.
.
.
Incremental Learning 소개
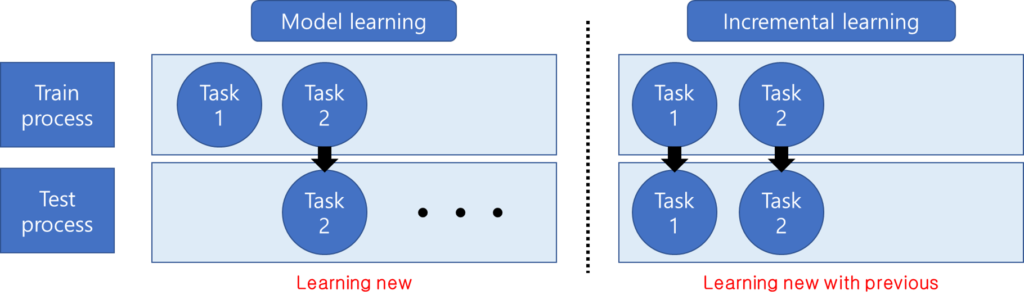
지난 주 세미나에서 소개드렸듯이 우선 본 논문의 task인 incremental learning에 대해 소개하고 시작하겠습니다. incremental learning이란 인공지능의 학습에서 새로운 task에 대해 학습할 때 기존의 task에 대한 지식을 변형 하느냐, 마느냐 문제에 대해 집중한 것입니다. 기존의 많은 deep learning 모델은 대용량 데이터(주로 Imagenet 데이터셋)에 대해 사전학습을 하고 직접적으로 서비스에 사용될 task에 대해 전의학습을 하여 task를 이동시킵니다. 그러나 기존의 지식을 유지하고 새로운 정보만을 추가하고 싶은 경우가 있겠지요. 예를 들어서 현대자동차에서 코나 풀체인지 SX2를 출시했는데요, 이처럼 회사에서 새로운 제품을 출시할 때 자동차 분류 모델과 같은 서비스 모델은 해당 데이터를 추가한 시스템으로 업데이트 해야합니다. 기존 방법론을 이용한다면 이전 데이터셋x와 새로운 코나 풀체이지의 데이터를 합쳐서 새로운 데이터셋(x’)을 구축하고 해당 데이터를 이용해 시스템을 학습시켜야 할 것 입니다. 즉 새로운 데이터를 학습하고 최근 학습한 데이터셋에 대한 예측 성능을 기대하는 시스템을 구축하게 됩니다. incremetal learning은 기존 시스템에서 이전 버전의 지식과 데이터를 유지한체로 새로운 데이터를 학습시키므로서 자원적 낭비를 최소화 하기를 바라는 방법론입니다. 기존 방법론이 learning new data라면 incremental learning은 learning new data while memorizing the previous 인 것이지요.
이런 incremental learning은 (제가 조사한 바로는) 아래의 3 줄기로 크게 나뉩니다. 기존 버전에서 학습한 데이터의 선별된 샘플만을 저장해놓았다가 재학습하는 방법(리허설 방법이라고도 합니다), 새로운 데이터에 대한 학습 시 기존 데이터를 학습한 모델의 파라미터를 변화하는 것에 제약을 가하여 기존 파라미터를 유지하도록 하는 정규화방법, 파라미터를 그대로 유지하는 방법이 바로 그 세가지 입니다. 그 중 해당 논문은 기존 버전의 데이터를 이용하는 첫번째 방법론에 속합니다.

