안녕하세요. 지난번에 읽은 논문에서 Alignment와 Uniformity 관점에서의 Loss를 설계한 논문을 바탕으로 하는 연구가 있었는데, 새로운 느낌이 들었습니다. 찾아보니 해당 연구를 바탕으로 하는 다른 논문들이 많아서 관심이 가서 다른 논문도 읽어봤습니다.
Introduction
Zero-shot video classification(이하 ZSVC)는 seen 클래스와 unseen 클래스를 나누어, seen 클래스에서 학습하고 unseen 클래스에서 평가하는 연구분야입니다. 이러한 특성 때문에 일반화된 표현력을 학습하기 위해서 visual 정보와 semantic한 정보를 잘 학습하는 것이 연구의 목표였습니다. 하지만 이 두 정보의 semantic-gap과 도메인의 차이 때문에, 모델이 일반화된 표현력을 가지게 하는 것이 쉽지는 않았습니다. 논문에서는 이 문제를 아래와 같이 해결합니다.
- Visual 정보와 Semantic 정보의 semantic-gap : Alignment와 Uniformity 관점에서의 Loss 설계
- Domain-shift(도메인 차이) : Seen 클래스를 바탕으로, Unseen 클래스를 합성해서 학습할 수 있는 모델
그리고 또 하나의 contribution으로 closness와 dispersion score라는 모델의 일반화를 정량적인 수치로 표현할 수 있는 metric을 제안하고 이를 통한 평가를 보여주고 있습니다.
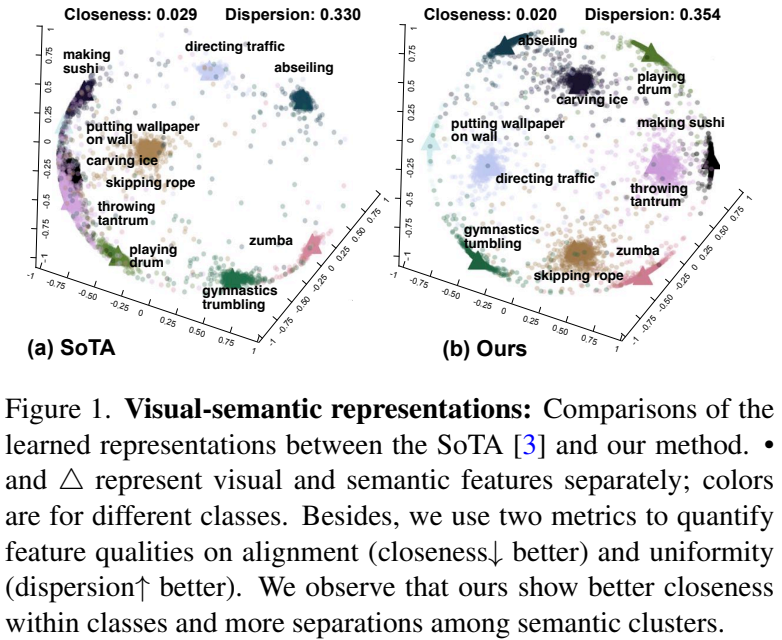
본 논문의 모델을 제안한 새로운 score와 representation을 시각화하면 [그림 1]과 같습니다. score 자체는 큰 차이가 없어 보일 수 있어도, 임베딩 자체는 구분력있이 분포되어 있는 것을 볼 수 있습니다.
