Patch-NetVALD는 local descriptor와 global descriptor의 장점을 모두 결합한 방법으로 기존 netVLAD에서 변형하여 patch level feature를 사용하였다. 또한 multi-scale fusion한 patch features를 사용하여 structure, illumination과 같은 condition과 translation과 rotation과 같은 변화에 모두 강인함을 보인다.

Visual Place Recogition(VPR)은 query image가 주어지고 database image중에 가장 비슷한 image를 찾는 image retrieval task에서 일반적으로 표현된다. query와 reference image의 유사성을 표현하는 방법이 크게 2가지로 global descriptor와 local descriptor를 사용한 방법이 있다. global descriptor를 사용하는 경우, query와 refence image사이의 유사도를 찾기위해 database에 있는 모든 local descriptor를 고려한다. 따라서 global한 정보를 포함하다보니 조도 변화나 작은 appearance 변화에 강인하다. local descriptor를 사용하는 경우, image에 있는 지역적인 특징을 고려하다보니 global descriptor보다 detail한 부분까지 고려할 수 있어 더 정확하게 6-DoF pose estimation을 할 수 있다고 한다. Patch-NetVLAD는 이러한 local, global descriptor를 사용할 때 강점들을 합쳐 SOTA를 달성할 수 있었다.
본 논문에서는 3가지 contribution을 제시한다.
1. locally-global descriptors를 통해 matching된 image pair에서 비슷한 score를 얻도록 새로운 place recognition system을 도입
2. multi-scale에서 locally-global descriptors를 얻어 fusion
3. performance와 computational간의 balance. 빠른 속도.
Related Work
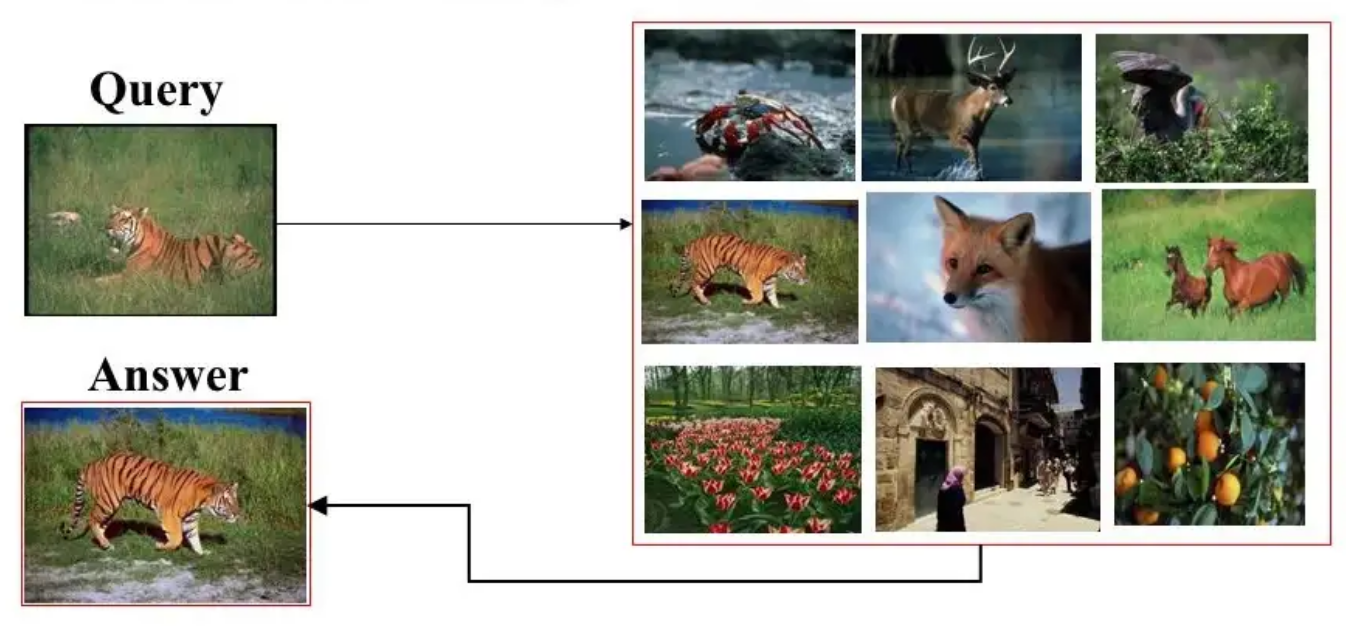
우선 image retrieval의 전체적인 단계를 살펴보면 Query 이미지(q)가 주어졌을 때 데이터베이스에 있는 이미 알고 있는 images집합(D)에서 q와 가장 비슷한 image(Answer)를 찾는 것이다. 각각 이미지(q, D)를 같은 크기의 vector로 바꾸고 둘 사이의 거리를 이용해 비슷한 정도를 판단하여 거리가 짧으면 두 이미지는 비슷하고, 거리가 멀면 두 이미지는 비슷하지 않은 것으로 판단할 수 있다.
