이번에 소개드릴 논문은 Self-supervised Learning으로 학습한 MAE를 data augmentation으로 활용해서 high-level recongnition task를 더 잘 수행하도록 학습시켜보자? 라는 방법론입니다. 컨셉 자체가 상당히 간단하여서 간단히 리뷰 작성해보겠습니다.
Intro
인트로의 내용 흐름을 요약하면 대략 아래와 같습니다.
- 딥러닝으로 모델을 학습시키기 위해서는 상당한 양의 데이터가 요구된다.
- 데이터의 양을 늘릴 수 있는 방법들(data augmentation)에 대한 연구가 진행되어왔으며 가장 흔한 것은 linear transformation 기반 방법들이다.(color jitter, geometry transformation 등등)
- 이러한 low-level transformation들은 적용하기 쉽고 빠르지만, 입력 분포를 효율적으로 일반화하기에는 아직 부족함이 많다.(휴리스틱한 방법론이기 때문에 데이터 증강에 한계가 존재한다.)
- 딥러닝 모델 기반의 데이터 증강 기법(i.e., GAN)은 의료쪽 분야와 같이 데이터 개수가 매우 적은 분야에서는 좋은 증강 기법으로 활용되지만, large-scale dataset에서는 큰 장점을 기대하기는 어렵다는 문제가 존재한다.(저자는 이 원인에 대해 GAN으로 생성된 샘플들이 원본 영상 대비 얼마나 잘 묘사되었는지를 측정할 수 있는 정량적인 지표의 모호함을 꼽음.)
- 따라서 저자는, 이러한 model based data augmentation (특히 GAN과 비교하여)의 단점을 극복하고자 adversarial learning을 적용하지 않은 image inpainting model 즉 SSL로 학습한 masked autoencoder(MAE)를 data augmentator로 활용하고자 한다.
요약하자면 SSL로 학습한 MAE를 data augmentator로 활용하여 다양한 classification task(supervised, semi-supervised, few-show)에서 성능 향상을 보였다는 것이 이 논문의 핵심인 듯 합니다.
Method
방법론 자체도 간단하니 빠르게 훑고 넘어가겠습니다. 먼저 논문에서 제안하는 방법론의 전체 흐름은 다음과 같습니다.
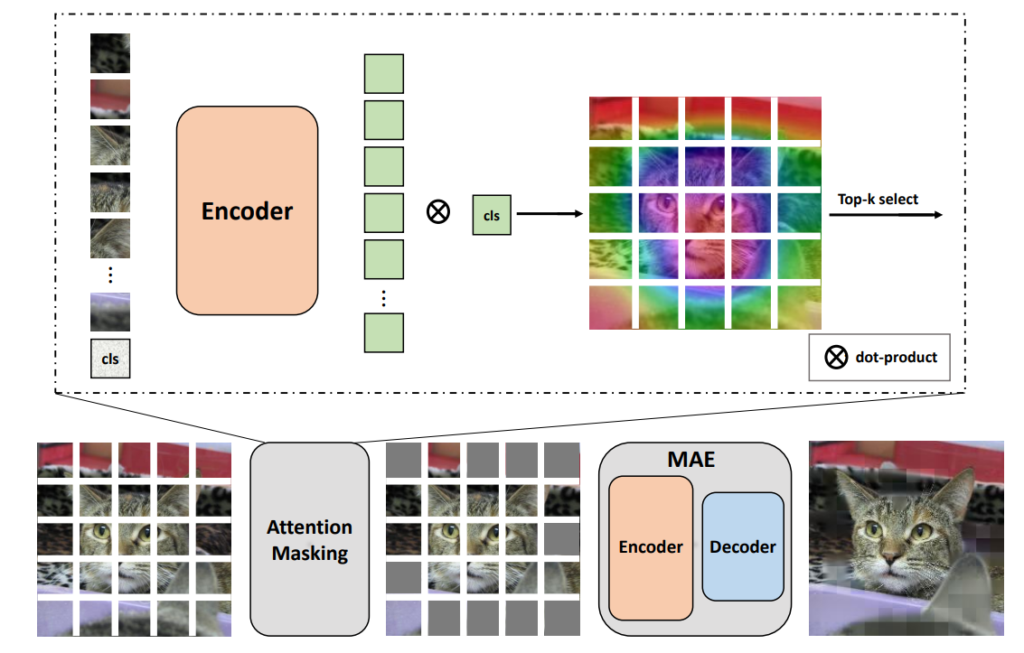
위에 흐름에서 중요한 부분은 Attention Masking과 MAE를 통한 증강 이미지를 생성하는 과정 이 두가지입니다. MAE에 대해서는 홍주영, 임근택 연구원이 작성한 MAE 논문 리뷰글들을 참고하시면 좋을 듯 하며, 간략한 컨셉은 영상의 많은 영역을 마스킹한 후 마스킹이 되지 않은 영역들을 ViT의 입력으로 넣어 마스킹이 된 영역을 재구현하도록 학습하는 기법을 의미합니다.
