Thermal 이미지에서 Semantic Segmentation을 수행할 때 RGB로 부터 유의미한 정보를 받아오는 과정에서
둘 사이의 domain gap을 줄이기 위한 DA 분야의 논문들을 계속해서 읽어 가는 도중 제목이 왠지 모르게 이끌리는 논문을 발견하여 되어 읽어보게 되었습니다.
리뷰 시작하도록 하겠습니다.
Computer Vision 하위 여러 분야의 많은 방법론들은 RGB image를 기반으로 한 연구를 수행하고 있습니다.
그리고 이러한 연구들은 풍부한 양의 RGB data를 발판 삼아 훌륭한 발전을 이루었죠.
하지만 여러분들도 다들 아시다시피 RGB sensor는 야간 상황의 illumination 변화에 취약하다는 치명적인 단점을 지니고 있습니다.
이 때문에 이런 illumination 변화에 강인한 Thermal sensor 가 연구에 적용되고 있으며, real 환경에서도 유용하게 사용되고 있습니다.
하지만 Thermal의 경우 labeling된 data가 부족하다는 단점을 가집니다. RGB와 pair를 이루는 multispectral dataset은 더더욱 부족한 상황이구요.
이러한 상황에서 필요한 연구가 Domain Adaptation 입니다.
large-scale dataset으로 충분히 학습한 RGB의 정보를 Thermal로 잘 전달해 주고 싶은데,
이때 두 domain 사이의 gap을 잘 해결하고자 하는 것이 본 연구의 핵심입니다.
하지만 단순히 RGB dataset을 통해 학습된 모델, 정보를 Thermal에 부여하게 된다면 어떻게 될까요?
두 sensor domain 사이의 고유한 차이 때문에 큰 성능 drop이 발생하게 됩니다.
Source domain에서 Target domain으로의 Adaptation 수행 시 성능 drop을 최소화 하기 위해 진행되는
Domain Adaptation을 위해 앞선 연구들을 아래의 방식을 많이 사용하였습니다.
Adversarial Domain Adaptation
GAN 모델에 영감을 받아 제안된 방식입니다.
많은 DA 방법론들도 해당 방식을 채택하고 있습니다.
GAN에서는 생성자(Generator)가 만들어 낸 image가 real인지 fake인지 구별하는 방향으로
판별자(Discriminator)가 동작한다면,
Domain Adaptation에서의 판별자(Discriminator)는 encoding된 feature가
source로 부터 추출되었는지, target 으로부터 추출 되었는지를 구별하는 역할을 합니다.
가령 source domain을 RGB, target domain을 Thermal라고 한다면
각 domain의 개별 feature extractor 에서 feature를 추출했을 때
Discriminator는 추출된 feature가 RGB, Thermal 중 어떤 domain에서 추출되었는지 구별하는 방향으로 학습을 진행하고,
반대로 RGB, Thermal의 개별 feature extractor는 Discriminator를 속이기 위해 domain invariant representation을 배우는 방향으로 학습을 진행하게 됩니다.
Adversarial Domain Adaptation의 핵심은 각 domain이 domain invariant representation를 학습하는 것입니다.
domain invariant representation를 잘 학습하였다면 두 domain은 domain invariant한 feature를 각각 추출하게 될테고,
그렇다면 source domain에서 잘 학습된 classifier나 decoder 등을 target domain에도 성공적으로 적용할 수 있겠지요.
하지만 위 처럼 단순히 domain invariant representation을 통해 각 domain feature의 distibution을 정렬(align)하는 것에 집중을 한다고 해서, 이것이 source -> target domain으로의 완벽한 generalization을 보장하지는 않는다고 합니다.
그래서 본 논문에서는 self-training guided adversarial domain adaptation(SGADA) 를 제안합니다.
물론 앞서 말씀드린 adversarial을 사용하되, 최근 DA 분야에 적용이 되고 있는 Self-Training 방식을 함께 활용하고 있습니다.