Patch-NetVLAD를 이해하기 위해 NetVLAD에 대해 먼저 알아보고자 한다.
NetVLAD는 image retrieval을 이용한 place recognition CNN방법 중 하나로 VLAD에서 발전되어 미분이 가능하도록 추가 값을 구성하여 backpropagation이 가능한 형태이다.
VLAD(Vector of Locally Aggregated Descriptors)는 간단하게 표현하면 영상을 표현하는 local descriptors(SIFT)들을 모아 vector의 형태로 표현하여 image의 visual words와 cluster centers와의 차이를 계산하여 이미지를 표현하는 방법이라고 할 수 있다.
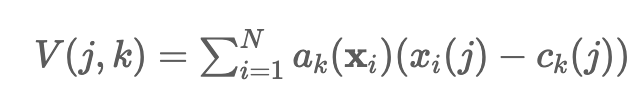
위의 수식은 VLAD representation 수식으로 xi는 영상에서 i번째 patch에서의 local descriptor이며 N은 HxWxD에서 HxW가 된다. ck(j)는 k번째 cluster center의 j번째 element를 의미하며 x와 마찬가지로 D개의 요소를 가진다. ak(xi)는 논문에서 정의하기로, local descriptor xi가 ck와 가장 가까울 때 1, 아니면 0을 가지는 membership이라고 표현한다(membership이라는 표현이 와닿지 않는다…). 다른 말로 xi와 ck가 같은 cluster에 속하면 1, 아니면 0을 가진다는 의미이다. 즉, 위의 수식 V는 local descriptors인 xi 중 k번째 cluster에 해당하는 xi와 cluster center와의 차이를 모두 합한 것을 나타낸다.
아래 수식인 NetVLAD는 VLAD방식(SIFT로 추출한 local descriptor 추출)으로 가장 가까운 cluster center를 찾는 것과 다르게, cnn을 적용하여 database에 있는 모든 이미지 vector들과 cluster centers의 거리를 비교한 후 soft assignment로 가중치를 부여한 결과를 query 이미지와 비교하고 그 차이를 다 합하여 single vector로 표현한 영상 전체에 대한 global descriptor를 얻는 방식이다.
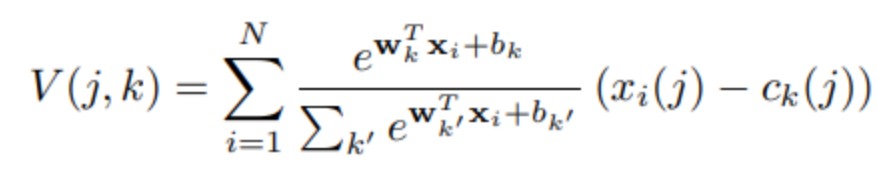
VLAD에서 ak(xi)가 membership이라는 표현으로 local descriptor와 cluster center가 가장 가까우면 1, 아니면 0의 값을 가지는 hard assignment로 사용되었다. 이로 인한 불연속성때문에 backpropagation에 문제가 되었고, 해당 부분을 가장 가까운 cluster center에 높은 가중치가 할당되는 softmax형태의 soft assignment로 바꾸면서 거리에 비례하여 같은 cluster뿐만 아니라 다른 여러 cluster와의 거리도 비교할 수 있도록 적용 가능한 형태가 되었다.
