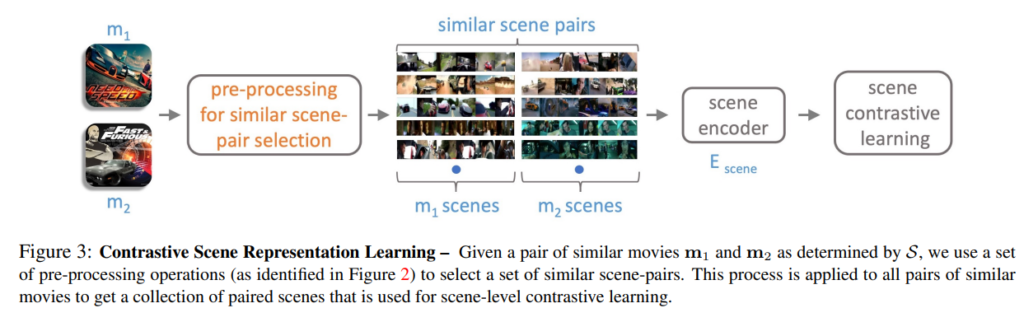
Before Review
꽤나 흥미롭고 자극적인(?) 논문을 가져왔습니다.
자극적이라고 한 이유는 저자들이 데이터셋 두개를 새롭게 제안 하였는데, 그 중 하나가 굉장히 자극적인 컨텐츠를 담고 있는 데이터셋이기 때문입니다. 논문의 방향 자체는 영화 데이터와 같이 2시간 정도로 긴 데이터에 대해서도 효과적이며 일반적인 Video Representation을 얻기 위해 고안된 연구입니다.
리뷰 시작하겠습니다.
Introduction
제가 이전에 Long-Form Video에 대해서 다룬 리뷰가 하나 있습니다. 그 리뷰에서는 Long-Form Video를 일반적으로 1분이 넘어가는 비교적 긴 길이를 가지는 동영상으로 정의했습니다. 비디오의 시간이 길어지면 비디오를 구성하는 요소들이 좀 더 복잡하고 정교한 관계를 만들어내며 굉장히 의미론적이고 추상적인 이야기를 만들어냅니다.
영화도 정확히 Long-Form Video에 속합니다. 저희가 자주 접하는 동영상 매체 중에서는 영화만큼 긴 것도 없겠네요. 따라서 영화를 이해하는 것, 영화의 장면을 이해하는 것은 정확히 Long-Form Video Understanding의 대표적인 task라 볼 수 있습니다.
영화의 구성 요소인 장면을 이해하는 것은 video moderation, video search, video recommendation오 같은 다양한 application에 도움이 될 수 있습니다. 이러한 영화 이해를 딥러닝에 맡긴다고 가정을 했을 때 지도 학습의 경우 엄청난 양의 annotation 이라는 병목이 항상 필요하게 됩니다.
역시나 저자는 지도학습 대신 Self-Supervised Learning(SSL)의 필요성을 강조합니다. 여기에는 대표적인 두가지 방식이 존재하는 데 1) Contrastive Learning 이 있고, 2) Pretext Task 가 있습니다.
대표적으로 CLIP의 경우 Image-Text Pair를 가지고 Contrastive Learning을 진행한 대표적인 framework 입니다. CLIP 연구의 성공은 자연어 데이터를 기반으로 한 supervision이 존재했기 때문에 가능했지만 이러한 pair를 구성하는 것은 굉장히 긴 Movie Dataset에서는 불가능한 상황입니다.
Pretext Task의 경우도 Scene Understanding과 같은 복잡하고 추상적인 작업에 대해서는 그다지 효과적이지 못했다고 합니다.
이에 저자는 general purpose한 scene representation 을 위한 contrastive learning 알고리즘을 제안합니다. 저자의 key intuition은 쉽게 사용할 수 있는 영화의 메타 데이터(genre, synopsis, co-watch)를 활용하는 것 입니다. 여기서 영화의 메타 데이터는 별다른 라벨링이 필요 없기 때문에 annotation의 부담이 없는 general 한 framework를 만들기에 적합합니다.
영화의 메타 데이터를 바탕으로 movie-level의 비슷한 pair를 구성합니다. 구성된 pair를 바탕으로 positive scene pair를 정의합니다. 유사한 scene을 정의할 수 있다면 그 다음에는 contrastive learning을 바탕으로 scene representation learning을 수행할 수 있겠네요. 아래의 그림을 보면 이해가 가실 겁니다.
