What is the point it talking about?
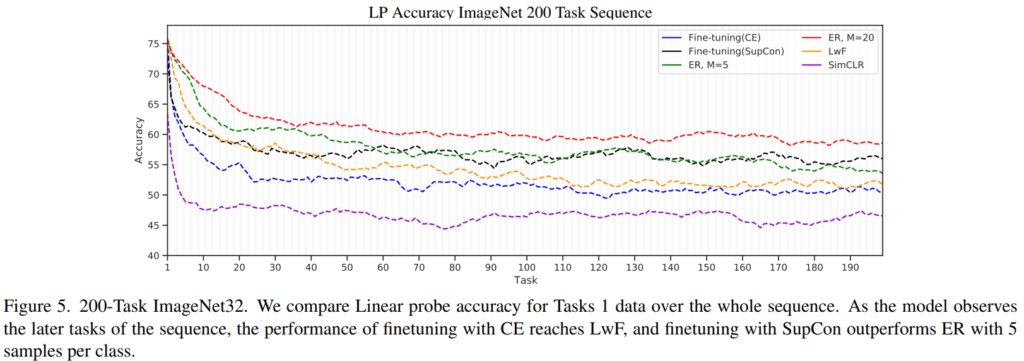
이번 논문 또한 incremental/continual learning(이하 CL)과 관련된 내용입니다. 앞선 세미나 등에서 태스크를 소개하며 말씀드린 것처럼 CL이란 여러가지 과제를 학습하고 확장하는 프로세스에 주로 적용되는 방법론으로 새로운 테스크를 학습 시 이전의 테스크를 잊지 않는것이 주요 해결과제입니다. 이렇게 새로운 데이터를 학습하므로써 기존의 지식을 잊는 문제를 categorical forgetting이라고 합니다. 용어가 따로 이름지을 정도로 CL의 주된 문제임을 예측할 수 있지요. 일반적으로 기존 학습모델을 새로운 데이터로 fine-tuning하는것은 기존 지식을 잊고, 새로운 지식에 맞춰진다고 생각됩니다. 따라서 기존 과제의 데이터 혹은 데이터의 대표값을 저장해놓고 재학습하는 리허설기반의 해결책, 혹은 기존 모델이 크게 변화지 않게 가중치를 주는 정규화방법, 모델의 파라미터를 그대로 보존하는 방법등을 CL을 위한 방법론으로 개발되곤 합니다. 그런데 해당 논문은 finetuning을 통해 모델이 기존 정보를 잊지 않는다고 주장합니다. 위의 Figure5 그래프를 보시면 forgetting을 위한 대안을 추가한 CL 방법론인 ER, Lwf와 추가하지 않은 모델 학습방법인 fine-tuning(CE, Supcon)을 비교합니다. 그래프를 보시면 fine-tuning(CE=cross entropy) 방법론이 LwF와 실제로 유사할 뿐만 아니라 fine-tuning(Supcon)은 forgetting을 위한 별다른 처리 없이도 LwF보다 높은 성능을 보이며 기존 task에 대한 지식을 보유하고 있음을 보였습니다.
그렇다면 왜 기존의 방법론들은 forgetting이 있다고 했는지, 해당 방법론은 실질적인 forgetting이 없음(혹은 생각보다 적음)을 어떻게 알아냈는지 이어서 소개해보겠습니다.
how to measure forgetting?
forgetting은 어찌보면 추상적인 개념입니다. 그렇다면 다양한 CL 연구에서 이를 어떻게 측정하고 있을까요? CL에서 주로 다루는 classification task를 기준으로 accuracy의 변화율을 측정하게 됩니다.
그러나 해당 논문은 끝의 classifier가 사실 측정치의 forgetting을 유발하는 이유라고 합니다. 즉 classifier만을 original task에 맞추어 재학습하고 이로 accuracy를 측정해야한다는 것입니다. 측정 방식은 아래 수식1과 같으며 T는 accuracy를 측정하는 함수입니다. 두 테스크 a, b로 학습한 테스크 모델을 이용하여 accuracy 차이를 계산하여 forgetting을 측정합니다.
