
오늘 리뷰할 논문은 RGB Night 상황에서 Semantic Segmentation을 수행할 때
효과적인 Domain Adaptation 을 통해서 성공적인 성능 향상을 이뤄낸 논문입니다.
원래는 미래 국방 과제의 follow up을 위해 depth 논문을 읽을 계획이였지만,
IPIU때 작업하던 Segmentation 연구를 좀 더 발전시켜 보자는 JM 연구원의 의견을 받아들여서
급하게 금요일 날 찾게 된 논문입니다.
간단히 Domain Adaptation을 적용시킨 Segmentation 논문인 줄 알았건만,,,,
Self-Training, 푸리에 변환, Curriculum Learning,,, 등 추가적으로 굵직한 방법론들이 여럿 적용이 되어서
꽤나 헤비한(?) 논문이였습니다.
그럼 리뷰 시작하도록 하겠습니다.
Introduction
현재 RGB 이미지를 사용해서 Nighttime Semantic Segmentation을 수행하는 많은 방법론들이 존재합니다.
본 논문에서 최종적으로 수행하고자 하는 task 또한 제목에서 볼 수 있듯이 Nighttime Semantic Segmentation 입니다.
우리는 흔히들 ‘밤이면 thermal 쓰면 되는거 아냐~?’ 라고 생각할 수 있지만,
RGB 센서만이 존재하는 환경에서는 thermal을 사용할 수 없기에 해당 연구가 필요하겠죠.
RGB 센서만을 사용해서 night에 성공적인 예측을 수행하기 위해선 모델을 어떤 식으로 설계해야 할까요?
RGB 센서의 경우 night 보다는 day에서의 장점이 더 부각되는 센서이기 때문에
day와 night을 잘 fusion 한다거나, day의 풍부한 정보를 night으로 전이(transfer) 하는 방식 또한 적용 가능하겠죠.
앞선 연구들 중 RGB day에 학습 된 모델을 RGB night에 그대로 사용하는 방법론이 존재하기는 했습니다만,
이는 RGB 센서의 특성 상 day와 night이 가지는 큰 gap 때문에 성능의 하락이 많이 생깁니다.
낮과 밤에서 우리가 봤을때도 확연히 볼 수 있는 시각적 정보 차이가 이에 해당합니다.
저자는 해당 gap을 huge domain divergence 라고 칭하구요.
그래서 해당 문제를 해결하고자 Nighttime Segmentation 에 Domain Adaptation을 적용한 연구들이 등장했습니다.
해당 연구들은 day에서 supervised 방식으로 학습 한 모델의 예측을 pseudo label로 설정하여 night에 전달하게 됩니다.
이때 단순히 전이(transfer) 하게 된다면 두 도메인 사이의 gap을 해결할 수 없겠지요??
그리하여 앞선 방법론들에서는 day와 night 사이에 twilight(일출? 일몰?) image를 추가하거나,
Synthetic nighttime image를 생성해서 두 domain사이의 큰 gap을 완화하고자 합니다.
intermediate domain을 생성해서 smooth knowledge transfer를 수행하는 것이지요.
(기존에는 계단 2칸을 한꺼번에 내려왔다면, 중간 계단을 생성해서 1칸씩 2번 내려오는 뭐 그런 느낌입니다.)
하지만 저자는 이러한 방식에도 문제가 있다고 언급합니다.
intermediate domain을 위해 추가적인 data나 network를 사용하게 된다는 것이죠.
(twilight image는 기존에는 사용하지 않았던, 새롭게 추가되어야 하는 data이기 때문이죠)
(또한 이러한 data를 처리하기 위해 추가적인 network 또한 필요합죠)
이러한 문제점을 해결하고자 저자는 Curriculum Domain Adaptation Method (CDAda) 라는 학습 방식을 제안합니다.
CDAda는 2가지 step의 Domain Adaptation을 통해 day와 night 사이의 domain gap을 완화하게 되는데,
각각에서의 gap을 inter-domain gap과 intra-domain gap 이라고 정의합니다.
그리고 이러한 2가지 step의 Domain Adaptation을 from-easy-to-hard domain adaptation 이라고 합니다.
이를 잘 나타내 주는 figure가 있어서 미리 첨부하겠습니다.
