이번에 감정 인식 관련하여 서베이를 하던 중에 emotion recognition in conversations이라는 분야를 발견하게 되었습니다. 결국에는 emotion recognition인거 아니냐 하시겠지만 디테일하게 살펴보니 emotion recognition과 emotion recognition in conversations은 다른 느낌의 연구인것 같더라구요. 그러면 첫 emotion recognition in conversations 논문 리뷰 시작합니다.
<introduction>
이번 논문도 마찬가지로 multi-modality를 사용하는 논문입니다. emotion recognition에서도 그랬지만 기존의 연구들은 text에만 집중하여 감정 인식을 진행한다고 하며, 논문의 저자는 text, acoustic, visual 정보를 모두 사용하여 emotion recognition in conversation 한다고 합니다. 이를 위해서 새롭게 제안한 모델이 M2FNet (Multi-modal Fusion Network) 입니다. 새로운 multi-head fusion attention layer를 제안하였기 때문에 이렇게 이름을 지은 것이 아닌가 합니다. multi-head attention layer를 간략히 설명드리자면 acoustic, visual feature를 textual feature의 latent space로 mapping해주는데, 이를 통해 풍부한 감정 정보를 얻을 수 있다고 합니다. 이후에 자세히 설명 드리겠습니다.
이 논문에서는 multi-head fusion attention layer 말고도 제안한 것들이 참 많은데요. 차근차근 설명 드리겠습니다. 또 제안한 것은 새로운 feature extector model 입니다. acoustic, visual feature로부터 deeper feature를 추출하기 위해서 새롭게 제안했다고 합니다.
3번째로 제안한 것은 새로운 adaptive margin기반 triplet loss function입니다. 이 loss는 representation을 더 효과적으로 학습할 수 있도록 한다고 합니다.
4번째로 제안한 것은 dual network 입니다. 이를 통해 현장에 존재하는 여러 사람을 고려하여서 현장의 감정 콘텐츠를 결합한다고 합니다.
이렇게 총 4개를 제안했는데요. 마지막으로 state-ot-the-art를 달성함으로써 총 5개의 contribution을 가진다고 볼 수 있습니다.
다음에는 앞에서 말씀드린 제안된 방법론들에 대해서 설명드리고자 합니다.
<emotion recognition in conversations>
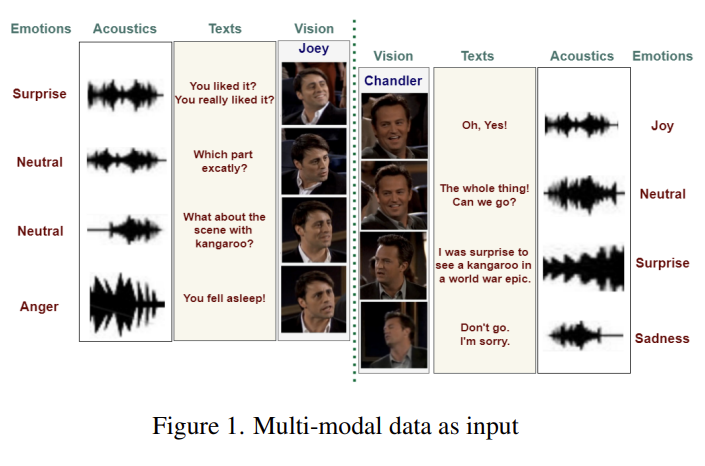
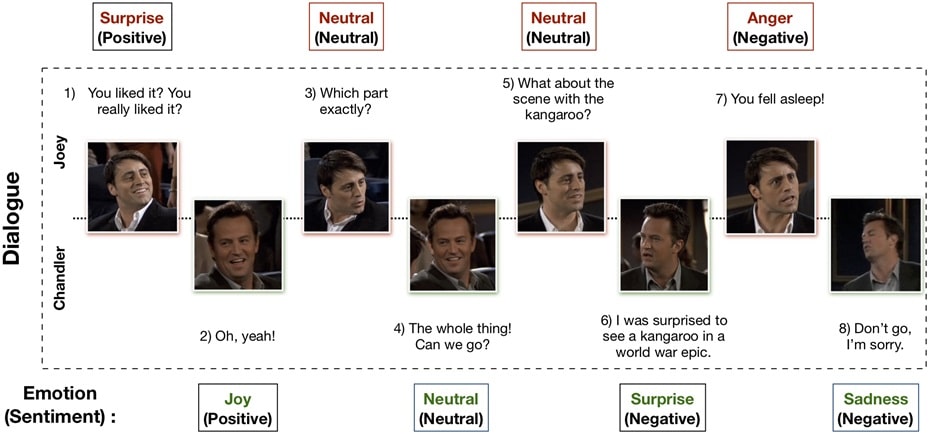
그 전에 emotion recognition in conversations와 traditional emotion recognition이 어떻게 다른지 논문에서 정의한 것이 있어 설명드리고자 합니다. 저희가 흔히 아는 emotional recognition은 감정을 정적 상태로 취급하여 인식합니다. 하지만 emotion recognition in conversations은 문맥(context)이 중요한 역할을 하는 대화의 emotional dynamic(감정 역학)을 포합합니다. 저는 이를 이렇게 이해했는데요. [Figure 1]을 참고하여 말씀드리겠습니다. [Figure 1]에 왼쪽 배우가 마지막 대사로 ‘You fell asleep!’이라고 말합니다. 만약 정적 상태로만 감정을 봤다면 neutral이 될 수도 있는 문장입니다. 그런데 대화 내용을 봐봅시다. 어떤 scene을 좋아하냐고 묻는데 오른쪽 배우는 영상을 보지 않고 잠들었었나보죠? 그래서 너 그때 잤었잖아! 라고 화내는 대회를 보면, 대화 내용에 따라 감정이 변화는 것을 알 수 있습니다. 저는 이를 emotional dynamic이라고 이해하였고 이 때문에 traditional emotion recognition과 emotion recognition in conversations가 다르다는 것을 인지하였습니다.