본 논문이 주장하길, Thermal classification 분야에선 self training을 적용한 DA는 최초라고 하네요.
Method
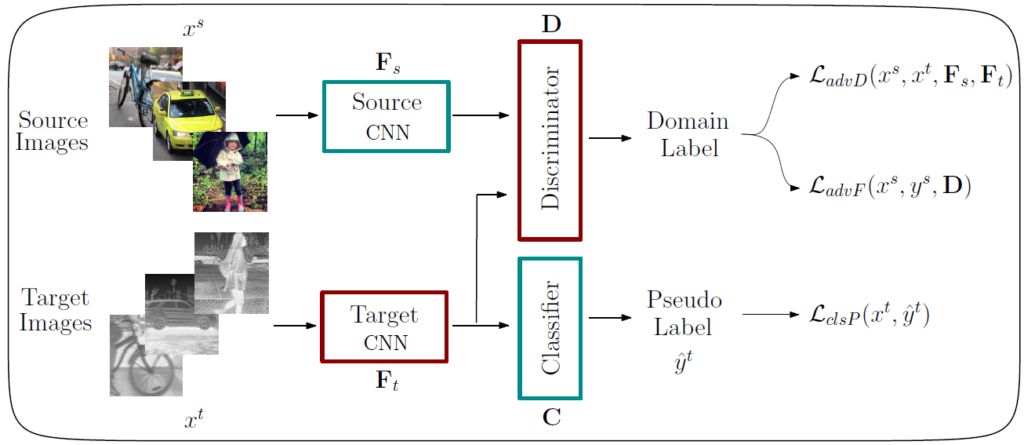
본 논문에서 제안하는 self-training guided adversarial domain adaptation(SGADA)의 전체 흐름은 위와 같습니다.
본 논문의 DA 방식에는 부가적인 contribution이 존재하는데, RGB-Thermal pair dataset이 필요하지 않다는 점입니다.
보통의 방식들은 pair dataset에서 DA를 수행해서 pair한 dataset만 사용 가능한데,
해당 방법론은 그렇지 않기 때문에 확장, 적용 가능성이 더 큰 거 같습니다.
(참고로 본 논문에선 RGB dataset은 MS-COCO를, Thermal dataset은 FLIR ADAS 를 사용하였습니다.)

아 그리고 위에서 제가 설명을 못 드린 부분이 있는데,
통상적으로 Domain Adaptation 방법론들은 labeled source data -> unlabeled target data 의 환경에서 수행 됩니다.
본 논문도 마찬가지구요.
그러면 그냥 labeled source data 로 supervised 방식으로 학습 하고, 해당 예측 값을 unlabeled target data에다가 pseudo label로 주면 안되냐~ 라고 생각하실 수 있는데 본 논문의 세팅 자체가 unpair한 dataset이므로 이는 불가능합니다. 이런 상황에서 어떻게 학습을 진행하게 될까요?
위 그림의 SGADA를 통해 self-training을 수행하기 전에 target domain을 위한 pseudo label을 생성해야 합니다.
이는 아래의 step을 통해 수행됩니다.
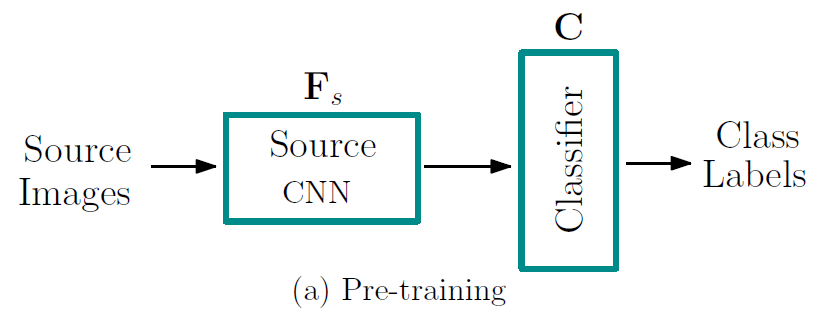
우선 source domain의 feature extractor F_s와 Classfier C를 labeled dataset을 사용하여 supervised 방식으로 pre-training 을 진행합니다. 위에서 말씀드렸다시피 MS-COCO dataset을 사용합니다.