Alignment-Uniformity aware Representation Learning (AURL)
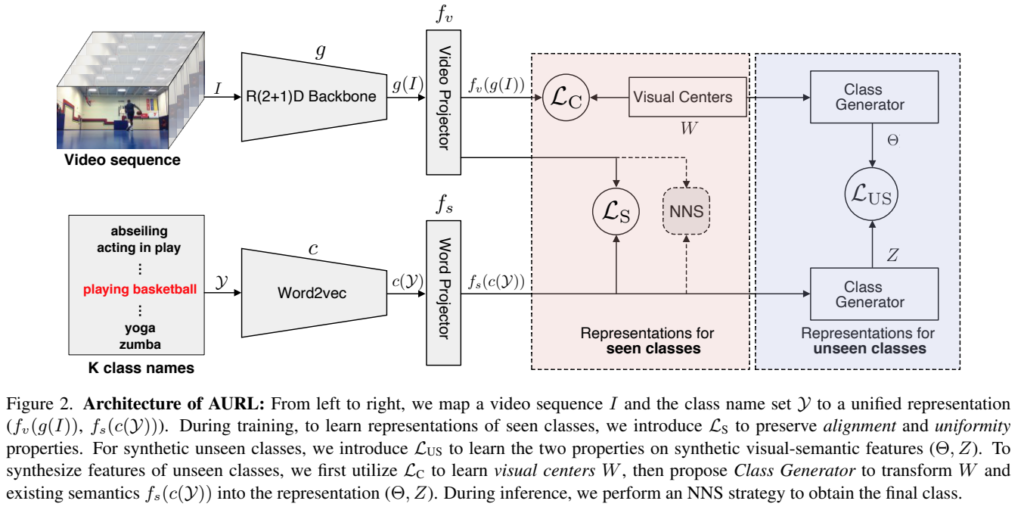
전반적인 모델 구조는 visual feature를 3D 백본을 이용하여 추출하고, text feature는 Word2Vec을 통해서 추출하고, 추출된 두 feature를 projection후에 Loss를 태우는 구조를 가지고 있습니다. (Text 정보는 라벨링으로 짧은 문장으로 구성된 정보를 사용) Video projection 레이어는 FC 레이어 3개로 구성된 MLP projection layer이고, word projection 레이어는 video proejction layer의 MLP projection 레이어의 앞에 FC 레이어가 하나 추가된 구조입니다. 모델은 간단하지만 뒤의 학습 매커니즘이 좀 복잡한 편이고, 기존의 SOTA 모델들이 video에 해당하는 부분만 학습했다면 이 논문에서는 두 데이터 모두를 학습한다는 부분에서 큰 차이가 있습니다.
Alignment-uniformity aware Loss
복잡한 Loss 이야기를 이제 시작해봅시다. 지난 리뷰에서도 alignment와 uniformity에 대한 내용을 다뤘었는데요. “Contrastive Learning via Alignment and Uniformity” 첨부하는 링크의 해당 파트를 읽고 넘어오시면 이해가 쉽습니다. 그래도 정리를 다시 해보면 Alignment는 positive sample들 끼리는 유사해지도록 feature를 학습하고, Uniformity는 feature가 unit hypersphere에 균일하게 분포하도록 해서, 일반화가 더 잘되도록 학습한다고 정리할 수 있습니다. 우선 여러 Loss에 대한 이야기가 쭉 나옵니다. 최종 Loss는 L_{contrast}만 보면 되고요. 그 단계까지 Loss를 발전시켜나가는 과정에 대해서 다루겠습니다.
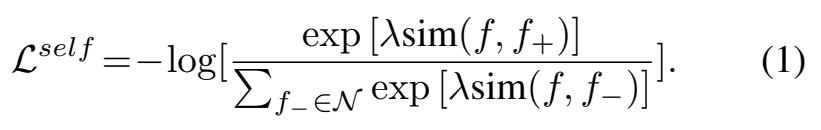
우선 “[NIPS 2021] Intriguing Properties of Contrastive Losses”에서 alignment와 uniformity 관점에서 generalization을 강조한 contrastive loss를 제안했고, 그 결과가 [수식 1]입니다. 이 수식은 self-supervised contrastive loss로 불려서, L^{self}로 정의합니다. (InfoNCE랑 유사합니다.) [수식 1]은 notation을 보시면 아시겠지만, f(feature)를 사용하는데요. 즉, visual feature만을 이용한 Loss입니다.
