이번에 소개드릴 논문은 네이버 랩스 유럽팀에서 연구한 CroCo라는 논문입니다. 분야는 핫하디 핫한 Masked AutoEncoder(MAE)를 기반으로 한 Self-supervised learning 연구이며, 네이버 랩스다 보니 3D Geometry 분야에 초점을 맞춘 MAE라고 생각하시면 될 것 같습니다.
Intro
논문에서 하고자 하는 방법론과 내용은 상당히 단순합니다. 기존 MAE의 경우에는 ImageNet과 같은 object-centric dataset으로 학습을 진행하였기 때문에 Image classification이나 object detection과 같은 high-level semantic task에서 상당히 좋은 모습을 보여주고 있습니다. 이러한 high-level의 semantic information을 활용한다는 것은 영상의 global 정보를 주로 활용한다고 볼 수도 있습니다.
여기서 저자는 이러한 object-centric dataset에 사전 학습된 MAE가 depth estimation이나 optical flow와 같은 3D vision task에서도 훌륭하게 transfer할 수 있는지에 대한 의문을 가지게 되었으며, 3D Vision task에 더 최적화된 Masked auto modeling 기법들을 제안하고자 했습니다.
그도 그럴 것이, 3D vision task의 경우에는 대부분 high-level의 semantic information보다는 local information이 더 필요할 뿐만 아니라 두 영상들간에 geometry, spatial relationship에 대해서 아는 것이 중요하기 때문이죠.
따라서 저자는 unlabeled data를 통해 3D geometry를 학습할 수도 있도록 하는 그림1과 같이 새로운 self-supervised learning, Cross-view Completion(CroCO)라는 방법론을 제안합니다. Croco의 학습 방식은 MAE 기반이기 때문에 상당히 단순합니다. 먼저 학습에 사용할 입력 영상은 한 쌍의 이미지로, 각각의 영상은 모두 동일한 장면에 대해서 서로 다른 viewpoint로 촬영된 것입니다.
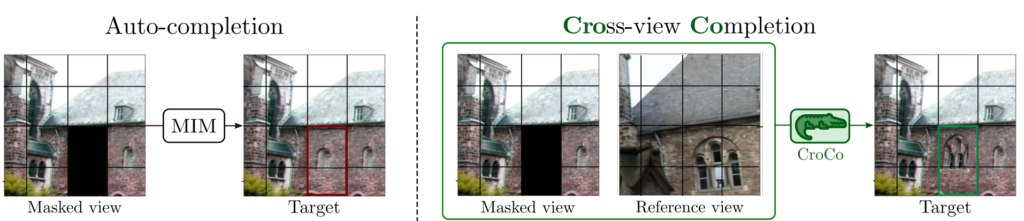
여기서 첫번째 이미지의 경우에는 기존의 MAE와 동일하게 Masking되는 patch와 visible patch로 나뉘게 되며, 모델의 입력으로 visible patch만을 사용하게 됩니다. 그리고 결과적으로 masked patch를 reconstruction하는 것이 목표입니다. 여기까지만 놓고 보면, 기존 MAE와 다를 것이 없어 보이지만 큰 차이점은 바로 그 뒤에 설명할 내용입니다.
첫번째 이미지와 쌍을 이루는 두번째 이미지는 어떠한 masking을 하지 않은 체, ViT 기반의 Encoder의 입력으로 들어갑니다. 이 두번째 영상을 encoding하여 추출한 token은 첫번째 visible token들과 함께 decoder에서 활용하여 첫번째 영상의 masked token을 reconstruction하는 것입니다.
저자는 한장의 이미지만으로 reconstruction하는 기존 MAE 방법론들은 아무래도 참고할 수 있는 정보라고 해봤자, 극히 적은 수의 visible token밖에 없으므로 모델의 학습 방향이 영상의 high-level sementic information에 초점을 맞춘다고 합니다.
반면에 Croco와 같이 두 영상 사이의 co-visibility가 존재하게 되면, 이러한 reference image에서의 정보를 토대로 target image의 mask token을 reconstruction 할 수 있다 보니, 모델이 semantic information에 초점을 두기 보다는 두 영상의 geometry, spatial relationship을 조금 더 고려할 수 있다는 것이죠.
