Before Review
Video 진영에도 GPT, BERT라고 할만한 Foundation Model이 등장한 것 같습니다.
결과만 놓고 보면 39가지의 데이터 셋을 가지고 평가하여 모든 SOTA를 갈아치웠습니다.
개인적으로는 아쉬운 점도 나름 있지만 좋은 연구 인 것 같습니다. 리뷰 시작하겠습니다.
Introduction
Image나 Text 분야에서는 이미 여러가지 Foundation Model 들이 등장하고 있습니다.
Text 같은 경우는 대표적으로 GPT나 BERT를 예시로 들 수 있습니다. GPT는 autoregressive 형태로 다음 단어를 계속 예측하는 형태로 문제를 풀고 BERT는 단어를 마스킹하고 예측하는 형태로 문제를 해결합니다. 이러한 방식은 이제 100억개의 파라미터를 가지는 대용량 모델에도 일반화된 표현을 학습시키는 것이 가능하게 만들었습니다.
이미지 같은 경우는 요즘 뜨고 있는 MAE가 되겠네요. MAE는 random 하게 마스킹된 패치의 부분을 reconstruction 하는 과정을 통해 이미지 도메인을 관통하는 일반적인 표현 학습을 가능하게 만들었습니다.
그런데 비디오의 경우는 아직 이렇다 할 Foundation Model이 등장하고 있지 않습니다. 이에 저자는 본인들이 처음으로 Video Foundation model을 제안합니다.
그런데 사실 Intro에는 별 할 얘기가 없습니다. 왜냐하면 저자가 어떠한 문제를 정의하고 이를 해결할 수 있는 참신한 insight를 제공하는 것은 아니기 때문입니다. 그냥 놓고 보면 대용량의 데이터 + 요즘 잘나가는 Encoder 이게 전부이기 때문입니다.
그럼에도 결과 자체는 굉장히 인상 깊습니다. 아래 그림을 보면 이전 SOTA 대비 성능 개선 정도를 보여주고 잇습니다.
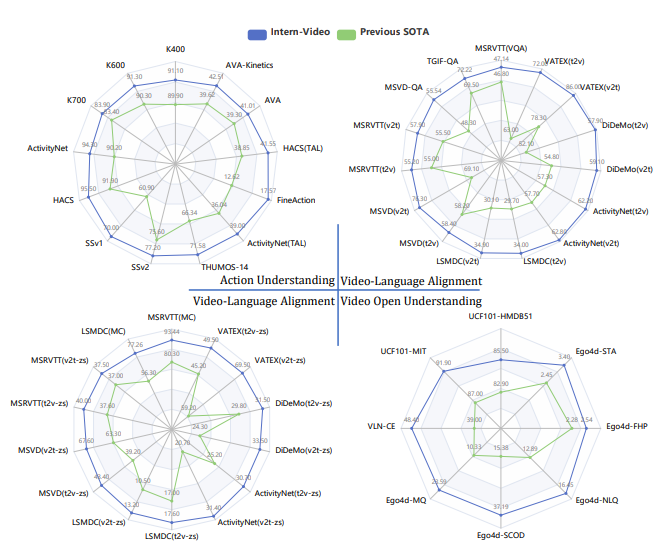
방법론 자체에는 novelty가 없다 하더라도 이 정도로 다양한 데이터 셋에서 평가를 진행한 것 자체는 굉장히 좋은 연구라 생각이 듭니다.
Method
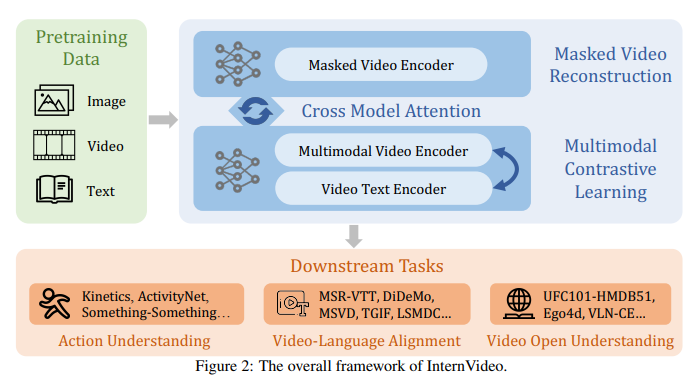
전체 framework 입니다. 학습은 크게 두 가지의 형태로 진행됩니다.
