안녕하세요, 오늘 제가 X-Review에서 소개해드릴 논문은 IEEE Transactions on Multimedia 저널에 게재된 ‘A Novel Action Saliency and Context-Aware Network for Weakly-Supervised Temporal Action Localization’입니다. 올해 1월 5일날 publish 되었다고 하여 2023으로 표기하였습니다.

최근 한 두 달정도 Self-supervised Video Representation Learning(SSVRL) 논문을 읽어왔었는데, 2월부터는 SSVRL 논문들과 더불어 제가 가장 큰 관심을 갖고 있는 Weakly-supervised Temporal Action Localization(WTAL) task 관련 최신 논문들을 다시 follow-up 할 예정입니다.
WTAL task는 untrimmed video에서 video-level label만을 가진 채로 action이 일어나는 구간과 그 action이 무엇인지 분류하는 task입니다. 여러 번 설명 드린 적이 있어 추가로 자세한 내용이 궁금하시면 이전 리뷰들을 참고하시거나 질문을 남겨주시면 좋을 것 같습니다.
이 논문은 최근 TMM에 게재되었다고 하여 쭉 읽어보았습니다. 다 읽고나니 방법론이 뭔가 최근 WTAL 연구에서 효과가 좋았던 기법들을 조금씩 변형하고 합쳐져 만들어졌다는 생각이 들지만, 그래도 성능이 높은 편에 속하기도 하고 오히려 잠깐 잊고 있었던 기법들을 복기할 수 있어서 도움이 되었던 논문입니다.
리뷰 시작하겠습니다.
1. Introduction
Introduction에서는 비디오 연구의 활성화, TAL, WTAL task의 중요성에 대해 먼저 언급합니다. 대부분의 논문에서 언급하는 내용이라 크게 주목할 부분은 없어 보이고, 이후 문제 정의하는 부분을 살펴보겠습니다.
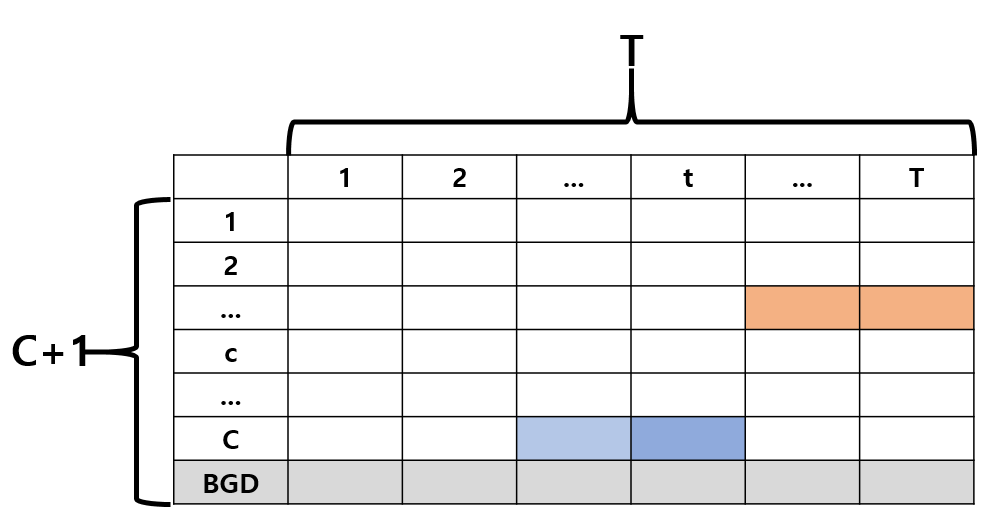
WTAL task 연구의 발전을 이야기할 때 Temporal Class Activation Map(TCAM)은 빠질 수 없습니다. TCAM은 위 그림 1처럼 데이터셋에 존재하는 클래스에 대해 하나의 비디오가 구간 1부터 T까지의 clip으로 나눠져 있을 때 각 clip이 각 클래스에 해당할 확률값을 담고 있는 형태였습니다.
연구 초창기에는 이 TCAM을 이용한 attention score를 뽑아내어 구간을 찾고 FC layer를 통해 분류하는 방식이 존재했지만, 이후에는 TCAM에 top-k pooling 방식을 적용해 localization을 수행하는 Multiple Instance Learning 방식으로 발전하였습니다.
결국 temporal annotation이 없는 상황 속, 그 비디오에 어떤 action이 존재하는지 분류하는 과정에서 clip들의 관여도를 나타내는 TCAM이 얼마나 잘 만들어졌는지가 localization 성능과 직결되었습니다. 그래서 이전 연구에서 TCAM을 잘 만들어내거나 노이즈가 최소화 된 attention score를 얻기 위한 다양한 노력들이 선행되었었습니다.
위와 같은 연구 동향 속 저자가 지적하는 문제에 대해 소개해드리겠습니다. 이전 연구들이 계속 발전해오며 좋은 성능을 달성한 것은 맞지만, 아래와 같은 두 가지 문제점은 해결하지 못했다고 합니다.
- Action saliency and context modeling problem
- Two-stream feature fusion problem
첫 번째 문제에 언급된 action saliency modeling을 통해 비디오 전 구간 중 action이라고 예측되는 부분들이 coarse하게라도 추려지길 기대하고, coarse하게 추려낸 구간들에 context modeling 정보를 활용해 더욱 정교한 action의 구간을 찾아내길 기대하는 것입니다.
사실 비디오에서의 action saliency와 context가 정확히 무엇인지 저자가 직접 정의하고 있지는 않습니다. 그래도 위 기대 효과에 따르면 action saliency는 비디오에서 action으로 특정할 만한 부분에 대한 정보를 의미하는 것으로 보이고, context는 특정한 구간의 completeness(예측 구간이 너무 넓거나 좁지 않고 알맞은 것)를 보장해줄 수 있는 비디오의 전반적인 문맥 흐름 정보를 의미하는 것으로 보입니다.
