Introduction
본 논문은 single image motion blur를 제거하는 새로운 방식의 end-to-end generative adversarial network(GAN) 방법인 Deblurgan-v2를 소개한다. 사실 이전에 Deblurgan이 존재했는데 이를 개선하여 제안한 모델이다. deblurgan-v2는 single image bling motion deblurring에 focus를 맞추었다. motion blurs는 보통 사진을 찍을때 손의 흔들림에 의해 발생하거나 물체가 이동하거나 low-frame-rate의 비디오 내에 움직이는 object가 존재할 때 발생한다. deblurgan-v2는 deblurring performance와 inference time 모두에서 좋은 성능을 보였다.
논문에서 크게 3가지로 나누어 개선된 부분을 설명하는데 아래와 같다.
1. Framework Level : image restoration task에서 처음으로 generator에 Feature Pyramid Network(FPN)을 적용, descriminator 내부에 least-square loss가 포함되도록하고 global(Image), local(patch) scales를 각각 평가하도록 함
2. Backbone Level : MobileNet, MobileNet-DSC, Inception-ResNet-v2
3. Experiment Level : 3개의 유명한 benchmarks에 대해 sota 달성
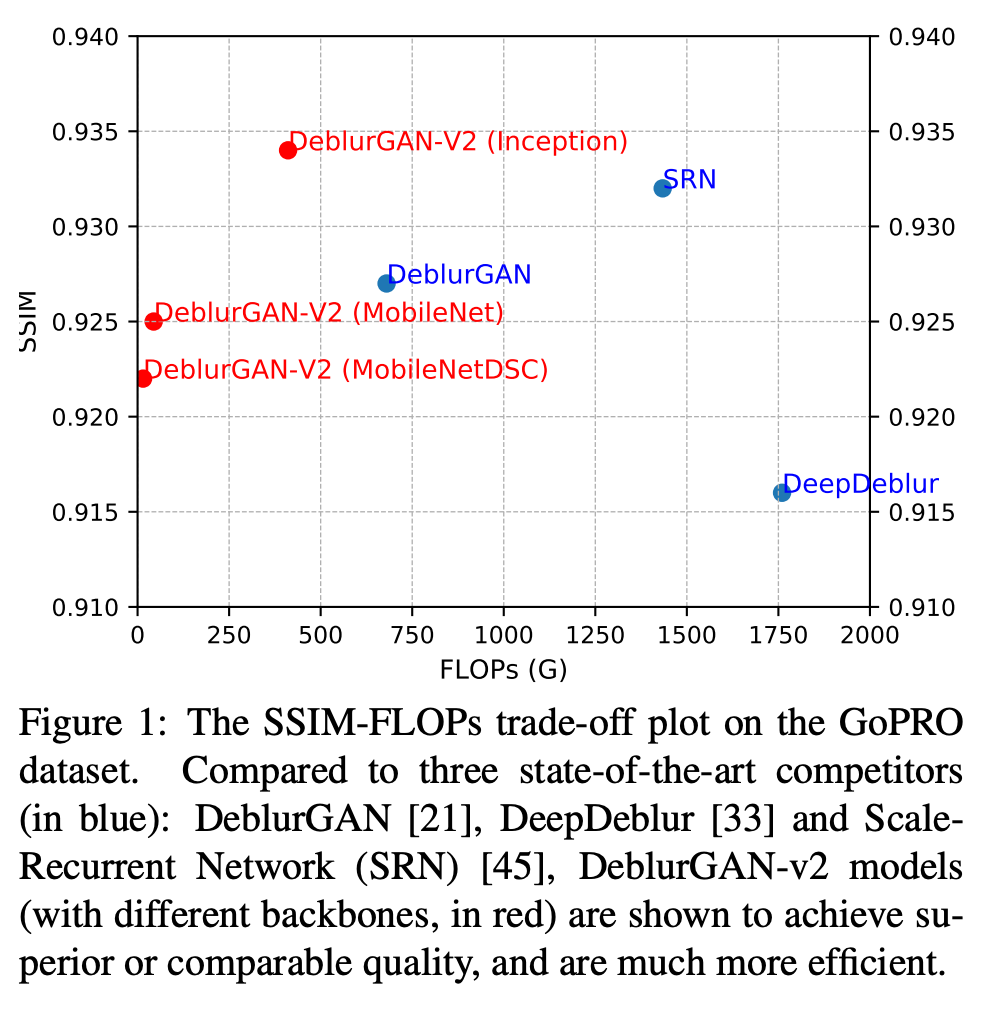
아래 그림은 기존 sota models(파란색)과 본 논문에서 다른 3개의 backbone을 적용하여 실험한 모델(빨간색)들과의 성능 비교이다. 본 논문에서 제안한 모델들(파란색)이 빠르고 좋은 성능을 보인다.
