VoxelNet은 Apple에서 제안한 network로, hand-crafted feature가 아닌 feature extraction과 bbox prediction이 one-stage로 구성된 end-to-end학습이 가능한 deep network이다. 딥러닝 기반 LiDAR 3D object detection분야에서 milestone이 된 논문 중 하나이다. 모델의 흐름을 요약하자면 3 dimension상의 point cloud를 voxel이라는 단위로 grouping, sampling하여 feature를 뽑아낸 후, 해당 voxel 위치에 대한 정보를 포함시켜 tensor형태로 만들어 3d convolution을 이용해 detection하는 방식이다. 당시 KITTI 데이터셋에 대해 LiDAR기반 3D detection 방법론 중 sota를 달성하였다. 아래에서 자세히 알아보자.
Introduction
우선 voxel이란 volume과 pixel을 조합한 단어로 3차원 공간에서 격자 단위 공간을 의미한다. input으로 사용되는 point cloud는 3차원 공간에 존재하는 point들의 집합(cloud)을 의미한다. 본 논문에서는 LiDAR를 이용해 point cloud를 얻는다. 기존 2d data와 다르게 depth 정보(z축)가 포함되어 3차원의 배열형태로 표현된다. point cloud는 정형화되지 않은 데이터로 3d 공간의 points들을 순서없이 기록되기 때문에 spatial한 특성을 파악하기 어렵다. 그리고 sparse한 특징을 가진다(빈 공간이 더 많다).
이미지 데이터와 다르게 LiDAR point cloud는 sparse하고 point density가 고르지 않다. RPN(Region Proposal Network)은 dense하고 organized(image, video 등)한 data를 필요로 하기 때문에 sparse하고 random하게 생성되는 point cloud에서는 잘 맞지 않았다. 이때 point cloud를 RPN에 입력하기 위해 hand crafted feature representation 방법론들이 적용되었다. 하지만 point cloud의 3d shape 그대로를 잘 이용할 수 없어 preprocessing을 하면서 정보 손실이 발생하는 문제가 있기 때문에 machine learned 방법으로 변화하게 되었다. 이전 방법론들에서는 point cloud를 처리하기 위해 feature transformer networks를 모든 input points에 대해 학습해야해서 많은 computation을 필요로 했고, network 크기가 커지면서 더 큰 challenge로 여겨졌다.
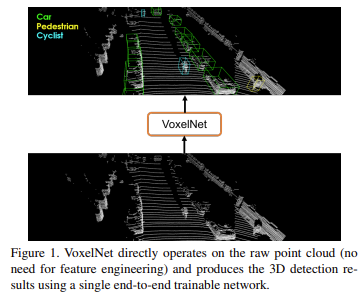
본 논문에서 제안하는 VoxelNet은 voxel이라는 개념을 통해 voxel 단위로 grouping과 sampling을 통해 voxel-wise feature를 추출한 후, voxel 위치정보를 포함시켜 4d tensor형태로 생성한 값을 3d conv를 이용해 detection하게 된다. VoxelNet은 LiDAR-only detection방식으로, hand crafted feature를 제거하고 feature extraction과 bbox prediction을 통합하여 simultaneous하게 discriminative feature representation을 학습하고, 더 정확한 3d bounding box를 end-to-end 방식으로 예측하는 모델을 제안한다. 또한 point cloud data의 특징인 density imbalance 문제를 해결하였고 non-empty voxel에만 연산을 적용해 연산량을 줄일 수 있었다.
본 논문에서 제안하는 contribution은 아래와 같다.
1. hand crafted feature를 찾는 대신 sparse한 point cloud를 바로 사용하는 end-to-end detection 제안
2. sparse point structure와 voxel grid의 병렬 처리를 효율적으로 실행하는 방법 제안
3. KITTI benchmark에서 sota 성능
VoxelNet
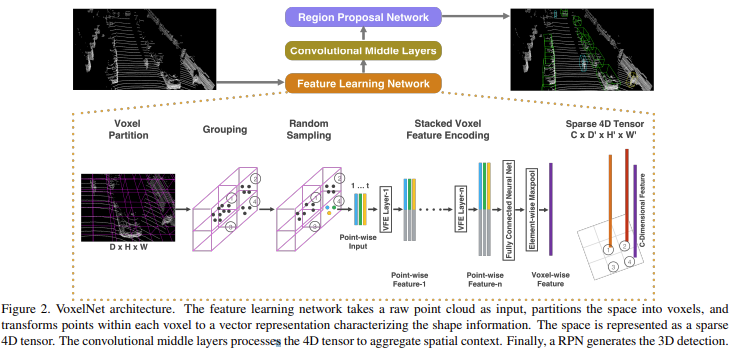
VoxelNet의 전체적인 흐름은 위의 figure2와 같다.
