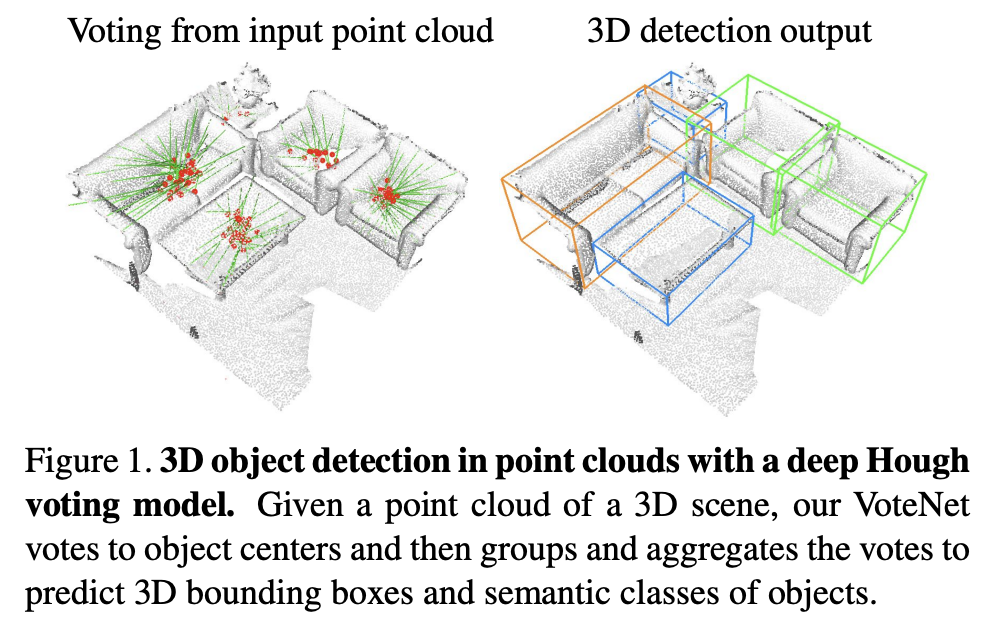
본 논문에서 제안하는 Votenet은 2d detector를 사용하여 feature 추출 시 정보 손실이 발생하는 것을 줄이고, surface만 나타나는 3d point cloud에서 object의 centroid를 더 잘 예측하기 위해 각 points마다 voting하는 방법으로 제안되었다. end-to-end 3d object detection network로 deep point set network와 hough voting을 기반으로 설계되었다. indoor scenes를 포함하는 데이터셋인 ScanNet과 SUN RGB-D에서 sota를 달성하였다.
Introduction
기존 3d object detector 성능은 sparse하고 irregular한 point cloud의 단점을 극복하기 위해 regular한 크기의 voxel 형태로 처리하였으나 여전히 sparsity를 극복하지 못하고 연산량이 많다는 단점이 존재했다. 이후 3d point cloud를 2d bird’s eye view image로 변환하여 2d detector로 object를 localize하였지만 이 경우 특히 indoor 상황에서, 공간의 geometric details를 잃어버린다는 단점이 존재하였다. 그 이후에는 front-view image에서 object를 detect하고 frustum point cloud에서 localizing하는 방법을 사용하였지만 역시 2d detector에 의지한다는 단점이 존재했다.
본 논문에서는 2d detector에 의지하지 않고 point cloud을 direct하게 사용하여 정보 손실을 줄일 수 있고, Hough voting방법에서 영감을 얻은 VoteNet을 제안한다. point cloud를 regular한 형태로 처리하기 위해 PointNet++을 사용한다. 여기서 문제가 하나 더 존재하는데, 3d point cloud에서 depth 정보는 object의 surface에서만 나타나게 된다. 즉, 실제 3d object의 centroid는 알 수 없다. 따라서 3d object centroid를 찾기 위해 voting방법을 사용한다. 이를 통해 object center를 예측하여 box proposal을 할 수 있다.
본 논문에서 제안하는 contribution은 아래와 같다.