Related work
handcraft방식으로는 real images에서 blur를 잘 찾아내지 못하였는데 deep learning이 등장한 이후로 image restoration tasks가 많이 발전하게 되었다. 우선 생성모델에 대해 간단하게 알아보자.
GAN(Generative Adversarial Network)는 Discriminator(D)와 Generator(G) 2가지 모델로 구성되어 있으며, 서로 상대방의 최고의 수가 나에게 가장 최소의 영향을 끼치게 만들자는 의미의 minimax 알고리즘처럼 동작한다. generator는 인위적 샘플을 생성하고, discriminator가 잘 맞추지 못하도록 학습된다. discriminator는 real data의 Distribution을 알아채도록 학습된다.
위에서 말한 것처럼 discriminator와 generator가 minimax problem을 푸는 방식으로 학습하게되며 이때 value function(V)는 아래와 같이 crossentropy 형태로 표현된다.
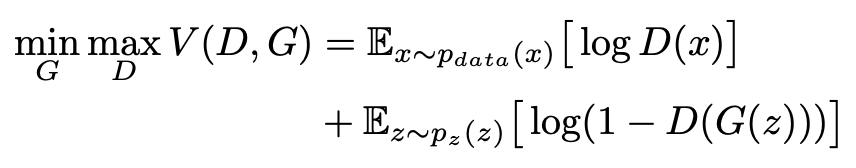
X~Pdata (x) : 실제 데이터에 대한 확률분포에서 샘플링한 데이터
Z~Pz(z) : 일반적으로 가우시안분포를 사용하는 임의의 노이즈에서 샘플링한 데이터
z : latent vector라고도 부르는데 차원이 줄어든 채로 데이터를 잘 설명할 수 있는 잠재 공간에서의 벡터
D(x)는 descriminator이고 진짜일 확률을 의미하는 0과 1사이의 값으로 데이터가 진짜이면 D(x)는 1, 가짜이면 0의 값을 가진다. 두 번째 항에 있는 분류자인 D(G(z))는 G가 만들어낸 데이터인 G(z)가 진짜라고 판단되면 1, 가짜라고 판단되면 0의 값을 가지게 된다.
이 목적함수는 optimize하기 어려우며 GAN 을 학습시키다보면 generator가 descriminator를 속이기 위해 다양한 이미지를 만들어내지 못하고 비슷한 이미지만 계속 생성하는 Mode Collapse가 발생하거나, training과정에서 gradient vanishing이 발생할 수 있다. 안정적인 학습을 위해 LSGAN(Least Squares GAN)에서는 아래와 같은 목적함수를 사용했다고 한다.
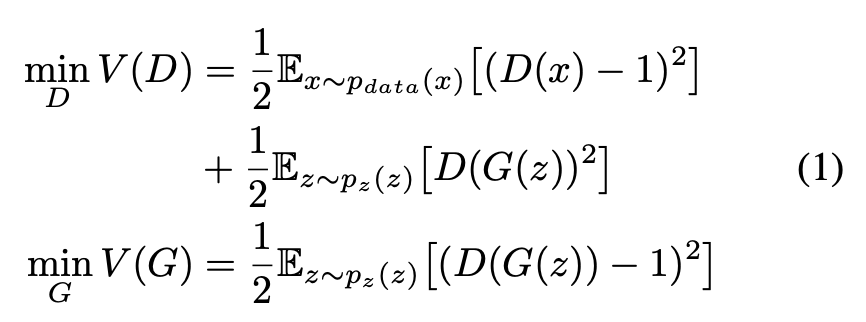
주어진 real data가 random하게 sample된 fake data보다 더 real하다고 추정하도록하는 discriminator를 적용하는 방법도 있고, 더 안정적이고 빠른 속도로 training할 수 있는 descriminators들이 등장했다.