개인적으로는 최근 대부분의 WTAL 연구가 암시적으로라도 위와 같은 방향으로 문제를 해결하고있다 느꼈었는데, 왜 앞선 연구가 위 문제를 다루고 있지 않다고 하는지에 대한 분석이 없어 설득력이 조금 떨어졌습니다. 저자의 방법론을 통해 앞선 연구의 부족함을 채운다기보다 유사한 방향으로 한 발짝 더 나아가는 논문이라고 생각하시면 납득하기 쉬울 것 같습니다.
그리고 두 번째 문제에서 two-stream이란 WTAL task에서 공통적으로 사용하는 RGB feature와 optical flow feature를 의미하는데, 연구 초반에는 한 비디오에 대해 RGB feature와 optical flow feature를 먼저 단순 concat 후 각자의 방법론을 적용하는 방식이 많았습니다. 하지만 RGB는 context 정보, optical flow는 motion 정보를 담고 있다는 특성을 잘 활용하려면 단순 concat만으로는 부족할 수 있을 것입니다.
따라서 저자가 정의한 두 문제를 종합해보면 본 논문은 RGB feature와 flow feature 각각이 담고 있는 정보의 관점에서 한 번씩 action saliency와 context를 추출하고, 전체 파이프라인 중 이들을 여러 형태로 다양하게 합치며 정제된 action saliency와 context 정보를 최대한 얻으려고 노력합니다.
저자가 위 주장을 펼칠 때 어떠한 분석이나 자료를 함께 제시하고 있지 않아 설득력이 조금 떨어지긴 합니다. 보통은 이전 연구에서의 문제점을 정성적으로 보여주거나, 더 나아가 그것을 개선한 자신들의 방법론과의 정성적 비교 정도는 맨 처음에 제시하고 시작하는 경우가 많은데 그러한 분석이 없었던 것이 아쉬웠습니다.
또한 Introduction이 WTAL task의 이전 방법론들과 그 설명을 쭉 나열한 뒤 위에서 언급한 두 가지 문제점이 등장하는데, 언급하는 논문만 다를 뿐 Related Work와 형식이 거의 동일한 것 또한 아쉬웠습니다. 어떻게 보면 정의한 문제 자체가 너무 추상적이라 분석 자료를 제시하기가 좀 어렵지 않았나 생각합니다.
Introduction에서는 더 살펴볼 만한 내용이 없어 이제부터 저자가 제안하는 방법론을 보도록 하겠습니다.
2. Action Saliency and Context-Aware Network
WTAL을 수행하기 위해 저자가 제안하는 전체 파이프라인(그림 2)이 Action Saliency and Context-Aware Network(ASCN)이고, ASCN은 Feature Extractor, Feature Enhance Module, Localization Module로 구성되어 있습니다. 그 중 Feature Enhance Module에 앞서 언급한 첫 번째 문제를 해결하는 Temporal Saliency and Context Module(TSCM)과 두 번째 문제를 해결하는 Channel self-attention module(CSAM)이 포함되어 있습니다.
빨간색 점선으로 표시한 부분이 본 논문의 핵심 contribution입니다. 그림의 아래 부분에서 TSCM, CSAM은 생각보다 단순한 구조로 이루어져있는 것을 알 수 있습니다. 더불어 Localization Module의 Hybrid Attention도 핵심으로 표시되어 있는데, 이는 뒤에서 설명드리겠습니다.
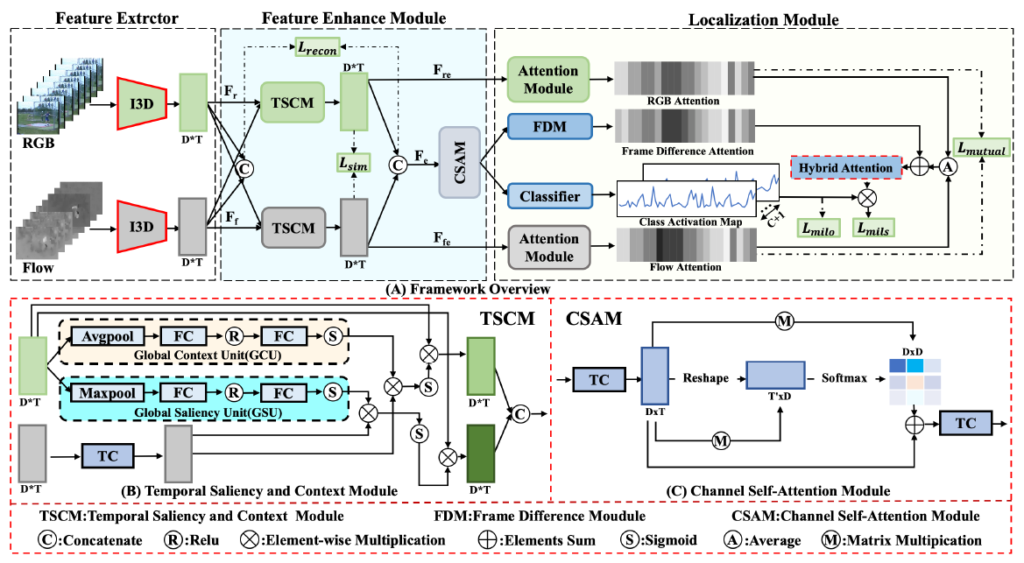
그러면 전체 방법론에 대해 입력부터 출력까지 순서대로 알아보겠습니다.
Feature 추출 부분까지는 새로운 점이 없기 때문에 익숙하신 분들은 A, B의 notation만 확인하시고 바로 C절로 넘어가셔도 좋을 것 같습니다.