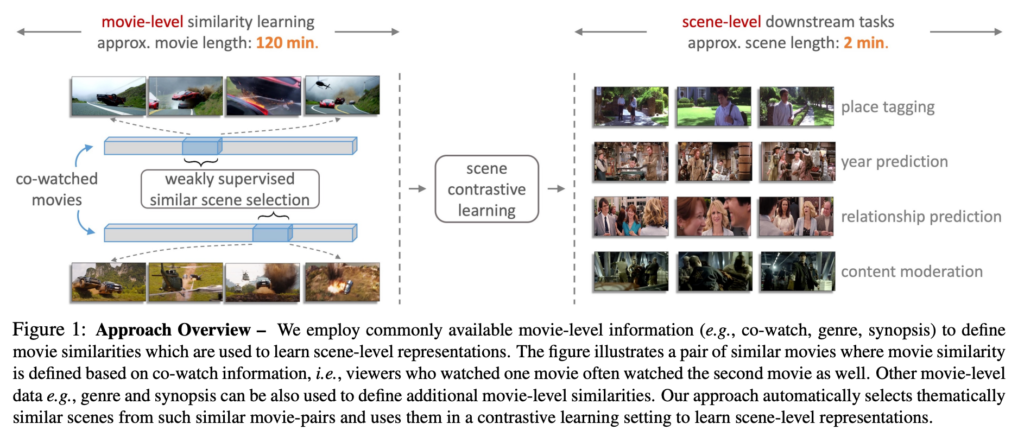
영화의 메타 데이터 중 co-watch는 사용자가 A라는 영화를 구매하고 B라는 영화를 다음으로 시청했을 때 발생하는 relation 정보입니다. 이렇게 영화 끼리 시청된 순서에 따른 연관관계 정보를 co-watch로 정의하고 있으며 이러한 연관 정보가 강한 영화 끼리는 movie-level에서 비슷한 영화라고 pseudo labeling을 한다고 보시면 됩니다.
유사한 두 영화에 대해서 비슷한 장면을 추출하고 이를 가지고 contrastive learning을 통해 일반적인 scene representation을 얻는 것이 방법론의 큰 흐름입니다.
저자는 scene representation 사전학습을 위해 MovieCL30K라는 데이터셋을 제안합니다. 30,340개의 영화 데이터로 구성된 데이터는 11개의 장르로 구성되어 있습니다. 제안된 데이터 셋에 대해서는 뒤에 실험 파트에서 자세히 다루는 것으로 하겠습니다.
또한 저자는 새로운 평가 데이터인 Mature Content Dataset(MCD)를 제안합니다. 연령 제한 동영상에 해당 되는 1) sex, 2) violence, 3) drug-use와 같은 장르에 해당되는 동영상 만을 모아둔 데이터셋 입니다. Video Streaming Service를 제공하는 입장에서는 자동적으로 이러한 비디오를 필터링 하는 것이 굉장히 중요한 서비스인데, 현재의 benchmark 데이터로는 이러한 학습이 불가능하다는 입장입니다.
정리하면 저자는 영화와 같은 굉장히 Long-Form Video Understanding을 위해 새로운 사전학습 데이터인 MovieCL30K를 제안하였으며 효과적인 Contrastive Learning framework를 제안하여 11가지 down-stream task에 대해서 state-of-the-art를 달성합니다. 추가적으로 새로운 장르에 해당되는 MCD dataset을 통해서 앞으로의 새로운 연구 방향에 대해서도 제안을 합니다.
그럼 이제 제안된 방법에 대해서 본격적으로 리뷰 들어가도록 하겠습니다.
Method
본격적인 설명에 들어가기 앞서 일관성을 위해 용어를 정의하고 들어겠습니다.
shot : 하나의 카메라를 가지고 연속적인 시간에 따라 발생하는 프레임들의 집합
scene : 수동 편집된 scene boundary 없이 연속적인 shot 들의 집합 (여기서 scene boundary란 사람이 인위적으로 처리한 영상 편집 기법들을 의미합니다.)
저자가 정의하는 scen은 꽤나 constraint가 적은 정의라 볼 수 있습니다. 단순히 shot의 연속이 scene이라 정의하는 것은 어떤 연구에서는 기피하기 때문입니다(event boundary detection과 같은 곳에서는 좀 더 case를 나누어 정의하곤 합니다.). 하지만 이렇게 naive하게 정의하면 좀 더 일반적인 system에서도 적용할 수 있기 때문에 큰 문제는 없다 보시면 됩니다.
Movie Level Similarity Learning
일단 영화의 메타 데이터를 활용해 movie-level의 유사도를 학습할 수 있는 방법에 대해서 소개하겠습니다.