DeblurGAN-v2 Architecture
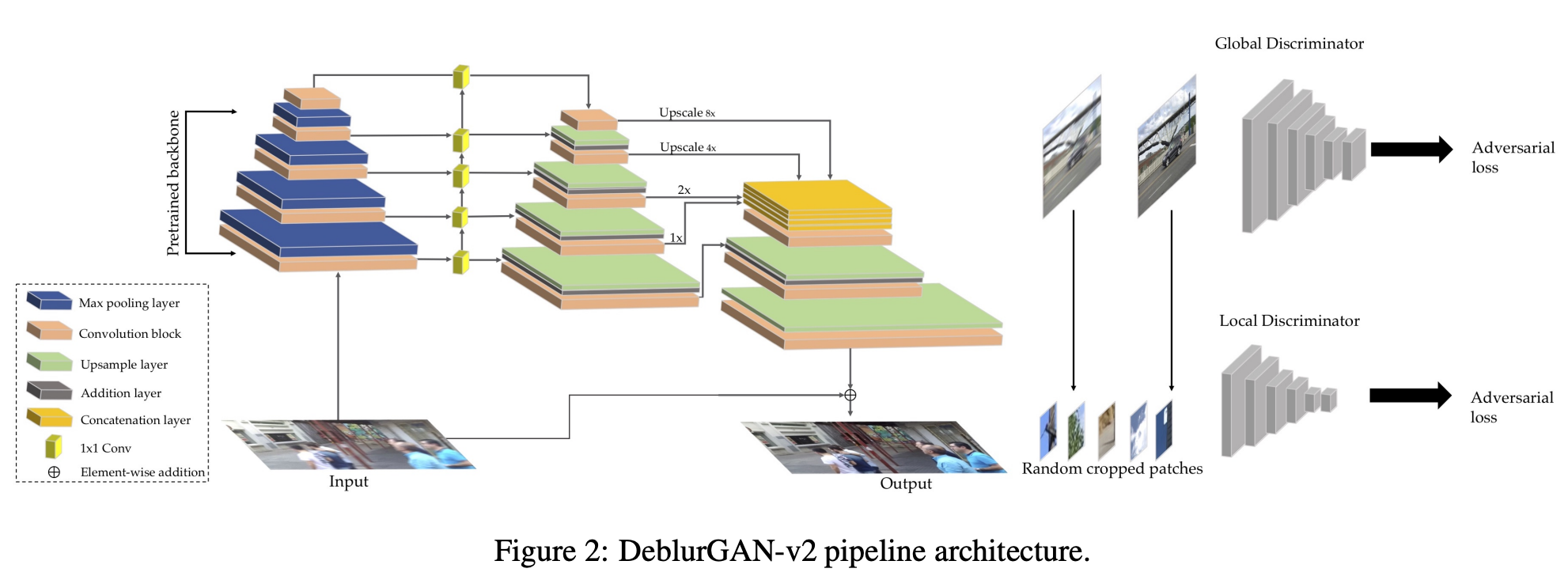
아래 그림은 DeblurGAN-v2의 구조이다. blur된 single image가 generator에 들어가 sharp image로 복원한다.
Feature Pyramid Deblurring
기존에는 서로 다른 level의 blurs를 다루기 위해 pyramid형태의 multi scale 이미지를 사용하였다. 하지만 multiple scale images를 사용하면 연산량이 많아져 시간이 오래 걸리고 메모리를 많이 차지하게 된다. 본 논문에서는 Feature Pyramid Networks를 도입하여 image deblurring을 한다. 저자는 deblur하는 모델에서 FPN을 최초로 적용했다고 주장한다. FPN은 object detection을 위해 고안되었는데 semantic정보와 detail한 정보를 모두 얻기위해 multiple feature map layers를 생성하는 구조이다. 본 논문에서 적용한 FPN은 총 5개의 다른 scale을 가진 feature를 추출한다. 그리고 input size의 1/4크기로 upsample한 후 하나의 tensor로 합쳐 semantic한 정보를 포함하게 한다. 그 뒤에 2개의 upsampling layer와 convolutional layer를 추가하여 original input image size로 만들어준다. 추가로 input에서 output으로 연결되는 direct skip connection을 통해 residual형태로 gradient vanishing문제를 해결할 수 있게 한다. 그리고 multi-scale feature를 합칠 때 속도와 정확도의 trade off 관계도 고려하였다고한다.
input image는 [-1,1]로 normalize해주었고 tanh activation function을 사용하여 output의 범위를 [-1,1]로 한정하였다.
