오늘의 X-Review도 마찬가지로 Self-supervised Video Representation Learning(SSVRL) 논문으로 준비했습니다. 논문의 제목은 Self-supervised Co-training for Video Representation Learning이고, 2020년도 NeurIPS에 게재된 논문입니다.
작년 10월 경 이광진 연구원님께서 해당 논문에 대한 리뷰를 작성하셨지만, 본 논문의 RGB와 optical flow 상호 활용법이 추후 Action 데이터셋에 효과적으로 응용될 수 있겠다는 생각이 들어 다시 한 번 정리하려고 합니다.

이전 리뷰에서도 적었지만 SSVRL은 아무 라벨 없이 비디오를 잘 표현해주는 feature를 추출하는 것에 목적이 있습니다. 저자들이 제안하는 방법론으로 학습시켜 표현력 좋은 feature를 추출하고, 해당 feature를 이용해 video recognition, video retrieval을 down-stream task로 수행하여 feature의 표현력을 평가하는 형태입니다.
논문의 전체 흐름에 대해 간략히 설명드리겠습니다.
먼저 저자는 그 당시까지의 SSVRL 연구들이 가지고 있던 문제점을 하나 지적합니다. 그리고 해당 문제점이 완전히 극복되었을 때 성능의 상한선(oracle 성능)은 어디인지 보여준 후, 자신들이 그 문제를 어떻게 해결하고자 했는지와 그 해결법이 어느정도 oracle 성능에 가까워졌음을 보여주며 마무리됩니다.
그럼 본격적으로 논문을 살펴보겠습니다.
1. Introduction
최근까지도 어느 도메인이든 data sample 간의 구별력을 학습하기 위해서 InfoNCE loss는 빠지지 않고 사용됩니다. 2020년도 이후부터 다양한 self-supervised 방법론들이 나왔지만, 그 중 기본적인 형태는 제가 아는 한에서 아래와 같다고 생각합니다.
각 train sample을 하나의 클래스로 보고 인위적인 augmentation을 적용하여 positive로, 다른 train sample과 그의 augmentation은 negative set으로 두고 InfoNCE loss를 통한 instance-based representation learning을 수행합니다. 또 augmentation을 적용한 sample들에 대해서는 어떤 augmentation을 적용했는지 알고 있으므로 그를 label로 두고 CE Loss를 통해 pretext task(instance discrimination)를 수행하기도 합니다.
결국 라벨이 없는 상황 속 위와 같은 방식에서의 가장 핵심은, 현재 sample에 대한 positive와 negative set을 무엇을 기준으로 어떻게 정해주느냐 일 것입니다. 왜냐하면 현재 sample에 대해 positive, negative로 지정된 sample들은 더 따질 것 없이 유사도를 각각 높이거나 낮추기 때문입니다.
여기서 저자가 하나의 질문을 제기합니다.
“ Is instance discrimination making the best use of data? “
Instance discrimination은 InfoNCE loss를 이용한 feature representation 학습을 의미하는데, 저자의 질문은 결국 앞서 핵심이라고 언급한 positive, negative sampling 방식을 좀 더 최적으로 만들 수 없을까에 대한 고민을 담고 있는 것입니다. 질문에 대해 저자는 no라고 대답하고 있고, 답변에 대한 이유를 아래와 같이 밝히고 있습니다.
지금까지의 연구는 Instance discrimination 과정에서 hard negative를 어떻게 구성할 것인지에만 집중하며 hard positive 구성의 중요성을 간과하고 있었다고 주장합니다. 보통 하나의 비디오를 하나의 클래스로 두고 학습하기 때문에 semantic level에서 유사한 두 비디오의 feature도 negative로 지정되며 서로 멀어지게 된다는 단점이 생기는 것입니다.
그렇다면 만약 저자가 주장하는 단점을 보완하기 위해 비디오의 의미론적인 정보를 파악함으로써 시각적으로는 다르지만 가까워져야 할 비디오를 찾아내어 positive로 지정해줄 수 있다면 얼마나 성능이 올라갈까요?
