안녕하세요. 이번 x-reivew는 임근택 연구원이 추천해준 논문 “data2vec: A General Framework for Self-supervised learning in Speech, Vision, and Language” 입니다. 요즘에 올라오는 리뷰마다 self-supervised 키워드가 붙어 있는 경우가 많은데 저도 드디어 self-supervised 논문을 리뷰하게 되었네요. 앞서서 많은 연구원님들께서 self-supervised learning에 대해 자세하고 친절한 설명을 하셨으니 저는 self-supervised learning 자체 보다는 “멀티 모달”에 집중하여 멀티 모달에서 어떻게 self-supervised learning을 하는지에 대해서 설명하도록 하겠습니다.
<Intro>
이 논문의 contribution을 한마디로 말하자면 “modality에 상관없이 self supervised learning을 진행할 수 있다” 입니다. 논문의 Introduction에서는 self supervised learning이 사람이 만든 정답 없이 데이터 자체에서 만들어진 정답을 학습하는 방법임을 간략히 설명합니다. 또한, self supervised learning이 현재 여러 모달리티(이미지, 텍스트, 음성 등)에서 잘 작동하고 있다고 말합니다.
하지만 지금까지 방법론들은 특정 모달리티에서의 self supervised learning에 집중했기 때문에 특정 모달리티에 적용한 방법(알고리즘, 학습 방법)을 다른 모달리티에 적용하기 힘듭니다. 왜냐하면 모달리티의 특정 target을 예측하도록 만들어졌기 때문입니다. 특정 타겟을 예를 들자면, NLP에서는 단어 token을, Computer Vision에서는 visual token을 예로 들 수 있습니다. visual token을 예측하는 self supervised learning 방법에서 단어 token을 예측하는 것은 힘들겠죠?
data2vec에서는 이를 간단한 방법으로 해결합니다. 모달리티의 특정 target (word, visual token, units of human speech)를 예측하는 것이 아닌 input의 information을 가지는 contextualized latent representation을 예측하는 것입니다. 이를 통해서 data2vec에서는 모달리티에 상관없이 self-supervised learning을 수행할 수 있습니다. contextualized latent representation에 대해서는 이후에 더 자세히 설명하도록 하겠습니다.
<사전 지식 정리>
멀티모달 논문이라고 패기롭게 달려들었지만 정말 읽는데 생각보다 많은 시간이 걸렸습니다… 제 기준으로 생각했을 때 논문을 이해하기 위해 사전에 알아야할 것들이 있다면 뭐가 있을까 작성해봤습니다.
- Exponential Moving Average (EMA)
최근에 높은 가중치를 주지만, 오래된 과거도 비록 낮은 영향력이지만 가중치를 부여하도록 고려한 방법입니다. 더 자세한 내용은 잘 정리된 글이 있으니 참고해주시면 감사하겠습니다. 이 글의 EMA를 설명한 글을 일부 가져와서 작성하면 아래와 같습니다.
EMA는 시계열 데이터에서 window size만큼을 고려해 지역적인 평균을 구합니다. noise를 보다 효과적으로 줄여주고, 합리적인 분석을 가능하게 해준다고 합니다.
- BYOL (Bootstrap Your Own Latent A New Approach to Self-Supervised Learning)
제 리뷰에서는 등장하지는 않지만 BYOL 방법과 많이 유사하다고 합니다. 이미 황유진 연구원이 리뷰한 글이 있으니 참고해주시면 좋을 것 같습니다.
<method>
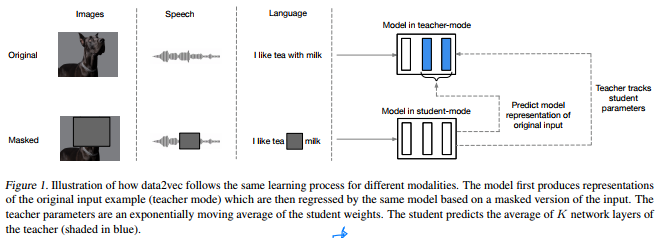
data2vec은 input의 partial view가 주어졌을 때 전체 input data의 model representation을 예측함으로써 학습됩니다. Figure1을 통해 그림으로 확인할 수 있습니다.
전체적인 학습 과정은 아래와 같습니다.