- Video MAE를 통한 clip reconstruction, 그냥 VideoMAE 그대로 사용했다고 보시면 됩니다.
- CLIP의 구조를 그대로 사용하지만 Video Encoder를 본인들이 제안하는 Uniformerv2로 대체
그리고 이 두 가지의 학습 방식을 Cross model attention하여 조금 더 일반화된 feature 를 기대하는 것이죠.
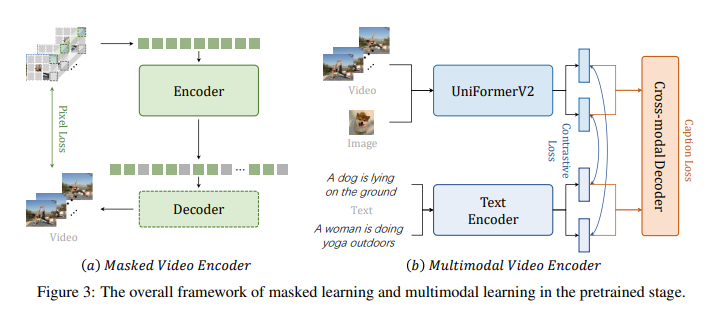
정말 이 부분은 드릴 말씀이 없는데 Masked Video Encoder는 제가 이전에 리뷰 한 VideoMAE 의 task를 그대로 사용했습니다. Pixel Reconstruction 이니 논문에서는 Generative Self-Supervised Learning이라 표현합니다.
Mutli-modal Video Encoder는 예전에 이현주 연구원이 작성한 CLIP이라는 논문의 구조를 그대로 사용하지만 Video의 Encoder는 ViT가 아닌 본인들이 제안하는 Uniformerv2를 사용합니다. CLIP은 간단히, 이미지 + 비디오 와 텍스트를 같은 공간으로 보내서 (Multimodal) representation learning을 수행하는 모델이라 생각하시면 됩니다.
저자는 여기서 Video Masked Modeling(VideoMAE) 과 Video-Language Contrastive Learning(CLIP)을 기반으로 좀 더 unified 된 video representation을 얻기 위해 cross model attention module을 추가합니다. 아래의 그림 처럼 말이죠.
여기서 두 Video Masked Modeling(VideoMAE) 과 Video-Language Contrastive Learning(CLIP) 백본은 freeze를 시킵니다. 사전 학습은 각각 따로 일단 진행한 상황이죠.
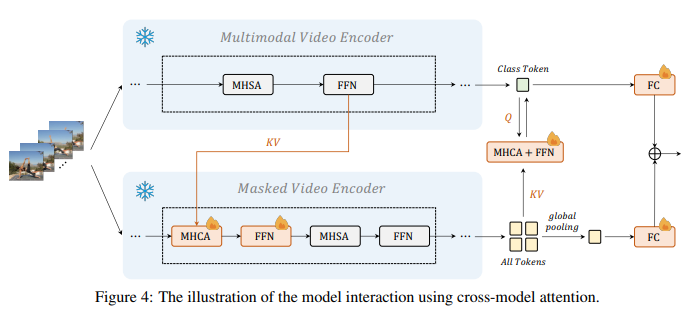
간단히 말해서는 Multi-Head Cross Attention + Feed-Forward Network로 수행됩니다. 여기서 Multi-modal video Encoder로 부터 나오는 class token은 query의 역할을 하고 Masked Video Encoder로 나오는 Token 들을 key, value로 가정하고 말 그래도 attention 연산 하는 것입니다. 이 과정을 통해 class token이 업데이트 됩니다.
그림을 보면 마지막에 FC Layer를 각각 태우고 더해주는 데 이것이 결국 어디에 활용이 되나면 Action Recognition에 활용됩니다.
저자는 Self-Supervised Pretraining + Post Supervised pretraining 을 해 InternVideo를 완성 시킵니다.
다시 정리하면 Self-Supervised pretraining은 Video Masked Modeling(VideoMAE) 과 Video-Language Contrastive Learning(CLIP) 각각 진행하고 cross modal attention을 위해 Post Supervised Learning을 진행합니다.
마지막에 FC 태우고 linear combination을 하면 score vector가 나오니깐 이를 가지고 action classification task를 하는 것입니다.
방법론은 이게 다입니다. 보시면 알겠지만 저자의 방법론은 이미 다 연구가 되어 있는 것들을 그냥 잘 조합 시킨 것에 불과합니다. 저자만의 insight나 novelty가 없는 것은 분명히 아쉬운 점입니다.