그냥 우리가 흔히 아는 classification model을 학습시키는 과정입니다.
학습 후 F_s는 source domain의 feature를 잘 추출 해 낼테고,
C는 source domain feature 를 잘 classification 하겠죠.
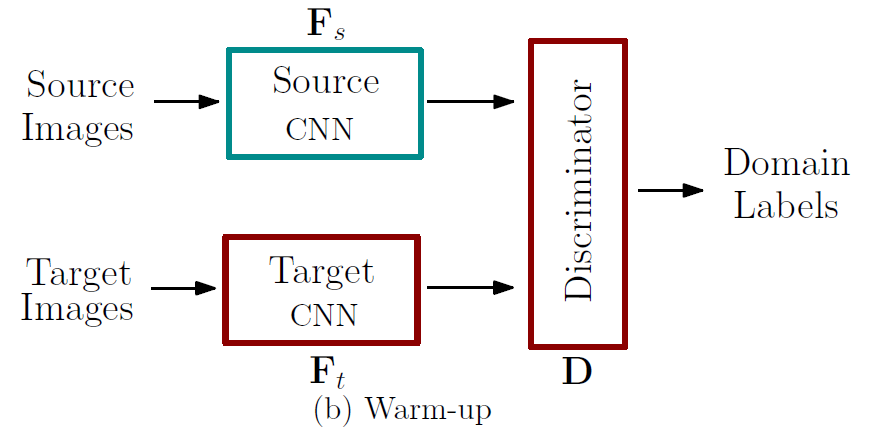
다음은 Warm-up 단계입니다.
label이 존재하지 않는 target image의 pseudo-label을 생성해 주기 위한 준비 워밍업 단계라고 생각하시면 됩니다.
F_s는 위의 Pre-training에서 학습 된 모델을 freeze해서 사용하고,
target domain의 feature extractor F_t와 Discriminator D만을 학습시킵니다.
F_t는 현재 label이 존재하지 않기 때문에 unsupervised 방식으로 Discriminator를 잘 속이는 방향으로만 학습을 진행하게 됩니다. 반면 Discriminator는 source와 target으로 부터 추출되는 각각의 feature를 잘 구분하는 방향으로 학습이 진행되겠죠.
결과적으로 F_t는 F_s와 유사한 feature를 추출하도록, adversarial 방식을 통해 각 domain의 align이 맞춰지는 방향으로 학습이 진행되게 됩니다.
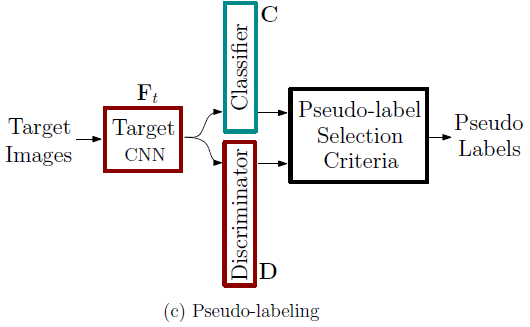
해당 step까지 종료 후,
본 모델이 제안하는 SGADA를 통해 self-training을 수행하며 DA를 진행하게 될텐데
self-training을 위해서는 초기에 일부의 label이 필요하게 됩니다.
본 target image의 경우 unlabeled 이므로 일부의 pseudo label이 필요하겠네요.
본 논문에서 수행하는 task는 classification이므로 어떤 class인지를 나타내는 pseudo label을 생성해야 할텐데 이는 위의 (c) 과정을 통해서 생성하게 됩니다.
F_t가 각각 Classifier C와 Discriminator D의 input으로 들어가게 됩니다.