1)full input을 이용한 represenation을 2)partial input을 이용하여 예측하는 문제를 풉니다. 학습되는 모델은 하나만 존재하며, Teacher, Student두 개의 모드로 동작할 수 있습니다. Teacher 모드의 경우, 모델 파라메터의 exponential moving average 값으로, Student모드의 경우 모델 파라미터를 그대로 이용합니다.
<model archtecture>
data2vec에서는 인코더로 transformer 구조를 사용하였습니다. 각 modality별로 인코더의 입력을 구성하는 방식이 다릅니다.
- image의 경우, 16×16 영역의 픽셀을 하나의 토큰으로 인코딩합니다. (ViT 전략 방식 이용)
- speech의 경우, multi-layer 1-D convolution neural network를 이용하여 16kHz wavwform을 50Hz representation으로 맵핑합니다.
- Text의 경우, sub-word 단위로 전처리를 한 뒤에 이를 embedding vector로 인코딩하였습니다.
<Masking>
각 모달리티의 입력이 토큰의 시퀀스(Transformer 입력의 형태)로 embedding된 후에, Student의 입력으로 이용하기 위해 maskng을 수행합니다. masking은 시퀀스(입력 단위)의 일부를 학습가능한 MASK으로 embedding token으로 대체하여 진행합니다. Figure1을 통해 masking의 예를 확인할 수 있습니다. 모달리티 별로 인코딩 입력이 달랐던 것처럼 여기서도 모달리티 별로 masking 방식을 설명할 수 있습니다.
- image feature의 경우, block-wise masking 전략(BEiT 방식)으로 masking 합니다
- 텍스트의 경우 토큰 중 일부를 masking 합니다. (BERT의 masking 방식으로 masking 합니다)
- 음성의 경우 latent speech representation의 span을 masking 합니다.
<Teacher parameterization>
[method] 부분에서 Teacher 모드가 모델 파라메터의 Exponentially Moving Average(EMA)로 구성된다고 말씀 드렸습니다. Teacher의 가중치를 Δ라고 표현한다면 식은 아래와 같습니다.
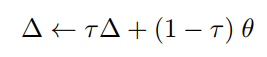
τ는 학습 진행정도에 따라 스케쥴하여 사용하였는데요. 첫 τ_n가 업데이트 하는 동안(즉, 학습의 첫 n번의 업데이트 동안) τ_0에서 τ_e까지는 선형적으로 증가하고 그 이후부터는 constant로 유지됩니다. 왜 이렇게 설정하는 걸까요? 이유는 아래와 같습니다.
학습의 시작부에서는 random으로 파라미터가 초기화되어 있기 때문에 τ를 작게하여 변화를 더 많이하게 하고, 파라미터가 어느정도 학습된 이후에는 τ를 크게하여 변화를 적게 반영하기 위함입니다.
논문의 저자분들이 말하길, 이 방법이 teacher와 student network 간의 feature encoder와 positional encoder의 파라미터를 공유하는 것보다 아주 약간 성능이 좋게 나왔다고 합니다.
<Targets>
모델은 masked sample의 인코딩을 base로 하여 unmasked training sample의 model representation을 예측하도록 학습됩니다. masked된 model representation을 예측하는데, 이 representation는 self-attention으로 인해 contextualized 합니다. (contextualized representation)
training target(학습하고자 하는 타겟; 학습 타겟)은 student mode에서 masking된 time-step에 대한 teacher network의 상위 K개의 block의 output을 기반을 구성됩니다.
time-step이 t일 때의 l번째 block의 output은 a^l_t라고 표현하다고 했을 때 아래와 같은 과정으로 target 값을 구셩합니다.
- 각 block에서 normalization을 적용하여 \hat{a^l_t}을 얻습니다.
- L개 block의 output 중에서 상위 K개의 output의 평균을 취합니다. (the top K blocks y_t = \frac{1}{K}\sum_{l=L-K+1}^L \hat{a^l_t} for a network with L blocks in total to obtain the training target y_t for time-step t)
이렇게 하면 student mode에 있을 때 모델이 regress할 training target이 만들어집니다.
target을 normalizing하는 것은 모델이 모든 time-step에 대해서 constant representation으로 collapsing된는 것을 방지하도록 합니다.
<objects>
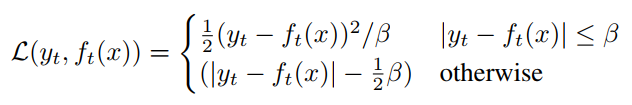
주어진 contextualized trainng target인 y_t과 student의 output f_t(x)에 대해서 Smooth L1 loss를 이용하여 regression을 수행합니다.