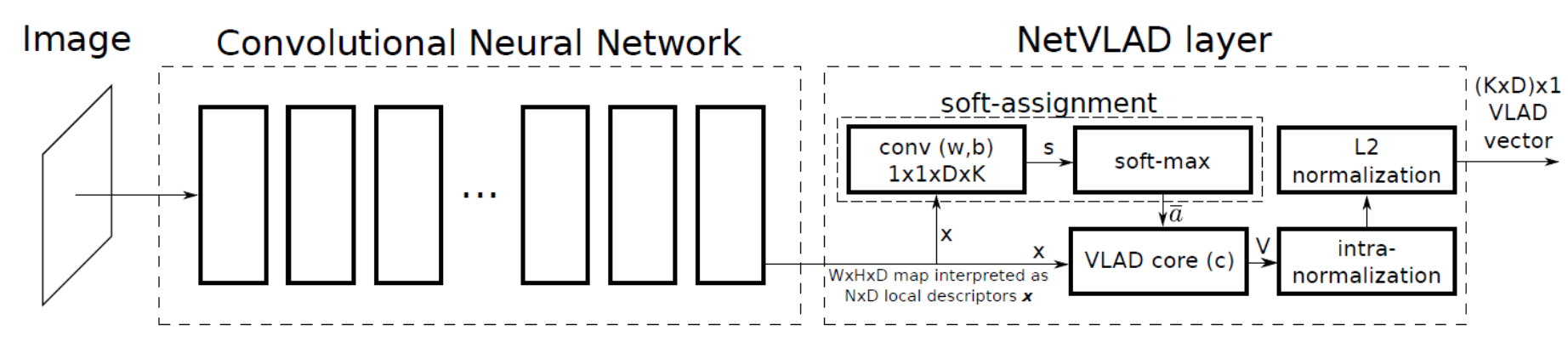
convolutional neural network를 통해 얻은 local descriptor를 convolution parameter형태의 출력으로 weight, bias를 구하여 softmax를 통과시킨다. 이후 VLAD core에서 descriptor와 cluster center의 차이에 가중치 형태로 곱하고 normalization을 거쳐 출력값을 얻는다.
Methodology
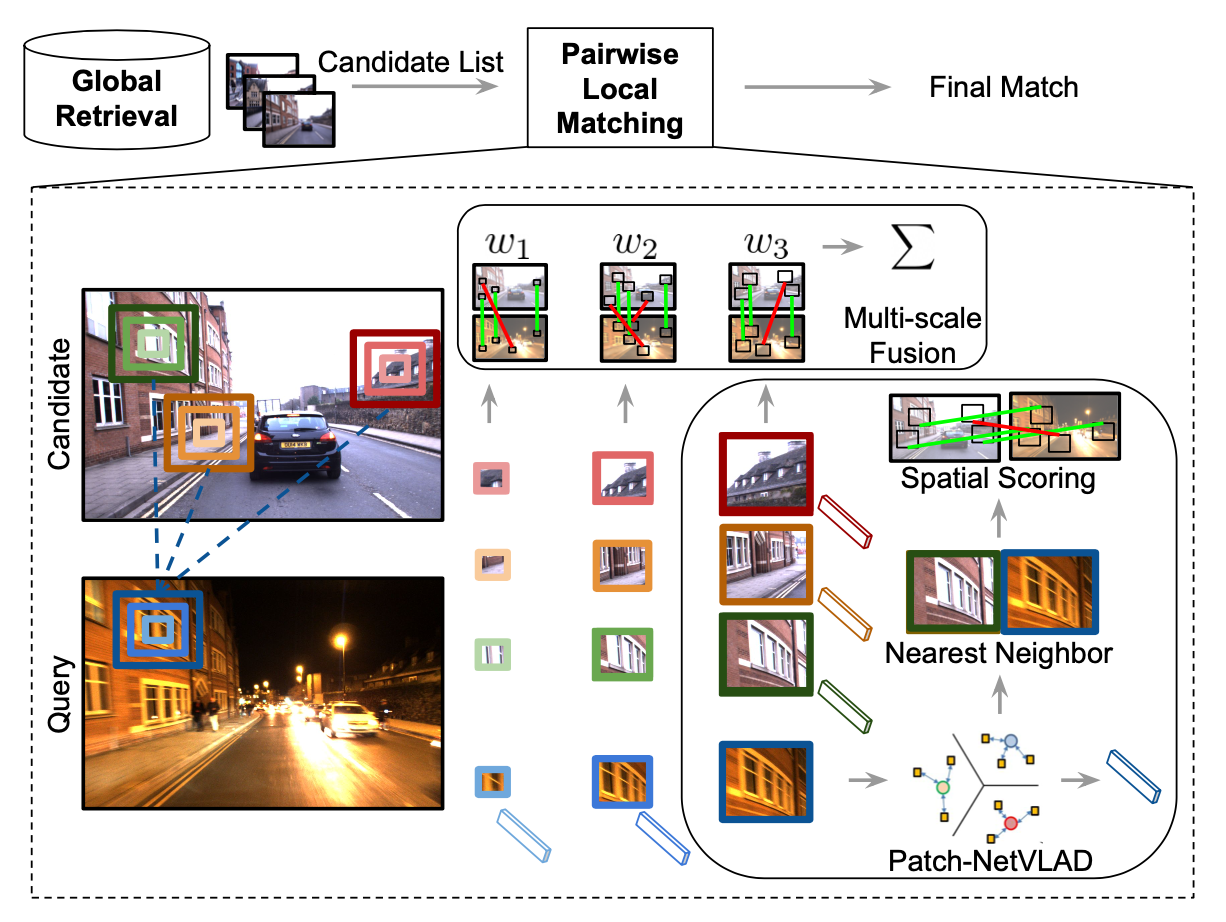
위의 그림은 Patch-NetVLAD가 어떻게 동작하는지 전체적인 흐름을 보여준다. 영상 전체에 대한 하나의 global descriptor를 추출하는 것이 아니라 영상을 patch단위로 나누어(5×5) 각 patch마다 NetVLAD를 사용하여 local descriptor를 추출한다. Database images에서 유사하다고 판단되는 top 100개의 Candidate List를 뽑고, 본 논문에서 제안하는 Patch-NetVLAD를 이용하여 pair끼리 matching하고 reranking을 통해 가장 유사한 이미지를 찾게된다. pairwise local matching하는 방법이 확대되어 있는데, 우선 각각의 local patch에 대해 NetVLAD방법으로 local descriptor를 뽑는다.
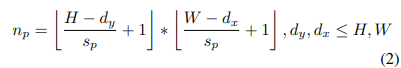
영상에 대해 patch 갯수(np)를 위의 식의 결과만큼으로 뽑는다. 논문에서 patch를 square patch로 하는 것이 가장 좋은 성능을 보인다고 했고 추후 다른 상황에서는 다른 형태의 patch를 사용할 수도 있을 것이라 했다. dx, dy는 차원 당 patch의 크기이고 sp는 stride이다.

그리고 모든 patch 각각(fi)마다 NetVLAD의 결과를 추출한다. 실험적으로 patch feature에 PCA를 적용한 것이 computation time과 image retrieval performance 모두에서 좋은 성능을 보였다고 한다.
그리고 이 NetVLAD를 이용한 local patch들을 multi-scale로 뽑아 local descriptor를 matching하는 것을 각 scale마다 반복한 후 weights 정보를 fusion하여 최종 multi-scale feature image retrieval score를 생성한다. multi-scale patch를 사용하기 때문에 영상의 작은 detail한 정보뿐만 아니라 semantic한 정보도 포함할 수 있다.
각 patch마다 local descriptor와 database의 이미지를 matching할 때 mutual nearest neighbor방식을 사용한다. 이때 모든 patch마다 거리를 계산하여 mutual nearest neighbor를 이용해 가장 가까운 patch와 matching한다.