A. Problem Formulation
먼저 방법론 설명에 사용될 notation을 정리해보겠습니다.
비디오V=\{x_{t}\}_{t=1}^{L}에 L개의 프레임이 존재하고, V에 대한 annotation Y=\{y_{1}, y_{2},\cdots{}, y_{n}\}라고 지정해줍니다. n은 전체 action 클래스 개수일 것이고, 만약 비디오에 j번째 action이 존재하면 y_{j}=1, 존재하지 않으면 y_{j}=0으로 들어가 있을 것입니다.
학습 데이터셋에서의 구성은 위와 같고 테스트 시에 Y는 당연히 존재하지 않습니다. 결국 action 구간과 종류를 예측해야 하니 output은 (t_{s}, t_{e}, c, o)가 됩니다. t_{s}는 시작 지점, t_{e}는 끝 지점, c는 해당 예측 구간의 action 클래스, o는 구간에 대한 score입니다.
B. Feature Extractor
비디오로부터 학습에 사용할 feature를 추출하는 과정입니다.
대부분 연구와 마찬가지로 backbone은 I3D를 사용합니다. 비디오 V\in{} \mathbb{R}^{C \times{} L \times{} H \times{} W}에 대해 backbone을 태워 RGB feature F_{r} \in{} \mathbb{R}^{D \times{} T}와 optical flow feature F_{f} \in{} \mathbb{R}^{D \times{} T}를 얻을 수 있습니다. 그리고 둘을 채널 축에 대해 concat하여 F \in{} \mathbb{R}^{2D \times{} T}도 얻을 수 있겠죠. F는 추후 loss 계산에만 쓰이고 실제 학습할 때에는 F_{r}과 F_{f}를 중점적으로 이용하니 참고하시면 좋을 것 같습니다.
C. Feature Enhance Module
앞선 단계까지 feature를 추출했다면, 이 부분에서 저자가 제안하는 ASCN의 핵심인 TSCM과 CSAM이 등장합니다. 여기서부터는 notation이 굉장히 다양하고 복잡해져서 천천히 하나씩 정리해보겠습니다.
C.1 Temporal Saliency and Context Module(TSCM)
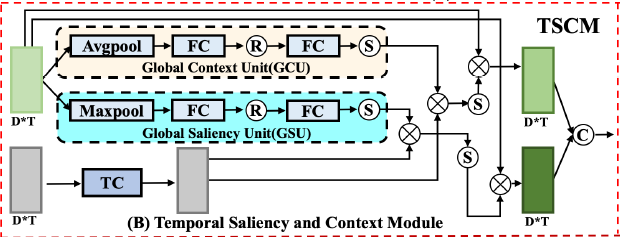

실제로 TSCM은 RGB와 flow를 위해 하나씩 존재합니다. 그림 3의 가장 왼쪽에 연두색과 회색 input이 있는데, 각각이 (RGB, flow), (flow, RGB)인 경우가 하나씩 있다는 것입니다. 편의 상 연두색이 RGB, 회색이 flow인 경우를 기준으로 설명드리겠습니다.
TSCM 내부의 구성 요소로 Global Context Unit(GCU)와 Global Saliency Unit(GSU)가 보입니다. GCU에는 global context를 잡기 위한 Avgpool이 존재하고, GSU에는 global saliency를 잡기 위한 Maxpool이 존재한다는 차이점이 있습니다.
- A_{context} = GCU(F_{r})
- A_{saliency} = GSU(F_{r})
우선 A_{context} \in \mathbb{R}^{D \times{} 1}, A_{saliency} \in \mathbb{R}^{D \times{} 1}입니다. 위와 같이 GCU를 거쳐 얻은 A_{context}는 비디오의 전반적인 문맥을 잘 포함하는 feature이지만, 그말은 곧 action을 찾아야 하는 상황에서 방해 요인이 되는 background도 함께 포함되어 있음을 의미니다. 그래서 Maxpool을 통해 불필요한 정보를 배제해줄 수 있는 GSU가 존재하고, 얻어낸 A_{saliency}는 상대적으로 background의 영향이 줄어들어있다고 볼 수 있습니다.
이후 flow feature도 함께 활용합니다. F_{f}에 단순한 Temporal Convolution(TC) 연산을 적용하고, 앞서 얻은 A_{context}와 A_{saliency}에 elementwise-multiplication을 적용해 R_{context}와 R_{saliency} 얻게 됩니다. 수식으로 보면 아래와 같습니다.
- R_{context} = TC(F_{f}) \otimes{} A_{context}
- R_{saliency} = TC(F_{f}) \otimes{} A_{saliency}
R_{context}는 context 특성이 강화된 flow feature로 해석할 수 있고, R_{saliency}는 saliency 특성이 강화된 flow feature로 해석할 수 있을 것입니다.
RGB feature를 기준으로 하는 TSCM의 목적은 saliency와 context 정보를 적절히 담아 각각의 기대 효과를 누릴 수 있는 정제된 RGB feature를 얻는데에 있습니다. 그렇기 때문에 여기까지 거쳐 얻은 R_{context}와 R_{saliency}에 sigmoid를 거쳐 일종의 attention score로 만들어준 뒤 다시 처음의 RGB feature F_{r}에 element-wise mutiplication 연산을 적용해줍니다. 이 과정은 아래 수식과 같습니다.
- F_{rc} = \text{Sigmoid}(R_{context}) \otimes{} F_{r}
- F_{rs} = \text{Sigmoid}(R_{saliency}) \otimes{} F_{r}
여기서 F_{rc} \in \mathbb{R}^{D \times{} T}와 F_{rs} \in \mathbb{R}^{D \times{} T}를 합치기 위해 TC를 적용하여 최종적으로 정제된 RGB feature F_{re} \in \mathbb{R}^{D \times{} T}를 얻게 됩니다.