그리고 한가지 더 재밌는 점은 Reconstruction 방식을 통해 pretraing한 후 학습에 사용한 디코더를 제거 및 인코더만 finetuning하는 기존의 MAE와 달리, 특정 분야에 따라 Croco의 디코더는 버리지 않고 pretraining에 사용했던 것 그대로를 그대로 재활용할 수 있다고 합니다.
이는 Decoder에 Cross-attention layer 연산이 들어가 있기 때문에, source imaeg와 target imaeg 간에 연관성을 중요하게 보는 분야들(Stereo depth estimation, optical flow 등등)에서 Croco의 decoder를 충분히 활용할 수 있고, 실제로 좋은 성능을 보여주었다고 합니다.
물론 monocular imaeg만을 활용하는 분야들(image classification, object detection)에 경우에는 기존 MAE와 동일하게 Decoder는 제거하고 Encoder만을 fine-tuning할 수 도 있지요.
Method
그럼 이제 Croco의 학습 방식, 구조 등에 대해서 조금 더 자세하게 다뤄보겠습니다. 사실 MAE 논문들이 다 비슷한 것이 loss function도 MSE로 상당히 단순하기 때문에 method 부분에서 자세히 설명하게 없긴 하지만요^^;;
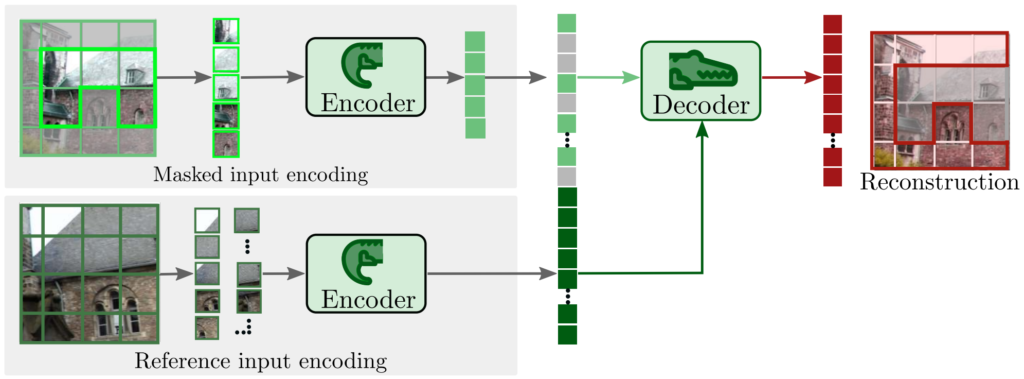
먼저 CroCo의 전체 구조는 그림 3과 같습니다. 입력으로 주어지는 두 영상을 각각 x_{1}, x_{2}라고 부를 것이며, 이 두 영상은 서로 동일한 장면에 대하여 서로 다른 view point를 가지고 있습니다. 그리고 각각의 이미지들은 모두 N개의 겹치지 않는 영역들로 쪼개져 token으로 활용이 되며, x_{1} 의 경우에는 masking이 적용됩니다.
이 때 마스킹을 통해 영상을 가리는 비율은 전체 영상 중 90%를 masking을 하게 됩니다. 기존 MAE가 75%정도 마스킹을 하는 것과 비교하면 상당히 더 큰 비율로 masking을 수행하는 것인데, 저자는 90% 비율로 마스킹을 하였을 때 가장 좋은 성능을 보여주었다고 말합니다. 해당 내용은 뒤에 실험 섹션에서 다시 다루겠습니다.
아무튼 90% 비율로 x_{1}에 대하여 랜덤하게 마스킹을 수행하며, 반대로 reference image인 x_{2}는 masking을 일절 적용하지 않습니다. 그리고 나서 이 각각의 non-overlapping patch를 각각 p_{1}, p_{2} 라고 하였을 때, 이들을 각각 encoder 및 decoder에 태워서 masking된 patch \hat{p}_{1} 을 reconstruction 합니다.
