이번에 들고온 논문은 열화상 영상과 컬러 영상 간의 cross-modal image retrieval에 해당합니다. MDII와 동일하게 Visble 2 Intrared 혹은 그 반대의 영상 검색을 목적으로 합니다.
Intro
멀티 모달 센서는 다양한 분야에서 활용되며, 특히 감시 카메라 분야에서는 컬러 카메라와 열화상 카메라 조합의 멀티 모달 센서를 활발하게 이용하고 있습니다. 두 카메라는 서로 상호적인 특성을 가지고 있습니다. 컬러 카메라인 경우에는 컬러 정보와 텍스쳐 정보를 가지고 있지만 조도에 심하게 의존적입니다. 반면에 열화상 카메라는 적은 조도에서도 강인하며, 심지어 인공적인 빛 없이도 잘 동작하지만 텍스쳐 정보가 불충분하다는 단점을 가지고 있습니다.
컬러 카메라와 열화상 카메라 조합의 상호 보완적 특성을 살리기 위한 많은 연구들이 존재합니다. 첫번째로는 registration methods가 있습니다. 해당 연구는 두 가지 관점으로 나눌 수 있습니다. 하나는 지역적인 특징을 검출하여 두 카메라 사이의 시점간 관계를 카메라 기하학으로 해석하는 방법이 있습니다. (신정민 연구원이 연구하는 분야라고 생각하시면 됩니다.) 또 다른 방법으로는 의미론적인 해석을 통한 registration이 있습니다. 해당 방법은 주요 관심을 가지고자 하는 대상(예를 들어, 사람)의 영역만 이동시키는 방법에 해당합니다. (대표적인 예시로 M3D dataset이 있습니다.) 하지만 registration methods는 동기화된 두 모달리티 영상이 없다면, 제대로 동작하기 어렵다는 문제가 있습니다.
반면에 image retrieval은 동기화 없이 query 영상과 데이터 베이스 속 영상들 간 유사성을 정략적으로 평가하여 구조적 혹은 의미론적 유사한 영상을 찾아낼 수 있다는 장점이 있습니다. 저자는 image retrieval의 장점을 살려 열화상 영상과 컬러 영상, cross-modal image retrieval을 제안합니다. (저자가 주장하길 해당 태스크에 대한 구체적인 연구는 자신들이 처음이라고 주장하네요)

저자는 열화상 영상과 컬러 영상 간 영상 검색의 challenge 요소들을 다음과 같이 정의합니다.
- 컬러 영상과 열화상 영상의 다른 특성(Different imaging effect, fig 1-(a))
- 서로 다른 시점을 가진 영상 쌍(Different imaging angles, fig 1-(b)),
- 저화질의 열화상 영상으로 인한 유사한 열화상 영상(The similarity of infrared images, fig 1-(c)).
열화상 카메라는 기술의 문제로 낮은 화질을 보여줍니다. fig 1-(c)의 열화상 영상은 서로 다른 사람이 같은 장소에서 비슷한 동작을 취한 영상에 해당합니다. 보이는 바와 시각화 정보가 부족하다는 문제로 인해 구분이 힘들다는 문제가 있습니다.
하지만 두 모달리티는 여전히 잠재적인 유사한 특징을 가지고 있습니다. 저자는 해당 특성을 고려하면서 위에서 언급한 문제점을 해소하는 방법을 제안합니다.