크게 Feature Learning Network, Convolutional Middle Layers, Region Proposal Network 이렇게 3개의 functional block으로 구성된다. 하나씩 알아보자.
Feature Learning Network
Feature Learning Network는 figure2에서 처럼 voxel partition, grouping, random sampling, stacked voxel feature encoding, sparse 4d tensor과정을 거친다.
[voxel partition]
주어진 sparse한 3d point cloud를 일정한 공간(equally space)의 voxel로 voxelize해준다. DxHxW의 point cloud 갯수를 가질 때, [D’, H’, W’] = [D/vD, H/vH, W/vW] 크기의 voxel grid로 쪼개짐.


[Grouping]
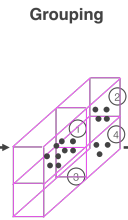
sparse하고 density variance가 심한 3d point cloud 특성상 하나의 voxel grid에 있는 points를 같은 group으로 grouping한다. 당연히 비어있는 voxel도 존재하게 된다.
[Random Sampling]
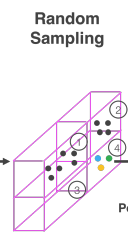
보통 LiDAR point cloud는 1 frame당 10만개의 points를 가지기 때문에 많은 computational cost를 요구하고 highly variable point density의 요인이 된다. 따라서 random하게 T를 설정하여, T개 이상의 points를 가지는 voxel에서 T개의 points를 sampling하여 computation을 줄이고 voxel에서 point imbalance를 줄였다.
[Stacked Voxel Feature Encoding]
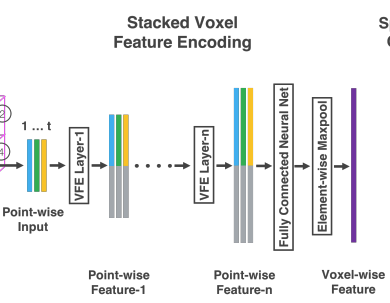
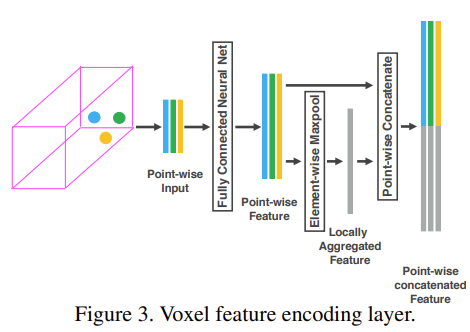
본 논문에서 VFE(Voxel Feature Encoding) layer를 적용했는데 2개를 연속적으로 적용한 것이 핵심이다. LiDAR data는 (x, y, z, r)의 형태로 구성되는데 r은 LiDAR에서 나온 beam이 반사된 세기(reflectance)를 의미한다. 우선 voxel 내 local points를 기준으로 centroids의 mean V = (vx, vy, vz)을 구한다. 그리고 각각의 point(i)들에 대한 상대적인 위치를 augment하여 Pi = (xi , yi , zi , ri , xi −vx, yi −vy, zi −vz)로 표현한다. 이렇게 얻은 P를 FCN(linear, bn, ReLU로 구성)을 통과시켜 feature space로 변환시킨다. 이렇게 얻은 point-wise feature는 voxel 내부의 surface형태가 encode된다. point-wise feature를 element-wise maxpooling을 통해 voxel 내부의 feature들을 aggregate하여 각 voxel마다 locally aggregated feature를 얻는다. 그리고 point-wise feature와 locally aggregated feature를 concate하여 output feature를 생성한다. 만약 point가 없는 빈 voxel도 같은 방법으로 encode하고 FCN parameter는 share한다. 이렇게 VFE layer를 2번 통과하여 얻은 point-wise feature는 voxel 내부 points들의 shape information을 학습할 수 있고, 이후 FCN과 element-wise maxpooling을 통과시켜 voxel-wise feature를 얻게 된다.