그래서 해당 논문에서도 증강 영상을 생성할 때 MAE를 활용하며, 동시에 MAE의 입력 전에 마스킹을 함으로 그림1의 고양이 패치 부분들 중 회색 패치가 존재하는 것을 확인하실 수 있습니다.
Attention-based Masking
MAE의 핵심 목적 함수는 결국 마스킹이 된 영역을 reconstruction하는 것이기 때문에, 영상을 어떤 식으로 visible한 patch와 masking patch로 구분 짓는가에 대해 많은 관심과 고민이 있었을 것입니다. 결과적으로는 기존 MAE 논문에서는 영상의 랜덤한 영역들에 대해서 masking patch를 선택하는 것이 가장 좋았다고 하지만, 본 논문에서는 랜덤 방식이 아닌 attention-based masking 전략을 적용하였다고 합니다.
그렇다면 이 attention-based masking 전략은 무엇이냐 하면 결국 논문에서 하고자하는 task가 image classification에 국한되는 것 같으며, 보통 image classification의 학습 및 평가로 사용되는 데이터는 영상의 중심에 분류하고자 하는 물체가 존재하는 물체 중심 데이터(object-centric data) 형태를 지니고 있습니다.
따라서 저자는 MAE를 통한 증강 데이터를 생성할 때 최대한 object 영역의 정보는 유지한 체 그 외에 다른 background 영역을 새로 reconstruction하여 증강 이미지를 생성하기를 원했습니다. 이를 위하여, 물체 위치의 inductive bais를 활용해 masking을 하는 방법을 적용하였다고 합니다.
그럼 여기서 잠깐, segmentation label이나 bounding box 같은 label이 없이 어떻게 foreground object에 대한 영역을 알고 그 영역을 제외한 다른 영역들을 마스킹할 수 있을까요?
저자는 단순히 DINO라는 또 다른 Self-supervised Learning을 통해 학습한 ViT pretrained encoder를 활용해서 이 문제를 해결했다고 합니다. DINO는 image inpainting을 pretext task로 학습하는 MAE와 달리, Contrastive Learning을 통해 ViT를 pretraining하는 기법입니다. 이 논문이 재밌는 점은 이렇게 학습시킨 ViT의 attention map이 영상 속 semantic 정보를 상당히 잘 활성화한다는 점입니다.

MRA 논문의 저자는 이러한 DINO의 성질을 활용하여 영상 속 패치가 foreground object에 대한 patch인지를 나타내는 여부를 attention 강도에 따라 확인하였으며 , 이러한 high attention patch를 제외한 나머지 patch들을 마스킹함으로써 전경과 배경을 나눌 수 있다고 합니다.
즉 그림1에서 Attention Masking이라고 적힌 모듈 속에 또 Encoder 그림이 있는 이유는 바로 Contrastive Learning으로 Self-supervised learning한 Pretrained ViT(DINO)를 활용한 것이죠. 결국 해당 논문은 SSL로 학습한 pretrained ViT 2가지(DINO, MAE)를 활용하여 데이터를 증강하고 이렇게 증강된 데이터를 가지고 다시 또 모델을 학습시키는 무한동력을 완성하게 됩니다.
