제가 이번에 리뷰할 논문은 WACV 2023에 발표된 TransVLAD라는 논문으로 Transformer와 VLAD가 합쳐진 논문입니다. 도로 환경에 대한 retrieval논문을 찾아보다 읽게 된 논문입니다.
Introduction
Visual geo-localization에서 기존의 SOTA 방법론들은 NetVLAD를 많이 이용합니다. 그러나 local한 영역을 보는 CNN은 occlusion이나 transient object(차, 보행자 등을 의미)와 같이 복잡한 씬에서 잘 작동하지 않을 수 있습니다. 사람의 시각 시스템으로 생각해보았을 때, 사람은 모호하거나 정보가 부족한 경우 local한 정보 뿐만 아니라 global한 정보도 함께 고려하여 예측을 하는데 CNN은 필터를 이용하여 인접한 픽셀들의 정보, 즉, local한 정보를 예측에 이용하기 때문이라고 합니다. 최근 ViT를 이용하는 연구가 진행되고 있지만 이는 1)inductive biases가 부족하다는 Transformer의 문제와 2) GPS 정보에 노이즈가 포함된 데이터셋으로 인해 geo-localization에서 잘 작동하지 않는다고 합니다.
1)inductive biases가 부족하다는 Transformer의 문제
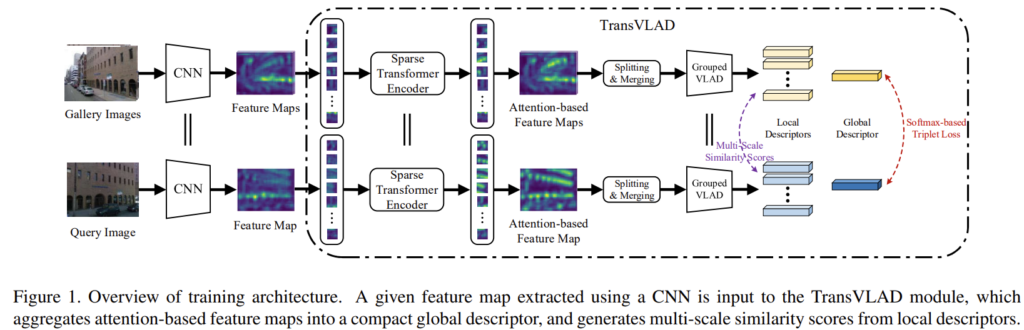
우선 inductive biases 문제를 해결하기 위해 본 논문은 NetVLAD의 CNN 구조를 유지하면서도 임베딩보드나 모바일에서 사용할 수 있도록 컴팩트한 CNN을 백본으로 이용하였다고 합니다. 또한, 효율적인 TransVLAD 모듈을 제안하였습니다. 제안한 TransVLAD 모듈은 이름에서도 드러나듯이 Transformer를 이용하였으며, VLAD방식으로 descriptor를 추출합니다. TransVLAD는 Transformer를 통해 global한 맥락 추론이 개선되고, attention기반의 feature map을 만들 수 있게 된다고 합니다. 또한, positional encoding 방식은 TransVLAD 모듈이 학습 과정에서 쿼리와 갤러리(DB)간의 기하학적인 형태를 잘 인코딩할 수 있게 합니다.
2) GPS 정보에 노이즈가 포함된 데이터셋
다른 문제점은 geo-localization 데이터셋의 GPS 정보가 noisy하다는 문제로, 이러한 문제로 인해 weakly-supervised 방식으로 학습을 해야한다는 것입니다. 따라서 기존 연구들은 top-1의 positive 영상을 이용하여 feature representation을 학습합니다. 그러나 이러한 방식은 외관 정보의 변동과 1개의 이미지만 이용하기 때문에 정보가 제한적이라는 문제로 인해 대용량 geo-localization에서 강인하지 못한 결과를 보였습니다. 이를 해결하기 위해 해당 논문은 lower-positive 영상들도 이용하는 self-supervised 학습 방식을 고안합니다. lower-positive 영상들은 쿼리 영상과 겹치는 영역이 적어 global descriptor만 이용할 경우 부정확한 결과를 가져오게 될 수 있으므로 split and merge라는 multi-scale patch를 이용하는 방식을 통해 local descriptor를 생성합니다. 이렇게 구한 local descriptor를 매칭시켜 유사도 점수를 구하고 학습을 진행합니다.