1. voting 방법을 사용한 end-to-end deep learning architecture
2. ScanNet, SUN RGB-D에서 sota 성능
3. 3d point cloud에서 3D object detection을 위한 voting 중요성
Related Work
[pointnet++]
우선 pointnet++을 사용하는데, 간단하게 이야기하자면 pointnet에서 local structure를 잘 파악하지 못하는 문제점을 개선하기 위해 pointnet을 하나의 layer처럼 여러 개를 사용하여 hierarchical feature extraction 방식의 네트워크이다. 모델은 크게 sampling layerm grouping layer, pointnet layer로 구성되어 있으며 한 번에 모든 points를 처리하지 않고 grouping을 한 후에 처리하는 방식이다. anchor points를 가지고 sampling layer에서 가장 먼 point로 sampling하고, neighbors끼리 grouping한 후 group별 feature extraction을 통해 local feature를 sampling하게 된다. 자세한 내용은 추후 리뷰하려고 한다.
[Hough transform]
기존 Image에서 사용되는 voting based 방식의 hough transform은 기울기와 bias를 parameter로 하는 parameter space에서 특정 점들 간 연관성을 찾아 특징(직선 등)을 추출하여 image space에 나타내는 방법이다. 이 전에 전공수업에서 차선 검출하는 실습 때 사용해보았던 경험이 있다.
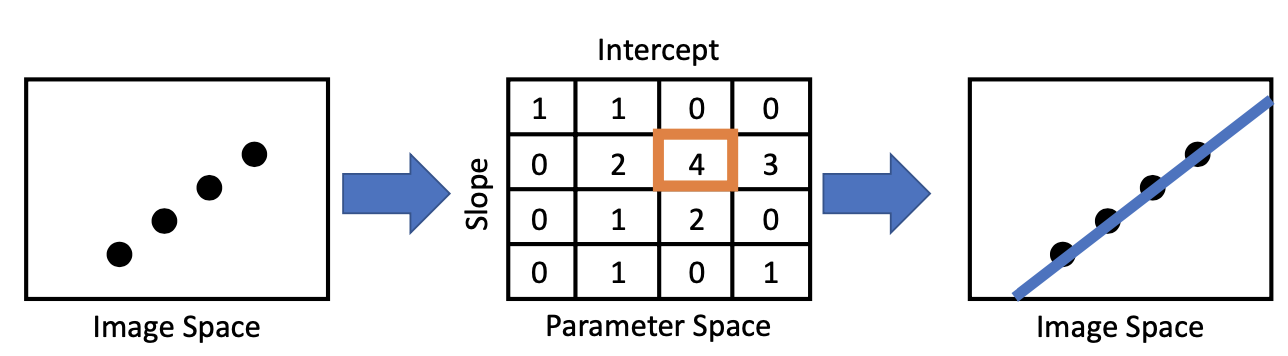
y = m0x + b0로 나타낼 수 있는 직선이 있다고 하자. 이때 image space에서 line은 parameter space에서 point로 나타나며, image space에서 point는 parameter space에서 line으로 나타난다.

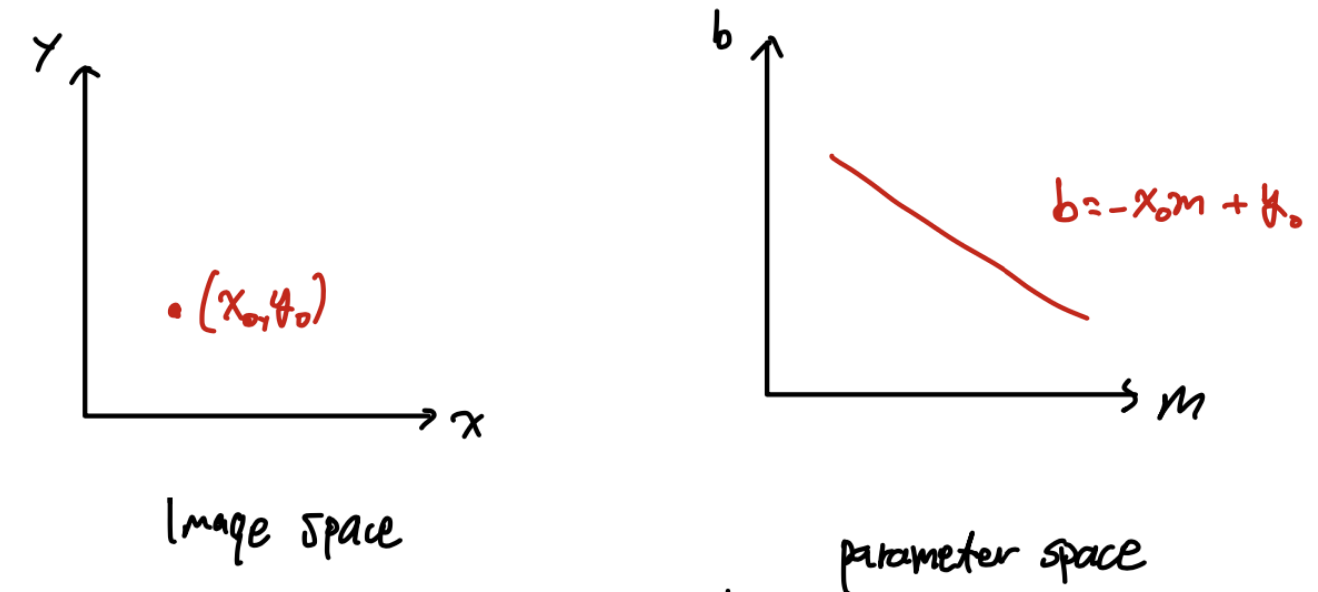
image space의 두 점을 parameter space에서 표현하면 교점이 생기는 두 line으로 나타난다.

위의 parameter space를 보면 m, b가 배열 형태로 표현되는데, 기울기(m)가 y축과 평행한 경우 unbounded한 범위를 가지기 때문에 표현에 한계가 존재한다. 따라서 angle과 offset의 형태로 표현하게 된다.

그럼 결과적으로 points들이 sin파 형태로 나타나게 되는 것을 볼 수 있다.

Deep Hough Voting