방법론 제안의 근거
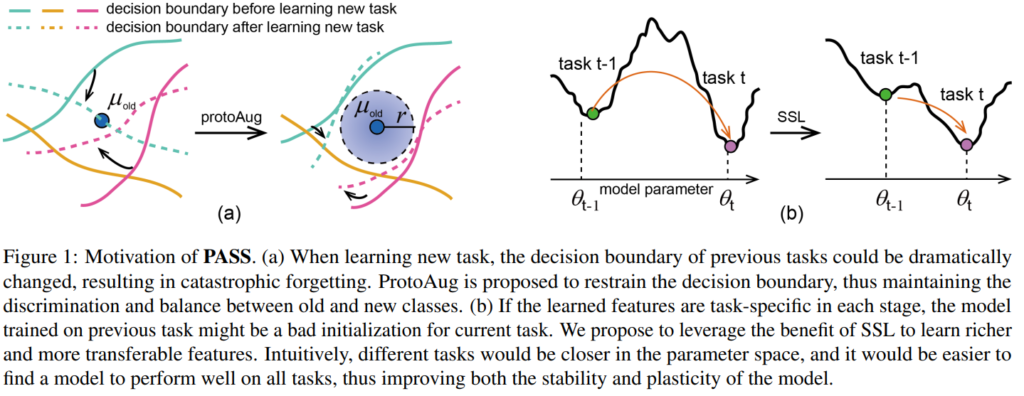
제안하는 방법론은 크게 argumentation된 prototype을 이용하는것과 ssl method를 이용했다는 점이 새로운데요, 이전 데이터에 대한 prototype을 이용해 sample을 그대로 사용할때 발생하는 메모리 낭비를 최소화하면서도 기존 버전의 모델이 갖는 정보의 변화를 최소화 하여 forgetting 문제(문단 주석 참고)를 해결합니다. 또한 SSL 방법론을 적용해 모델이 학습시 data에 fitting 된 정보가 아닌 일반화된 정보를 학습하게 하여 task 이동시 발생할 수 있는 어려움을 최소화하였습니다.
- forgetting 문제란, incremental learning에서 새로운 데이터를 학습하므로써 발생하는 이전 데이터를 잊어버리는 현상을 의마합니다
방법론
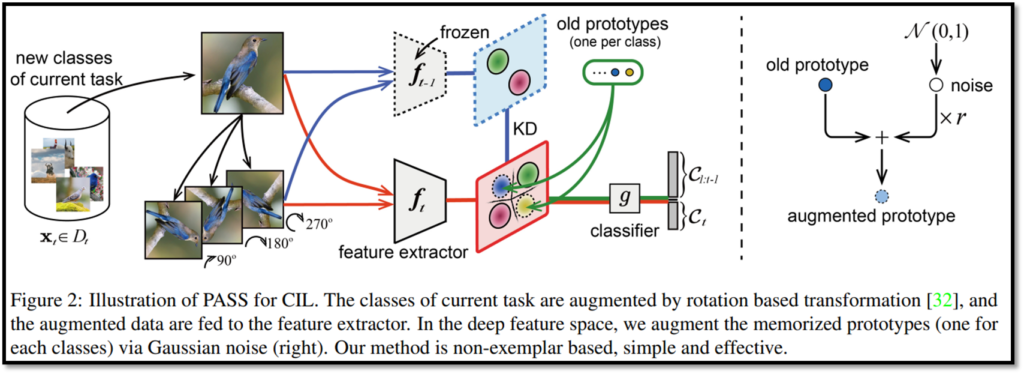
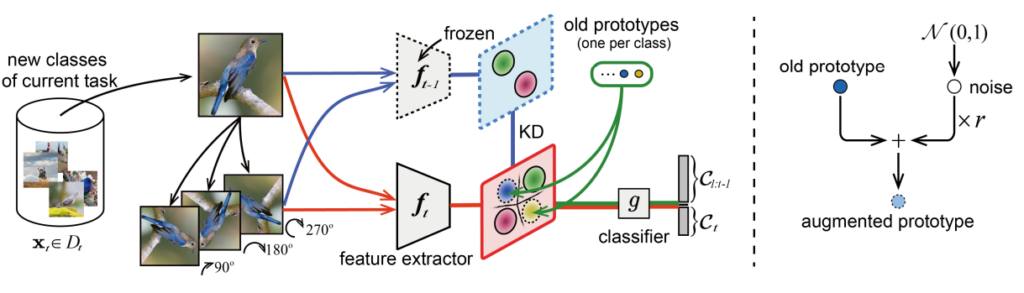
방법론은 다음과 같습니다. 먼저 forgetting 문제를 해결하기 위해 기존 데이터에 대한 prototype을 생성하고 저장하여 다음 task 학습시 사용하였는데요, prototype은 기존 데이터에서 같은 class에 속하는 데이터의 embedding feature들의 평균을 이용합니다. 또한 해당 embedding에 noise를 추가하여 augmentation을 해 다양성을 증가시킵니다.
