아주 오랜만에 X-review를 작성하는 거 같습니다.
신년이 시작했기 때문에 새 마음 새 뜻으로 열심히 작성 해야겠습니다.
오늘은 Self-Supervised Learning 에 대해 제가 공부 한 내용들을 리뷰하겠습니다.
방학동안 Multimodal Self-Supservised Learning 관련 연구를 수행 할 예정이여서
이를 위해 Self-Supervised 방법론을 공부 해야 할 필요성이 생겼기에 해당 주제를 선정하게 되었습니다.
Self-Supervised Learning 논문을 읽는 것은 처음이기에 흐름과 틀을 파악하는데 집중하였고,
이에 대해 제가 공부한 내용들을 전반적으로 설명드리겠습니다.
후반부에 MoCo에 대한 간단한 설명도 진행되는데, 간단하게 소개만 하는 거여서 내용이 많이 부실 할 수 있습니다.
앞선 홍주영, 황유진 연구원의 훌륭한 리뷰를 참고하시면 MoCo를 이해하는데 더 큰 도움이 되리라 생각합니다.
그럼 리뷰 시작하겠습니다.
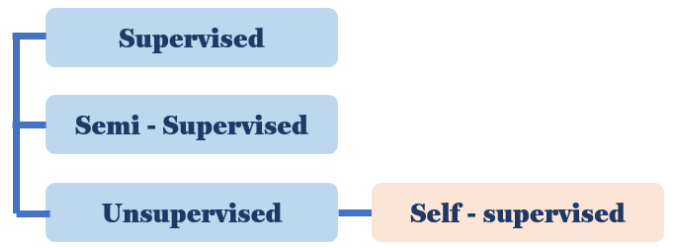
Self-Supervised Learning
시작하기 전 Self-Supervised Learning 논문을 처음 읽는 것이라 해당 방법론에 대한 전반적인 이해가 필요하였습니다.
그래서 간단하게나마 Self-Supervised Learning에 대해 제가 공부한 내용을 정리하고 MoCo 리뷰를 시작하고자 합니다.
모델을 학습하기 위해서는 데이터가 필요합니다.
그리고 보통은 Label을 가진 데이터를 사용해서 Supervised 방식으로 학습 시키는 것이 일반적입니다.
하지만 실제 데이터에 label을 부여하는 annotation 과정은 시간,비용 적으로 매우 expensive 하기 때문에
모든 데이터에 label을 부여하는것이 현실적으로는 거의 불가능합니다.
이러한 상황에서 label이 없는 데이터를 사용해 모델을 학습하고자 하는 필요성이 증가하였고,
해당 방법론을 Unsupervised Learning이라 칭합니다.
그리고 이 중에서도 스스로(self) supervision을 만들어서 모델을 학습하는 방식을 Self-Supervised 라고 합니다.
(여담으로 예전에는 Self-Supervised가 정답을 사용하지 않는다는 이유로 Unsupervised의 일종으로 보기도 하였지만,
스스로 supervision을 만들어서 학습하기 때문에 Self-Supervised를 Unsupervised와는 다르게 봐야 한다는 주장이 제기되고 있습니다.)
여기서 우리는 당연히 정답이 존재하는 Supervised 방식이 존재하지 않는 Self-Supervised 보다 성능이 일정 수준 이상 높을 것이라고 추측할 수 있습니다. 하지만 여러 task들에서 Self-Supervised 방식이 Supervised과 성능이 유사하거나, 오히려 능가하는 수치를 보여줍니다. 오늘 리뷰하게 될 MoCo에서 진행한 실험에서도 이를 리포팅하고 있구요.
사실 해당 부분에 대해서 상식적으로 이해가 가지는 않았지만, 어느정도 납득(?)을 시켜 준 블로그 글이 있습니다.
해당 블로그 글을 참고하였고, 블로그 글쓴이는 Alexei A. Efros 교수님의 해당 발표 영상을 참고하였다고 하네요.

우리가 흔히 알고 있는 CNN 분류 모델이 Supervised 방식으로 학습을 진행한다고 생각 해 봅시다.
모델에는 Chair, City 이미지와, 이에 해당하는 정답 label이 입력으로 들어가게 됩니다.
아래 설명에서는 의자로 예시를 들도록 하겠습니다.
모델은 다양한 종류의 의자 그림과, 동일한 Chair라는 class를 입력으로 받게 됩니다.
여기서 모델은 위 그림처럼 각양각색으로 생긴 의자를 Chair로 예측하기 위해
공통된 feature를 추출하는 방향으로 학습을 진행하게 됩니다.