기존 RPN(Region-Proposal networks)를 사용하지 않고 voting 방식을 채택하였는데, 우선 voting-based 방식이 object center와 가까운 points를 generate해야하는 RPN보다 연산량에서 이득이라고 판단했다. 그리고 bottom-up원리에 기초하여 vote space를 조금씩 정보를 더해가는 방식이 large receptive field에서 가진 정보를 고려하여 효과적이라고 판단했다고 한다. 하지만 기존 Hough transform방식은 여러 개의 module로 나누어져 있기 때문에 end-to-end를 위해 몇 가지를 개선했다.
– Interest Points : hand-crafted feature방식이 아닌 deep neural network를 이용하여 선택.
– Vote : vote generation은 codebook을 사용하지 않고 network에 의해 학습. 더 넓은 receptive field로 효과적이고, vote location을 feature vector로 하여 더 나은 aggregation 가능.
– Vote aggregation : 학습 가능한 parameters와 함께 point cloud processing layer를 통해 aggregation.
– Object proposal : aggregated features를 통해 location, dimensions, orientation, semantic classes까지 direct로 generate 가능하게 하여 다시 vote의 원래 point를 찾아 처리하는 과정 없어도 됨.
VoteNet Architecture
아래 그림은 VoteNet의 전체 구조이다. 크게 2개 parts로 나누어지는데, 하나는 points마다 vote를 generate하는 과정이고 다른 하나는 vote된 virtual points로 object를 propose, classify하는 과정이다.

Voting in Point Clouds
우선 random sub-sampling한 N(40k)개 points들로 구성된 N x 3크기의 3d point cloud input으로 M개의 votes를 생성하는 과정이 필요하다. 크게 backbone network를 통한 point cloud feature learning과 hough voting with deep networks 두 과정으로 나누어 진다.
point cloud feature learning에서 backbone으로는 다양한 3d task에서 좋은 성능을 보인 PointNet++을 사용했다. Figure 2.에서 Seeds를 추출하는 과정으로 N x 3 크기의 input points를 통해 (x,y,z) + feature vector(C)의 output을 M개 얻게 된다(M x (3+C)). 그리고 각 seed point마다 voting하게 된다.