이전에 교수님께서 네이버 이야기를 잠깐 해주신 적이 있는데요. 네이버에서는 이런 연구를 한다고 하였습니다. 어떤 사람이 통화를 하면서 친구에게 이야기를 하는데 치과에 가서 사랑니를 뺐다는 내용입니다. “나 오늘 너무 힘들었잖아(슬픔)→치과 가서 사랑니를 뻈는데 너무 아팠어(슬픔)→근데 빼고 나니까 너무 시원하더라!(기쁨)” 이런식으로 감정이 변했을 때 최종적으로 이 사람의 감정은 기쁨이라고 말할 수 있습니다. 정확히 기억은 나지는 않지만 이런 내용이었던거 같은데 아마 이게 emotion recognition in conversations를 말하는 것은 아닌가 합니다.
<proposed framework>
<1. problem statement>
- k : utterance의 개수
- U : utterance
- Y : 각각의 labels
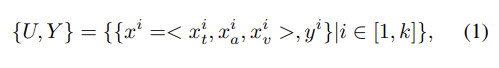
여기서 x^i는 x_t(text), x_a(audio), x_v(visual) 요소에 대응되는 i번째 발화를 말합니다. y_i는 각각의 i번째 발화의 감정 label을 의미합니다.
<2. Muli-modal Fusion Network: M2FNet>
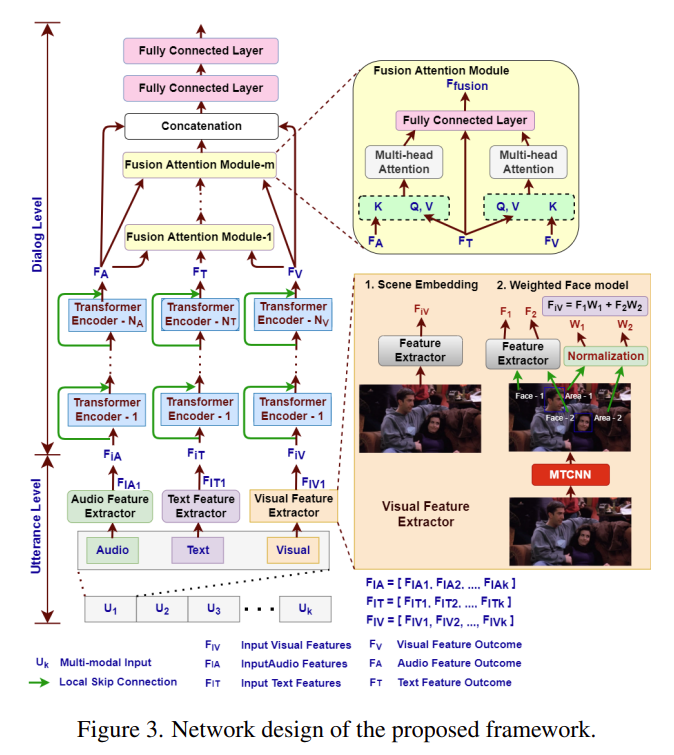
[Figure 3]을 통해 이 논문의 저자가 제안한 MEFNet(Multi-modal Fusion network)의 구조를 확인할 수 있습니다. network는 feateure extraction을 2개 level로 진행하는데요. Utterance level feature extractoion과 Dialog level feature extraction입니다.
처음에는 feature들이 utterance level 모듈에서 독립적으로 추출됩니다. 그런 다음에 dialog level extraction network에서 대화의 상황 정보를 전체적으로 사용하여 각 발화에 대한 올바른 감정을 예측하는 방법을 학습합니다.
<2.1. Utterance level feature extraction>
utterance level feature extraction에서는 dialog level feature extraction network로 넘어가기 전에 각 모달리티에서의 features들이 각각의 발화에 대해서 추출됩니다. 각 모달리티의 input signal은 임베딩하기 위해서 각각의 대응하는 feature extractor를 통과합니다.
- text
이 논문에서는 text feature extractor module로 modified RoBERTa model(\phi_{M-RoBERTa})를 사용했다고 합니다. \phi_{M-RoBERTa}를 fine-tuning하여 F_{IT}를 얻습니다. 수식으로 표현하면 아래와 같습니다.
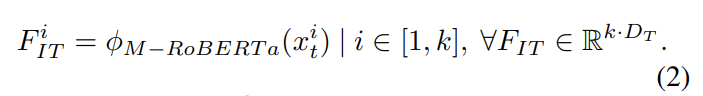
여기서 F_{IT}^I는 i번째 발화의 임베딩을 의미하고, D_T는 임베딩 사이즈를 의미합니다.
