오늘의 X-Review는 Self-supervised Video Representation Learning 관련 논문으로 준비해보았습니다. 2021년도 CVPR에 게재되었으며, 중국 기업 알리바바에서 작성하였네요. 참고로 아직 해당 task의 20, 21년도의 논문을 follow-up 하고 있기 때문에 완전 최근 방법론과는 결이 다를 수도 있다는 점 감안해서 읽어주시면 감사하겠습니다.
해당 task의 22, 23년도 논문은 단순한 아이디어 레벨이 아닌 비디오의 더욱 깊은 특성을 분석하여 이를 최신 연구 트렌드에 적용한 것으로 알고 있는데, 어떠한 방향으로 연구가 발전한 것인지를 포인트로 앞으로의 리뷰를 읽으시는 것도 유의미할 것이라고 생각합니다.

Self-supervised Video Representation Learning(SSVRL) task의 목적은, 비디오의 어느 annotation도 가지고 있지 않은 상황에서 오로지 모델이 비디오의 시공간적 구조를 분석함으로써 좋은 표현력을 가지는 feature를 추출하는 것입니다. 좋은 feature라 함은 어떤 비디오 내의 semantic spatio-temporal 정보를 적절하게 담고 있다는 뜻이고, 이러한 정보를 이상적으로 잘 담고 있다면 어떤 downstream task에 적용하더라도 좋은 성능을 보여줄 것입니다.
비디오가 무슨 내용을 담고 있는지, 중요한 내용이 일어나는 구간이 어디인지 등의 정보를 아예 모르는 상황에서 어떻게 표현력 좋은 feature를 추출할 수 있을지 고민해보아야 합니다. SSVRL 방법론은 내부적으로 수행되는 pretext task와 그로부터 얻은 feature를 이용해 contrastive learning 형태를 갖고 있습니다.
Pretext task는 unsupervised 상황 속에서, 영상 또는 비디오 데이터 그 자체로부터 얻을 수 있는 ‘free label’을 통해 학습하는 것을 의미합니다. 영상에서는 대표적으로 anchor 영상을 0°, 90°, 180°, 270°씩 회전시킨 후 특정 영상을 보고 몇 °가 회전되었는지 분류하는 task가 존재합니다. 하지만 비디오는 영상의 spatial 축 뿐만 아니라 temporal 축 또한 갖고 있습니다. 이러한 특성들을 잘 이용하는 방식으로 다양한 아이디어 레벨의 video-specific pretext task들이 제안되었습니다.
Video-specific pretext task는 결국 비디오 프레임의 공간적 정보와 더불어 영상 데이터에는 존재하지 않는 시간 축 정보까지 활용하는 것입니다. 다른 논문의 Introduction을 참조하자면, 그 당시까지의 video-specific pretext task를 크게 두 갈래로 나눠볼 수 있습니다.
- Discriminative classification/regression: 앞서 영상에 적용할 수 있는 회전 관련 pretext task가 이에 해당한다고 볼 수 있습니다. 비디오에서도 한 프레임에 대해 회전을 적용해 맞추는 task를 설계할 수도 있고, temporal 정보를 활용한다면 모델이 frame의 순서가 무작위로 섞인 clip을 보고 다시 올바른 시간 순서로 정렬하는 task들이 존재합니다. 또는 sampling rate를 다르게 하여 pace가 다른 회귀를 통해 motion 정보를 학습하는 방식도 존재합니다.
- Generative dense prediction: 모델이 특정 feature를 만들어내고 그 정답과 비교해가며 학습하는 방식인데, 앞서의 방식인 분류나 회귀와 다르다고 볼 수 있습니다. 예를 들어, RGB frame을 보고 optical flow feature를 예측할 수도 있고 현재 feature를 보고 미래 feature를 예측하여 비디오의 temporal structure를 파악하는 방식이 있습니다. 물론 각 task에서 예측하는 값에 대한 정답은 전부 가지고 있는 상태이겠죠.