[Sparse Tensor Representation]

LiDAR point cloud는 sparse한 특징이 있기 때문에 90% 이상이 empty voxel이라고 한다. 만약 C x D’ x H’ x W’의 4차원 tensor로 나타내면 backpropagation 시 메모리와 연산량 측면에서 손해이기 때문에, non-empty voxel에 대응하는 feature들을 list형태로 관리하는 sparse tensor representation을 사용한다.
Convolutional Middle Layers
ConvMD(cin, cout, k, s, p)로 M-dimension convolution operator를 표현한다.
– cin, cout : input, output channel 수
– k : kernel size
– s : stride
– p : padding size
각 convolutional middle layer는 3d convolution, bn, ReLU를 순차적으로 거친다. ConvMD로 voxel-wise features를 합쳐 점차 receptive field를 넓혀 더 많은 shape description에 대한 context를 추가한다.
Region Proposal Network
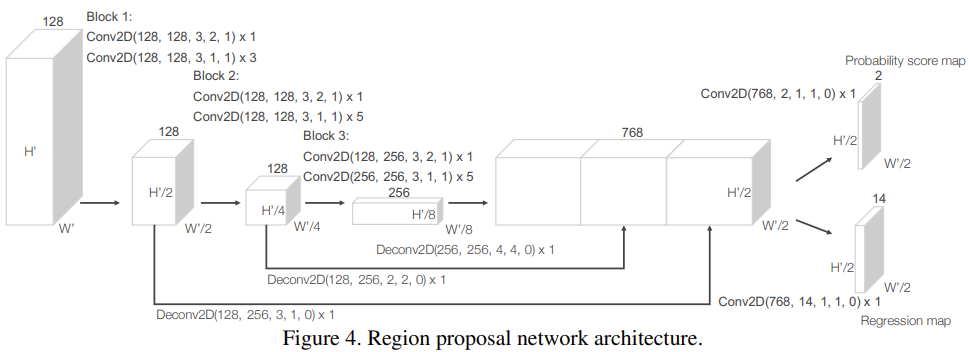
RPN에서 수정을 통해 feature learning network와 convolutional middle layer를 결합하여 end-to-end 학습이 가능한 pipeline을 만들었다. input은 ConvMD로 만들어진 feature map이고 network는 fully convolutional layers로 구성된 3개의 blocks로 구성된다. 각 block의 첫 번째 layer는 feature map을 1/2로 downsampling한다. 다른 layer들은 크기를 유지한다. 각 conv layer를 통과한 후 bn, ReLU를 거치게 된다. 각 block을 통과한 output은 일정한 fixed size로 upsample한 후 concate하여 high resolution feature map을 얻게 된다. 이렇게 생성된 feature map은 probability score map과 regression map으로 mapping된다. 여기서 3d convolution을 통해 4d feature map이 생성되어야할텐데 2d convolution이 나와 의아하게 생각할 수 있다. z축 방향을 없앤 3차원으로 reshaping하여 bird’s eye view형태 feature map으로 만들어주었기 때문이라고 한다.
Loss function
3D gt box에 대한 parameter는 (xgc , ygc , zgc , lg , wg , hg , θg )로 표현된다.
– xgc , ygc , zgc : center location
– lg , wg , hg : 각각 box의 length, width, height
– θg : z축 기준 yaw rotation
gt box와 matching된 positive anchor와의 차이(regression)는 아래 식과 같이 계산된다. da는 anchor box의 diagonal을 의미한다.
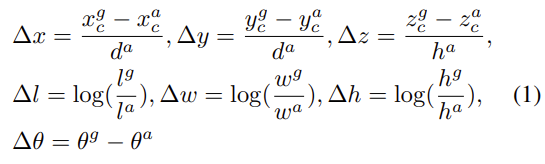
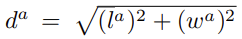
전체 loss는 아래와 같다.