<(추가) RoBERTa에 대해서>
BERT는 많이들 들어보셨을 거 같은데 RoBERTa는 많이 들어보시지 못할 것이라 생각하여 간략하게 소개하고자 합니다. RoBERTa는 BERT의 파생 모델로, 기존 모델에 추가적인 학습 방법을 제시하여 성능을 향상시킨 모델입니다. 모델 구조는 BERT와 많이 유사합니다. 자세한 설명은 이 블로그[https://facerain.club/roberta-paper/]를 참고해주시면 좋을 것 같습니다.
- Audio
이 논문에서는 audio feature를 추출하기 위해서 새로운 feature extractor model을 제안하였습니다. 우선 audio 신호를 2D의 Mel Spectrogram으로 변환합니다. 이후에 feature extractor model을 통과하게 되는데, 먼저, 오디오 신호는 time warping, Additive White Gaussian Noise (AWGN) noise와 같은 augmentation 기법으로 processing됩니다. 그 이후 Mel spectrogram으로 변환됩니다. 좀더 자세한 설명은 이후에 설명 드리고자 합니다. Mel Spectrograms(x_a)가 audio feature extractor를 통과하여 F_{IA}로 임베딩되는 과정을 수식으로 표현하면 아래와 같습니다.
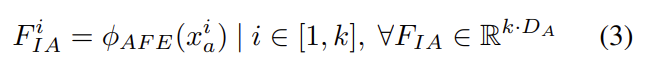
- Visual
visual 부분에서는 풍부한 감정 표현을 위해서 dual network를 제안하였습니다. 여기서도 마찬가지로 논문에서 제안한 extractor model을 사용하였는데 이는 이후에 자세히 설명하고자 합니다. dual network가 어떻게 구성되었는지에 대해서 먼저 설명하고자 합니다.
scene의 context information을 전체적으로 encoding하기 위해서 feature extractor는 15개의 연속된 프레임에서 수행됩니다. 그 다음에는 feature이 frame 축으로 max pooling하여 scene embedding을 얻습니다. 15개의 연속된 프레임에서 얼굴의 감정 관련 feature를 추출하기 위해서 weighted Face Model을 제안했다고 합니다. [Figure 3]에서 확인할 수 있는데 아래 사진을 통해 weighted Face Model을 확인할 수 있습니다.
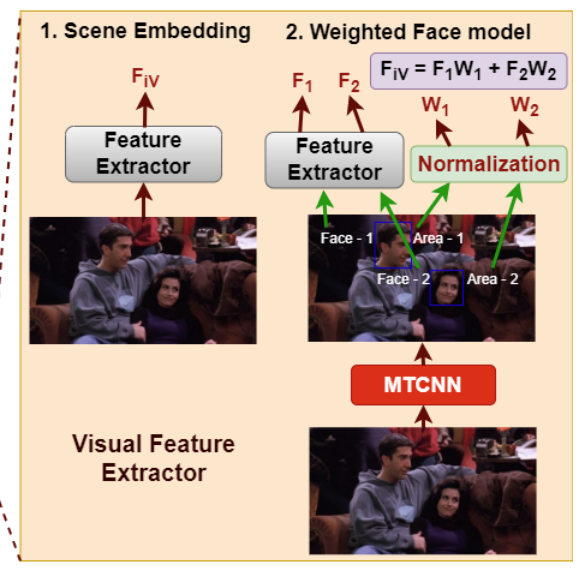
frame이 주어지면, MTCNN(Multi-task Cascaded Convolutional Network)을 통과합니다. MTCNN은 frame에서 현재 사람의 얼굴을 detect하여 bounding box와 confidence를 반환합니다. 그 이후 각각의 얼굴은 feature extractor를 통과하여 각 얼굴의 감정 관련된 feature를 추출합니다. 얼굴과 함께 제공되는 bounding box의 영역은 0과 1 사이가 되도록 normalize 됩니다. 이후에, frame의 얼굴 감정 feature를 얻기 위해서 얼굴의 feature와 각각의 정규화된 영역을 사용하여 weighted sum을 수행합니다. 이러한 과정이 15개의 frame에 대해서 진행됩니다. 이후에는 위에서 말한데로, 추출환 feature는 frame 축으로 max pooling하여 scene embedding을 얻습니다.
이러한 과정을 거쳐서 최종적으로 [식(4)]와 같은 output을 얻게 됩니다.
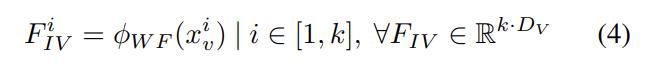
F^i_{IA}는 i번째 발화의 임베딩을 의미하고, \phi_{WF}(x_v^i)는 weighted face model funcion을 의미하고 D_V는 feature embedding의 사이즈를 의미합니다.
이렇게 얻은 text, acuoustic, visual 임베딩을 dialog level feature extractor의 입력으로 하여 각 발화에 대해서 emotion을 예측합니다.
