Introduction
intro에서는 이 당시 등장했던 cnn classification모델인 alexnet, vgg, googlenet을 설명하며 이들의 구조에 관해 이야기합니다. 기존 cnn모델은 [그림 1]과 같이 convolution을 이용해 특징을 추출하고, 이를 fc레이어에 통과시켜 입력 이미지의 클래스를 추론합니다. 저자는 이러한 cnn기반의 네트워크로 segmentation을 수행하기 위해 fc레이어 대신 conv 레이어를 사용하고, 픽셀 단위의 예측을 위한 upsampling기법으로 deconvolution을 사용한 Fully Convolutional Network를 제안하였습니다.
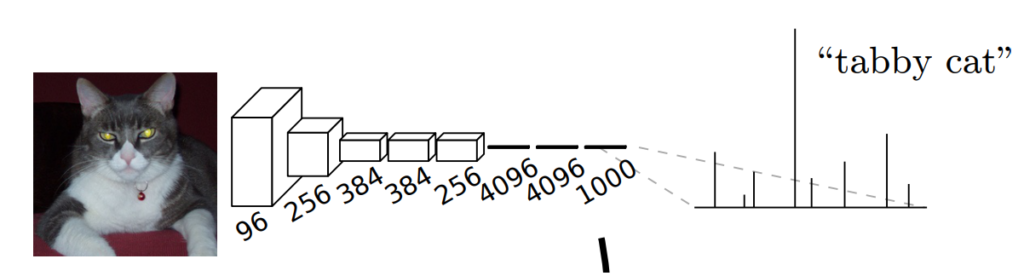
Fully Convolutional Networks
논문에서 소개하는 FCN
- Fully Convolutional Network : cnn분류기의 fc레이어를 제거 후 conv 레이어로 변형
- deconvolution: upsampling기법으로 모델의 end-to-end학습을 가능하게 함
- skip connection
Adapting classifiers for dense prediction
논문의 가장 핵심적인 부분으로, fully connected layer와 convolutional layer를 비교하며, 기존 모델에서 fc레이어가 차지하던 부분을 conv레이어로 바꿀 수 있다는 내용입니다. 보다 구체적으로 설명하자면 fc레이어는 입출력 노드의 수가 정해져 있어 고정된 크기의 input만을 사용할 수 있으며, [그림 2]과 같이 모든 노드들이 연결되므로 공간 정보가 소실된다는 특징이 있습니다, 그러나 segmentation은 이미지의 각 픽셀을 클래스로 분류하는 것으로 위치 정보가 중요합니다.
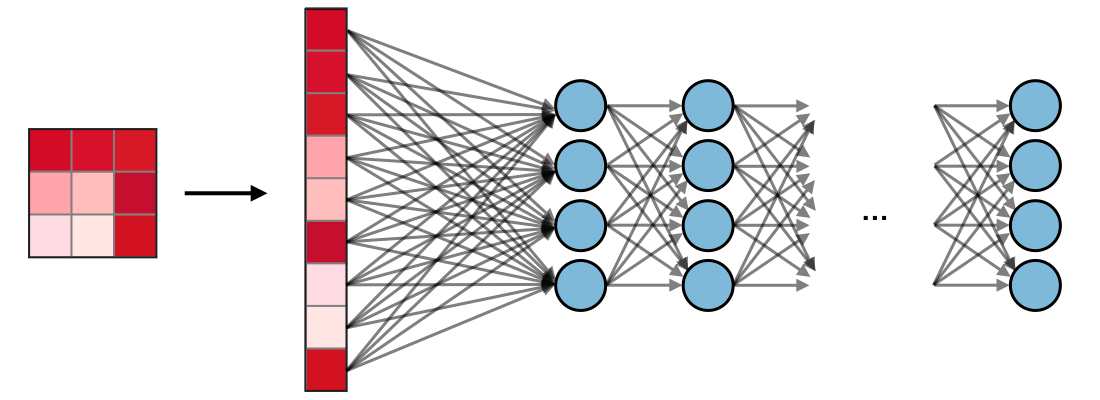
feature의 공간 정보를 유지하기 위해, FCN은 기존 CNN모델에서 fc레이어를 제거하고, input의 전체 영역을 보는 kernel을 사용해 fc 레이어를 conv레이어로 대체하였습니다. fc레이어는 flat한 출력값을 도출하는 데 반해 conv레이어는 공간 정보를 포함하는 출력값을 도출합니다. 이를 시각화하면 [그림4]와 같습니다.