아무튼 다시 attention masking 방법론으로 돌아와서, 이렇게 pretrained DINO를 활용해 입력 영상에 대한 encoded patch와 cls token을 얻었다면, 이제 cls token과 encoded patch의 key 값들 사이에 attention map을 생성해야 합니다. 즉 쉽게 말해서 그림2의 예시처럼 attention map을 생성하기 위한 과정이라고 생각하시면 됩니다. 어떤 패치가 fg object고 어떤 패치가 bg인지를 나타내는 attention map을 생성하는 것이죠.
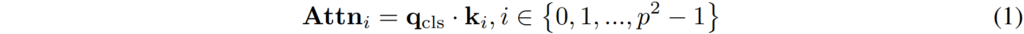
위에 수식은 i번째 패치에 대한 cls token의 attention map을 구하는 과정인데, 여기서 q_{cls} 는 class-token의 query를 의미하며, k_{i} 는 i번째 패치의 key 임베딩 벡터를 의미합니다.
결과적으로 전체 패치 개수에 대한 query와 key 사이에 Attn attention 벡터를 계산하게 되고 난 후에, 이 attention map들에 대한 top-k개의 인덱싱 과정을 거치게 됩니다. 즉 상위 k개만큼의 가장 큰 값을 지닌 attention vector들을 인덱싱하겠다는 것이죠.
이렇게하여서 최종적으로 입력 영상에 대해 high score를 지닌 영역과 아닌 영역들을 거르는 binary mask를 생성할 수 있으며, 이렇게 마스킹된 패치들은 제외하고 visible patch만을 MAE로 태워서 증강 영상을 생성하게 됩니다.
Experiments
자 그럼 실험 섹션에 대해서 다뤄보도록 하겠습니다. 일단 먼저 알아두셔야 할 점들이 몇가지 있는데, 본 논문에서 사용한 MAE의 경우에는 downstream task에 적용할 backbone network가 아닌, backbone network를 학습시키기 위한 데이터 증강용 모델이므로 너무 무거우면 학습 시간에 많은 영향을 주게 됩니다.
따라서 저자는 기존에 12 layer를 지닌 encoder와 6개의 레이어를 지닌 decoder로 구성된 standard MAE와 달리, 4개의 encoder layer, 2개의 decoder layer로 구성된 augmentation 전용 MAE-mini 모델을 따로 SSL을 진행하였습니다.
이렇게 학습된 MAE-mini를 실제 down-stream task에서 backbone network(본 실험에서는 Resnet-50을 활용한 듯 합니다.)를 학습시키기 위한 데이터 증강용 전처리 모델로 사용하는 것이지요.
Fully-supervised Image Classification
그럼 먼저 가장 대표적인 ImageNet에 대한 정량적 성능부터 살펴보겠습니다.
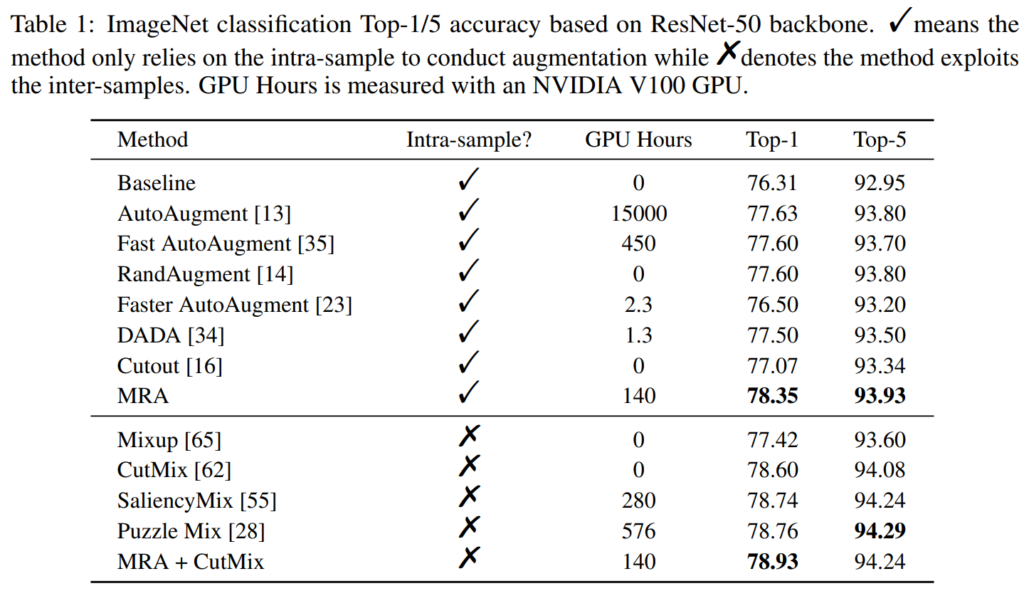
Intra-sample에 체크표시가 되어있는 것은 data augmentation 기법을 적용할 때 이미지 한장에 대해서만 적용하는 것을 의미하며, x 표시가 되어있다면 2개 이상의 영상으로 data augmentation을 수행했다는 것을 의미합니다. 대표적으로 CutMix의 경우에는 A영상과 B영상을 crop해서 섞는 식으로 영상을 증강시키죠.