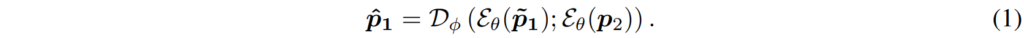
여기서 \mathbf{D} 는 Decoder를, \varepsilon는 Encoder를 의미합니다.
여기서 사용된 encoder의 경우에는 잘 아시다시피 ViT를 활용하였으며, 입력 영상이 p_{1}, p_{2}로 두 장이라 하더라도 동일한 encoder를 사용하여 encoding 합니다. 즉 weight shared encoder를 활용한다는 것이죠. 논문에서는 실험에서 224 x 224 해상도에 패치 사이즈는 16 x 16을 활용했다고 합니다.
Decoder
디코더의 경우에는 크게 2가지의 타입에 대해서 실험을 진행하였다고 합니다. 이게 아무래도 p_{1} 뿐만 아니라 p_{2} 에 대한 정보도 잘 녹여서 reconstruction을 해야하기 때문에 각각의 정보들을 디코더에서 어떻게 융합할 것인지에 대하여 고민하다보니 디코더의 구조를 2가지로 나눠서 실험을 진행한 듯 보입니다.
먼저 첫번째 디코더 구조는 CrossBlock이라는 명칭으로 (1) multi-head self-attention, (2) multi-head cross-attention, (3) MLP 의 순서를 가지고 있습니다. 여기서 첫번째 self-attention은 첫번째 이미지에 대한 토큰들만을 입력으로 넣어서 진행되며, 두번째 cross-attention 부분에서 2번째 이미지와 첫번쨰 이미지 사이에 토큰을 서로 정보교환?한다고 보시면 될 것 같습니다. 그리고 나서 MLP을 통해서 디코딩 연산을 수행하는 것이구요.
두번째 디코더의 구조는 CatBlock이라는 명칭을 가지며, (1) 먼저 각각의 영상에서 추출된 토큰들( p_{1}, p_{2} )을 concatenate한 후 흔히들 알고 있는 평범한 트랜스포머 블록을 연속으로 적용해주면 됩니다(즉 Self-attention과 MLP로 구성된 block들)
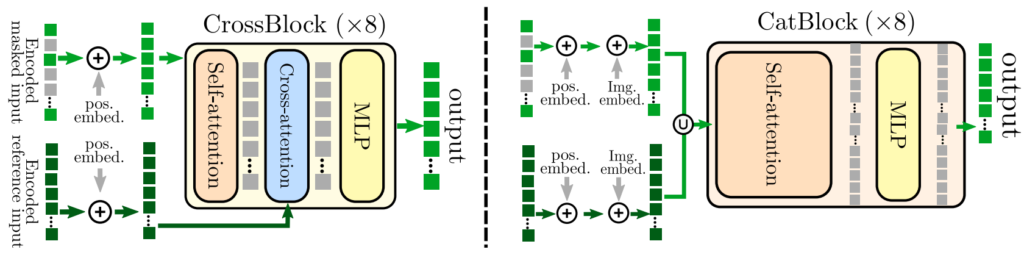
이 두 attention decoder block은 서로 model size와 연산량 관점에서 장단점을 뚜렷하게 지니고 있습니다. CrossBlock의 경우에는 Cross-attention이라는 레이어가 새로 생겼기 때문에, 모델이 학습해야할 파라미터 양이 증가하는(즉 모델의 사이즈가 커지는) 단점이 발생합니다.
반면에 CatBlock의 경우에는 모델의 크기가 늘어나지는 않지만, Self-attention 연산 전에 두 영상에서의 토큰을 concat하기 때문에, attention 연산시 계산해야할 연산량이 제곱으로 늘어나게 되는 것입니다. 따라서 메모리는 적지만 연산 속도가 상당히 느려지는 단점이 발생합니다. 뒤에 실험 섹션에서도 다시 말씀드리겠지만, 결론적으로 논문에서는 CrossBlock을 활용합니다.
