
그동안 Hybrid Learning (Self-supervised Learning + Active Learning) 연구에 집중해서 리뷰를 했다면, 이번에는 다시 Active Learning 논문을 리뷰하려고 합니다. 해당 논문은 Active Learning에서는 크게 다루지 않는 케이스인 “Unlabeled data 중 Unseen class가 존재하는 경우 즉 Class Distribution Mismatch“ 에서의 데이터 가치 판단을 진행한 논문입니다. 이를 위해서 semantic 한 정보를 고려하여 가치 판단을 진행하였다고 합니다. 저는 데이터의 Semantic 한 something을 어떻게 고려하였는 지와 같은 인사이트를 얻고자 읽어보게 되었습니다. 리뷰 시작해보겠습니다.
Contrastive Coding for Active Learning under Class Distribution Mismatch
Introduction
우선, 해당 논문의 제목에서도 알 수 있듯, 이 논문은 Class Distribution Mismatch 상황에서의 Active Learning 문제를 풀고자 하였습니다. 즉, 기존 AL 이 풀고자하는 상황보다 약간 더 복잡한 경우라고 할 수 있습니다. 기존 논문은 Labeled dataset의 클래스와 Unlabaled dataset의 클래스가 동일하다는 가정하에 문제를 풀고 있습니다. 그러나 실제 시나리오에서 이런 가정이 정상적으로 작동하는 것은 제법 어렵습니다. 가령 아래 이미지와 같이 “현재 가지고 있는 라벨을 알고 있는 데이터가 강아지 고양이로만 이루어져 있는 상황에서” 추가 크롤링을 진행했을 때 꽃이나 사슴과 같은 다른 unseen 클래스가 존재하는 것은 어찌보면 당연합니다. 물론 아직 Active Learning이 워낙 선도적인 분야라 대부분의 논문이 Unlabeled 와 labeled 의 클래스가 동일하다는 전제를 깔아두고 가치있는 데이터를 선별하는 연구가 집중되고 있긴 합니다.
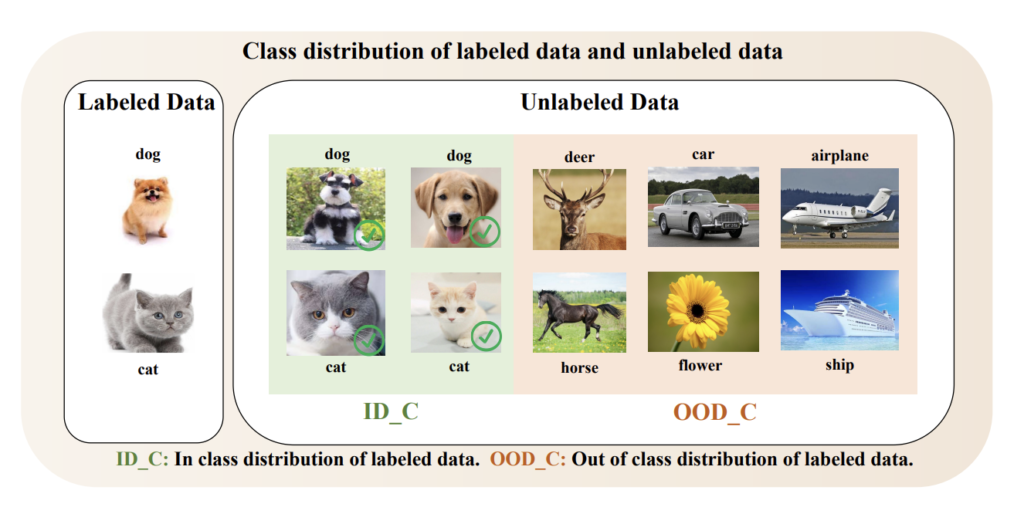
그런데 저자는 나아가서 이런 클래스 분포 불일치 상황에서 기존 연구와 같이 정보량이 많은 데이터를 고르려고 하면, Out-of-Distribution(이하 OOD)의 데이터가 다수로 선별되어 오히려 타겟 모델 성능에는 드랍으로 이어질 수 있음을 지적합니다. 즉, Class Distribution Mismatch 이라는 상황에는 그에 적합한 새로운 데이터 선별 방식이 진행되어야 합니다.