논문에서는 위 맥락 속 가장 이상적인 상황에서의 성능(oracle)을 보여주기 위해 UberNCE를 도입합니다. Fully-supervised 관점에서 비디오들의 실제 클래스 라벨을 모두 가진 채로 positive, negative를 지정해준 후 representation learning을 수행하는 UberNCE loss(oracle)의 성능을 보겠다는 것입니다. 자세한 내용에 대해서는 뒤에서 다시 살펴보도록 하겠습니다. 참고로 uber는 ‘최고의, 최대의’ 라는 뜻을 가지고 있다고 합니다.
일단 UberNCE 방식의 성능은 당연히 supervised 기반이기 때문에 기존 self-supervised의 InfoNCE 방식보다 좋을 수 밖에 없을 것입니다. 여기서 본 논문의 목표는 저자가 제안하는 학습 방식 CoCLR(Co-training Contrastive Learning of visual Representation)를 통해 기존 InfoNCE 방식과 UberNCE 방식의 성능 차이를 좁히는 것입니다.
이제 핵심적으로 보아야 할 것은 CoCLR인데, 우선 CoCLR의 목표를 다시 생각해보겠습니다. 제가 지금까지 말씀드린 내용을 모두 종합해보면, CoCLR의 목표는 self-supervised 상황에서 대부분의 연구가 간과하고 있는 hard positive들을 마치 fully-supervised 상황인 것처럼 최대한 이상적으로 샘플링 해내는 것으로 정리할 수 있습니다. 이 목표를 이루기 위해서는 저희가 마치 self-supervised 상황에서 pretext task를 수행하기 위해 데이터 자체로부터 ‘free-label’을 얻어 학습에 사용하듯, 좋은 hard positive임을 알아볼 기준이 되어줄 무언가가 필요할 것입니다.
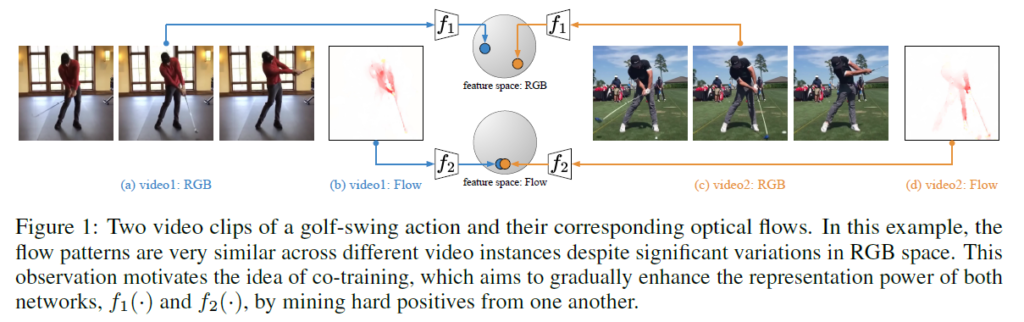
저자는 이 때 그 ‘무언가’로 other complementary views of the data를 사용한다고 하고, 결국 이는 비디오의 RGB frame과 그에 상응하는 optical flow를 의미합니다. 그림 1을 통해 CoCLR의 mining 방식을 알 수 있습니다. 왼쪽과 오른쪽 비디오 모두 ‘GolfSwing’ 이라는 action을 담은 비디오입니다. SSVRL의 목표는 두 비디오에 대한 feature가 유사해져야 하는 것인데 RGB space에서의 feature는 서로 멀리 떨어져 있는 것을 볼 수 있습니다. 하지만 flow space에서의 feature들은 서로 유사합니다.
CoCLR는 위 특징을 이용해 RGB frame feature에 대한 representation learning을 수행할 때 optical flow feature를 기준으로 positive set을 정하고, 반대로 optical flow feature에 대한 representation learning을 수행할 때는 RGB frame feature을 기준으로 positive set을 정해줍니다. 그러면 실제로 유사한 샘플들이 기존 InfoNCE에서는 negative로 들어가 멀어졌었다면 이제는 positive로 지정되어 가까워질 수 있게 되는 것입니다.