Method
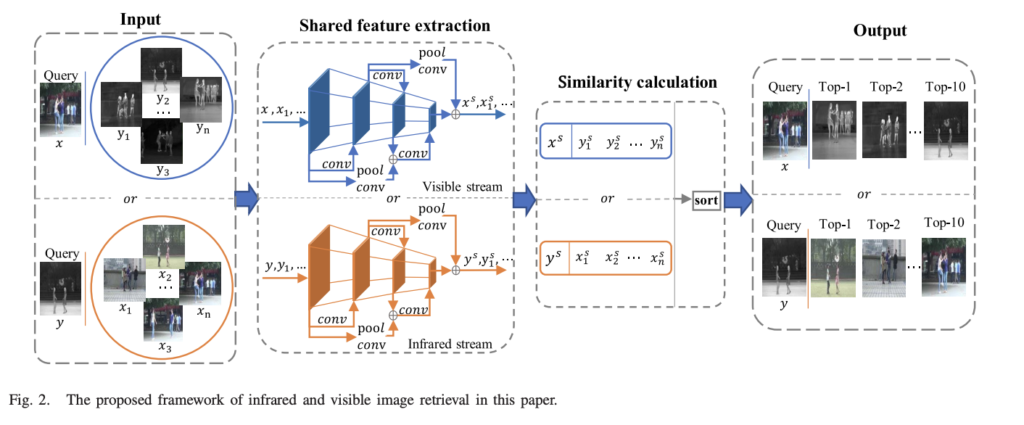
Overview
전반적인 파이프 라인은 fig 2와 같습니다. 쿼리 컬러 영상 x가 주어져 있을 때, 열화상 영상 셋 {y_1, y_2… y_n}으로부터 가장 유사한 열화상 영상을 찾아야합니다. 두 모달리티가 반대인 경우에도 동일하게 동작합니다. 먼저, two steam으로 구성된 shared feature extraction module으로부터 shared features \{ x^s, y_{1}^{s}, y_{2}^{s}, ..., y_{n}^{s} \} 를 추출합니다. 그 다음 두 모달리티 피쳐를 Euclidean distance를 기반으로 유사성에 대한 랭킹을 세워 가장 유사한 영상 순으로 추려냅니다.
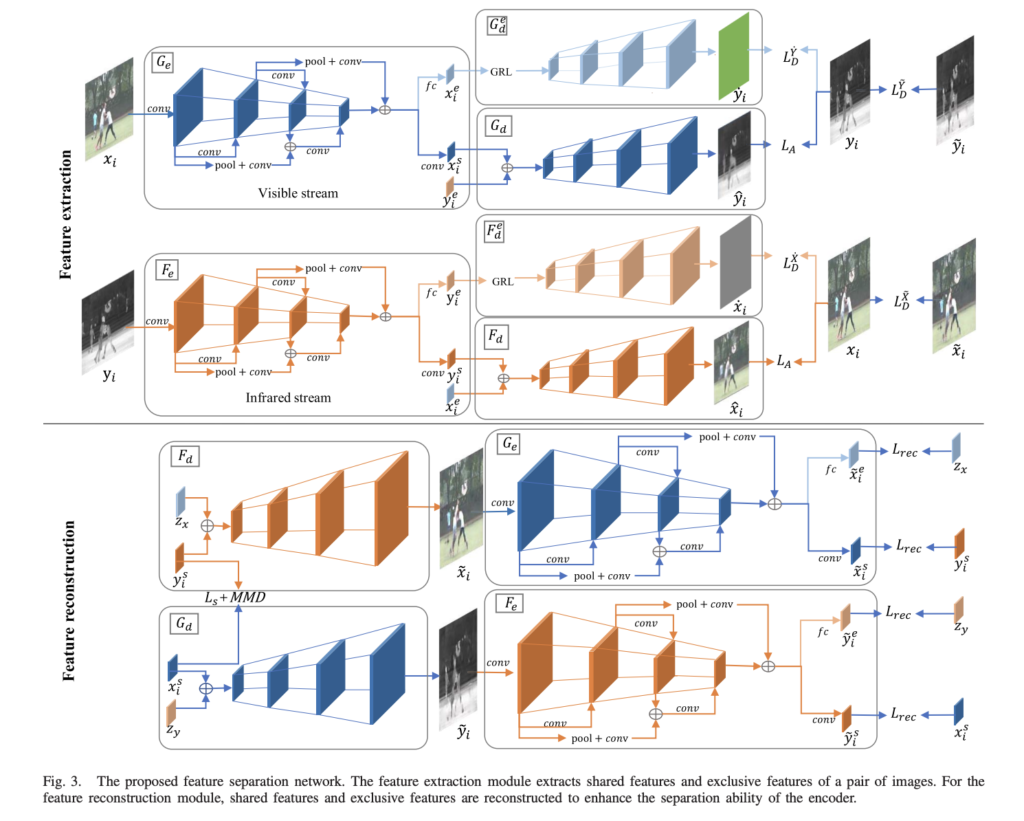
Feature Separation Network
Feature Separation Network은 feature extraction과 feature reconstruction 두 가지 모듈로 구성됩니다. feature extraction은 영상으로부터 shared feature와 exclusive feature로 나눠 특징을 추출함으로써, 두 모달리티의 영상 측면에서 shared feature 제약을 걸고, feature reconstruction은 feature 측면에서 제약을 거는 것을 목적으로 합니다.
