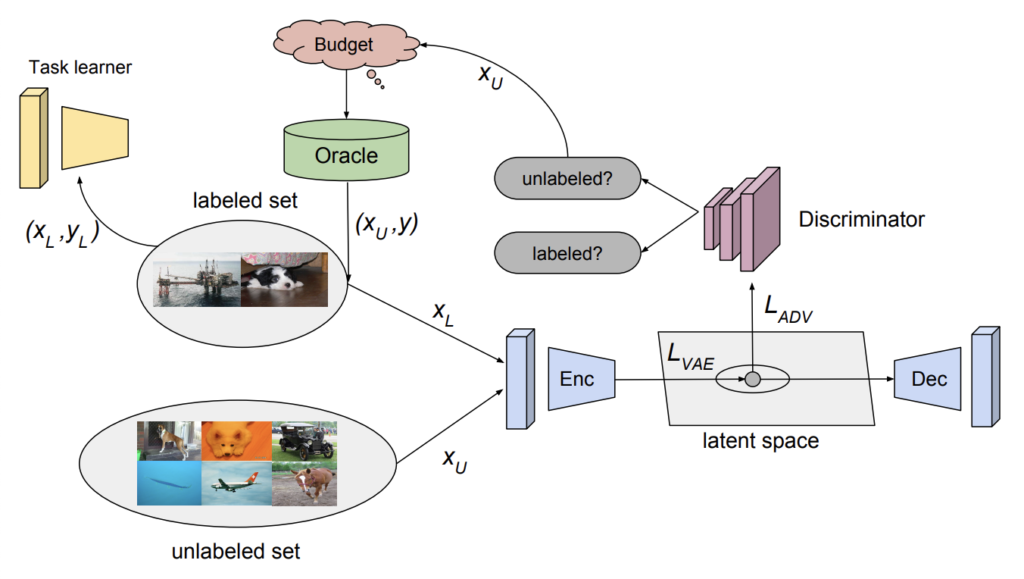
저자는 어떤 feature 로 만들지에 대해서는 VAE와 Discriminator를 사용하였습니다. 이를 통해 Labeled 말고도 Unlabeled 를 동시에 사용할 수 있다는 것이 가장 큰 Contribution이지 않을까 싶습니다.
이제 학습된 feature를 바탕으로 라벨링할 데이터를 선별할 기준으로는 Discriminator가 Unlabeled 라고 판단하는 데이터 중 불확실성이 높은 데이터를 기준으로 나열한 뒤, 고정된 B개 만큼 선별합니다. (B개는 보통 학습 전에 정해져 있습니다.) 큰 그림은 이해하셨을 거라 생각이 들고 이제 파트 별로 상세한 내용 설명을 하겠습니다.
[2]-1. Transductive representation learning
우선 데이터를 공통의 latent space로 만드는 VAE 파트에 대해 설명하겠습니다. 저자는 \beta-variation autoencoder를 사용하였다고 합니다. 여기서 인코더는 보통 Gauossian prior를 사용하여 기본 Distribution에 대한 저차원 space를 학습하고, 디코더는 Reconstruction 기능을 합니다. 이때, LAbeled set에서는 부족한 representation을 feature를 얻기 위해, Unlabeled 를 사용하였다는 것이 앞서 언급한 가장 큰 Contribution입니다. 기존에는 Unlabeled 데이터를 사용하는 방법론이 많지는 않았습니다.