따라서 저자는 데이터 선별 시 데이터의 semantic과 distinct 한 특징을 모두 고려하기 위한 새로운 학습 모델인 CCAL을 제안하였습니다. 모델이 데이터의 semantic한 피처를 파악함으로써 OOD 데이터 쿼리를 필터링하고, distinct (구별되는 -> 정보량이 많은) 한 것을 고려하면서 정보량이 많은 데이터를 동시에 고려할 수 있도록 말이죠. 위의 이미지로 예를 들어본다면 deer, car, airplane은 OOD 임으로 semantic한 정보를 통해 invalid query error가 증가될 것입니다. 기존에 가지고 있던 클래스 외의 데이터로 이 데이터가 라벨링되도록 쿼리될 경우 유효하지 않은 쿼리라고 판단합니다. 반면 이  고양이는 기존에 가지고 있는 이
고양이는 기존에 가지고 있는 이  회색 고양이와 비슷하죠? 이런 고양이는 정보량이 적다고 판단합니다. 왜냐 이미 가지고 있는 데이터와 유사하니 성능 향상에는 큰 폭으로 도움이 되지 않을 수도 있기 때문이죠 (물론 모델마다 다릅니다 이해를 위한 설명입니다) 따라서 회색 고양이에 대해서는 valid query error가 증가하게 됩니다. 유효한 쿼리 중에서도 정보량이 적으니 에러값은 커지는 것이죠.
회색 고양이와 비슷하죠? 이런 고양이는 정보량이 적다고 판단합니다. 왜냐 이미 가지고 있는 데이터와 유사하니 성능 향상에는 큰 폭으로 도움이 되지 않을 수도 있기 때문이죠 (물론 모델마다 다릅니다 이해를 위한 설명입니다) 따라서 회색 고양이에 대해서는 valid query error가 증가하게 됩니다. 유효한 쿼리 중에서도 정보량이 적으니 에러값은 커지는 것이죠.
따라서 정리하면 저자는 semantic 한 something을 통해 invalid query error 를 고려하고자 하였고, distinct한 something을 통해 valid query error를 고려하고자 하였습니다. 이를 동시에 고려하고자 Contrastive Learning 기법을 적용하였구요. 이로 인해 저자는 Contrastive Coding based AL이라고 하여 CCAL 이라는 방법론을 제안하였습니다.
Proposed Method: CCAL
설명에 앞서 notation에 대한 정의를 하고 시작하겠습니다. D_L, D_U는 각각 Labeled dataset, unlabeled dataset을 의미하며, X^{ID_C}, X^{OOD_C}는 각각 클래스 분포 안에 존재하는 데이터와, 클래스 분포 외로 존재하는 새로운 라벨 데이터를 의미합니다. 위의 첨부한 이미지로 예를 들자면 고양이와 강아지는 X^{ID_C}이며, 사슴과 자동차 그리고 비행기는 X^{OOD_C}가 되겠네요. Active LEarning 과정을 통해 라벨링이 필요하다고 선별된 데이터를 X_{query}라고 합니다. 선별된 데이터 중에서 OOD인 샘플을 X^{OOD_C}_{query}라고 하며, ID는 X^{ID_C}_{query} 라고 합니다. 워낙 수식이 많아서 한번 정리해보았습니다.
