안녕하세요. WACV 2023 페이퍼 리스트가 공개되어서 무슨 논문이 있나 슥 둘러보다가 관심가는 논문이 있어서 하나 골라왔습니다. 해당 논문은 video summarization에 대한 논문인데, “Local”정보와 “Global”정보를 함께 이용해서 Background 프레임으로 정의된 관계없는 프레임을 억제하는 관점에서 수행되었습니다. 이러한 컨셉이 좀 읽어볼만해서 한번 읽어봤습니다.
Introduction
리뷰를 몇번 해서 이제 연구실 분들은 이 task에 대해 알고 계실 것이라 생각합니다. 그래서 해당 task에 대한 설명은 넘어가고… video summarization에서 Unsupervised 학습 방식은 diversity와 representativeness 관점에서 학습 목표를 두고 진행되었다고 합니다. diversity는 이제 프레임들 끼리의 표현력의 차이를 이용하여 유사도 관점에서 다르도록 하는 목표이고, representativeness는 원본 비디오의 정보를 잘 담고있는 요약본을 생성하기 위한 목표라고 보시면 됩니다.
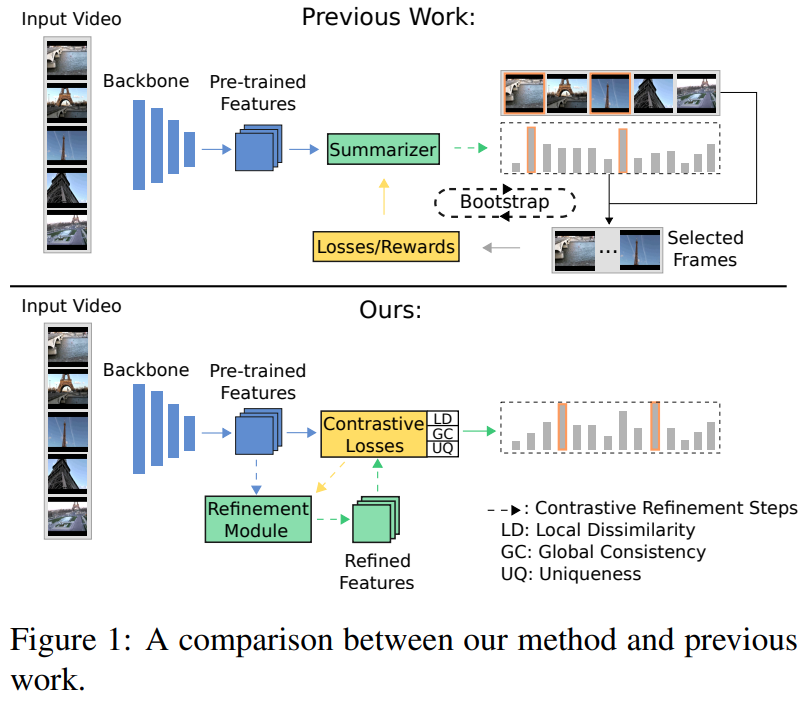
이러한 관점에서 접근하고 있었던 기존의 방식과 이 논문에서 제안하는 방식의 가장 큰 차이점은 “Bootstrap”의 차이라고 합니다. [그림 1]에서 확인할 수 있듯이, 최종 결과물과 loss를 이용하여 모델을 학습하는 방식을 채택하는 것이 이 방식이라고 논문에서는 설명하고 있는데요. 쉽게 설명하면 BCE loss와 같은 loss를 이용해서 해당 프레임이 중요 프레임인지 아닌지를 직접적으로 비교하면서 학습하는 방식이 이 방식이라고 합니다. 논문 저자들은 이 방식이 성능이 좋지 않았고 개선할 방식을 찾아야한다고 제안하면서 local dissimilarity와 global consistency 관점에서 학습을 제안합니다. 이 부분은 “Contrastive learning via alignment and uniformity”에서 소개할 Loss와 연결되는 부분이라 자세한 설명은 뒤에서 하겠습니다.