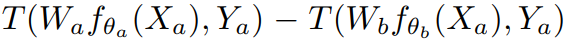
위와같은 새로운 측정법을 제안하므로써 forgetting에 대한 측정 지표가 representation이 되어야한다는것을 알 수 있습니다. 모델이 실제로 기존 데이터를 잊는지 잊지 않는지에 대한 측정 기준을 바꾸는 것입니다. 이어서 논문은 해당 측정법을 통해 방법론간의 forgetting이 실제와 기존 연구가 발표한 성능과 다를 수 있음을 실험을 통해 보입니다.
실험
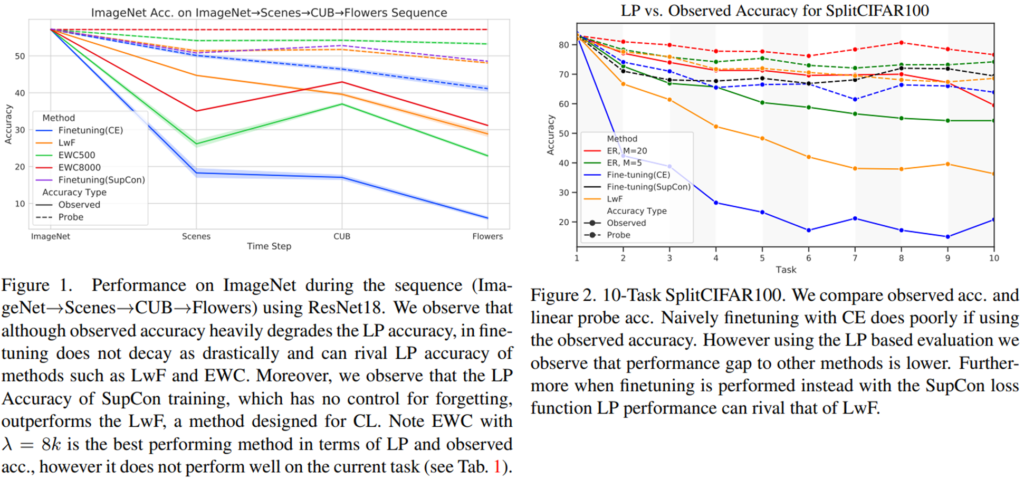
실험으로는 제안하는 LP accaracy와 기존의 observed accaracy간의 비교와 Supcon loss의 forgetting 예방 효과를 확인할 수 있습니다. 제안하는 forgetting 측정방식에 관한 실험으로 먼저 figure1을 확인해봅시다. 점선이 제안하는 LP accaracy, 실선이 기존의 observed accaracy입니다. ImageNet->Scenes->CUB->Flowers->Sequence 순서로 학습을 진행한 후 다시 ImageNet데이터로 classification accuracy를 측정한 결과인데요, obseved accaracy를 이용하면 방법론간의 차이가 크며 마치 심각한 forgetting이 발생하는 듯 보입니다. 그러나 제안하는 방식으로 측정하면 실제 forgetting은 크지 않으며 방법론간의 차이도 작습니다. 또한 figure5에서 본것처럼 LwF 방법론보다 finetuning(Supcon)방법론이 더욱 기존 task의 정보를 잘 보존함을 알 수 있습니다. 이러한 경향은 figure2의 CIFAR100 을 이용한 task 전환실험에도 동일하게 나타납니다. 이는 cifar100의 100클래스를 10개의 task로 나누어 실험을 진행한 실험입니다.
