
원래는 이 논문을 리뷰하려고 했던 건 아니었으나… 이 자극적인 논문의 제목 (모든 악의 근원은 랜덤성이다…) 을 보고 홀린듯이 리뷰하게 되었습니다. 물론 제가 이걸 리뷰하는 이유 100%가 제목 때문은 아닙니다 ㅋㅋ 이 논문이 AL 에서의 평가 환경 및 세팅 문제에 대해 다룬 것이기에, 과연 어떤 인사이트를 줄 지가 궁금했기도 했죠.. 논문 구성이 제법 신기합니다. Active Learning 에서 발생할 수 있는 여러 랜덤 요인에 대한 분석 결과를 제시한 뒤, 앞으로 이렇게 사용하는 것이 좋다 정도의 명쾌한 가이드라인을 제시합니다.
사실 AL에서의 평가 환경 및 세팅에 대해서는 연구는 지속적으로 진행되고 있었는데요. 예를 들어 제가 전에 리뷰한 CVPR 2022에 발표된 논문도 이와 같은 결이죠. 그렇다면 평가 환경이나 랜덤성 등이 Active Learning 에서는 얼마나 중요하길래 지속적으로 연구가 되고 있는지, 그리고 저자는 어떤 결과를 제안하는 지 알아보겠습니다.

Introduction
Active Learning은 소량의 Labeled Data로 학습된 모델을 바탕으로 Unlabeled dataset 중 라벨링이 필요한 데이터를 찾는 연구라고 할 수 있습니다. 보통 높은 가치를 가지는 데이터에 대해 라벨링을 하는데요. 많은 연구진들이 “가치 있는 데이터” 를 매번 새로운 방법으로 정의하고 있습니다. 즉, 가치 있다의 정량적 기준을 새롭게 제안하고 있다고 표현할 수 있을 듯 하네요.
그런데 Active Learning의 초기 설정이 워낙 적은 양의 Labeled data로 시작하다보니, 모델의 성능이 컨트롤하기 어려운 다양한 요소에 쉽게 영향을 받곤 합니다. 예를 들어, 동일한 양이라고 한들 초기 데이터가 어떻게 구성되었는지에 따라서도 성능의 Variance 가 커지기도 하고, backbone model의 가중치에도 안정적이지 못한 성능이 발현되곤 합니다.
따라서 저자는 reproducibility와 rigorous comparative evaluation 에 집중하였습니다. 사실 기존 논문들과 성능을 비교하기 위해서는 초기 데이터셋의 구성도 모든 논문이 똑같아야 할 것 같죠? 가령 CIFAR-10이라고 한다면, 1, 10, 20, …, 3000 등 초기 데이터의 정확한 인덱스나 파일이 지정되어 시작해야 Fair Comparison이라고 할 수 있을 것 같습니다. 물론 한 논문 안에서는 같은 초기 데이터로 시작한 다른 방법론들과 비교한 결과를 리포팅하지만, 사실 모든 논문이 똑같은 셋으로 시작하는 것은 아니기에 논문마다 리포팅된 성능이 모두 다르다는 것이 문제입니다.
그래서 저자는 영향을 주는 요인들을 제어하는 방법에 대해 이해하여, Active Learning 연구 전반에 걸친 일관된 평가 프레임워크 구축이 필수적이라고 하였습니다. 따라서 본 논문에서는 (1) 기본적인 learning 설정 (2) 서로 다른 randomness의 source (3) 실행 환경에 대한 구체성 이 3가지의 카테고리로 서로 다른 AL 방법론들의 영향을 분석하였습니다.
2. Reliable Evaluation of Deep Active Learning
제목처럼 저자는 성능이 모두 다르게 평가되는 원인으로 랜덤성을 골랐습니다. 이 랜덤성 때문에 안정적인 평가가 불가능했다고 저자는 평가합니다. 따라서 안정적인 평가가 가능한 랜덤성을 일으키는 요소들이 무엇인지를 알아봐야겠죠. 해당 섹션에서는 랜덤성 소스를 제한하기 위한 프레임워크 (가이드라인)을 제시하고, 성능에 미치는 영향을 제시하였습니다. 그 전에, 성능 평가 및 분석은 다음과 같이 통일하여 비교실험을 진행했다고 합니다.