Experiments
먼저 Croco는 기존 MAE와 달리 동일한 장면에 대해 서로 다른 viewpoint로 촬영한 pair 이미지가 존재해야만 합니다. 그래서 논문에서는 학습 데이터로 3D 합성 indoor scene들을 활용했다고 하는데, 각각 HM3D, ScanNet, Replica, ReplicaCAD Dataset 등을 활용했습니다.
이러한 3D scene들 중에서 저자는 두 영상의 co-visibility가 50%이상이 되는 카메라 뷰포인트를 가지는 100개의 페어들을 샘플링하였으며, Habitat simulator를 사용하여 렌더링을 진행하였다고 합니다. 최종적으로 논문에서는 1,821,391 쌍의 영상들을 렌더링하여 모델 학습에 사용했다고 합니다.
Ablation
먼저 논문의 ablation study 결과부터 살펴보겠습니다. 첫번째 ablation 실험은 masking ratio 관련된 내용입니다. 아까 본문에서도 말씀드렸다시피, masking ratio를 90%를 하였을 때 가장 좋은 성능을 보여준다고 했었는데, 실제로 transfer learning할 때 ADE Segmentation, NYU depth estimation 그리고 다양한 multi-task가 존재하는 taskonomy 데이터 셋에서 모두 90% masking을 하였을 때 가장 좋은 성능들을 보여주고 있습니다.(아래 그림 참조)
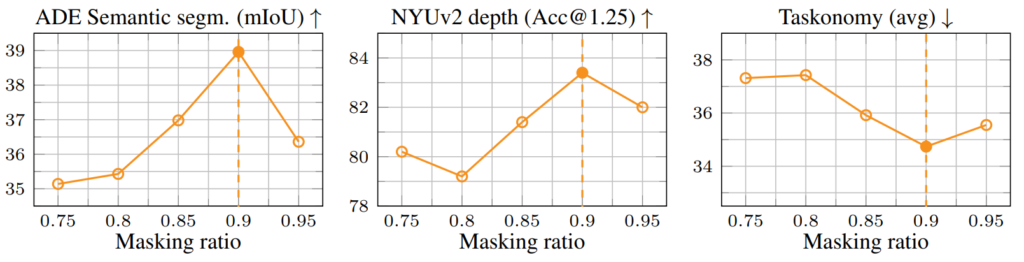
저자는 이렇게 많은 수의 패치를 마스킹해도 좋은 성능을 보여준 것에 대하여, reference image로부터 상당량의 정보들을 제공받기 때문에 오히려 masking을 70%정도로 하는 것보다 90%하는 것이 더 유의미한 결과를 가져올 수 있었다고 합니다.
Normalized targets
해당 내용의 실험은 매우 단순한데, 그저 pre-training 과정 중 RGB 영상을 reconstruction할 때 해당 RGB 영상이 mean과 std로 normalization이 되었는지 아닌지에 대한 비교 실험입니다.
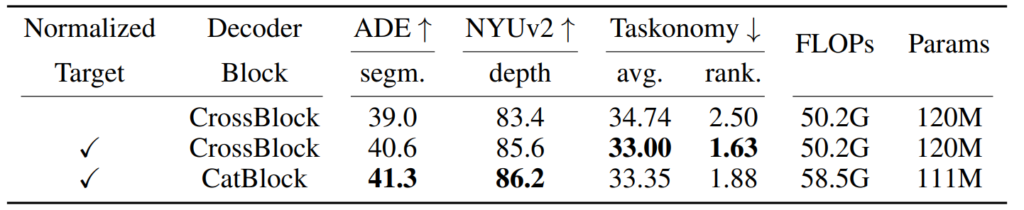
위에 표를 보면 결과적으로 target image를 normalize하는 것이 그렇지 않은 것보다 모든 데이터 셋에서 더 좋은 성능을 달성하였음을 보여줍니다.
Decoder architecture
다음은 decoder architecture에 따른 정량적 비교 결과입니다. 위에 normalize 여부에 따른 실험 결과(표1)에서 마찬가지로 decoder block의 종류에 따른 성능 비교를 확인하실 수 있게 됩니다.