저자가 이야기하는 논문의 contribution은 아래와 같습니다.
- We show than an oracle with access to semantic class labels improves the performance of instance-based contrastive learning. (UberNCE)
- We propose a novel self-supervised co-training scheme, CoCLR, to improve the training regime of the popular InfoNCE, exploiting the complementary information from different view of the same data source.
- We thoroughly evaluate the quality of the learnt representation on video action recognition and retrieval, on UCF101 and HMDB51; SOTA or comparable performance over other self-supervised approaches.
지금부터 방법론에 대해 자세히 알아보겠습니다.
2. InfoNCE, UberNCE, CoCLR
앞서 세 가지 모두 무엇인지에 대해서는 설명드렸기 때문에 수식을 중점으로 하나씩 알아보겠습니다.
2.1 Learning with InfoNCE and UberNCE
InfoNCE
N개의 비디오로 이루어진 데이터셋 \mathcal{D} = \{x_{1}, x_{2}, \cdots{}, x_{N}\}가 있을 때, SSVRL의 목표는 action recognition이나 video retrieval 같은 downstream task를 위해 좋은 feature를 추출해줄 모델 f(\cdot{})를 얻는 것입니다.
앞서 설명드렸듯 기본적으로 현재 sample에 augmentation function \psi{(\cdot{};a)} (a는 여러 개의 augmentation transform A 중 하나)를 \mathcal{D}에 적용합니다. 이후 하나의 비디오 샘플 x_{i}에 대한 positive set \mathcal{P}, negative set \mathcal{N}은 아래와 같습니다.
- \mathcal{P}_{i} = \{\psi{(x_{i};a)}|a \sim{} A\}
- \mathcal{N}_{i} = \{\psi{(x_{n};a)}|\forall{} n \ne{} i, a \sim{} A\}
그리고 현재 sample x_{i}에 대해 z_{i} = f(\psi{(x_{i};\cdot{})})를 얻고 InfoNCE loss를 통해 아래와 같이 representation learning을 수행하였습니다.
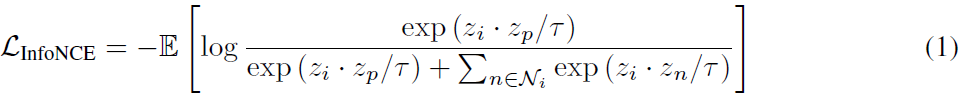
현재 sample에 augmentation을 적용하여 얻은 positive와는 유사도를 크게, 다른 sample에 augmentation을 적용하여 얻은 negative와는 유사도를 작게 만드는 방향으로 학습합니다.
UberNCE
InfoNCE 방식이 데이터를 제대로 사용하고 있지 못함을 증명하기 위해 이상적인 상황에서의 성능을 보고자 저자는 UberNCE를 소개합니다. 데이터셋 \mathcal{D} = \{(x_{1}, y_{1}, (x_{2}, y_{2}), \cdots{}, (x_{N}, y_{N})\}으로 이루어져 있고 y_{i}는 x_{i}의 클래스 라벨입니다. 이제는 실제 라벨을 가지고 있으니 InfoNCE에서와는 다른 방식으로 \mathcal{P}, \mathcal{N}을 지정해주겠죠.
- \mathcal{P}_{i} = \{\psi{(x_{i};a)}, x_{p}|y_{p} = y_{i}\:and\:p \ne i, \forall{}p \in{} [1, N], a \sim{} A\}
- \mathcal{N}_{i} = \{\psi{(x_{n};a)}, x_{n}|y_{n} \ne y_{i}, \forall{} n \in [1, N], a \sim{} A\}
수식을 보면 \mathcal{P}는 x_{i}와 같은 클래스에 속하는 모든 샘플들과 자신의 augmentation을 포함하고 있고, \mathcal{N}은 x_{i}와 다른 클래스에 속하는 샘플들과 그들의 augmentation을 포함하고 있습니다.