그리고 voting을 하는데 deep network based voting module을 통해 더 빠르고 효과적으로 할 수 있다. si = [xi ; fi]에서 {si}i=1M로 표현되는 seed에 대해 voting module을 통해 각 seed마다 vote를 하게 된다. voting module은 ReLU와 BN을 포함한 fc layer로 구성된 multi-layer perceptron(MLP) network이다. output은 euclidean space offset( ∆xi ∈ R3)과 feature offset(∆fi ∈ R C)으로, seed마다 vote(vi = [yi ; gi ])를 generate한다. yi와 gi는 각각 yi = xi + ∆xi, gi = fi + ∆fi 로 정의한다.
예측한 3d offset(∆xi)은 아래 regression loss로 사용되므로써 gt에서 object의 center point와 가까워지도록 학습된다. 결국 같은 object에 더 가까워지게 된다.

– 1[si on object] : seed(si)가 object surface에 존재하는지 여부
– Mpos : object surface에 존재하는 seeds의 total 갯수
– xi : seed position
– ∆xi* : gt와 차이로, seed point와 object의 bounding box center와의 차이
Object Proposal and Classification from Votes
이제 vote된 points를 이용하여 object proposal과 classification하는 과정이 남았다. votes를 clustering한 후 이 feature들을 합쳐 object proposal과 classification을 진행하게 된다.
M개의 votes들을 clustering하기 위해 공간에서 인접성을 고려한 간단한 uniform sampling and grouping 방법을 사용한다. M개의 votes({vi = [yi ; gi ] ∈ R3+C }i=1M) 중에서 K개의 votes({vik} with k = 1, …, K.)를 sampling하는데 3D Euclidean space에서 farthest point sampling을 사용한다. 이렇게 sampling한 votes를 서로 이웃하는 것들끼리 K개의 cluster로 구분해주게된다(Ck = {vi(k) | ||vi – vik|| <= r} ). 위의 Figure 2.에서 vote cluster에 해당하는 과정이다.
이 후 shared PointNet을 이용하여 각 cluster에서 vote를 aggregation하고 proposal하게 된다. vote cluster(C = {wi} with i = 1, …, n)에서 cluster center는 wj , where wi = [zi ; hi ] 이며 zi는 vote location이고 hi는 vote feature이다. local vote의 geometry정보를 활용하기 위해 vote location을 local normalized coordinate로 변환해준다(zi‘ = (zi – zj )/r).
이제 해당 cluster에 대한 object proposal(p(C))은 PointNet에서처럼 2개의 MLP를 통과하여 generate된다.

MLP1을 통과한 후 channel-wise maxpooling을 통해 single feature vector로 MLP2로 넘어가게된다. proposal(p)는 multi-dimensional vector로 표현되며 objectness score, bounding box parameter(center, headingm scale parameter), semantic classification scores를 포함한다. 최종적으로 K개의 bounding box 정보를 얻을 수 있고 3D NMS를 통과하여 K’개의 bounding box 정보를 얻게된다. 3D NMS시 IoU threshold는 0.25로 하였다.
loss function은 objectness, bounding box estimation, semantic classification score로 구성된다. vote와 gt object center와 거리가 0.3m보다 가깝거나 0.6m보다 멀 경우 positive, negative로 분류한다. objectness는 ignored(positive or negative가 아닌)되지 않은 proposal 수로 정규화 한 cross entropy loss를 사용한다. positive에 대해서는 가장 가까운 gt bounding box와의 bounding box estimation과 class prediction을 진행한다. semantic classification은 일반적인 Cross entropy loss를 사용한다. 그리고 regression loss는 smoothL1 loss를 사용하였다.
Experiments
실험은 indoor scene으로 되어있는 SUN RGB-D와 ScanNet을 사용하여 진행하였다.