GPU Hours가 정확히 단위가 무엇인지는 잘 모르겠으나, 결과적으로 GPU Hours가 있는 방법론들은 model based 방법론으로 이해하면 될 것 같습니다. Intra-Sample에 한해서 MRA가 가장 좋은 성능을 보여주고 있으며, Inter-sample의 경우에는 사실 MRA보다 타 방법론들이 Top-1이나 Top-5 모두 더 좋은 성능을 보여주고 있습니다.
그래서 저자는 MRA + CutMix를 적용하였으며 그때 Top-1에서 가장 좋은 성능을 보여주었다고 합니다. 근데 성능 향상 폭이 Puzzle Mix와 비교하였을 때 그리 유의미한 차이가 나지는 않은 듯 보입니다. 대신 GPU Hours가 약 4배 더 빠르다는 점에서 긍정적으로 봐야겠네요.
Semi-supervised Classification
다음은 Semi-supervised classification 관련 실험입니다. Semi-supervised 방법론은 라벨링이 존재하는 스몰 데이터 셋과 라벨이 존재하지 않은 많은 양의 데이터를 함께 학습하는 분야로, 논문에서는 해당 분야의 베이스라인을 Fix-Match를 적용했다고 합니다ㅣ.
Fix-Match는 하나의 영상에 대해 2개의 서로 다른 augmented image를 생성하는데, 이때 한 장의 이미지는 weak augmentation을, 다른 이미지에게는 strong augmentation을 적용해줍니다. 그 다음 두 영상 사이에 일관성을 최대화하는 방향으로 모델을 학습시키는 것이죠. 참고로 FixMatch에서 Strong augmentation을 생성하는데 사용하는 기법은 RandAugment로 정말 다양한 augmentation 종류들이 랜덤하게 적용되는 것을 의미합니다.
논문에서는 제안하는 MRA를 Strong augmentation image를 생성하는데 사용하였으며, STL-10 dataset에서 사용 가능한 labeld sample을 각각 40, 250으로 나누어 실험을 진행하였다고 합니다.
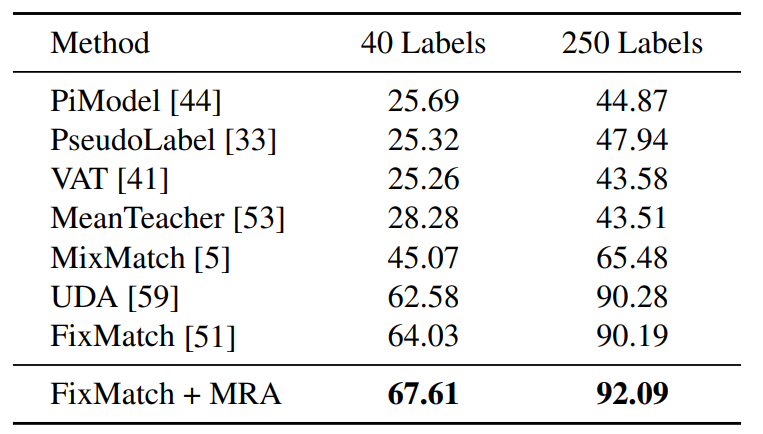
보시면 그냥 FixMatch를 적용했을 때 대비 MRA를 함께 적용하면 꽤나 높은 성능 향상을 달성할 수 있습니다.