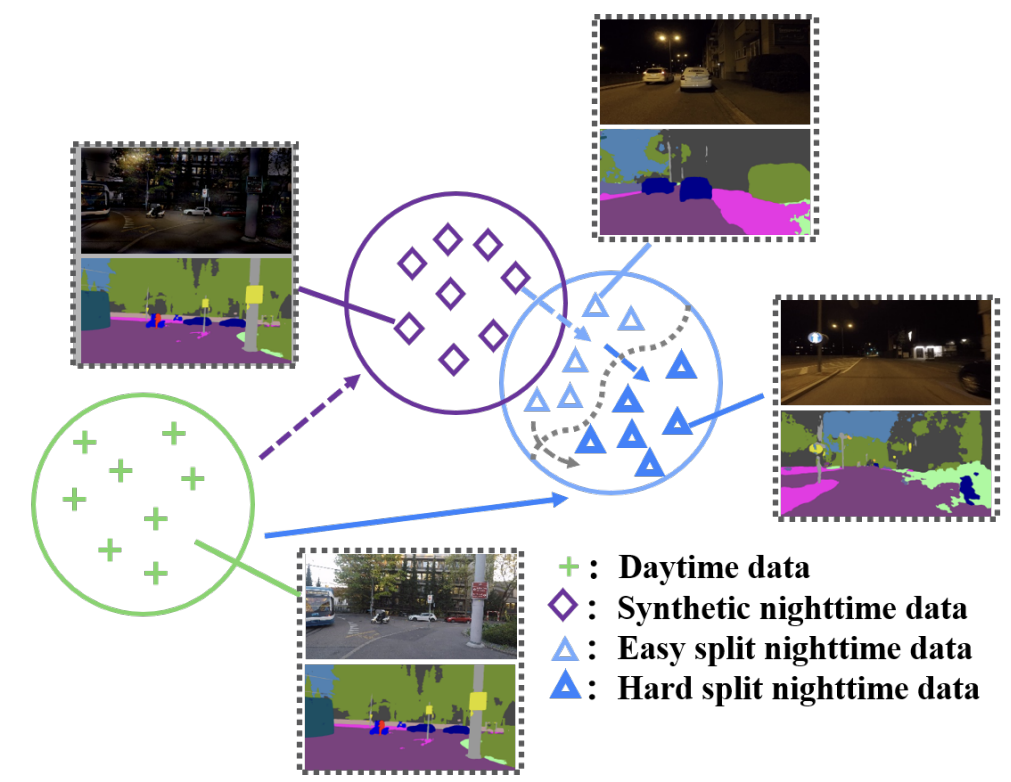
그림 1은 easy-to-hard domain adaptation을 시각적으로 표현 한 그림이고,
해당 그림의 legend를 보시면 4가지 종류의 data가 존재합니다.
위에서 아래의 방향으로, easy->hard 라고 보시면 됩니다.
본 논문에서 수행하고자 하는 task는 결론적으로 daytime 에서 nighttime으로 domain gap을 줄이면서 성공적인 domain adaptation을 수행하는 것입니다. 해당 그림에서 + 문양과 △ 문양은 특정 space에서 거리가 매우 멀지요?? domain gap이 크게 존재한다는 것이고, domain divergence가 크게 존재한다고 표현하기도 합니다.
Step 1 – IDSA (Inter Domain Style Adaptation)
우선 2가지 step의 Domain Adaptation 중 첫번째에 해당하는 부분입니다.
우선 그림 1에서 ◇ 문양으로 표시된, Synthetic nighttime data를 사용합니다.
앞선 방법론에서 추가적인 data를 사용한다는 문제점이 있다고 했는데 본 논문에서도 Synthetic(합성) data 라는 단어가 왜 나오는지 의문을 가질 수 있습니다.
물론 기존의 방식처럼 Synthetic nighttime data를 사용하긴 하지만, 그들과의 차이점은 Synthetic data를 학습하기 위한 추가적인 network를 사용하지 않는다는 겁니다. 이는 아래에서 더 설명 드릴 예정입니다.
어쨌든, 본 논문에서는 day와 night 사이의 징검다리 역할을 할 수 있는 Synthetic nighttime image를 생성 해 냅니다.
고속 푸리에 변환(FFT) 를 통해서 데이터를 생성 해 내는데, 그 과정은 아래 그림 2를 참고하시면 됩니다.