이 논문의 contribution을 다시 정리해보면,
- attention 기반의 feature map을 구별력 있는 컴팩트한 global descriptor로 종합하는 TransVLAD 모듈 제안
- multi-scale patch로부터 더 많은 정보를 인코딩하기 위한 self-supervised 학습 방식 제안
- TransVLAD 모델이 더 낮은 계산 복잡성으로 SOTA를 능가한다는 것을 실험적으로 보임
Method
Sparce Transformer of TransVLAD
TransVLAD는 transformer가 CNN이 가지는 inductive bias가 부족하다는 문제가 있어 백본으로 CNN을 이용하여 local feature를 추출하였다고 합니다. 이때, CNN이 가지는 inductive bias는 translation invariance 와 locality로, translation invariance는 동일한 물체가 이동한 영상에 대해서도 동일한 예측 결과를 내는 것이고 locality란 주변 인접 픽셀들이 서로에게 영향을 준다는 것입니다. 이렇게 CNN을 통과한 feature는 Sparse transformer로 들어가 attention기반의 feature map을 구하게 됩니다.
Sparce Transformer of TransVLAD
TransVLAD는 transformer가 연산량이 많고, CNN이 가지는 inductive bias가 부족하다는 문제가 있어 백본으로 CNN을 이용하여 local feature를 추출하였다고 합니다. 해당 논문에서 CNN이 가지는 inductive bias는 translation invariance 와 locality로, translation invariance는 동일한 물체가 이동한 영상에 대해서도 동일한 예측 결과를 내는 것이고 locality란 주변 인접 픽셀들이 서로에게 영향을 준다는 것입니다. 이러한 이유로 CNN을 통과시켜 local feature를 추출한 뒤, attention기반의 feature map을 구하기 위해 Sparse transformer를 통과합니다.
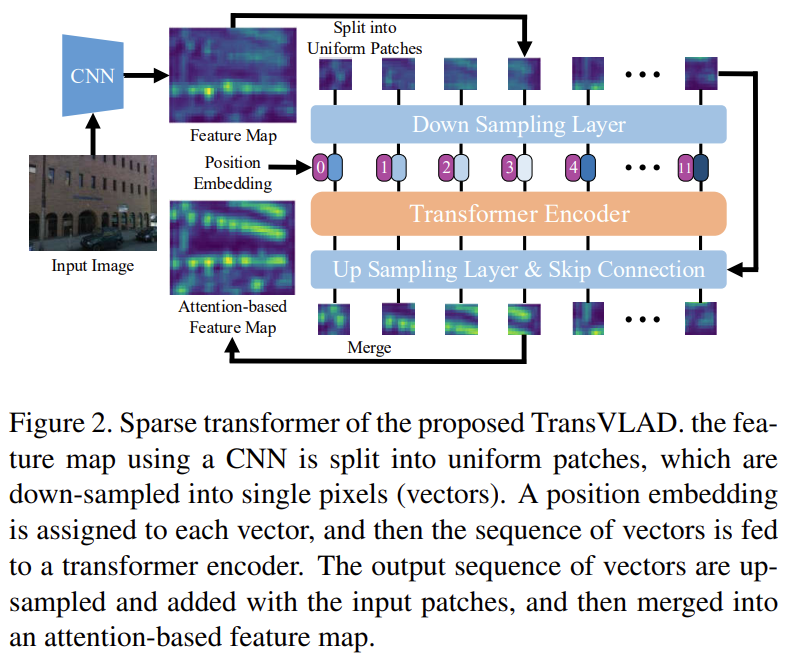
feature map을 2D 패치 \mathbf{m}_p ∈ \mathbf{R}^{N⨉P^2⨉C}로 나눈 뒤, Down sampling을 통해 하나의 픽셀값 \mathbf{x}_p ∈ \mathbf{R}^{N⨉C}(채널축으로 백터값)이 되도록 합니다. 여기에 학습할 수 있는 1D position embedding \mathbf{x}_{pose} ∈ \mathbf{R}^{N⨉C}를 이용하여 기하학적인 대응 관계를 학습할 수 있도록 합니다. 따라서, embedding vector \mathbf{x}_0 = \mathbf{x}_p + \mathbf{x}_{pose}를 만들어 transformer encoder로 입력합니다.