하지만 사람은 어떠한 인지 과정을 거쳐서 의자를 의자라고 분류할까요?
사람들이 어렸을 때 의자를 의자라고 분류할 수 있는 이유는 ‘다리가 길고, 사람이 앉는 곳이 있고~’ 등등
누군가가 의자의 형태 하나하나를 묘사하며 의자라고 알려주었기 때문이 아니라,
먼저 각각의 의자 특성을 잘 파악하고 서로 유사한 지 아닌지 비교해나가는 과정을 통해 새로 마주하게 된 의자를 의자라고 분류할 수 있는 것입니다.
즉, 애초에 위 그림처럼 각양각색의 의자들을 모두 Chair라는 동일 class로 가정하고 출발하는 것 자체가
인간의 학습 방식과는 맞지 않다고 언급합니다.
이러한 문제를 해결하기 위해 딥러닝 모델 또한 사람과 유사하게,
각각의 의자 이미지들에 대한 특성을 잘 파악하는 것이 우선시 되어야 한다고 합니다.
즉, “해당 이미지들이 무엇인지를 학습하는 것이 아닌 해당 이미지들이 무엇과 유사한지를 살펴보도록 하는 게
인간의 학습 관점에 더 맞다” 라고 판단 한 것입니다.
이러한 관점에서 보면, 데이터셋에 정답 label이 없는 상황에서 각 이미지들의 feature를 잘 표현(representation) 하는 방향으로 학습을 진행하는 Self-Supervised 학습 방식이 일부 task에서 Superviseㄴd와 유사한 성능을 보이는 것이 살짝은 납득이 가긴 합니다,,
그리고 이러한 원리는 아래에서 설명드릴 Self-Supervised 학습 방식 중 Contrastive Learning과 유사하다고 볼 수 있겠네요. Positive와 Negative 사이에서 유사도를 판단하는 학습 방식이니까요. 이에 대해서는 추가적으로 설명을 드리겠습니다.
Pretext Task & Downstream Task
어쨌든 unlabeled dataset에 대해 self로 label을 직접 만들어서 사용하는 Self-Supervised 학습 방식은 크게
pretext task와 downstream task로 나누어 집니다. 아래 그림이 이를 잘 설명해 주고 있네요.
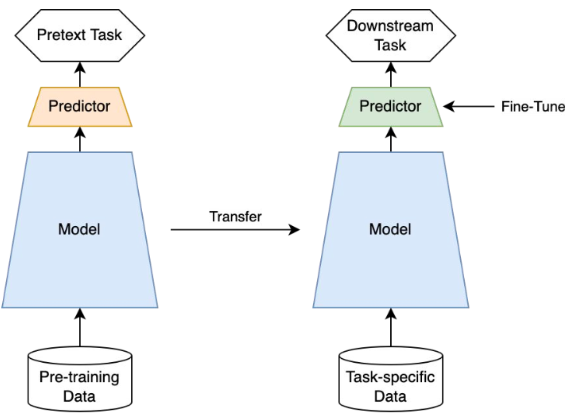
좌측이 pretext task이고, 오른쪽이 Downstream task 입니다.
해당 학습 방식을 간단하게 설명 하면 아래와 같습니다.
unlabeled dataset으로 Self-Supervised 학습을 진행하는 pretext task란 데이터 자체에 대해 이해를 하고,
특징을 잘 추출해내며, 모델의 representation 능력을 학습시키기 위한 임의의 학습 task를 의미하고,
이를 통해 pretext task의 모델(Encoder)이 먼저 학습됩니다.
그리고 성공적으로 학습된 pretext task모델의 weights 들을 우리가 실제로 적용하고자 하는 Downstream Task의 모델에 Transfer(전이) 한 후에 우리가 원하는 task의 방향성에 맞게 Fine-Tuning을 진행하는 것입니다.
=> 다시 말해, Pretext Task로 feature를 잘 표현하도록 Self-Supervised 학습을 시킨 뒤,
이를 target으로 삼는 Downstream Task에 전이하는 것입니다.
Self-Supervised 학습의 목적은 Downstream Task를 잘 수행하는 것이기 때문에
성능을 비교 할 때에 Downstream Task를 수행하는 모델에서의 성능을 비교하게 됩니다.
위와 같이 미리 학습 된 모델의 weights를 사용하는 전이 방식은 우리 모두가 많이 사용해 오고 있습니다.
대부분의 task에서 대규모 데이터셋(e.g ImageNet)을 통해 pre-trained된 모델을 전이해서 사용하는 것이 그 예입니다.