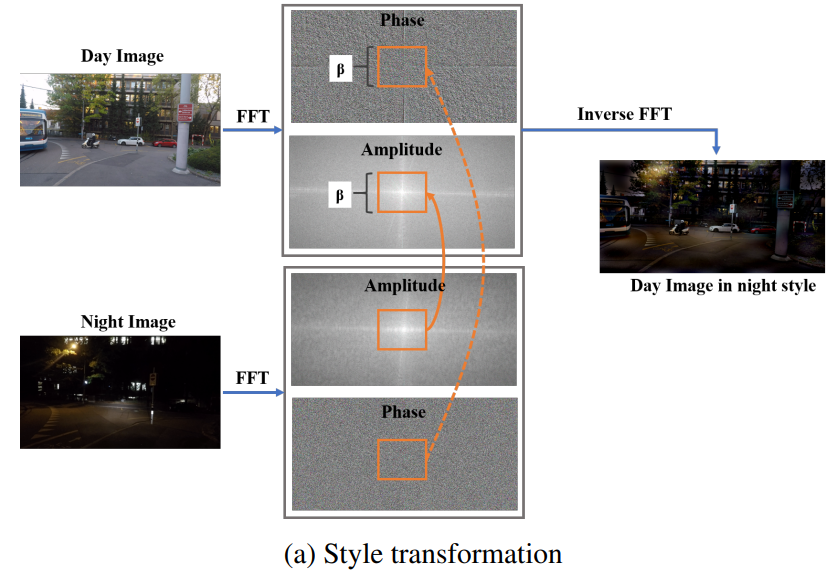
Synthetic image를 생성하기 위해서는 사실 생성 모델이나, image translation 등의 방법론 등을 통해 만들어 낼 수 있는데 저자는 FFT 를 사용하였습니다.
FFT란 영상, 음성 등의 신호를 주파 대역에서 sin, cos 등의 주기 함수의 결합(?) 으로 분해 해 내는 변환 방식입니다.
사실 제가 FFT 에 대한 내용은 영상 처리 수업 때만 간단하게 배운지라 완벽하게 이해를 하지는 못한 부분입니다.
해당 내용에 대한 이해도가 있는 상황이라면 Synthetic data를 만들때에 해당 개념을 도입한 저자의 의도를 더 확연하게 파악할 수 있었을텐데, 그러지 못해서 조금은 아쉬웠습니다.
아무튼, day와 night 각각에 대해 FFT를 적용 해 줍니다. 그러면 주파수 대역에서의 image가 나오게 되는데,
해당 주파 대역 image에서 중심에 근접할 수록 저주파 성분, 중심에서 멀어질수록 고주파 성분을 의미합니다.
영상의 고주파 성분은 pixel값의 변화가 심한 edge와 같은 부분이고, 저주파 성분은 값의 변화가 완만한 부분입니다.
그런데 그림 2에서 화살표의 방향을 자세히 보시면 아래 night에서 위의 day쪽으로 향한 것을 볼 수 있습니다.
(night의 특정 영역을 day로 보낸다고 생각하실 수 있는데, 이와 반대로 night 영역의 일부를 day로 대체합니다)
그리고 주황색 ㅁ 표기가 된 부분은 주파 대역 image의 중심 영역이므로 저주파(low-frequency) 영역입니다.
FFT를 적용했을 때 nighttime의 low-frequency 영역을 daytime 영역으로 대체하는 과정을 통해 Synthetic nighttime image를 만들어 냅니다. 그림 2 (a) 에서 Phase와 Amplitude에 대해 대체 과정을 진행하고, 우측이 결과 image에 해당합니다.
nighttime의 low-frequency 영역을 daytime 영역으로 대체하는 과정이 도대체 무엇을 의미할까요??
그것은 그림 2 (a)의 Night image와 생성된 우측의 Synthetic nighttime image 를 잘 비교해 보시면 알 수 있습니다.
RGB센서의 특성 상 저조도 환경에서는 물체를 잘 포착해 내지 못한다는 단점이 존재합니다. image 속에서 이러한 영역은 주변 픽셀과의 변화가 거의 없는 low-frequency 영역이겠지요. Night image를 보시면 암흑으로 어둡게 표시 되어 있습니다. 하지만 사실 해당 영역에는 나무, 차 등의 실질적인 object가 존재하고, 이러한 정보를 살리기 위해 day image의 영역으로 대체 하는 것입니다. 결과적으로 생성된 우측의 Synthetic nighttime image에서는 이러한 object들이 잘 표현된 것을 볼 수 있지요.
