제가 이번에 리뷰할 논문도 Re-ID 논문 중 하나 입니다.
visible-infrared Re-ID는 서로 다른 모달리티에서 동일한 id를 예측하는 것을 목표로 합니다. 기존의 연구들이 다른 모달리티의 feature의 분포를 맞추는 것에 집중을 하였으나, 이러한 경우 구별력 있는 특징을 학습하기 어려워진다는 문제가 있습니다. 해당 논문은 MPANet을 제안하여 모달리티의 불일치를 해결하면서도, 구별력있는 특징을 추출하기 위해 패턴의 미묘한 차이를 학습한다고 합니다. 이제 자세한 방법에 대해 알아보도록 하겠습니다.
Method
Problem Formulation
visible 이미지를 \mathcal{V}=\{ \mathbf{x}^i_v \} ^{N_v}_{i=1} 열화상 이미지를 \mathcal{R}=\{ \mathbf{x}^i_r \} ^{N_r}_{i=1}라고 정의할 때, N_v,N_r는 각각 visible과 열화상 이미지의 갯수를 의미합니다. 또한, 라벨을 \mathcal{y}=\{ \mathbf{y}_i \} ^{N_p}_{i=1}라 할 때 N_p[는 아이디의 개수를 의미합니다. cross-modal Re-ID에서 쿼리 이미지가 주어졌을 때, 다른 모달리티에서의 동일한 사람을 찾는 것을 목표로 합니다.
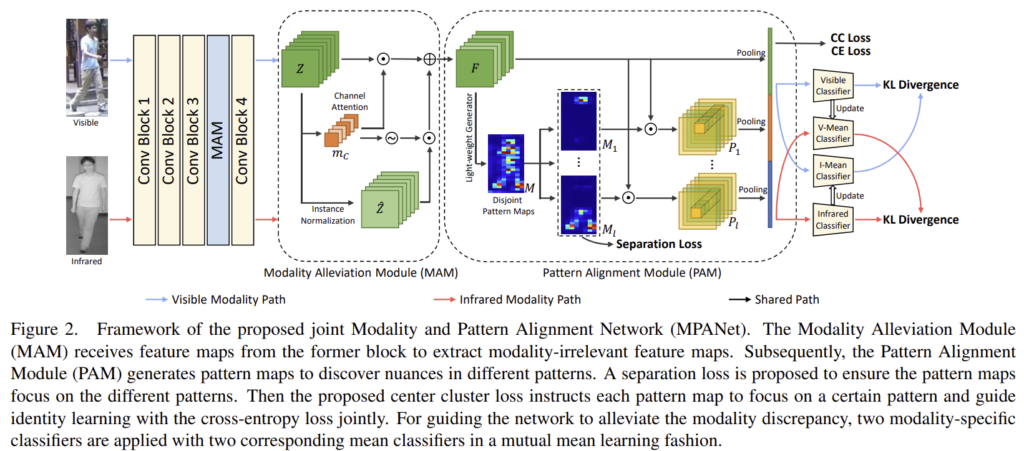
위의 그림2가 MPANet(Modality and Pattern Alignment Network)의 프레임워크를 나타낸 것으로 MPANet은 동일한 CNN 네트워크를 이용하여 visible과 열화상 이미지의 feature를 추출합니다. 추출된 feature map은 MAM(Modality Alleviation Module)에 들어가 두 모달리티간의 불일치를 완화하고 뉘앙스와 구분력 있는 특징을 학습하기 위해 PAM(Pattern Alignment Module)은 pattenr map을 만들어냅니다. 이제 각 모듈에 대해 더 자세히 알아보도록 하겠습니다.