각각의 영화는 연속적인 shot들로 구성되어 있습니다. 두 영화의 유사도 계산은 두 영화를 구성하는 shot끼리의 인접행렬을 통해 시작됩니다. shot-adjacency matrix를 먼저 얻어야 하는 데 이 과정은 간단합니다.
Fixed Encoder와 Learnable Encoder를 가지고 shot feature 들을 정의하고 두 비디오의 shot feature 끼리 dot-product을 통해 shot-adjacency matrix를 얻을 수 있습니다.
- A_{x_{1},x_{2}}=E_{learnable}\left(E_{fixed}\left( x_{1}\right)\right)\cdot E_{learnable}\left(E_{fixed}\left( x_{2}\right)\right)
이때 A_{x_{1},x_{2}}는 두 영화를 구성하는 shot 끼리의 pair-wise similarity를 담고 있는 인접행렬 입니다.
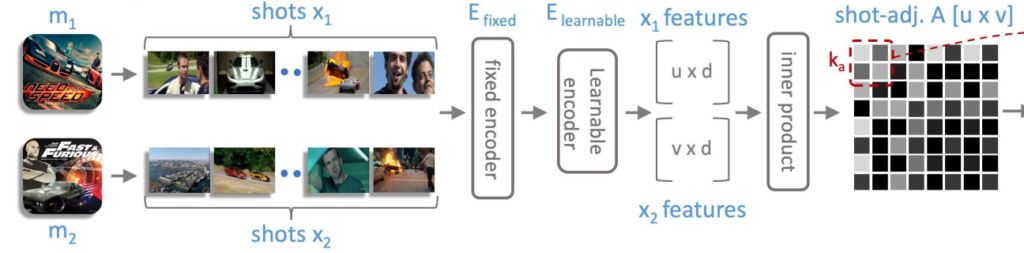
방금 말한 과정이 위의 그림과 같습니다. 크게 어려운 부분은 없다고 생각이 듭니다.
다음으로 k_{a}개의 인접한 shot을 scene이라 가정하고 shot-adjacency matrix를 scene-adjacency matrix로 변환합니다. 여기서는 shot-adjacency matrix에 kernel size가 k_{a}이며 stride가 s_{a}인 average pooling을 A_{x_{1},x_{2}}에 적용합니다.
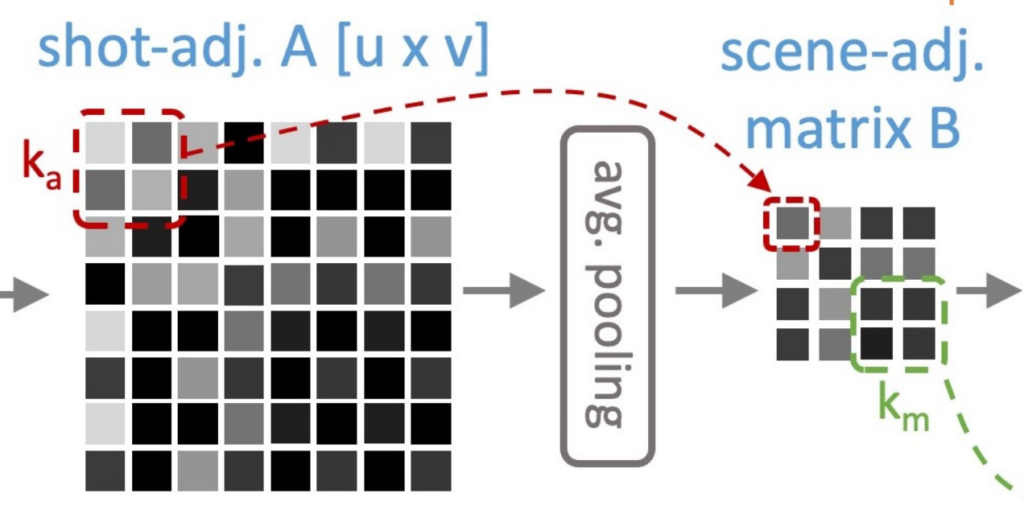
단순히 scene 단위의 유사도는 shot을 일정 부분 grouping 하여 평균 내고 있습니다. 굉장히 나이브하네요.
다시 scene-adjacency matrix를 max pooling + flatten 하여 vector V_{x_{1},x_{2}}를 생성합니다. 이 비디오 level의 벡터를 가지고 linear projection(L_{out})을 시켜 이진 분류를 진행합니다. 이진 분류는 두 비디오가 유사한 관계인지 아닌지 분류하는 작업입니다. 두 영화 비디오가 유사한 관계인지 아닌지를 나타내주는 pseudo label을 정의하기 위해 비디오의 메타 데이터인 1) Co-watch information, 2) Synopsis, 3) Genre 가 사용되었습니다.