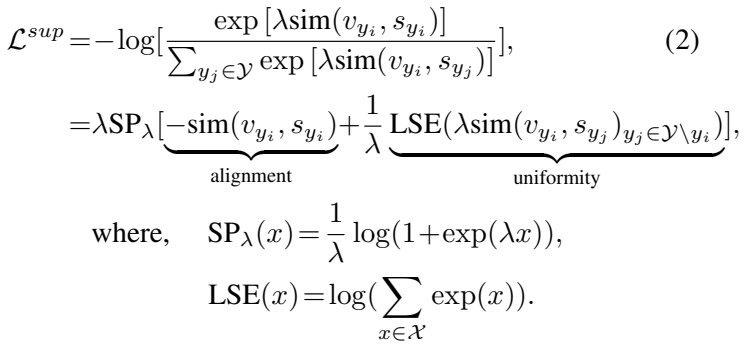
[수식 2]는 supervised loss라고 부릅니다. 기존의 ZSVC에서는 visual feature와 semantic feature가 유사해지는 것에만 집중했지만, 여기서는 약간 다르게 접근합니다. v_{y_i}, s_{y_i}는 각각 class set \gamma에 속하는 클래스 y에 대한 visual feature와 semantic feature를 뜻합니다. [수식 1]에서는 이 visual-semantic feature의 유사도가 [수식 1]의 visual feature 끼리의 유사도 부분을 대체합니다.
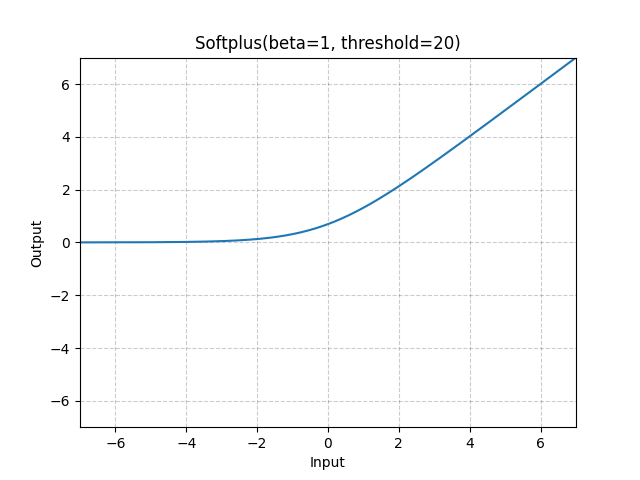
이 수식을 풀어쓰면 두가지 함수로 나누어서 alignment 관점과 uniformity 관점에서 볼 수 있는데요. 먼저 Alignment를 측정하는 부분에서는 SP(Soft-Plus function)를 사용합니다. 이건 첨부해드리는 이미지처럼 activation function의 한 종류입니다. 그래서 visual-semantic feature 페어의 유사도가 높아지는 방향으로 학습을 수행합니다. 그리고 Uniformity를 측정하는 부분에서는 LSE(LogSumExp)를 사용하는데, 수식을 보면 텐서의 지수의 로그합이죠? 그래서 특정 visual feature와 해당 visual feature의 페어가 아닌 모든 semantic feature와 유사도의 로그 합이 됩니다. 이렇게 학습을 하면 서로 다른 클래스의 feature 들의 유사도를 최대화 시키는 방향으로 학습이 되기 때문에, feature들을 멀리 퍼뜨린다고 보면 됩니다.
L^{sup}performs better
그래서 이렇게 설계한 두 Loss를 비교해보면 당연히 visual feature와 semantic feature를 동시에 학습하는 L^{sup}가 더 좋았다고 합니다. 가장 최근 논문들에서 만든 supervised contrastive loss랑 비교해도 더 좋았다고 하네요. 이 부분에서 L^{self}와 triplet loss의 장점을 유지하기 위해서 upperbound를 지정했다고 합니다.
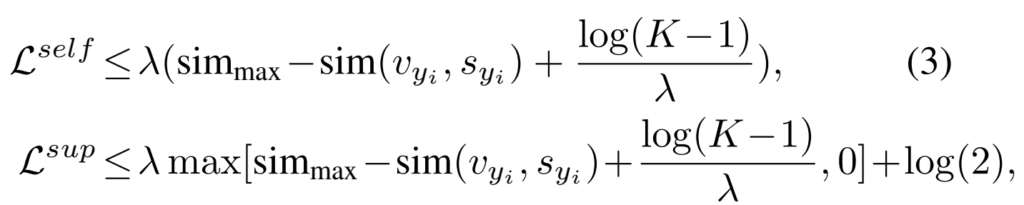
K가 클래스의 갯수라고 가정했을 때, negative pair들의 유사도의 최대값(sim_{max} = max_{y_j\in{Y}\backslash{y}}sim(v_{y_i}, s_{y_i}))가 되어서 학습시에 최대값이 지정되게 됩니다. 비교를 위해서 L^{self}에도 비슷한 식으로 upper bound를 지정해주었습니다. 그래서 이러면 어떤 장점이 있느냐… 하면…
- \frac{log(K-1)}{\lambda}\geq2 일 때, 두 upper bound는 비슷해져서 L^{sup}는 L^{self}만큼 repsentation learning task에서 잘 작동합니다.