Modality Alleviation Module(MAM)
모달리티 불일치 문제를 완화하기 위해 인스턴스 간의 차이를 줄일 수 있는 Instance Normalization(IN)**을 적용하려 하였으나, 이를 그대로 적용할 경우 사람을 식별할 수 있는 정보에 악영향을 주기 때문에 Re-ID에 맞게 적용하였다고 합니다.(즉, 인스턴스들을 정규화하여 모달리티로 인한 차이를 줄이고 싶으나 인스턴스를 정규화 할 경우 사람을 식별하기 어려워지는 문제가 있어서 이를 해결하고자 변형을 준 것입니다.)
** Xingang Pan, Ping Luo, Jianping Shi, and Xiaoou Tang. Two at once: Enhancing learning and generalization capacities via ibn-net. In Vittorio Ferrari, Martial Hebert, Cristian Sminchisescu, and Yair Weiss, editors, ECCV
저자들이 이용한 방식은 channel attention-guided IN으로, 아래의 식으로 정리가 됩니다. 이때, \mathbf{Z}는 CNN을 통과하여 나온 feature map을 의미하며, \hat{\mathbf{Z}} 은 \mathbf{Z} 에 IN이 적용된 결과를 의미합니다.
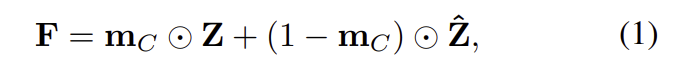
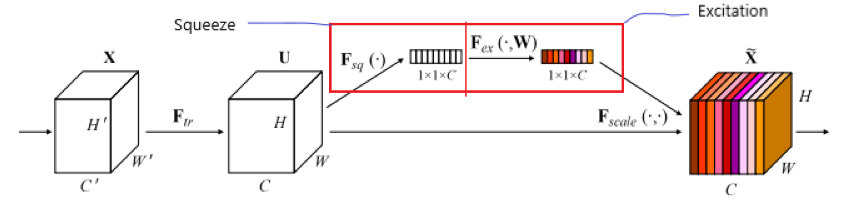
\mathbf{m}_{C}는 채널별 마스크로 SENet의 방식을 이용하여 생성하였으며 식으로 나타내면 아래의 식과 같습니다.
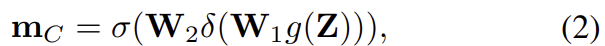
여기서 SENet을 간단하게 설명하자면, 채널에 가중치를 주어 상호작용을 고려한 방식으로, 가중치가 크면 중요한 특징을 가지고 있다는 의미를 갖습니다.
또한, IN은 아래의 식으로 정의가 되며, \mathbf{Z}_k 는 \mathbf{Z} 의 k-th 차원을 의미합니다.
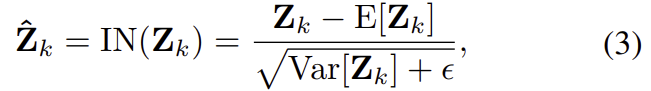
Pattern Alignment Module(PAM)
해당 모듈은 인물별 패턴의 미묘한 차이를 찾아내는 것을 목표로 합니다. feature map을 l개의 패턴으로 구성된 패턴 맵 \mathbf{M} = [\mathbf{M}_1, \mathbf{M}_2, ...,\mathbf{M}_l]] 으로 나눕니다.

pattern map은 서로 다른 패턴에 집중을 해야하며, pattern map과 feature map은 요소곱을 이용하여 \mathbf{P}_k를 구합니다.
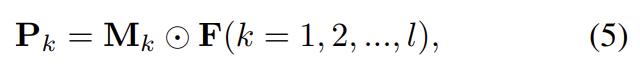
이후 \mathbf{P}_k에 global average pooling을 적용하여 PAM의 output feature \mathbf{f} = [ {\mathbf{p}_1}^T, {\mathbf{p}_2}^T, ..., {\mathbf{p}_l}^T, {g(\mathbf{F})}^T ] 를 구합니다.
이렇게 pattern map이 사람을 식별하는 역할을 하기 위해, pattern map들은 서로 다른 패턴에 대한 정보를 얻을 수 있어야 한다. 따라서 아래의 식을 이용하여 각 pattern map이 달라지도록 separation loss를 이용하여 학습을 하였다고 합니다.