<2.2. Dialog level feature extraction>
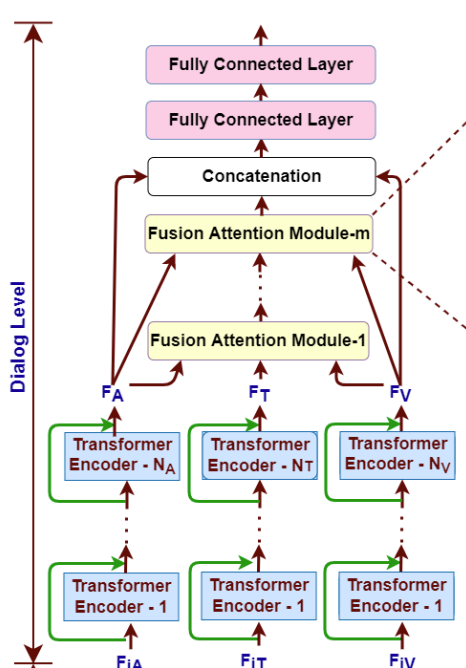
각 모달리티 임베딩(F_{IT}, F_{IA}, F_{IV})은 각각의 대응되는 transformer encoder를 통과하게 됩니다. 이 과정에서 발화의 문맥을 학습하게 됩니다. transformer encoder의 개수는 모달리티마다 다른데, N_T는 text, N_A는 audio, N_V는 visual 모달리티의 인코더 개수를 의미합니다.
또한, lower-level feature를 무시하지 않기 위해서 각 encoder 마다 skip connection을 사용했다고 합니다. 위의 그림을 통해 확인하면 초록색 선이 skip connection을 의미합니다. 이러한 과정을 수식으로 표현하면 [식(5)]와 같습니다.
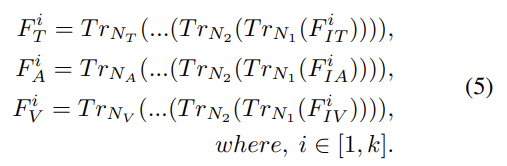
여기서 T_r은 transformer encoder를 의미합니다. 이렇게 임베딩을 transformer encoder를 통과시켜 F_T, F_A, F_V를 얻습니다.
이후에, F_T, F_A, F_V은 논문의 저자가 새롭게 제안한 Multi-Head Attention Fusion 모듈을 통과하게 됩니다. 이 모듈을 통해서 network가 vsual, acoutic information을 더 잘 참고하게 됩니다.
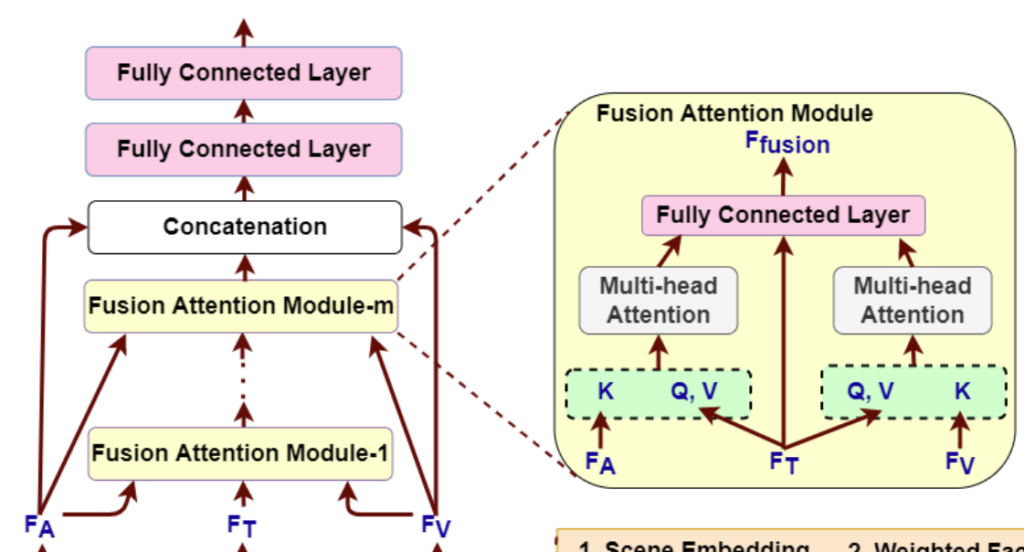
text feature인 F_T는 mult-head attention연산을 위해서 fusion 모듈의 Query(Q), Value(V)의 입력으로 들어가게 됩니다. visual feature F_V, acoustic feature F_A는 Key(K)로 입력됩니다. 이를 통해서 각각의 모달리티는 text vector space로 mapping 됩니다. 그 이후 vector\in\mathbb{R}^{kD_T}을 ouput으로 가지는 fully connected layer를 통과하여 concat 됩니다.
이를 m번 반복하여 최종 output인 F_fusion을 얻는 과정을 수식으로 표현하면 [식 (6)]과 같습니다.
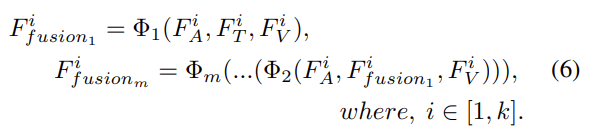
\mathit{\Phi}는 논문의 저자가 제안한 Multi-Head Attention Fusion layer를 의미합니다.
마지막 multi-head attention fusion layer의 output(F_fusion_m)은 visual, acoustic feature map인 F_V, F_A와 CONCAT 됩니다. 이를 식으로 표현하면 [식 (7)]과 같습니다.
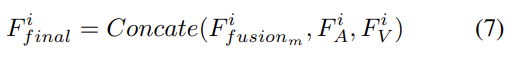
마지막으로 두개의 fully connected layer의 output으로 Y를 가집니다. (Y_p^i =<y^i_1, y^i_2, …., y^i_p. where. i \in [1,k]) 식으로 표현하면 [식 (8)]과 같습니다.