여기까지가 RGB feature를 기준으로 했을 때 TSCM의 작동 방식이고, flow feature에 대해서도 완전히 대칭적인 과정을 거쳐 F_{fe} \in \mathbb{R}^{D \times{} T}를 얻을 수 있습니다. 이후 다음 과정으로 넘어가는 최종 output은 F_{re}와 F_{fe}를 concat F_{e} \in \mathbb{R}^{2D \times{} T}입니다.
C.2 Channel self-attention module(CSAM)
다음은 두 번째 핵심 모듈인 CSAM입니다. 보통 RGB feature는 spatial, flow feature는 temporal 정보를 나타내는데 이들을 단순 concat하는 대신 각각에 특화된 정보를 최대한 활용하기 위해 CSAM이 설계되었습니다.
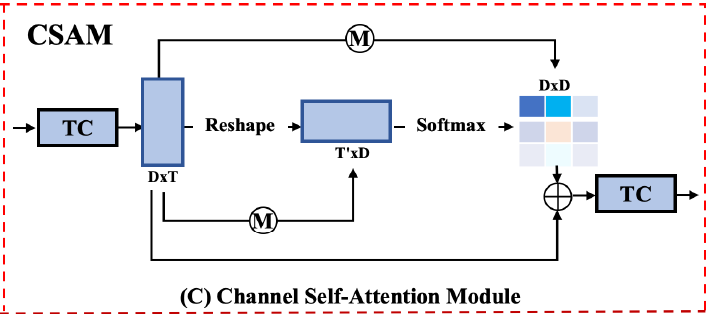
CSAM의 input은 TSCM의 최종 output인 정제된 feature F_{e}입니다. 그림과 같이 F_{e}에 TC, 즉 1D Convolution을 적용한 뒤 self-attention 연산과 유사한 과정을 거쳐 attention map A_{map}을 얻습니다. Channel self-attention 연산을 통해 모달 별 특성을 잘 살려주겠다는 것입니다.
- A_{map} = \text{Softmax}(F_{e}F_{e}^{T})
A_{map} \in \mathbb{R}^{2D \times{} 2D}이고, 위 수식에서 F_{e}는 TSCM의 output에 TC를 적용한 후라고 생각하시면 됩니다. 논문에서는 같은 notation을 사용하고 있네요.
또한 논문 글에서는 F_{e}가 TC를 거쳐도 \mathbb{R}^{2D \times{} T}의 shape을 가진 상태로 뒤 과정이 진행되는데, 그림 4에서는 F_{e}가 TC를 거친 후 shape이 \mathbb{R}^{D \times{} T}로 바뀐 상태로 뒷 과정의 shape 표시되어있습니다. 우선은 figure가 아닌 논문의 글에 따라 shape을 작성해보겠습니다.
A_{map}을 구했으니 다시 원래 feature F_{e}와 element-wise multiplication 연산을 적용해 F_{ea}를 얻고, residual 연산을 통해 최종 output F_{ec}를 얻습니다.
- F_{ea} = A_{map}F_{e}
- F_{ec} = F_{e} + \lambda{} \times{} F_{ea}
여기서 \lambda{}는 learnable parameter이고, 전체적으로 self-attention 연산과 유사하게 흘러왔다는 것을 알 수 있습니다. F_{ea} \in \mathbb{R}^{2D \times{} T}, F_{ec} \in \mathbb{R}^{2D \times{} T}이고, F_{ec}는 추후 TCAM을 생성하는데 사용됩니다. 그림에서는 F_{ec}가 마지막 TC도 거치는데, 논문 글에서는 이 과정에 대해 따로 언급이 없습니다.
이제 TSCM, CSAM으로부터 얻은 feature들을 어떻게 활용해 action classification, localization이 수행되는지 알아보겠습니다.
D. Localization Module
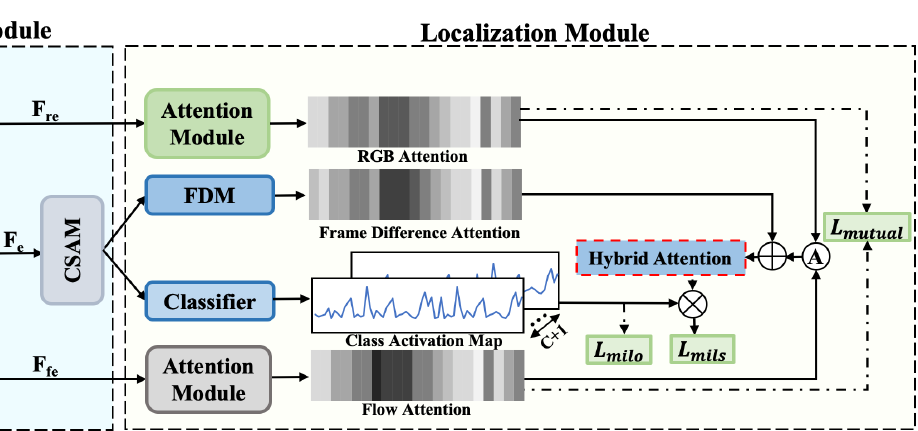
그림 5의 Localization module을 보시면, 기본적으로 F_{ec}을 이용해 TCAM을 만들어냅니다. 그리고 TSCM에서 얻은 F_{re}, F_{fe}와 FDM을 거쳐 얻은 Frame Difference Attention을 조합하여 만든 Hybrid Attention이 TCAM의 background score를 suppress하는데 사용되는 구조를 갖고 있습니다. 우선 Hybrid attention부터 설명 후, TCAM을 만드는 과정 순서로 설명드리겠습니다.