Choice of Backbones: Trade-off between Performance and Efficiency
FPN이 적용된 architecture는 feature extractor의 backbone을 선택하기에 agnostic(인간이 인식 불가능하다는 철학적 관점)하다. 어떤 backbone을 선택해야할지 모른다는 것이다. 그래서 본 논문에서는 여러 backbone을 선택하여 실험적으로 사용하였다. 먼저, 많은 semantic한 정보를 얻기위해 Inception-ResNet-v2를 사용하였고 좋은 deblur performance를 보였다. 그리고 mobile device에서 image의 blur를 개선하기 위해 MobileNet V2를 사용했고, 모델의 복잡성(연산량)을 줄이고자 network의 모든 convolutions를 Depthwise Separable Convolutions로 대체하였다. 마지막으로 MobileNet-DSC를 backbone으로 사용하여 연산량을 크게 줄이고 image deblurring을 할 수 있도록 했다.
Double-Scale RaGAN-LS Discriminator
기존 DeblurGAN에서 사용한 WGAN-GP대신 새로운 cost function을 제안하는데 이름이 RaGAN-LS loss이다.
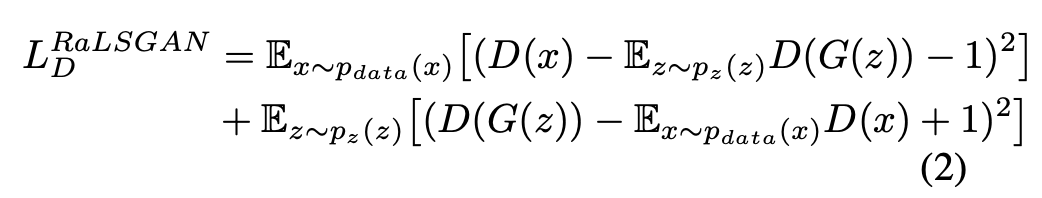
X~Pdata (x) : 실제 데이터에 대한 확률분포에서 샘플링한 데이터
Z~Pz(z) : 일반적으로 가우시안분포를 사용하는 임의의 노이즈에서 샘플링한 데이터
z : latent vector라고도 부르는데 차원이 줄어든 채로 데이터를 잘 설명할 수 있는 잠재 공간에서의 벡터
위의 loss는 WGAN-GP보다 빠르고 더 안정적으로 학습할 수 있다고 한다. 경험적으로 더 좋은 quality의 sharp한 output을 얻을 수 있었다고 한다. related work에서 언급한 LSGAN loss function을 수정하여 사용하였다.
<Extending to Both Global and Local scales>
만약 물체가 복잡하여 움직이는 형태의 균일하지 않은 blur가 심한 image가 있다면 전체적인 spatial한 정보를 포함하는 global scales가 discriminator에게 중요한 역할을 할 것이다. global feature와 local feature의 이점을 모두 포함하기 위해 본 논문에서는 double-scale discriminator를 제안한다. double-scale discriminator는 patch level로 동작하는 하나의 local branch와 전체 input image에 대해 동작하는 global branch로 구성되어 크고 서로 다른 blur들을 더 잘 다룰 수 있었다고 한다.
<Overall Loss Function>
image를 복귀하는 생성모델에서 원래 image와 새로 복원한 image를 비교하기 위해 loss가 필요하다. 먼저 일반적으로 단순히 L1, L2사이 거리를 비교하는 pixel-space loss(Lp)가 있다. 하지만 Lp를 사용하면 pixel space가 작다보니 신경망의 layer 수가 늘어나는 경우 작은 공간에서의 지역적인 정보가 아니라 전반적인 정보를 보게되어 임베딩이 비슷하게되는 oversmoothing이 발생할 수 있다. 이를 해결하기위해 content loss형태의 perceptual distance를 사용한 loss(Lx)가 제안되었다. 이 loss는 VGG19의 conv3_3 feature map에서 Euclidean loss를 의미한다. 위에서 제시된 loss들을 모두 합하여 3가지 term을 가진 loss로 DeblurGAN-v2를 학습하였다.