Transformer는 multihead self-attention(MSA)모듈로 레이어가 구성되며, MSA 모듈은 L2LTR**이라는 방법론의 self-cross attention 방식을 이용하였다고 합니다. 논문을 보니 L2LTR이라는 방법론은 시각적 모호성이나 불완전성을 효과적으로 줄일 수 있는 방식으로 transformer에서 key를 이전 레이어의 key를 이용하는 방식이라 합니다.(아래의 그림이 L2LTR에서 제안한 self-cross attention방식)
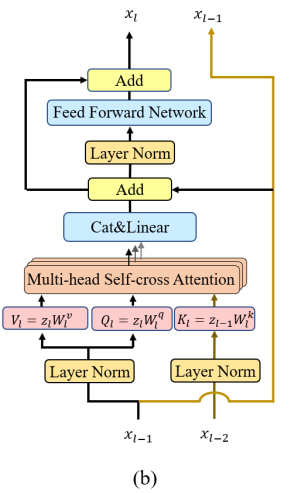
**Yang, H., Lu, X., & Zhu, Y. (2021). Cross-view geo-localization with layer-to-layer transformer. Advances in Neural Information Processing Systems
MSA 모듈을 식으로 정리하면 아래와 같습니다.
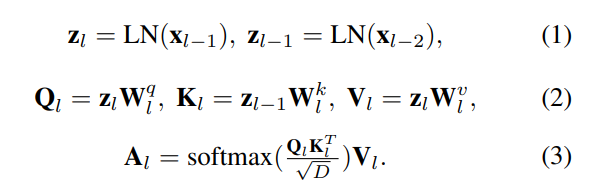
여기서 LN은 Layernorm 블록을 의미하며, \mathbf{W}^q_l, \mathbf{W}^k_l, \mathbf{W}^v_l는 각각 query, key, value의 선형 projection matrix을 의미합니다.
해당 논문에서 제안한 Sparse Transformer는 아래의 식으로 정리가 됩니다.
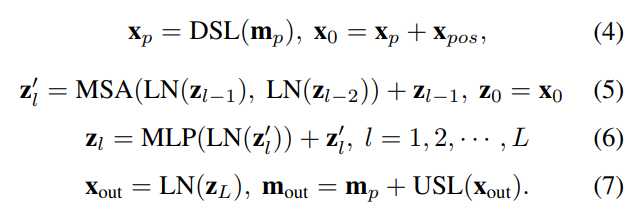
입력 이미지가 패치단위로 나뉘어 down sampling(DSL, average pooling 이용)을 거친 뒤, position embedding과 합쳐져 embedding vector \mathbf{x}_0가 된 뒤, MSA 모듈, multi-layer perceptron(MLP), Layernorm(LN)을 순서대로 통과하여 \mathbf{x}_{out} 이 됩니다. 이후 up sampling(USL, transposed convolution 이용)을 수행한 뒤, 원본 패치\mathbf{x}_{p}에 합쳐 attention을 줍니다.
Grouped VLAD of TransVLAD
기존의 NetVLAD는 VLAD layer를 이용하여 global descriptor를 생성하였으나, global descriptor의 차원이 커 연산량이 많다는 문제가 있습니다. 이에 저자들은 input feature vector를 상대적으로 낮은 차원의 벡터 그룹으로 바꾸어 output 차원을 줄이고 VLAD의 비선형성을 주기 위해 grouped weight \bar{\beta}를 제안하였습니다.