다음으로 ssl로는 pretext task로 많이 사용하는 접근법을 사용하였는데요, 이미지를 90, 180, 270도로 회전시키고 해당 각도와 클래스를 모두 예측하도록 하므로써 적용하였습니다.
마지막으로 기존 incremental learnig에서 많이 사용하는 KD loss를 적용하므로써 모델이 새로운 데이터에 대해 과하게 변화하지 않도록 하였습니다.
실험
실험은 image classification 데이터셋에 중점을 맞춰 진행되었으며 제안하는 방법을 사용할 때 새로운 데이터의 추가로 인한 성능 하락이 기존 방법론보다 적음을 알 수 있습니다.
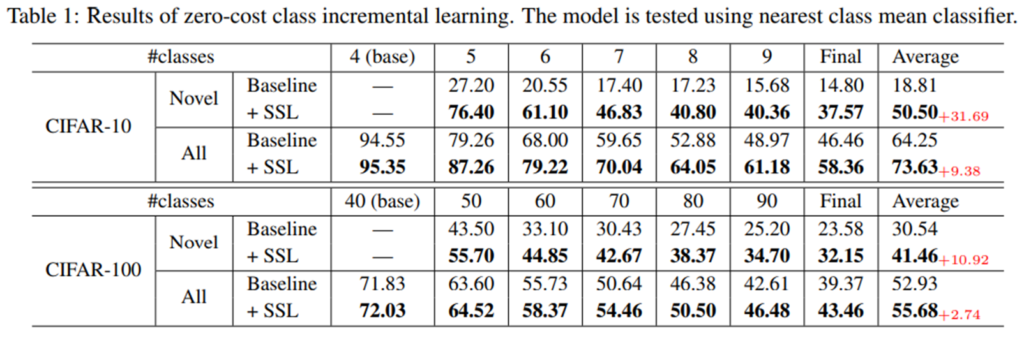
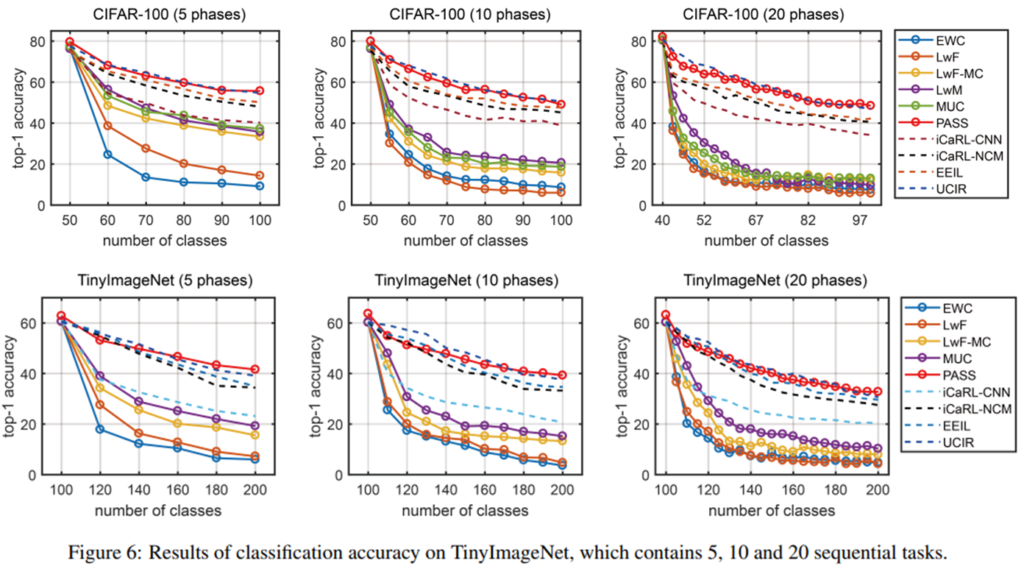
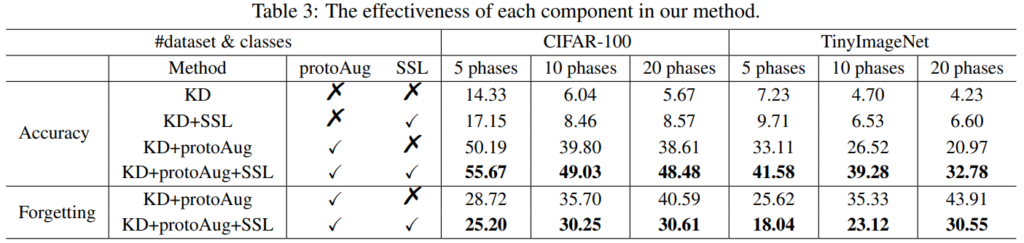
다음은 제안하는 아키텍쳐인 PASS의 ablation study 입니다. CIFAR-100과 TinyImageNet 데이터셋을 나누어서 각 n 개의 테스크(n phases)로 순차학습을 적용한 결과입니다. KD Loss 만 사용할때는 매우 낮은 성능을 보이며 CIL 이 실패하였음을 알 수 있습니다. KD에 SSL을 적용하므로써 성능이 약간 오른것을 확인할 수 있습니다. 이는 SSL이 classifier간의 imbalance 문제를 효과적으로 해결하여 일반화된 표현력을 지녔음을 알 수 있습니다. 한편 KD에 protoAug를 적용하였을때는 성능이 크게 올랐음을 통해 CIL이 효과적으로 진행되었음을 알 수 있습니다. 마지막으로 모두 적용한 결과가 가장 높은 성능을 보였음을 확인할 수 있습니다.
좋은 리뷰 감사합니다.
Incremental learning에서는 kd loss 가 자주 사용되는데 같은데 어째서 새로운 데이터에 대해서 과하게 변하지 않는것인가요?
Kd loss를 통해 이전 학습모델과 최신모델의 출력값을 동일하게 합니다