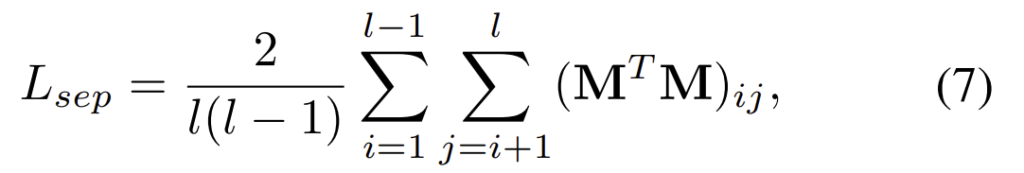
이때 (\mathbf{M}^T \mathbf{M})_{ij}는 \mathbf{M}^{h×w×l}을 \mathbf{M}^{hw×l}로 바꿔준 (\mathbf{M}^T \mathbf{M})의 i행, j열의 값으로, separation loss의 의미를 생각해보면, 각 pattern map별 상관관계가 낮아지도록 학습을 하는 것입니다.
Modality Learning(ML)
visible, 열화상 모달리티에서 추출한 feature map을 각각\mathbf{f}_v\mathbf{f}_r라 할 때, 각 모달리티별로 classifier를 통해 예측을 하고 cross entropy loss를 이용하여 loss를 구합니다.
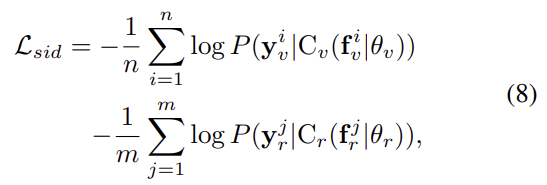
또한, 두 모달리티에서 나온 예측값이 동일한 경우, 모달리티 불일치 문제가 해결되었다고 보며, 이를 위해 아래의 식을 이용하여 loss를 계산한다고 합니다.
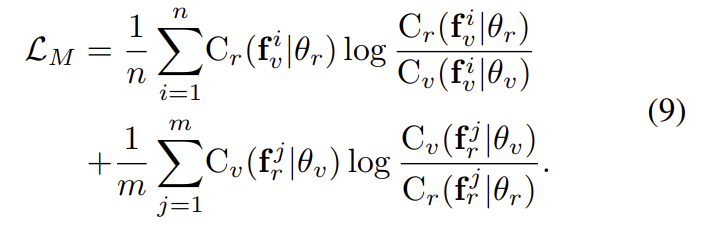
이때 이 식은 Kullback–Leibler divergence라는 두 확률분포의 차이를 계산하는 데에 사용하는 함수를 기반으로 하며, Kullback–Leibler divergence는 어떤 이상적인 분포에 대해, 그 분포를 근사하는 다른 분포를 사용해 샘플링을 한다면 발생할 수 있는 정보 엔트로피 차이를 계산한다고 합니다. 어쨋든 이 loss를 이용하여 각 모달리티에 특화된 분류기가 동일한 사람에 대해 일관성 있는 예측을 할 수 있도록 한다고 합니다.
그러나 식9를 그대로 사용할 경우, 분류기가 서로 다른 모달리티로부터 정보를 얻으므로 모달리티와 무관한 feature를 학습하고자 하는 목표에서 벗어나게 된다는 문제가 있어 두 분류기의 평균을 이용하는 방식으로 loss를 구한다고 합니다.
