
저는 이번에 다시 Self-supervised + Active Learning 논문을 리뷰하려고 합니다. 그동안 제가 Hybrid Learning 논문은 Image Classification에 대해 Rotation Prediction을 Self-supervised model로 사용했을 때 가장 효과적이라고 주장하였었는데요. 해당 논문의 저자는 Contrastive 기반의 Self-supervised Learning 을 Active Learning 에 결합한 연구를 제안하였습니다. 여기서 Contrastive 기반의 SSL 연구는 대표적으로 MoCo, SimCLR, BYOL 등이 있고, 이 연구들이 현재의 Self-supervised가 핫해지게끔 만든 장본인이라고도 할 수 있습니다. 이런 Contrastive 기반의 SSL이 궁금하신 분들은 우리 연구원들의 리뷰를 읽으면서 소양을 쌓아보는 것을 추천드립니다! 그럼 리뷰 시작해보겠습니단
< Self-supervised learning? >
- Self-supervised Learning @신정민
- Self-Supervised Learning에 대해 @권석준
- SimCLR: A Simple Framework for Contrastive Learning of Visual Representations (초반) @홍주영
< MoCo >
- [CVPR 2020] Momentum Contrast for Unsupervised Visual Representation Learning – @홍주영
- Momentum Contrast for Unsupervised Visual Representation Learning (MoCo) – @황유진
- MoCo2 [ICCV 2021] An Empirical Study of Training Self-Supervised Vision Transformers @홍주영
< SimCLR >
< BYOL >
< Simsiam >
- Exploring Simple Siamese Representation Learning @황유진
- [CVPR 2021] Exploring Simple Siamese Represent @김태주
MoBYv2AL: Self-supervised Active Learning for Image Classification

Introduction
저자가 문제 삼은 부분은 역시나 기존 Active Learning 에서의 고질적인 cold start problem 입니다. 그렇다면 Cold Start problem이 무엇일까요? Active Learning 은 초기 소량의 Labeled 데이터셋이 존재합니다. 따라서 이 작은 Labeled 데이터셋을 기반으로 데이터의 가치를 판단하는 모델을 지도학습 방식으로 학습합니다. 그런데 문제는 너무 작은 크기의 데이터셋으로 학습할 경우, 모델이 그 작은 데이터셋에 편향된다는 것이죠. 그로 인해 Labeled 데이터셋이 아무리 추가되어도 그리고 추가된 데이터에 대해 모델을 재학습시켜도 성능이 충분히 오르지 않는 문제가 발생합니다.
하지만 Active Learning 에서 초기 Labeled 셋을 늘리는 것은 불가능합니다. 애초에 문제 정의 자체가 조금의 라벨 데이터가 있을 때 어떻게 학습을 해야 데이터의 가치를 판단하여 선별할 수 있느냐 이기 때문이죠. 따라서 많은 연구진들이 Unlabeled 데이터에 눈을 돌리기 시작하였습니다. 게다가 최근 self-supervised learning의 연구는 supervised 를 뛰어 넘을 정도로 활발하게 연구가 진행되고 있기에…
요즘의 화두는 이 Unlabeled를 어떻게 사용해야 데이터의 가치를 파악하는 데 도움이 될 지에 대한 것이라고 할 수 있죠! 최근 제가 지속적으로 리뷰하고 있는 Hybrid Learning (Semi/Self + AL) 이 다 이런 맥락에서 연구가 시작된 것이라고도 할 수 있습니다. 그런데 그동안 제가 리뷰한 Hybrid 연구에서는, 대부분 Self-supervised learning 중 가장 보편적으로 사용 가능한 “회전 각을 예측하는 Rotation 예측 문제”를 활용하였습니다.
그런데 본 논문의 저자는 Rotation 예측이 아닌 Contrastive Learning 기반의 SSL 모델을 AL에 접목한 방식에 대해 제안하였습니다. 특히 Contrastive Learning 기반의 SSL 중 MoCo와 BYOL을 결합한 MoBY과 AL을 jointly 하게 학습하는 MoBYv2AL이라는 방법론을 제안하였습니다.