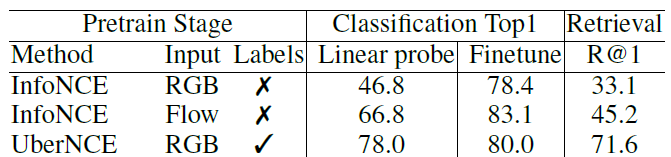
위와 같이 \mathcal{P}, \mathcal{N} 구성만 달라지고 나머지는 모두 동일한 상태에서 downstream task 성능을 측정했을 때, 표 1을 보시면 UberNCE 성능이 같은 input의 InfoNCE 성능을 크게 능가하는 것을 알 수 있습니다. 결과를 통해 “ Is instance discrimination making the best use of data? “ 라는 질문에 대해 저자의 대답이 옳았음이 증명된다고 볼 수 있습니다.
2.2 Self-supervised CoCLR
2.1에서 InfoNCE가 극복해야 할 문제점이 충분히 정의되었으니, 드디어 CoCLR에 대해 자세히 알아보겠습니다. 하나의 비디오 클립 \mathbf{x}_{i} = \{x_{1i}, x_{2i}\}가 있을 때 x_{1i}, x_{2i}는 각각 RGB frame과 optical flow를 의미합니다. 모달이 2개이므로 학습할 모델도 f_{1}(\cdot{}), f_{2}(\cdot{})로 2개입니다. Representation learning을 위한 최종 embedding은 z_{1i} = f(x_{1i}), z_{2i} = f(x_{2i})입니다. 그럼 이제 CoCLR의 \mathcal{P}, \mathcal{N} 샘플링 방식을 순서대로 살펴보겠습니다.
RGB frame만을 이용해 \mathcal{P}를 샘플링하는 것은 어렵습니다. 의미론적으로 유사한 비디오의 RGB frame feature가 서로 비슷해야 하는데, 애초에 이들끼리 비슷하도록 만드는 것이 SSVRL 연구의 궁극적인 목적이기 때문입니다.
비디오가 의미론적으로 비슷하다는 것은 아무래도 비디오 내에서 진행되고 있는 action이나 contents가 유사하다는 것으로 이해할 수 있습니다. 조금 더 action 비디오에 맞춰 설명하자면, 배경이 정적인 static camera setting 하에서 시각적으로는 다르되 같은 동작을 수행하는 두 비디오가 존재한다면 그 둘의 optical flow feature는 유사하게 추출될 것입니다. 이런 특정 상황에서만큼은 RGB frame으로는 찾을 수 없었던 hard positive 샘플을 optical flow를 통해 상대적으로 쉽게 찾을 수 있다는 것이 저자의 주장입니다. 그리고 학습 시작 직후 f_{2}(\cdot{})로부터 RGB frame의 \mathcal{P}를 샘플링하는 것은 불안정하기 때문에 InfoNCE로 어느정도 학습을 진행한 후 샘플링을 수행한다고 합니다.
f_{1}, f_{2}가 처음에는 각각 InfoNCE 방식으로 어느 정도 학습하게 되고, 이후 f_{1} 먼저 학습이 시작됩니다. f_{2}가 뽑아내는 optical flow feature를 참고하여 f_{1} 학습에 사용할 \mathcal{P_{1i}}를 구성하게 되는 것입니다.
- \mathcal{P}_{1i} = \{\psi{(x_{1i};a)}, x_{1k}|k \in{} topK(z_{2i} \cdot{} z_{2j}, \forall{}j \in{} [1, N], a \sim{} A\}
- \mathcal{N}_{1i} = \overline{\mathcal{P}_{1i}}
수식을 보면 모든 clip의 optical flow feature 중 현재 샘플의 optical flow feature와 비교했을 때 유사도가 가장 높은 k개의 clip에 대한 RGB frame feature가 \mathcal{P}_{1i}를 구성함을 알 수 있습니다. \mathcal{N}_{1i}는 단순히 \mathcal{P}_{1i}의 여집합으로 이루어집니다.