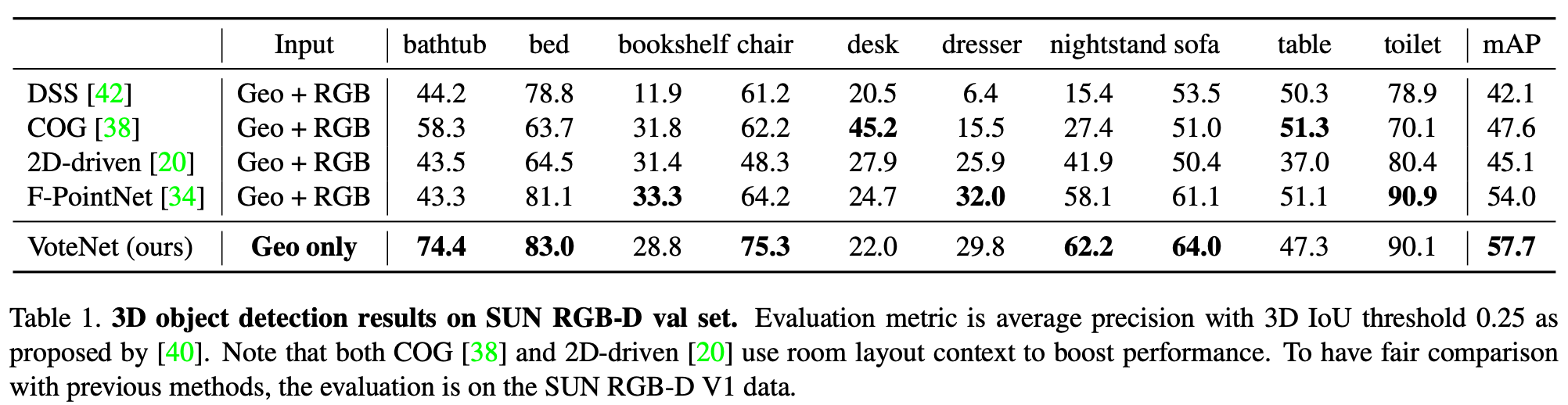
Table 1.은 SUN RGB-D validation dataset에서 결과이다. DSS는 3D CNN based detector로 Faster R-CNN을 기반으로 한다. COG는 cloud of gradient로 sliding window based detector이다. 2D-driven과 F-PointNet은 2D based 3D detector이다. VoteNet은 point cloud를 input으로 하고 나머지 모델들은 point cloud와 RGB를 함께 input으로 사용하였다. 전체적으로 point cloud만을 사용하는 방식이 fusion 방식보다 좋은 성능을 보이는 것을 알 수 있다.

Table 2.는 ScanNet validation dataset에서의 결과이다. 마찬가지로 point cloud만 사용한 방식이 rgb와 fusion하거나, multi-view를 적용한 입력 방식보다 정확한 성능을 보여주는 것을 알 수 있다. 참고로 3D-SIS는 3D CNN based detector로 multiple RGB view를 사용하여 성능을 향상시켰다고 한다.

Table 3.은 BoxNet과 비교 결과이다. BoxNet은 VoteNet과 같은 backbone을 사용한다. 하지만 voting을 하지 않고 seed point에서 바로 box를 generate한다는 차이점이 있다. 즉 voting방식의 차이로 인한 성능을 확인하기 위해 BoxNet을 baseline으로 만들고 진행한 실험이다. SUN RGB-D와 ScanNet 모두에서 voting을 적용한 방식이 앞서는 성능을 보이고 있다. 이런 성능 향상의 결과를 두고 voting을 통해 points들을 더 정확하고 가깝게 aggregation 할 수 있다는 것을 알 수 있다. 아래 Figure 3.에서 ScanNet에서의 성능 비교를 볼 수 있다.