질문이 하나 있습니다.
해당 방법론에서는 표현력의 일반화성을 위해 SSL 기법을 적용하였다고 하였으며, 그 pretext task로는 90, 180, 270 등의 회전 여부를 사용한 것으로 이해하였습니다.
근데 저자가 이런 회전 정도 분류를 pretext task로 적용한 이유가 있나요? 제가 알기로 해당 pretext task는 제법 옛날 방법론으로 기억하고 있고, 또 너무 휴리스틱한 기법이라서.. 잘 아시다시피 Contrastive learning이 21년도 당시에는 유행하였을텐데 굳이 휴리스틱한 예전 방식을 채택한 이유가 있는지 궁금하네요.
방법론 적용의 편의성 때문일까요? 아니면 실제로 해당 기법이 다른 pretext task보다 유의미한 성능을 달성하였기에 적용한 것일까요? 그러고보니 리뷰에는 SSL 적용 여부에 따른 ablation study가 없네요. 실제로 SSL을 적용하고 안하고 성능 차이는 어떻게 되나요?
채택이유나 다른 ssl방법론과의 비교는 확인하지 못했으나 다시한번 확인 후 말씀드리겠습니다
Ssl적용 여부에 따른 ablation study는 논문에는 포함되어있으며 모든 제안을 적용하였을때 성능이 좋습니다
ablation 결과를 추가했습니다 :- )
안녕하세요 질문이 몇개 있습니다.
incremental learning이라는 것은 이전에 학습한 것에 대해서는 앞으로 어떤 학습을 하든 절대 틀리지 않겠다라는 것이 컨셉이라 보면 되나요? 개념적으로 보면 꽤 인상깊은 학습 방법인 것 같습니다.
리뷰에는 갑자기 prototype이라는 개념이 등장하여 이해하기 조금 어려웠습니다. prototype이 뭔가요??
1. incremental learning은 기존 학습에 대한 지식을 가진 채로 지식을 확장하기위한 방법론입니다.
2. 해당 글에서 prototype이란 clustering center의 역할을 할 수 있는 데이터셋을 대표하는 특징값으로 이해하시면 됩니다.