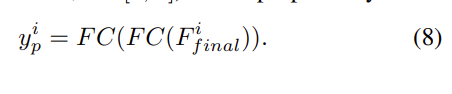
<3. Feature Extractor Module>
위에서 계속 논문의 저자가 제안한 feature extractor module을 나중에 소개한다고 말했는데 지금인 것 같습니다. audio와 visual의 deep feature를 패치하기 위해서 [Figure 4]와 같은 새로운 feature extractor model을 제안하였습니다.
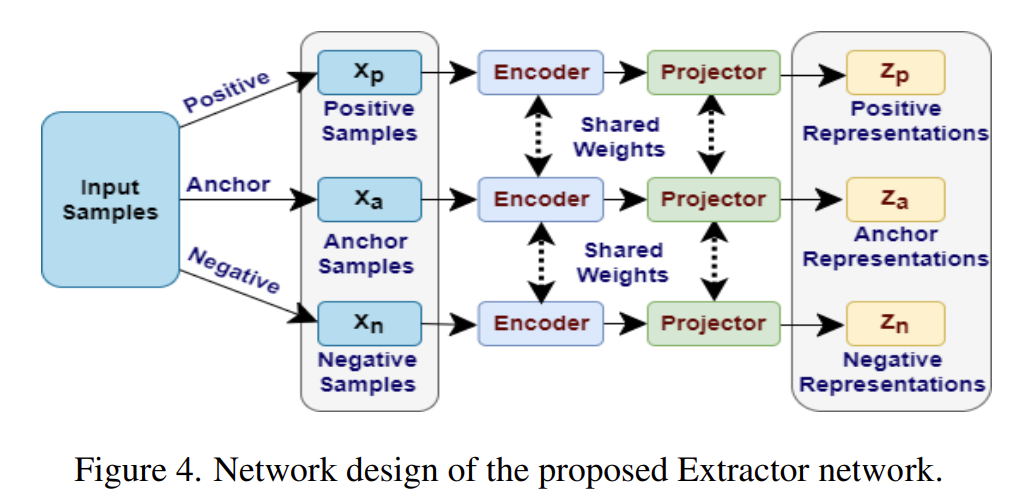
[Figure 4]를 보시면 느낌이 오시겠지만 feature extractor는 triplet network를 기반하여 디자인 되었습니다. 처음에, audio, visual 모달리티에 대해서 anchor, positive, negative sample들이 Facenet(Facenet: A unified embedding for face recognition and clustering)에서 제안된 방법론으로 생성됩니다. 그 다음 eoncder와 projector를 통과합니다. encoder network로는 ResNet18을 backbone으로 사용했다고 합니다. 이를 통해 representation Z (Z = [z_1,…z_N] \in R^(N\times{d})를 얻습니다. d는 차원을, N을 개수를 의미합니다.
제안된 extractor model은 adaptive margin triplet loss (L_{AMT}), covariance loss (L_{COV}), variance loss(L_{Var})의 가중 조합을 사용하여 훈련됩니다. 식으로 표현하면 [식 (9)]와 같습니다.
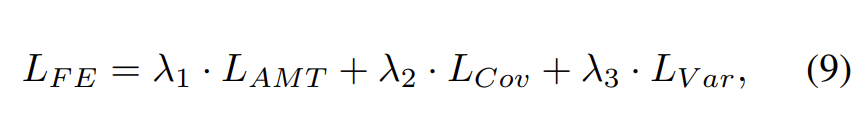
\lambda_1, \lambda_2, \lambda_3은 서로 다른 .loss 함수의 분포를 제어하는 가중치 인자입니다.
각각의 loss 함수가 어떻게 구성되어 있는지 설명드리고자 합니다.
FaceNet에서 triplet loss를 구성할 때 고정 마진 값을 사용하였습니다. 아래 이미지의 알파를 통해서 마진 값이 있다는 것을 파악할 수 있습니다.
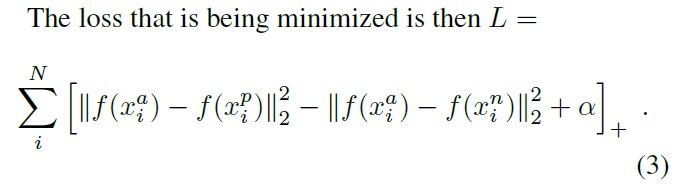
그런데 어떠한 경우에는, positive sample 혹은 negative sample이 anchor와 같은 거리를 갖거나 positive sample이 negative sample 보다 조금만 가까우면 loss가 0이 되어 버립니다. 이러한 이슈를 해결하기 위해서 논문의 저자는 adaptve margin 값을 기반으로 하는 triplet loss를 제안합니다. 식으로 표현하면 [식 (10]과 같습니다.
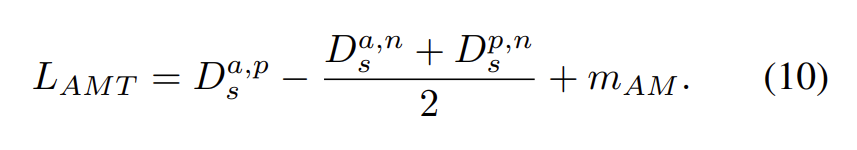
[식 (10)]에서 D_S^{a, p}는 anhor와 positive의 euclidean distance를, D_S^{a, n}는 anchor와 negative의 euclidian distance를, D_S^{p, n}는 positive와 negative의 euclidan distance를 의미합니다. m_{AM}은 adaptive margin을 의미하는데 [식 (11)]읕 통해 계산됩니다. [식 (11)]에 sim은 similarity를, dissim은 dissimilarity를 의미합니다.