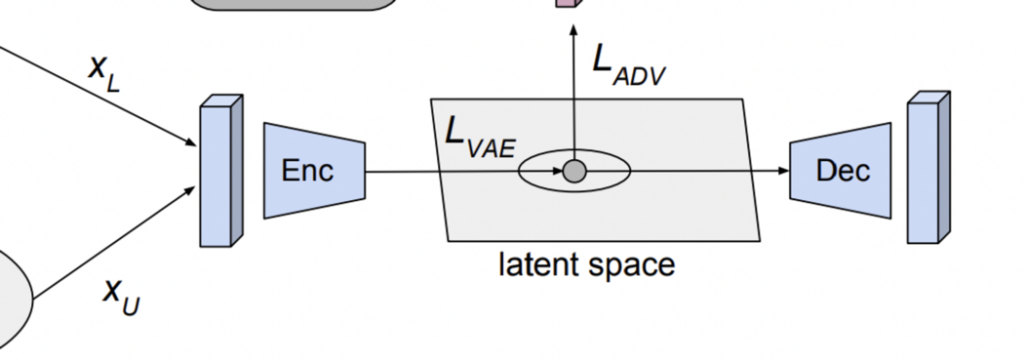
따라서 이를 기반으로 한 Loss는 아래와 같습니다. VAE의 대표적인 Loss 라고 할 수 있습니다. q_\theta, p_\theta는 각각 인코더와 디코더를 의미하며, p(z)는 unit Gaussian으로 사전에 정해진 값입니다.
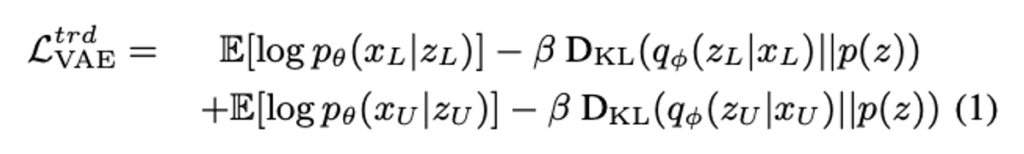
[2]-2. Adversarial representation learning
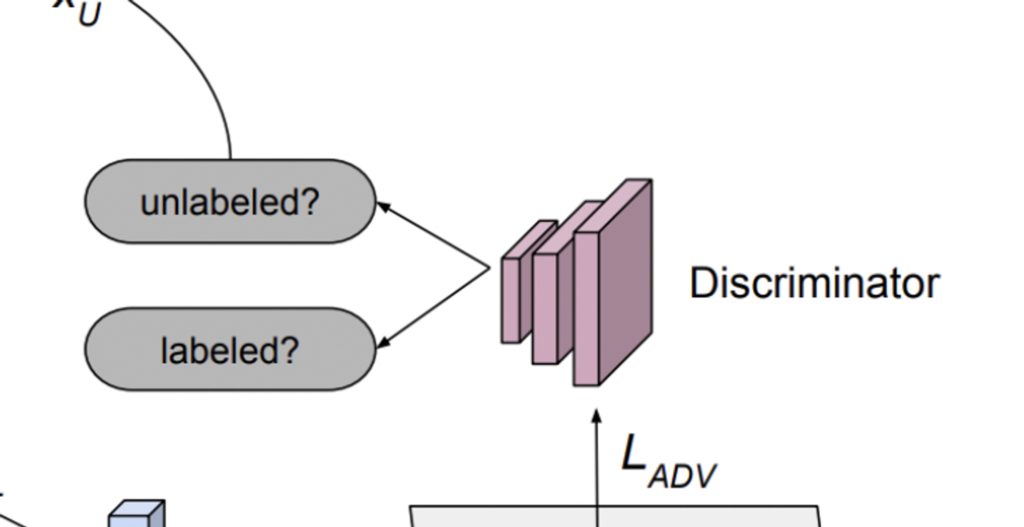
그 다음으로 Encoder의 출력으로 공동 임베딩된 피처를 기반으로 Unlabeled/Labeled 를 구분해내는 Discriminator 부분 입니다.
Active Learning 에서 많은 연구들은 라벨링이 필요하다고 하는 데이터를 (1) Uncertainty (2) Distribution 기반으로 선택하곤 합니다. (1) 의 경우, 어떤 클래스에 속할지 불확실한 데이터로 보통 결정 경계에 많이 분포된 데이터를 우선적으로 선별하는 방식이죠. 기존 대부분의 방식이 이 (1) 기반으로 데이터를 선별하곤 하는데, 저자가 말하길 이는 outlier에 민감하다고 주장합니다. 결정 경계를 위주로 데이터를 선별하기 때문이죠. 결정경계와 멀리 떨어진 outlier에는 취약할 수밖에 없습니다.