1의 분류의 경우 보통 CE Loss로 학습하고, 2의 경우 예측한 feature로 contrastive learning(InfoNCE Loss)을 적용하는 경우가 있습니다.
위와 같이 video-specific pretext task에 대해 간단하게 알아보았습니다. 오늘 제가 소개해드릴 논문은 2에 해당합니다. 그럼 본격적으로 논문을 살펴보겠습니다.
1. Introduction
Introduction의 시작부터 논문의 컨셉에 대해 소개하고 있습니다. 제목을 봐도 알 수 있듯 논문의 주된 컨셉은 비디오에서 context와 motion을 분리하여 둘을 명시적으로 학습하겠다는 것입니다. 사실 비디오의 어떤 context 속에서 어떤 motion이 일어나는지를 파악하면, 해당 비디오 전체를 나타내는 유의미한 feature를 뽑을 수 있을 것이라 생각합니다.
그렇기 때문에 이전에도 위와 같은 접근 방식의 연구가 있었는데, 그 연구는 비디오의 RGB frame과 optical flow를 사용해 context와 motion의 정보를 얻었고 본 연구에서는 그림 1과 같이 H.264 포맷으로 압축되어 있는 비디오의 I-frame과 motion vector로부터 각각 context, motion 정보를 얻어 사용합니다. 이에 대한 자세한 내용은 뒤에서 다루도록 하겠습니다.

그렇다면 context와 motion이 왜 SSVRL에서 중요한 역할을 하는지 알아보겠습니다. 이 내용은 제가 이전에 계속 작성하던 action localization 논문에서도 비슷한 맥락으로 설명드렸던 적이 있었어서 기억하시는 분들이 계실겁니다.
Context와 motion은 결국 서로 분리되는 개념이지만 상호보완적으로 존재합니다. 예를 들어, 수영하는 motion에서는 context로 수영장이 등장하기 마련입니다. 그렇기 때문에 수영장이라는 context를 파악한다면 그 곳에서 이루어지는 수영 motion을 파악하는데 도움이 될 수 있습니다. 하지만 수영장과 비슷한 context에서 다른 motion을 취한다면, 모델이 수영장이라는 배경에 편향되어 motion 정보를 제대로 인식할 수 없기도 할 것입니다. 이런 작용을 background bias라고 칭합니다. 따라서 context 정보만으로는 제대로 된 representation을 파악할 수 없고 그에 따른 motion 정보까지 함께 주어져야 한다는 결론을 얻을 수 있습니다.
이제 Video Representation learning 과정에서 context와 motion 정보가 왜 필요한지는 납득이 됩니다. 다들 이러한 사실을 알고 있음에도 명시적으로 해당 정보들을 모델링할 수 없었던 이유는 Self-supervised 상황이었기 때문입니다. 이번 논문에서는 앞서 언급했듯 비디오의 H.264 압축 포맷으로부터 얻을 수 있는 key-frame(I-Frame)과 motion vector(pixel offsets)가 각각 context와 motion의 label 역할을 수행합니다.
원본 데이터로부터 얻을 수 있는 정보를 최대한 뽑아내 contrastive learning framework를 설계해야 하는 Self-supervised 상황 속에서 압축된 비디오 형태에서의 P-Frame과 motion vector를 ‘free label’로 사용하겠다는 것입니다. 압축된 비디오로부터 label을 얻는것은 CPU에서도 500 fps로 굉장히 빠르고 효율적이라고 하네요.
논문의 contribution은 아래와 같습니다.
- Unlike existing works where the source of supervision usually comes from the decoded raw video frames, we present a self-supervised video representation learning method that explicitly decouples the context and motion supervision in the pretext task.
- We present a context matching task for learning coarse-grained and relatively static context representation, and a motion prediction task for learning fine-grained and high-level motion representation.
- To the best of our knowledge, we present the first approach that exploits the modalities in compressed videos as the efficient supervision sources for visual representation learning.