- 0\leq \frac{log(K-1)}{\lambda}< 2 일 때, L^{sup}의 upper bound가 triplet loss와 비슷해져서 hard positive/negative mining이 가능해집니다.
- L^{sup}는 분모에서 모든 negative에 대한 합을 보존해서, 클래스간의 분별력을 개선한다.
L^{sup}for seen and unseen classes
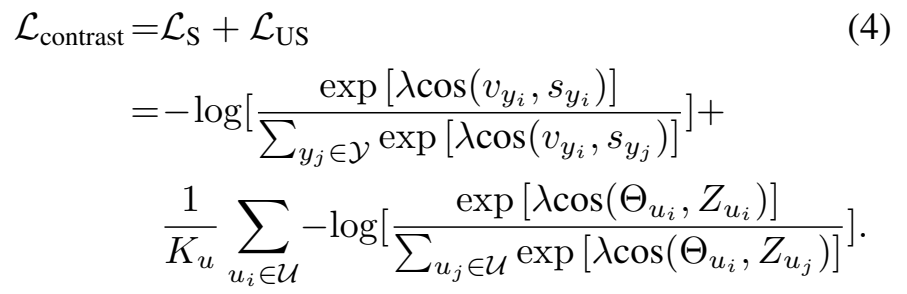
앞서 정의한 L^{sup}를 이용해서 seen class와 unseen class를 학습하는데 사용합니다. (각각 S와 US로 Loss에서 표현) Seen class에서의 학습은 동일하다고 보면 되는데, unseen class에서의 학습이 살짝 달라집니다. Unseen class에서는 합성 클래스 \mu를 사용하는데요. 이건 class generator를 통해서 생성이 되고, \Theta{}는 합성된 visual feature Z는 합성된 semantic feature에 해당하는데 자세한 부분은 다음 섹션에서 설명하겠습니다. 결론적으로는 Seen 학습과 (정규화를 감미한) Unseen 학습을 한번에 수행한다는 것이 핵심입니다.
Class Generator
Visual과 semantic 페어들 (\Theta, Z)을 합성하기 위해서 본 논문은 seen class들의 visual/semantic feature들의 모든 페어를 uniform하게 선형 변환시키는 class generator를 사용합니다.
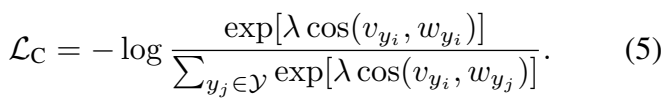
학습은 [수식 5]를 통해 수행됩니다. cosine similarity로 두 feature의 유사도를 계산하는 것을 제외하면 나머지와 유사합니다. 여기서 계산하는 두 feature v_{y_i}, w_{y_i}는 각각 visual feature와 visual center를 뜻합니다. 여기서 visual center는 fc 레이어로 학습되는 값입니다. L_c는 angular softmax loss(classification loss)를 통해서 특정 feature가 해당하는 클래스의 분포의 중심으로 모이게 합니다.
Class generator 자체는 이렇게 학습을 하는게 맞는데. 모델 그림을 보면 이 generator는 unseen class를 이용해서 학습됩니다. 그러니까 입력 데이터는 위에서 설명했던 데이터랑 살짝 달라집니다. 여기서는 입력에 inter-polate / extra-polate를 적용해서 변환을 줬다고 합니다.
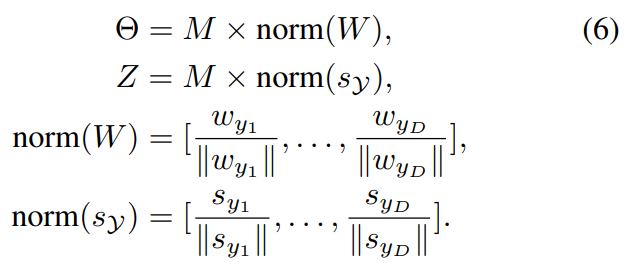
변환 과정은 [수식 6]으로 정리됩니다.