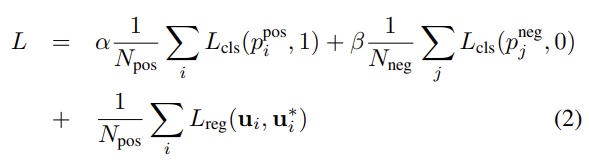
– {aposi }i=1…Npos : positive anchor
– {anegj }j=1…Nneg : negative anchor
positive, negative anchor 모두 loss에 사용된다. pposi와 pnegj는 각각 positive, negative anchor의 softmax를 취한 output이다. ui와 ui∗는 각각 regression output, positive anchor에 대한 gt이다. 처음 두 항은 각각 positive, negative anchor 수로 normalize한 classification loss로 binary cross entropy loss를 적용하였고, 실험에서 α, β는 각각 1.5, 1을 사용했다. 마지막 항은 regression loss로 smooth L1을 사용하였다.
Efficient implementation
GPU는 dense tensor처리에 최적화 되어있기 때문에 sparse한 point cloud나 voxel마다 variable한 point를 가지는 경우 처리하기 비효율적이라고 한다. 그래서 stacked VFE(Voxel Feature Encoding)을 이용하여 dense tensor로 바꾸어 voxel에서 병렬 처리가 가능하도록 했다고 한다.
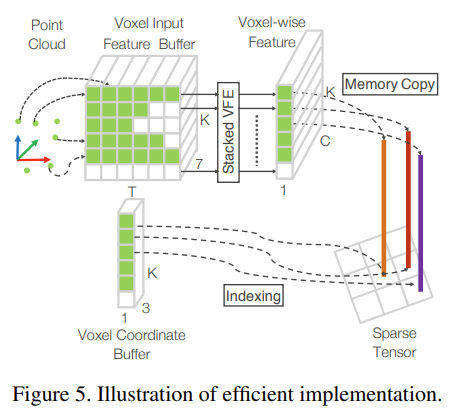
먼저 K x T x 7 크기의 Voxel input Feature Buffer와 K x T x 1 크기의 Voxel Coordinate Buffer를 초기화 해준다. 여기서 T는 voxel 당 가질 수 있는 최대 point 수, K는 non-empty voxel의 최대 갯수이고 7은 input encoding parameter(x,y,z,r,x-vx, y-vy, z-vz)를 의미한다. random한 points를 voxel location에 넣어주는데 이때 설정한 T개보다 작은 points가 들어가게되고 나머지는 무시된다.
이후 각 point마다 돌아가며 해당 point가 포함된 voxel이 초기화 되지 않았다면 voxel 좌표를 voxel coordinate buffer에 추가하고, point를 voxel input feature에 해당하는 위치에 넣어준다.
이렇게 생성된 voxel input feature buffer를 stacked VFE에 넣어 dense한 tensor구조로 연산할 수 있고 GPU에서 병렬 처리가 가능하다. 만약 빈 voxel의 경우 0으로 채워 연산한다.
VFE를 거쳐 얻은 voxel-wise feature는 기존에 생성되어있던 voxel coordinate buffer를 이용해 feature들을 다시 3d voxel grid로 mapping 가능하다.
해당 과정을 통해 sparse한 point들을 정해진 형태를 가지는 tensor형태로 처리할 수 있고, 해당 feature를 다시 mapping하는 과정으로 GPU 연산 효율을 높였다.
Training
KITTI 데이터에서 정의하는 LiDAR 좌표계는 위를 +z, 좌측을 +y, 전방을 +x로 정의한다고 한다. 그리고 KITTY 3d object detection task에서 (z, y, x)의 범위를 object class마다 다르게 정의한다.
– Car에 대해서는 (z, y, x) 범위 [−3,1] X [−40,40] X [0,70.4]로 정의
– Pedestrian, Cyclist에 대해서는 [−3,1] X [−20,20] X [0,48]로 정의
pedistrian, cyclist가 car보다 좁은 범위를 보는 이유는 pedestrian, cyclist가 더 작기 때문에 거리가 멀면 너무 작은 point를 가지기 때문이라고 한다. 또한 image에서 보이는 object에 대해서만 labeling되어 있기 때문에, image에 projection했을 때 범위를 벗어난 point는 무시한다고 한다.