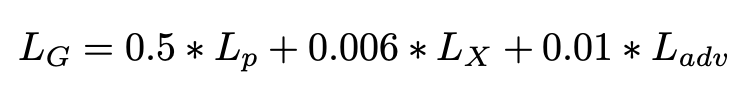
수식 마지막에 Ladv는 global과 local discriminator loss를 모두 포함한다. 또한 Lp에서는 mean-square-error(MSE)를 사용했다.
Training Datasets
GoPro dataset
GoPro Hero 4 camera를 사용하여 240fps의 비디오를 capture한 데이터셋이다. motion blurring에서 benchmark dataset이라고 하며 3,214쌍의 blurry/clear pair 이미지로 구성되어있다. 본 논문에서는 2,103쌍을 training에, 1,111쌍을 evaluation에 사용했다.
DVD dataset
DVD dataset은 71개의 real-world video capture이며 240fps로 iphone6s, GoPro Hero4, Nexus 5x로 촬영되었다고 한다. 6,708쌍의 blurry/sharp pair 이미지로 되어있다.
NFS dataset
NFS dataset은 원래 visual object tracking을 위해 만들어졌다. iphone6, ipad pro로 찍은 75개 video captures로 구성되고 240fps에서 capture된 YouTube영상 25 sequence도 포함되어있다.
training data preparation
blur frame에서 아래 그림의 (a), (c)처럼 이상한 effect가 발생할 수 있다고 한다. 이것을 해결하기 위해 240 fps를 3840 fps로 증가시켜 frame에서 Interpolation을 한다고 한다. 이후 같은 시간에 해당하는 window에 대해 average pooling을 하여 smooth하고 연속적인 blur를 얻을 수 있다. 이러한 전처리는 성능 지표 PSNR,SSIM에 영향을 미는 것이 아니라 visual quality적인 면에서 효과가 있는 전처리이다.

Experimental evaluation
training dataset은 GoPro, DVD에서 각 1 second frame에서 얻었고, NFS dataset에서 10 frame마다 얻었다. 거의 10,000쌍의 이미지로 학습했고 Inception-ResNet-v2, MobileNet, MobileNet-DSC 이렇게 3가지 backbone에 대해 평가를 진행했다. Inception-ResNet-v2이 가장 좋은 deblur성능을 보였고, MobileNet-DSC는 Inception-ResNet-v2보다 96% 적은 parameter를 가진다고 한다.
본 논문에서는 평가 지표로 PSNR, SSIM을 사용했다. PSNR, SSIM은 GAN과 같은 생성 모델에서 이미지 품질을 측정하는 metric이다. 우선 PSNR과 SSIM이 각각 어떤 평가 지표인지 알아보자.
PSNR은 Peak Signal-to-Noise Ratio의 약자로 한글로 그대로 번역하면 최대 신호에서 noise비율을 말하는 거 같은데 직관적으로 어떤 의미인지 다가오지 않는다. 의미를 이해하기 쉽게 정리하자면, 손실이 적을수록(==화질이 좋을수록) 높은 값을 가지는 영상 화질에 대한 손실 정보를 평가하는 metric이다. 수식으로는 아래와 같다.
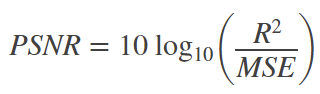
R은 pixel의 최대 가능한 값을 의미한다. 예를 들어 8bit의 unsigned integer인 경우 255가 된다. 그리고 MSE가 분모에 들어가있는데 이때 MSE가 0이되면 정의될 수 없다. PSNR은 높을 값을 가질수록 유사하다는 의미인데 손실이 없는 무손실 영상의 경우 PSNR을 정의할 수 없다. 아래에서 MSE에 수식을 살펴보자.