(그림 2 (a)의 FFT에서 Phase의 경우 style information의 위치(where) 정보를, Amplitude의 경우 style information이 무엇(what)인지에 대한 정보를 담고 있다고 하는데,,, 이 부분은 도무지 이해가 가지 않아 그러려니 하고 넘겼습니다. 양해 부탁드립니다..ㅎ)
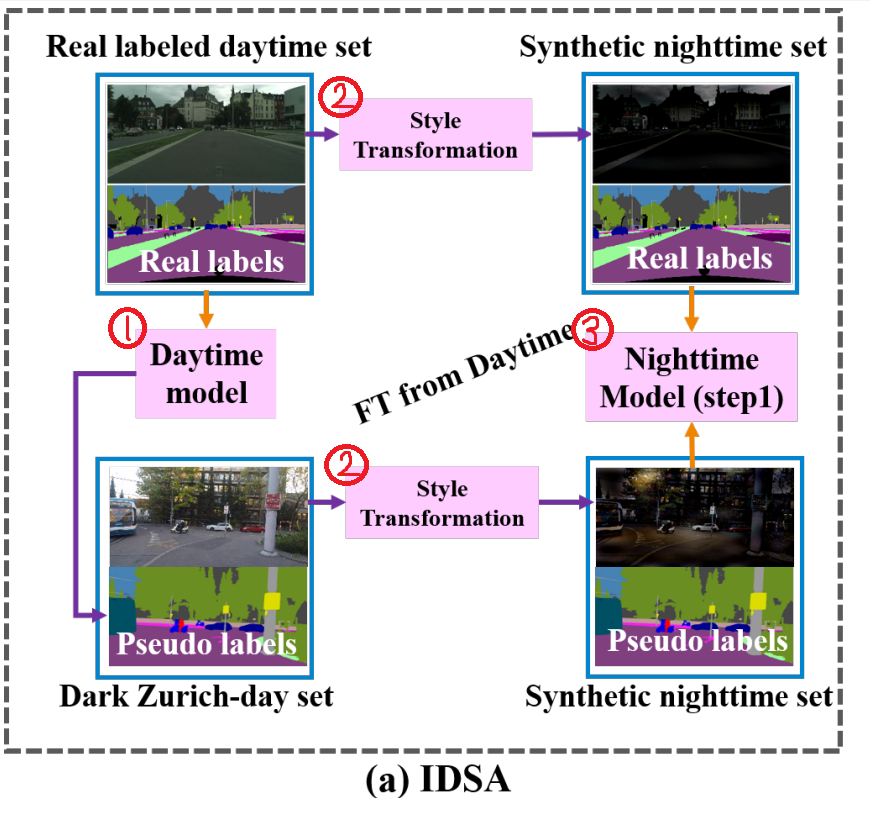
위의 그림 3은 day와 night 사이의 inter-domain에서의 adaptation을 위해 둘 사이의 Synthetic nighttime image 생성을 통해 smooth한 adaptation을 수행하는 IDSA 의 흐름도입니다.
그림 1에서 (+ 문양 => ◇ 문양) 로의 adaptation에 대응되며,
본 논문에서 제안한 2가지 step 중 첫번째 Domain Adaptation 이지요.
우선 본 학습 과정에는 2가지 dataset이 존재합니다.
1) Cityscapes dataset
매우 큰 규모의 dataset이며 segmentation GT 가 존재하는 labeling dataset 입니다.
위의 그림 3의 좌측 상단의 Real labeled daytime set 에 사용되는 데이터 셋이지요.
2) Dark Zurich dataset
GT는 존재하지 않지만, 특이하게 3가지 domain (day, twilight, night) 에 대한 image가 GPS를 기반으로 해서 서로 align이 맞은 상태로 제공이 되는 데이터 셋입니다.
위의 그림 3 좌측 하단의 Dark Zurich-day set에 사용되는 데이터 셋입니다.
해당 내용에 대해 숙지 한 상태로 그림 3의 학습 과정을 설명 드리겠습니다.
우선 Cityscapes day dataset으로 Daytime model을 학습 시킵니다.
그리고 이렇게 pretrained된 모델을 통해 Dark Zurich-day set을 위한 Pseudo label을 생성하는 것이지요.
여기서 Cityscapes day와 Dark Zurich day는 같은 RGB day image이지만 서로 다른 환경에서 촬영 된 dataset이기 때문에 어느 정도의 domain gap은 존재 하게 됩니다. 그래서 Dark Zurich-day set을 위한 Pseudo label을 생성하기 전에 조금의 Fine Tuning을 진행해야 하지 않을까 라고 조심스럽게 추측은 하고 있는데, 해당 부분에 대한 언급이 딱히 없어서 모르겠네요.. 그런데 뒤쪽의 loss 설명쪽에 딱히 언급이 안된것으로 보아 Fine Tuning을 안한 거 같기도 합니다..ㅎ
그 다음은 숫자 2로 적힌, Style Transformation 과정을 통해 두 가지 day image에 대해 Synthetic nighttime image를 구하게 됩니다. 구하는 과정은 위에서 열심히 설명 드렸죠??