I-Frame, motion vector
압축 표준 중 하나인 H.264의 I-Frame과 motion vector에 대해 간단하게 살펴보고 방법론으로 넘어가겠습니다. 용량이 굉장히 큰 비디오를 유통하기 위해 압축은 필수입니다. 비디오의 원본 내용을 적은 용량만 유지하며 유통할 수 있다면 굉장히 효율적이겠죠. 이를 위해 I-Frame, P-Frame, 추가로 B-Frame까지 사용되는데 I-Frame은 비디오의 key-frame을 의미합니다. 비디오의 전체 프레임 중 일부만이 I-Frame으로 선택되는 것입니다. 그리고 그림 2처럼 I-Frame 사이에 I-Frame의 33% 용량만을 차지하는 P-Frame을 만들어냅니다. 이 때 P-Frame은 I-Frame 사이사이의 프레임들과 I-Frame 간의 pixel offset인 motion vector, 그리고 residual error를 이용해 reconstruct 되는 것입니다.
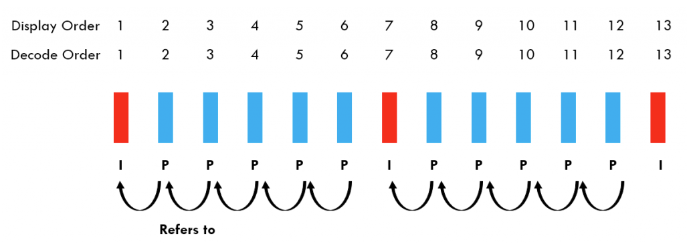
Residual error은 프레임 간 새로 생기거나 사라지는 픽셀들에 대한 정보라고 합니다. 정확한 개념은 잘 와닿지 않아 논문의 구절을 인용하겠습니다.
“Residual errors are supplementary information of motion vectors, which indicate the vanishing and emerging pixels and compensate for the estimation errors of motion vectors.”
실제 학습에는 I-Frame과 motion vector가 사용됩니다. I-Frame은 CNN 등의 알고리즘을 이용해 비디오 내에서 선택된 키프레임이고 어느정도 비디오 전반의 context 정보를 담고 있다고 생각할 수 있습니다. 또한 motion vector는 키프레임과 다른 프레임 간의 pixel offset에 해당하므로 motion 정보를 담고 있다고 볼 수 있습니다.
이제 논문의 컨셉을 이해하였으니 방법론으로 넘어가보겠습니다.
2. Methodology
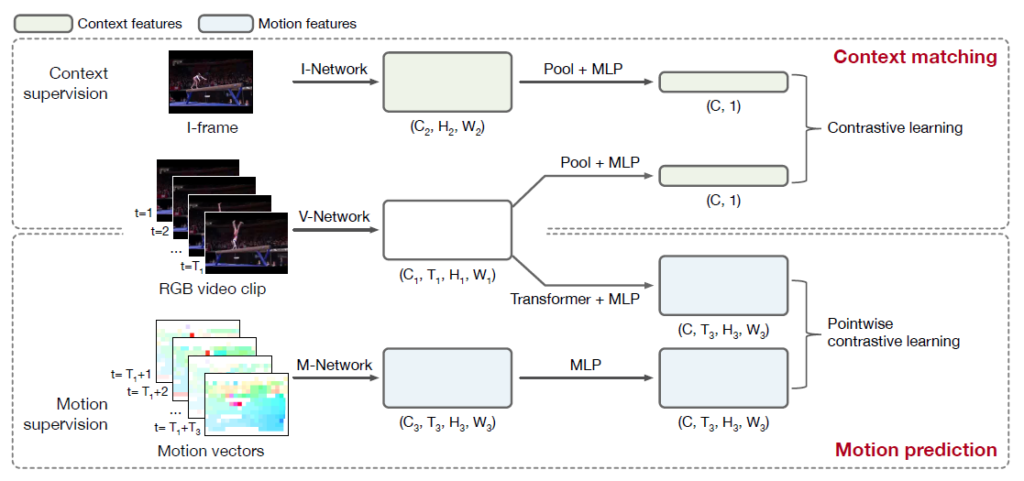
2.1 Overall Framework
두 번째 contribution에 언급되어있듯 방법론의 두 가지 핵심은 context representation을 학습하기 위한 context matching task와 motion representation을 학습하기 위한 motion prediction task입니다. 앞서 설명드린 I-Frame을 context matching의 라벨로, motion vector를 motion prediction의 라벨로 삼습니다.