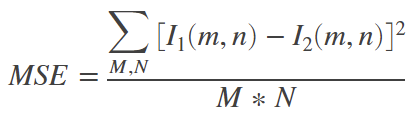
수식에서 l1, l2는 각각 MxN의 영상을 의미하고, MSE를 통해 두 영상 간의 픽셀 값 차이를 계산하게 된다. 이때 두 영상이 동일한 경우에는 MSE값이 0이 될 것이다.
중요한 점은 결론적으로 PSNR이 사람이 시각적으로 느끼는 품질의 차이를 나타내는 방법이 아니기 때문에, 실제 사람이 보았을 때 PSNR이 높은 영상이 항상 화질이 더 좋게 보이는 것은 아니라고 한다.
SSIM은 Structural Similarity Index Map의 줄인 말로 PSNR과 다르게 사람이 시각적으로 느끼는 화질 차이를 평가하기 위한 metric이다. 이것도 PSNR에 비해서는 상대적으로 시각적인 요소를 고려했다는 의미이다. 보통 단순히 두 이미지의 유사도를 비교하기 위해 사용하기도 하지만 두 이미지가 유사해지도록 만들어야되는 문제일 때 loss function으로 사용하기도 한다. 왜냐하면 SSIM이 gradient-based로 구현되어있기 때문이라고 한다. SSIM은 사람의 시각기관이 인식하는 방법을 따라 Luminance, Contrast, Structural 이렇게 3가지 측면에서 영상의 품질을 평가한다. 1에 가까울수록 두 이미지가 유사한 것이며 수식은 아래와 같다.

l이 luminance, c가 contrast, s가 structural(두 이미지의 correlation)을 의미한다. α, β, γ로 상대적인 중요도를 부여할 수 있다. 각각 함수에 대한 수식은 아래와 같다.

이때 μx, μy는 영상의 illuminance를 나타내고 σx,σy는 영상에서 픽셀 간 표준편차이며 σxy는 x,y이미지에 대한 cross-covariance를 의미한다. C1, C2, C3은 DynamicRange value인 L에 대해 정의된 상수로 아래와 같다. L은 pixel값의 범위로 uint8일 때 0~255값이며 defalut는 255이다.

SSIM 수식을 정리하면 아래와 같다. 만약 RGB 영상에 SSIM을 적용한다고하면 각 채널마다 SSIM을 구한 후 모두 합해주면 된다.


먼저 GoPro dataset에 대한 평가를 보면 SRN이 PSNR에서, Inception-Res-Net-v2를 backbone으로 사용한 DeblurGAN-v2가 SSIM에서 각각 좋은 결과를 보였다. Inception-Res-Net-v2를 backbone으로 사용한 DeblurGAN-v2가 SRN에 비해 78% 빠른 inference time을 보였고, MobileNet과 MobileNet-DSC를 backbone으로 사용한 모델은 더 빠른 inference time을 보인다.

Kohler dataset은 총 12개 kernel로 만들어진 blur가 포함된 4장의 images로 구성되어 있다. 결과를 보면 SRN이 PSNR, SSIM에서 모두 최고 성능을 보였지만 DeblurGAN-v2 모델들도 거의 비슷하게 좋은 성능을 보였다. 하지만 위에서 본 것처럼 DeblurGAN-v2중 가장 느린 Inception-ResNet-v2를 backbone으로 했을 경우에도 inference time이 SRN의 1/5 수준으로 빠르다. PSNR, SSIM 수치가 항상 좋은 시각적인 deblur효과를 보이는 것은 아니지만 아래 visualization한 결과에서도blur가 약해진 것을 확인할 수 있다.