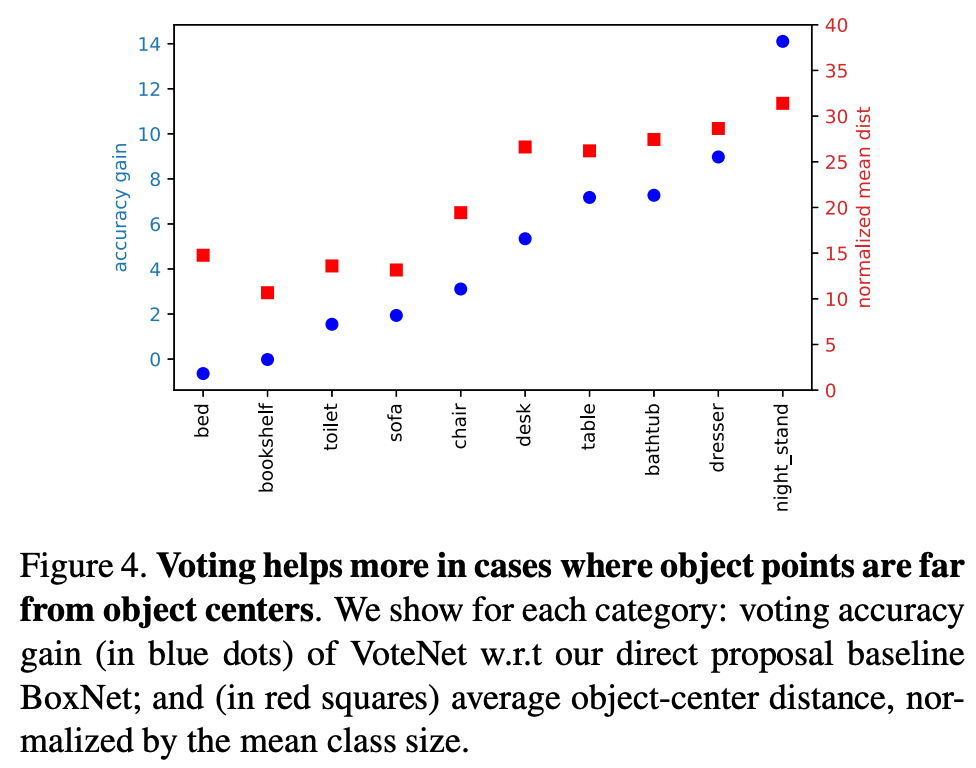
아래 Figure 4.에서는 distance가 멀 수록, 즉 object points가 box center와 더 멀리 떨어져 있는 경우일수록 voting이 더 좋은 효과를 내는 것을 알 수 있다.
아래 Figure 5.는 vote aggregation에 대한 분석이다. 왼쪽부터 보면 radius가 0.2보다 커지면 정확도가 감소한다. 많은 votes가 포함되면 그만큼 clutters도 많아져 성능 하락이 있는 것 같다. 오른쪽을 보면 radius를 0.3으로 하여 feature를 aggregation 방식을 실험한 결과이다. 