본 논문에서는 (vD, vH, vW)를 (0.4, 0.2, 0.2)로 정의했다.
3d bounding box의 parameter는, Car의 경우(l, w, h)를 해당 논문에서는(3.9, 1.6, 1.56)으로 세팅하였다. θ는 0~2π의 범위로 나타나며 하나의 anchor로는 이 범위를 전부 커버하기 어려우므로 각각 0, 90 degree의 θ를 갖는 anchor 2개를 각 위치마다 사용한다. 위에 RPN그림에서 보면 probability score map과 regression map의 channel 수가 각각 2, 14인 것을 확인할 수 있다. gt와 anchor사이의 IoU가 Car는 0.65, Pedestrian와 Cyclist는 0.5보다 높으면 positive로 하고 0.35보다 낮으면 negative로 정하게 된다. 0.35보다 크거나 0.5보다 작으면 don’t care로 처리 했다고 한다.
data augmentation방법으로는 크게 3가지를 적용했다고 한다. 이 부분은 어떻게 적용한 것인지 정확히 이해하지 못했다.
1. gt bbox에 perturbation을 적용 -> bbox의 center를 중심으로 [−π/10, π/10] uniform distribution에서 sampling한 각도만큼 rotation시킨 후 (x,y,z) 방향으로 각각 평균이 0이고 표준편차가 1인 Gaussian distribution에서 sampling한 값만큼 translation을 수행(개별 box에 대해).
2. [0.95, 1.05] uniform distribution에서 sampling한 수만큼 모든 GT bbox들과 전체 point cloud에 global scaling을 적용-> 다양한 거리, 다양한 크기를 갖는 object를 detect 할 수 있어 robustness.
3. [−π/4, π/4] uniform distribution에서 sampling한 각도만큼 GT bbox들과 전체 point cloud에 원점을 중심으로 global rotation을 적용(scene 전체에 대해).
Experiments
KITTY 3D object detection benchmark를 사용했고 7,481개의 images와 point cloud로 구성된 train data와 7,518개의 images와 point clouds로 구성된 test data로 사용했다. category는 car, pedestrian, cyclist 이렇게 3개이며 각 class마다 object size, occlusion, truncation level에 따라 easy, moderate, hard 3개의 difficulty로 나누어 결과를 얻었다. AP(average precision) metric을 사용하여 평가하였다.
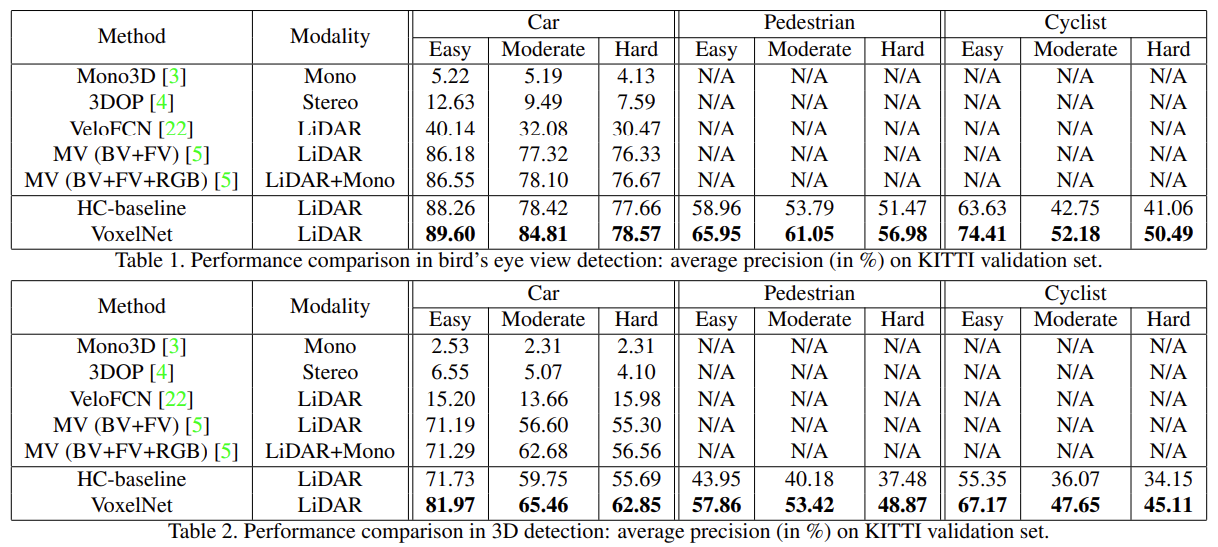
KITTY validation set에서 bird’s eye view, 3d detection에 대해 비교했을 때 sota를 달성했다. 2d plane에서 localization의 정확도만 고려하는 bird’s eye view와 달리 더 까다로운 3d task에서도 좋은 결과를 보였다. Car에 대한 IoU는 0.7, pedestrian과 cyclist에 대한 IoU는 0.5로 설정했다. 추가로 image기반(mono, stereo) 모델보다 LiDAR기반 모델이 더 좋은 성능을 보이는 것을 알 수 있다.