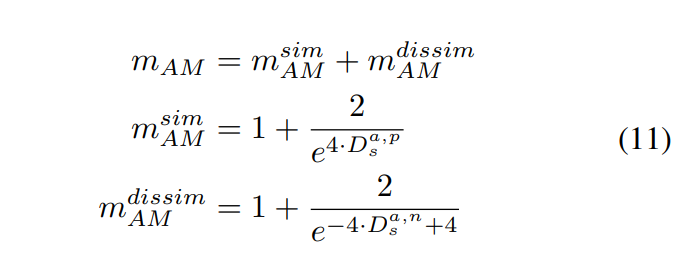
또한, model collapse 문제를 해결하기 위해서 variance loss를 사용하였습니다. [식 (12)]을 통해 확인할 수 있습니다.
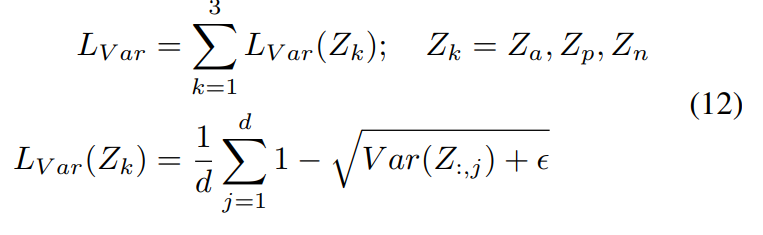
Var(Z) (i.e., \frac{1}{N-1}\sum^N_{i=1}(Z^i - \hat{Z})^2)는 repersentation으로부터 계산한 variance를 의미하고, Z는 mean을 의미합니다.
여기에 covariance loss 또한 적용했는데 [식 (13)]과 같습니다.
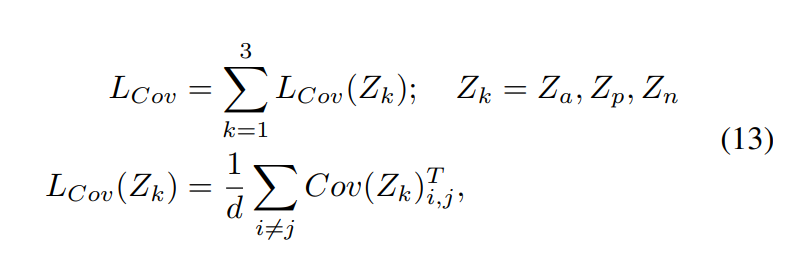
Cov(Z)는 \frac{1}{N-1}\sum^N_{i=1}(Z^i - \hat{Z})(Z^i - \hat{Z})^T를 의미합니다.
<Experimental Analysis and Discussion>
<Dataset>
M2FNet에서는 2개의 데이터셋을 이용하여 실험을 하였는데요. IEMOCAP(Interacive Emotional Dyadic Motion Capture), MELD(Multimodal EmotionLines Dataset)을 사용하였습니다. 서베이 하면서 보니까 주로 emotion recognition in conversations에서는 MELD 데이터셋을 사용하는 것 같아 설명하고자 합니다.
<MELD> (참고)
MELD는 Friends TV 시리즈의 1400개 이상의 대화와 13000개의 발화가 있고 여러 명의 화자가 대화에 참여했습니다. 각 발화는 분노, 혐오, 슬픔, 기쁨, 중립, 놀라움, 공포의 7 가지 감정 중 하나로 분류되며 각 발화에 대한 감정 (긍정적, 부정적 및 중립적) 주석이 있습니다. 다음은 MELD 데이터 세트에 포함된 예제입니다.
찾아보니 데이터셋 다운로드가 쉬워 많은 논문에서 이 데이터셋을 사용하는 것은 아닌가 싶네요.
<Training setups>
loss는 [식 (14)]와 같이 사용되었습니다. categorical cross-entropy를 사용하였고, M은 dialog, k는 utterance의 수를 나타냅니다.
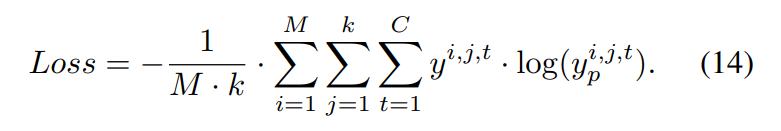
<Experiment>
실험 결과는 text는 베이스로한 sota와 비교한 것과 multimodal을 베이스로한 sota와 비교한 것 두가지가 있어 참신했습니다. [Table 6]이 text를 베이스로한 모델과 비교한 것입니다.
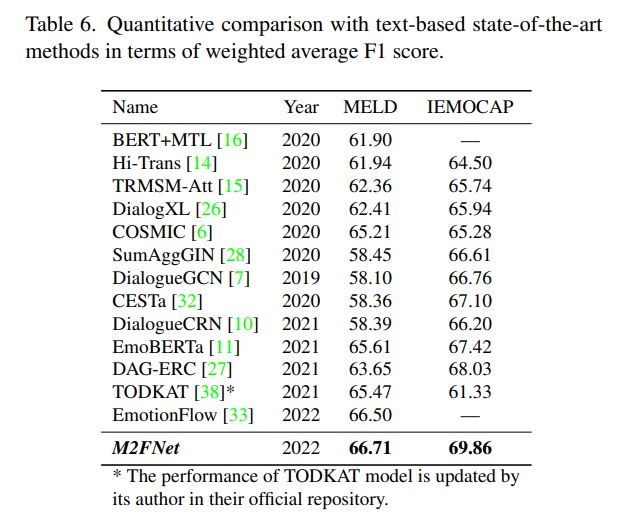
M2FNet의 성능이 제일 좋은 것을 알 수 있습니다.