이 두 학습 목표에 하나의 목표가 더 추가됩니다. 바로 Background frame이라는 개념이 등장하는데요. 이 논문에서는 Background frame들이 서로 다른 비디오에 등장하면서 특별하지 않은 프레임으로 정의하고, 이 프레임들을 제거할 수 있는 unquness filter를 이용해서 이러한 백그라운드를 제거하는 방향으로 학습을 진행합니다. (저희 논문의 DDM과 비슷한 방식입니다.)
Preliminaries
Instance Discrimination via the InfoNCE Loss
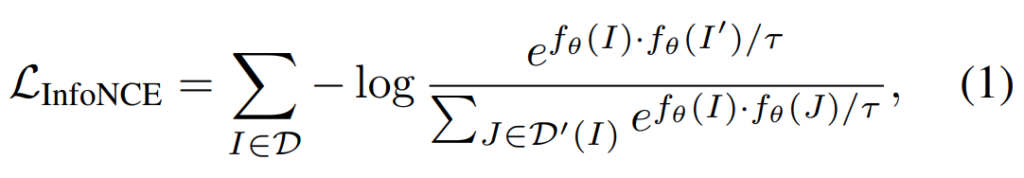
다들 많이 아는 InfoNCE Loss입니다. 이 논문에서도 사용을 하고 있는데요. 이제는 익숙한 수식일 것 같습니다. 이 논문에서는 backbone model을 freeze하고 학습하기 때문에, 이 Loss에서는 f_θ(I_n)으로 정의된 encoder를 학습시키기 위해 사용됩니다. (I는 positive sample, I'는 augmentation이 적용된 positive sample, D'(I)는 negative sample)
Contrastive Learning via Alignment and Uniformity
익숙한 InfoNCE는 빨리 넘어가고… 좀 더 비중이 높은 파트로 넘어갑시다. 해당 논문에서 Contrastive Learning을 수행하기 위해서, ICML 2020에 출간된 “Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere”을 베이스라인으로 사용하고 있습니다. 이 방식의 핵심은 Alignment와 Uniformity 관점에서의 최적화를 수행하는 방식입니다.
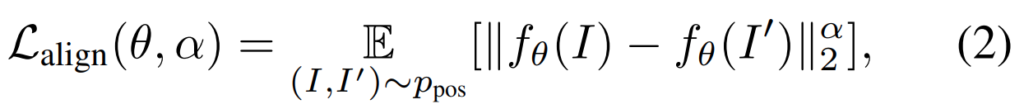
우선 Align Loss를 먼저 확인해봅시다. [수식 2]를 보면 확인할 수 있는데요. Notation은 InfoNCE와 동일합니다. 보면 Positive feature 와 Augmented positive feature distance를 계산해서, 서로 비슷한 표현력을 가지도록 하는 메트릭으로 확인할 수 있습니다.
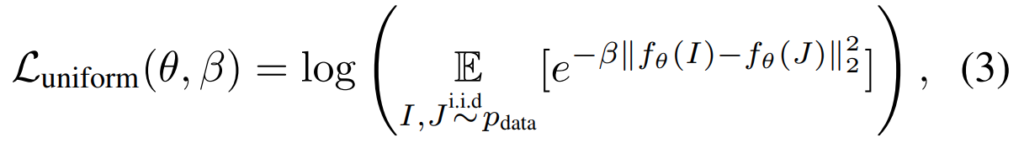
다음으로 Uniform Loss에 대해 봅시다. 이 Loss는 모든 feature들에서 Gausian potention의 평균을 계산하는 것으로 정의됩니다. 수학적인 정의를 찾아봤는데… 이해가 쉽지 않아서 결론만 정리하면 데이터의 분포를 전체 데이터셋에서 계산하여, feature들이 정규적인 분포를 가지도록 하는 metric이라고 하네요.