그림 3을 통해 방법론은 크게 I-Network, V-Network, M-Network로 이루어지고 각각은 I-Frame, RGB video clip, motion vector를 입력으로 받는 것을 확인할 수 있습니다. 이후 각 네트워크의 output을 이용한 contrastive learning으로 비디오를 잘 represent 하는 feature를 만들어낸다는 정도를 파악할 수 있습니다.
참고로 각 네트워크 backbone은 I-Network, V-Network, M-Network 각각 R2D-10, R(2+1)D-26, R3D-10입니다.
이제 각 task를 기준으로 어떻게 학습이 이루어지는지 알아보겠습니다.
2.2 Context Matching
두 가지 task 중 먼저 context matchinig task에 대해 살펴보겠습니다.
비디오에서의 context는 상대적으로 정적이라고 할 수 있습니다. 비디오가 쭉 재생될 때, motion은 계속해서 변화하되 배경인 context는 거의 정적으로 유지된다는 특성을 관찰한 것입니다. 따라서 context의 supervision으로 활용하기로 한 I-Frame에는 비디오의 global environment가 녹아들어있다고 볼 수 있습니다. 이를 이용해 I-Frame의 feature를 추출해 한 비디오의 global context feature로 사용하겠다는 것입니다.
먼저 비디오에 대한 사람의 annotation이 전혀 없는 상황이기 때문에, i번째 비디오 임의 구간의 feature x_{i} \in \mathbb{R}^{C_{1} \times{} T_{1} \times{} H_{1} \times W_{1}}를 추출합니다. 그리고 임의 구간 근처에 I-Frame이 존재할텐데, 해당 I-Frame에 대한 feature z_{i} \in \mathbb{R}^{C_{2} \times{} H_{2} \times W_{2}}도 추출합니다. x와 z는 각각 clip에 대한 3D feature, frame에 대한 2D feature이므로 size가 다르게 나오는 것입니다.
앞서 I-Frame은 비디오 전반에 걸친 global 정보를 담고 있다고 상정하였는데, 이를 이용하기 위해 두 feature x_{i}와 z_{i}에 global average pooling을 거쳐 x_{i}' \in \mathbb{R}^{C_{1}}, z_{i}' \in \mathbb{R}^{C_{2}}를 만들어줍니다.
이후에는 SimCLR 논문을 따라 contrastive learning 전 MLP head를 적용해줍니다. 두 MLP head g^{V}, g^{I}를 각 feature x_{i}', z_{i}'에 적용해 x_{i}^{*} \in \mathbb{R}^{C}, z_{i}^{*} \in \mathbb{R}^{C}를 얻고 InfoNCE loss를 적용합니다.
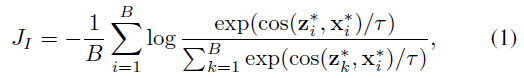
B는 미니배치 내 샘플의 개수를 의미하고 cos는 코사인 유사도입니다. 이를 통해 같은 비디오의 I-Frame과 clip의 feature representation은 가까워지도록, 다른 비디오의 feature representation은 멀어지도록 학습합니다. I-Frame을 통해 비디오 clip feature들이 global하면서 coarse-grained contextual information을 잡아낼 수 있도록 학습하는 것입니다.
여기서 생긴 개인적 의문점은, 비디오의 context가 상대적으로 정적이라면 중간 아무 frame이나 선택해도 여기서 언급하는 I-Frame과 동일한 역할을 할 수 있어야 하는게 아닌가 생각했습니다. 이 부분은 아무래도 Video compression 관점에서 I-Frame을 추출하는 알고리즘이 실제로 어떤 식으로 동작하는지, 다시 말해 무슨 기준으로 keyframe(I-Frame)을 선정하는지 알아야 할 것 같은데 이것은 나중에 기회가 되면 다시 정리해보겠습니다.