먼저 표1의 2번째 행과 3번째 행을 중점적으로 보시면 되는데, 2번째 행의 CrossBlock의 경우에는 Cross-attention layer가 추가적으로 존재하므로, CatBlock과 비교하여 약 9M정도의 학습 파라미터 수가 증가합니다.
하지만 CatBlock의 경우에는 Self-attention 연산 전에 p_{1}와 p_{2} 를 먼저 concatenate한 후 Self-attention을 수행하므로, p_{1} 만을 Self-attention하는 CrossBlock보다 더 많은 양의 attention 연산을 수행하게 됩니다.
따라서 학습해야 할 파라미터 수는 더 적음에도 불구하고 FLOPs의 경우에는 8.3G로 더 큰 모습임을 확인 가능합니다. 물론 디코더 구조에 따른 성능 차이도 존재하긴 합니다만, 성능이 항상 일관성 있게 차이가 나는 것이 아닌, 데이터 셋의 종류에 따라서 반대의 경향성을 보이고 있습니다.
구체적으로 CatBlock을 적용한 경우 ADE 20K 데이터 셋과 NYUv2 데이터 셋에서 더 좋은 결과를 보여주고 있지만, 반대로 Cross-Block의 경우에는 Taskonomy 데이터 셋에서 더 좋은 성능을 보여주는 모습입니다. 논문에 저자는 최종적으로 Cross-Block을 채택한 모습인데, 아무래도 학습해야 할 파라미터 수 보다는 추론 속도 측면이 더 중요하기 때문에 CrossBlock 구조를 채택한 것으로 생각됩니다.
Training Pairs
다음은 학습 데이터 쌍을 구성하는 방법에 대한 설명입니다. 본문에서도 밝혔듯이, Croco는 real 데이터가 아닌, 합성 데이터를 통해 학습을 수행합니다. 이는 두 영상이 동일 대상에 대하여 서로 다른 viewpoints를 가지는 대용량 데이터 셋의 부재로 인하여 합성 데이터 셋을 활용한 것이 아닐까 하고 저는 생각합니다.
아무튼 그래서 저자는 합성 데이터를 만들기 전에, 실제 RGB 영상 한장에 대하여 Geometry transformation(e.g., Homography, rotation, scaling, crop etc)을 적용해 인위적인 합성 pair image를 생성하고 학습하는 실험을 진행하였습니다.

해당 실험 결과는 표2에서 확인하실 수 있는데, 요약하면 다양한 조건의 two viewpoint 영상으로 학습한 결과와 달리 하나의 영상에 대해 랜덤한 변화를 통해 학습한 데이터 셋이 모든 데이터 셋에서 좋지 못한 결과를 보여주었습니다.
저자는 이러한 결과에 대해, 아무래도 pretraining 과정 중 모델이 두 영상 사이의 유의미한 spatial relation ship을 학습하는 것이 아닌, 그저 인위적인 쌍을 만들기 위한 랜덤 geometry transformation의 일정한 변환 분포를 외웠기 때문에 좋은 표현력을 사전 학습하지 못한 것으로 판단하였습니다.
이러한 결과를 토대로, 학습 영상 쌍을 어떻게 구성하면 좋은가?에 대해 저자는 나름대로 고민을 많이 한 것으로 보이며 결과론적으로 말씀드리면 대략 50%정도의 co-visibility가 보이도록 비율을 잡으면 모델의 pre-training이 잘 된다고 저자는 주장합니다.
이는 co-visibility가 너무 작게 될 경우 사실상 한 장의 영상을 입력으로 masking을 reconstruction하는 기존 MAE와 유사하게 학습이 되던지, 혹은 반대로 co-visiblity가 너무 큰 경우 모델이 reference 영상으로부터 많은 양의 정보를 받아 너무 쉽게 reconstruction하기 때문에 encoder 자체의 표현력이 줄어들게 됩니다.