이후, C를 통해 어떤 class인지를 예측하는 prediction과 신뢰도 confidence를 얻게 되고,
D를 통해 F_t로 부터 추출된 feature가 source 와 target중 어떤 domain과 더 유사한지에 대한 confidence를 얻게 됩니다.
Classifier C 의 예측 중 일부를 self-training의 초기 pseudo label로 설정하게 됩니다.
그리고 이를 선정하는 기준은,
Classifier C의 confidence가 특정 threshold보다 높고,
Discriminator D의 prediction이 source domain에 더 가까우면
Self-training의 초기 Pseudo label로 채택하게 되는 것입니다.
자 이렇게 DA를 위한 Self-Traning의 초기 세팅에 사용되는 target domain의 일부 Pseudo label을 생성 했습니다.
그 후엔 아래의 전체 과정을 통해 self-training guided adversarial domain adaptation(SGADA) 를 진행하게 됩니다.
(위의 그림과 동일)
위의 학습을 진행할 때 하늘색으로 표시 된 F_s와 Classifier C는 freeze 시키고,
빨간색으로 표시된 F_t와 Discriminator D만 학습을 진행하게 됩니다.
이후 Self-Training을 진행하면서 위의 (c) Pseudo-Labeling 과정과 동일한 원리로 점차적으로 Pseudo label을 확대 해 나가는 방식으로 학습이 진행됩니다.
Experiment
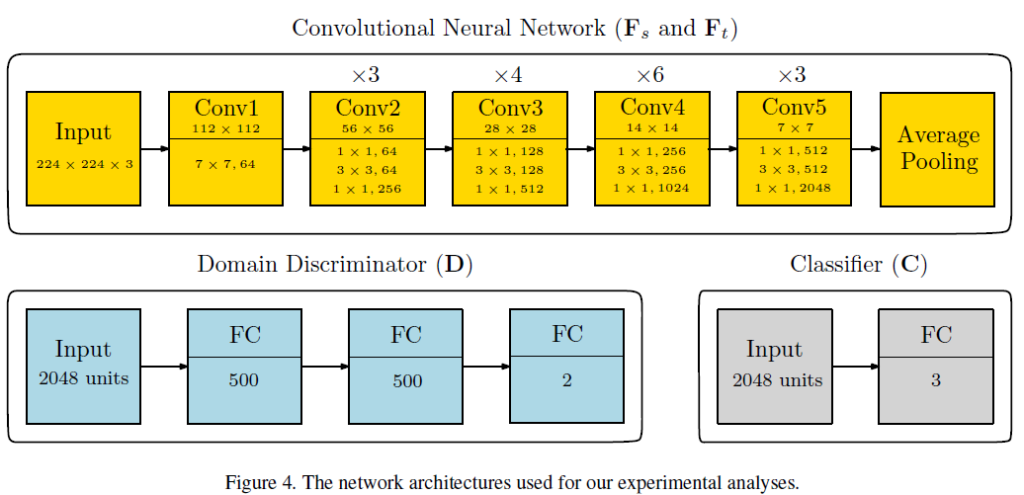
해당 논문은 학습 방식을 제안한 논문이기 때문에,
다른 DA 학습방식을 제안한 방법론들과의 fair comparison을 위해서 ImageNet pretrained ResNet-50을 사용했습니다.
그리고 Discriminator와 Classifier 또한 엄청나게 간단하게 구성되어 있네요.