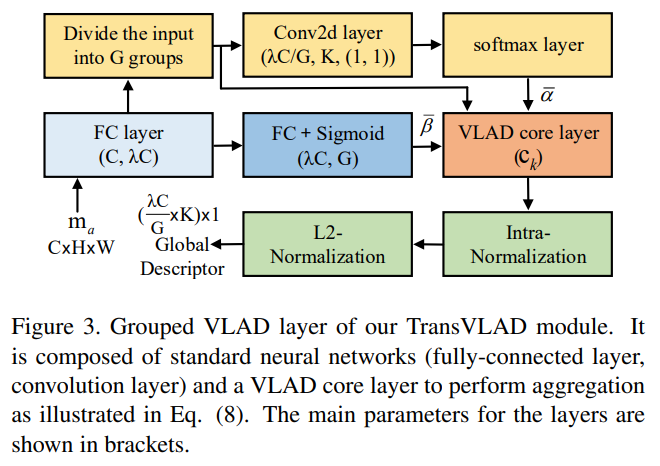
위의 그림이 Grouped VLAD를 도식화한 것으로, K-차원의 descriptor는 위의 과정을 거쳐 { \lambda C} \over {G} ⨉ K-차원의 global descriptor V가 됩니다.
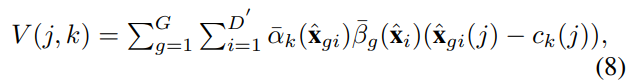
아래의 식이 최종 output을 나타내는 값으로, \bar{\alpha}_k는 NetVLAD 방식에서 이용하는 soft-assignment이고, \bar{\beta}_k는 그룹에 대한 가중치가 됩니다. \bar{\alpha}_k (\hat{\mathbf{x}_{gi}})는 global descriptor \hat{\mathbf{x}_{gi}}가 cluster k에 할당된 것을 의미합니다.
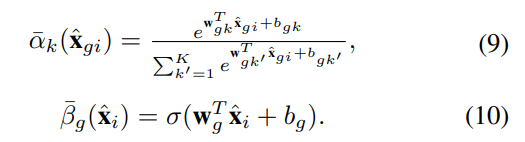
이렇듯 grouped VLAD를 통해 { \lambda C} \over {G} 배 차원을 줄여 global descriptor를 생성한다고 합니다.
Self-supervised Learning Method
기존의 방식은 top-1의 positive를 이용하였으나, 이 논문에서는 더 많은 representation 정보를 추가로 인코딩하기 위해 self-supervised 방식을 이용하여 낮은 랭크의 positive 이미지들도 이용하도록 학습합니다. 아래의 그림이 이 과정에 대한 설명으로, feature map을 여러 크기의 패치(12+6+2)들로 나누고 쿼리와 갤러리 이미지간의(cross) descriptor 대응관계를 생성합니다.(그림은 이미지로 표현되어있지만 실제로는 feature map에 대하여 작동하는 것입니다)
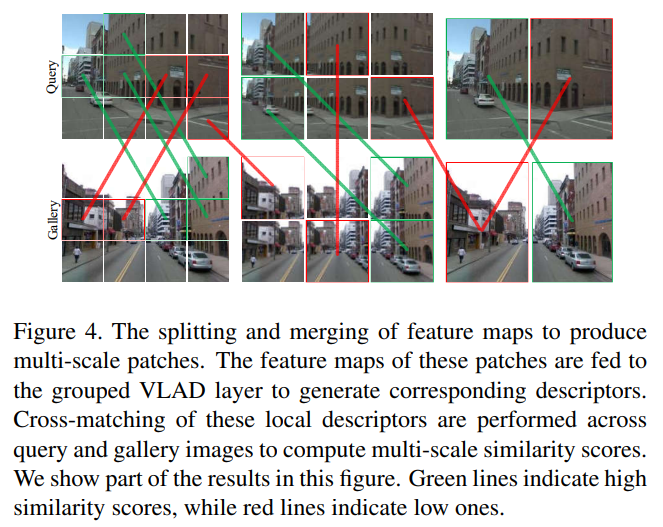
multi-scale 패치들의 초기 유사도는 아래의 식으로 정의되며, 쿼리 패치들과 lower-positive 패치들간의 내적으로 유사도를 구합니다. 이때, \tau_0는 초기의 유사도 score 조절을 위한 파라미터이며 _q는 쿼리를 _{p^1}는 갤러리 중 낮은 랭크의 positive 이미지를, \theta는 네트워크, <·,·>는 내적,f는 grouped VLAD를 통과하여 얻은 descriptor를 의미하며 descriptor는 global descriptor f_q , f_{p^1}와 local descriptor f_{q_1},f_{q_2}, ..., f_{p^1_1}, ..., f_{p^k_20}로 구성됩니다.