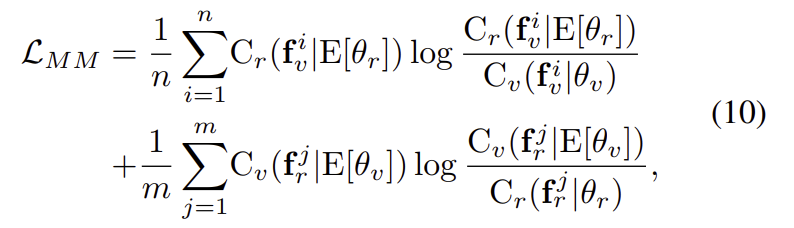
Objective functions
이 외에도 예측된 id가 동일하도록 하기 위해 cross-entropy를 적용한 id loss
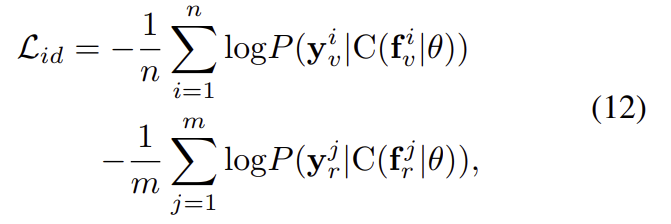
id 간의 관계를 학습하고 각 패턴 맵이 특정 패턴에 초점을 맞출 수 있도록 하기 위한 center cluster loss을 이용합니다.
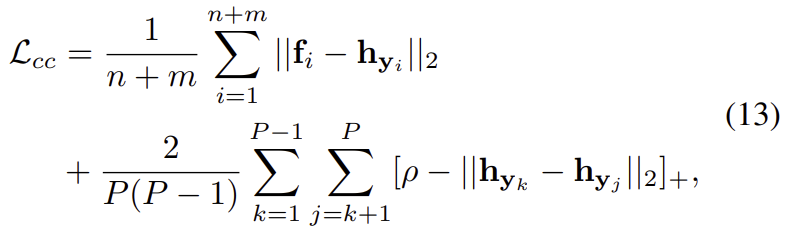
이렇게, MPANetㅇ르 학습하기 위한 Total loss는 위의 loss들에 가중치를 주어 구하게 됩니다.
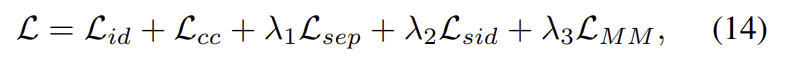
Experiments
Dataset
마찬가지로 cross-modal re-ID에서 많이 사용되는 두 데이터셋인 RegDB와 SYSU-MM01을 이용하였다고 합니다.
- SYSU-MM01
- 4개의 visible 카메라와 2개의 thermal 카메라로 촬영.
- train set에 395 id