어떤 데이터셋(labeled vs unlabeled)을 가지고 어떤 학습(supervised vs self-supervised)을 진행했는지만 다를 뿐
미리 학습을 한 뒤 Downstream Task 로 전이하는 방식은 동일합니다.
Self-prediction & Contrastive Learning
그렇다면 Self-Supervised 학습 방식은 unlabeled dataset에서 좋은 representation을 잘 얻을 수 있는 방향으로 pretext task를 수행해야 하는데, 어떤 식으로 학습이 진행되는것일까?
사실 용어가 완벽하게 확립이 된 거 같지는 않은데,
크게 2가지로 분류하자면 Self-prediction과 Contrastive Learning 이 있다.
Self-Prediction
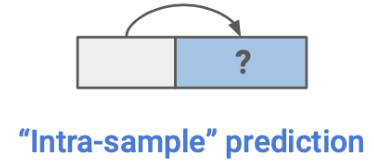
batch 단위로 data sample이 들어올 때,
해당 sample 내의 한 부분을 통해 다른 부분을 예측하는 task를 말한다.
해당 분야에 대해 서베이를 깊게 해 보지 않아서 어떠한 task들이 있는지 구체적으로 말씀은 드리지 못하지만,
최근 들어 이미지의 일부를 masking하고 나머지 부분을 복원(reconstruction) 하는 방식의 연구가 활발히 진행되고 있습니다. Masked Autoencoder(MAE) 라고 불리는 분야입니다.
당장 이번주 저희 연구실 X-Review 에서도 GT연구원과 JM연구원이 해당 분야에 대해 리뷰를 상세히 작성하였으니, 참고해서 읽어 보셔도 좋을 거 같습니다.
Contrastive Learning
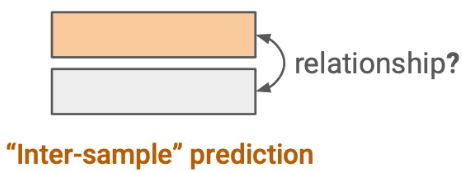
오늘 아래에서 리뷰 할 MoCo, 그리고 Self-Supervised 분야의 근본 2탄인 SimCLR 또한 Contrastive Learning 를 진행하는 논문입니다. SimCLR는 JY연구원이 작성한 리뷰에 자세히 설명되어 있으니 참고하시면 좋을 듯 합니다.
Contrastive Learning이란 Contrastive loss를 사용해 특정 embedding 공간에서
유사(similar)한 data 끼리의 거리는 가깝게 하고, 유사하지 않은 data 끼리의 거리는 멀게 하도록 하는 방식입니다.
각 batch마다 특정 data를 기준으로 positive와 negative를 정의한 뒤 Contrastive Learning를 진행할수록
유사하지 않은 data 끼리의 차이가 좀 더 명확해 지는 방향으로 학습이 진행되겠지요.
그러므로 해당 방식에서 중요하게 다뤄지는 문제는 positive와 negative를 정의하는 ‘유사(similar) 에 대한 정의’ 인데요,
이에 따라 많은 연구들이 진행된다고 보시면 될 거 같습니다.
Self-Supervised Learning이 아주 굵직하고 중요한 분야라 그런지
제가 짧은 기간 동안 공부한 내용들로 해당 분야를 모두 설명드리기에는 부족함이 많은 거 같습니다,,
아무튼 각설하고, MoCo에 대해 간단하게 소개 후 리뷰를 마치겠습니다.
MoCo

MoCo는 위에서 말씀드린 방식 중 Contrastive Learning 를 사용하는 Self-Supervised 학습 방식을 제안하였습니다.
Self-Supervised 에 대한 설명은 위에서 꽤나 자세히 설명드린 거 같으니 생략을 하겠습니다.
저자는 다른 Contrastive loss를 사용하는 방식과의 차이점을 비교하며 자신들 방식의 장점을 주장하였습니다.
본 논문을 포함하여 당시 Contrastive Learning을 수행하는 많은 방법론들은 모두 dictionary look-up 방식을 사용하였습니다. 해당 방식은 매우 많은 key로 구성된 dictionary 중에서 query와 positive 관계에 있는 key는 높은 유사도를, negative 관계에 있는 key는 낮은 유사도를 가지게 하는 방식입니다.