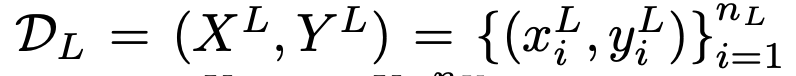
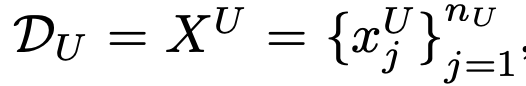
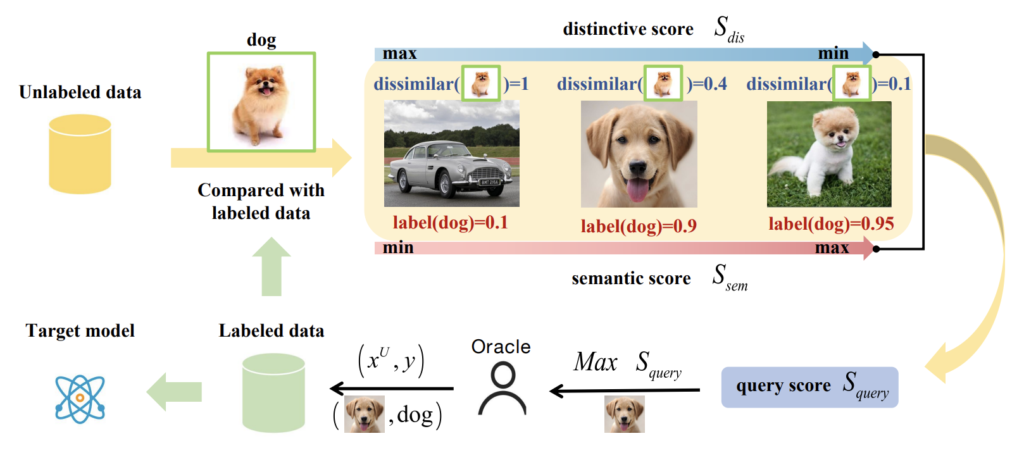
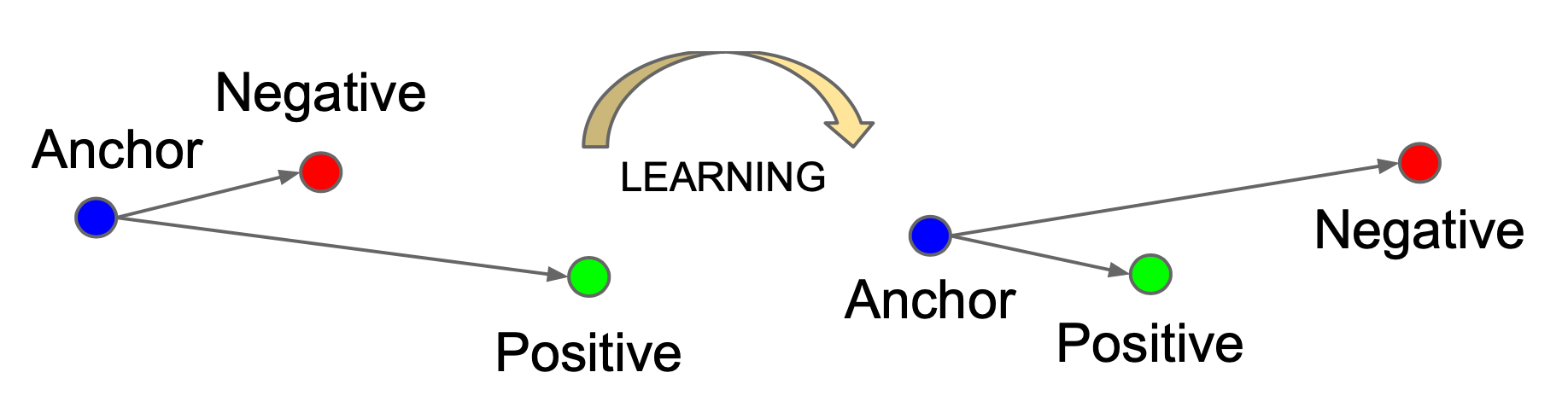
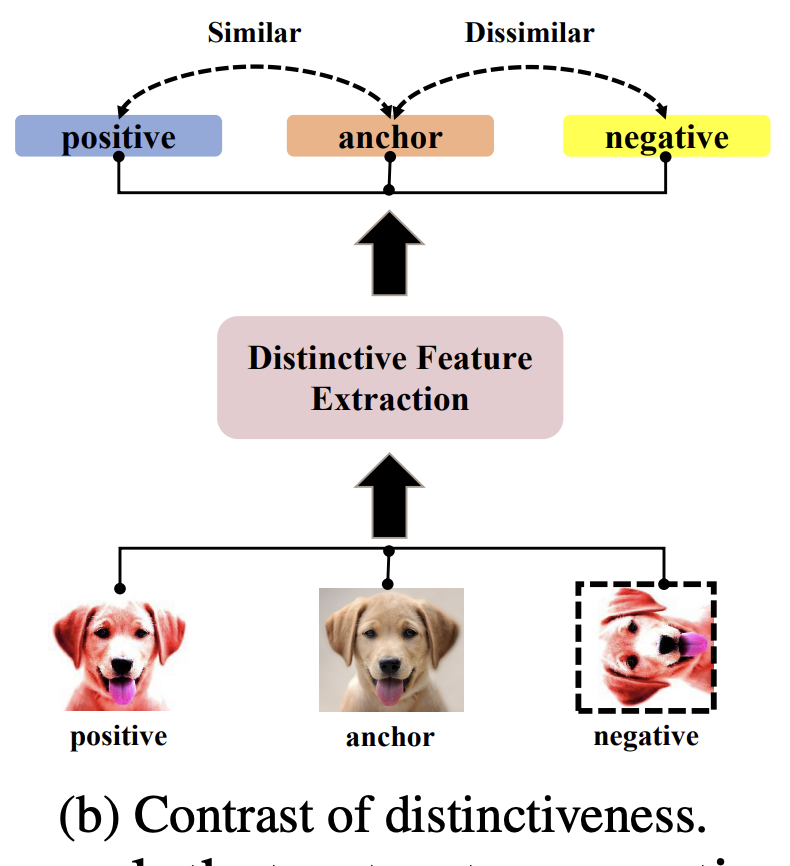
아래 그림이 바로 저자가 제안하는 CCAL의 프레임워크입니다. 간단하게 그 흐름을 우선 설명드리고 다음 섹션에서 디테일한 내용을 다뤄보겠습니다. semantic한 것을 고려하여 기존에 가지고 있는 dog와는 거리가 먼 첫번째 데이터에 대해서는 S_{sem}이 낮도록 학습되어야 합니다. 그와 동시에 쿼리되는 데이터에는 정보량이 많아야 합니다 .이를 위해 distinctive score S_{dis}로 dissimilar 정도를 계산해냅니다. 가지고 있는 데이터와 유사도가 다르면 정보량이 많다고 판단하는 것이지요. 따라서 이 두 가지 요소를 동시에 고려함으로써 저자는 OOD는 필터링하면서 ID 중에서도 정보량이 많은 데이터를 쿼리할 수 있는 그런 Active Learning 방법론을 제안하였습니다.
Learning Semantic Features
우선 unseen class를 필터링하기 위한 semantic feature를 구하는 방식입니다. class distribution mismatch 상황에서, 데이터의 정보량만을 우선순위로 데이터의 가치를 선별(쿼리)하는 기존 AL방식은 타겟 데이터의 성능을 드랍시킬 수 있습니다. 가지고 있는 데이터와는 결이 다른 데이터를 아무리 추가한 들 성능이 오를 리가 만무하겠죠. 최악의 상황에는 라벨링 비용을 낭비하는 꼴만 됩니다. 따라서 이를 위해 unseen class를 필터링하여 데이터를 선별해야합니다. 그리고 필터링을 위해서는 모델이 X^{ID_C}, X^{OOD_C}를 구별해내야합니다. Y 값을 모르는데도 말이죠.