Method under test. 저자는 기존 AL 연구에서의 랜덤성 분석을 위해 아래 Table.2 속 AL 방법과 랜덤 샘플링까지 총 8가지의 연구를 다시 구현해보았습니다. 모든 실험은 CIFAR-10 과 CIFAR-100 데이터셋에 대해 수행하였으며, 뒤이어 설명할 Sec 2.1 ~ Sec 2.3의 권장 사항에 맞추었습니다. 또한 init label size는 1,000 그리고 추가되는 라벨 개수는 2,000으로 통일하였습니다. 보통 Active Learning 에서는 성능 테이블을 그래프로 보이곤 합니다. 라벨 데이터가 계속 추가되기 때문에 성능을 보이기 위해서는 그래프가 가장 직관적이기 때문이죠. 그런데 기존 연구들마다 어떤 연구는 1000개의 데이터에서 시작해서 10K까지의 성능을 보고하는데, 다른 연구에서는 25K~30K까지 보고하고 있기 때문에, 이를 표현하기 위해 그래프의 X축은 0~25K 까지로 통일하였습니다.
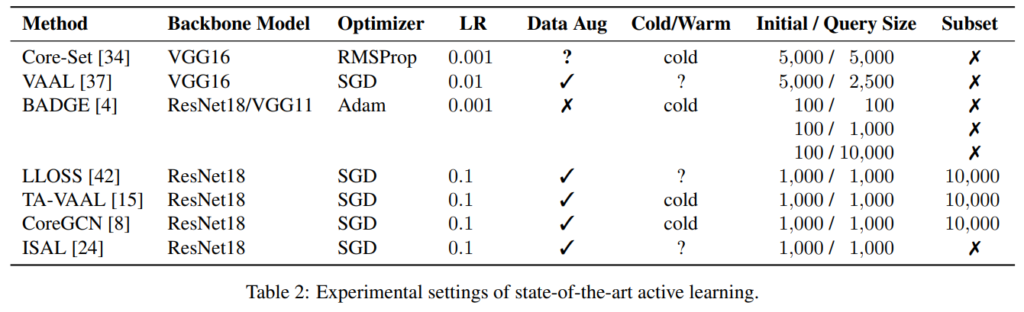
Significance tests. 서로 다른 세팅에서 비교하기 위해, 서로 다른 seed 로 초기 라벨 셋을 바꾼 뒤, 3번의 실험을 수행하였습니다. 많은 기존 연구들은 딱 여기까지 하고 평균값과 표준 편차를 함께 리포팅 하였는데요, 저자는 여기서 two-tailed paired t-tests 라는 기법을 통해 통계적 분석을 시도하였습니다. t-test는 두 표본 집단 간의 차이를 비교할 때 사용하는 대표적인 방법 중 하나라고 합니다. 간단하게, 기존에는 3번의 Accuracy의 평균으로 성능을 비교했다면, 이제는 그 Accuracy 값에 대하여 통계적 특성을 이용한 분석 기법을 사용했다고 보시면 좋을 것 같습니다.
최종적으로 비교하고자 하는 두 개의 AL 방법 i와 j를 쌍 별로 비교하는 Pair-wise Penalty Matrix 로 시각화하였습니다. 이 시각화 결과를 아래 이미지를 참고하시기 바랍니다. 결국 두 개의 방법론을 직접적으로 비교한 테이블이라고 보시면 되는데요. 이 상관관계 그래프에서 한 셀의 값이 높을 수록 row에 있는 method i가 column method j보다 강하다 즉, Active Learning이 잘 수행됨을 뜻합니다. 마지막으로 가장 아래 \phi가 바로 순위를 구성하기 위한 열에 대한 평균치를 구한 값입니다. 저자는 기존 논문과는 다르게 해당 논문의 모든 파트에서 이 상관관계 메트릭을 사용하여 각 방법론을 비교하고자 하였습니다.