Feature extraction.
한 쌍의 컬러 영상과 열화상 영상들을 visible stream G_e , infrared stream F_e 에 각각 입력합니다. 두 encoder의 마지막 단에서 컨볼루션 레이어를 통해 shared feature x_{i}^{s}, y_{i}^{s} 를, FC 레이어를 통해 exclusive feature x_{i}^{e}, y_{i}^{e} 를 얻습니다. shared feature x_{i}^{s}, y_{i}^{s} 는 두 모달리티 간의 유사도 시각 정보를 가지고 있습니다. 저자는 해당 정보를 얻기 위해서 L1 Loss와 MMD(Maximum Mean Discrepancy) Loss를 이용하며 먼저 L1 Loss는 다음과 같은 방법을 사용합니다.
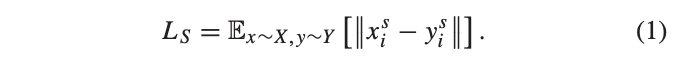
MMD는 서로 다른 상대적인 분포간의 거리를 측정하기 위한 도구로, transfer learning 태스크에서 흔한게 많이 사용하는 Loss에 해당합니다. 해당 Loss는 source domain을 target domain으로 변환하기 위한 거리 값 최소화 도구로 사용합니다. 저자는 이에 대해 영감을 얻어 두 모달리티의 shared feature 간의 거리를 가깝게 만드는 용도로 사용합니다. MMD Loss는 다음과 같습니다.
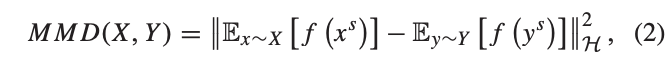
위의 식에서 f는 mapping function으로 Reproducing Kernel Hilbert Spaces (RKHS)에 해당합니다.
++ MMD는 두 분포의 평균을 L2 norm으로 최소화하는 방법을 이용합니다. 허나 단순하게 해당 방법을 적용하게 되면 두 분포 복잡도로 인해 원하는 방향으로 최적화가 이뤄지지 않을 수 있습니다. 이러한 문제를 해결하기 위해 커널을 이용하여 분포의 복잡도를 해소하는 방법을 사용합니다. RKHS도 복잡도를 해소하기 위한 커널의 한 종류입니다.
+++ RKHS의 원리에 해당 링크를 참고하시길 바랍니다.
Exclusive feature x_{i}^{e}, y_{i}^{e} 는 두 모달리티의 독립적인 특징만을 가집니다. 즉, x_{i}^{e} 는 진짜 열화상 영상을 생성하지 못하고, 그 반대도 동일합니다. 이를 달성하기 위해 저자는 domain-agonostic을 학습하기 위한 도구인 Gradient Reversal Layer (GRL)을 적용합니다. GRL은 decoder G_{d}^{e} 의 앞단에 위치하며, decoder는 x_{i}^{e} 로부터 fake image \dot{y_{i}} 을 생성합니다. 다른 모달리티에서도 동일한 작업을 수행합니다.
+ GRL은 domain adaptation 분야에서 사용되는 기법이며, 손실 함수의 값을 최소화하는 기존의 역전파와 다르게 음수를 붙여 손실 함수를 극대화하도록 학습하는 방법입니다. 이는 domain 간 독립적인 특성을 명확하게 구분할 수 있도록 합니다.
두 모달리티로부터 생성된 exclusive feature는 서로 교환되며, (x^{s}_{i}, y^{e}_{i}) 를 G_d 에 전달되어 영상 /hat{y_{i}} 을 생성합니다. 반대 모달리티도 F_d 를 통해 영상을 생성합니다. 해당 기능은 영상 측면에서의 shared feature를 정렬하기 위해서 사용됩니다. alignment loss는 L1 Loss를 이용하며 다음과 같이 정의 됩니다.
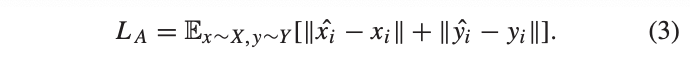
Feature reconstruction.