표 3은 여러 방법론들과 Croco 사이에 정량적 결과를 비교한 표입니다. 보시면 DINO와 같은 discriminative 기반 방식이 Classification과 같은 high-level infomration 정보가 필요한 분야에서 좋은 성능을 보여주고 있습니다.
다만 이러한 결과는 pixel level prediction인 segmentation과 Depth estimation 등에서 DINO보다는 CroCo가 훨씬 더 좋은 모습들을 보여주고 있습니다. 실제로 표3을 다시 살펴보시면, 1등(bold체)과 2등(밑줄)을 CroCo가 대부분 차지하는 모습입니다.

또한 재밌는 점은 기존 MAE와 달리 CroCo는 사전 학습된 디코더를 그대로 fine-tuning 시에 활용할 수 있으므로 위에 표와 같이 Optical FLlow에서 우수한 성능을 달성한 모습입니다. 비록 저 MPI-Sintel clean 데이터 셋에서 비교 실험하는 최신 Optical Flow 논문들은 CroCo의 clean 기준 3.0의 성능을 가뿐히 뛰어넘긴 하지만, 논문에서는 pre-training 과정 중에서 학습시킨 디코더를 활용할 수 있다는 점, 또한 학습 방식이 MAE와 같이 매우 심플하다는 점 등등 여러 이점들을 어필하고 있습니다.
결론
MAE 논문들의 공통점이 컨셉 자체는 그리 어렵지는 않지만 실험적인 측면에서 매우 꼼꼼하고 그럴 듯한 분석을 수행하는 것처럼 느껴졌습니다. 저도 이 쪽 관련에서 실험을 진행하고 싶은데 데이터 셋과 GPU 등 이슈로 걱정이 많네요 허허;
아무튼 기존의 단순히 RGB 영상에서의 feature representation 뿐만 아니라, MultiMAE부터 시작해서 CroCo까지 정말 다양한 논문들이 각 분야 별로 성능을 이끌 수 있도록 연구가 빠르게 진행되는 것 같습니다.
리뷰 잘 읽었습니다.
리뷰를 보면서 멀티스펙트럴에서 큰 효과를 보일 것 같다는 생각이 들었습니다.
데이터 셋만 충분히 구축된다면 꽤나 좋은 결과를 보일 것 같아요.
신정민 연구원의 생각은 어떠하신지 궁금합니다.
그리고 visible-lwir Re-ID에서는 다른 뷰포인트를 가진 페어한 멀티스펙트럴 영상 데이터를 이용합니다.
해당 데이터 셋을 이용해도 잘 작동할지 궁금합니다.
보행자를 기준으로 crop된 영상을 제공하기는 하나, 동적인 물체의 특성상 물체의 형상이 많이 틀어져서 잘 안될 것 같기는 한데…
이 또한, 신정민 연구원의 생각이 궁금합니다.
일단 CroCo에서 학습에 사용한 데이터 셋은 서로 다른 view point를 가지는 것은 맞으나 동일한 RGB 도메인을 활용합니다.
따라서 multispectral 데이터처럼 도메인이 다른 경우에도 잘 동작할지는 확신하기 어렵습니다. 다만 지난번에 리뷰로 작성한 MultiMAE랑 잘 융합하면 misalignment 상황인 Multispectral dataset에서도 잘 학습할 수 있지 않을까라는 생각을 할 수도 있을 것 같긴 합니다.
하지만 또 문제인 것이 CroCo에서 두 영상 쌍이 보는 co-visiblity가 적당한 비율에 매번 다른 뷰포인트를 가져야 학습이 잘 된다는 실험을 증명했기에.. 센서 셋업이 고정된 Multispectral setup에서 과연 좋은 효과를 볼 수 있을지 걱정이 들기도 하네요.
그리고 person re-id 데이터 셋의 경우에는 person에 한해서만 reconstruction을 하기 때문에 다른 downstream task에서는 잘 동작하지 않을 것 같지만, object detection 및 person re-id task 관점에 한해서는 해당 데이터 셋으로 CroCo 방식의 학습을 하면 오히려 좋은 pretrained weight으로 사용할 수 있지 않을까 합니다.