- M은 inter- and extra-polations에 사용되는 matrix
- \Theta는 visual feature인데, visual center W를 활용해서 합성된 feature
- Z는 semantic feature인데, 특정 클래스의 visual center값에 해당되는 semantic feature s_{y_i}에 합성해서 만들어진 feature
로 정리할 수 있을 것 같습니다.
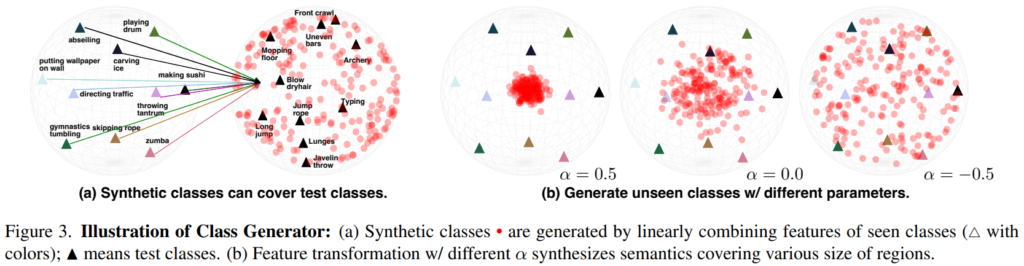
수많은 증명 과정은 넘어가고, 결과만 보게 되면 [그림 3]과 같은데요. 실제로 이렇게 seen class에서 unseen class를 생성하면 test class를 커버할 수 있을 만큼의 풍부한 데이터를 생성할 수 있다는 것을 확인할 수 있습니다.
Closeness and Dispersion
이제 alignment와 uniformity를 정량적으로 보여주기 위한 metric에 대해서 알아봅시다.
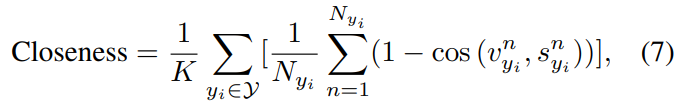
[수식 7]은 closeness로, 같은 클래스 내의 feature들의 평균을 계산합니다. 이러면 visual feature와 semantic feature가 얼마나 유사해졌는지를 측정할 수 있습니다.
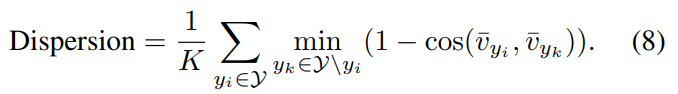
[수식 8]은 Dispersion인데요. 이건 이제 특정 visual feature를 사용하는 것이 아니라, 특정 클래스 내의 모든 visual feature의 평균을 입력으로 사용합니다.
Experiments
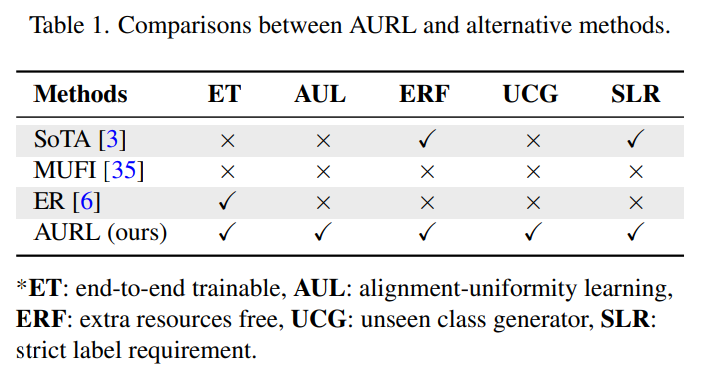
[표 1]은 다른 방법론과의 특장점 비교(?) 정도인데요. 기존의 방법론들에서 없는 특이점들이 많다고 이야기는 하는데, 최근에 나오거나 이 논문에서 제안하는 내용이 많아서 end-to-end 학습이나 ERF / SLR 정도만 비교선으로 보면 좋을 것 같습니다.