그래서 Introduction에서 local dissimilarity와 global consistency가 이 Loss와 관계가 있다고 했는데요. 이걸 어떤 관점으로 적용을 했느냐 하면…
- Alignment (→ local dissimilarity)는 semantic하게 유사한 비디오들의 프레임들의 구분력을 학습
- Uniformity (→ global consistency)는 특정 프레임이나 연관된 비디오의 전반적인 느낌이 semantic한 연관 관계가 있는지 학습
을 위해 각각 적용하였습니다. 방향성이 좀 발전된 Contrastive learning이라고 보면 되겠고, 그걸 여기서 적용을 했다. 정도로 생각하면 될 것 같습니다.
Proposed Method
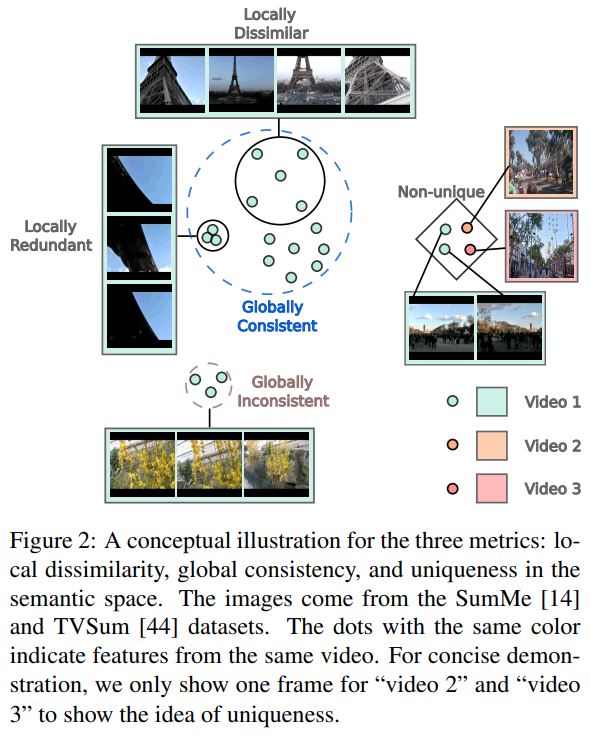
[그림 2]와 같이 이 논문에서는 기존의 방법들과 다르게 projection 하는 encoder만 학습해서 이 논문에서 정의한 3가지 관점(Local dissimilarity/Global consistency/Uniquness)에서 프레임들이 구분력을 가지는 것을 목표로 두었습니다.
Local Dissimilarity
ImageNet으로 학습된 백본 모델에서 deep feature를 추출한 feature를 x_t라고 정의합니다. Local dissimilarity를 정의하기 위해서, 한 비디오 내에서 프레임 간 유사도를 cosine similarity로 계산하여, 가장 유사한 top-K 프레임 셋 N_t를 일단 만듭니다.
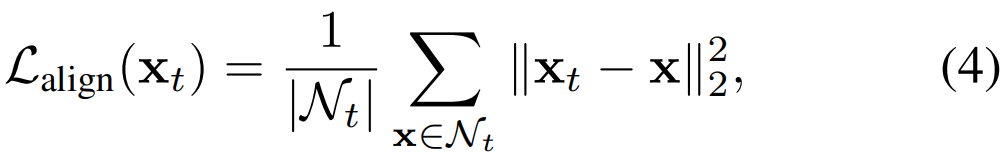
이때 local alignment loss는 [수식 4]와 같이 정의됩니다. t번째 feature와 N_t사이의 차이의 제곱에 L2-normalization을 적용하고 평균을 취해서, 유사한 프레임들끼리 구분력을 학습하는 것을 기대합니다. 이 Loss는 커질수록 이웃 프레임과 유사하지 않게 됩니다. 그래서 비슷한 프레임들끼리 적정 거리를 가지도록 하여, semantic한 정보량의 다양성을 추구합니다.
(사실 왜 적정 거리가 유지되는지는 모르겠습니다. 그림과 수식상으로 보면, 적정 거리 유지와 이 부분은 상관 없는 설명같은데, 잘 모르겠네요.)
Global Consistency
유사한 프레임 셋인 N_t에는 semantic한 관점에서 관계없는 프레임이 포함되어 있을 수 있습니다. 이러한 문제를 해결하기 위해서 비디오의 전반적인 정보(여기서는 분포)와 프레임이 얼마나 연관되어있는지를 측정하는 global consistency metric를 사용합니다.