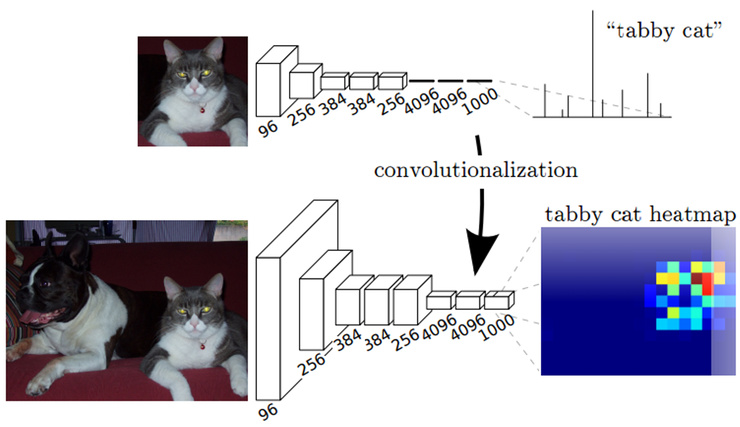
segmentation을 진행하기 위해서는 convolution을 통해 도출된 출력을 처음 입력된 이미지의 크기로 upsampling을 수행해야 합니다.
upsampling
upsampling은 coarse한 output을 dense하게 변형하기 위한 방법입니다. segmentation은 픽셀 단위의 예측을 수행해야 하므로 convolution에 의해 downsampling된 feature를 input크기로 upsampling하는 과정이 필요합니다. 논문에서는 upsampling방법으로 deconvolution을 사용하였습니다.
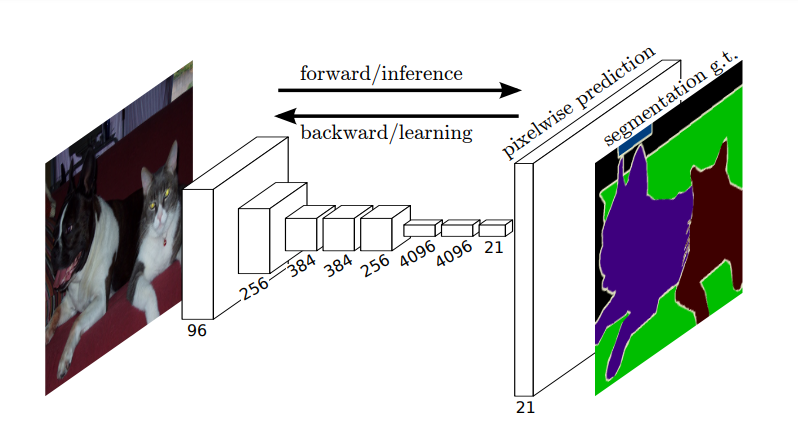
make dense predictions for per-pixel tasks like semantic segmentation.
deconvolution
deconvolution은 학습 가능한 parameter를 통해 upsampling을 진행합니다.
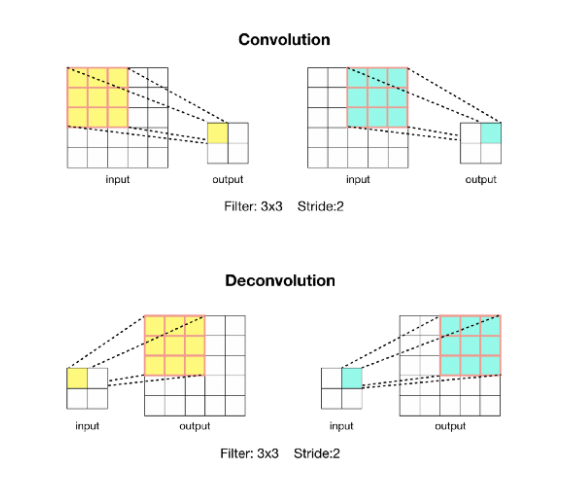
deconvolution은 [그림 6]과 같이 convolution 연산으로 feature를 압축 시킬 때 필터의 parameter를 학습하듯, feature를 팽창 시킬 때도 parameter를 학습시키는 방법을 사용하는 방법입니다. 이러한 방식의 upsampling은 convolutioin의 forward, backward를 반대로 수행하면 되므로 네트워크에서 사용될 때 pixelwise loss를 통한 end-to-end학습이 가능하다는 장점이 있습니다. 또한, convolution처럼 windowing방식으로 연산이 진행되기 때문에 입력의 크기에 영향을 받지 않으며, activation function과 결합하여 nonliniar한 연산이 가능합니다.