그렇다면 왜 하필 저자는 그 두 개의 모델을 섞었고, 어떤 차별점이 있으며, 어떤 방식으로 데이터를 선별하는 지 등 이에 대해 리뷰를 통해 알아보도록 하겠습니다.
Methodology
Contrastive learning의 경우 일반화된 표현을 학습하는 것을 목표로 합니다. 따라서 이러한 표현력을 구하기 위해 보통 피처 내의 유사성을 분석하는 방식을 차용합니다. MoCo와 BYOL은 모두 이런 Contrasitve learning 기반의 방법론으로 dual encoder, data augmentation, feature-vector projection, and similarity approximation 등의 요소로 구성된다는 특징을 가집니다.
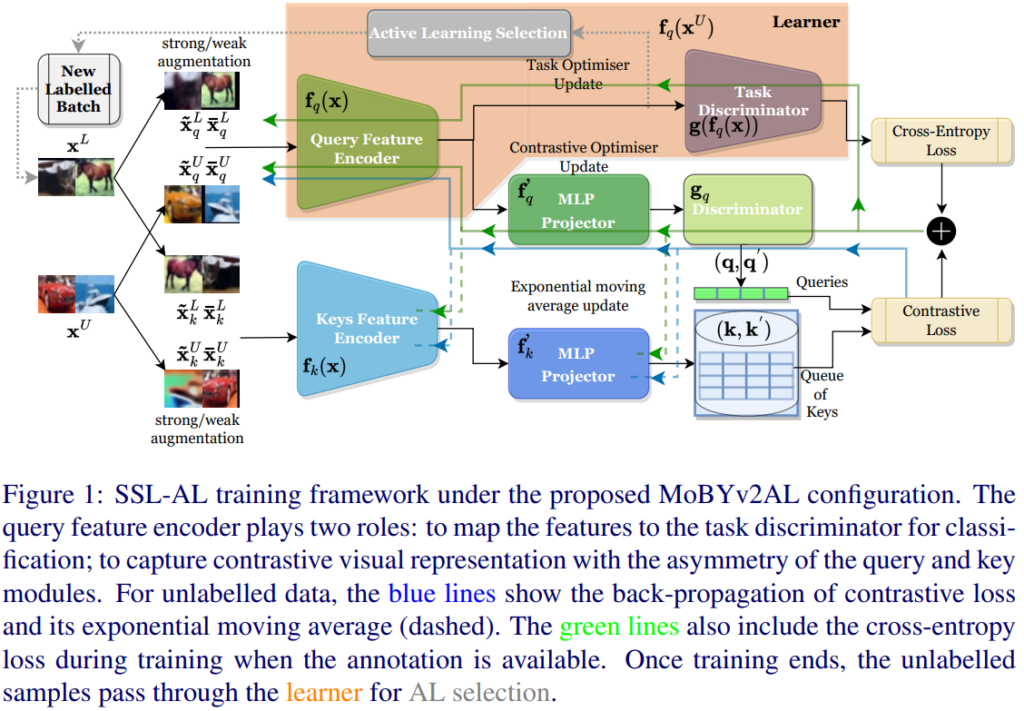
상단 그림이 바로 저자가 제안하는 MoCo와 BYOL을 결합한 모델입니다. 두 모델 모두 두 개의 인코더를 사용합니다. 우선 상단 Branch의 discriminator g_q는 아래 브랜치와의 출력와 동일한지 여부를 판단하는 역할을 합니다. 이 때 두 브랜치의 MLP projector는 동일한 구조로 구성됩니다.