따라서 저자는 Contrastive Learning 을 사용하였습니다. Self Learning 에서도 많이 알려진 것처럼 이 방법은 세부 디테일에 집중하기 보다는 데이터의 불변하는 semantic 한 속성을 학습하는 대표적인 방법이기 때문이죠. 다양한 방법들 중 저자가 택한 것은 Instance Discrimination에서 사용한 Contrastive learning 기법입니다. 우선 Labeled 이미지로부터 랜덤 크롭, HOrizontal flip과 같은 랜덤한 augmentation 여러개를 수행한 샘플을 positive sample이라 합니다. 아래 이미지 중 왼쪽에 변형된 리트리버가 positive sample (\hat{x}_i^+)이죠. 그리고 unlabeled 데이터 중 랜덤하게 한 가지를 선택하여 negative sample이라고 합니다. 아래 비행기가 negative sample(]\hat{B}_{-i})이 되겠군요.
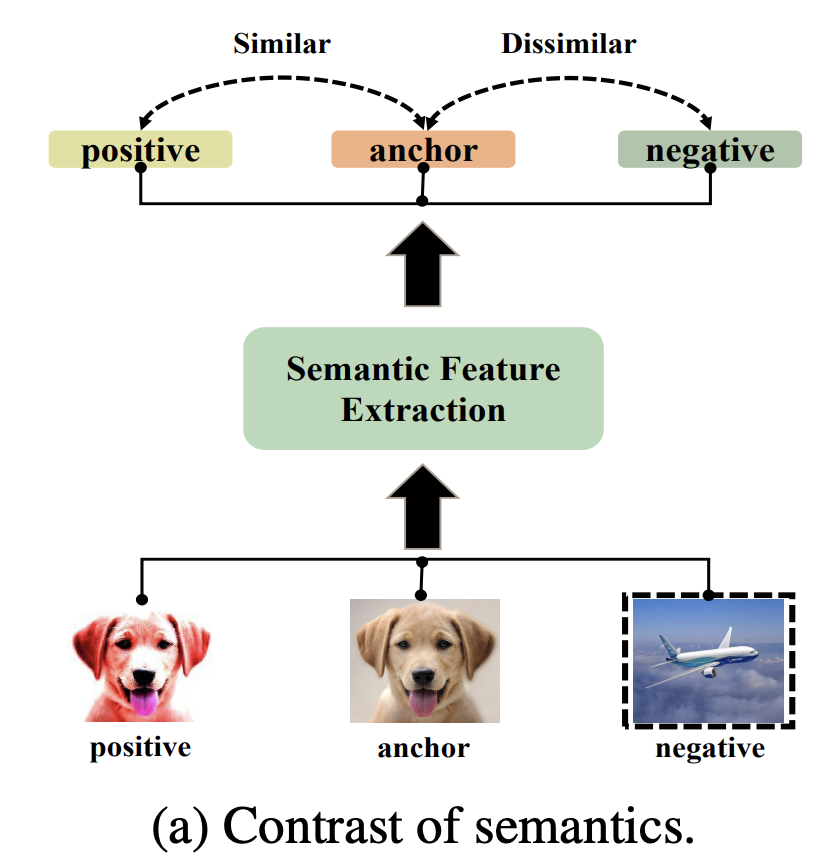
이제 수식 2에 따라 anchor를 기준으로 negative와는 멀어지게, positive 와는 가까워지게 모델 학습이 진행됩니다,. 여기서의 loss는 흔히 사용하는 triplet loss 입니다.
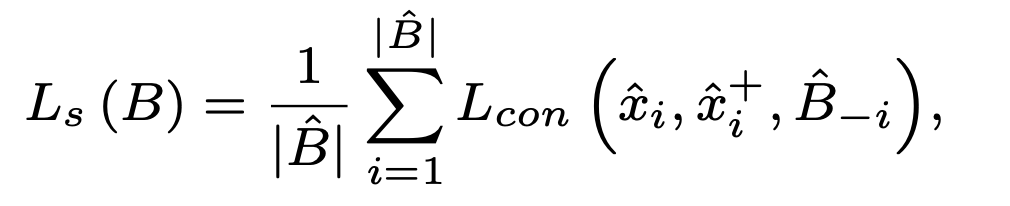
그러고나면 이제 semantic한 정도를 나타내는 semantic score S_{sem}은 semantic feature z_s를 비롯한 위에 수식에 의거하여 아래 수식 3처럼 정의내릴 수 있습니다.