RGB feature representation을 학습하는 f_{1}에 대한 Multi-Instance InfoNCE loss \mathcal{L}_{1}은 아래 수식과 같습니다.
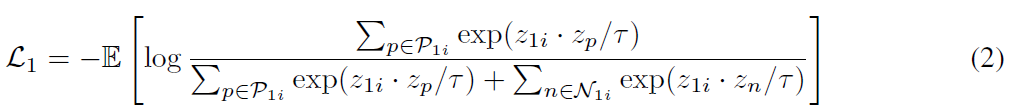
이제 CoCLR training set 구성이 끝났고 \mathcal{L}_{1}의 학습 방향은 InfoNCE와 같겠죠.
Optical flow feature representation을 학습하는 f_{2}에 대한 Multi-Instance InfoNCE loss \mathcal{L}_{2}와 \mathcal{P_{2i}}는 정확히 RGB와 optical flow가 뒤바뀌어 진행됩니다.
- \mathcal{P}_{2i} = \{\psi{(x_{2i};a)}, x_{2k}|k \in{} topK(z_{1i} \cdot{} z_{1j}, \forall{}j \in{} [1, N], a \sim{} A\}
- \mathcal{N}_{2i} = \overline{\mathcal{P}_{2i}}
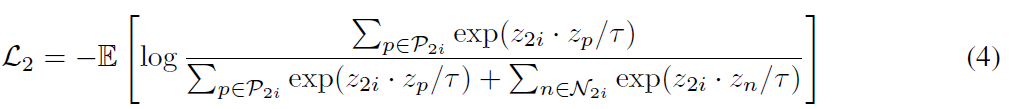
The CoCLR algorithm
이제 위 내용을 바탕으로 실제 학습 과정이 어떻게 되는지 살펴본 뒤 실험 결과 부분으로 넘어가겠습니다.
앞서 f_{1}(\cdot{}), f_{2}(\cdot{})가 초반에는 각자 InfoNCE loss로 학습된 후 서로의 \mathcal{P_{1i}}, \mathcal{P_{2i}}를 구성하는데 관여한다고 말씀드렸었습니다.
저자는 초반에 각자 \mathcal{L}_{InfoNCE}(식 1)로 학습되는 부분을 ‘initialization’, 이후 \mathcal{L}_{1}(식 2), \mathcal{L}_{2}(식 3)를 번갈아가며 학습하는 부분을 ‘alternation’이라고 칭합니다.
Initialization 과정을 마친 f_{1}(\cdot{}), f_{2}(\cdot{})는 랜덤 초기화 된 모델보다는 각 모달에 대해 강한 표현력을 갖고 있을 것입니다. 그렇기에 alternation 단계에서 서로에게 더 좋은 hard positive K개를 전달해줄 수 있게 되고, 이렇게 학습된 하나의 모델이 또 다른 모델에게 더욱 뚜렷한 hard positive를 제공해주게 되는 것입니다.
이 과정에서 과연 몇 개의 hard positive를 찾아 사용할 것인지와 서로를 몇 번 번갈아가며 학습할지도 중요한데요, 저자는 실험을 통해 K=5이면서, 많이 번갈아가며 학습할 수록 성능이 최적에 해당했다고 밝히고 있습니다. 이는 아래에서 더 자세히 알아보겠습니다.
3. Experiments
기본적인 실험 구성이나 방식은 이전 저의 SSVRL 리뷰에서와 동일하고, 당시 자세히 서술하였기 때문에 궁금하신 분들은 이전 리뷰 또는 본 논문을 참고해주시면 감사드리겠습니다.
Initialization 단계에서, 첫 300에포크는 L_{InfoNCE}를 이용해 각자 학습합니다. 이 때 MoCo의 history queue를 차용해 학습에 사용한다고 합니다. 이후 alternation 단계에서는 데이터셋마다 다르지만 UCF101의 경우 \mathcal{L}_{1} 100에포크, \mathcal{L}_{2} 100에포크 순서대로 학습하게 됩니다.