이에 반해 저자가 제안하는 방법은 VAE를 통해 학습된 latent space를 기반으로 feature를 구별하는 Discriminator를 사용하였습니다. 그러니까 저자의 주장에 따르면, 모델의 output을 그대로 사용하는 것보다 latent space라는 하나의 feature를 거친 방식이 더 효과적이라는 얘기겠네요. 아무튼 VAAL에서의 Discriminator는 latent space가 Labeled 라면 0 아니면 1 이라는 이진 분류로 학습됩니다. 그리고 GAN과 같이 VAE와 Discriminator가 동시에 학습되죠. 따라서 이에 대한 VAE와 Discriminator의 Loss는 아래와 같이 정의됩니다.
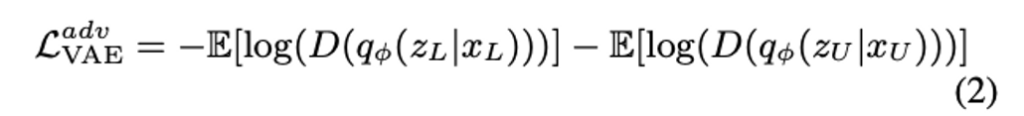
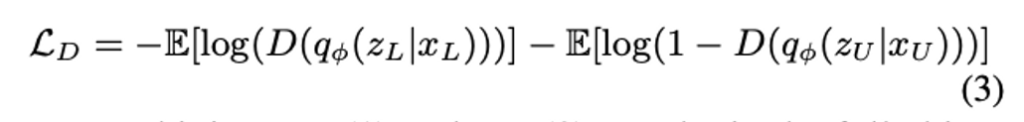
이제 Eq. (1)과 Eq. (2)를 결합함으로써 VAAL에서 VAE에 대한 최종 Loss는 아래와 같이 얻을 수 잇ㅆ습니다.
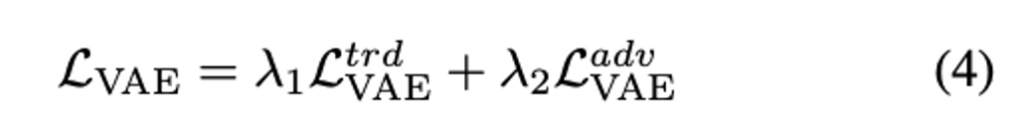
따라서 지금까지의 VAE 그리고 Discriminator를 학습하는 알고리즘은 아래와 같이 정리할 수 있습니다.

[2]-3. Sampling strategies and noisy-oracles
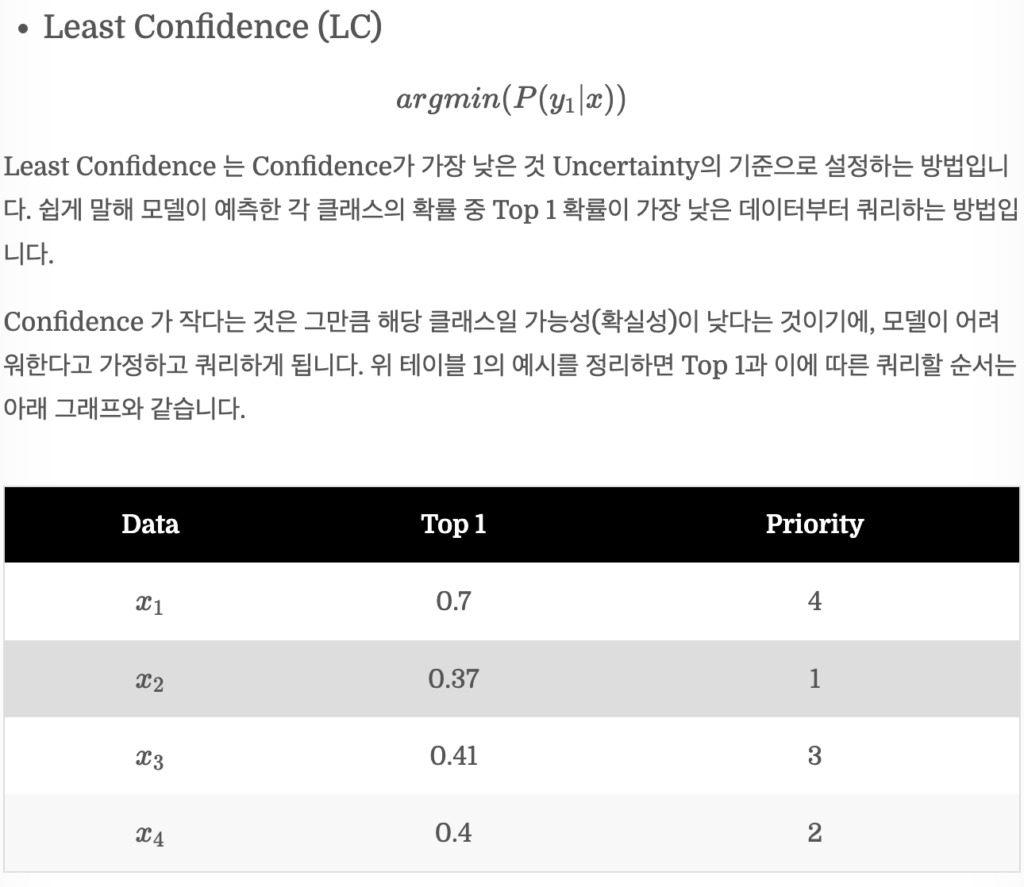