2.3 Motion Prediction
앞서 살펴본 context 정보에 비해 motion은 상대적으로 fine-grained한 특성과 temporal, spatial 축에 대한 position에 민감하다는 특성을 갖습니다. 이런 상황 속 high-level이면서 long-term에 대한 motion information을 학습하기 위해 저자는 현재 clip을 기준으로 가까운 미래의 motion dynamic을 예측하는 motion prediction task를 제안합니다. 이 때 압축된 비디오에서 얻을 수 있는 motion vector를 라벨로 삼는 것입니다.
Context matching task에서 사용한 feature x_{i}가 여기에서도 사용되고, 그로부터 가까운 미래에 해당하는 motion vector map의 feature v_{i} \in \mathbb{R}^{C_{3} \times{} T_{3} \times{} H_{3} \times W_{3}}를 추출합니다.
이제 현재 feature x_{i}를 이용해 가까운 미래에 대한 motion feature를 예측해야 합니다. 이 때 Transformer \mathcal{T}를 적용한 \hat{v}_{i} = \mathcal{T}(x_{i}) \in \mathbb{R}^{C_{3} \times{} T_{3} \times{} H_{3} \times{} W_{3}}를 예측값으로 사용합니다.
앞서와 마찬가지로 v_{i}, \hat{v}_{i}는 각각 MLP head를 거쳐 {v}_{i}^{*} \in \mathbb{R}^{C \times{} N}, \hat{v}_{i}^{*} \in \mathbb{R}^{C \times{} N}를 얻어내고 둘에 대해 pointwise InfoNCE loss를 적용해줍니다.
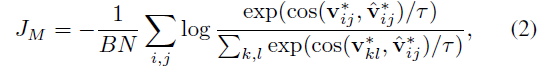
여기서 N = T_{3} \cdot{} H_{3} \cdot{} W_{3}을 의미하고 앞서 언급한 motion의 position sensitive를 다루기 위해 pointwise로 contrastive learning을 수행했다고 합니다. 같은 비디오의 spatial, temporal position인 (x, y, t)가 같은 feature에 대해서만 positive로 두고 나머지는 모두 negative로 두어 학습한다는 것입니다. 이렇게 되면 좀 더 fine-grained한 motion의 특성을 학습할 수 있을 것입니다.
2.4 Joint Optimization
최종 학습은 앞선 두 InfoNCE loss의 선형 결합으로 이루어집니다.
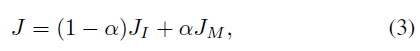
\alpha{}는 0.5로 설정하였다고 하고 이를 통해 I-, V-, M-Network와 모든 MLP head들이 end-to-end 방식으로 joint하게 학습할 수 있게 됩니다.
3. Experiments
이 당시까지 SSVRL의 실험은 일반적으로 아래와 같이 진행되었습니다.