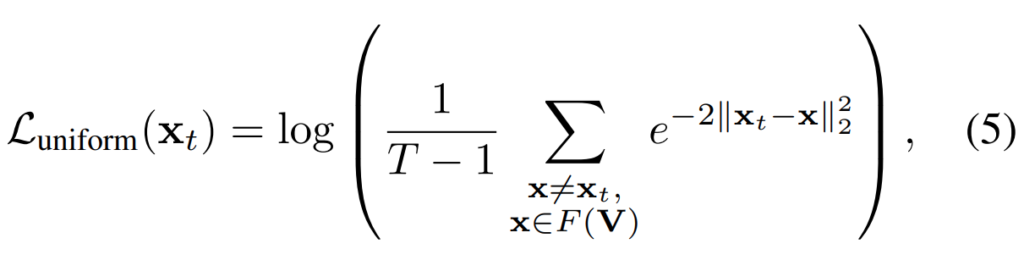
[수식 5]를 통해 확인할 수 있는데요. 조금 달라지기는 했는데, 비디오를 봐야해서 T가 추가됬을 뿐이지 위의 “Preliminaries”에서 설명한 Loss와 동일한 구조입니다. 수식에서 잘 보면 x \not= x_i를 볼 수 있는데요. 특정 프레임과 나머지 프레임들의 유사도를 계산해서, 약간 reconstruction 관점에서 학습이 진행된다고 하는데… 전체 데이터의 분포와 현재 프레임의 분포를 비교하는 연산이라 그렇게 주장하는 것 같습니다.
Contrastive Refinement
[그림 1]을 봤었던 기억을 되살려보면, 이 논문에서는 refinement 과정이 들어가 있습니다. 앞의 수식들이 백본 feature를 바로 사용하는데, freeze 되어 있다는 설명에서 그럼 어딜 학습하는지 의아했을 텐데 그 설명은 여기서 나옵니다. 이 논문에서는 Refinement를 위해서 Transformer Encoder를 사용합니다. (Notation은 z_t=G_θ(x_t)로 정의) 다만, 유사한 프레임 셋으로 정의했었던 N_t는 Transformer Encoder를 태우지 않은 feature를 사용합니다.
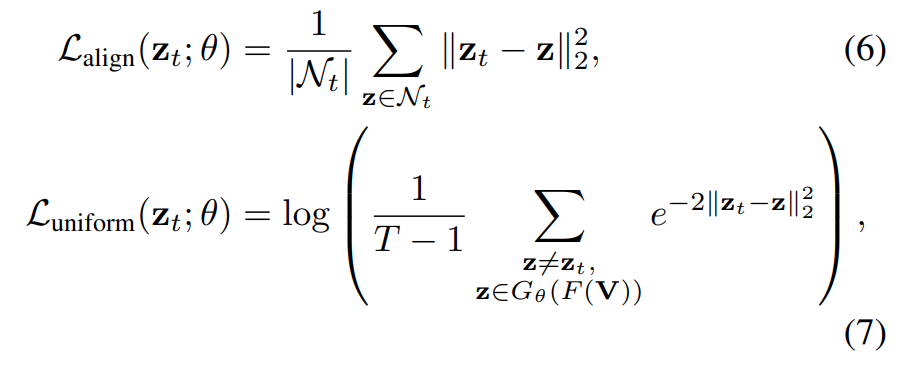
그래서 기존의 Loss Function들에서 x_t가 z_t로 바뀌면 됩니다.
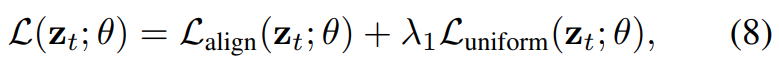
그래서 두 Loss를 [수식 8]과 같이 더해주면 학습 부분은 정리됩니다.