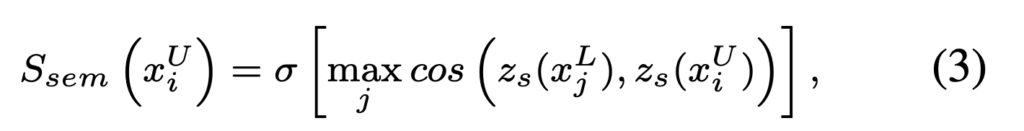
이를 통해 Unlabeled 샘플과 Labeled 데이터 사이 maximum semantic similarity 정도를 구할 수 있게 되었습니다. 이 값이 클수록 현존하는 class에 속할 확률이 높고 invalid query error 역시 낮다고 해석할 수 있습니다.
Learning Distinctive Features
이제 선별된 데이터 중에서 정보량이 많은 샘플을 얻어야합니다. contrastive 를 통해 얻어진 semantic feature로도 충분히 데이터를 선별할 수 있지만, 이 semantic 한 정보만 고려되어 데이터가 선별되면 계속 비슷한 데이터만 쿼리될 확률이 높습니다. introduction에서 그림 중 회색 고양이만 쿼리될 수 있는 것이죠. 따라서 정보량이 많은 것을 얻기 위해 구별되는 고유성 정도를 정량적으로 판단하고자 하였습니다.
회전 변환된 데이터는 표본 입력 분포를 이동시키지만 불변하는 semantics를 유지됩니다. 따라서 저자는 이렇게 회전된 샘플을 negative로 간주하고 semantic feature 에서의 positive sample를 늘릴수 있도록 아래와 같이 설정하였습니다. 그러니까 아래 이미지에서는 negative라고 설정하였지만, 바로 앞 챕터인 semantic feature 파트에서는 positive sample이 더 많아진 것이지요. 여기서는 오직 distinctiveness를 파악하기 위한 임의의 negative 설정으로 보시기 바랍니다.
따라서 distinctive features 는 아래 수식 4에 의해 학습됩니다. unlabeled 샘플은 가장 가까운 레이블을 수도 semantic 라벨로 설정하였습니다.
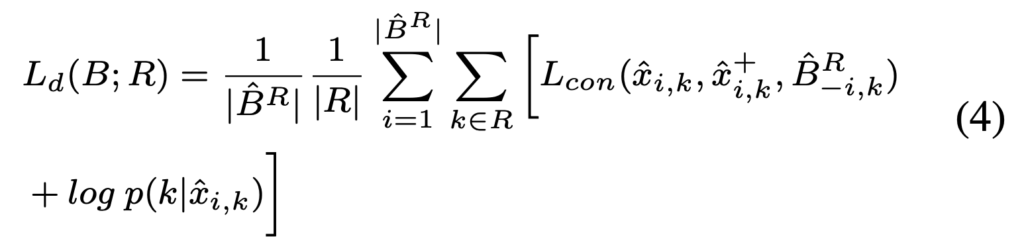
최종적으로 동일한 샘플 별 구별성을 측정하기위한 S_dis는 다음과 같이 정의할 수 있습니다.
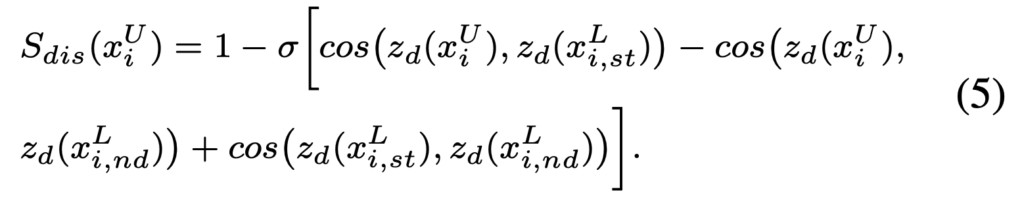
결론적으로 S_{dis}값이 클수록 데이터의 고유성은 커지고 valid error는 작아짐을 의미합니다.