저자는 두 모델을 단순히 합치기 보다는 BYOL과 MoCo 의 특징을 중화시키기 위해 각각의 모델의 요소를 합친 구조를 구축하고자 노력하였습니다. 예를 들어 앞서 해당 모델이 비대칭적인 구조로 구성되었다고 하였는데, 이렇게 비대칭적인 구조는 BYOL에서 착안한 구조라고 합니다. positive와 negative sample을 모두 사용하는 MoCo에서는 Loss 함수로 InfoNCE를 사용하나, BYOL은 positive sample만 필요하기 때문에 Contrastive learning 의 대표적인 loss인 InfoNCE를 사용하지 않습니다. 저자는 MoCo의 개념을 포함시키기 위해 InfoNCE를 loss 로 사용하였다고 합니다. 또한 이를 위해 MoCo의 가장 큰 특징인 메모리 뱅크가 필요하죠.
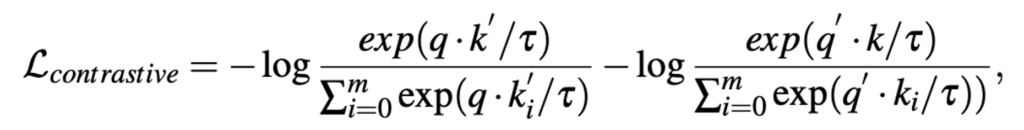
이에 따라 정의되는 Loss는 상단 수식과 같습니다. m은 메모리 뱅크의 크기입니다. 전형적인 InfoNCE Loss 라서 익숙하실 것입니다.
이제 키 인코더가 Momentum과 함께 느리게 업데이트되는 동안 쿼리 인코더는 즉각적으로 업데이트 됩니다. 이는 MoCo 인코더의 특징이죠. Key는 Dictionary이므로 천천히 업데이트 시켜서 최대한 원형의 특징을 유지하고자 하였고, Query는 바로바로 업데이트 하는 것이죠.
따라서 저자는 이런 결합 설계를 통해 MoCo와 BYOL 표현을 모두 보존할 수 있도록 모델을 구성하였습니다. 추가로 보통 Self-supervised learning 의 경우, 1차적으로 self 방식으로 학습한 뒤 Downstream task 에 대해 fine-tunning 하는 두 차례의 파이프라인으로 구성되었는데, AL에서는 효과적이지 않았다는 논문에 따라 self-learning과 active learnign 을 동시에 진행하도록 objective 를 jointly하게 설정하였습니다.
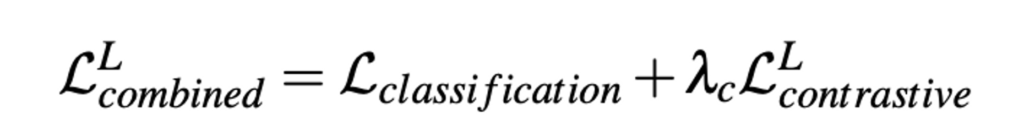
모델의 구조와 objective 에 대해 알아보았으니, 가치를 판단하는 sampling method (selective metric)에 대해 알아봅시다. 저자는 동시에 task 와 self-supervised 모델을 학습하였기 때문에 표현력이 좋아졌다는 점에 집중하였습니다. 따라서 저자는 Diversity 기반의 AL 방법론인 Core-set 에서의 샘플링 메트릭을 선택했습니다. Core-set을 간단하게 설명하자면, K-means 와 같이 일정한 반지름이 전체 데이터 space의 loss 차이를 제한하는 샘플들을 선택하는 것을 목표로 하는 방식입니다.
Active Learning 에서는 크게 두 개의 방향으로 연구가 진행됩니다. 1) Task/Scoring 모델의 표현력 향상
2) Sampling Metric: 가치 있는 데이터 선별 기준
다시 말해 저자는 Unlabeled 를 사용하여 Task 모델을 동시에 학습시킴으로써 1) 표현력을 증강시키는 연구를 진행한 것입니다.
Experiments
Quantitative experiments
여느 논문들과 비슷하게 CIFAR-10/CIFAR-100에 대한 실험을 진행하였습니다. 이 외에도 SVHN, FashionMNIST에도 진행하기도 했습니다.