Segmentation Architecture
From classifier to dense FCN
cnn기반 분류기인 Alexnet, VGG16, GoogLeNet을 각각 FCN으로 변형하였습니다. 이때, pixelwise loss를 사용하고, skip을 통해 coarse, semantic한 정보와 local, apperance정보를 모두 사용하였습니다.
- GooLeNet은 마지막 average pooling층을 버리고 사용
- 각 네트워크에서 마지막 분류층을 버리고 모든 fully connected layer를 21채널의 1*1 convolution으로 변형, 그 뒤에는 deconvolution layer로 coarse output을 upsamling함
Combining what and where
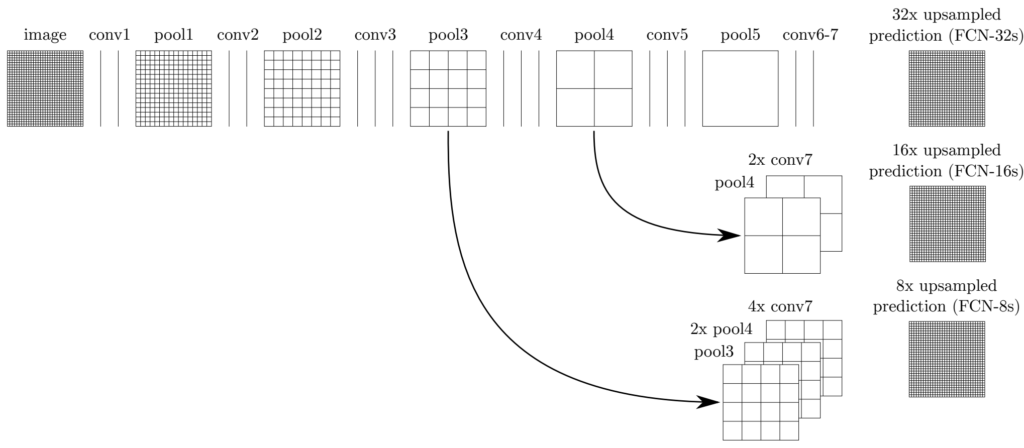
논문에서 정의하는 FCN(fc to conv + upsampling + skip connection)과 [그림7]과 같으며, skip connection에 따른 segmentation결과는 [그림8]과 같습니다.
FCN뒤의 숫자는 conv이후 마지막 prediction layer에서 upsampling의 stride를 나타낸 것으로 FCN-32s는 32배 upsampling한 것을 의미합니다. [그림 8] 가장 왼쪽의 FCN-32s의 segmentation 결과를 보면 저해상도와 같이 뭉개지고, 세밀한 부분은 부정확하게 segmentation이 되어있습니다. 이러한 현상을 개선하기 위해, 논문에서는 convolution의 앞부분에 존해하는 높은 해상도의 이미지 정보를 deconvolution으로 전달하는 skip connection을 사용하였습니다. [그림 7]을 보면 네트워크 구조에 따라 각 단계별로 대칭적인 skip connection이 만들어 지는 것을 볼 수 있습니다.
[그림 7]은 FCN-32s, FCN-16s, FCN-8s의 구조를 하나의 그림으로 표현한 것으로 각각의 구조는 다음과 같습니다.
- FCN-32s: conv7의 feature를 그대로 32배 upsampling
- FCN-16s: 1개의 skip connection이 존재하는 모델로, conv7의 feature를 2배 upsampling한 후 pool4의 output과 합칩니다. 합친 feature를 prediction layer에서 16배 upsampling합니다.
- FCN-8s : 2개의 skip connection이 존재하는 모델로, pool4와 conv7*2를 합친 결과를 2배 upsample하고 이를 pool3의 output과 합칩니다. 합친 feature를 prediction layer에서 8배 upsampling합니다.