The Uniqueness Filter
여기까지의 학습은 기존 논문의 Loss를 이 Task에 적용한 것에 가까운데요. 이 논문에서는 Filter라는 개념이 추가가 됩니다. 저희 팀에서 논문 쓰는 내용 설명을 들으신 분들은 이 논문의 기나긴 설명을 패스해도 될 정도로 비슷한데요. 요약하면 “비디오의 공통적인 특성을 가진 프레임들을 학습해서 필터링 할 수 있다!”입니다. 비디오의 배경이 될 수 있는 프레임들은 주제와 관계없이 공통적으로 등장하는 프레임들로 정의됩니다. 이 논문에서는 “car accidents, city tours, city parades”와 같은 주제에서 등장하는 도시 전경으로 가득찬 프레임을 예시로 들고있습니다.
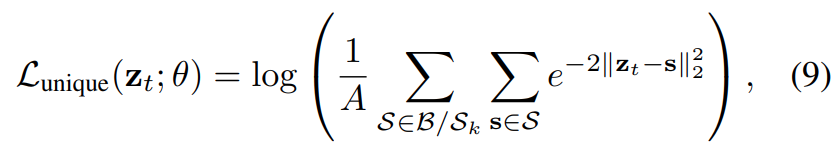
제가 생각했을 때는 모델이 Loss 하나 추가해준다고 학습할 수 있는지 좀 의문이 들지만, 어찌 되었던 이 필터는 [수식 9]를 통해 학습됩니다. 이 부분이 많이 복잡한데, 일단 랜덤한 비디오(B) 내에서 frame-feature들을 동일한 길이로 묶은 뒤에, pooling을 통해 segment feature(S)로 변환합니다. 정리하면 내가 학습하고자 하는 feature z는 결국 랜덤한 비디오의 segment feature와 연산을 수행해서 계산을 합니다. 근데 여기서 쓰는 수식은 위에서도 설명한 수식과 똑같은데 “Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere”에서의 Uniformity 관점의 Loss를 채용한 것입니다. 이걸 또 정리하면 특정 feature와 여러 프레임이 모아진 segment feature간의 분포를 학습하면 이 논문에서 주장하는 흔하게 등장하는 프레임들(논문에서는 semantic한 관점에서 관계없는 프레임)을 이 Loss를 통해 학습시킬 수 있다는 것이 됩니다.
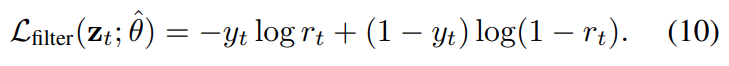
하지만 [수식 9]가 결국은 랜덤한 비디오에서 학습이 되기 때문에, 학습 과정에서 이 수식을 importance score로 바로 변환하는데 약간의 문제점이 있다고 합니다. 따라서 [수식 9]의 출력 값(y_t)에 따라 학습 유무를 결정시킬 필요가 있었는데, 여기서 sigmoid 연산과 비슷하게 작용할 수 있는 [수식 10]의 Cross Entropy Loss를 추가해줬습니다. (importance score로 변환하는 이유 : Summarization의 목표는 프레임마다 이 importance score를 계산해서, 이 score를 보고 요약할 영역을 선택하기 때문)
The Full Loss and Importance Scores
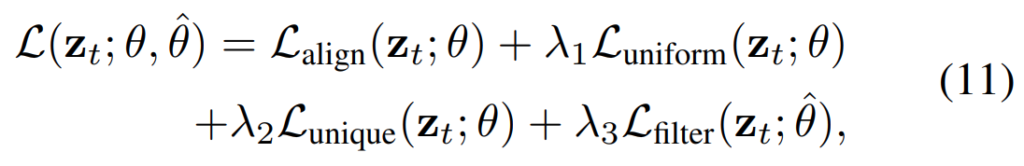
그래서 최종 Loss는 [수식 11]과 같이 계산됩니다.

그리고 importance scores는 [수식 12]와 같이 계산됩니다.