D.1 A Hybrid Mechanism
TSCM, CSAM과 더불어 또 다른 핵심 contribution인 hybrid attention mechanism이 등장합니다. 이는 여러 관점으로부터 비디오의 시간 축에 대한 attention score를 추출하고, 적절히 합쳐 최적의 attention score를 만들어내는 이전 기법인데 본 논문에서는 어떠한 attention score들이 합쳐지는지 살펴보겠습니다. 여러 attention score를 합치는 것은 예전에도 있었지만, 합치는 attention score가 무엇인지가 논문의 contribution이라고 보시면 됩니다.
그림 5의 Attention Module은 두 개의 convolution과 dropout, sigmoid로 구성되어 있습니다. F_{re}, F_{fe}을 각각 Attention Module에 통과시켜 A_{r} \in \mathbb{R}^{1 \times{} T}, A_{f} \in \mathbb{R}^{1 \times{} T}를 얻을 수 있습니다. A_{r}, A_{f}는 각각 RGB-, flow-specific attention으로 볼 수 있겠죠.
이제 Frame Difference Module(FDM)이 등장합니다.
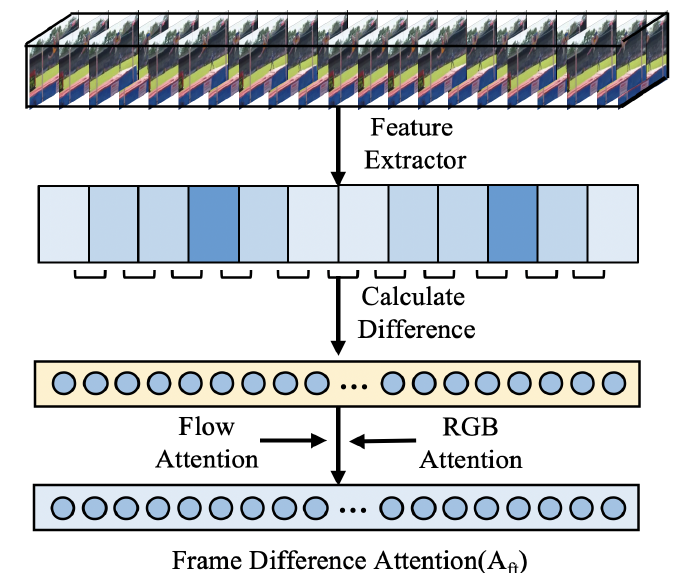
Hybrid attention에 포함될 Frame Difference Attention(A_{ft})를 얻는 것이 FDM의 목적입니다. 저자는 action에서 background로, background에서 action으로 전환되는 시점에서 feature의 L1-norm이 크게 변화한다는 관찰을 이용합니다. 그림 6에서 Calculate Difference 과정에서 다음 클립 feature와의 L1-norm 차이를 구해줍니다. 0번 클립과 1번 클립 L1-norm 차이를 1번 위치에 넣어주는 식으로 계산되고 0번 자리는 ‘0’으로 채워주게 됩니다. 이렇게 얻은 attention score가 F_{t}입니다.
이에 대해 설명을 좀 덧붙이면, RGB feature의 magnitude는 프레임이 단색이거나 특징이 적을 경우 낮게 나오게 됩니다. 반대로 복잡하고 정보가 많은 프레임으로 전환되면 magnitude가 커지게 되고 그 두 프레임 사이에서 큰 변화량을 얻을 수 있게됩니다. 같은 맥락으로 flow feature에 이를 적용한다면 시각적 변화량이 아닌 motion 변화량이 큰 지점을 찾아내게 되는데, FDA는 두 feature를 잘 조합한 F_{ec}로부터 시각적 변화와 motion의 변화가 동시에 큰 부분을 naive하게 잡아낼 수 있는 수단으로 활용한 것이 아닌가 생각해 보았습니다. 물론 추후에 실제로 action과 background가 교차하는 지점이 위와 같은 특징을 갖는지에 대한 분석까지 해보면 좋을 것 같습니다.
이후 A_{r}, A_{f}의 평균 A_{t}와 방금 얻은 F_{t}를 잘 이용해 A_{ft}를 얻습니다. 논문 글에는 ‘based on’이라고만 표현되어 있고, 그림 5에는 이 과정이 아예 표현되어 있지 않고, 그림 6에는 단순히 화살표로 되어 있어 정확히 어떤 연산이 수행되는지는 알 수 없었지만 어쨌든 A_{ft}에는 RGB, flow, frame difference 정보가 모두 녹아들어 있다고 볼 수 있습니다.
지금까지 Localization Module에서 얻은 값들은 A_{r}, A_{f}의 평균 A_{t}와 A_{ft}입니다. 최종적인 Hybrid attention A_{h} = A_{t} + A_{ft}입니다. A_{h}를 구성하는 A_{t}, A_{ft} 모두 action은 더욱 salient하게, background는 억제하는 방향의 attention score이므로 저자의 의도와도 잘 맞는 값이라고 생각할 수 있습니다. 추가로 모든 attention score의 shape은 \mathbb{R}^{1 \times{} T}입니다.
D.2 Classifier
Video-level class score를 얻기 위해 TCAM을 생성하는 과정입니다. 앞서 CSAM에서 얻은 F_{ec}를 FC layer에 통과시켜 TCAM s \in \mathbb{R}^{T \times{} (n+1)}를 얻습니다. s에 클래스 별 top-k pooling과 softmax를 적용해 video-level class score p를 얻고 학습에 사용할 수 있을 것입니다.
하지만 F_{ec}로부터 TCAM을 만들게 되면 각 모달의 특성을 잘 활용한 attention score라고는 볼 수 있겠지만 background로 인해 action score가 상대적으로 영향을 받고 있다고 볼 수 있습니다. 이에 대처하고자 F_{ec}에 앞서 얻은 Hybrid attention score A_{h}를 곱해준 뒤 생성한 CAS s^{att}로부터 video-level class score p^{att}도 만들어줍니다. s^{att}는 background가 억제된 상태의 TCAM으로 해석 수 있습니다.