3.1 Model comparisons on UCF101
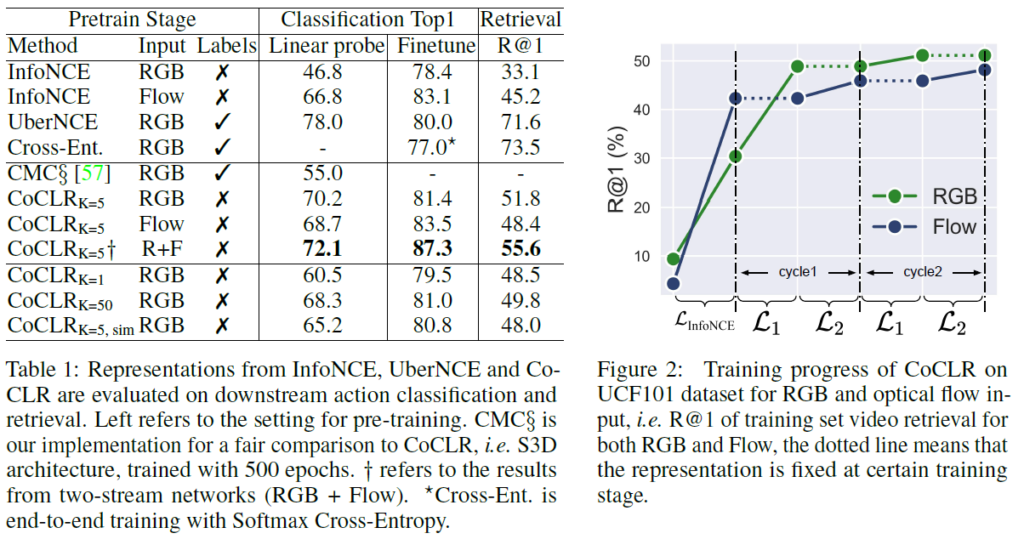
왼쪽 표는 하이퍼파라미터에 대한 ablation study입니다. UCF101 데이터셋으로 pretrain 후 action classification과 retrieval을 수행한 성능입니다. UberNCE 성능은 이상적으로 오를 수 있는 상한선을 보여주고 있습니다. 왼쪽 표의 두 번째 블록은 학습은 방법론 특성 상 RGB+flow로 하되 inference 시 input에 따른 성능 차이를 보여주고 있습니다. RGB만 평가에 사용하는 경우 InfoNCE는 Linear probe에서의 성능이 46.8%, UberNCE는 78.0%인데 제안하는 CoCLR의 경우 UberNCE 성능에 가까운 70.2%로 크게 향상되었음을 알 수 있었습니다. 또한 몇 개의 hard positive를 mining할 것인지에 따른 성능도 리포팅하고 있습니다.
오른쪽 그림은 학습 중 initialization과 alternation 과정을 거치며 성능이 어떻게 향상되는지 나타내고 있습니다. Cycle1의 \mathcal{L}_{1} 구간에서 f_{2}는 freeze 된 채로 hard positive mining에 관여하는 것입니다. 왼쪽 표에서 CoCLR_{K=5, sim} 성능은 위와 같은 alternation 과정 없이 두 네트워크가 동시에 학습되는 것인데 오히려 성능이 조금 하락하는 것을 알 수 있습니다. 그 이유로는 동시에 학습할 경우 네트워크의 가중치가 너무 빨리 수렴해버리기 때문이라고 합니다. 결국 이를 통해 저자가 제안하는 alternation 과정이 더욱 효과적임을 알 수 있었습니다.