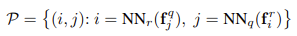
위의 수식은 patch마다 database의 이미지와 match된 set을 의미하여 fjq, fir은 각각 query feature와 reference feature이다. 이때 Nearest Neighbor(NN)은 Euclidean distance를 사용하여 두 patch 사이 거리를 구하고 matching score로 사용한다.
reranking을 하기 위한 matching된 두 이미지의 similarity score를 알기 위해 spatial scoring method를 제시했다. 하나는 RANSAC-based scoring method이고, 다른 하나는 spatial scoring method이다.
먼저, RANSAC-based 방법은 matching된 patch image들의 homograpy를 맞출 때 RANSAC을 통한 inlier만 살리고 inlier 갯수를 patch의 갯수로 평균을 내어(normalize) 사용한다. 속도는 느리지만 성능 향상의 효과가 있다.
그리고 RANSAC의 대안으로 제시한 rapid spatial scoring로 불리는 방법은 patch들을 horizontal direction, vertical direction에 대해 각각 차이를 비교하여 score를 계산하는 것이다. RANSAC에 비해 약간의 성능 손실은 있지만 속도는 빠르다. 아래 수식은 x(horizontal direction)에 대한 patch에서 direction 차이와 그 평균을 나타내었고 y에 대해서도 마찬가지로 적용된다. 즉 patch에서 모든 방향에 대하여 score를 계산한다.

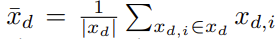
그리고 아래와 같이 각 patch에서 direction별로 각 direction마다 NN(Nearest Neighbor)로 matching된 것들 중 최대로 가능한 spatial offset에 대해 차이들을 평균한 값으로 spatial score가 계산되며, 가장 큰 값과 평균에 비해 얼마나 떨어져있는지의 차이를 평균내어 사용하므로 높은 score일 수록 좋다. 차이가 크게 되면 score값이 작으므로 outlier처럼 처리되는 효과가 있다.
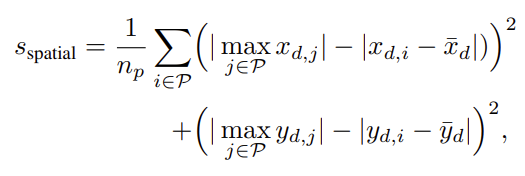
그리고 아래와 같이 각기 다른 patch size(ns)에 대해 가중치를 부여하여 각 patch마다 spatial score를 더한 것이 최종 score로 사용된다. 이때 가중치는 0보다 크고 합이 1이다.

multi-scale의 patch descriptor를 계산하기 위하여 새로운 IntegralVLAD를 제안하였는데 patch마다 나타내는 descriptor가 각 patch내에 1×1 patch descriptor의 합으로 표현될 수 있다는 것이다.
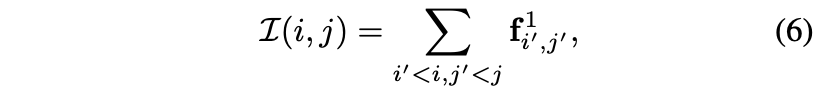
이때 달라진 크기의 patch는 아래 kernel K로 2D depth-wise dilated convolutions를 이용해 복구할 수 있다고 한다. 이 kernel 부분은 사실 잘 이해가 되지 않는다… 왜 저런 형태로 생겼는지

Experimental Results
Patch-NetVLAD를 적용하기 전 모든 이미지는 640×480으로 하여 patch feature를 추출하였다. NetVLAD feature를 추출하기 위해 학습할 때 Pittsburgh 30k와 Mapillary Street Level Sequences 데이터셋을 사용했다. patch size는 228×228 image일 때 5×5로 하고 patch가 이동하는 stride는 1이다. 사용된 multi scale patch size는 2, 5, 8이고 각각 0.45, 0.15, 0.4의 weights를 적용하였다.
Patch-NetVLAD를 평가하기 위한 데이터셋으로는 Nordland, Pittsburgh, Tokyjo24/7, Mapillary Streets, RobotCar Seasons v2, Extended CMU Seasons 총 6개를 사용하였다.