지금까지 VAAL을 학습하는 방식에 대해 이해했습니다. 그럼 이제 데이터는 어떻게 선별할까요? 사실 굉장히 단순합니다. Discriminator의 출력값을 기준으로 Unlabeled 라고 속하는 데이터 중 신뢰도가 가장 낮은 b개의 데이터를 선별합니다. 즉, Least Confidence (LC) 방식을 택했습니다. 이해를 위해 제가 예전에 엑스리뷰로 작성했던 부분을 캡처로 올리겠습니다
보통 Active Learning 에서는 라벨링을 요청한뒤 추가된 데이터는 항상 정답을 라벨링한다고 가정합니다. 그런데 예전에 제가 리뷰했던 논문에서도 이 가정은 사실상 실제 시나리오에서는 말이 안된다고 꼬집었었죠. 따라서 저자는 2가지의 상황을 고려하였습니다: (1) 기존 전제처럼 항상 정답값만을 반환하는 어노테이터 (2) 일부 특정 클래스에는 잘못 라벨링하는 노이즈 어노테이터. 따라서 이에 대한 샘플링 기준을 정리하면 아래 알고리즘과 같습니다.

[3] Experiments
실험에 사용된 데이터셋 비율은 다음과 같습니다: 초기 라벨 데이터셋의 크기(init_size)는 10%입니다. 또한 사이클마다 추가되는 데이터는 5%(add_size)입니다. 실험에는 CIFAR-10, CIFAR-100 말고도 Caltech-256, ImageNet을 사용하였습니다. (ImageNet에 대한 실험이 있다는 건 제법 인상적이네요) ImageNet을 제외한 나머지 실험들은 모두 5번 돌렸을 때의 평균입니다. ImageNet은 2번에 대한 평균이라고 합니다.
[3]-1. VAAL on image classification benchmarks
아래 그림은 이전 연구들과 비교한 Classification에 대한 실험으로, 우선 기존 AL 과 같이 오라클은 항상 정답을 반환한다는 가정하에 실험을 진행하였습니다.