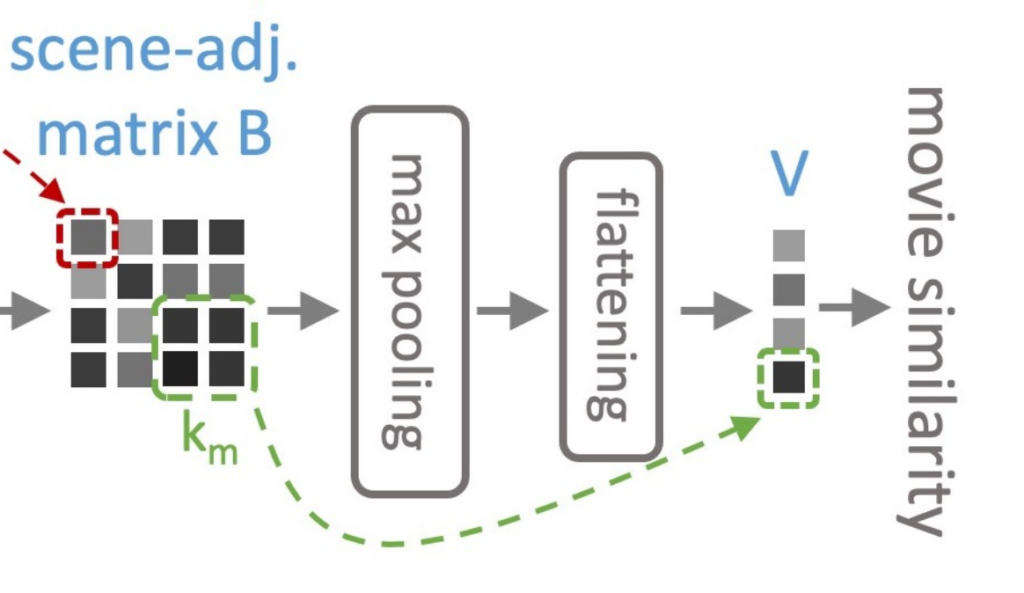
- Co-watch information의 경우 추천 시스템의 구매 기록을 통하여 정의 됩니다. 영화 m_{1}의 경우 영화 m_{1} 다음에 시청된 영화 들의 리스트를 기록합니다. 그리고 ranking을 메겨 m_{1} 다음에 시청된 영화들 중 가장 빈번하게 시청된 영화에 대해서는 둘이 유사한 영화라고 임시 라벨링 하는 방법입니다.
- Synopsis의 경우 영화의 시놉시스를 사전학습된 NLP 모델에 임베딩 시켜 textual embedding을 얻고 영화끼리 textual embedding 유사도를 바탕으로 가장 유사한 영화를 찾아 줍니다.
- Genre의 경우 같은 장르에 있는 비디오 중에서 랜덤하게 비디오를 선택하고 앞서 언급한 Co-watch information 이나 Synopsis의 방식으로 유사도를 결정하고 유사한 영화를 결정합니다.
이렇게 저자는 세가지 메타 데이터를 바탕으로 두 영화 비디오간 유사성을 나타낼 수 있는 binary pseudo label을 만듭니다. 그리고 이를 활용해서 이진 분류를 통해 E_{learnalbe}과 L_{out}을 학습 시킵니다.
Scene Contrastive Learning
앞서 정의된 Movie Pair를 가지고 E_{learnable}(E_{fixed}(\cdot))을 가지고 scene adjacency matrix를 만들 수 있었습니다.
여기서 유사도가 높은 상위 50%의 scene에 대해서는 positive pair를 구성합니다. 비슷한 비디오에서 비슷한 장면을 찾았다고 보시면 됩니다. 그리고 이 pair를 가지고 이제 contrastive learning을 진행합니다.
Scene Encoder
Scene Encoder는 결론적으로 Vision Transformer를 사용합니다. 요즘에 나오는 연구 같은 경우는 이 ViT를 많이 활용하는 것 같은데 미리 읽어두길 잘한 것 같습니다.
예를 들어 k개의 연속적인 frame들로 구성된 shot 하나가 존재할 때
(k,w,h,c)의 차원을 가지는 프레임 텐서를 패치 (k,\frac{w}{p},\frac{h}{p},c)로 분할 합니다. ViT Transformer Encoder의 입력으로 넣어주기 위해서는 Linear Projection이 필요한데 이는 2D Convolution으로 쉽게 가능합니다. Kernel size가 p \times p이고 stride 역시 k \times k 라면 패치 마다 동일한 weight를 가지고 embedding이 가능합니다.