2.1 Controlling the Underlying Learning Setup
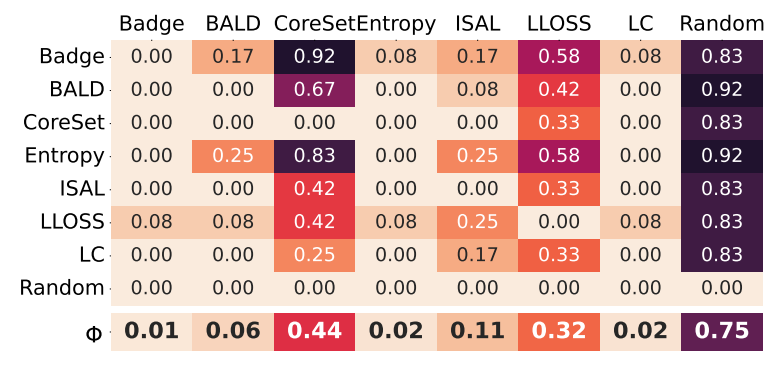
이제 본격적으로 저자가 살펴본 요소 별 AL 특징에 대해 알아보겠습니다. 기존에도 평가에 영향을 미치는 요소들을 조사한 연구가 있었는데요, 아래 테이블이 바로 그동안의 연구를 정리한 테이블입니다. 한눈에 봐도 알 수 있듯, 저자가 가장 많은 요소들을 조사하였음을 알 수 있죠. 다만 회색 동그라미는 저자가 직접 실험을 통해 도출한 결과는 아니긴 합니다. 아무튼 이제 각 요소들에 대해 알아보도록 하겠습니다.
2.1.1 Backbone Architecture
여느 논문이나 이 백본 네트워크가 달라서 발생하는 성능 차이가 존재하기 마련입니다. 게다가 추출된 Feature를 기반으로 데이터의 가치를 평가하는 연구이다 보니, 이런 백본 네트워크에 민감하기 마련입니다. 실제로 [22] 논문에서는 CIFAR-10을 사용했을 때의 VGG16, ResNet18, DenseNet201 을 비교한 결과 ResNet18이 성능이 가장 좋았다는 결과가 있었습니다. 게다가 기존 대부분의 연구진들이 Backbone Network로 ResNet18 을 사용하고 있기 때문에, fair comparison을 위해 CIFAR-10 / 100에 대해서는 ResNet18을 사용하는게 좋을 것 같다고 합니다.

2.1.2 Types of Optimizer, Learning Rate, Data Augmentation
해당 파트의 제목들이 미치는 영향들에 대해서는 이 리뷰를 읽는 여러분들도 알고 계실 것이라 생각이 듭니다. 이렇게 까지 고정을 시켜야한다고..? 라고 생각할 수도 있지만, 논문마다 성능이 다르다는 너무나도 큰 이슈로 인해 저자가 이런 요소들에 대해서도 고려를 한 것 같다고 보입니다. 사실 이 쪽에 대해서는 저자가 실험을 통해 이런게 좋다~ 라는 인사이트를 제시하기 보다는 기존에 이런걸 많이 쓰더라 혹은 이게 경험적으로 성능이 제일 좋더라~ 정도의 내용 정도라.. 그냥 권고 사항이 있구나~ 정도로 파악하면 될 듯 합니다.
저자가 권고하는 내용을 요약하자면, (1) optimizer는 SGD를 lr은 0.1로 사용하는 것을 권장. (2) Augmentation의 경우 모든 방법에 동일한 방법들을 사용한다면 괜찮지만 가급적 random horizontal flipping & random cropping 정도의 베이스라인을 따르길…
2.2 Containing Randomness
실험 설계에 가장 큰 영향을 미치는 요인은 바로 랜덤성인데요. 이번 파트에서 저자는 다양한 랜덤 소스에 대해 다뤄보았습니다.
2.2.1 Model and Method Initialization
Active Learning 에서는 모델을 업데이트 하는 과정이 여러번 반복됩니다. 예를 들어 처음에는, 1000개의 라벨 데이터로 200 epoch 만큼 모델을 학습시킵니다. 해당 모델은 라벨링이 필요한 2000개의 데이터를 쿼리하고, 라벨 데이터에 추가됩니다. 그럼 다시 앞서 학습된 모델을 바탕으로 3000개의 라벨 데이터로 200epoch만큼 다시 모델을 학습시키죠. 이 과정을 10번 반복하는 것이 Active Learning 의 과정입니다.
따라서 모델 업데이트 관점에서 랜덤성이 발현된 부분은 바로 맨 처음의 사이클입니다. 처음 백본 모델이 어떻게 초기화 되어 있느냐 혹은 어떤 데이터셋으로 구성되어 있느냐에 따라서 랜덤성이 생기게 됩니다. 따라서 이에 대해 저자는 다음과 같이 정리하였습니다.
고정 랜덤 시드를 사용하여 T개 초기 데이터셋을 만든 뒤, 각각을 사용하여 T개의 서로 다른 가중치 초기화 모델을 학습한 뒤 TxT개의 모델을 만들어 실험해야한다는 것이죠.