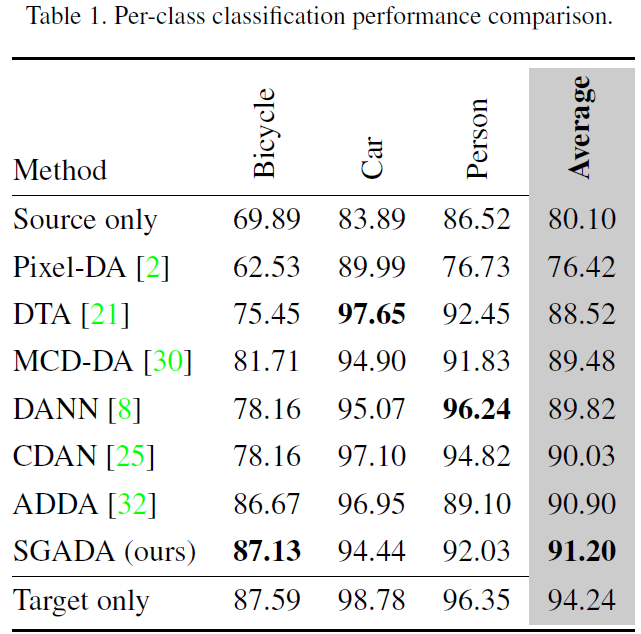
위는 classification 성능을 리포팅 한 결과입니다.
해당 표에서 Source only란 Source image로 학습한 모델을 통해 Target image를 예측 한 성능입니다.
한마디로 Domain Adaptation이 수행되지 않은, 본 실험의 lower bound에 해당하지요.
반대로 Target Domain이란 Target image를 supervised로 학습한 모델을 통해 Target image를 예측 한 성능입니다.
본 실험의 upper bound에 해당합니다.
본 논문에서 제안하는 방식을 통해 Upper bound와 그렇게 큰 차이가 나지 않는, 좋은 성능을 내고 있네요.
또한 3가지 class에서 상대적으로 균등한 예측을 수행함으로써,
real-world에서 다뤄지는 class imbalanced 문제를 타 방법론에 비해 잘 해결했다고 주장하고 있습니다.
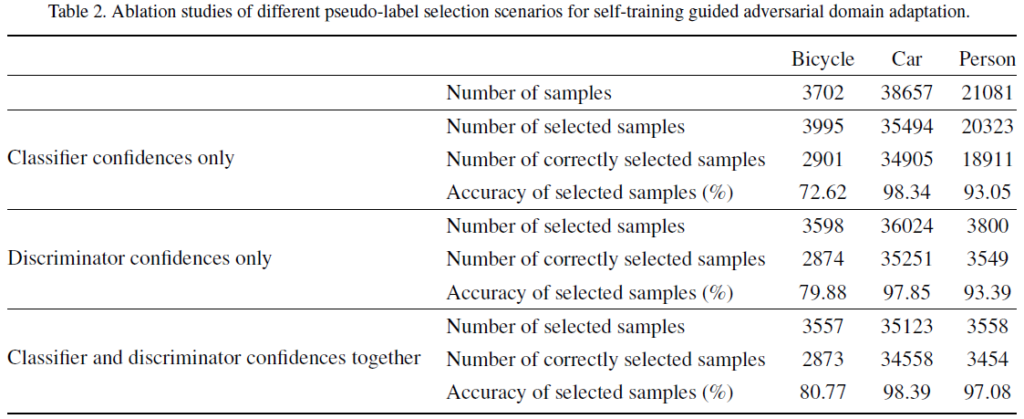
그리고 위는 Ablation study 입니다.
해당 table에 대한 참신한 분석은 없고, 그냥 Classifier와 Discriminator를 모두 사용 시 성능 향상이 일어났다… 뭐 이렇게만 리포팅 하고 있습니다.
사실 전체적으로 조금 아쉬운 논문이였습니다.
multi modal data에서 DA를 수행할 때 unpair한 상황에서도 적용이 가능하다는 확장성은 보여주었다고 생각해서 이는 꽤나 인상깊었지만, 방법론이 막 참신하다는 생각이 들지 않았고, 특히 실험 부분이 너무 부실해서 이게 끝인가.. 싶긴 했습니다. 또한 Self-training에 대한 Ablation도 존재하지 않았구요..
Thermal classification 분야에 self training을 적용한 최초의 DA 방식이라서 가치를 인정 받은 것일까요..?