해당 모듈은 (x_{i}^{s}, z_{y}) 를 G_d 에 입력하여 fake image \tilde{y_i} 를 생성합니다. 이전과 동일하게 반대 모달리티도 적용합니다. Gaussian noise z_y 는 N(0, 1)에서 샘플링됩니다. 여기서의 fake image는 real image와 유사하도록 학습을 진행합니다.
fake image \tilde{y_i} 는 encoder G_e 에 다시 입력되어 reconstruction shared feature \tilde{y_{i}^{s}} 와 exclusive feature \tilde{y_{i}^{e}} 을 추출합니다. Reconstruction loss는 \tilde{y_{i}^{s}} 와 y_{i}^{s} , \tilde{y_{i}^{e}} 와 z_y 들이 같아지도록 유도합니다. 즉, feature 측면에서 두 모달리티의 값들이 유사하지도록 제약을 겁니다. Reconstruction loss는 아래와 같습니다.

Adversarial Loss.
리뷰 논문에서는 총 4개의 generators로써의 decoder를 사용합니다. 저자는 generators의 안정적인 학습을 위해 WGAN-GP에서 제안한 아래와 같은 loss를 이용합니다.
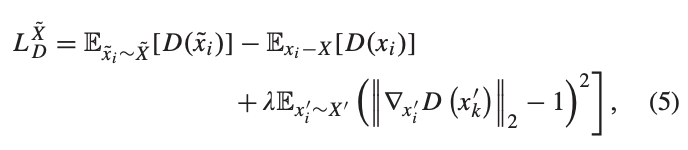
++ WGAN-GP의 loss에서는 WGAN의 critic weight clipping이 좋지 못한 방향으로 이끄는 것을 방지하기 위해 Gradient Penalty를 사용할 것을 제안합니다. 이에 대한 수식이 수식 5의 3번째 수식으로 간단하게 설명하자면, X’는 복원 영상과 타겟 영상을 일정 비율 섞은 영상으로 이를 이용하여 gradient의 제약을 걸어주는 방법을 이용합니다. 자세한 내용은 논문 (상단 하이퍼링크)를 참고하시길 바랍니다.
D()는 discriminator로 single scalar를 출력합니다. 각 decoder는 동일한 loss를 사용하며, 전체 loss는 아래와 같이 정의됩니다.
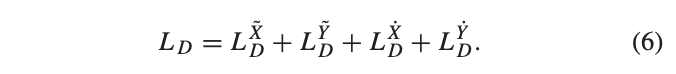
Instantiation
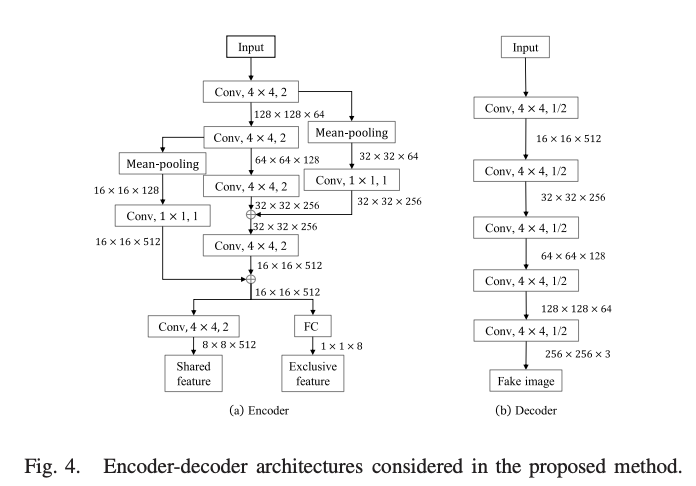
encoder와 decoder는 fig 4와 같은 구조를 가집니다.
Overall Loss
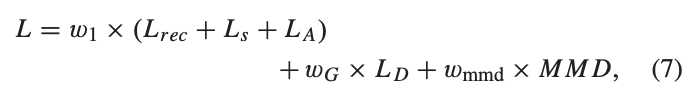
Similarity Measurement
유사도 측정은 shared feature 만을 이용하며, L2 norm으로 거리를 측정합니다. 이를 정의하면 아래와 같습니다.