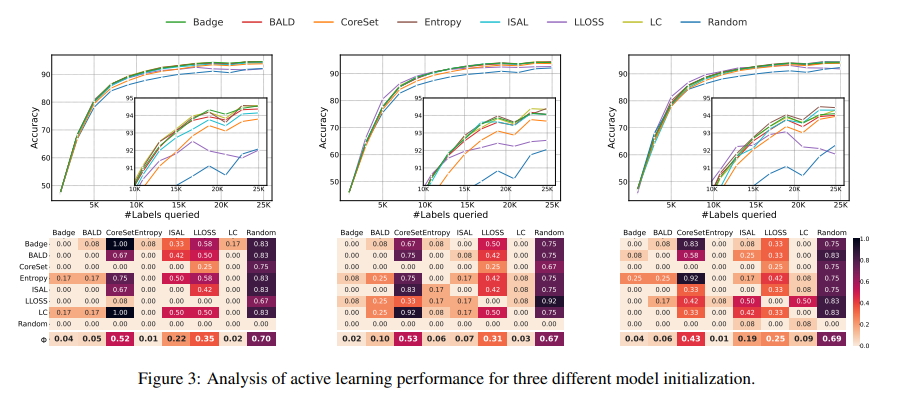
#Influence of initialization sets (“init sets”).
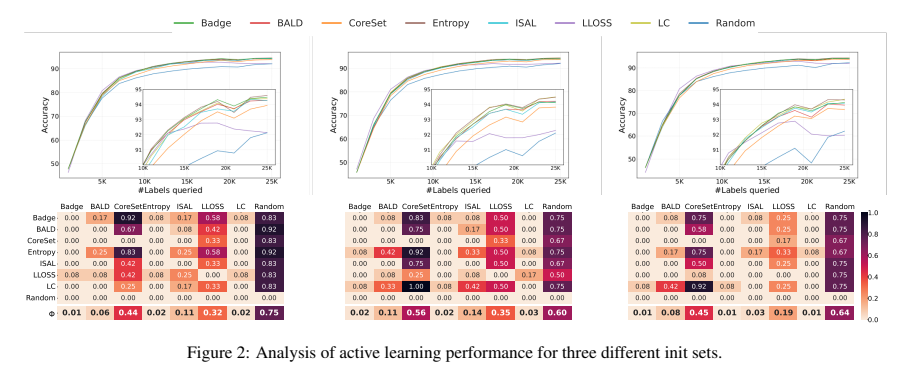
아래 그림은 동일한 init set으로 시작한 모델에 대해 t-test를 수행하여 Pairwise Penalty Matrix(이하 PPM)로 표현한 것들 중 최상의 3개의 결과를 나타낸 것입니다. x축 은 추가되는 라벨 데이터를 의미하고ㅡ y축은 정확도를 그리고 아래 상관관계가 각 방법론들을 1:1로 비교할 수 있는 PPM을 나타냅니다.
첫번째 초기 시드 세트인 가장 왼쪽 그림을 통해 BADGE가 \phi에서 가장 작은 값을 보입니다. 이는 BADGE가 다른 방법론보다 우수한 성능을 보였고, 그 뒤를 Entropy, LC가 따른다는 것을 알 수 있었습니다. 두번째 시드에서는 BADGE, 그리고 Entropy가 유사한 결과를 보였고, 세번째 시드 역시 크게 다르지 않았습니다.
또한 L-Loss를 살펴보면 첫번째 두번째와 세번째를 비교했을 대 성능 차이가 큰 것을 알 수 있었는데요. 이를 통해 초기 시드에 따른 성능 차이를 정량적으로 제시를 하였습니다. 즉, seed 빨(???) 이 될 수도 있다 라는 리포팅을 하며 기존 [25] 논문의 정성적 분석과 동일하였음을 다시 한번 상기시켜주었습니다.
#Influence of model initialization.
다음으로 모델의 가중치 초기화에 동일한 시드를 사용하는 모델에 대한 t-test를 수행한 결과를 보이도록 하겠습니다. 이 역시 마찬가지로 T개의 seed 중에서 3개의 결과를 아래 그림에서 알 수 있습니다. 우선 첫번째와 세번째 모델 초기화의 경우 엔트로피가 BADGE보다 약간 더 높은 성능을 보였으나, 두번째는 BADGE가 엔트로피보다 높았습니다. ISAL과 LLOSS의 경우 시드에 따라 성능 차이가 크게 다르다는 것을 통해, 이 방법들이 특히 초기화의 분산을 일으키기 쉽다는 것을 알 수 있었다고 합니다.