[Table 7]은 multimodal을 베이스로한 모델끼리 비교한 것입니다.
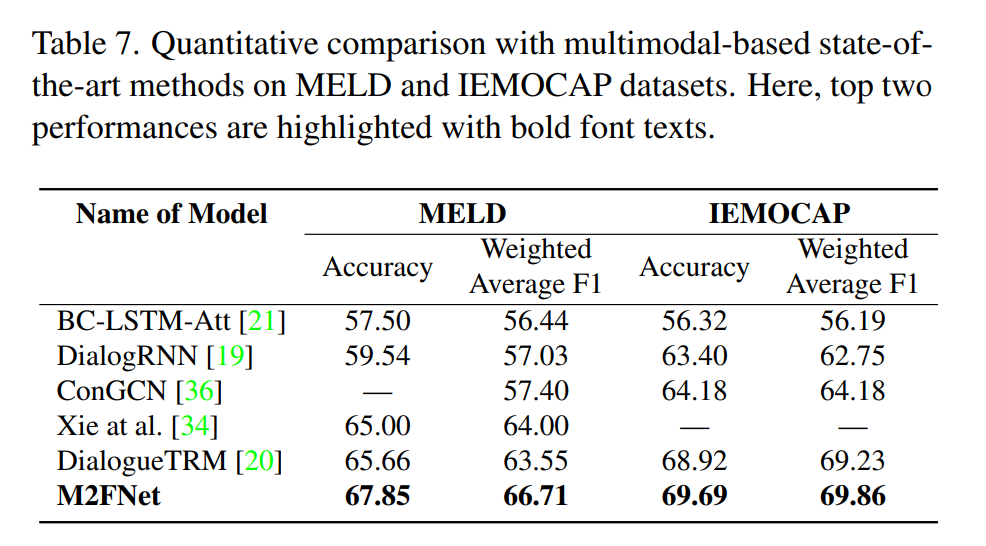
역시나 M2FNet이 가장 좋은 성능을 내는 것을 알 수 있습니다.
<Ablation study>
ablation study도 진행하였는데요.
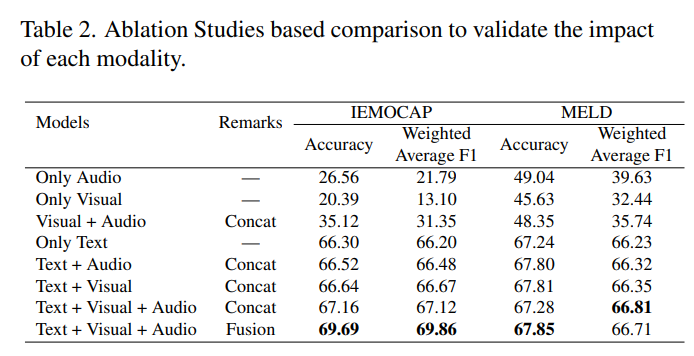
논문에서 multimodal을 써야한다고 주장하는 것과 마찬가지로 text+visual+audio를 모두 사용했을 때 + 저자가 제안한 fusion 방식을 사용했을 때 가장 좋은 성능이 나오는 것을 확인할 수 있습니다.
이렇게 논문 리뷰를 마쳤습니다. emotion recognition in conversations는 emotion recognition과는 다른 재미가 있는 분야인 것 같아 이쪽 분야의 논문을 주로 읽을 것 같습니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
저는 같은 text이더라도 어떤 어조로 말하는지에 따라 감정이 크게 달라질 것으로 생각했는데, 가장 아래 실험 결과를 보니 text만 사용해도 visual+audio보다 높은 성능을 보인다는 것이 신기합니다.
그렇다면 본 논문에서 text를 기반으로 다른 모달들을 추가했을 때의 inference time이나 연산량 차이도 같이 보여주고 있나요?
Only Text와 T+V+A의 성능 차이가 특히 MELD 데이터셋에서는 거의 없다시피한데, inference time이나 연산량은 얼마나 늘어나는지 궁금하여 질문 드립니다.
댓글 감사합니다.
본 논문에서는 inference time이나 연산량 차이에 대한 리포팅이 없는데요. 여태까지 experiment 보면서 생각하지 못했던 부분인것 같습니다. 연산량에 대해서는 아예 연급이 없다싶이하여 말씀드리기 힘들 것 같습니다.
감사합니다
안녕하세요 김주연 연구원님. 리뷰 잘 읽었습니다.
설명에서 “multi-head fusion attention layer를 제안”와 같이 표현하고 있는데요. 제안이라고 표현하기에는 이미 저희 베이스라인 논문에서도 유사한 방식을 사용하고 있어 새롭다고 보기에는 어려운 것 같습니다. 구조의 novelty가 따로 더 있을까요?