인상적인 점은 첫번째 사이클에서부터 데이터를 랜덤으로 선택하는 기 AL 방법론들에 비해 CIFAR-10에서는 많으면 62% CIFAR-100에서는 28% 가량 성능이 높다는 점입니다. 이를 통해 공동으로 모델을 학습하는 것이 효과적이었음을 확인할 수 있었습니다.
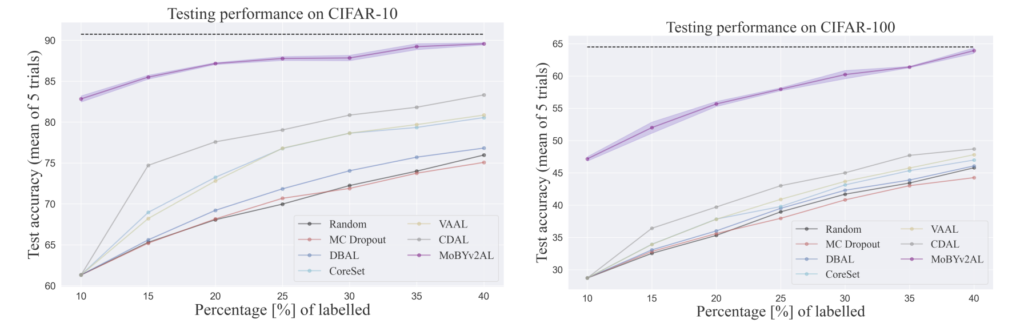
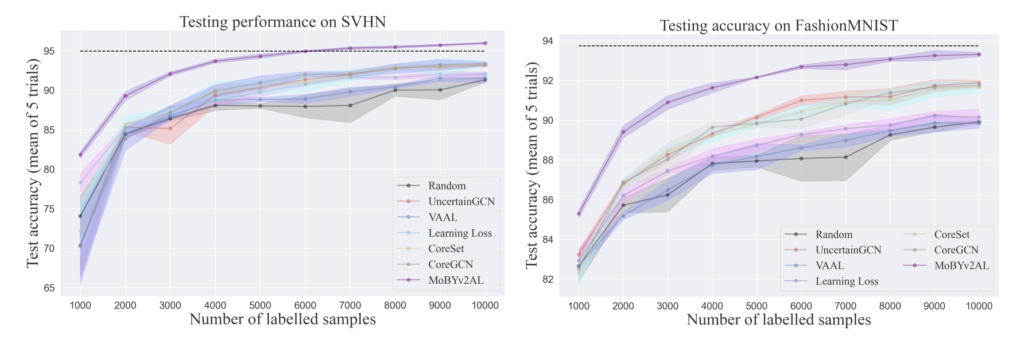
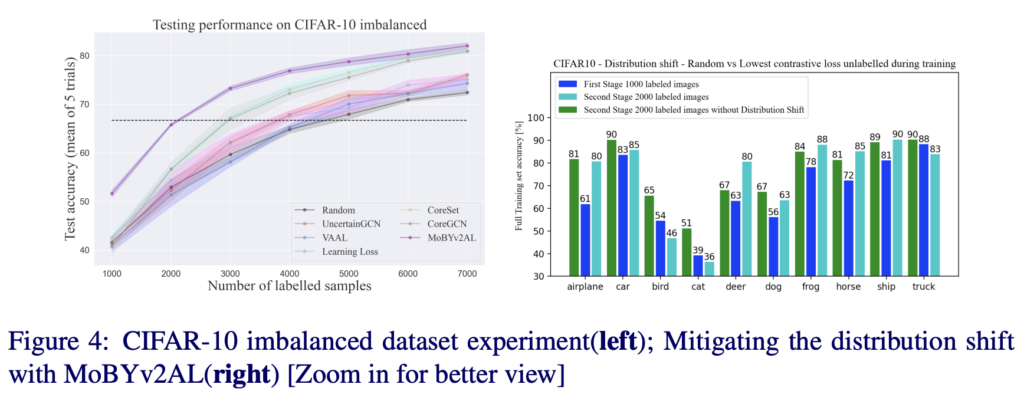
또한 저자가 제안하는 MoBYv2AL의 정교한 표현력은 CoreSet에 유용한 정보를 제공하며 가장 높은 성능을 달성했다는 것을 다른 메트릭과 비교한 결과를 제시하였습니다. 이에 대해 저자는 높은 Contrastive loss로 샘플링할 때 일부 특정 클래스에서 반복적인 샘플이 선택된 것을 알 수 있었다고 합니다. 따라서 Uncertatinty 기반의 Metric보다는 데이터의 전체 분포를 고려하는 Core-set이 적합하였다고 합니다.