E. Optimizing Process
이제 방법론은 모두 끝났고 학습 과정에 사용되는 loss를 보겠습니다.
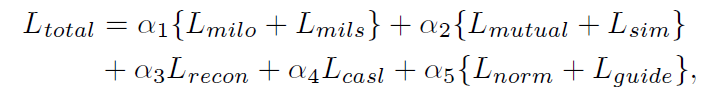
위와 같이 전체 loss는 8개인데, 식이 복잡하지는 않아 한 묶음씩 천천히 설명해보겠습니다.
우선 L_{milo}, L_{mils}는 p, p^{att}으로 action classification을 학습하는 CELoss입니다.
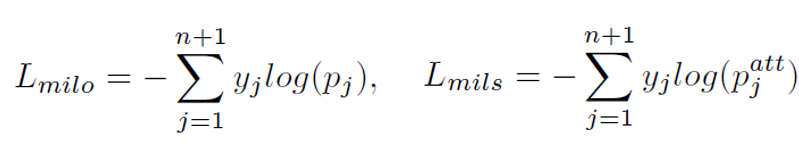
L_{milo}는 background가 존재하는 GT, L_{mils}는 억제되었으므로 존재하지 않는 GT를 주어 학습합니다.
다음으로 L_{mutual}, L_{sim}의 수식은 아래와 같습니다.
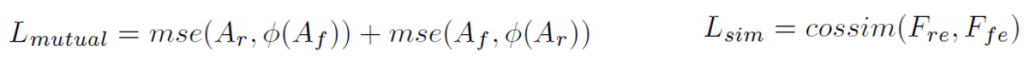
위 두 loss의 목적은 RGB와 flow 사이의 일관성을 부여하는 것입니다. L_{mutual} 식의 \varnothing{}은 freeze를 의미하며, 상대 attention 값의 pseudo label이 되어주는 것입니다. 그리고 feature-level에서의 일관성을 높여주는 L_{sim}은 각 TSCM의 output인 F_{re}, F_{fe}의 코사인 유사도가 높아지도록 학습합니다. cossim은 코사인 유사도 loss로 궁금하신 분들은 파이토치 문서를 참고하시면 좋을 듯 합니다.
다음 두 가지 loss L_{recon}, L_{casl}을 살펴보겠습니다.
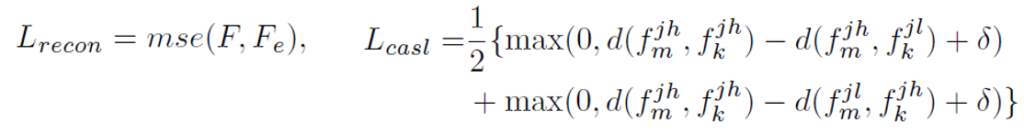
L_{recon}은 action 분류를 더 잘하기 위해 TSCM에서 얻은 F_{e}가 원래 feature F의 정보를 어느정도 보존하도록 도와줍니다. 다음으로 L_{casl}은 coactivity similarity loss로서, 같은 action을 포함하고 있는 비디오 feature 간 관계를 학습하는 일종의 metric learning loss입니다. 말로 설명드리기가 복잡해 notation을 포함한 그림으로 설명드리겠습니다.
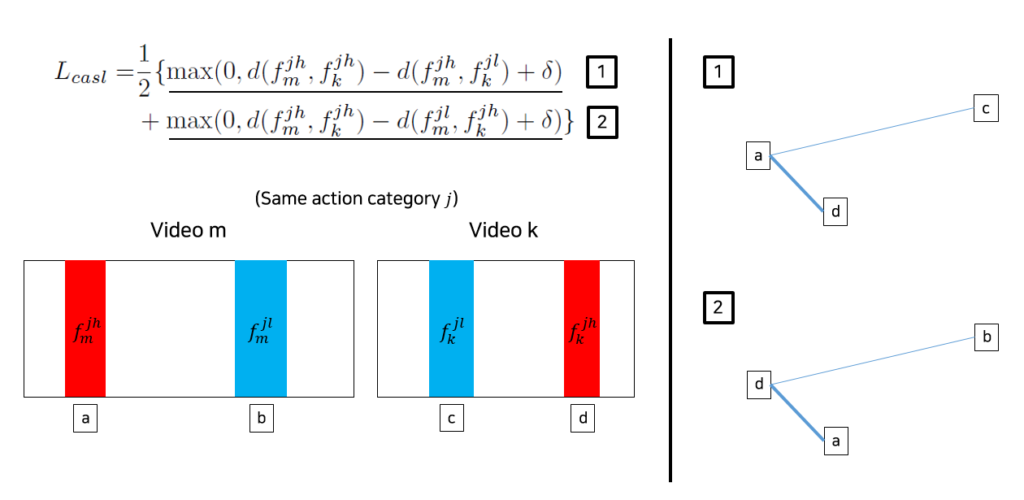
그림 7을 보시면 같은 action category j를 갖는 두 비디오 m, k에 대해 해당 action의 s^{att}가 가장 높은 clip a, d와 가장 낮은 clip b, c가 존재합니다. 수식에서의 d는 cosine sim loss로 낮아질수록 유사한 것입니다. 따라서 L_{casl}의 학습 방향은 그림 7의 오른쪽과 같이 높은 score의 clip a, d를 기준으로 상대 비디오의 낮은 clip feature와는 멀어지도록 거리를 학습하는 형태입니다.
마지막으로 L_{norm}, L_{guide}인데 L_{norm}은 attention 값들을 sparse하게 만들어주고 L_{guide}는 action score와 background score가 동시에 커지는 현상을 방지해주는 역할을 수행합니다.