평가지표로는 ranking system에서 좋은 recommandation을 했는지 평가하는 방법으로 recall@N을 사용하였다. recall@N에서 N은 추천된 item의 수를 의미하며, top N개를 뽑았을 때 그 중에 실제 top N의 뽑혀야 할 것들 중 포함되어야 한다고 예측한 것이 몇 개가 포함되어 있는지를 나타내는 metric이다. 추가적으로 precision@N은 top N중에서 예측된 것들 중 실제 포함되야할 것들의 비율이다. RobotCar Seasons v2, Extended CMU Seasons에서는 translational(.25 .5, 5.0)과 rotational(2, 5, 10) error를 사용하였다.

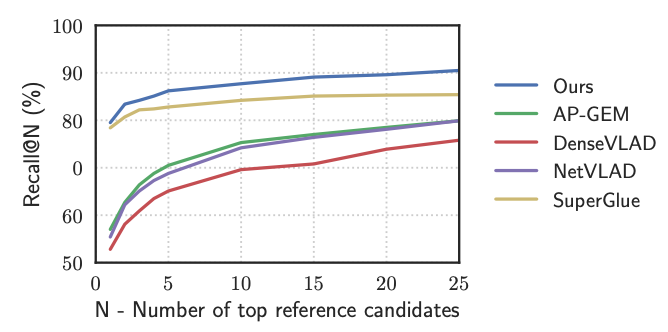
평가는 Nordland, Pittsburgh, Tokyo24/7, Mapillary Streets, RobotCar Seasons v2, Extended CMU Seasons의 총 6개 dataset을 사용하였다. table1에서 비교한 AP-GEM, DenseVLAD, NetVLAD는 global descriptor만을 사용하여 retrieval하는 방법론이고, SuperGlue는 이미지 속 keypoint의 위치와 local feature 정보를 추출하는 SuperPoint를 적용한 방법론이다. 본 논문에서 제안한 Patch-NetVLAD가 다른 global descriptor만을 사용한 방법들 보다 좋은 성능을 보인다. Pittsburgh 30k, Tokyo 24/7, Extended CMU Seasons 데이터셋에서 SuperGlue방식이 동일하거나 더 좋은 recall성능을 보이기도 한다. Patch-NetVLAD는 특히 보이지 않는 환경에서 큰 variations가 나타났을 때(낮과 밤 차이, 날씨 혹은 계절의 차이 등) 성능에 영향을 미치는데 SuperGlue보다 낮은 성능을 보인 데이터셋에 해당 variations가 포함되어있다.

ablation study에서 single-spatial-patch와 multi-spatial-patch, single-RANSAC-patch와 multi-RANSAC-patch를 적용한 것을 비교하였다. single-spatial-patch에서 patch size는 5로 하였고 multi-spatial-patch방식에서는 rapid spatial과 동일하지만 patch size만 3가지를 사용한 부분이 차이점이다. spatial과 RANSAC은 위에 Methodology에서 설명한 것 처럼 matching할 때 방식이다. 결과적으로 multi-fusion방법인 multi-RANSAC-patch 방식이 가장 좋은 성능을 보였다.
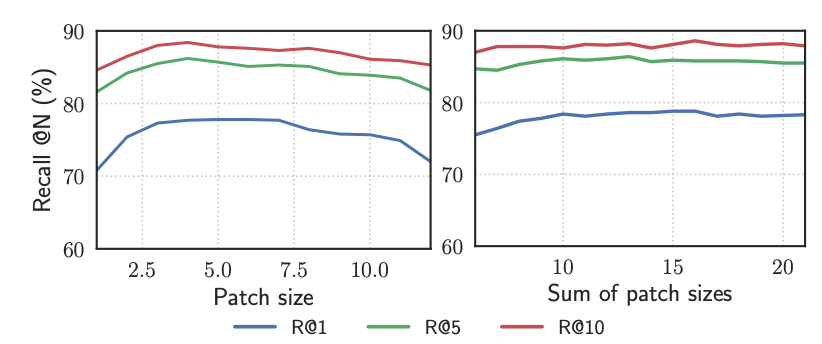
위의 결과는 patch를 single patch를 사용하느냐(left) multi patch를 사용하느냐(right)에 따른 차이이다. multi patch를 사용했을 때 더 좋은 recall을 보였고, patch size가 작거나 큰 경우 성능이 낮은 경향을 보인다. 본 논문에서는 patch size를 2, 5, 8 size로 하여 muti patch를 적용하였다.