3.2 Comparison with the state-of-the-art
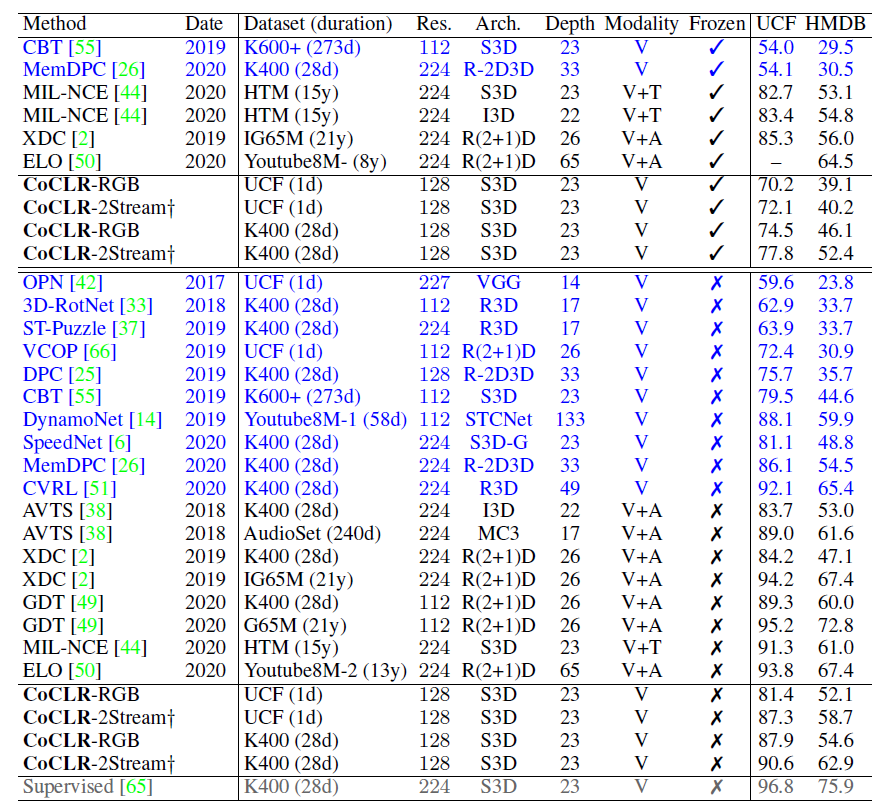
다음은 Action classification task에서의 벤치마크 성능입니다. 파란 글씨의 방법론들이 CoCLR와 마찬가지로 비디오의 visual representation만 학습에 사용하는 것들입니다. Backbone을 제외하고 같은 조건 내에서 CVRL이라는 방법론만이 CoCLR보다 높은 성능을 보여주고 있습니다. CVRL(Spatiotemporal Contrastive Video Representation Learning)은 21년도 CVPR논문으로 여러 X-Review가 이미 존재하니 궁금하신분들은 찾아보시는 것도 좋을 것 같습니다. 하지만 backbone 인코더의 depth 차이가 크게 나서 같은 backbone으로 비교하였을 때 어떤 방법론의 성능이 더 높을지 궁금하네요.
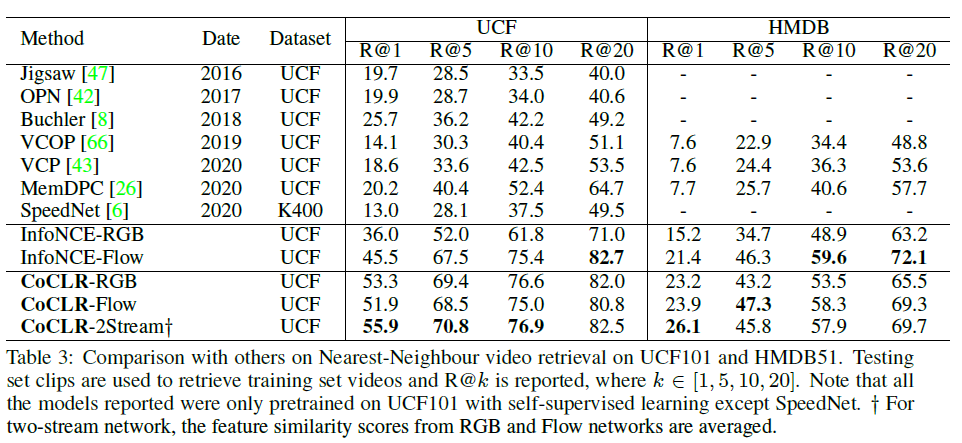
다음은 Video retrieval task에서의 벤치마크 성능입니다. 과거 방법론들에 비해 CoCLR가 확실히 높은 성능을 기록하고 있지만 과거 방법론들은 InfoNCE 기반의 representation learning이 아닙니다. 따라서 InfoNCE 성능과 비교하는 것이 더 합리적인 것으로 보이는데, 앞서와 마찬가지로 각 input에 대해 크게 성능이 향상된 것을 알 수 있습니다.