from layers with different strides improves segmentation detail.
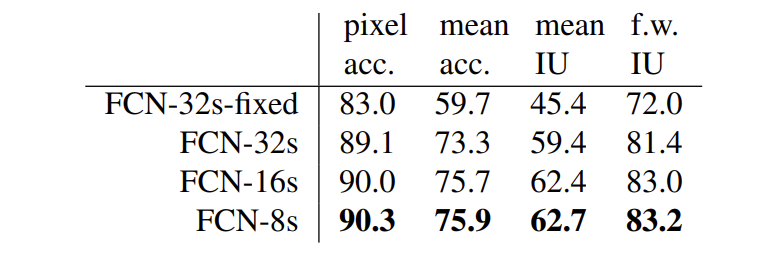
[표1]은 skip connection의 개수가 다른 FCN의 성능을 비교한 결과입니다. PASCAL VOC 2011데이터셋으로 평가를 진행하였으며, 결과를 보시면 FCN-8s의 성능이 가장 좋은 것을 확인할 수 있습니다. 이는 FCN-8s에서 pixel 단위의 예측을 수행 시, 여러 개의 skip connection을 통해 conv 레이어의 coarse한 정보와 dense한 정보를 모두 사용하기 때문입니다.
Experimental
실험은 FCN-AlexNet, FCN-VGG16, FCN-GoogLeNet으로 진행되었으며, image classifier를 segmentation에 맞도록 fine-tuning하였습니다.
Pascal VOC
[표 3]은 Pascal VOC데이터셋으로 평가한 결과이며, 기존 SOTA 모델인 R-CNN과 SDS와 저자의 FCN-8s를 비교하였습니다. 에 비해 성능과 속도가 개선되었음을 확인할 수 있습니다.

[그림 9]는 FCN-8s와 SDS 모델을 Pascal데이터셋으로 평가한 결과를 시각화한 것입니다. 1~3행의 sample에 대해서 FCN-8s가 물체의 끝 부분의 detail한 정보를 더 잘 인식하는 것을 확인할 수 있습니다. 그러나 4행의 sample의 경우 사람과 비슷한 구명 조끼를 사람으로 인식하는 등의 오류가 발행한 것 또한 확인할 수 있습니다.

Semantic Segmentation이란 익숙한 단어를 보고 들어오게 되었습니다. 사실 워낙 base적인 방법론이라 내용적인 부분에서의 질문은 없는데요, 해당 분야의 논문을 읽게 된 계기가 무엇인지 여쭤봐도 될까요?
그리고 추가적으로 실험 부분에서 그냥 table을 캡쳐해서 올리는거 말고, 각각에 대한 분석이나 설명이 있으면 좋을 거 같습니다.
감사합니다.
피드백 감사합니다. 리뷰에 실험 결과에 관한 설명을 추가하였습니다.
해당 논문은 이승현 연구원님의 추천으로 읽어보게 되었습니다. 접해본 적 없는 dl기반 segmentation분야의 base논문이기도 하고 FCN자체로도 여러 분야의 활용되는 base방법론이기도 해서 리뷰를 작성하게 되었습니다.
Combining what and where에서 “논문에서 정의하는 FCN(fc to conv + upsampling + skip connection)과 [그림]과 같으며” 라고 하셨는데, 이 부분의 설명이 조금 더 있으면 좋을 것 같습니다. 어떻게 작동이 되는지 더 자세하게 설명해주실 수 있나요?? 또한 어떤 그림을 의미하는지 헷갈려서 다음에는 매칭을 시켜주시면 좋을 것 같습니다.
FCN의 작동에 관해 추가적으로 설명드리자면 conv1~7까지 convolution layer를 통해 feature extraction, downsampling을 진행하고, conv7의 결과값을 32배 upsampling하여 입력 이미지와 같은 scale로 만드는 과정입니다. 이때, upsampling을 진행하면서 모델의 앞부분에서 생성된 pool4, pool3의 feature를 더헤주는 skip connection이 사용되는 것입니다. (Combining what and where 부분에 해당 내용에 관한 설명을 추가하였습니다.)
figure를 지칭할 때 번호가 누락되었습니다… 해당 부분 역시 수정하였습니다.