2.3. Fixing the Execution Environment
SW 말고도 HW 에 대해서도 랜덤성에 대해 알아보았다는 것이 제법 인상적이었습니다. 사실 이 요소들이 랜덤성에 영향을 미칠 수 있다는 것은 뭐 자명한 사실이기도 하긴 합니다. 여기서 특별한 얘기를 하기 보다는 이런 요소들이 성능에 영향을 미칠 수 있을 수 있으니 원복을 위해 코드에 수정이 필요할 수도 있다 정도의 이야기를 합니다.
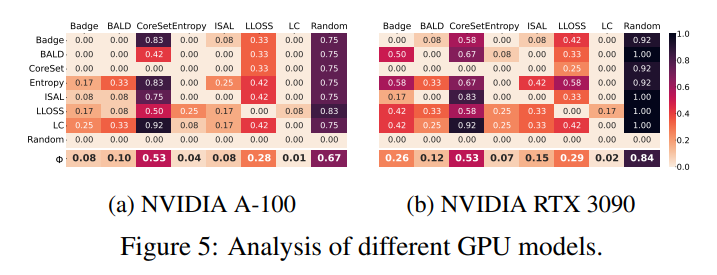
Influence of varying GPU models.
저자는 GPU에 따른 성능 차이를 보이기 위해 A100와 3090에서 T번의 실험을 진행하여 t-test 결과 확인한 결과는 아래와 같습니다. 그 결과 특히 BADGE가 이 GPU에 따라 성능 차이가 컸다는 것을 알아냈습니다. 따라서 모든 실험에 대해 GPU 역시 고정해서 실험을 일관성 있게 진행해야함을 보였습니다.
3. Analyzing Active Learning
3.1. Query-Batch Size
Budget 이라고도 부르는 query-batch는 한번의 사이클이 끝나고 추가되는 데이터 개수를 의미합니다. 이미 이 전 연구들에서 이 쿼리 배치 사이즈를 다룬 적이 있으며, 논문에 따라서 이게 통일되어 있지 않은 부분이기도 하죠.
저자는 1000, 2000, 4000 으로 나누어서 실험을 진행하였습니다. 아래 그림이 각각에 대한 성능입니다. 여기서 이 쿼리 사이즈에 따라 방법론들의 순위가 달라지는 것을 알 수 있었습니다. 1000에서는 BALD이 1위이지만, 2000 및 4000에서는 월등하게 Entropy 가 앞서게 되죠.
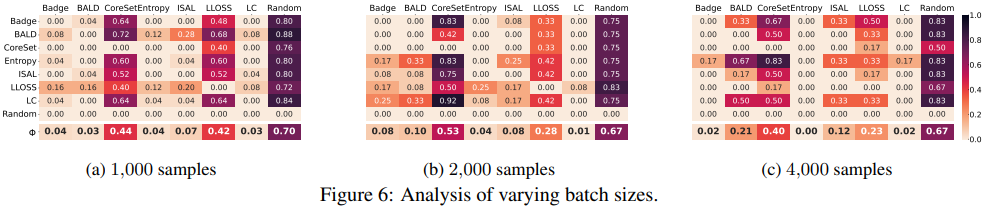
따라서 저자는 여러 쿼리 배치 크기를 고려하여 실험 결과를 제시해야 한다고 주장하였습니다.