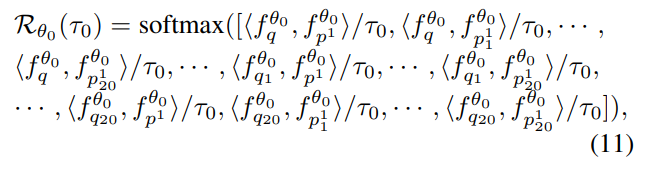
이렇게 얻은 유사도는 다음 학습에서 네트워크 학습 지도에 사용이 되며, 아래의 식과 같이 cross-entropy loss를 이용하여 학습을 진행합니다.
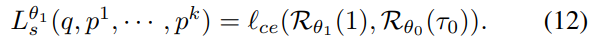
![]() 는 cross-entropy loss이며, \nu번째의 학습시 이전에 구한 유사도에 \tau_{\nu-1}로 나눈 값을 gt로 사용하여 학습을 하게 됩니다. 이때, 학습이 진행될수록 정확도가 높아지므로, \tau는 작아지도록 한다고 합니다. 또한, \mathcal{R}_{\theta_\nu}(1)는 쿼리 이미지와 1~k개의 positive 이미지들 간의 유사도로 구해집니다.
는 cross-entropy loss이며, \nu번째의 학습시 이전에 구한 유사도에 \tau_{\nu-1}로 나눈 값을 gt로 사용하여 학습을 하게 됩니다. 이때, 학습이 진행될수록 정확도가 높아지므로, \tau는 작아지도록 한다고 합니다. 또한, \mathcal{R}_{\theta_\nu}(1)는 쿼리 이미지와 1~k개의 positive 이미지들 간의 유사도로 구해집니다.
또한, softmax-based triplet loss(아래의 식)를 이용하여 하나의 유사한 쌍(쿼리와 positive)은 더 유사하도록, 다른 negative 이미지들은 멀어지도록 학습하였다고 합니다. 아래의 식의 p^*는 top-1 positive, \{ n_i |^M_{i=1} \} 는 M개의 negative 이미지라고 합니다.
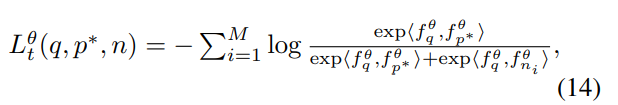
이렇게 두 식을 이용하여 total loss가 계산된다고 합니다.