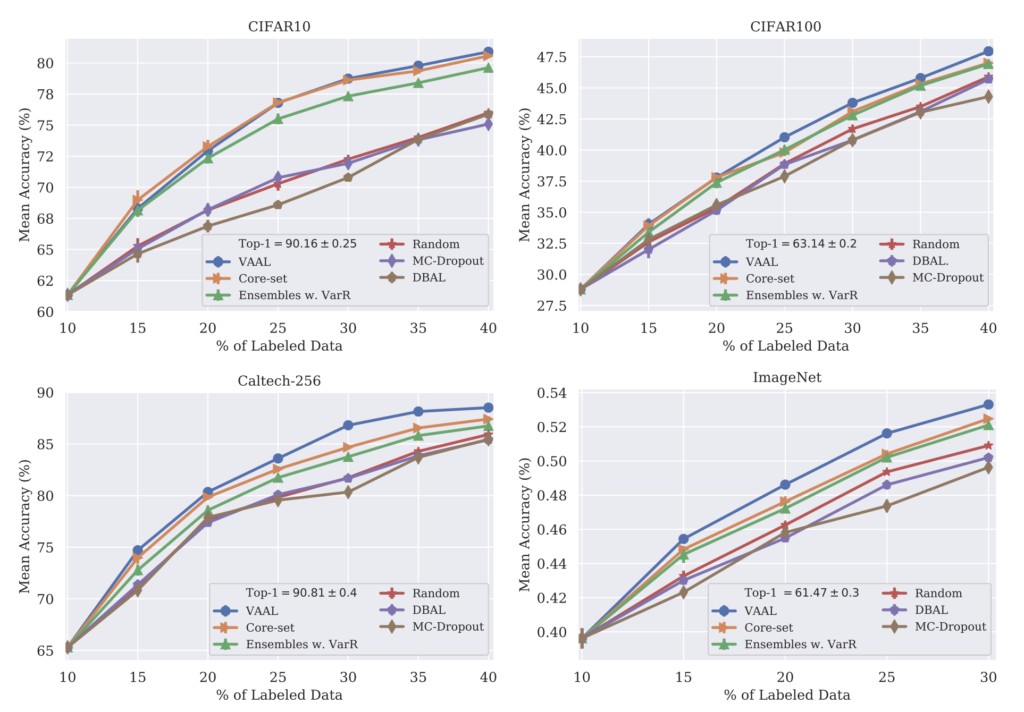
실험 테이블에서 Top-1은 전체 데이터를 사용하여 supervised 로 학습했을 때의 성능입니다. 데이터를 일부만 사용하는 AL에 대한 upper bound라고 할 수 있겠죠. 또 AL에서는 Random으로 샘플링햇을 때의 결과를 베이스라인으로 삼습니다. 최소한 랜덤으로 뽑는 것보다 성능이 좋아햐겠죠.
CIFAR-10에서는 40%만을 사용했을 때 80.9%의 mean accuracy를 달성합니다. 여느 논문과 마찬가지로 가장 좋은 성능을 보였다고 주장합니다. 특히, 15% 부터 평균 정확도 값은 VAAL이 큰 차이로 기 방법론 대비 높은 성능을 보였죠. CIFAR100에서는 Ensambles, 그리고 Coreset과 성능이 비슷한데, 20%가 넘어가면 VAAL은 동일한 정확도를 달성할 때, 2.5%의 적은 라벨링 데이터 개수가 필요하다는 점에서 효율적인 라벨링을 할 수 있었음을 알 수 있습니다. 그리고 VAAL은 클래스 수가 점차 늘어나는 CIFAR-10 -> CIFAR-100 -> Caltech-256 에서 점점 높은 차이로 Core-set의 성능을 뛰어넘습니다. 이를 통해 저자는 VAAL 과 다르게 고차원의 피처에서 데이터의 가치를 판단하는 탓에 p-norm에 미치는 부정적인 영향으로 클래스가 더 적을 때 효과적이었음을 알 수 있었다고 합니다.