그리고 숫자 3으로 적힌, Nighttime Model을 학습 시킵니다. 해당 과정에서 앞서 미리 학습된 Daytime model을 추가적으로 Fine Tuning 하게 되는데 이때는 단순히 두가지 데이터셋에서의 cross-entropy loss 를 더해줍니다.
Synthetic nighttime image 같은 경우 daytime image와 유사한 시각적 정보(그림 2 참고)를 가지기 때문에 night->day로의 급격한 변화 보다는 훨씬 더 성공적인 domain adaptation이 수행되게 됩니다.
Step 2 – IDGST (Intra Domain Gradual Self-Training)
네, 2가지 step 중 두번째 domain adaptation인 IDGST 입니다.
앞선 학습에서 사용된 Synthetic nighttime image와 nighttime image 사이의 domain gap을 해결하고자 하기 위함이며,
그림 1에서 ◇ 문양과 △ 문양 끼리의 domain adaptation 입니다.
아래 그림에서는 (b)에 해당합니다.
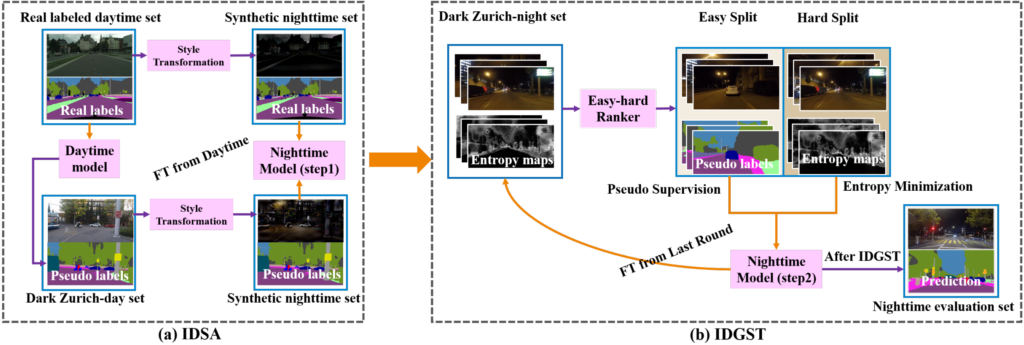
본 논문 adaptation의 전체 흐름은 day->synthetic night->night 의 흐름으로 진행되며, 현재까지 day->synthetic night 는 수행 된 상태입니다. 여기서 synthetic night으로 학습한 그림 4 (a)의 Nighttime Model(step1) 은 Dark-Zurich-night set을 위한 pseudo label을 생성해 내게 됩니다. 하지만 해당 pseudo label 는 noise의 포함을 피할 수 없고,
이러한 noise는 아래 2가지 문제가 있다고 저자는 언급합니다.
문제점 1) imbalanced class distribution
segmentation을 위한 pseudo label의 경우 각 pixel별로 어떤 class 인지 분류를 하게 되는데,
해당 pseudo label이 분류하기 쉬운 class에 대해 easy-to-adapt 되었다고 합니다.
다른 class를 무시하고 adapt 하기 쉬운 class로만 초기부터 편향된다는 문제가 존재한다는 뜻입니다.
문제점 2) terrible prediction of hard split nighttime data
RGB 센서의 특성 상, 일부 hard한 night image의 경우 class를 예측하기 매우 어려운, 심지어 사람도 예측하기에 힘들 정도의 region이 존재하게 됩니다.
이러한 문제를 해결하고자 저자는 아래 3가지의 해결책을 제시하고 이를 통해 synthetic night->night 으로의 성공적인 Intra-domain adaptation을 수행합니다.
해결책 1) Class-balanced Pseudo Labels Generation
아래에서 설명할, Self Training을 단계별로 적용할 때 parameter \alpha 를 0.2,0.4,0.6,0.8,1.0 으로 달리 하면서, Pseudo label을 생성 할 때에 confidence에 rank를 매기는 방식입니다.