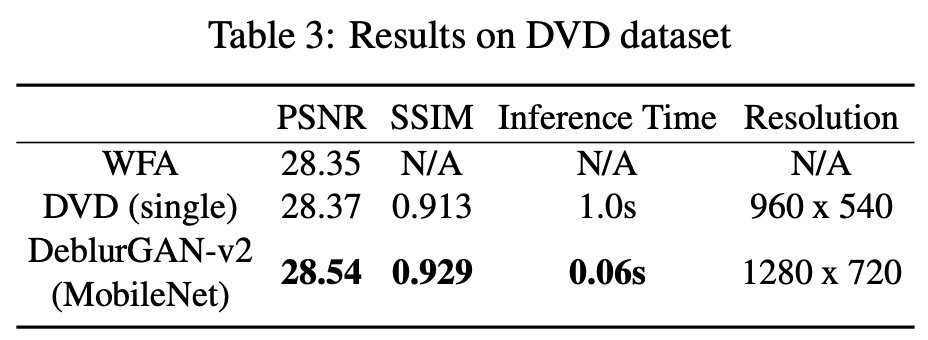
DVD dataset에서도 DeblurGAN-v2모델이 PSNR, SSIM에서 좋은 성능을 보였다.

Lai dataset에서도 DeblurGAN-v2가 좋은 average subjective scores를 보였다. gt가 없어서 score를 normalize하지는 않았다고 한다. 아래 Figure 5의 visualization 결과에서도 edge나 눈, 코, 입 등의 특징들을 보았을 때 DeblurGAN-v2(Inception이 backbone인)과 SRN이 상대적으로 deblur를 잘했다고 보여진다. MobileNet기반의 모델은 속도가 매우 빠르기 때문에 deblur 성능에 trade off관계가 있다.

Ablation Study and Analysis
기존 DeblurGAN에 여러가지를 적용한 ablation study이다. 역시 모든 걸 다 적용했을 때 수치적으로 좋은 성능을 보인다.
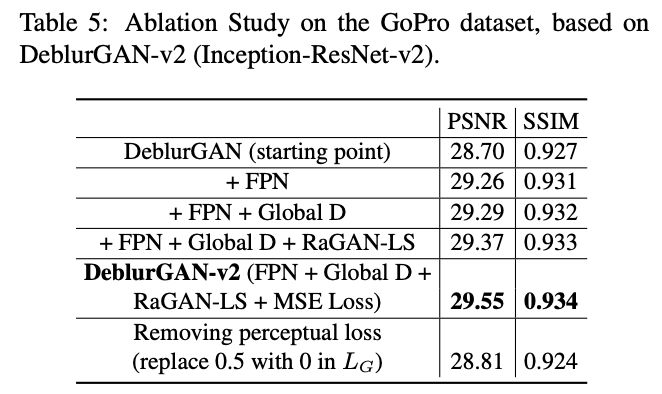
Inception-ResNet-v2를 backbone으로 사용했을 때 가장 높은 PSNR, SSIM수치를 보였다.


좋은 리뷰 감사합니다.
loss 부분에서 질문이 있는데요, pixel-space loss 에서 pixel의 space가 작다는 것이 layer가 깊어질 수록 feature map의 pixel이 더 넓은 영역의 정보를 담고 있다는 건가요? 이 때문에 oversmoothing 이 발생한다는 거구요.
그런데 이를 해결하고자 perceptual distance를 사용한 loss(Lx)를 사용한 의도는 알 거 같습니다. vgg 앞단의 feature map끼리의 loss를 적용 했으니까요. 그런데 앞선 문제를 해결하기엔 loss끼리의 가중치 scale차이가 좀 커 보이는데, loss 가중치에 대한 추가적인 언급이나 실험은 없나요??
아 그리고 추가적으로, 본 논문을 읽게 되신 계기가 궁금합니다. 그냥 개인적인 궁금증입니다 ㅎㅎ
저도 리뷰 보면서 loss 쪽 부분에 질문이 있어 권석준 연구원 댓글 밑에 추가로 질문 남깁니다.
본 리뷰 내용 중 “먼저 일반적으로 단순히 L1, L2사이 거리를 비교하는 pixel-space loss(Lp)가 있다. 하지만 Lp를 사용하면 pixel space가 작다보니 신경망의 layer 수가 늘어나는 경우 작은 공간에서의 지역적인 정보가 아니라 전반적인 정보를 보게되어 임베딩이 비슷하게되는 oversmoothing이 발생할 수 있다. 이를 해결하기위해 content loss형태의 perceptual distance를 사용한 loss(Lx)가 제안되었다. ” 라는 내용의 인과관계를 잘 모르겠네요.