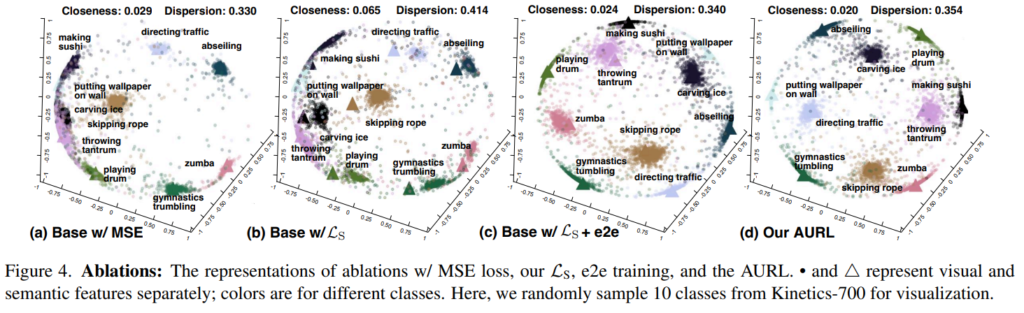
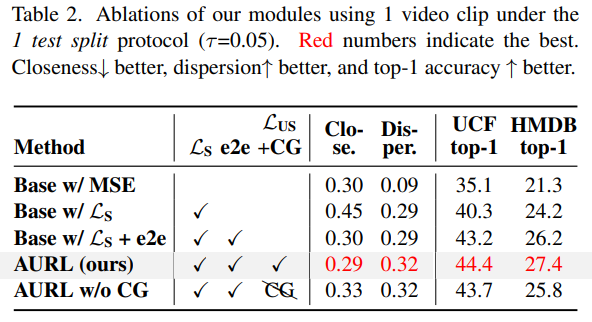
[그림 4]와 [표 2]는 본 모델에서의 module-wise ablation입니다. Base 모델은 뒤에서 비교할 SoTA라고 표현하는 모델의 구조만 따왔다고 보면 됩니다. 기본적으로 alignment/uniformity 관점의 Loss만 있으면 성능은 좋지만 clossness와 dispersion 관점에서는 오히려 안 좋은 것을 볼 수 있습니다. 이러한 관점은 end-to-end 학습에서 개선되고 unseen class를 학습하면 더 성능이 오르는 정도로 정리할 수 있을 것 같습니다.
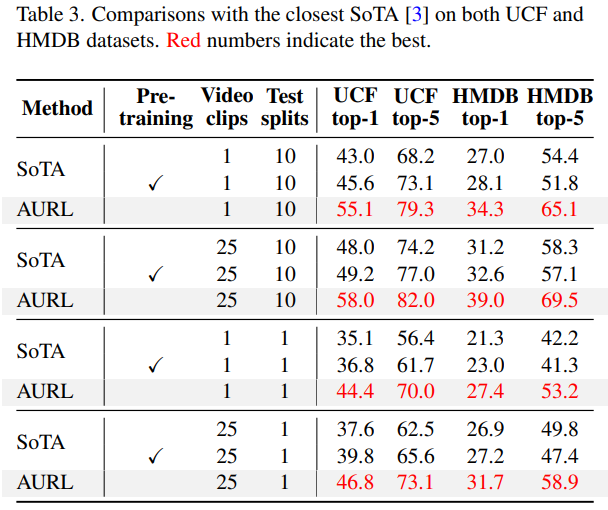
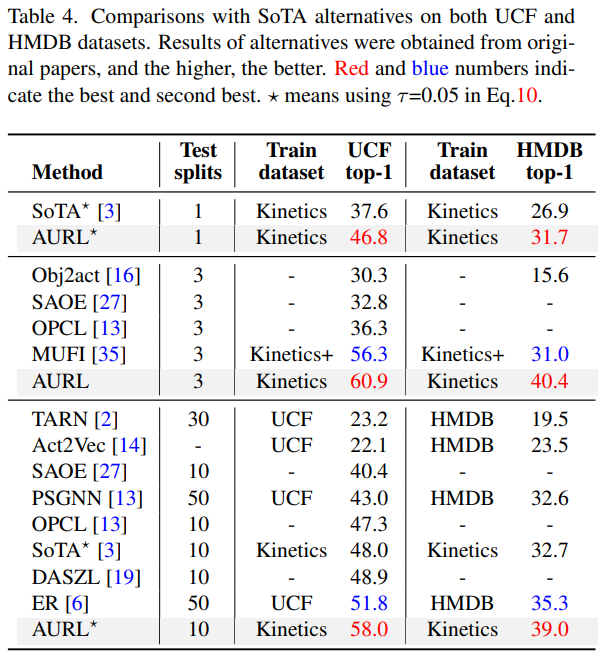
[표 3]과 [표 4]는 타 방법론과의 정량적인 비교입니다. 대충 봐도 기존 방법론 대비 성능이 크게 오른것을 볼 수 있습니다. 학습 데이터셋과 평가 데이터셋이 다를 수는 있어서 비교를 잘 하면서 봐야하지만, UCF→UCF와 같이 같은 데이터셋으로 학습/평가를 진행한 경우보다 더 좋은 성능을 보입니다.