개인적으로 꽤나 중요한 부분이라고 생각했고, 이해를 하고자 노력 했지만 설명이 너무 부족해서 원문으로 대체 하도록 하겠습니다. 이해가 되는 대로 바로 수정하도록 하겠습니다.
- Then we generate top-confident pseudo labels in every class according to the same ratio α.
Because the process of self-training is dynamic, α will be improved respectively in each round.
해결책 2) Easy-to-hard Self Training
그림 1을 보시면 아시다시피 nighttime 을 easy 와 hard로 split 한 것을 볼 수 있습니다.
hard split data의 경우 예측의 entropy와, illumination을 기준으로 나누어 집니다.
한마디로, 예측하기에 어렵거나 빛에 많이 노출(over-exposure) 되었거나, 적게 노출(under-exposure)된 것이 이에 해당합니다.
이 때문에 본 논문에서는 5번의 Self-Training을 진행 할 때에 필요한 Pseudo Label을 easy split data만으로 생성해 내게 됩니다. 이러한 easy split data 로 부터 배운 knowledge를 통해서 hard split data 에 대한 예측을 증진 시킬 것이라는 기대를 가지면서 말이죠.
easy split data의 선택 비율은 앞선 \alpha와 동일하게 가져가고, 아래 score 계산을 통해 easy와 hard를 구분한다고 합니다.
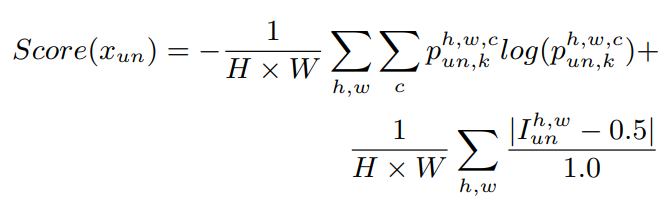
x_{un}은 unlabeled nighttime image를, p_{un,k}는 input image에 대응하는 예측 map을 나타냅니다. 앞쪽 term은 prediction entropy를 , 뒤쪽 term은 illumination estimation을 의미합니다.
해결책 3) Guidance from the Paired Daytime Image
학습때 사용하는 Dark Zurich dataset은 앞서 언급했던 것 처럼 GPS를 기반으로 각 domain image의 align이 거의 맞춰 진 상태입니다. 그 말은 즉슨 day와 night이 동일한 viewpoint를 가진다는 것이고, day의 훌륭한 예측을 night으로 transfer해도 무방하다는 말이 되겠죠.
본 논문에서는 day와 night의 예측 사이에서의 KL divergence loss를 사용하는데, 예측 전체가 아닌 patch 단위로 나눠서 loss 계산을 진행했다고 하네요.
보통의 방식대로 pixel 단위의 loss 계산을 할 경우 day와 night이 완벽한 align이 맞아야 한다는 가정이 존재하지만,
해당 데이터셋의 경우 GPS를 기반으로 align을 맞췄으니 조금의 오차가 존재하긴 합니다.
따라서 patch 단위로 loss를 적용하였네요. 꽤나 훌륭한 접근인 거 같습니다.
위에서 설명드린 Self-Traning에서 \alpha 값을 변경하면서 5번 반복한 뒤 학습이 종료되게 됩니다.
그 후 eval dataset으로 prediction이 진행되는 방식입니다.
Experiment
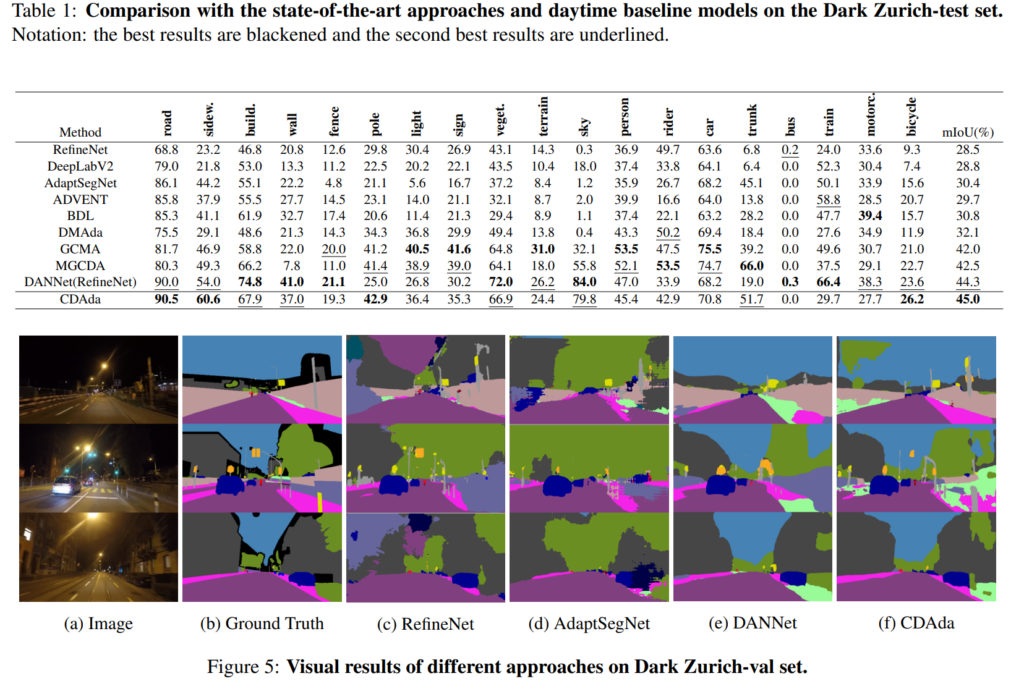
Dark Zurich dataset에서의 정성적, 정량적 평가입니다.