학습된 Pointnet을 사용하는 것이 manual하게 feature aggregation하는 것보다 높은 정확도를 보인다.

Table 4.에서 VoteNet이 다른 모델들보다 모델 size는 4배 정도 작고, 실행시간은 20배까지 빠른 것을 볼 수 있다.

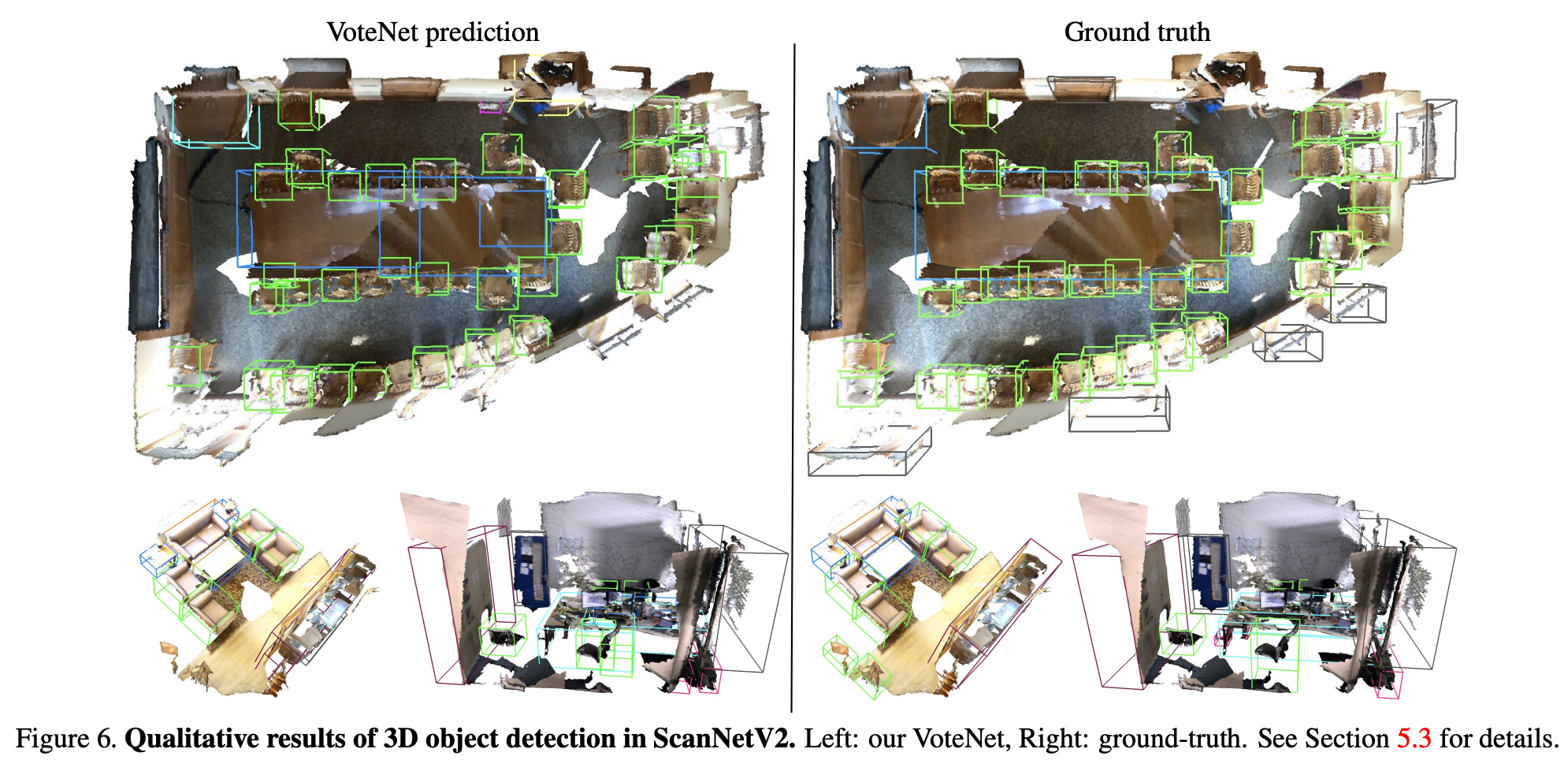
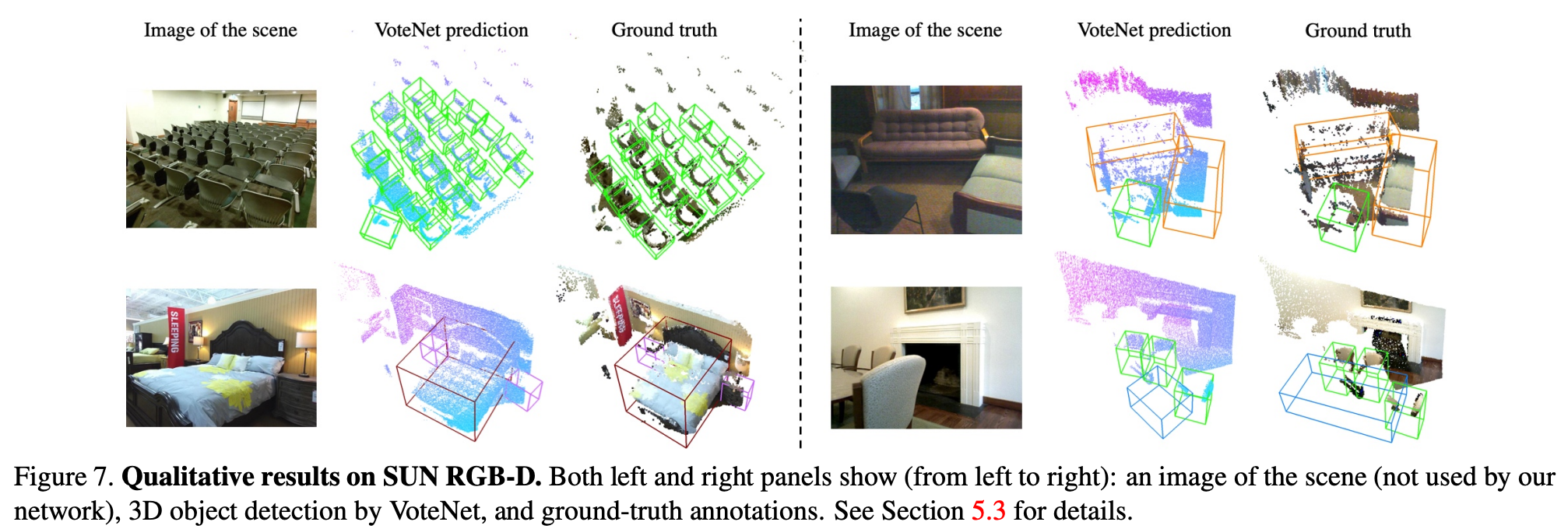
Figure 6.과 Figure 7.에서는 각각 ScanNet과 SUN RGB-D dataaset에서 VoteNet과 gt를 비교한 결과를 시각화한 것이다.