Experiments
이 논문은 특이하게 rank correlation coefficient로 Kendall’s \tau와 Spearman’s \rho 를 평가에서 보여줍니다. 일반적으로는 F1 score를 가지고만 보여주는데, 다른 논문(CVPR 2019 Rethinking the Evaluation of Video Summaries)에서 F1 score가 랜덤으로 생성한 요약본에서도 성능이 높게 나와서 이 부분이 문제라고 판단했고, 이에 새로운 Metric을 같이 제안했는데 그걸 여기서 사용했습니다.
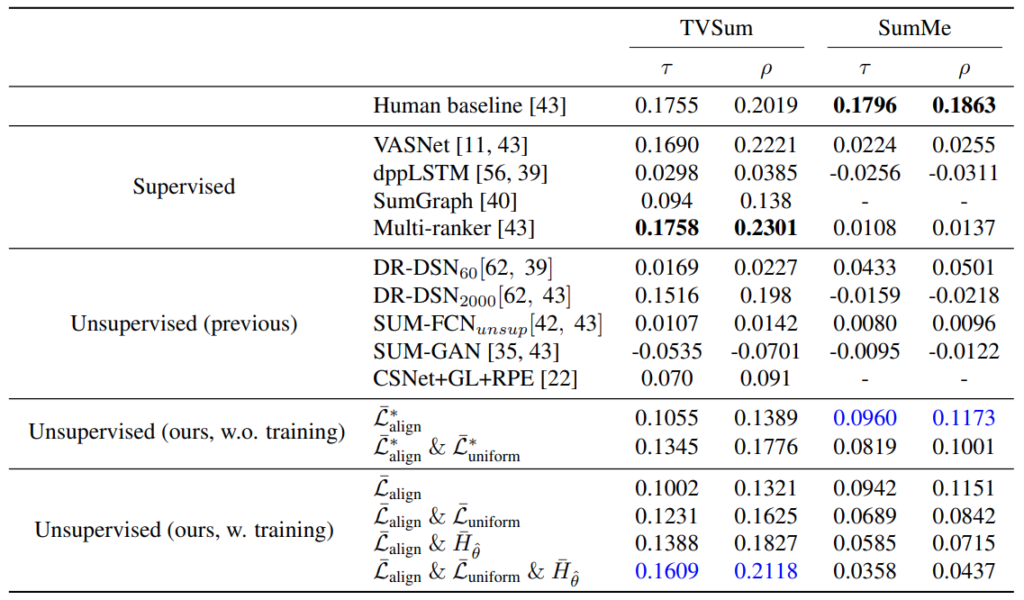
그래서 새로 제안한 평가 방식을 통해 보면 Unsupervised 방법론들 중에서 좋은 성능(높을 수록 좋습니다)을 보이는 것을 확인할 수 있습니다. 특이하게 학습할 경우 SumMe 데이터셋에서 성능이 많이 떨어지는 것을 볼 수 있습니다. 대부분의 논문에서 이 부분을 똑같이 설명하는데, 결국은 학습 데이터셋 (TVSum의 경우 40개, SumMe의 경우 20개)의 부족으로 인해서 학습을 통해 모델이 일반화된 표현력을 학습하기가 어려워서 SumMe에서는 성능이 떨어진다고 지적하고 있습니다.
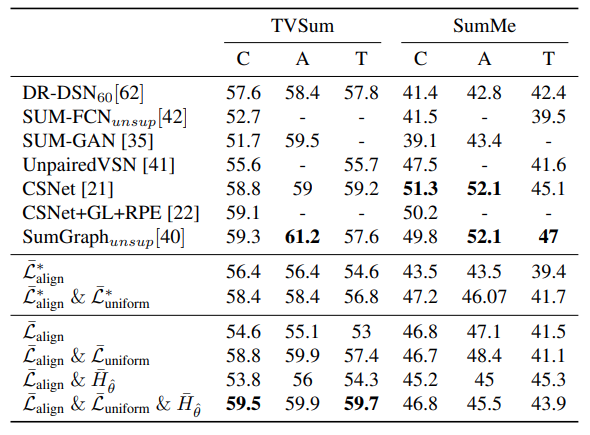
F1 score로 평가한 경향성을 보면, 이 논문 저자들이 제안한 rank correlation coefficient와 살짝 다른 경향성이 나옵니다. Unsupervised에서 성능이 좋기는 한데, SumMe쪽 경향성이 달라진 것을 볼 수 있습니다. 이러한 실험이 F1 score가 평가에 적합하지 않다는 부분을 어느정도 보여주는 부분 같습니다.