본 논문이 nighttime에서의 segmentation 예측을 수행하기 때문에 다른 방법론들도 nighttime에서의 예측만을 수행하였습니다.
표1을 보고 느낀것이 pole, bicycle 등의 small class에 대한 성능이 많이 올랐다는 것입니다.
사실 두 도메인에서 adaptation을 진행할 때 small class에 대한 transfer가 정말 어렵다는 것을 제 개인적인 실험을 진행하면서 느꼈는데, 본 논문에서 easy hard split이 제 값을 톡톡히 ㅎ나 거 같습니다.
정성적인 결과 또한 꽤나 잘 예측해 내는 것을 볼 수 있습니다.
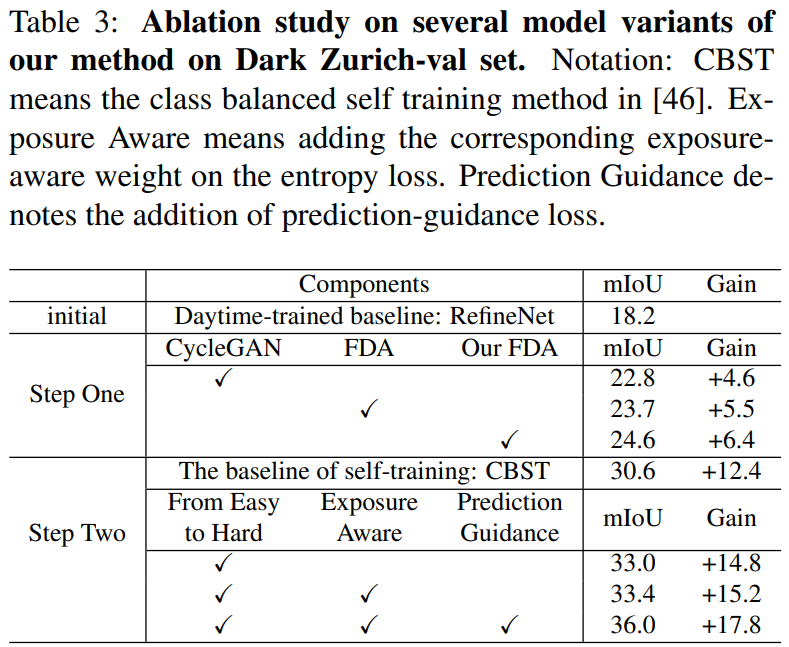
위는 2가지 step으로 진행된 Domain Adaptation중 각 step에서 구성 요소를 변경해 가면서 진행한 결과입니다.
기존 초기 RefineNet의 경우 Daytime으로 학습하고 Nighttime 예측을 진행했을 때 18.2mIOU 의 성능을 보입니다.
보통 새로운 이미지를 생성할때 많이들 사용하는 CycleGAN의 경우 baseline 대비 4.6의 성능 향상을 보인데에 반해,
본 논문의 방법론으로는 6.4 의 성능 향상을 이루어 냈습니다.
두번째 step(Intra domain) 에서는 easy-to-hard self training의 적용으로 hard split data의 noise를 최대한 피함으로써 성능 항상을 이루어 냈습니다.