역시 최초가 중요한가 봅니다.저도 어서 MAE를 UDA에 적용하러 가 봐야겠습니다,,
네 아무튼 이번 리뷰를 마치도록 하겠습니다.
감사합니다.
리뷰 잘 읽었습니다.
리뷰 내용을 보다가 조금 헷갈리는 부분이 target data에 대한 pseudo label을 생성하기 위해 먼저 source data에 대해서 pretraining을 진행한다고 하셨는데, 해당 부분에 대해서 보다 명확하게 정리해줄 수 있나요?
classifier를 학습한다는 것처럼 그림에서는 보이는데, 그럼 해당 영상이 사람인지, 자전거인지 등등을 classification하면 되는건가요? 아니면 object detection을 수행하는 것인가요?
그리고 Flir dataset에 대한 예시를 보면 무언가 전제 장면이라기 보다는 object 영역에 대해 crop한 것 같은데 이는 그냥 예시만 그렇게 보이는건가요? 아니면 bounding box를 이용해 object 영역을 crop해서 입력으로 사용하는 것인가요?
본 논문에서 수행하는 task는 단순 classification 입니다. detect는 수행하지 않습니다.
source와 target이 서로 다른 domain임에도 불구하고 공통된 classifier (정확히 말하면 source domain에 align이 맞춰진 classifier) 로 잘 동작하게 하고자 DA가 수행되는 것입니다.
우선 (a) pre-training 단계에서 source feature extractor와 classifier를 source domain에 맞게 학습시킨 뒤, (b) warm-up 단계에서 Discriminator를 통해 target feature extractor가 source와 유사한 feature를 추출하는 방향으로 학습이 일어나는 것입니다. 그렇게 되면 target feature extractor 를 통해 추출한 target feature도 앞선 source domain에 맞게 학습된 classifier로 잘 분류가 가능하겠지요. 저자는 이러한 학습 효과를 기대했습니다.
Thermal image로 사용한 Flir ADAS의 경우 Object annotation bbox정보를 통해 crop을 미리 시켜서 input image로 사용한겁니다. Thermal image 전체가 해당 방식을 사용합니다.
좋은 리뷰 감사합니다. 이해하기 쉽게 설명해주신 거 같습니다.
궁금한 점이 하나 있는데 SGADA를 통해 self-training을 수행하기 전, self-training을 위해서는 초기에 일부의 label이 필요하다고 하셨는데 왜 일부 label이 필요한 건지 설명해주시면 감사하겠습니다!
음 사실 self-training은 Semi-Supervised Learning에서 처음 사용된(?) 학습 방식입니다. 전체 dataset중 label이 존재하는 data는 일부에 불과한데, label이 존재하는 data만으로 초기에 모델을 학습 한 뒤 unlabeled data를 예측하여 confidence가 높은 녀석들을 labeled data 진영으로 추가 시키면서 학습을 반복해 나갑니다. 이를 통해 모델이 점점 정확해지는게 해당 방식의 핵심이죠. 구글에 검색해서 간단하게 공부 해 보셔도 좋을 듯 합니다.
본 방법론에서는 해당 self-training의 학습효과를 누리고자 하였는데 이를 통해선 초기에 일부 labeled data가 필요하게 됩니다. 하지만 target domain는 unlabeled data이므로 self-training을 수행하기 위해 몇가지 step을 거쳐서 초기 pseudo label을 생성하는 과정을 수행한것입니다.
안녕하세요 좋은 리뷰 감사합니다.
논문의 컨셉 자체는 잘 설명해주셔서 이해가 되었지만,
self-training의 개념이 생소하다보니 궁금한 것이 생겼습니다.