그러면 (k,\frac{w}{p},\frac{h}{p},c) -> (k,D,\frac{w}{p},\frac{h}{p}) 이렇게 되겠죠.
그리고 flatten 시켜 주면 (k,D,\frac{w}{p},\frac{h}{p}) -> (k,D,N), patch들의 연속으로 만들 수 있습니다. k개의 프레임이 존재할 때 하나의 프레임에서 N개의 patch가 존재하고 patch embedding의 차원은 D라고 보시면 됩니다.
Vision Transformer와 동일하게 Class Token을 사용해서 각 프레임 마다 (N+1,D)개의 patch embedding을 생성할 수 있습니다. 그리고 (N+1,D)차원의 position embedding을 더해주면 이제 ViT의 입력으로 넣어줄 수 있겠네요.
위의 과정이 단일 shot에 대해서 진행인데, shot으로 구성된 scene 역시 동일하게 진행해줄 수 있습니다. 저자는 여기서 shot과 scene 간의 frame 갯수가 다르기 때문에 position embedding 과정에서 dimension이 맞지 않는 문제가 발생한다고 합니다. 자세히는 안 나와있지만 이렇게 얘기하는 걸 보면 학습 과정에서는 backpropagation이 shot 단위로 진행되는 것 같습니다.
하지만 positonal embedding을 2차원 보간 진행해주면 간단하게 해결할 수 있다고 합니다.
이렇게 ViT를 사용하면 두 가지의 장점이 존재한다고 합니다.
- Image-level의 large-scale 데이터셋으로 사전학습된 weight를 이용할 수 있다고 합니다.
- position embedding을 2차원 보간 해주면 어떠한 가변 길이에도 대응할 수 있다고 합니다.
사실 위의 내용은 Transformer 구조를 사용하면 당연한 건데 뭔가 본문에는 특별한 의미가 있는 것처럼 조금 길게 내용을 차지하고 있네요..
Contrasive Learning
앞서서 positive pair를 구성했으면 contrastive learning은 쉽게 진행할 수 있습니다. 논문에서는 복잡하게도 써놨는데 MoCO의 방식을 차용한 것 같습니다.
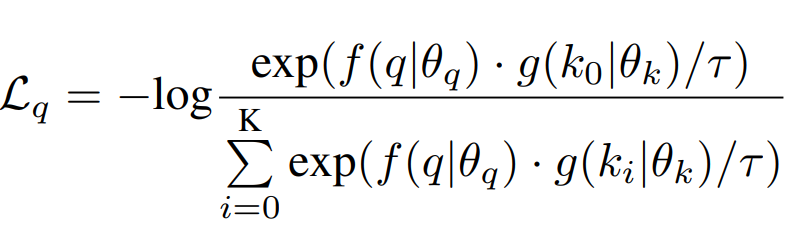
f가 backpropagation으로 업데이트가 되는 query encoder 이며 g가 momentum 방식으로 업데이트 되는 key encoder 입니다. Query Encoder는 당연히 앞서 설명한 ViT Encoder 입니다. 마지막 fc layer 없이 feature만 사용하는 구조인데 여기서 class token에 대한 feature를 사용한다는 얘기는 따로 없지만 정황상 class token의 representation을 사용할 것 같습니다.
Contrastive Learning이 끝나면 ViT Encoder 만을 가지고 이제 다양한 down stream task를 수행할 수 있습니다.
Experiments
Comparisons on Benchmark Datasets
저자는 사전 학습과 downstream evaluation을 진행할 때 중복되는 데이터 셋이 없도록 하였다고 합니다. 무슨 얘기냐면 아래에서 진행되는 모든 실험은 저자가 제안한 MovieCL 30K라는 데이터 셋으로 진행됩니다. 그런데 downstream evaluation으로 사용되는 데이터 셋인 LVU나 MovieNet과 중첩되는 데이터가 있어 그 부분은 사전 학습 단계에서 제외를 하였다는 얘기입니다.
LVU Benchmark
LVU Benchmark는 제가 이전에 리뷰 했던 Towards Long-Form Video Understanding 논문에서 제안한 Long Form Video Understanding 에 해당하는 Benchmark 입니다.