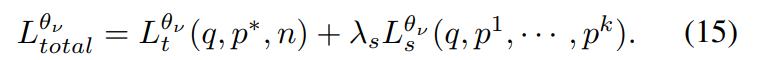
Experiments
Comparison with the State-of-Art
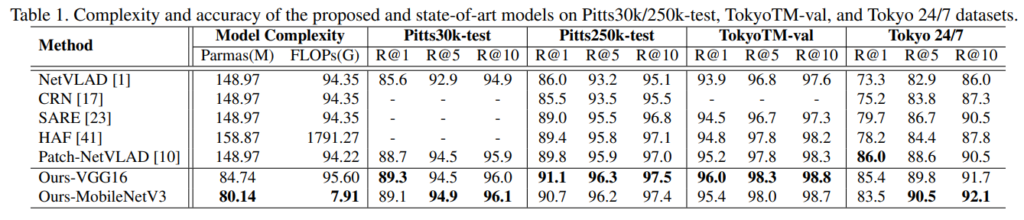
아래의 표는 geo-localization에서의 5가지 SOTA 모델(NetVLAD, CRN, SARE, HAF, Patch-NetVLAD)과 비교한 결과로, Pitts30k-train 데이터셋으로 학습을 진행하고, Pitts30k/250k-test, TokyoTM-val, Tokyo 24/7에 대하여 평가를 수행합니다. 거의 모든 벤치마크에서 좋은 성능을 보였으며, 연산량 측면에서도 장점을 보입니다. 백본이 VGG16일 때, 파라미터가 크게 줄었고, MobileNet을 이용할 경우 FLOP을 크게 줄이고도 성능은 크게 줄지 않았습니다.
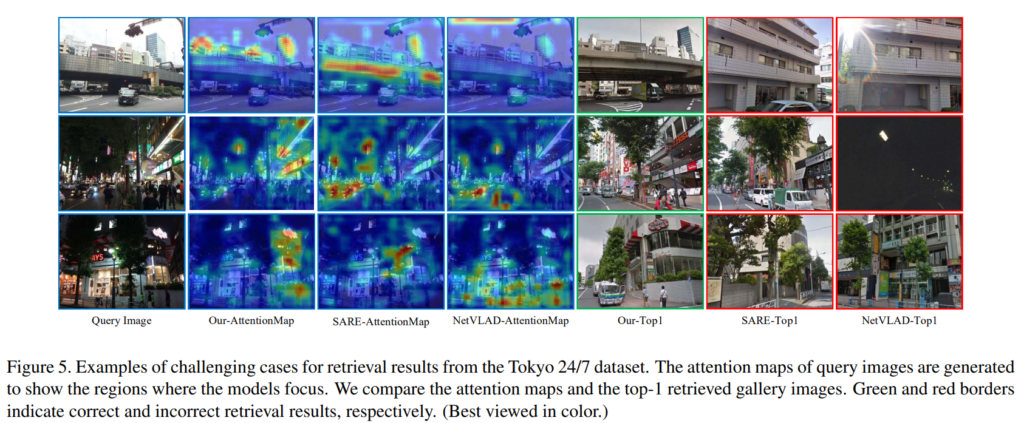
아래의 그림은 정량적 결과를 나타낸 것입니다. attention-map을 통해 저자들은 TransVLAD 방법론이 건물이나 표지판과 같이 구분력 있는 영역에 집중하였고, 다른 방법론들은 나무나 차, 사람들과 같이 변화하는 객체에 집중하였다고 합니다. 해당 논문의 방법론만 정답이고 나머지 두 방법론에서는 잘못된 결과가 나왔을 때에 대한 결과만 리포팅하여 다양한 경우를 리포팅하지 않은 것이 아쉽습니다.
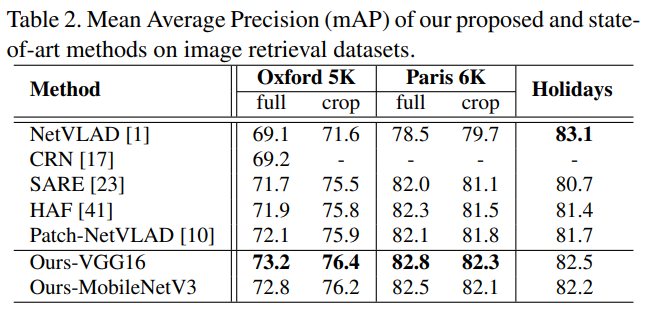
아래의 표는 retrieval에서의 일반화 능력을 평가한 실험으로, Pitts30k-train으로 학습한 모델을 fine-tunning하지 않고 추론만 진행하였다고 합니다. 표의 full은 이미지를 그대로 이용한 것이고, crop은 이미지의 랜드마크 영역만 사용한 것을 의미한다고 합니다. 마찬가지로 다른 방법론들과 비교했을 때 대체로 가장 좋은 성능을 보였고, Holidays 데이터셋에서는 NetVLAD에 비해서는 정확도가 조금 떨어지는 결과가 나왔다고 합니다.