추가적으로 학습은 어떻게 진행되나요? 보니까 맥락을 이해하려면 모델 그림에서 U의 값을 이용하는 것 같은데. Output Y에 대한 설명은 있는데… 학습에서는 이 Y를 어떻게 사용하는걸까요? 맥락을 이해하려면 Y를 어떻게 묶어서 쓰는 설명이 있을 것 같은데 없어서 질문드립니다.
댓글 감사합니다.
1) 이광진 연구원님의 댓글을 보고 다시 생각해보니 마찬가지로 저희 베이스라인 논문에서도 이미 유사한 방식을 사용하고 있어 novelty가 떨어진다는 생각이 들었습니다. 그래서 novelty가 더 있는 부분을 본다면 저희 베이스라인 경우 한번만 encoder를 거친다면 여기서는 multi-head fusion attention layer를 여러번 통과하면서 key로 계속 audio와 visual feature를 던저주는 것이 novelty가 아닌가 싶습니다. 사실 이것만으로 부족할 수 있는데 이 논문에서 이것 말고도 여러가지를 제안하였기 때문에 전체를 통틀어서 novelty가 있다고 생각한 것은 아닌가 싶습니다.
2) 이 질문은 input이 어떻게 들어가는냐에 대해서 말씀드리면 해결될 것 같습니다. 우선 input은 utterance(ex:나 밥 먹었어)로 들어간다고 생각하시면 될 것 같습니다.(나 밥 먹었어에 해당하는 text, audio, visual 묶음으로 들어간다고 생각하시면 됩니다.) 이에 따라서 utterance에 맞는 y가 들어가는 것이구요. 저도 많이 헷갈렸던 것이 utterance의 묶음인 dialog(대화)가 input으로 들어가는 것이라 생각하였는데 읽다보니 그것은 아닌것 같고 utterance 하나, 하나가 들어가는 것 같습니다.
+) 세미나에서 들어온 질문과 동일하게 생각해봤는데 feature extractor를 학습 시키고 그 이후에 발화 하나, 라벨 하나 이렇게 들어가는 것은 아닌가…? 싶기도 하고…. 좀더 확실히 알아본 후에 댓글 달도록 하겠습니다… 근데 y label을 묶는 부분은 없어서 하나 하나 학습시키는 것이 아닌가 싶습니다.
감사합니다
좋은 리뷰 감사합니다.
Figure 4에서 audio와 visual의 deep feature를 패치하기 위해 feature extractor model을 제안하였다고 했는데 feature를 패치한다는 것이 무슨 의미인가요?
그리고 마지막 성능평가에서 text+autio보다 text+visual이 약간 더 높은 성능을 보이는데 emotion recognition in conversations에서는 표정에서의 detail보다 말투에서의 detail정보가 더 크게 영향읆 미칠 것 같다고 저는 생각했는데요, 김주연 연구원님의 생각도 궁금합니다!
댓글 감사합니다.
1) deep feature를 가져오기 위해서 feature extractor model을 제안하였다고 생각하시면 될 것 같습니다!
2) 저도 이 부분은 조금 신기한 부분이라 생각합니다. 실험 결과를 보면 only audio, only visual부분을 보면 audio 부분의 성능이 더 높은 것을 보면 말투에서의 정보가 더 성능에 영향을 줄 수 있다고 할 수 있는데 text+audio, text+visual 부분을 보면 text+visual 성능이 더 높은 것을 확인할 수 있습니다. 저는 이렇게 생각하는데요. 완전 제 뇌피셜(ㅎㅎ)이라고 생각하시면 좋을 것 같습니다. 저는 text에서도 말투에 대한 정보가 들어있다고 생각합니다. (ex: 알았다구요, 알겠습니다의 차이) 그 때문에 audio에 있는 말투에 대한 정보와 text에 있는 말투에 대한 정보는 비슷한 경향을 띄는데, visual은 text와 완전히 다른 경향성을 띄는 정보이기 때문에 audio+text에 비해서 visual+text가 더 풍부한 정보를 가져 성능이 높은 것은 아닌가…. 싶습니다. 사실 이거는 다른 모델에서도 이런 경향성을 띄는지 봐야 확실하겠지만 우선 제 생각은 이렇습니다. 이 부분에 대해서는 깊게 생각해보니 못했는데 댓글 덕분에 생각하게 되었네요. 감사합니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
모델의 학습과 데이터셋 관련해서 궁금한 점이 있는데, M2FNet은 모델 학습 시 입력 데이터가 어떤 식으로 들어가나요? dataset에 관한 설명만 읽어 보았을 때는 하나의 긴 영상, 텍스트, 음성 데이터를 사용하고 발화 구간별로 감정 label이 존재하는 것으로 이해하였습니다. 그런데 [그림3]을 보면 U를 input으로 사용하는데 혹시 uttetance를 의미하나요? 만일 그렇다면 utterance단위로 세 가지 데이터가 각각 feature extractor에 들어가는데 데이터셋의 발화 구간의 데이터만 뽑아서 쓰는 건가요?
댓글 감사합니다.
네 맞습니다. 발화 단위로 세 가지 데이터가 각각 feature extractor에 들어간다고 생각하시면 될 것 같습니다. 모델의 input으로 긴 비디오가 들어가는데 모델이 발화 구간의 데이터를 뽑아서 사용하는 것은 아니고, 발화 구간의 데이터를 input으로 넣어준다는 것이 맞는 것 같습니다.
감사합니다.