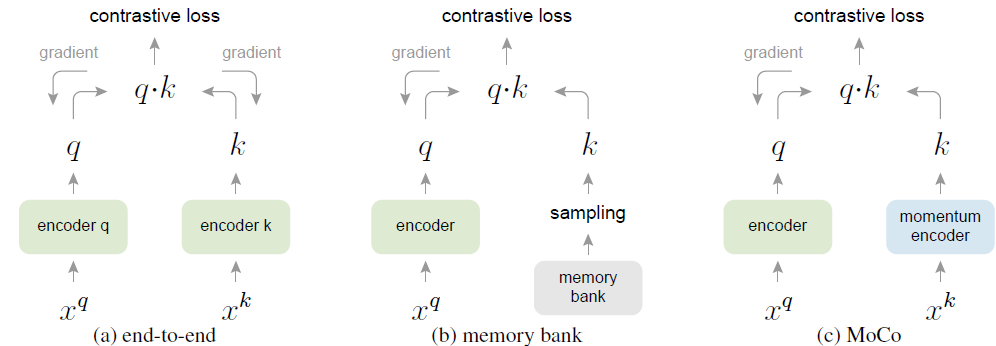
(a) : 많은 key로 구성 된 dictionary를 back-propagation을 통해 end-to-end 방식으로 학습시키는 방식입니다. 해당 방식에서는 dictionary를 따로 구성하는 것이 아니라, 현재 mini batch의 sample로 구성합니다. batch 크기 만큼 dictionary를 구성하는 것이죠.
해당 방식에서는 batch가 커질수록 성능이 좋아지는데, 이 때문에 GPU 메모리 문제가 생긴다는 문제가 존재합니다.
(b) : memory bank 방식은 데이터셋의 모든 sample representation으로 구성됩니다. 각각의 mini batch에 따른 dictionary는 back-propagation 없이 memory bank에서 무작위로 샘플링됩니다. 따라서 (a)에 비해서 큰 dictionary 크기를 가질 수 있겠지요.
However, the representation of a sample in the memory bank was updated when it was last seen, so the sampled keys are essentially about the encoders at multiple different steps all over the past epoch and thus are less consistent.
memory bank는 위와 같은 문제를 가진다고 하는데, 스스로 이해를 잘 하지 못한 부분이라 원문을 그대로 첨부 하였습니다..
(c) : 본 논문의 방식입니다.
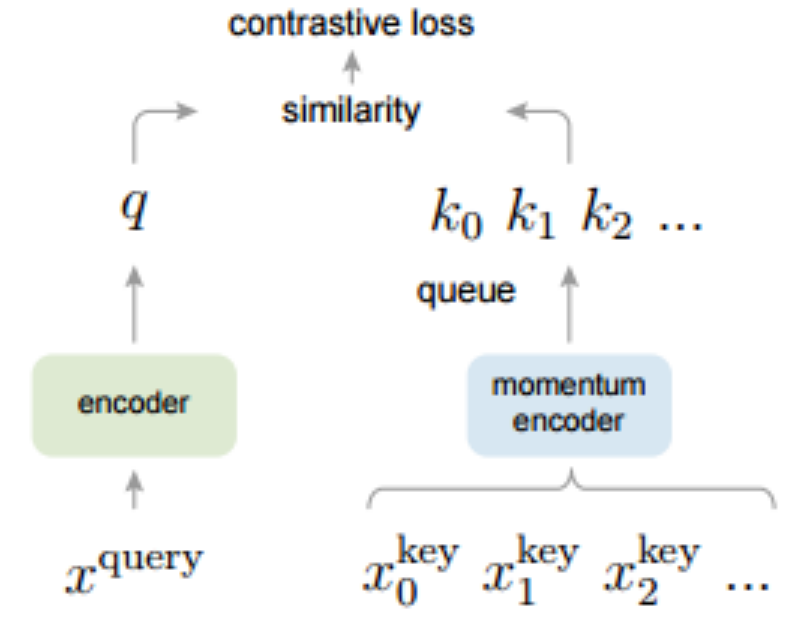
x^{query}가 encoder를 거친 후 생성된 representation vecotr q와
dictionary의 key가 momentum encoder를 거친 후 생성된 representation vector k_0, k_1, k_2 ...에 대해
query와 동일한 데이터로부터 생성된 positive key에 대해서는 유사도를 높이는 쪽으로,
반대로 query와 다른 데이터로부터 생성된 negative key에 대하여 유사도를 낮추는 쪽으로 학습을 진행합니다
그렇다면 MoCo에서는 dictionary를 어떻게 구성할까요?