Generalization on Matching Keypoint
아래의 그림은 keypoint matching 방법론인 DFM의 CNN 백본을 저자들의 TransVLAD로 변경한 실험을 시각화 한 것으로, 초록 선이 dense해진 것을 통해 DFM의 백본을 변경함으로써 keypoint matching이 개선되었음을 보인 실험입니다.

이렇듯 저자들은 retrieval 태스크로의 확장과 keypoint matching에 자신들의 방법론을 적용하여 TransVLAD의 범용성을 보였습니다.
안녕하세요 이승현 연구원님 좋은 리뷰 감사합니다.
Introduction에서 뭔가 Transformer에 대해 CNN보다 부족하다고 말하길래 엥 그럼 왜 논문 제목이 TransVLAD지 했더니, feature를 뽑는 것만 CNN이 었군요. 그럼 혹시 이 backbone에 ViT를 사용한 실험은 없나요? 실험해보니 여기서도 inductive bias가 부족했던 건지 아니면 흔히 알려진 바에 의해 그렇게 판단한 건지 궁금하여 질문드립니다.
그리고 두번째는 굉장히 간단한 질문인데, k개의 positive는 어떻게 결정되는지 알 수 있을까요?
말씀하신 것 처럼, ViT를 backbone으로 이용한 실험은 리포팅되어있지 않습니다. 심지어 저자들이 ViT 를 적용하였으나 잘 작동하지 않았다고 이야기한 논문들의 실험 결과도 리포팅 되어있지 않아서 근거가 부족하다고도 생각이 됩니다. 비판적 의견 감사합니다.
또한, k개의 positive는 positive(10m 거리 이내의 이미지)들 중, TransVLAD로 구한 global descriptor의 유사도를 기반으로 k개 결정한다고 합니다. 추가로 알려드리면 negative도 마찬가지로 negative(25m 이상 떨어진 곳에서 촬영된 영상)를 유사도 기반으로 정렬하여 유사한 이미지로부터 M개 이용하게됩니다.
좋은 리뷰 감사합니다.
VLAD의 논문을 최근에 읽고 어떻게 사용되는지 알고 싶어 해당 리뷰를 읽게 되었는데, VLAD 논문에도 언급된 데이터셋인 Holidays 데이터셋에서 NetVLAD의 성능이 더 좋은데 해당 데이터셋에서는 transformer를 사용하지 않는 NetVLAD에 좀 더 잘 맞는 데이터셋이라 생각해도 될까요?
감사합니다.
질문 감사합니다.
논문에는 “On the Holidays dataset, our model with VGG-16 performs lower than NetVLAD since Pitts30k-train dataset lacks images with natural scenes like those in Holidays dataset.”라고 나와있습니다. 즉, 저자들이 모델 학습에 사용한 Pitts30k-train 데이터가 Holiday 데이터 셋과 차이가 있어 성능이 더 낮게 나왔다고 합니다. 논문을 보았을 때는 NetVLAD에 더 잘 맞는 데이터라는 이야기를 하기보다, 학습에 사용된 데이터 때문에 Holidays 데이터에서 성능이 조금 낮았다는 이야기를 하고자 한 것으로 보입니다. (하지만 저자들이 NetVLAD 논문의 성능을 가져온 것이라면, NetVLAD 논문의 학습 방식도 비교해보았을 때 NetVLAD에 좀 더 잘 맞는 데이터 셋이라 보는 것이 맞다고 생각합니다.)