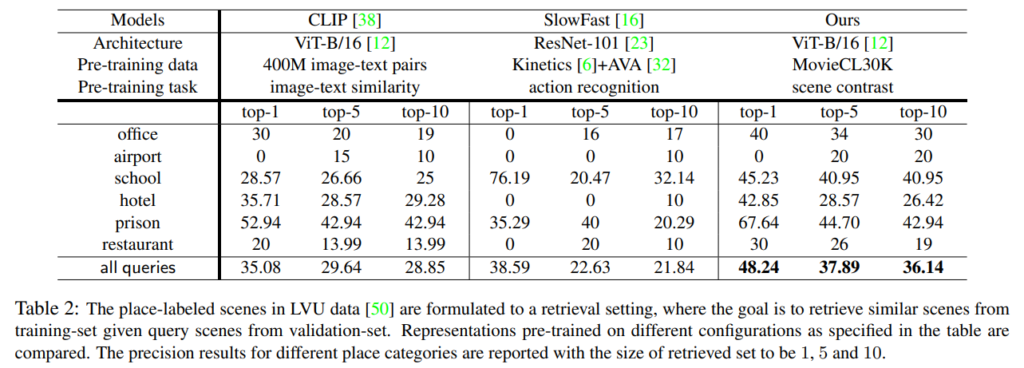
CLIP, SlowFast 그리고 저자가 제안한 방법론 이렇게 세 가지 방법론에 대해서 비교하고 있습니다.
LVU benchmark 에는 다양한 task가 존재합니다. 위의 실험은 일단 Place Retrieval 에 대한 비교 실험이라고 합니다. 다양한 장소에 대해서 저자가 제안한 방법론이 가장 우수한 성능을 보여줍니다.
그런데 여기서 비교 실험을 진행한 각각의 방법론의 Pretraining data가 너무 달라 조금 애매한 감이 있습니다. 물론 CLIP의 경우 Image-Text Pair 가 존재해야 하기 때문에 저자가 제안하는 Long-Form Movie 데이터 셋으로 학습하기는 어려웠을 것입니다. 하지만 SlowFast는 분명히 Movie의 장르를 예측하거나 유사한 관계를 예측하는 등의 사전 학습이 가능했을 텐데 그 결과를 넣지 않은 게 조금 아쉽습니다.
이게 이렇게 되면 성능이 좋은 게 저자가 정말 좋은 framework를 제안해서 높은 건지 아니면 사전 학습 데이터 덕분인지 확실하게 구분이 안 가기 때문에 애매하다고 말씀 드립니다.
일단 이슈는 이 정도로 정리하고 정성적 결과 보도록 하겠습니다.

CLIP 과의 place retrieval 정성적 결과를 비교하고 있습니다. CLIP의 경우 애매한 장면에 대해서는 뭔가 시각적인 정보를 바탕으로 reasoning 하는 것 같은데 저자가 제안하는 방법은 어떻게 유추하는 건지 참 잘 맞추네요.
저자는 이러한 비교를 통해 본인들의 방법론이 단순히 visual clue 뿐만 아니라 semantic information도 잘 capture를 한다고 주장합니다.
다음은 LVU benchmark의 다른 정량적 task 입니다. view-count나 like ratio와 같은 연속적인 값을 맞추는 regression 문제 들이 있고, 다른 7가지의 classification task가 존재합니다.
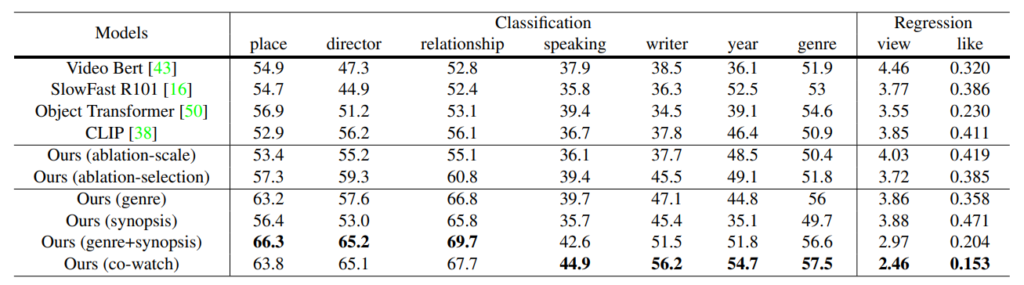
일단 저자가 제안하는 방법이 LVU benchmark의 새로운 sota를 보여주고 있습니다. 여기서 genre + synopis를 가지고 만들어낸 pseudo label을 사용했을 때의 성능과 co-watch 만을 가지고 만들어낸 pseudo label을 사용했을 때 학습 방법 마다 특정 task의 성능이 높아지는 경향이 있습니다.
양상이 다른 이유는 장르나 시놉시스는 사실 두 개의 관계가 어느 정도 correlation이 있는 반면에 co-watch의 경우는 사람마다 관계가 다르게 그려지기 때문에 조금 더 복잡한 관계를 내포하고 있기 때문의 둘의 결과가 조금 다르게 나타난다고 설명하고 있습니다.
성능이 일단 제일 높은 건 알겠는데, genre + synopsis + co-watch를 다 사용한 건 왜 없는지 궁금하네요.