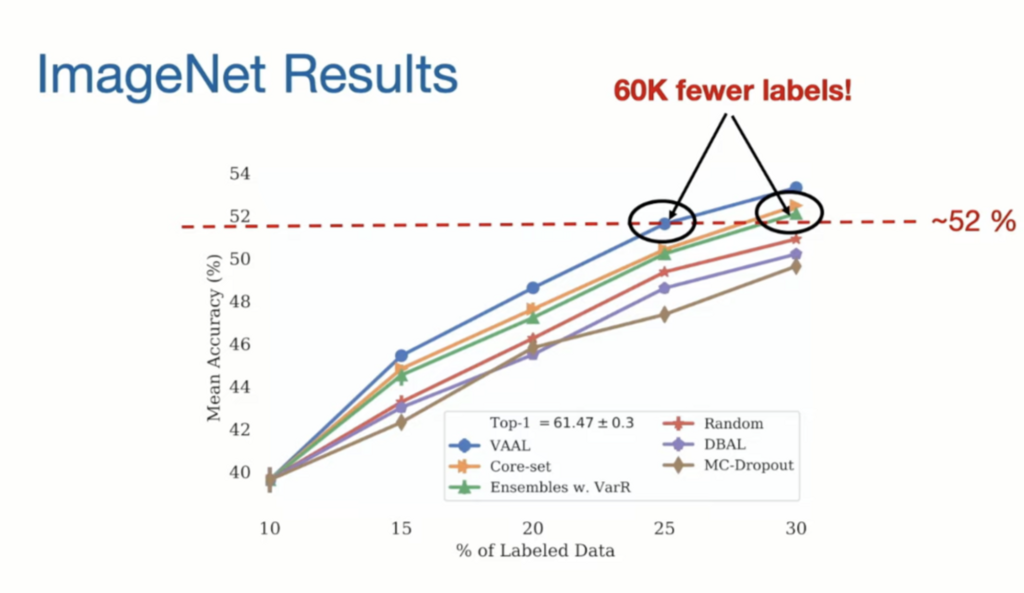
사실 제가 집중한 건 ImageNet에서의 결과입니다. 성능 향상 폭이 대규모 데이터셋임을 가정하면 엄청난데, 이는 저자 역시 강조한 부분입니다. 클래스가 1000개 그리고 데이터셋은 120만개로 기존 AL 연구에서는 성능을 보이지 않곤 하였습니다. 그런데 저자는 기존 방법론들에 비해 엄청난 차이의 성능을 보였다고 합니다. 아래 그림을 보면 25%만 라벨링했을 때 30%의 라벨 데이터로 학습한 Coreset 혹은 VarR과 비슷한 성능을 낼 수 있었습니다. 5% 차이라고 한다면 별거 아닌 것처럼 보일 수 있으나, 데이터셋이 이미지넷임을 감안하면 60K 6만개의 라벨링 비용을 아낄 수 있던 것이죠
[4] Analyzing VAAL in Detail
이제 디테일한 분석에 대해 다루는 섹션입니다. Ablation 말고도 다양한 상황에 대한 성능 분석을 진행하였습니다.
[4]-1. Ablation study
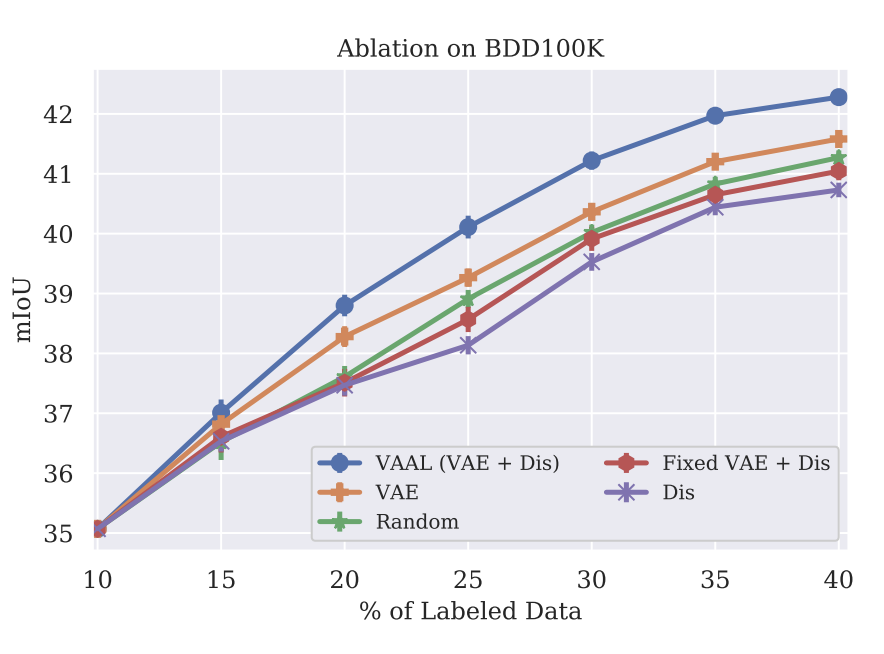
아래 그림은 VAE와 Discriminator(D)를 포함한 VAAL의 주요 모듈에 대한 Ablation study 입니다: 1) eliminating VAE, 2) Frozen VAE with D, 3) eliminating D. 우선 1) Unlabeled/Labeled를 구별하기 위한 Discriminator(D)만 학습시킴으로써 representation learner로서의 VAE역할을 살펴보고자 하였습니다.