visualization도 잘 된 것을 확인할 수 있다.
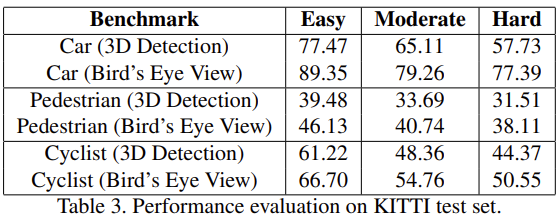
official server에서 진행한 KITTY test set에 대한 평가에서도 모든 difficulties(easy, moderate, hard)에서 sota를 달성하였다.
본 논문은 3d object detection을 survey하면서 접하게 되었습니다. 3d point cloud를 처리하는 다양한 방식 중 voxel형태로 처리하는 방법론으로 앞으로 최신 논문까지 다양한 방법론들에 대해 알아보려고 합니다. 감사합니다.
좋은 리뷰 감사합니다.
애플의 페이퍼라니 신기하네요. 제가 이해하기로는 기존 연구에서는 이 Voxel이러는 개념을 적용하지 않은 것 같은데 맞나요? 그렇다면 실험 테이블 리스트 중 voxelnet을 포함하여 테이블을 가로줄로 나눈 이유는 이 voxel 사용 여부가 맞나요?
두번째로 차보다 사람의 AP가 낮은데 어떤 측면에서 이렇게 다른 결과가 나온지도 궁금합니다.
질문 감사합니다.
기존 연구에서도 voxel의 개념이 도입되었습니다. 하지만 3d point cloud를 voxel형태로 바꾸기 위해 hand-crafted algorithm을 사용했지만, 본 논문에서는 end-to-end형식의 detector를 설계했다고 합니다.
테이블에서 가로줄을 나눈 기준은 voxel여부는 아닙니다. Mono3D, 3DOP는 image영상을 사용하고 VeloFCN은 3d point cloud를 voxel형태로 처리해서 사용하고 MV는 multi-modal을 사용합니다. 가로줄 위에 부분은 기존에 존재하는 다양한 Modality의 방법론과 비교한 것이고, 가로줄 아래는 hand-crafted feature extraction을 baseline으로 하여 본 논문에 적용된 region proposal network의 강점과 비교하기 위해 나누어놓은 것 같습니다.
사람의 ap가 낮은 부분에 대해 논문에서 언급하고 있지는 않지만, 개인적인 생각으로는 car에 비해 크기가 더 작고(cyclist도 동일한 이유라고 생각합니다) sparse한 3d point cloud특성에 더해져 낮은 성능을 보인다고 생각합니다.
좋은 리뷰 감사합니다. voxel라는 개념이 생소한데 덕분에 잘 이해하녔습니다.
point cloud가 sparse하고 point density하다는 말을 일부분에만 밀접하게 point가 있고 나머지 공간에는 point가 별로 없다는 걸로 이해하였는데 맞을까요?
질문 감사합니다.
네. 말씀하신 것처럼 3d point cloud가 sparse한 특징이 있어 애초에 별로 많은 data가 들어오지 않고, voxel공간에서 보았을 때 빈 voxel이 더 많이 생기게 됩니다.