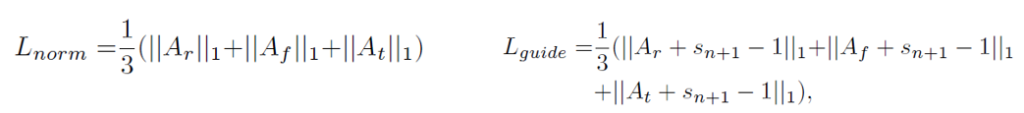
Loss가 8개나 존재하지만 모두 이전 연구에서 제안한 것들을 조금씩 변형하여 사용한 형태라 더 살펴볼만 부분은 없었습니다.
3. Experiments
마지막으로 벤치마크 성능과 ablation 실험들을 보고 리뷰를 마치겠습니다.
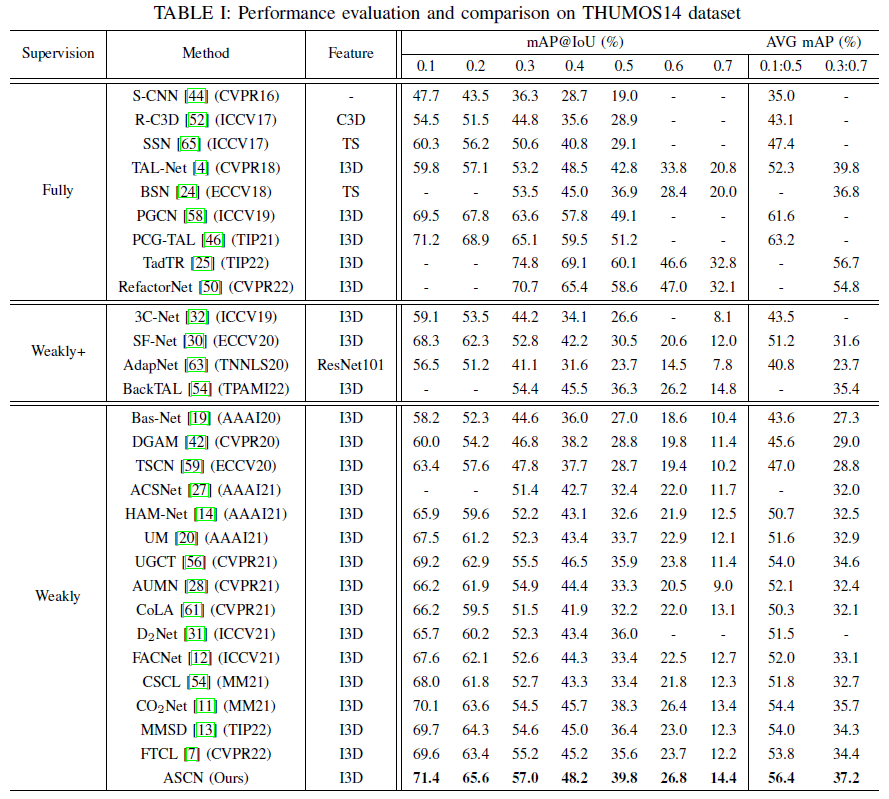
표는 THUMOS14 데이터셋에서의 벤치마크 성능입니다. 같은 ‘Weakly’ annotation 기준 다른 방법론들보다 성능이 크게 앞서고 있는 것으로 보입니다. 리포팅되지 않은 2022년도 CVPR 논문들보다도 평균 1% 이상의 mAP 향상이 있지만, 현재 arxiv에 올라와 있는 논문들보다는 조금 낮은 성능을 보이고 있습니다.
이전 방법론들 중 CO2Net의 성능이 가장 높은 것을 알 수 있습니다. 저자는 이에 대해 CO2Net에서는 Avgpooling을 통해 feature들을 합치게 되며 불필요한 정보들이 모두 포함되는데, 저자의 ASCN에서는 maxpooling을 거치는 GSU와 frame difference 계산을 통한 background suppression이 보다 효과적으로 작용했다고 주장하고 있습니다.
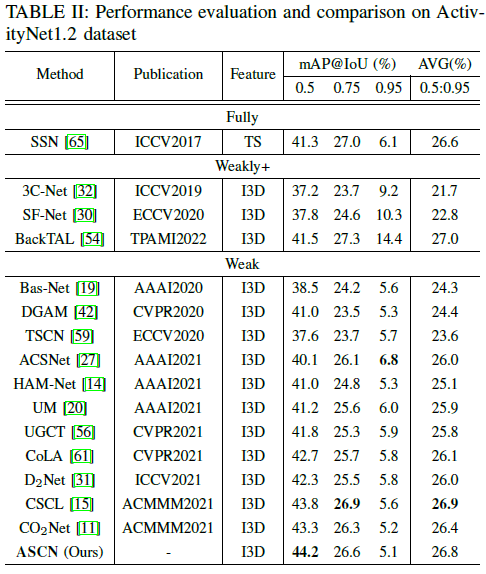
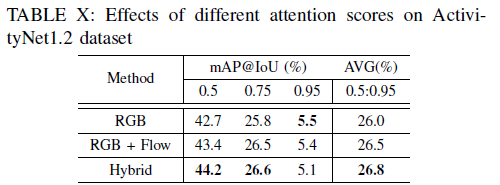
ActivityNet v1.2 데이터셋에서의 벤치마크 성능입니다. CSCL이라는 방법론이 더 높은 성능을 보여주고 있는데, 저자는 이에 대해 THUMOS14 데이터셋보다 ActivityNet 데이터셋의 비디오들이 더 길고 action의 종류가 많아 큰 성능 향상이 없었다고만 이야기하고 있습니다. 이 분석은 잘 이해가 되지 않았습니다.