- Pretraining: Kinetics-400, UCF101
- Evaluation: UCF101, HMDB51
- Downstream task: Action recognition, Video retrieval
3.1 Benchmark Results
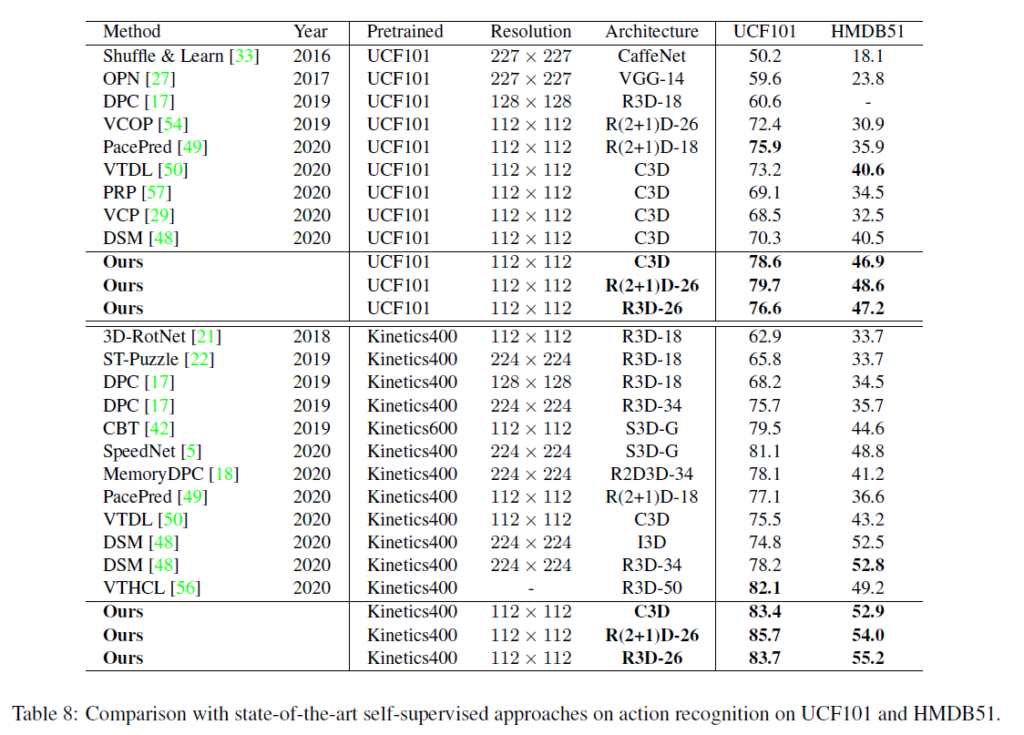
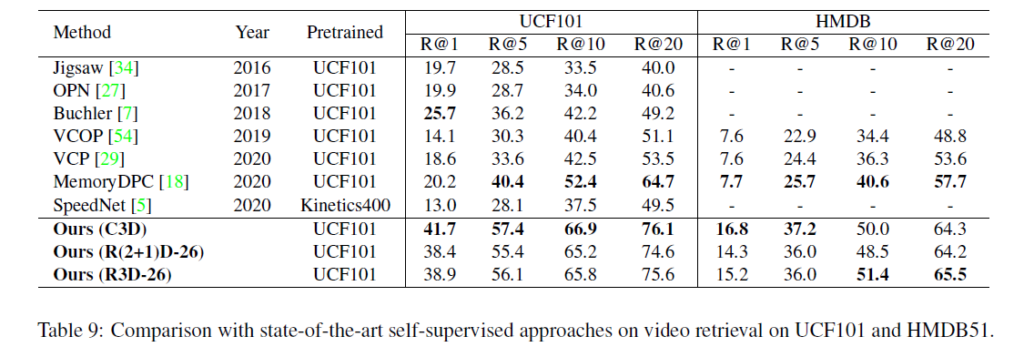
표 1과 표 2는 각각 action recognition, video retrieval task에서의 SSVRL SOTA 모델들과의 성능 비교 표입니다.
Kinetics-400은 대용량 데이터셋으로 영상 도메인에서의 ImageNet과 비슷합니다. 이 당시엔 실제로 자신들의 방법론이 좋아서 성능이 올랐다는 것을 보여주기 위해 Kinetics-400으로 사전학습 했을 때의 성능보다, 그보다는 작은 규모인 UCF101로 사전학습 시 downstream task의 성능이 높은 경우를 유의미(대용량 데이터셋 덕분에 좋은 성능이 나온게 아님을 보여주는 것)하게 보았었습니다. 표 2를 통해 UCF101로 사전학습 후 HMDB51 데이터셋에서 video retrieval 성능을 측정했을 때 다른 방법론들에 비해 큰 폭으로 성능이 향상된 것이 유의미하다고 볼 수 있겠습니다.