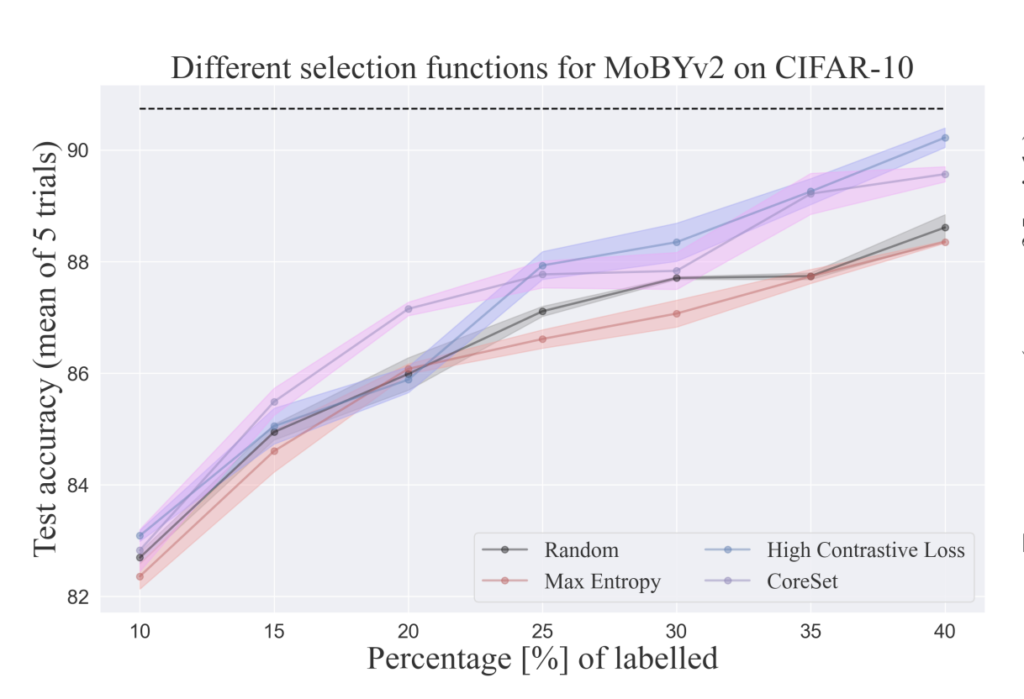
Distribution shift discussion
새롭게 레이블링된 데이터로 모델을 재 학습하는 AL의 프로세스는 다른 로컬 minima에 최적화하는 결과를 초래할 수 있습니다. 그렇기 때문에 초기 데이터셋의 분포 그리고 distribution shift는 굉장히 민감한 것으로 알려져 있습니다.
이 문제에 대해 저자는 1000, 2000 샘플을 제공할 때의 CIFAR-10 에 대한 MoBYv2AL 에 대한 성능을 분석하였습니다.