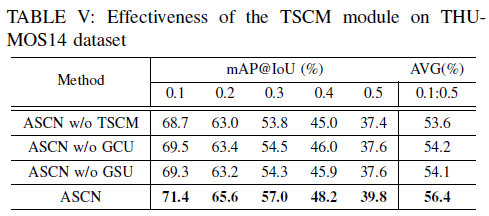
다음은 module 별 ablation 성능인데, TSCM 실험에서 살펴볼 점은 GCU와 GSU가 하나만 존재할 때보다 동시에 존재할 때 성능 향상 폭이 훨씬 크다는 것입니다. Action saliency와 context 정보가 각각 부여되었을 때 좋은 정보를 주는 것은 맞지만, 둘이 함께 사용되어야만 fine-grained한 action 구간을 찾아낼 수 있다는 점을 보여주고 있습니다.
CSAM보다 TSCM이 조금 더 많은 정보를 추출하는 과정이라는 느낌이 있었는데, 실제 ablation 실험에서도 TSCM만 존재할 경우 56.0%, CSAM만 존재할 경우 53.6%의 mAP를 보여주며 둘 중에는 TSCM이 더욱 핵심적 역할을 수행했다는 것을 알 수 있었습니다.

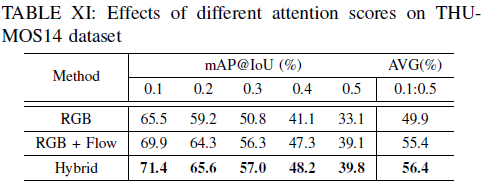
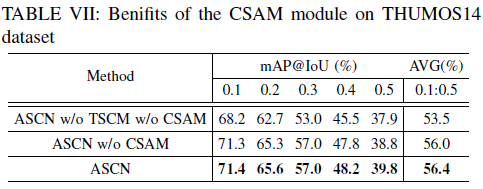
Loss 관련 ablation 실험과 Hybrid attention의 효과를 알아보기 위한 ablation 실험입니다. 마지막 표에서 RGB + Flow에 Frame Difference Attention까지 적용한 ‘Hybrid’가 가장 높은 성능을 보이고 있습니다. THUMOS14 데이터셋보다 ActivityNet 데이터셋의 비디오들이 더 길고, 많은 action class를 포함하고 있습니다. 그래서 처음 FDA 모듈을 봤을 때 너무 단순하여 길고 복잡한 비디오에서는 큰 효과가 없지 않을까 생각하였는데, 상대적으로 짧은 THUMOS14에서는 큰 성능 향상을 보여주었고 긴 ActivityNet 비디오에서는 그 효과가 덜 한 것을 실제 실험 결과를 통해 확인할 수 있었습니다.
4. Conclusion
리뷰 첫 부분에서도 말씀드렸지만 방법론이나 실험 결과에 대한 분석이 아쉬웠고, 아직 게재된지 얼마 되지 않아서인지 오타나 중간중간 맥락이 끊기는 부분도 있었습니다. 논문에 수렴 속도 관련 실험이나 정성적 결과도 있으니 궁금하신 분들은 찾아보시는 것을 추천드립니다.
방법론이 크게 어렵지 않은데 그 의미를 찾으려 하다보니 리뷰가 많이 길어진 것 같습니다. 앞으로는 더욱 핵심적인 내용만 담아 짧고 굵은 리뷰를 만들어보도록 노력하겠습니다.
리뷰 읽어주셔서 감사합니다.
안녕하세요 김현우 연구원님. 리뷰 잘 읽었습니다.
본문 내용을 보면 핵심 모듈(GCU/GSU)를 보면, maxpool을 통해 불필요한 정보를 제거한다는 말을 사용하고 있는데요. 이 결과값이 background의 영향이 줄었다는 설명에서 궁금한 점이 있어 질문드립니다. 평균을 사용하는건 저희도 그렇게 사용을 하고 흔한 내용이라고 생각을 하는데요. 배경이 복잡해질 경우에는 maxpool을 사용한다고 잘 작동할지에 의문이 있습니다. [표 5]를 봐도 GSU/GCU 각각의 단독 사용시에 성능 차이가 그렇게 큰 편도 아니고요. 혹시 이렇게 saliency 정보를 사용하는게 흔한 방식인지 아니면 논문에서 어떻게 background를 제거했는지 설명이 추가적으로 있을까요?
단순히 maxpool 연산을 통해 action saliency를 모델링한다는 방법론은 처음 접하였습니다.
말씀해주신대로 THUMOS 보다 더욱 복합적인 ActivityNet에서는 베이스라인에 GSU를 붙이는 경우 성능 향상 폭이 0.2%로 효과가 굉장히 미미합니다.
논문에서 L_milo와 L_mils의 차이로 보아 저자는 GSU보다는 Frame difference attention을 좀 더 명시적인 background suppression 과정으로 보고있다고 생각됩니다.
좋은 리뷰 감사합니다.
tcam에 대한 설명과 attention saliency, context modeling problem 설명 덕분에 깊이 이해할 수 있었습니다. 감사합니다. 저도 이광진 연구원님과 같은 의문이 있는데 어떻게 maxpool을 통해 background와 같은 불필요한 정보를 배제할 수 있다는 것인지 궁금합니다. 실제로 잘 배제해주는가도 궁금하기는 한데 실혐 결과를 보면 그래도 성능 향상을 가져오니 잘 배제해주는 것 같기도 하고 해서 신기하네요.
감사합니다.
저자는 maxpool을 통해 background를 제거하기 위해 GSU를 사용한다기보단, action 부분을 조금 더 살리는 효과를 기대한 것으로 보입니다. 물론 둘이 비슷한 이야기로 생각되실 수 있겠지만, 뒷부분의 Frame difference attention 과정이 있다는 점으로 미루어 보았을 때 위와 같이 생각해볼 수 있을 것 같습니다.