Joint Query Strategy
이제 지금까지 구한 semantic과 disticnive를 동시에 고려할 수 있도록 jointly 하게 데이터를 선별하는 기준에 대한 설명입니다. 어느 하나에만 치중하면 안되죠. 보통 둘을 jointly 하게 고려하기 위해서는 가중치를 설정하여 적절한 값을 찾는 것이 또 하나의 방법이라고 할 수 있습니다. 그러나 저자는 둘을 조합하는 데에 tanh 함수를 사용하였습니다. 왜냐하면 semantic 이 낮은 샘플은 OOD일 확률이 높기 때문에 이를 급격하게 줄여야했기 때문이러고 하였습니다. 즉 범위에 따른 가중치를 위해 tanh를 사용하였음을 알 수 있습니다.
이에 따른 데이터 선별 기준인 S_{query}는 다음과 같습니다.
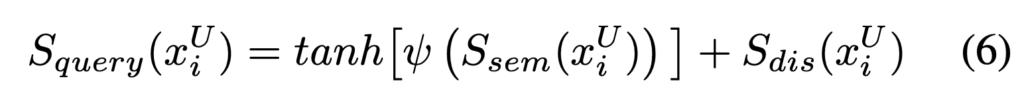
이제 CCAL 의 최종적인 알고리즘은 다음과 같습니다.

Experiments
Result: Classification
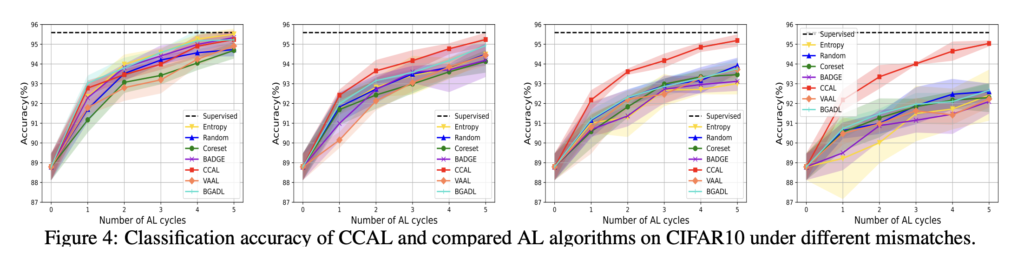
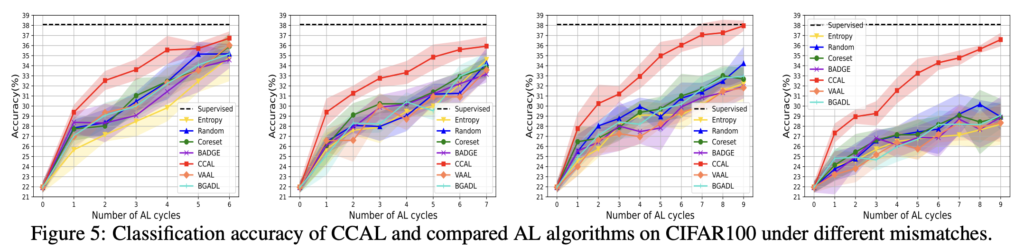
mismatch한 상황을 도출해내기 위해 CIFAR-10에서 비행기와 자동차에 대한 이진 분류 모델을 task 모델로 설정하였습니다. 또한 나머지 8개 클래스는 알수 없는 클래스로 간주됩니다. CIFAR-100에서는 4개의 슈퍼 클래스 즉 20개의 클래스에 대한 분류 모델을 task 모델로 삼았습니다.