아래 그림 중 진한 파란색 막대는 분류 정확도를 처음 1000개의 랜덤 샘플과 동일하게 선택한 것입니다. MoBYv2AL을 사용하여 다른 이미지셋을 계속 선택하는 실험을 반복한 결과 최적화가 다른 방향으로 진행된 것을 확인할 수 있었습니다. 다시 말해, 일부 클래스가 무시된 채로 편향적으로 모델이 업데이트가 되었다고 할 수 있는데요. 저자는 데이터의 가치 판단을 CoreSet으로 하는 것이 높은 Contrasitve를 가지는 샘플을 대상으로 데이터가 선택된다고 생각하였습니다. 따라서 이렇게 Core-set을 적용한 초록색 막대 정확도를 보면 성능이 향상된 것을 알 수 있습니다.
SSL results and multi-stage AL
아래 Multi-stage semi supervised 는 SimSiam으로 학습한 모델로부터 Active Leanring 을 downsteam으로 택한 연구입니다. 앞서 다단계로 SSL 과 AL을 진행하는 것이 적합하지 않다고 주장하였는데, 그 근거에 대한 실험이라고 할 수 있습니다. MoBYv2AL처럼 동시에 학습하는 것이 더 효과적임을 확인하기 위한 실험이라고 할 수 있습니다.

Limitation and Conclusions
Limitation으로 저자는 Data augmentation 변화 그리고 momentum encoder 효과에 대한 분석을 충분히 제시하지 못한 점을 아쉬워 하였지만, 4개의 데이터셋에서 SOTA임을 강조하며 불균형 데이터셋에서도 충분히 좋은 성능을 보였음을 강조하였ㅅ습니다
논문이 공개되었을 당시에는 코드가 공개되지 않아 의심의 눈초리로 살펴보았었는데요. 논문을 제대로 읽어 보니 저자가 self와 active 방식을 엮기 위해 노력한 과정에 대해 이해할 수 있었습니다.
좋은 리뷰 감사합니다.
Core-set란 “K-means 와 같이 일정한 반지름이 전체 데이터 space의 loss 차이를 제한하는 샘플들을 선택하는 것을 목표로 하는 방식”이라고 이야기하셨는데, Diversity기반의 AL 방법론에서 사용되는 샘플링 메트릭이라 하여 경계선 부근에 존재하는 데이터들을 샘플링하는 것이라 이해하였는데 맞나요?? 아니라면 다시 설명해주실 수 있나요?
또한, 비대칭적인 구조는 BYOL에서 착안하였다 했는데, 비대칭적인 구조가 어떤 영향을 주는지도 설명해주실 수 있을까요?
승현 연구원님이 말씀해주신 “경계선 부근에 존재하는 데이터를 샘플링하는 것”은 Uncertainty 기반의 연구라고 할 수 있습니다. 경계성 부근에 존재할 경우, 모델이 해당 샘플에 대해 불확실한 예측을 할 것이기에 이 uncertainty가 높은 데이터를 우선적으로 샘플링하자는 것이 목적이라고 할 수 있죠. 그에 반해 Diversity는 결정 경계 근처가 아닌 전체 데이터 분포를 커버할 수 있는 데이터를 샘플링하는 것이라 할 수 있습니다. 즉 전체 분포를 커버한다고 해서 Diversity 기반의 샘플링 기법이라고도 합니다. 그래서 K-means 라는 예시를 들었던 것이구요!
좋은 리뷰 감사합니다
몇몇 연구에서 Contrastive learning의 학습 불안정성을 다루었던것으로 기억합니다 (자세한 논문이 기억이 나지 않네요 죄송합니다) 혹시 다양한 SSL 방법론 중 Contrastive learning 을 적용한 이유나 해당 방법론의 특징등이 논문에 나와있었는지 궁금합니다
저도 그 점이 궁금했으나, 해당 논문을 통해 유의미한 분석 결과를 확인할 수는 없었습니다. 기존에 rotation만 사용했으니, 이제는 MoCo 랑 BYOL을 합치려고 시도한 것이 아닌가 싶습니다.