Experiments
실험 입니다. 결국 본 논문의 Method에는 사실 크게 Novelty가 있다고 볼 수는 없고 실험 부분이 중요하다고 볼 수 있습니다. 근데 실험도 그냥 다 성능이 높다 정도로 서술이 되어 있습니다. 사실 그래서 조금 지루합니다. 별다른 분석이나 insight는 찾아볼 수 없어서 조금 아쉬웠습니다.
실험 전체에 대한 저의 생각은 Conclusion에 담도록 하겠습니다.
Data for Pretraining
Kinetics-710 : 저자가 쓴 다른 논문인 Uniformer version2에서 새롭게 제안된 Kinetics-710을 사용했다고 합니다. 650,000개의 비디오를 가지고 있으며 710개의 unique action category를 포함하고 있는 데이터 입니다. 이 Kinetics-710은 supervised post training 과정에 사용됐다고 합니다. 즉, supervised post training에는 Kinetics만 사용된 것이죠.
Unlabeled Hybrid : 여러가지 public benchmarking data들을 섞은 데이터 셋 입니다. Kinetics-710 + Something-Something V2 + AVA + WebVid2M + 저자가 직접 모은 비디오 라고 하네요.
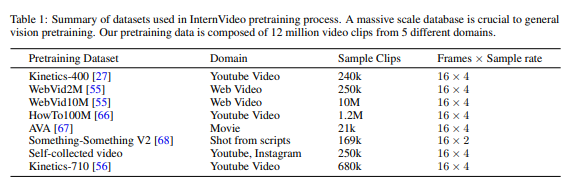
위의 테이블을 보시면 각각의 데이터 셋 도메인과 개수, 그리고 sampling ratio 까지 확인할 수 있습니다. 핵심은 저기에 있는 모든 데이터를 다 사용했다는 것이죠. 어마 어마 합니다.
Implementations
Multi Modal Training
위에 테이블에도 나와 있지만 Mutlimodal Training을 위해서는 WebVid2M, WebVid10M 그리고 HowTo100M 이라는 데이터 셋을 가지고 진행했다고 합니다. 여기서 Video-Text dataset은 CLIP-400M 만큼 풍부하지 않기 때문에 저자는 LAION-400M이라는 데이터의 subset을 추가로 활용하여 학습에 사용했다고 합니다.
음.. 다 처음 보는 데이터 셋 들이고 다 하나 하나 찾아보면서 어떤 성질이 있는지 파악하기는 너무 오래 걸릴 것 같아 일단 설명은 여기까지 하도록 하겠습니다.
Masked Video Training
VideoMAE-Huge 모델을 가지고 아까 위에서 설명한 UnlabeledHybrid라는 데이터 셋을 가지고 1200 epoch, A-100(64G) x 80개를 가지고 학습을 했다고 합니다. 원래 이런 detail은 리뷰에 따로 안 적는데 scale이 말이 안되는 것 같아서 적었습니다.
아마 저희 연구실에서 원복 실험은 못하겠네요.. ㅎㅎ
Down stream Task
다양한 down-stream task에 대해 InternVideo의 generality를 실험하고 있습니다.
Action Understanding Tasks
Action Recognition
비디오 연구의 가장 기본이 되는 Action Recognition 입니다.
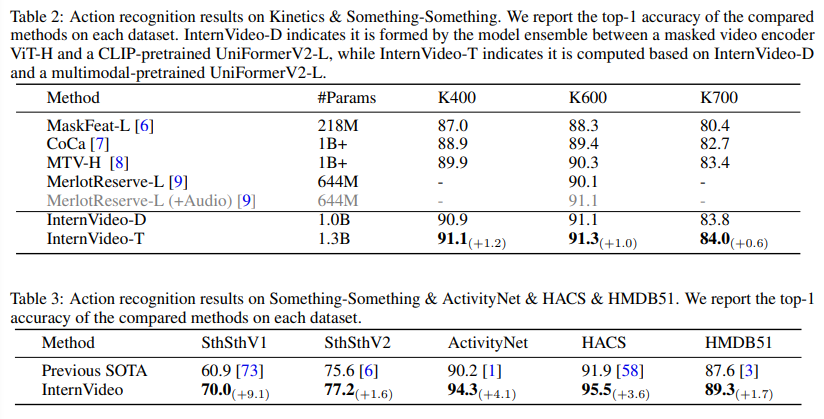
InterVideo D와 T의 차이는 테이블 위에 캡션에 잘 정리되어 있습니다. 성능이 높네요. 근데 본문의 내용도 그게 다입니다. 별 다른 분석이나 insight를 담은 내용은 없네요.