본격적으로 학습하기 전 pseudo-labeling 과정을 거쳐 선정 기준에 부합하는 샘플만 라벨이 붙는 것으로 이해하였습니다. 이렇게 생성된 일부 pseudo label로 SGADA를 수행하면 다시 위의 pseudo labeling 과정으로 돌아갈 필요 없이, 즉 아무 선정 기준 없이 SGADA 과정에서 얻은 나머지 샘플들에 대한 pseudo label을 믿고 바로 사용하는 것인가요?
만약 맞다면 데이터셋마다 다르겠지만, 맨 처음 pseudo labeling 과정에서 전체 데이터셋의 어느정도 비율의 데이터들이 라벨링되는지 궁금합니다.
네 이해하신 내용이 맞습니다. 다시 pseudo labeling 과정으로 돌아가지 않고 믿고(?) 사용하는 것입니다.
두번째 질문에 대해서는,, 매우 흥미로운 질문이긴 하지만 저자는 이에 대한 언급은 하지 않고 있네요. 특정 threshold를 기준으로 구분한다고만 나와있지, 해당 threshold를 변경해가면서 성능을 분석 한 실험이나, 이를 통해 초기 pseudo label의 선정 비율에 대해 리포팅한 부분은 아쉽게도 없네요../. 워낙 실험섹션 내용이 부족한 논문이라 그런 거 같기도 합니다.
안녕하세요 권석준 연구원님 리뷰 잘 읽었습니다.
이 논문에서 말하는 unpair는 pseudo label을 통해서 class는 맞춘 상태로 진행되나요? 아니면 class 자체도 다른 상태에서의 unpair 상황에서도 학습이 되나요?
음.. 제가 읽은 내용에선 딱히 언급이 없었긴 하지만,,
class가 다른 unpair에서도 학습이 진행 되지 않을까요?
target domain이 unlabeled니까 class를 일치시킬 수 없을 뿐더러, 학습의 흐름을 보았을 때 class꼭 동일해야 할 필요는 없기 때문이죠.
+ 궁금해서 코드도 대강 까봤는데, dataloader가 개별적으로 구성되어 있는것으로 보아 class 도 다른 상황에서 학습이 진행되는 거 같습니다. 중간중간에 동일 class인 pair도 섞여서 들어오긴 하겠죠.
좋은 리뷰 감사합니다. Domain Adaptation이라는 것에 대해서 확실히 알게된 것 같습니다. 두가지 질문이 있습니다.
1) self-training 수행하기 전에 target domain을 위한 pseudo label을 생성하는데 이는 unpair이기 떄문인가요?
2) figure들의 Source Image와 Target Images를 보면 unpair하지만 동일한 종류의 object가 들어가는 것을 볼 수 있는데 그러면 pretraining 했다는 것이 object를 분류하도록 학습되었다로 볼 수 있을까요?
답변해주시면 감사하겠습니다.
1) 음 사실 unpair라기 보다는 target domain에 unlabeled data가 사용되기 때문입니다.
self-training의 초기 pseudo label 생성에 대해선 위쪽에 김도경 연구원의 질문에 대한 제 답변을 참고해 주시면 될 듯 합니다.
2) 맞습니다. 정확히 말하면 object가 아닌, image classification 이죠.
신정민 연구원의 질문에 대한 제 답변을 참고하시면 흐름 파악에 도움이 되실 거 같습니다.
리뷰 감사합니다.
pseudo labeling을 통해 unlabeled data를 이용하는 방법이 재미있네요.
해당 논문에서는 사람, 차, 자전거 세가지를 분류하는 테스크를 주 실험으로 리포팅 한것이 맞나요? 이러한 실험 구성이 기존 방법에서 많이 쓰였던 것인지 궁금합니다..
음 제가 image classification쪽 논문과는 친하지 않아서 그 부분에 대해선 잘 모르겠네요.
추가적으로, 본 논문에서 사용한 Flir ADAS dataset 의 경우 object bbox label이 사람,차,자전거,강아지 이렇게 4개가 존재하는데, dog는 annotation 수가 너무 적어서 저자가 임의로 제외를 했다고 합니다.