3.2 Ablation Studies
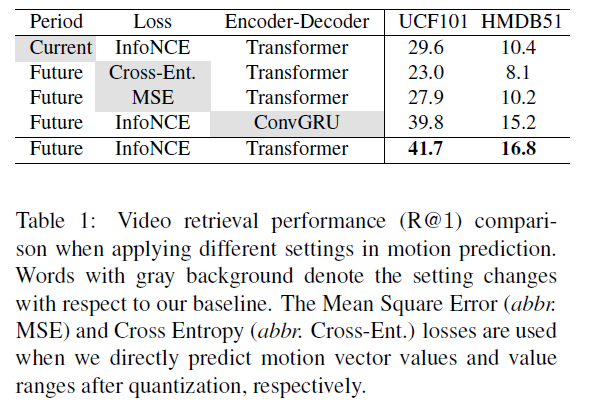
표 3은 기본적인 방법론 구조에 대한 ablation 실험입니다. 회색 부분이 기본 Baseline과 변화를 준 것들이고, 인상 깊은 점은 현재 시점에 대한 motion을 예측하는 것보다 미래의 motion을 예측하는 것이 훨씬 높은 성능을 보였다는 것입니다. 저자가 이에 대해 분석하고 있지는 않지만, temporal structure를 파악하는 것이 중요한 비디오에서 “미래”라는 하나의 축을 추가로 두고 학습하는 것이 모델이 비디오의 long-term context를 파악하는데 큰 역할을 한 것이라고 생각합니다.
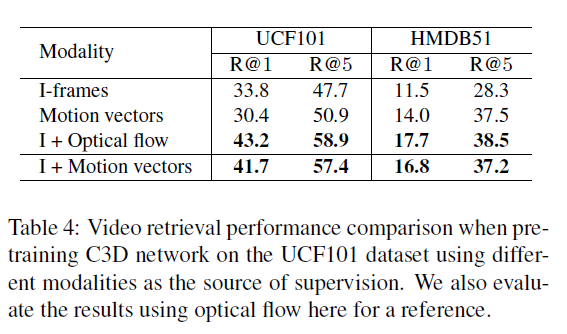
표 4는 supervision의 source를 무엇으로 두는지에 따른 video retrieval 성능 ablation입니다. Context나 motion을 각각 하나만 학습하는 것보다 둘을 joint하게 학습하는 것이 성능이 더 좋은 것은 논문에서 둘은 서로 상호보완적 관계라고 주장했던 바와 일치합니다.
사실 motion vector는 결국 추출하는데에 computational cost가 큰 optical flow를 대체할 수 있는 또 다른 supervision source라고 생각하여 optical flow를 사용했을 때 보다 성능이 낮을 것으로 생각하긴 했습니다. 하지만 I-Frame과 motion vector를 CPU에서도 500fps로 추출할 수 있다는 점을 감안하면 이정도의 성능 차이는 trade-off 속 꽤 합리적인 결과라는 생각이 듭니다.
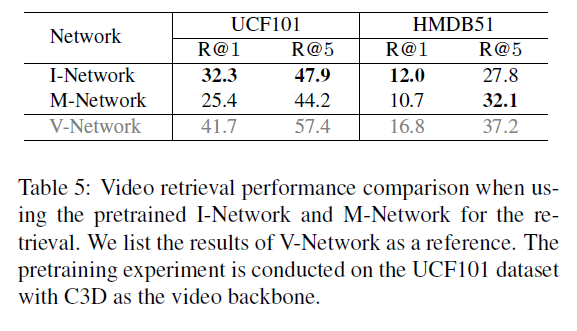
실제로 downstream task를 수행하는데에는 V-Network가 사용되지만, I-Network와 M-Network도 의미있는 feature를 학습한다는 점을 보여주기 위한 실험입니다. 여기서도 마찬가지로 둘 중 하나의 modal만을 학습하는 것보다 둘을 joint하게 학습하는 것이 더욱 효과적이라는 것을 보여주고 있으며, 전반적으로 I-Network가 M-Network보다는 좋은 표현력을 가지고 있는 것으로 보입니다.