본 논문의 핵심은 dictionary를 queue로 구성 한 것입니다. 이를 통해 바로 이전의 mini batch에서 encoding된 key를 재사용 할 수 있고, dictionary의 크기를 매우 키울 수 있다는 장점이 있겠네요.
위와 같은 장점이 존재하긴 하지만,
back-propagation을 통해 key-encoder를 update하기 어렵다는 단점이 존재합니다.
본 논문에서는 이를 해결하고자, back-propagation을 통해 query encoder만을 update 시키고 key endocer는 아래 식을 통해서 update를 수행하는 momentum update를 제안합니다.
query encoder의 parameter는 \theta_q, key encoder의 parameter는 \theta_k 입니다.
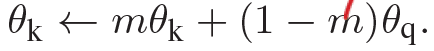
m의 default값은 0.999입니다.
이번 리뷰 작성을 통해 Self-Supervised Learning 분야에서의 큰 흐름에 대해 파악할 수 있었습니다.
그리고 무조건 Supervised로 pretrain 후 transfer learning하는것이 좋다고만 생각했던 제 고정관념(?)을 조금은 타파시켜 준 좋은 경험이였습니다.
다음에는 Masked Autoencoder(MAE) 관련 논문, 혹은 Multimodal 에서의 Self-Supervised Learning 논문에 대해 읽어보고 리뷰 할 예정입니다. 감사합니다.
?? 무언가 앞에 내용에 힘을 잔뜩 주신 탓인지 정작 MOCO 논문에 대한 설명은 빠진 부분이 좀 있어보이네요? MOCO를 사용하였을 때와 그 외에 end-to-end, memory bank 방법론들 간에 정량적 성능 비교 혹은 GPU 연산량 등 실험적인 결과도 추후에 보충해주면 좋을 것 같습니다.
작성하면서 저도 그걸 느낀지라,,
MoCo가 아닌, 앞쪽의 Self-Supervised 부분에 초점을 두고 봐 주시면 좋을 듯 합니다,,!
부족 내용은 추후에 보충 하도록 하겠습니다
SSL에 대한 전반적인 리뷰 잘 보았습니다.
허나 MoCo에 대한 좀 더 구체적인 설명이 필요해 보이네요.
query랑 key는 동일한 데이터 인가요? Contrastive Learning은 augmentation이 중요한 것으로 알고 있는데 MoCo에서는 어떻게 진행되는지 궁금합니다.
MoCo 에 대해 설명이 부실한 부분은 추후에 보충하거나, 기회가 된다면 따로 리뷰를 작성 하도록 하겠습니다.
기준이 되는 query가 있고, key의 경우는 positive와 negative로 나누어집니다. query에서 data augmentation을 적용해서 만든 key는 positive key이고, 나머지 dictionary 내의 key는 모두 negative key가 되어 아래 코드를 통해 유사도를 계산하게 됩니다.
———————————————
# positive logits: Nx1
l_pos = torch.einsum(‘nc,nc->n’, [q, k]).unsqueeze(-1)
# negative logits: NxK
l_neg = torch.einsum(‘nc,ck->nk’, [q, self.queue.clone().detach()])
———————————————
MoCo에서 수행하는 augmentation의 경우 resize, color jittering, horizontal flip, grayscale 등이 random으로 수행됩니다.
안녕하세요. 좋은 리뷰 감사합니다.
MoCo는 dictionary를 queue로 구성하여 바로 이전의 mini-batch에서 encoding된 key를 재사용할 수 있고, dictionary의 크기를 매우 키울 수 있다는 장점이 있다고 하셨는데, queue에서 뽑힌 데이터들은 이전 데이터여서 이전 데이터와 유사한 데이터에 대해서는 성능이 높아질 수 있지만 새로운 유형의 데이터에 대해서는 학습이 덜 될 수 있을 것 같은데 queue를 사용함으로써 생기는 단점은 없는지 궁금합니다.
감사합니다.
음.. 결국에는 queue도 enqueue, dequeue 과정을 거치면서 계속해서 새로운 batch가 들어오니까 계속해서 새로운 유형의 데이터를 보지 않을까요? 이러한 queue 내부의 data sample에 대해 positive, negative 관계를 통한 contrastive learning을 진행하는것이죠.
제가 Self-Supervised쪽 지식이 풍부하지 않아서 답변이 부족할 수도 있습니다. MoCo, Self-Supervised 그리고 contrastive learning에서 추가적으로 구글링해서 더 공부해보시면 좋을 거 같습니다. 앞선 연구원들이 작성한 훌륭한 리뷰들도 많으니 이를 참고하셔도 좋구요.