VoteNet은 hough voting에서 영감을 얻어 voting을 적용하여 object centroids를 point cloud에서 찾고 votes를 aggregate하여 object proposal을 하는 3d object detection model이다. 저자는 conclusion에서 미래에 RGB image를 함께 사용할 방법을 찾아보겠다고 한다. 이때까지 fusion방식이 3d dataset만을 사용한 것보다 좋은 성능을 내지 못했던 이유에서 이런 말을 한 것 같다. 그래서 다음에는 ImVoteNet을 읽어보려고 한다.
hough transform.. 머신 비전 시스템 강의에서 공부한 기억이 있는데 이번 리뷰를 보고 다시 한번 정리하게 되었습니다. 감사합니다.
실험부분에서 Geo + N view라 적혀 있는데 여기서 view는 정확히 어떤 정보를 사용하는 건지 알려주실 수 있나요?
Geo + N view에서 Geo는 geometry로 3d point cloud data를 의미하고, N view에서 view는 다양한 각도에서 찍은 rgb 이미지에서의 view를 의미합니다. 3d object 특성 상 multi-view data로 학습한 것이 더 좋은 성능을 보인다는 2015년 논문이 있어 해당 방식을 적용한 것 같습니다.
좋은 리뷰 감사합니다.
Hough transform에 대해서 잘 알지 못했는데 덕분에 쉽게 이해할 수 있었습니다.
이 분야에 도메인 지식이 없어서 그래서 그런지 ‘3d point cloud에서 depth 정보는 object의 surface에서만 나타나게 된다.’라는 말이 잘 이해가 가지 않습니다. object에 대해서 3d point cloud를 구한 경우 object의 surface 정보만 있어서 depth 정보가 별로 없다는 말인걸까요?
3d point cloud 데이터는 LiDAR sensor혹은 RGB-D sensor에서 수집되는 정보로, 전송된 빛(레이저), 신호가 물체로 부터 반사된 신호를 수신하여 points들이 생성된 형태입니다. 따라서 object의 surface에서만 points들이 나타나게 됩니다. depth 정보가 별로 없다기보다 object의 정확한 centroid 위치를 파악하기 어렵다고 생각하시면 될 것 같습니다.
안녕하세요 좋은 리뷰 감사합니다.
point cloud는 lidar센서와 같이 물체에 반사된 좌표값을 데이터로 가지고 있어 물체를 특정하거나 물체의 영역(이렇게 표현하는 것이 맞는 지는 모르겠습니다…)을 알 수 없는 것으로 이해하였고, 이를 알아내는 것이 voting 방법이라는 것으로 이해하였습니다.
리뷰에서는 “Vote : vote generation은 codebook을 사용하지 않고 network에 의해 학습. 더 넓은 receptive field로 효과적이고, vote location을 feature vector로 하여 더 나은 aggregation 가능.”라고 언급해 주셨는데 vote의 개념이 무엇인지 잘 모르겠습니다.
결론적으로 voting방식은 더 정확한 object proposal을 위한 전처리 방법이라고 생각하시면 될 것 같습니다. Figure 2.를 보시면 먼저 입력된 3d point cloud에서 feature를 추출합니다. 그리고 object를 clustering하기 위해 각 object의 surface에만 points가 존재하다보니 centroid를 찾는데 어려움이 있습니다. 이때 더 정확한 object clustering을 위해 추출한 각 points(seeds)마다 voting을 통해 해당 object의 centroid를 예측하는 것입니다.