3.3 Qualitative results for video retrieval

마지막으로 정성적 결과입니다. 원래는 논문을 읽을 때 정성적인 결과에 엄청나게 큰 의의를 두지 않았었는데, CoCLR가 결국 시각적으로는 매우 달라도 의미론적으로 유사한 비디오들을 잘 retrieve 한다는 점이 인상깊어 포함하였습니다. 특히 PoleVault나 Fencing의 경우 시각적으로는 달라보여서 원래라면 찾아내기 힘들었겠지만 CoCLR의 mining 전략을 통해 의미론적으로 유사한 비디오들을 잘 찾아내었다는 점이 유의미하다고 생각합니다.
RGB와 optical flow 정보의 특성을 잘 파악하여 활용한 논문이라고 생각하지만, 사실 optical flow로는 패턴을 잡아내기 힘든 콘텐츠 기반의 비디오에서도 효과적으로 동작할지는 의문이 듭니다. 위와 같은 한계점은 있겠지만 어쨌든 action을 포함하는 비디오를 다루는 action localization task 쪽에 앞으로 계속 관심을 가질 저에게는 또 하나의 통찰력을 주는 논문이었습니다.
리뷰 마치겠습니다.
감사합니다.
좋은 리뷰 감사합니다!
혹시 마지막 exeriments부분에서 성능 비교를 할 때 UCF와 HMDB benchmark로 비교한 부분에서 두 데이터셋에서 전체적으로 성능차이가 큰 것 같은데 데이터셋의 어떤 특성때문에 이런 차이가 발생하는 건가요?
먼저 HMDB는 UCF 데이터셋에 비해 규모가 작습니다. 그래서 retrieval benchmark 표를 보시면 규모가 큰 UCF의 학습 데이터로 사전학습 한 후 UCF와 HMDB에서 평가하고 있는 것을 볼 수 있습니다. 이는 아무래도 같은 UCF 데이터셋으로 학습하고 평가했기 때문에 HMDB의 성능이 UCF의 성능보다 높다는 것이 어느정도 설명 가능합니다.
하지만 action classification 벤치마크에서 더 큰 데이터셋인 K-400으로 사전학습 한 경우에도 HMDB의 성능이 상대적으로 더 낮은 것을 볼 수 있는데, 이는 두 데이터셋의 클래스 자체 범위가 조금 다르기 때문이라고 생각합니다.
K-400과 UCF 클래스: Apply Eye Makeup, Golf Swing, Walking with a dog 등
HMDB 클래스: drink, eat, jump, catch 등
위와 같이 HMDB 데이터셋은 상대적으로 클래스가 포괄적인 범주로 나뉘어져 있어 모델이 특정한 spatio-temporal 정보를 확실히 잡아내기에 어렵기 때문에 낮은 성능이 나오는 것으로 생각됩니다.
좋은 리뷰 감사합니다.
flow feature를 가지고 contrastive learning을 하는 새로운 방법을 제안한만큼 optical flow 방법론을 다양하게 변화시켜 진행한 ablation은 혹시 있을까요? 아마 benchmarking에는 논문 연구에서 주로 사용하는 TVL1을 사용했을 거 같은데 flow 알고리즘에 따른 성능 변화도 궁금해져서 질문드립니다.
말씀하신대로 실험은 TV-L1 알고리즘의 optical flow로 수행되었습니다.
제가 리뷰에 담은 실험이 논문에 언급되어 있는 모든 실험이라 따로 optical flow 방법론에 따른 성능은 없었고, 저자가 제공하는 추가 슬라이드 자료에도 해당 실험은 찾아볼 수 없었습니다.
감사합니다.