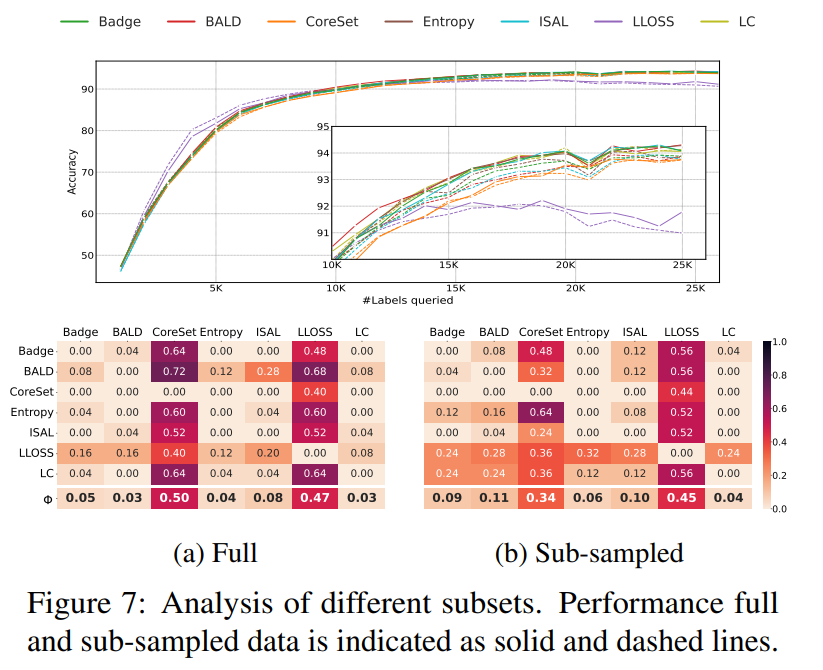
3.2. Subset Sampling
위에서는 몇 개씩 데이터를 라벨링할지에 대해 알아보았습니다. 그런데 사실 많은 AL 방법론들이 데이터의 가치를 판단할 때 전체 데이터셋에 대하여 데이터의 가치를 판단하지 않습니다. 계산의 복잡도와 데이터의 중복성을 고려해서 가령 5만개의 데이터가 있다면 3만 개로 랜덤하게 서브 샘플링한 뒤 그 안에서 데이터의 가치를 판단하곤 합니다. 따라서 이번 파트에서는 서브 샘플링이 미치는 성능 변화를 알아보도록 하겠습니다. 다만 랜덤 샘플링은 여기서 제외하였습니다. (서브 샘플링 자체가 랜덤으로 뽑기 때문이죠. 랜덤 샘플링을 포함하게된다면 이 과정을 두 번 반복하는 것과 다름 없습니다)
그 결과는 아래와 같습니다. BALD 및 BADGE의 경우 하위 샘플링을 사용한 게 오히려 성능 드랍을 가져오는 반면, Core–set의 경우 그 영향력이 상대적으로 작았습니다. 이런 경향은 Core-set과 LLoss를 제외한 모든 방법에서 상당한 차이를 보이는 것을 정확도 그래프에서도 확인할 수 있었습니다. 따라서 하위 샘플링을 사용하면 AL 방법론의 순위를 바꿀 수 있고, 이 역시 성능에 영향을 줄 수 있는 요소임을 확인할 수 있었습니다.
흥미로운 점은 LLoss 논문에서는 하위 샘플링을 사용한 이유가 불확실성 기반 방법에 대한 선택의 중복성을 완화할 수 있다고 하였었다는 점을 꼬집습니다. 그러나 이것은 데이터셋에 크게 의존적이었음을 알 수 있었다고 합니다. 예를 들어 CIFAR-100에서는 이 서브 샘플링을 사용한 뒤 LCㄱ와 엔트로피가 확실히 나은 성능을 보인 반면, CIFAR-10에서는 그 반대였습니다.

3.3 Comparative Analysis
마지막으로 비교 평가를 설명하는 파트입니다. 서로 다른 쿼리 배치 크기 (budget size) {1000, 2000, 4000}, 데이터셋 {CIFAR-10, CIFAR-100} 에 대한 paired penalty matrix (PPM)을 비교한 결과가 아래 그림 입니다. 모든 실험은 3번을 돌린 결과입니다.
마지막 행이 그 순위이며, 이 값은 열에 대한 평균으로 구성됩니다. 또한 이 값이 작을 수록 다른 방법에 비해 더 좋다고 할 수 있습니다. 그 결과 LC > BADGE > BALD > ISAL > Entropy > L-Loss > Coreset > Random 이라는 결론을 내릴 수 있었습니다.


4. Conclusion
지금까지 연구된 많은 연구들이 신뢰할 수 있는 평가를 위한 포괄적인 프레임워크가 부족하였다는 점을 지적하며, 앞으로 이런 가이드라인을 준수할 수 있도록 다양한 요소를 살펴본 논문이 아닌가 싶습니다.
개인적으로 언젠가 이런 여러 요소를 분석해보면 좋겠다라는 생각이 있었는데… 역시 누군가는 하네요.
안녕하세요 좋은 리뷰 감사합니다.