그 외에도 day->night으로의 KL divergence loss를 적용한 Prediction Guidance를 통해서 2.6의 성능 향상 또한 이루어 졌습니다.
domain adaptation 이 어떤 식으로 적용이 될 수 있는지 알아보기 위해 해당 논문을 읽게 되었습니다.
사실 제가 이때까지 읽은 논문 중에서(별로 없긴 하지만,,,)
읽는데에 꽤나 시간이 많이 소요된 논문인 거 같습니다.
Method에서의 방법론이 너무 방대하고, 어느정도의 사전지식 또한 요할 뿐 아니라 너무 방대하다 보니 자세한 설명을 넣지 못한 부분도 있는 거 같아서 이해하는데에 꽤나 어려웠습니다.
그래서 꼭 이해하고 싶은 부분들을 이해 못하고 넘어간 것에 대해서는 좀 아쉬웠고, 물론 다시 해당 부분을 계속 읽어 볼 생각입니다.
특히 IDGST 의 해결책 1에서 pseudo label의 정확도를 위한 class balance를 언급하는 부분을 꼭 다시 이해하고 싶습니다. 제가 적용 할 만한 부분일 수도 있겠다는 생각이 들었기 때문이죠.
또한 day와 night의 예측에서 KL-Divergence Loss를 적용할 때에 patch 단위로 적용하는 것도 꽤나 참신했습니다. 해당 방식이 많이 사용되는 방식일 수도 있긴 한데, 저는 처음 보는지라.. 새로웠고 좋았습니다.
그럼 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요. 권석준 연구원님 리뷰 잘 읽었습니다.
FFT를 통해서 낮 이미지를 가상의 밤 이미지로 변환하는 과정에 대해 질문이 있습니다. “nighttime의 low-frequency 영역을 daytime 영역으로 대체”라고 표현을 하고 계시는데, 예시 이미지를 확인해보면 pixel->pixel replacement로 보이지는 않는데, 이 대체 과정이 어떻게 수행되는지 궁금합니다.
night->day 영역으로 대체하는 과정 또한 영상 도메인에서의 pixel 간 변환이 아니라, FFT로 변환된 주파수 도메인에서 변환이 수행되는 겁니다. 그래서 단순히 pixel replacement와는 결이 다른 결과가 도출되는 듯 합니다. FFT에 대해 추후에 공부 후 확실히 해당 내용을 숙지하게 된다면 추가적으로 말씀 드리도록 하겠습니다.
좋은 리뷰 감사합니다.
그림 2 (a)의 FFT에서 Phase는 위치(where) 정보를, Amplitude는 무엇(what)인지에 대한 정보를 포함하고 있다는 부분이 이해가 안된다고 하셔서 저도 궁금해져 찾아보았습니다. 우선 이미지가 FFT를 통해 복소수 형태로 표현되며 sin, cos의 주기성분들의 합(오일러 공식)으로 나타나게 되는데 이때 코사인 법칙을 예시로 들면 cos(2πft + ϕ) = cos(2πft)*cos(ϕ) – sin(2πft)*sin(ϕ)로 표현됩니다. 이때 phase의 경우 각 sin, cos함수의 주기가 어디서 시작하는지를 의미하기 때문에 위치 정보를 포함하고 있다고 표현한 것 같습니다. amplitude의 경우 저주파 부분에서 높은 값을 가지고 고주파에서 낮은 값을 가지기 때문에 물체에 따라 다른 amplitude를 가지기 때문에 그렇게 표현한 것 같습니다. 석준님 생각은 어떠신지요?
네 저도 추가적으로 찾아봤는데, FFT 변환 수행 후 Phase와 Amplitude가 나타내는 게 도경님이 말씀하신 부분과 동일하네요. 좋은 정보 감사합니다 ㅎㅎ
안녕하세요 석준님. 좋은 리뷰 감사합니다.
synthetic image를 통해, huge domain gap을 한번에 adaptation하는게 아닌 순차적으로 진행해서 성능이 좋았졌다는 것이 인상적이였습니다.
night time 데이터를 easy와 hard로 나누는 과정에서 예측의 entropy와 illumination으로 분류한다고 읽었습니다. 그리고 easy split data를 통해 배운 knowlege를 통해 hard split data에 대한 예측을 증진 시킨다고 봤습니다.
그런데 왜 easy hard split 방식이 small class 예측에 기여를 했는지 잘 이해가 가지 않습니다.
단순히 더 noise가 없는 데이터로 학습시켰기에 small class에 대한 예측도 잘하게 되었다라고 이해하면 될까요?