- query와 gallery 셋에는 96 id
- 일부 사람이 실내와 실외에서 모두 촬영되어 challenging함.
- RegDB
- 10개의 visible, 10개의 thermal 카메라로 촬영.
- 412 identity(사람) 포함.
Comparison with SOTA Method
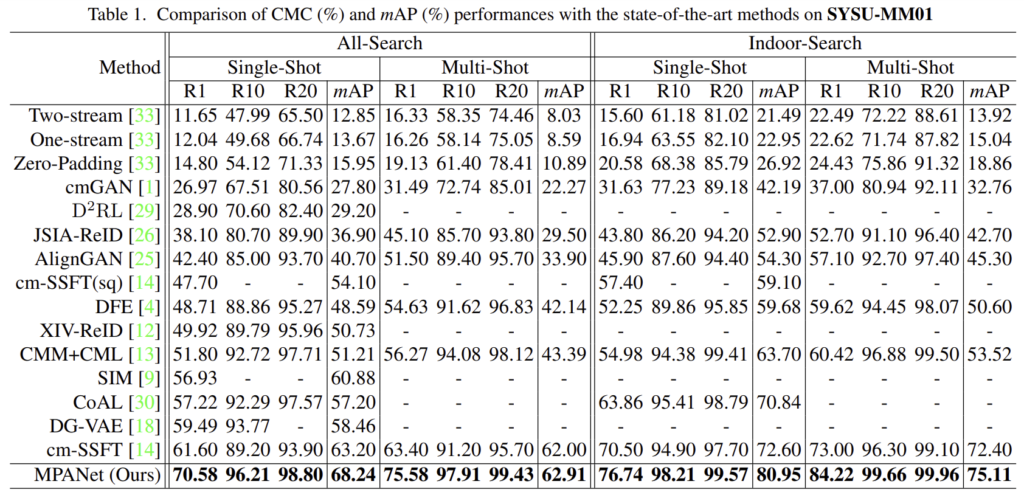
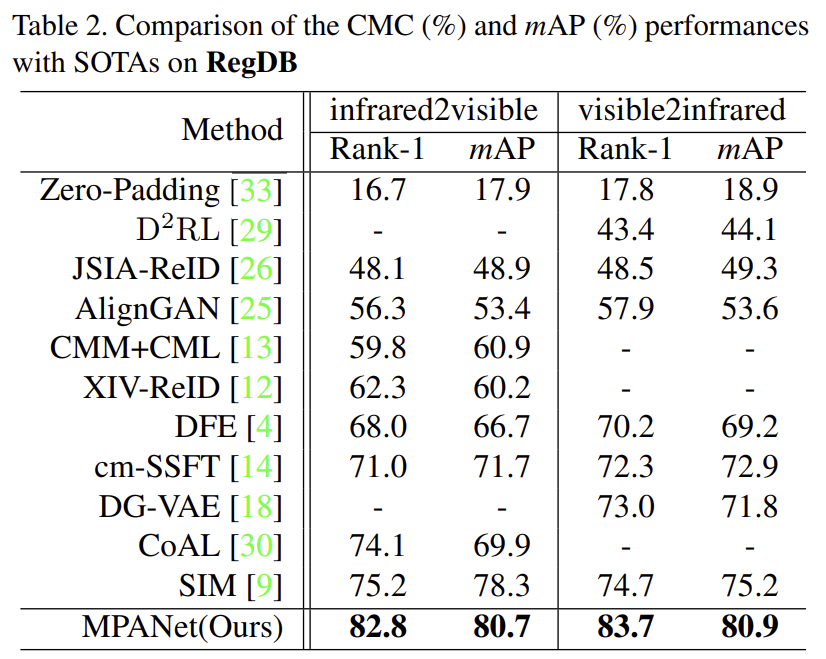
해당 논문이 나올 당시의 SOTA 논문들과 비교했을 때, 상당한 성능 개선이 이루어진 것을 확인할 수 있습니다.
Ablation Study
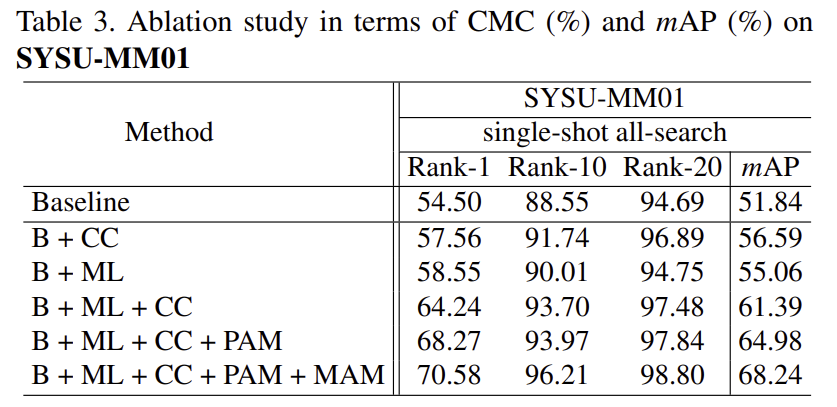
해당 논문은 많은 Loss term을 가지고 있으며, 저자들은 loss를 이용하여 ablation study를 진행하였고 위의 표3에 리포팅하였습니다. B(baseline)는 id loss를 이용한 경우를 의미하며 loss들을 추가할 때 마다 상당한 성능개선이 이루어진 것을 확인할 수 있습니다.
Discussions
Attention to Patterns.