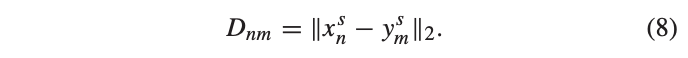
EXPERIMENT
Datasets

데이터 셋은 공개된 infrared-visible video datset[1]을 이용합니다. 해당 데이터 셋은 12의 액션 (one hand wave, two hand wave, clap, walk, jog, jump, skip, shake hands, hug, push, punch and fight)을 포함합니다. 각각의 액션은 13 장소에서 촬영되었습니다. 저자는 실험을 위해 열화상 비디어 기준으로, 컬러 영상과 이에 대응되는 열화상 영상을 1~2 프레임을 추출하였으며, 총 1,363 쌍의 영상으로 구성하였습니다. 해당 데이터는 학습:평가, 9:1로 구분하였습니다. 각 영상 쌍은 단 하나의 ground truth를 가지고 있습니다.
[1] L. Wang, C. Gao, Y. Zhao, T. Song, and Q. Feng, “Infrared and visible image registration using transformer adversarial network,” in Proc. 25th IEEE Int. Conf. Image Process. (ICIP), Oct. 2018, pp. 1248–1252.
Quantitative Evaluation
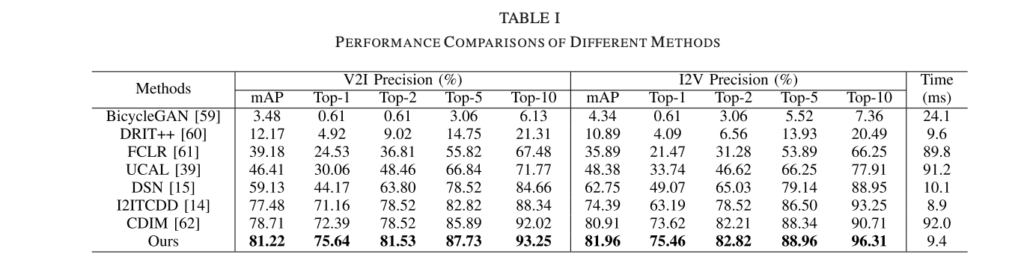
FCIR: single-modal retrieval method -> siamese architecture 구성
UCAL: 비지도 학습 기반 cross-modal retrieval 방법론
CDIM: cross-domain image matching with deep feature maps
BicycleGAN, I2ITCDD: image translation
DRIT++, DSN: domain separation networks
DRIT++, BiCycleGAN -> pixel alignment method -> 가장 낮은 성능
UCAL, FCIR -> single modal method -> 위보다 나은 성능을 보임
I2ITCDD, DSN -> shared feature -> single modal 보다 좋은 성능을 보임 -> 두 모달리티를 고려하는 것이 좋다는 증거
CDIM -> similarity measure way -> 비교 방법론 중 가장 좋은 성능을 보임 -> 유사도 측정의 효과를 보여줌
비교를 위한 다른 방법론들도 나쁘지 않은 결과를 보여주었지만, 저자가 주장하길 각 방법론들은 두 모달리티의 특성을 고려하지 못하기 때문에 제안하는 방법론 보다 낮은 성능을 보여준다고 말합니다.
Qualitative Evaluation


V2I와 I2V에서 정성적으로 가장 좋은 결과를 보여줍니다.

Fig 9는 물체가 없는 background에서의 결과이며, 물체가 없는 경우에도 좋은 결과를 보여줌으로써, 의
Ablation study
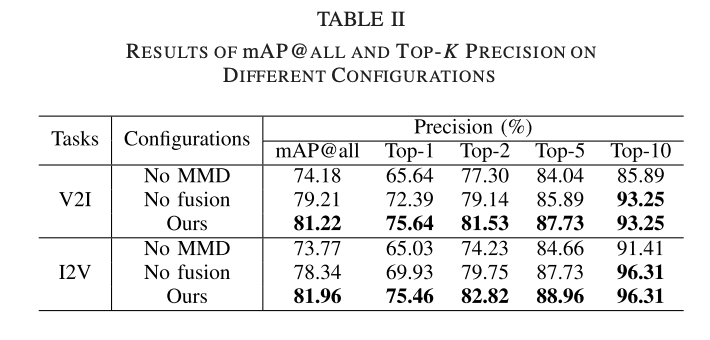
Table 2는 MMD Loss의 효과와 fusion layer의 효과를 보이기 위한 실험으로 MMD loss에서는 7% 정도의 성능 개선을 보여주고 있습니다.