논문 제목이 진짜 눈길을 끌 수 밖에 없겠네요…ㅎ
혹시 query-batch size마다 방법론들의 순위가 달라지는 것을 알 수 있는데, 그럼 batch size를 선택할 때 1000, 2000과 같은 size는 어떤 기준으로 실험된 것인지 서술되어있나요? 아니면 기존 연구들에서 보통 그 정도 size로 실험을 했던 것인가요?
네 기존에 많이 쓰이는 크기로 설정하였습니다. 보통 1000, 2000, 2500을 사용하는 연구를 보았는데 그 이상의 크기도 확인하기 위해 4000으로 설정한 것 같습니다.
주영 연구원님의 다른 AL 논문 리뷰를 읽었다면 이 논문의 제목이 읽을수 밖에 없는 제목이라 생각드네요. 랜덤성과 관련하여 성능 측정하는것이 얼마나 중요한지도 배워갑니다ㅎㅎ 중간에 PPM이 정확히 무엇을 측정한건지 알 수 있을까요?
Pairwise penalty matrix의 경우 Significance tests 에서 간단하게 내용을 다뤘었는데요. 간단하게 T-test에 의해 도출된 값이 method i보다 j가 성능이 높을 횟수만큼 Penalty 를 부여한 상관관계를 표현한 것이라고 보면 될 것 같습니다. 그렇기때문에 값이 작아야 성능이 더 좋다 라고 해석할 수 있는 것이죠
안녕하세요 홍주영 연구원님, 좋은 리뷰 감사합니다. 막연히 active learning에 대한 리뷰를 찾아보다가 논문의 제목을 보고 홀린듯이 들어왔습니다.
정리를 하자면, AL은 소량의 Labeled Data로 학습된 모델을 바탕으로 unlabeled dataset 중 라벨링이 필요한 데이터를 찾는데, 초기에는 적은 양의 labeled data로 시작하기 때문에 모델 성능이 다양한 요소에 쉽게 영향을 받게 되고 논문마다 랜덤 소스를 통일하지 않아서 reporting된 성능이 모두 다르니 이를 통일해주는게 좋다 정도로 요약할 수 있겠네요, 일관성 있는 변인 통제에 대한 중요성을 강조한 것으로 보입니다. Data Aumentation, optimizer, backbone, regularization, Learning rate, 등등 생각보다 신경써야 할 부분이 많아보입니다. 나중에 실험을 하게 된다면 이러한 부분들을 염두해 두고 실험을 진행해야 할 것 같습니다.
method 요소에 cold/warm 이라는 부분이 있는데, 혹시 이것은 무엇을 의미하는지 알려주실 수 있을까요?
저도 사실 Warm start에 대해서는 해당 논문에서 처음 접해서 정확한 정의는 모르겠으나, 아마 Cold start의 반대가 아닐까 조심스럽게 예측해봅니다.
Cold start 란 초기 데이터셋의 영향으로 성능이 기대치 이상으로 오르지 않는 경우를 의미합니다. 즉, 아무리 데이터를 추가해도 성능이 충분히 오르지 않는 현상을 의미하죠. 예를 들어, 1000개로 학습이 시작된 뒤, 1000개씩 총 3번 추가되어 4000개의 데이터셋으로 모델이 주기 학습을 했을 때의 성능이 그냥 처음부터 2000-3000개의 데이터로 학습한 것보다 좋지 않은 경우도 그 예라고 할 수 있을 것 같습니다.
보통 초기 데이터셋이 극히 작은 크기로 구성되어있을 때 많이 발생하는 현상인데요. 데이터셋이 0.01%와 같이 극히 작을 경우, Semi-supervised learning 에서도 기대치 이상 성능이 오르지 않는 현상이 발생합니다. 이런 Cold-start 는 아주 작은 크기의 데이터셋으로 학습을 시작하는 경우에 많이 발생하는 문제로 Active Learning에서의 고질적인 문제 중 하나라고 할 수 있습니다.
이 Cold start 문제를 해결하기 위해 초기 데이터셋을 선별하는 방법에 대한 연구를 진행하고 있기도 합니다. (아마 재연님이 최근에 제게 댓글을 달아준 리뷰가 그 중 하나이기도 합니다) 이해가 잘 되셨기를 바라며, 추가 질문이 있을 경우 댓글 남겨주시면 설명 드리도록 하겠습니다.