Ablation Study
다음은 ablation study에 대해서 다뤄보겠습니다. Ablation study 실험을 위해 Resnet50을 사용해 ImageNet 데이터 셋에서 90에포크를 학습시켰다고 합니다.
Masking Ratio
먼저 해당 실험은 MAE-mini를 pretraining할 때 masking ratio를 몇으로 두는 것이 data augmentator로 활용할 때 가장 좋은 성능을 보이는가에 대한 실험입니다.
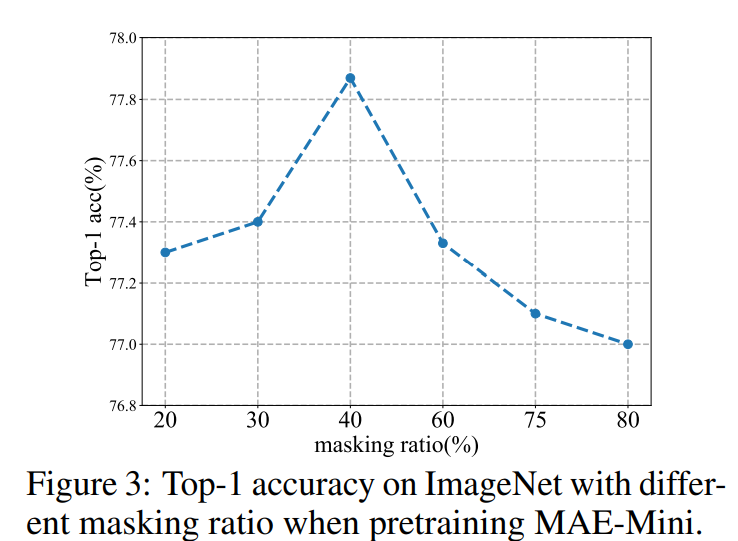
위에 그림3 결과를 살펴보시면 masking ratio를 40%로 하였을 때 가장 좋은 성능을 달성했다고 합니다. standard MAE의 경우에는 75%나 masking을 해야만 좋은 성능을 달성했는데, 네트워크의 크기가 훨씬 작아져서 ratio를 더 낮춰야 효과가 있는 것인지, 아니면 단순히 backbone이 아닌 data augmentator로 활용했기에 이러한 경향성을 보이는 것인지 까지는 논문에서 밝히지는 않았네요.
Model Size
다음은 모델 사이즈에 대한 결과입니다. 논문에서는 최종적으로 MAE-mini 모델을 data augmentator로 활용하고 있지만, 모델의 크기가 실제 standard MAE처럼 ViT-B 혹은 ViT-L일 때 어떤 결과를 보이는지를 보여주는 것이죠.

보시면 MAE-B 혹은 MAE-L의 경우에는 임베딩 차원이 각각 768, 1024로 Mini와 비교하여 더 큰 모습입니다. 하지만 생각보다 Top-1 에러의 경우에는 그리 큰 향상을 보여주지 못하였으며 오히려 메모리 관점이나 데이터 throughput 관점에서 상당히 많은 시간을 차지하는 것을 볼 수 있습니다.
결과적으로는 ratio를 40%로 잡은 MAE-mini가 가장 좋은 Top-1 성능을 보여주는데, 이 결과만 놓고 보면 MAE-B와 MAE-L도 Mask-Ratio에 따라서 Top-1 성능을 더 높게 올려주는 하이퍼 파라미터가 있을 것 같다는 생각이 드네요.
결론
논문의 문제 정의 및 해결을 위한 시도 자체는 좋았던 것 같은데, 생각보다 방법론 및 실험 내용이 단순해서 아쉬운 논문입니다. 어디에 제출했는지는 모르겠지만 지금 리뷰 심사중인 논문인 것 같은데, 방법론이 간단한 만큼 실험적인 측면에서 더 다양한 실험 및 분석을 보여주었으면 하는 아쉬움이 있네요.