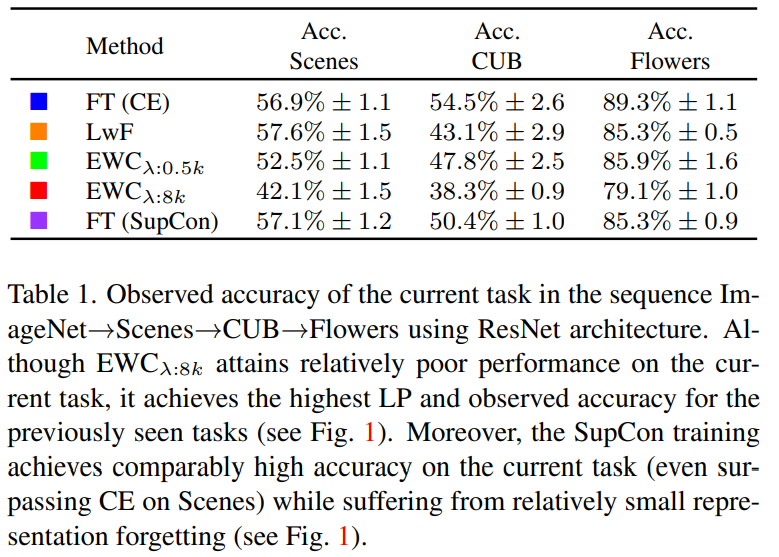
또한 아래 Table1은 Figure1의 연장실험인데요, 각 original task에 대한 observed accuracy(기존 측정법)또한 finetuning 방법론이 대체적으로 좋습니다. 특히 forgetting 문제를 가장 잘 해결한 EWC는 original task에 대한 성능은 일반적을 좋지 않음을 확인할 수 있습니다. EWC는 기존 테스크의 데이터를 일부 활용하는 리허설기반의 forgetting 해결방안으로 기존 데이터를 많이 참조할수록(500<8,000) original task에 대한 성능이 낮음을 보였습니다.
또한 위에 있어 추가하지 않았지만 figure5를 보면 SimCLR에 대한 성능도 같이 비교된것을 알 수 있는데요 figure 5의 10~50구간을 보시면 SimCLR이 다른 방법론에 비해 평평함을 볼 수 있습니다. 이러한 비교를 통해 self-learning 방법론인 SimCLR이 labeled information을 활용하지 않아 초기 성능이 낮으나, 전체적으로 일반적인 정보를 학습해 성능이 task 전환에 큰 영향을 받지 않음을, 즉, 일반화된 정보를 학습하고 있음을 알 수 있다고 합니다.
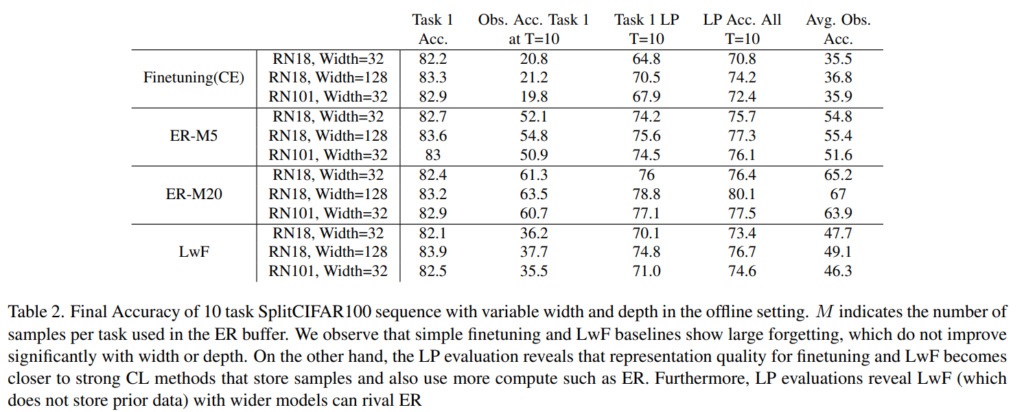
마지막으로 Table3는 모델의 크기에 따른 비교실험입니다. 전체적으로 observsed acc보다 제안하는 LP acc의 정확도가 높은것을 알 수 있으며 observed와 finetuning 방법론간의 성능차이가 다른 방법론(ER, LwF)에 비해 finetuning에서 크게 차이남을 확인할 수 있습니다. 이를 통해 finetuning이 기존 측정법으로 비교적 큰 패널티를 가지고 있었음을 알 수 있습니다.