그 결과는 아래 이미지와 같으며 이를 통해 다음과 같은 결과를 알 수 있었습니다/
1) 클래스 미스매치 비율이 증가할수록 성능이 저하되는 기존 방법들과 달리 CCAL은 이에 대응이 가능하며, 80%의 미스매치 상황에서도 충분히 좋은 성능을 달성하여씁니다. 구체적으로 보자면 CIFAR10/100 각각 16.3% 26.09%만 라벨링해도 높은 정확도를 달성하였습니다.
2) Mismatch 비율이 증가하면 기존 방법론(VAAL, Coreset)은 랜덤샘플링 성능과 다를 바 없습니다. 다시 말해 불일치 상황에서 기존 방법론은 전혀 동작하지 않음을 알 수 있습니다.
Conclusion
mismatch 상황을 고려한 최초의 Active LEarning 방법론에 대해 알아보았습니다. 결국 contrastive를 그대로 활용하되, informative를 동시에 고려할 수 있는 방법을 제안한 것이 임팩트가 있었던 것 같습니다.
안녕하세요 홍주영 연구원님 리뷰 잘 읽었습니다.
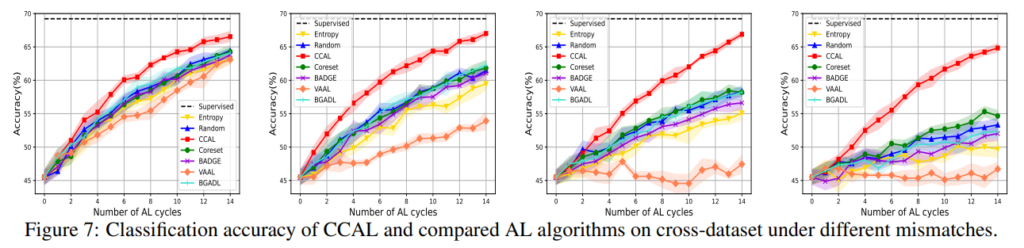
Semantic score와 disticnive score를 동시에 고려해서, 학습하고자하는 데이터를 선별하는 과정 까지는 이해가 가는데, 평가를 어떻게 했는지 잘 모르겠습니다. Unseen Class가 존재한다고 가정해두고 학습을 하면 해당 방법론에서 잘 학습하게 되는 것은 비행기와 자동차만 잘 분류하는 이진모델을 학습하는 것으로 이해했는데요. 이러한 가정을 두고 보면 밑에 그래프도 각각 목표로 하는 클래스만 분류하는 모델의 정확도인가요?
넵 그러니까 이광진 연구원님의 예시를 빌어 설명드리자면, 현재 가지고 있는 데이터가 비행기와 자동차라고 합시다. 그리고 나머지 클래스는 unseen class 로 분류하는 것이죠. 따라서 마지막 그래프는 이 목표로 하는 클래스를 분류하는 모델의 정확도를 의미하는 것이 맞습니다.
리뷰 감사합니다
학습하지 않은 클래스를 일차적으로 제거하는 접근법이 흥미롭네요
하지만 CIFAR-10과 CIFAR-100에서만 실험된것이 아쉽습니다.
실제 상황이라면 클래스에 속하는 여부와 클래스에 속하더라도 분포가 너무 다른경우를 둘다갖을것 같은데 이는 단순히 제안하는 OOD 구별법으로 판별하기가 쉽지 않아보입니다. 혹시 논문에서 이러한 상황에 대한 한계점을 언급했나요? 아니면 혹시 다른 데이터셋 실험이 있는지 궁금합니다.
아! 제가 이 내용을 리뷰에 빠뜨렸네요. 우선 추가 실험으로 cross-dataset이라고 5개의 데이터를 합쳐서 만든 데이터셋에 대한 실험을 진행하였습니다. 데이터셋은 다음과 같습니다: CIFAR10, CIFAR100, Flowers, Places-365, Food-101. 이에 대한 실험 결과를 리뷰에 추가하였습니다. 정확히 [그림7]과 같습니다.