그리고 이 두 표가 Ablation의 역할도 같이 수행하고 있는데요. 붙일수록 성능이 오른다는건 당연한 부분일테고… 이 논문에서 제안하는 uniqueness filter(\bar{H}_{\hat{\theta}})가 성능 향상에 영향이 있긴 하지만 데이터셋의 특성에 종속된다는 문제가 있습니다. (SumMe에서는 오히려 성능 떨어짐)
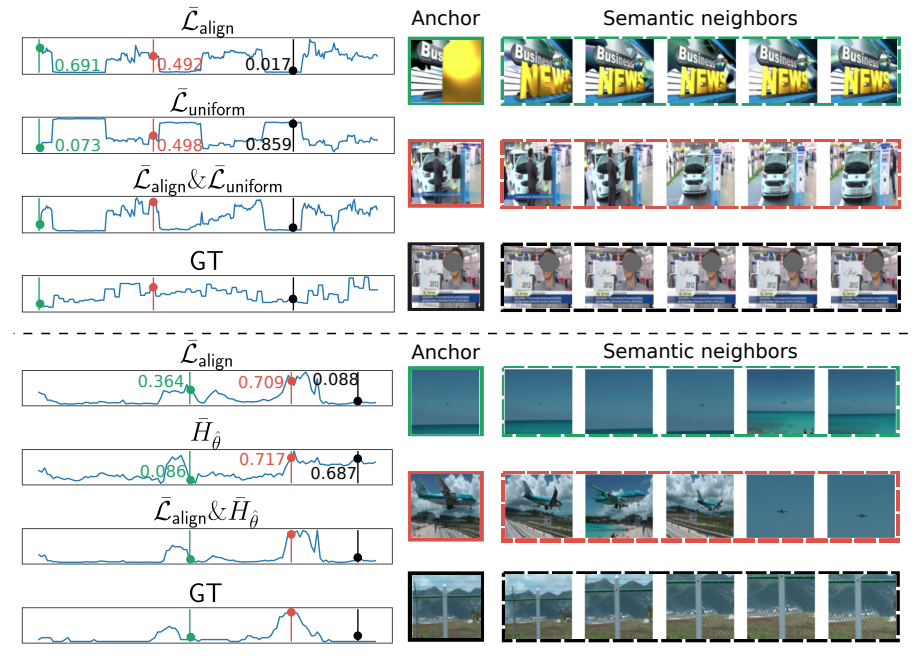
정량적인 결과는 위와 같으니 참고하실 분들이 보면 좋을 것 같습니다.
Conclusion
새로운 Metric을 제안한 것은 매우 좋다고 생각합니다. F1 score의 문제점에 대해서는 충분히 공감했지만… 논문의 핵심 내용은 “Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere”의 Loss를 붙이는 부분이었다고 생각합니다. 정말 제안하는 부분은 uniqueness filter와 관련된 내용인데 아무리 데이터셋이 적다고 해도, 한쪽 데이터셋에서는 성능이 떨어지는데 실험 결과가 이게 맞는지 의문이 드네요.
이광진 연구원님, 좋은 리뷰 감사합니다.
Video summarization에서 F1 score가 어떻게 계산되는지 설명해주실 수 있을까요? F1 score가 어떻게 계산되길래 랜덤에서 좋은 성능을 보이는지 궁금합니다.
F1 score 자체는 아실것 같고, 여기서 랜덤에서 성능이 좋아지는 이유는 얼마나 겹쳤는지를 보지 않기 때문입니다. 요약이다보니 특정 세그먼트와 일치하는지를 확인하는데, 1프레임만 겹쳐도 맞춘걸로 됩니다. (Video localization task에서도 F1 score를 쓰는데 동일한 문제가 있습니다.)