MovieNet Benchmark
LVU benchmark 말고 MovieNet Benchmark 에서도 평가를 진행합니다.
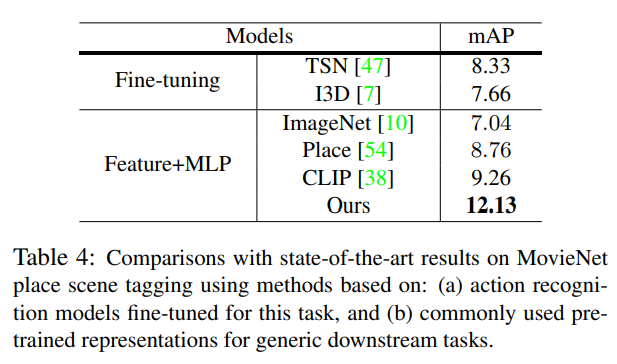
일단 성능은 가장 높습니다. Place tagging 이라고 해서 classification task라 하는데 정확히 어떤 것인지는 저도 잘 모르겠습니다. 영화 장면을 보고 장소를 예측하는 것이 아닌가 예측해봅니다.
아쉬운 점은 기존의 다른 방법론들이 성능이 좀 많이 낮은데 이런 이유에 대해서 저자의 insight가 있었다면 조금 더 좋았을 것 같습니다. 논문에는 그냥 “우리의 방법론이 성능이 제일 높다.” 라고만 서술 되기 때문입니다.
다음은 Scene Boundary Detection Task에 대한 benchmark 입니다. 개인적으로 여기는 조금 인상 깊었던 부분이 있습니다.
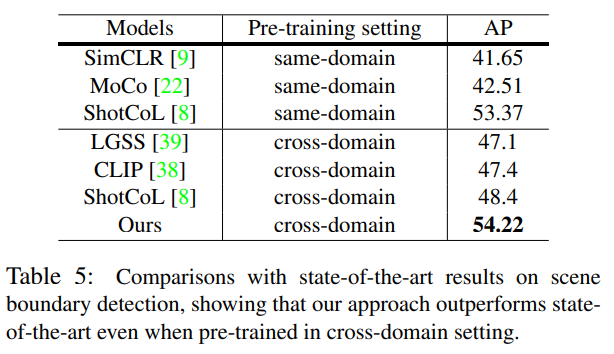
테이블을 보시면 Pre-training setting에서 same-domain, cross-domain 이렇게 나뉘는 것을 확인할 수 있습니다.
여기서 same-domain은 사전 학습도 MovieNet 그리고 평가도 MovieNet으로 진행한 경우입니다. cross-domain은 사전 학습과 평가의 데이터 셋이 다른 경우입니다.
저자의 방법론은 사전 학습을 비록 저자가 제안한 MovieCL30K라는 데이터 셋으로 진행했지만 cross-domain의 상황에서 평가를 진행해도 다른 방법론들에 비해 성능이 많이 높다는 것이 인상 깊습니다.
ShotCoL이라는 방법론은 same-domain, cross-domain 두 가지 방식 모두 평가를 진행 했는데 same domain 일 때 성능이 높다가 cross domain의 상황에서는 성능이 확 떨어지는 양상을 보여주고 있습니다.
Video Moderation
Video-Moderation 이라고 해서 저도 이번에 처음 알았는데 비디오 모니터링이라 보면 됩니다. 유해한 콘텐츠가 Video Streaming Service 에 올라오면 바로 차단을 해야 하고 이런 것을 video moderation이라 부르는 것 같습니다.
하지만 현재 비디오 분야에서 자주 사용되는 benchmarking dataset(Kinetics, AcitivtyNet, Thumos, AVA, LVU, Muses.. etc) 들은 유해한 비디오에 대해서는 자세히 다루지 않습니다.
저자는 이제 video streaming service를 위한 age-appropriate activities를 검출할 수 있는 데이터셋을 제안합니다. Mature Content Dataset 입니다. 논문에는 어노테이션 과정도 자세하게 서술이 되어 있는데 대충 우리가 제안하는 데이터셋의 라벨링이 매우 정교하게 이루어졌다는 내용입니다.