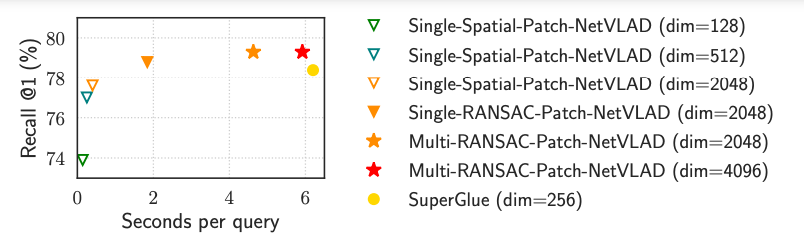
위의 결과는 Mapillary dataset에서 하나의 query 이미지의 processing time과 recall at 1의 결과이다. PCA로 dimension 축소를 위해 {128, 512, 2048, 4096}의 차원 수로 실험한 결과이다. multi-RANSAC-patch 방식의 4096 dimension일 때 가장 좋은 성능을 보이며 SuperGlue와 비교했을 때 3%가 빠르고 1.1%의 recall at 1 성능 향상이 있다고 한다. 노란색 동그라미 점인 SuperGlue의 차원 수(256)와 가장 성능이 좋은 빨간색 별 의 차원수(4096)와 비교했을 때 많은 차이에도 불구하고 Multi-RANSAC-Patch-NetVLAD방식이 오히려 precessing time이 더 적게 걸린다는 점이 신기하다.
아래 그림은 정성적 평가한 결과이다.

마지막으로 스스로 정리를 해보자면 netvlad 방법에서 patch단위의 local descriptors를 netVLAD방식으로 추출하여 patch-NetVLAD descriptors를 얻는다. 그리고 scoring방식으로 matching을 진행한 후 multi scale patch 각각에 weight를 fusion하고 최종 multi scale fusion image retrieval score를 생성하여 reranking을 한다. image retrieval을 처음 접하게되며 읽어본 논문인데 전체적으로 vlad -> netvlad -> patch-netvlad로 이어지는 흐름과 각각의 내용이 조금 어렵게 느껴졌고 SuperGlue와 실험 데이터셋에 대한 이해가 더 필요하다고 생각되었다.
안녕하세요. 좋은 리뷰 감사합니다.
논문에서 patch를 square patch로 하는 것이 가장 좋은 성능을 보이며, 추후 다른 상황에서는 다른 형태의 patch를 사용할 수도 있을 것이라고 했는데, 다른 상황이라함은 구체적으로 어떤 상황인지 언급이 되어있었는지 궁금합니다.
또, R@1은 1장의 이미지를 추출했을 때 해당 이미지가 허용오차 범위에 있는 것을 백분율로 나타낸 것이고, R@10은 10장을 추출했을 때 1장이라도 허용오차 범위내에 있는 백분율을 나타내는 것으로 이해해도 괜찮을까요 ?
마지막으로 4096차원인 Multi-RANSAC-Patch-NetVLAD가 256차원인 SuperGlue보다 좀 더 빠르고 정확하게 동작하는 이유가 궁금합니다.
댓글 감사합니다.
특정 상황에서 수직과 수평방향으로 서로 다른 texture가 반복되는 경우, square가 아니라 직사각형모양의 patch가 더 좋은 성능을 발휘할 수도 있겠다는 생각이 드네요.
R@10을 10개 추천 결과에 대한 recall을 의미하며, 관심이 있는 모든 아이템 중 모델이 추천한 10개가 얼마나 포함되었는지를 의미합니다.
Multi-RANSAC-Patch-NetVLAD는 병렬 process로 batch단위로 연산이 가능하기 때문에 image를 encoding하는데 더 효율적으로 빠르게 할 수 있어 retrieval시 시간을 줄일 수 있습니다. 하지만 superglue는 더 복잡한 matching과정을 거치기 때문에 오래걸리게 됩니다.