리뷰 잘 읽었습니다.
본 논문에선 결국 classification을 수행하는 task이고, image의 object가 위치한 영역을 캐치하기 위해 DINO라는 방법론을 통해 foreground object 영역에 높은 attention값을 부여해서 이를 masking 전략에 사용했다고 이해하였습니다.
두가지 질문이 있는데,
1. classification 이 아닌, segmentation이나 detection으로의 확장은 불가능 할까요? seg,detect 는 cls와는 다르게 object centric한 데이터는 아니지만 object에 대한 정보가 마찬가지로 중요하기 때문에 한 이미지 내 여러 object들에 대한 attention정보를 뽑아내고 이를 활용할 수 있을거 같다는 생각이 들긴 하는데.. 본 논문에서 뭔가 이런 확장성에 대한 언급은 없었나요?
2. Data Augmentation에 대한 근본적인 의문이 있어서 질문 드립니다. DINO를 통해 attention based masking을 진행하는건 알겠는데 왜 attetion이 낮은, background의 확률이 높은 영역을 위주로 masking을 진행하는 것인가요? DA 관련 논문을 잘 안읽어봐서 모르는 것일수도 있는데, cutmix, cutaug 와 같은 이런 DA방법론에선 오히려 object 영역에도 변형을 줌으로써 모델이 여러 상황의 input에 강인하도록 학습을 하는것으로 알고 있는데 본 논문에서는 object일 확률이 낮은 low attention patch를 masking한다고 하여 질문 드립니다.
1. 일단 본 논문에서는 오히려 limitation section에서 본 방법론이 dense prediction(i.e., segmentation)에 적용하기 어렵다는 평을 내놓았습니다. 그 이유는 segmentation의 경우 scean 전체에 대해서 픽셀레벨로 prediction을 수행해야하지만, MAE 특성상 reconstruction된 영상은 high frequency 성분이 많이 손실된 블러한 영상이 생성되기에 object boundary 등에서 prediction이 너무 방해되지 않을까 라는 것이 저자 주장입니다. 물론 실험적으로 보이지는 않았지만, 제가 생각해도 blur한 영상에 대해서 픽셀 레벨의 좋은 prediction을 수행할 수 있을지에 대한 의문이 존재하긴 합니다. object detection은 잘 모르겠네요.
2. 해당 질문에 대한 답변은 1번의 질문에 대한 답변과 연관성이 있어보입니다. 저희가 흔히 사용하는 augmentation은 영상의 색상을 변경하거나, 기하학적인 변환을 하거나, 혹은 cutmix와 같이 두 영상끼리의 합성 및 조합을 많이 활용합니다. 하지만 이러한 증강 기법들은 high frequency 정보를 손상시키지는 않습니다. 물론 가우시안 커널을 적용해서 블러한 영상을 학습하는 증강기법도 있긴 있습니다만, 거의 안쓰는 것으로 저는 알고 있습니다.
아마 본 논문에서 이러한 점을 의식해서, MAE를 통해 object를 reconstruction하였을 때 발생할 수 있는 high frequency 정보의 손실이 모델 학습에 긍정적이지 못한 영향을 줄 것으로 판단한 것 같습니다. 그리고 DINO 모델 기반으로 object에 대한 attention map을 계산하다보니, 사람이 임의로 오브젝트의 30%, 50% 등 특정 비율만큼 가릴 수가 없는 것도 한 몫을 한 것 같습니다.
실제로 cutmix나 cutout은 object에 대해 심하면 절반, 대부분 30%정도의 영역만을 가릴 수 있지만, DINO의 attention map은 object의 거의 대부분을 가려버릴 수도 있기 때문에 모델 입장에서는 무엇을 분류해야하는지 모호해지게 됩니다. 이에 대한 직관적인 그림이 본 논문의 figure2 2번째 행에 있으니 한번 참고해보셔도 좋을 듯 합니다.