아래 그림 중 보라색 별표 라인처럼 그 결과 D가 데이터만 기억할 뿐 성능은 가장 낮았습니다. 또한 이를 통해 VAE가 풍부한 latent space 학습 뿐 아닌 D의 과적합을 막는 역할을 할 수 있었음을 확인할 수 있었다고 합니다.
[4]-2 VAAL’s Robustness
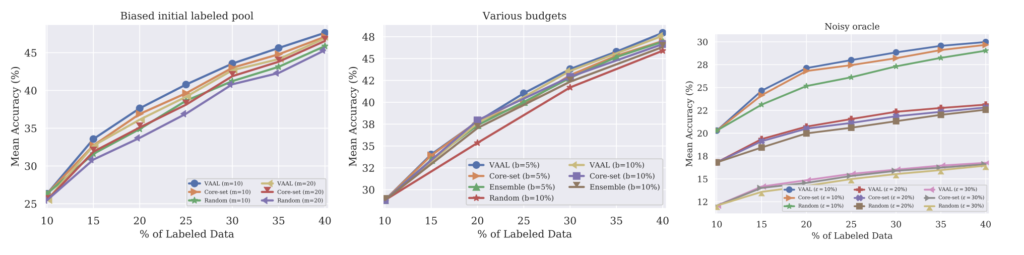
(1) Effect of biased initial labels in VAAL
AL에서는 초기 라벨 데이터셋의 클래스 분포에 따른 성능 차이가 있곤 합니다. 소량의 학습 데이터를 사용하는 대부분의 태스크에서 겪고 있는 문제기도 하죠. 본 논문에서는 초기 라벨 데이터의 클래스가 편향적인 경우에 대한 성능을 확인하고자 하였습니다.
사실 Biased 된 초기 데이터만으로는 latent space가 대부분의 영역을 커버하기엔 불충분합니다. 어쩌면 균형적인 초기 데이터셋보다는 성능이 저조한 게 당연한 것이죠. 이에 대한 영향을 확인한 결과가 상단 그림 중 가장 왼쪽입니다. CIFAR-100에 대한 성능인데요. 초기 라벨셋을 10 혹은 20개의 클래스를 제외하고 미치는 성능을 확인한 결과입니다. 그 결과 Core-set, 혹은 랜덤샘플링보다 우수한 결과를 보였음을 확인하였습니다. (음 그런데 저자의 분석이 여기에 그친 것은 다소 아쉽습니다. 실험 결과를 여러 번 돌렸다는 얘기도 없고, 초기 라벨 구성에 따른 성능 차이가 너무 차이가 커서 그런지 이 편향적인 데이터 실험에 대한 결과를 그대로 신뢰하긴 조금 어려움이 있지 않을까 하는 것이 저의 개인적인 생각이긴 합니다)
(2) Effect of budget size of performance
데이터 개수를 얼만큼씩 추가하는지에 따른 성능 차이를 확인하였습니다. 위에 첨부한 그림 중 가운데 그래프가 바로 CIFAR-100에 대한 비교실험인데요. 5%씩 데이터를 추가하는 것 말고 10%씩 추가하는 결과를 확인하였습니다. 그 결과 VAAL은 5%에서 더 약간 좋은 성능을 보였습니다. 저자는 그 이유로 중복된 샘플을 계속 추가하였기 때문이라고 예상하였습니다.