β를 이용하여 경계선을 컨트롤하는데, target값과 output 값의 차이가 β보다 작거나 같으면 L2 loss를 이용하고, 차이가 크면 L1 loss를 이용한다. 이러한 loss를 사용하면, outlier의 덜 민감하다는 장점이 있지만 β를 튜닝해야한다는 단점이 있다고 합니다.
<Experiment Results>
실험 결과는 각 모달리티 별로 측정하였습니다. Table1~3을 통해 data2vec의 성능을 확인할 수 있습니다.
computer vision
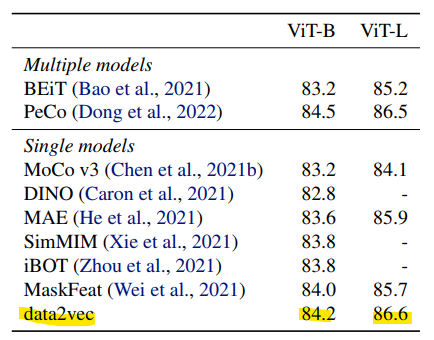
ImageNet-1K를 이용하였고, 모델은 ViT-B와 ViT-L을 이용하여 성능을 측정하였습니다. [Table 1]을 보시면 data2vec의 성능이 single models에서 가장 좋은 것을 확인할 수 있습니다.
Speech and Audio Processing
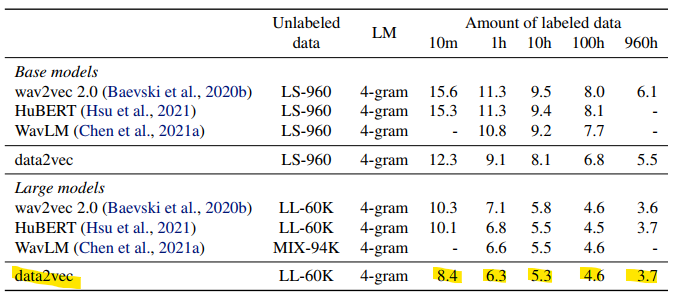
Librispeech (LS-960) 벤치마크(960 시간의 오디오 데이터)를 이용하여 성능을 측정하였습니다. 이 벤치마크는 영어로된 오디오북을 낭송한 데이터로 깨끗한 음성이 들어있다고 합니다. speech에서도 역시나 성능이 좋은 것을 확인할 수 있습니다.
Natural Language Processing

GLUE 벤치마크를 이용하여 성능을 측정하였습니다. 월등한 성능은 아니지만 BERT와 Baseline인 RoBert에 준하는 성능을 보이는 것을 확인할 수 있습니다. [+wav2vec 2.0 masking]은 4개의 연속된 토큰을 masking하는 방식인데 이를 적용하여 사전학습 했을 때 성능이 더 좋은 것을 확인할 수 있습니다.
여태까지 x-review를 많이 작성한 것은 아니지만 가장 어려웠던 리뷰인 것 같습니다. 중간 중간에 굉장히 많은 reference들이 등장하면서 이해하는 것이 굉장히 어려웠던 논문이었던 것 같습니다. 이 때문에 리뷰도 잘 작성하지 못한 것 같아 아쉽습니다. 그래도 논문에서 굉장히 친절하게 reference를 달아주었고, 유명한 방법론들을 많이 사용하였기 때문에 reference를 타고 들어가면 굉장히 유의미한 공부가 될 것 같습니다.
부족한 리뷰 읽어주셔서 감사합니다.
리뷰 잘 읽었습니다.
transformer를 사용하는 것이라 적혀있는데 modality별로 transformer가 따로 존재하는 건가요? 하나만 존재해서 모든 modality의 입력을 커버하는 것인가요? 개인적으로는 후자인거 같은데 좀 더 자세히 설명해주시면 감사하겠습니다.
댓글 감사합니다.
후자라고 생각하는 것이 좋을 것 같습니다. 이 논문에서는 standard한 transformer을 사용하는 것을 굉장히 강조하는데 모달리티 별로 인코딩 방식을 달리 가진다는 것이 차이가 있습니다
감사합니다
좋은 리뷰 감사합니다.
해당 논문은 그럼 모델은 동일하지만 결국 모달 별로 각각 학습해야하는게 맞나요?