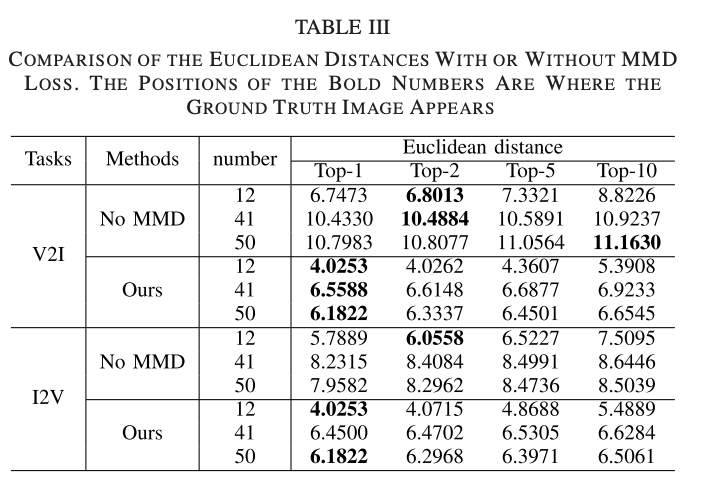
가장 흥미로운 실험은 Table 3에 해당합니다. 해당 실험은 MMD의 유사도 측정 성능에 대한 영향력을 보이기 위한 실험입니다.
해당 논문은 크로스 도메인을 이용한 위치 인식 연구 – 기본 연구의 확장 연구를 위해 찾아본 논문 입니다. 해당 논문이 하고자 하는 태스크와 직결되기도 하지만 해당 논문에서 사용한 데이터는 사람의 액션을 중심으로 구성된 데이터 셋입니다. 저희가 하고자 하는 태스크는 위치 인식 태스크이기에 유동적인 물체인 사람보다는 고정적인 배경에 집중하여야만 합니다. 물체의 열 정보를 측정하는 열화상 영상의 특성상 사람과 같은 유동적이 물체에서 뚜렷한 모습을 보이는 문제가 있습니다. 그렇기에 해당 방법론을 필두로 유동적인 물체가 아닌 배경에 집중할 수 있는 방법을 적용해볼 예정입니다.
좋은 리뷰 감사합니다.
shared feature extraction module라고 하셨는데, 그렇다면 각 모달리티에 대한 feature를 추출하는 CNN 모델은 동일한 파라미터를 공유하고 있는 것인지 궁금합니다. 그렇지 않다면 어떤 점에서 “shared” 라고 하는 것이지 설명해주시면 감사하겠습니다..
GRL이라는 개념이 낯설게 느껴지는 데, 컬러 영상과 열화상 영상이 독립적으로 학습이 되도록 하는 역할을 한다고 이해하였습니다. 제가 제대로 이해한 것이 맞을까요? 그렇다면, domain-agnostic해지는 것이 아니라 오히려 domain에 특정하게 학습이 되는 것은 아닌가요??
1. ‘shared feature extraction module라고 하셨는데, 그렇다면 각 모달리티에 대한 feature를 추출하는 CNN 모델은 동일한 파라미터를 공유하고 있는 것인지 궁금합니다. 그렇지 않다면 어떤 점에서 “shared” 라고 하는 것이지 설명해주시면 감사하겠습니다.’
-> 각 모달리티는 독립된 파라미터를 가집니다. 본 논문에서 ‘shared’의 의미는 ‘weight를 공유’하는 것이 아닌 ‘공통된 feature space를 공유’한다는 의미에서 사용된 것입니다.
2. ‘GRL이라는 개념이 낯설게 느껴지는 데, 컬러 영상과 열화상 영상이 독립적으로 학습이 되도록 하는 역할을 한다고 이해하였습니다. 제가 제대로 이해한 것이 맞을까요? 그렇다면, domain-agnostic해지는 것이 아니라 오히려 domain에 특정하게 학습이 되는 것은 아닌가요??’
-> domain에 특정하게 학습되는 것이 맞습니다. domain-agnostic도 그런 의미로 사용되었습니다.