마치며
본 논문은 다양한 데이터와 다양한 CL 세팅 (테스크의 전환, 데이터셋의 전환)으로 다방면(모델 크기, 다양한 accuracy, Supcon Loss와 SimCLR의 적용가능성) 실험을 진행하여 기존 연구들이 주장하는 forgetting을 새로운 방식으로 바라보아야 한다고 주장합니다. 따라서 해당 논문을 기반으로 CIFAR-10에 몇가지 실험을 했을때 실제로 representation이 상당부분 보존되는것과 같은 결과를 보였습니다. 그러나 리뷰를 작성하는 현 시점에서는 약간 다른 생각도 듭니다. CL에서 보통 forgetting은 얕은 레이어일 수 록 크고 깊은 레이어일수록 작다고 합니다. 이론상 DNN의 얕은 레이어는 조금 더 피상적인 정보에 집중하고 깊은레이어 일수록 추상적인 정보를 볼 수 있기 때문인데요, 이러한 forgetting의 정도차이가 classifier만을 재학습하므로써 감추어지는게 아닐까 합니다. 즉, task 변동을 계속 진행한다면 forgetting은 결국엔 발생지 않을까 합니다. 물론 이러한 상황에서 forgetting이 발생할 정도로 시간이 많이 지난 데이터를 inference에서 실제 사용하는가? 라는 궁금증도 생기지만, 이렇게된다면 어쨌든 forgetting을 해결하자 라는 본래의 목적과는 약간 다르니까요. 물론 제안하는 LP accuracy로 forgetting을 측정해야한다는 것에는 매우 동의합니다. 이상으로 리뷰 마치겠습니다.
황유진 연구원님 좋은 리뷰 감사합니다.
리뷰에서 다음과 같이 말씀하셨는데요. “그러나 해당 논문은 끝의 classifier가 사실 측정치의 forgetting을 유발하는 이유라고 합니다. 즉 classifier만을 original task에 맞추어 재학습하고 이로 accuracy를 측정해야한다는 것입니다. ”
우선 첫번째는 어떤 근거로 마지막 classifier가 forgetting을 유발하는 지가 궁금합니다. 논문 안에서 이에 대해 밝힌 실험이 있을까요?
그리고 두번째는 기존에는 어떤식으로 forgetting을 정량적으로 평가했었나요? 수식1이 저자가 주장하는 메인 아이디어 같은데 어떤 차별점이 있는지 궁금하여 질문 드립니다
마지막 classifier가 forgetting을 유발하는 지에 대한 실험은 제안하는 LP accuracy와 기존의 observed accuracy 간의 차이를 통해 알 수 있습니다. LP accuracy에서 classifer만 original task에 맞게 재학습하였을때 기존 측정법 대비 forgetting 비율이 작은 것으로 보아 classifer가 forgetting에 큰 영향을 미침을 알 수 있습니다.
다음으로 기존에 평가방식은 observed accuracy인데 orginal tast data에 대한 재학습 없이 즉, task b로 학습된 모델을 task a에 대한 재학습 없이 task a에 대해 accuracy를 측정합니다.
좋은 리뷰 감사합니다.
이전에 incremental learning관련 리뷰 중 파라미터의 일부 파라미터만 학습하도록 하는 방식이 있다고 하셨는데, 이 논문에서 저자들이 주장하는 바를 근거로(representation은 categorical forgetting이 거의 일어나지 않고 classifier가 변하는것) representation을 학습하는 부분은 fine-tuning시 자유롭게 두고 classifier 영역만 기존 연구들을 활용하여 실험을 해보았는지 궁금합니다.
이 논문에서 저자들이 주장하는 바는 representation을 하는 backbone을 finetuning시 freeze합니다.