그리고 테이블 2는 실험이 어떻게 진행된건가요? Unlabeled data 로 두 개의 데이터셋 실험 결과가 리포팅 된거 같은데 두 데이터셋 차이가 뭔지 그리고 두 데이터셋이 어떻게 다르길래 성능차이가 발생한 것인지도 궁금합니다.
마지막으로 혹시 기존 Speech 분야에서는 어떤식으로 self-supervised 기법이 적용되고 있을까요? 멀티 모달이 올해 목표인 만큼 이런 연구에 팔로업을 해두는 것도 좋겠지만, 각 모달 별 self-supervised learning 기법이 어떻게 적용되고 있는지를 이해한 뒤 이 논문을 다시 읽게되면 또 다른 인사이트를 얻을 수 있지 않을까 싶습니다.
댓글 감사합니다.
1) 네 맞습니다. 모델은 동일하지만 결국에는 모달 별로 각각 학습을 시킵니다.
2) 테이블 2에서 사용한 데이터셋은 3개의 데이터셋이 있는데요. 설명은 아래와 같습니다.
—————————-
* LibriSpeech (LS-960): 960시간의 오디오 데이터로 구성된 오디오북 데이터셋 입니다. 상대적으로 clean한 음성으로 구성된 데이터셋이라고 합니다.
* Libri-light (LL-60K) : 이것 역시 LS-960과 마찬가지로 오디오북 데이터셋 입니다. 그런데 60K 시간의 unlabelled speech과 small labelled 데이터셋(10h, 1h and 10min,,,)으로 구성되어 있습니다.
* MIX-94K : 94k 시간의 오디오 데이터셋 입니다. LibriLight, VoxPopuil와 GigaSpeech가 섞인 데이터셋인데 찾아보니 이 논문에서 제안된 데이터셋인 것 같습니다(https://arxiv.org/pdf/2110.13900.pdf)
—————————-
논문을 리뷰하면서 이 데이터셋에 어떤 차이가 있어 성능 차이가 발생하는지 깊게 생각하지 못한것 같습니다. 단순하게 생각하면 데이터셋 크기 차이로 인해 성능 차이가 발생한다고 생각할 수도 있을 것 같습니다. 이 부분에 대해서는 다시 한번 생각해보겠습니다.
3) Speech 분야에서의 self-supervsed learning 방식으로 wav2vec 2.0와 HuBERT 이 제일 유명하다고 합니다. wav2vec 2.0에 대해서 간단히 설명 드리자면, data2vec에서 contextualized latent representation을 예측하는 것처럼 마찬가지로 wav2vec 2.0에서도 wavwform을 cnn을 통해 latent speech representation을 얻습니다. 이를 quantizer(양자화 모듈)와 transformer에 넣는데 이때 마스킹을 진행해서 넣습니다. 얼추보면 data2vec과 진행방식이 비슷한 것을 확인할 수 있습니다. 제 생각에는 wav2vec 또한 페이스북에서 나온 논문이기 때문에 이것을 발전시켜 data2vec이 나온 것은 아닌가 싶습니다.
저도 이번 논문을 읽을 때 굉장히 시간이 오래걸리고 이해하는 것이 힘든 부분이 많았는데 그것이 각 모달 별 self-supervised learning 기법을 잘 모르기 때문이 아닌가 합니다. data2vec 논문에서 각 모달별로 유명한 self-supervised learning 기법을 언급해주기 때문에 이를 가이드 삼아 읽어보겠습니다.
감사합니다
좋은 리뷰 감사합니다.
결국 modality마다 따로 학습을 시켜야하는 거죠?
그리고 제가 speech와 같은 language model에 대해 잘 몰라서 그러는데 table2에서 LM column의 4-gram은 무엇을 의미하는지 간단히 설명해주시면 감사하겠습니다!
댓글 감사합니다.
1) 결국 modality마다 따로 학습을 시키는 것이 맞습니다.
2) 4-gram은 N-gram에 N=4인 것을 말합니다. N-gram은 n개의 연속적인 단어 나열을 의미합니다. 갖고 있는 단어에서 n개의 단어 뭉치로 끊어서 이를 하나의 토큰으로 간주합니다. 예를 들어서 “나/는/너/를/사랑해”라고 단어들이 있다면 n=2일때는 “나는/너를/사랑해”이렇게 보고, n=4라면 “나는너를/사랑해” 이렇게 합쳐 볼 수 있습니다. N-gram 언어모델을 자세히 알고 싶으시다면 https://wikidocs.net/21692을 참고하시면 좋을 것 같습니다.
감사합니다.