Temporal Action Localization
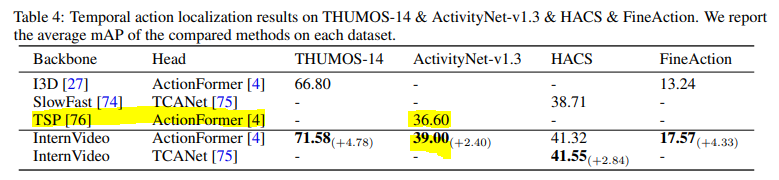
다음으로는 제가 즐겨 리뷰 했던 Temporal Action Localization에 대한 평가 입니다. 흥미로운 점은 TSP라고 해서 저희 지금 에트리 연구에서 사용하고 있는 Feature 대비 더 높은 성능을 보여주고 있습니다. TSP가 사전 학습도 ActivityNet으로 하고 평가도 ActivityNet으로 진행 하였는데 InternVideo의 사전 학습에는 ActivityNet이 존재하지 않았습니다. 물론 데이터의 scale은 훨~씬 크지만요…
저는 이 리포팅을 보고 일단 InternVideo가 제공하는 사전 학습 feature를 사용해보기로 결정했습니다.
Saptiotemporal Action Localization
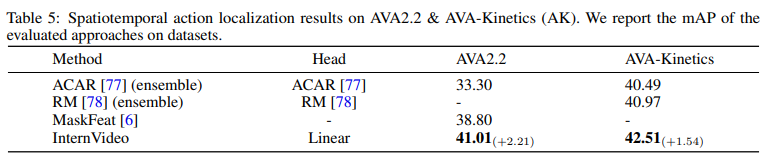
spatiotemporal action localization은 action을 하고 있는 주체인 사람에 대한 bounding box 까지 치는 조금 더 어려운 task 입니다. 그리고 갑자기 설명이 없었던 AVA-Kinetics라는 데이터 셋이 등장하는 데 찾아보니 AVA+Kinetics 데이터셋인 거 같습니다. 저자는 AVA-Kinetics라는 데이터셋에서 성능이 더 높은 것을 보고, 결국 Kinetics dataset을 추가하는 것이 AVA dataset을 이해하는데 도움이 되는 것 같다고 얘기합니다.
Video-Language Alignment Tasks
다음으로는 Multi-modal understanding task 입니다. 요즘 굉장히 많은 연구가 진행되고 있는 분야입니다.
Video Retrieval
비디오 검색입니다. 텍스트를 던져서 비디오를 찾거나 비디오를 던져서 텍스트를 찾는 연구 입니다. 개인적으로 텍스트를 던져서 비디오를 찾는 건 이해가 되지만 비디오를 던져서 텍스트를 찾는 건 어디에 활용이 가능할까요?
무튼 InternVideo는 Video Retrieval 에서도 좋은 성능을 보여줍니다.
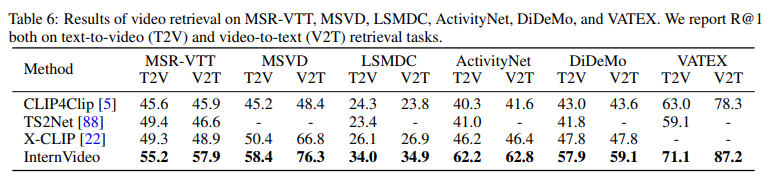
down-stream 실험의 전반적인 세팅은 CLIP4Clip의 세팅을 따라 하였다고 합니다. 그 정도의 디테일은 리뷰에서 따로 다루지 않겠습니다.
Video Question Answering
Video Question Answering은 제가 리뷰에서 따로 다룬적이 없으니 어떤 task 인지 간단하게 소개하도록 하겠습니다. 굉장히 어려운 task라 볼 수 있는데, Video와 Question Text를 Pair로 입력으로 던집니다. 그리고 Deep learning model은 Question에 맞은 Answer를 Video를 보고 reasoning 해야 하는 것이죠.