sex, violence, drug-use와 같은 카테고리에 해당되는 장면들이 존재합니다. sex에 해당되는 예시는 모자이크 처리기 되어있지만 굳이 올리고 싶진 않아서 가리도록 하겠습니다.(궁금하시면 직접 찾아 보시길…)
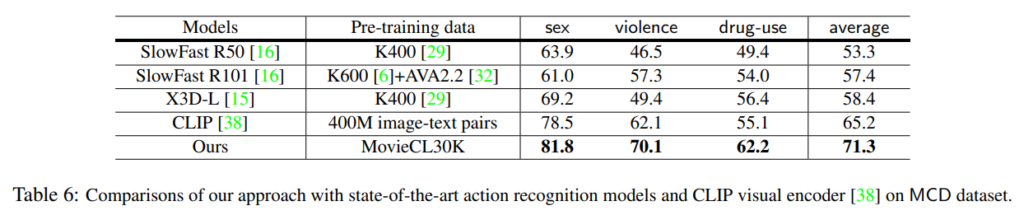
MCD dataset을 가지고 평가를 진행했을 때의 비교 실험 입니다.
이러한 자극적인 콘텐츠에 대해서도 좋은 성능을 보여주는 것이 그래도 저자의 framework (pretrain + learning method)가 꽤나 효과적임을 보여주는 것 같습니다.
앞으로는 이러한 자극적인 콘텐츠에 대해서도 효과적인 비디오 모델이 등장해야 stream market에서 효과적인 application을 제공할 수 있다고 저자는 주장합니다. 저도 이러한 주장에 대해서는 동의합니다. 좋은 연구인 것 같네요.
Conclusion
arXiv에 올라온 논문이고 포맷을 보아하니 CVPR2023에 submit한 논문인 것 같습니다. 실험의 결과 자체는 인상적이지만 성능이 전적으로 본인들이 제안한 사전 학습 데이터에 의존하는 듯한 모습을 보여줬습니다. 다른 방법론들과의 비교에서 사전 학습 데이터는 본인들이 제안한 데이터 셋으로 고정했으면 더욱 fair한 비교가 됐을 거 같은데 그 부분은 조금 아쉬웠습니다.
그럼에도 새로운 데이터 셋을 두 가지나 제안한 것은 분명한 strong contribution으로 작용할만한 부분입니다.
아직까지 제가 읽어본 논문들은 비디오의 frame 혹은 shot 단위의 유사도를 측정할 때 인접 행렬을 사용하는 논문만 존재했는데, 다른 방식으로 유사도를 정의하는 논문도 만나보고 싶습니다.
리뷰 읽어주셔서 감사합니다.
안녕하세요 임근택 연구원님. 리뷰 잘 읽었습니다.
진짜 Long-form 비디오 연구가 슬슬 나오는걸 보니 인상깊네요.
두가지 질문이 있는데요. 이 논문에서 정의하는 Scene에 평균적으로 몇개의 Shot이 포함되는지에 대한 정보가 있는지가 궁금합니다. 그리고 Movie Level Similarity Learning 과정을 보면 비디오 끼리 Shot feature들을 바탕으로 계산을 하는데, 특정 구간을 자른 페어 기반으로 학습을 수행하는 것이 아니라 2시간 짜리 영화 전체에서 모든 Shot을 기반으로 학습을 진행하는 것인지도 궁금합니다. 혹시 맞다면 학습 시간 얼마나 걸렸는지가 궁금하네요.
이 논문에서 정의하는 Scene에 평균적으로 몇개의 Shot이 포함되는지에 대한 정보가 있는지가 궁금합니다. => 9개 입니다.
Shot을 기반으로 학습을 진행하는 것인지도 궁금합니다
=> 네 맞습니다.
혹시 맞다면 학습 시간 얼마나 걸렸는지가 궁금하네요.
=> 논문에 안나와있어 모르겠네요.
임근택 연구원님, 안녕하세요.
최근 비디오 논문 리뷰 위주로 보고있는데, 논문마다 비디오를 나누는 기준이 조금씩 다른 것이 흥미롭습니다.
혹시 논문에서 인코더를 Fixed 인코더와 learnable 인코더로 나눈 이유는 무엇인가요? 그리고 fixed encoder같은 경우는 뭔가 다른 곳에서 학습이 된 encoder인가요? 아니면 완전히 랜덤으로 초기화되고 전혀 학습되지 않은 인코더인가요?
혹시 이런 구조가 흔히 사용되는 건지도 궁굼합니다!
감사합니다.
본 논문에서 얘기하는 fixed encoder는 흔히 얘기하는 ImageNet으로 사전학습된 ResNet-50이나 Vision Transformer(ViT)에 해당됩니다.
혹시 이런 구조가 흔히 사용되는 건지도 궁굼합니다!
=> 실험 하기 나름인 것 같지만 fixed encoder 까지 backpropgation을 시키면 메모리와 연산량이 많이 필요하니 보통은 Pretrain Backbone(ResNet,ViT)은 그냥 BoVW, VLAD 마냥 feature extractor로 사용하는 경우가 많긴 합니다.