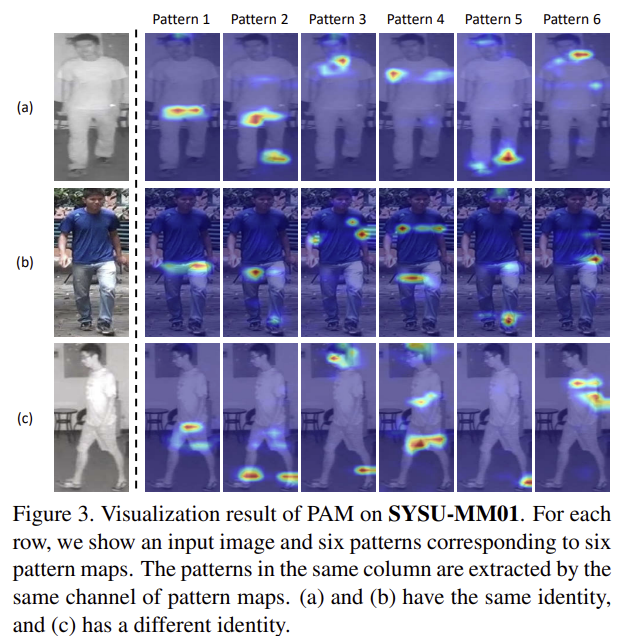
그림3은 pattern map을 시각화 한 것으로, k번째 열은 \mathbf{M}_k를 의미하며, 각 패턴 map을 통해 사람의 id나 포즈와 관계없이 특정 패턴에초점을 맞춘다는 것을 보였다고 합니다. (시각화 결과를 보았을 때 패턴 1,2,5은 사람의 비슷한 부분에 초점을 맞추었다는 설득이 되지만 3,4,6의 경우는 그렇지 않은 것으로 보이는데 조금 더 뒷받침할만한 결과가 있었으면 좋앗을 것 같습니다.)
Visualized Distributions

test 데이터 중 임의로 10개의 id를 골라 feature를 시각화 한 결과로 색은 id, 동그라미와 세모는 각각 visible, 열화상 이미지로부터 추출된 feature를 의미합니다. 시각화 결과를 보았을 때, MPANet을 이용한 경우 클러스터링이 더 잘 되어잇고, 동일한 id에 대해서 모달리티별 분포의 차이가 줄어든 것을 확인할 수 있습니다.
가장 인상 깊었던 것은 그림4의 시각화 결과입니다. 물론, 10개의 class중 가장 잘 나타내는 것들을 골랐을 수는 있지만, 동일한 아이디 내에서 두 모달리티간의 차이가 대체로 줄었다는 점에서 RGB와 열화상 간의 차이를 줄이도록 학습하는 목적에 맞는 방법론을 제안하였다고 생각됩니다. 해당 논문을 사람이 아닌 도로 환경에 적용해볼 때, pattern map에 class 정보를 도입해본다면 도로 환경에서 움직이는 object의 영향을 줄이는 데 도움이 되지 않을까 하는 생각이듭니다.
좋은 리뷰 감사합니다. 혹시 수식 14의 MPANet을 학습하기 위한 total loss에서 가중치는 어떻게 부여하게되나요? 관련된 실험이나 명시된 수치가 있는지 궁금합니다.
가중치는 하이퍼파라미터라 저자들이 실험적으로 설정한 것 같습니다. 실험에 사용된 가중치는 λ1, λ2는 0.5, λ3은 2.5로 설정하였다고 합니다.가중치 변화에 따른 ablation study는 없었습니다.
안녕하세요, 좋은 리뷰 감사합니다.
마지막 시각화 결과에서 하나의 ID에 대해 RGB와 infrared가 한 점선 내에 분포되어 있는 것을 볼 수 있습니다.
그런데 그 점선 내에서도 나름 RGB는 RGB끼리, infrared는 infrared끼리 모여있는 것을 볼 수 있는데 방법론 자체는 같은 ID라면 모달리티에 관계 없이 같은 결과를 예측하도록 설계된다고 이해했습니다.