(3) Noisy vs ideal oracle in VAAL
Sampling 기법을 설명할 때 저자는 2개의 가정을 고려하였다고 하였는데요. 오라클이 항상 정답을 반환하는 결과는 앞선 Experiment 에서 보였고 여기서는 일부 부정확한 값을 반환하는 결과에 대해 설명하였습니다. 이를 위해 각 이미지에는 Fine Label과 Sparse Label 중 추가되는 데이터의 라벨값을 일부 다르게 랜덤으로 변경한 결과를 실험하였습니다. 그 결과는 상단 그림 중 가장 오른쪽 그림입니다. 노이즈 레이블의 비율이 증가함에 따라 모든 AL 방법론 결과를 random sampling에 수렴됨을 알 수 있었습니다.
Conclusion
그동안 기본이 되는 연구를 디테일하게 정리를 하지 않았었는데요. 이번 기회에 한번 기존 대표 방법론들을 디테일하게 정리해보는 시간을 가져야겠습니다. 또한 방법론들끼리 비교해보며 어떤 식으로 나아가야할 지 고민해봐야겠습니다.
좋은 리뷰 감사합니다
GAN 방법론의 영향을 받은 고가치 데이터 선별방법이 인상깊네요. 해당 방법론의 확장선상으로 gan 구조를 이용한 al이 실제로 많이 확장되고 좋은 성능을 내고있는지 궁금합니다.
VAAL 이후로 TA-VAAL 이라는 방법론이 등장하였는데, (이건 제가 추후 리뷰 올릴 예정입니다) 이 논문이 RankCGAN을 사용한 것으로 알고 있습니다. 그런데 그 다음에 이 구조를 사용하는 연구에 대해서는 아직 컨퍼런스 페이퍼에서 발견하지는 못했는데요 … 왜그런지는 TA-VAAL을 읽고 확인해봐야겠습니다. 그렇게되면 다음 확장 연구에 대해서도 한번 살펴볼 계가가 되지 않을까 싶네요 좋은 질문과 제가 생각할 내용를 함께 제공해주셔서 감사합니다.
리뷰 잘 읽었습니다.
해당 분야 리뷰를 읽은지 오랜만이라서 좀 기초적인 부분에 질문을 드리겠습니다.
리뷰 내용 중 “보통 Active Learning 에서는 라벨링을 요청한뒤 추가된 데이터는 항상 정답을 라벨링한다고 가정합니다. 그런데 예전에 제가 리뷰했던 논문에서도 이 가정은 사실상 실제 시나리오에서는 말이 안된다고 꼬집었었죠.” 라고 하셨는데, 간략하게 왜 해당 가정이 말이 안되는지 세줄 요약 해주실 수 있으신가요?
그리고 Active Learning 분야에서는 일반적으로 ImageNet을 잘 활용하지 않는 듯한 내용을 작성해주셨는데 왜 그런건가요? 기존 연구들은 ImageNet에서는 유의미한 성능 향상을 보지 못하였기 때문인가요?
안녕하세요 신정민 연구원님, 우선 좋은 질문 감사합니다.
실제 시나리오에서 사람이 정말 항상 올바른 정답값을 라벨링하는 것은 어렵다는 얘기입니다. 예를 들어 두 개의 이미지가 다른 클래스임에도 불구하고 일부 공간적 유사성으로 인해 사람이 잘못된 예측을 할 경우를 배제할 수 없다는 얘기이죠. 사실 이 전제는 직관에 근거한 하나의 가정일 뿐 이를 뒷받침할 실험은 없긴 합니다.
그리고 두번째 질문, 사실 해당 논문이 발표되기 전에는 ImageNet을 리포팅한 논문이 없었습니다. 대규모의 데이터셋에서의 동작 여부를 판단하기에는 아직 선행적인 연구라고 판단하여 그동안 리포팅하지 않은 듯 합니다. 그러나 해당 논문 이후로 종종 ImageNet에 대한 실험 결과를 리포팅한 연구들이 늘어나고 있습니다. 참고로 제가 리뷰한 논문은 2019 ICCV 에 게재된 다소 예전에 속한다고 할 수 있는 논문입니다.