Conclusion
확실히 alignment와 uniformity라는 특성이 ZSVC에 적합하고, 그 적합하다는 사실을 잘 발견해서 잘 적용한 논문이었던 것 같습니다. 이렇게 학습하면 이런 결과가 나온다는 설명도 논문에는 꽤 자세하게 나와있어서 좋았던 것 같습니다.
좋은 리뷰 감사합니다.
학습 때 사용하는(실제로는 seen인) 데이터들의 클래스들을 seen과 unseen으로 임의 가정하여 위와 같은 학습 방법을 거치는 것이 맞나요?
그리고 class generator에서 unseen 클래스를 학습할 때 inter/extrapolate 의 변환 과정이 왜 필요한지, 무엇을 기대하고 적용해주는 것인지 잘 이해하지 못했는데 설명해주시면 감사드리겠습니다.
학습 때 사용하는(실제로는 seen인) 데이터들의 클래스들을 seen과 unseen으로 임의 가정하여 위와 같은 학습 방법을 거치는 것이 맞나요?
=> Seen Class로 정의된 클래스들이 있는데 학습은 그걸로만 합니다. 랜덤으로 고르는지 까지는 모르겠는데, 아무튼 클래스가 10개라면 5개로 학습하고 나머지 5개로 평가해본다고 생각하는게 쉬울 것 같네요.
그리고 class generator에서 unseen 클래스를 학습할 때 inter/extrapolate 의 변환 과정이 왜 필요한지, 무엇을 기대하고 적용해주는 것인지 잘 이해하지 못했는데 설명해주시면 감사드리겠습니다.
=> 해당 TASK에서 내가 학습하지 않은 클래스를 잘 맞춰야하는게 핵심입니다. feature embedding은 한정적인 공간안에 분포될 수 밖에 없는데, seen class 만으로 학습을 하면 그 클래스만 있다고 생각하고 학습도 일반화가 안되도록 학습이 됩니다. 이를 방지하기 위해서 변환 과정을 통해서 임의의 클래스가 있다고 가정하고 학습을 하면, 좀 더 많은 클래스에서 학습을 하는 효과가 나서 일반화 정도가 높아지는 것을 기대한다고 보면 될 것 같습니다.
좋은 리뷰 감사합니다.
Uniformity를 위해 설계한 loss(수식2)를 학습시키기 위해, Class generator 과정이 필요하고, Class Generator에서 unseen class를 만들어 내는 과정은 두 feature가 기존의 seen class의 visual/semantic center를 기반으로 동일한 matrix을 적용한 것으로 이해하였습니다. 그렇다면 여기에는 visual feature와 semantic feature가 비슷한 representation을 가진다는 가정이 있는 것인가요??
그렇다면 여기에는 visual feature와 semantic feature가 비슷한 representation을 가진다는 가정이 있는 것인가요??
=> 네. Alignment 관점의 최적화가 결국은 두 feature가 비슷해지게 하는 역할을 수행합니다.
좋은 리뷰 감사합니다.
실험에 사용된 데이터셋이 human motion 위주의 데이터 인 듯 합니다! 그렇다면 물체데이터나 상업데이터에 대한 확장은 적용되지 않은것인가요? 해당 데이터셋이 본 테스크에서는 더 쉬울 듯 하긴 하지만 여쭤봅니다 ㅎㅎ
비디오로 하는 zero-shot learning 연구를 하려면 비디오 데이터셋이 있어야 하는데 적합한 데이터셋이 action 데이터셋 밖에 없어서 이거밖에 없는 것 같습니다.