그렇다면 이게 원래 더 조밀하게 모여야 하는데 어쩔 수 없는 모달리티 간 차이 때문에 좀 벌어진 것인지, 아니면 원래 두 모달 사이에도 어느 정도 구별력을 갖도록 학습하는데 제가 놓친 부분이 있는 것인지 궁금합니다.
두 모달리티간의 구별력을 갖도록 학습한다기보다는 두 모달리티의 차이가 있어도 동일한 id로 예측하도록 하는 것이 목표입니다. 그러나 식7과 같이 모달리티에 특화된 loss가 존재하고, 입력 자체의 차이가 있으므로 동일 id 내에서 열화상과 RGB feature의 구분이 생긴 것 같습니다. 말씀하신대로 구분 없이 잘 모이는 것이 Re-ID의 목표라 생각하시면 될 것 같습니다.
좋은 리뷰 감사합니다.
Re-id는 다른 모달 간 동일인을 찾는 연구이며, 본 저자는 채널축을 기반으로 attention을 적용한 pattern map을 통해 구별이 되는 성능 좋은 네트워크를 제안한 것으로 이해했는데요. 인스턴스 정규화가 사람을 구별할 수 있는 정보를 없앤다는 게 두 개의 모달에 대해 동시에 정규화를 진행해서 그런가요? 그리고 채널 축 어텐션이면 데이터 배이스에ㅜ있는 사람의 수 만큼 채널 개수가 결정되나요?
인스턴스 정규화를 적용할 경우 style 정보로부터 얻을 수 있는 사람에 대한 정보를 얻기 어려워진다는 의미로 이해하였습니다.
채널 축 attention은 feature map의 채널 개수로 결정됩니다.
좋은 리뷰 감사합니다
해당 방법론에 적용하지는 않았지만 Instance Normalization 이 어떠한 방식으로 이루어지는지 알 수 있을까요? 기존 이미지 단위의 Normalization 과 다르게 적용되는지 궁금합니다.
식3이 instance normalization이 적용되는 방식입니다. 기존 IN과 다른것은 mask를 적용하여 normalization을 적용한 feature와 적용하지 않은 feature를 모두 사용하였다는 점입니다.
인스턴스 정규화는 style transfer에서 많이 사용되는 정규화 방식으로, style 변동성을 제거하는 효과가 있다고 합니다.
좋은 리뷰 감사합니다.
1. 해당 태스크에 맞는 Instance Normalization을 사용한다고 했는데, 어느 부분에서 변경된 건지 궁금합니다.
2. 각 모달리티들은 shared weight model를 이용하여 학습이 진행되는 건가요?
3. 미묘한 pattern에 attention을 주는 기법이 참신합니다. 허나, 해당 태스크에서는 찾고자 하는 데이터들은 큰 차이를 가지고 있다고 생각합니다. 근데도 미묘한 차이를 학습하는 방법론이 좋은 결과를 보여준 이유가 무엇인가요?
1. 기존 IN과 다른 점은 mask를 적용하여 normalization을 적용한 feature와 적용하지 않은 feature를 모두 사용하였다는 점입니다.
2. 네 맞습니다. Shared path이므로 shared weight model을 이용하였습니다.
3. 해당 태스크가 집중하는 것은 사람의 포즈와 같은 큰 차이가 아닌, 옷과 안경과 같은 정보라고 합니다. 여기서 저자들이 주장하는 미묘한 차이(뉘앙스)란, 상의와 하의가 짧거나 긴 정보, 혹은 안경의 유무와 같은 정보라 합니다. 사람을 식별할 때 포즈는 달라져도, 옷은 동일하기 때문에 뉘앙스 정보에 집중한 것으로 보입니다.
안녕하세요?
여기가 질문 맛집이라는 소문을 듣고 찾아왔습니다.
감사합니다.