실제 GT 영상과 generated image 사이에 pixel level loss가 신경망의 layer 수랑 무슨 관련이 있기에 local information이 아닌 global information을 본다는 것인가요? 말씀해주신 내용에 따르면 그럼 신경망의 layer 수가 작아지면 pixel level loss를 적용하더라도 local information을 잘 보게 되나요? 그 이유는 무엇인지요?
또 임베딩이 비슷하게 된다고 표현하셨는데, 임베딩이 비슷해진다는 것은 무슨 의미인지요? 앞 문장만 살펴보면 영상의 픽셀 값으로 비교를 하는데 보통 임베딩은 어떤 latent space 상에 feature vector를 의미하지 않나요? 픽셀 레벨에서의 비교가 어째서 임베딩 vector가 비슷해진다는 것인지 잘 모르겠습니다.(애초에 그 embedding vector라는 내용이 어디서 나왔는지 명확치 않은 것 같아요.)
그리고 위의 문제를 해결하기 위해 perceptual loss가 적용된다는 것 역시 앞선 내용의 흐름과는 조금 연관 짓기가 어려운 듯 합니다. Perceptual loss를 적용하면 왜 local한 정보를 살펴볼 수 있는 것인가요? 오히려 원본 해상도의 RGB 영상에서 픽셀 레벨로 보는 것이 low-level feature map보다 더 세부적인 local 정보를 살펴볼 것 같은데 말이에요.
아마 DeblurGAN-v2저자가 논문에서 pixel level distance의 문제점 지적 및 perceptual loss 도입 의도를 설명할 때 레이어의 수에 따른 local information과 global information~~관련 내용들로 설명하지는 않았을 것 같은데.. 다시 한번 확인하신 후 정리해서 댓글 남겨주시면 좋겠습니다.
좋은 지적 감사합니다.
위의 댓글에서 말씀드린 것과 마찬가지로 oversmoothing에 대한 설명을 하려다 잘못 말한 것 같습니다. Lp에서 high resolution이미지와 low resolution에서 개선시킨 image간의 차이를 MSE를 사용하여 pixel 단위로 loss를 구하기 때문에 high frequency 부분이 smoothing된다는 문제가 발생할 수 있다는 점을 말씀드리고 싶었습니다. 그래프 생성 모델에서 vertex가 아니라 여기서는 그래프 전체를 vector로 표현하여 사용하기 때문에 embedding은 oversmoothing을 설명하기 위해 추가되었고 본 논문에서는 관계가 없습니다. MSE를 기반으로 만들어진 loss function은 위에서 언급한대로 texture details들이 smoothing되는 결과로 이어집니다. 그래서 인지적으로는 좋지 않은 결과를 만들게 됩니다. 따라서 local한 정보를 더 잘보기 위함이라기 보다, pixel끼리 비교하는 방법에서 smoothing되는 문제를 해결하기 위해 perceptual loss를 추가하였습니다. perceptual loss는 image를 pre-trained CNN모델인 vgg19를 통과시켜 conv3_3 feature map에서 Euclidean loss를 계산했습니다. 본 논문에서 loss에 대한 설명이 자세하지 않은데, reference를 타고 보니 말씀하신대로 local, global information으로 설명하지는 않았네요. 감사합니다
먼저 제가 그래프 생성 모델에서 oversmoothing 설명 내용을 추가하려다보니 내용이 잘못 꼬였네요… reference 논문에서 설명하기로 리뷰에서 oversmoothing이 발생한다는 것은, high resolution이미지와 low resolution에서 화질 개선한 이미지와의 차이를 제곱하여 평균내는데(MSE) pixel단위로 평균을 구하는 loss이기 때문에 edge와 같은 high frequency부분이 smoothing되어 texture가 잘 표현되지 않는다는 의미입니다.
논문에서 loss 가중치에 대한 언급이나 실험은 따로 없습니다. 저도 리뷰 중 스케일 차이가 많이 난다고 생각했는데 그 이유에 대해서는 알아내지 못했습니다…혹시 의견있으시면 개인적으로 말씀해주시면 감사하겠습니다.
마지막으로 본 논문은 이번에 결과보고서 작성 시 이미지 blur 제거와 관련된 실험을 할 때 DeblurGAN-v2 방법론을 적용하기 위해 읽어보게 되었습니다.