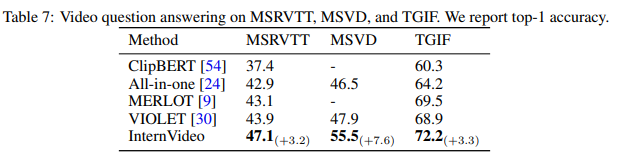
VQA라는 굉장히 semantic한 task에 대해서도 InternVideo는 효과적인 모습을 보여줍니다. 그런데 평가는 어떻게 진행하는 걸까요? 이에 대한 설명은 나와있지 않아 후에 VQA 논문을 읽을 때 자세히 다루도록 하겠습니다.
Video Open Understanding Tasks
zero-shot 이나 open-set에 대한 실험도 진행하였습니다.
zero-shot learning or open-set recognition 이란 train set에 포함되지 않은 unseen class를 예측하는 연구 분야 입니다.
Zero-shot Video Retrieval

조금 헷갈리는 게 zero-shot video retrieval이랑 그냥 video retrieval이랑 차이가 무엇인지 궁금하네요. 다른 task들은 다 설명해주는데 왜 또 여기는 설명을 안 하는 건지..ㅎㅎ
무튼 zero-shot task 에서도 좋은 성능을 보여주면서 제안된 방법론의 generality를 강조합니다.
Zero-shot Multiple Choice

zero-shot multiple choice라는 task 도 model의 generality를 확인하는 데 많이 하는 task 라고 합니다. Multiple choice라는 것은 다지 선다 문제를 푸는 것이라 보면 됩니다. 특히나 zero-shot multiple choice 에서는 성능 향상 폭이 굉장히 크네요.
다른 task에 비해 성능 향상 폭이 굉장히 큰데 이에 대한 별다른 설명이 없어 아쉽습니다.
Open-set Action Recognition
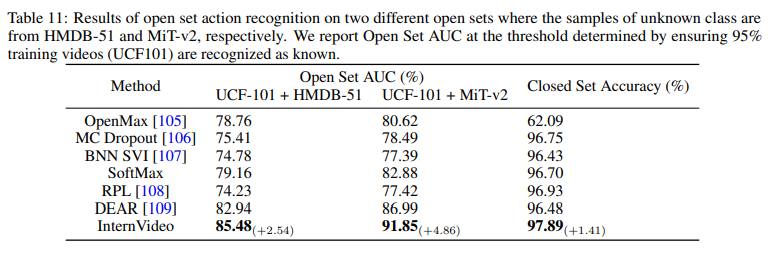
학습 과정에 보지 못한 action class 에 대해 unknown class라 예측하는 문제 입니다. 특히나 video 분야에서의 open set 문제는 이미지에 비해 더욱 어려운 task라 여겨진다고 하네요.
위의 실험 들을 통해 InternVideo는 Closed Set과 Open Set 모두 효과적인 feature representation을 학습 한 것을 알 수 있었습니다.
제가 리뷰를 쓴 걸 보면 뭐지 이 사람 대충 썼나 싶을 수 있는데 정말 리뷰에 쓸 내용이 없습니다..
논문 포맷 자체는 NIPS인데 NIPS2022에 없는 걸 보면 떨어진 거 같은데 왜 떨어진지 조금은 이해가 가는 거 같습니다. 방법론 자체에는 novelty가 전혀 없고 단순히 데이터와 연산을 때려 박은 논문 인 것 같습니다. 실험에도 여러 task에 대한 정량적 평가만 진행 했지 이에 대한 분석은 진행하지 않아 아쉬웠습니다. 아마 성능이 높은건 그냥 데이터를 엄청 많이 사용했으니 당연한 수순이 아닌가 싶습니다.
Conclusion
실험의 내용을 보니 기막힌 방법론을 가지고 천하를 평정한 논문 인줄 알았으나 그냥 데이터 쏟아붓고 GPU 때려 박아서 만들어진 결과들이라 괴리감이 드네요. 뭐 요즘 딥러닝 연구가 그러한 상황이긴 합니다.
요즘 ChapGPT, DALLE, 등등 대용량 모델이 많은 주목을 받고 있는 상황입니다. 이러한 연구들의 공통점은 초 대용량의 데이터 + computing resource 이죠. 이러한 흐름 속에서 저희는 어떤 연구를 해야 하는지 고민을 하게 만드네요.
아무튼 논문의 결과 자체는 굉장히 인상적이라 에트리 올해 베이스라인 선정으로 적합할 것 같습니다.
리뷰 읽어주셔서 감사합니다.