저자는 이에 대해 context와 motion의 특성을 살려 설명하기보단 UCF101 데이터셋은 context만으로도 구별하기 쉬운 비디오들이 많고, HMDB51 데이터셋은 주로 motion 정보에 의해 구별되는 비디오가 많기 때문이라고 설명합니다.
비디오에 대해 주어지는 정보가 없는 SSL 상황 속에서 압축된 비디오로부터 context와 motion 정보를 얻어낸다는 점이 참신하게 와닿은 논문이었습니다. 사실 context와 motion의 명시적인 모델링은 action 데이터셋에서는 굉장히 중요하게 작용할 것입니다. 하지만 모든 비디오가 action을 담고 있는 것은 아니기에, 정말 비디오를 잘 파악하기 위해 context와 motion 외에 어떤 특성을 모델링해볼지 고민해보는 것도 중요할 것이라는 생각이 듭니다.
이상으로 리뷰 마치겠습니다.
리뷰 잘 읽었습니다. 비디오 논문을 잘 쓰려면 압축도 알아야 되네요!
I-Frame에는 비디오의 global environment가 녹아들어있다고 볼 수 있습니다.
=> 실제 H.264 포맷에서 I-Frame이 어떻게 선정되는지도 알려주실 수 있나요? 이러한 접근은 굉장히 신선해서 그 background가 궁금하네요.
감사합니다.
최신 코덱(코덱의 인코더)을 이용해 압축 시 I-Frame을 선정하는 방식은 굉장히 다양하다고 합니다. 우선 비디오의 가장 첫 프레임은 I-Frame이어야 합니다(용량이 더 작은 p, b-frame은 앞이나 뒤 프레임을 참조해서 예측되며 만들어지는데 비디오의 첫 프레임보다 앞선 프레임이 없으므로). 이후에 다음 몇 프레임 간격 이후 I-Frame을 지정할지는 인코더에 인자를 넘겨줄 수 있다고 합니다.
등간격으로 I-Frame을 선정하기보다는 현재 I-Frame으로부터 최소 몇 프레임 이후, 최대 몇 프레임 이내에 다음 I-Frame을 선정하라는 구간만 정해줍니다. 최근에는 추정한 motion vector를 이용해 장면이 전환되는 지점을 탐지하고 앞서 넘겨 받은 구간 내 그 지점을 I-Frame으로 지정해주는 Scene detection 방식이 있다는 것을 알 수 있었습니다.
덕분에 Video Representation learning 과정에서 context와 motion 정보가 왜 필요한지 등등에 대해서 쉽게 이해하였습니다. I-Frame이 굉장히 주요한 역할을 하는거 같은데 저도 어떻게 I-Frame을 선정했는지 궁금했는데, 현우님 리뷰를 읽어보니 논문에서 어떻게 I-Frame을 선정하는지 언급이 없는거 같아 아쉽네요. 논문에서 어떻게 I-Frame을 선정했는지에 대해서 언급이 없다면 혹시 데이터셋에서 I-Frame을 제공해주는 건가요?? (그러진 않을거 같지만)
I-Frame의 선정 방식은 위 임근택 연구원님의 질문에 대한 답변을 참고하시면 해결될 것으로 생각됩니다.
데이터셋은 일반적으로 .mp4, .flv 형태의 비디오를 포함하고 있고 만약 압축된 형태의 비디오를 갖고 있다면 ffmpeg의 함수를 이용해 I-Frame을 얻을 수 있다고 합니다.
순서는
1. 압축 스트림으로부터 packet 읽기 (packet에 I, P, B-Frame 포함)
2. packet decoding
3. 원하는 형태로 변환
이라고 하는데, 아래 블로그를 참고하시면 더욱 자세하고 많은 내용을 얻으실 수 있습니다.
https://core7ms.tistory.com/entry/FFMPEG-%EC%9D%B4%EC%9A%A9%ED%95%9C-H264-Decoding