제가 이번에 리뷰할 논문은 cross-modality간의 Re-ID를 수행하는 논문입니다. 해당 논문에서 localization 태스크에 가져올 수 있는 것을 고민하고 있으며, 실험을 하고있는 논문입니다.
VI-reID(V:visible, I: Infrared)에서의 문제점은 inter-calss variation과 cross-modal간의 불일치라 합니다. 해당 논문은 feature learning 방식을 제안하여 이러한 문제들을 해결하고자 한 논문으로, 이를 통해 모달리티간의 불일치를 해결하여 인물의 표현에서 모달리티와 연관된 feature를 억제할 수 있으며(모달리티별로 드러나는 특징을 억제하여 모달리티와 관련이 없는 특징에 집중하도록 하는 것이라 이해하시면 됩니다.), 픽셀별 관계를 높여 discriminative한 feature를 학습하도록 하였다고 합니다.
논문의 contribution을 정리하면 다음과 같습니다.
- dense cross-modal correnspondences를 이용한 새로운 feature learning framework를 제안하여 모달리티간의 불일치는 완화화고, discriminative한 특징은 강화하였다.
- ID consistency와 dense triple loss를 제안하여 end-to-end로 학습할 수 있도록 하였다.
- VI-reID 밴치마크에서 SOTA를 달성하였고, 효율성과 확장성을 실험으로 보였다.
Method
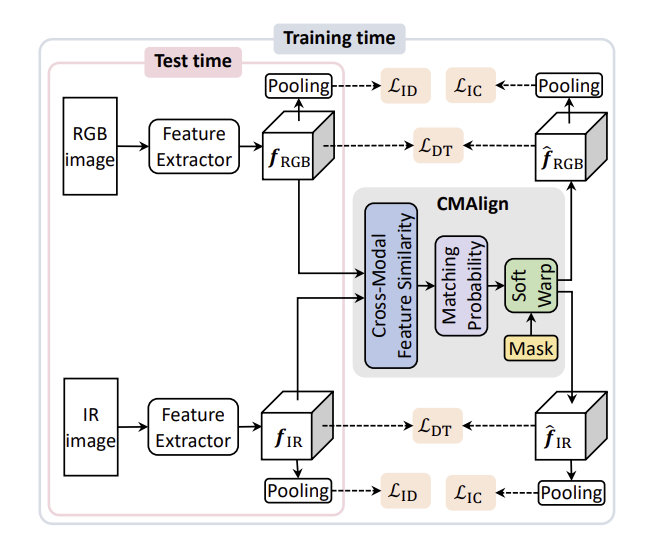
해당 논문의 VI-reID 프레임워크는 위의 그림1과 같다. RGB와 IR 이미지로부터 각각 feature를 추출하고, 두 feature와, 두 feature의 align을 맞춰주는 CMAlign 모듈을 통과하여 얻은 aligned feature들을 이용하여 모델을 학습한다. 학습을 위해 ID loss와 ID consistency loss(이하 IC), dense triplet loss(이하 DT)를 이용하며, 이때 IC와 DT loss는 본 논문에서 제안한 함수입니다. (뒤에서 loss에 대해 더 설명하도록 하겠습니다.) IC와 DT loss는 동일한 사람에 대해 RGB와 IR feature를 이용하는 목적함수로, 이를 통해 cross-modal에서도 feature를 추출할 수 있다고 합니다. 그리고 이 논문은 사람의 몸, landmark와 같은 정보를 이용하지 않고, 사람 label만을 학습에 사용하였다고 합니다.
1. Network 구조
- Feature Extractor
두 CNN을 이용하여 각각 RGB와 IR feature를 추출합니다. 기존의 연구**를 근거로 저자들은 cross-modality로 인한 불일치는 low-level feature 에 있다 보아 앞부분은 RGB와 IR이 분리되어있고, 뒷부분은 파라미터를 공유하도록 하였다고 합니다.
** Ancong Wu, Wei-Shi Zheng, Hong-Xing Yu, Shaogang Gong, and Jianhuang Lai. <RGB-infrared cross-modality person re-identification> In ICCV, 2017
**Mang Ye, Jianbing Shen, Gaojie Lin, Tao Xiang, Ling Shao, and Steven CH Hoi. <Deep learning for person reidentification: A survey and outlook> IEEE TPAMI, 2021
- CMAlign
CMAlgin 모듈은 RGB와 IR feature의 align을 맞추기 위한 모듈로, RGB에서 IR과 IR에서 RGB로를 모두 고려하여 dense cross-modal correspondence를 이용합니다. 먼저 IR-to-RGB는 두 쌍간의 local 유사도를 이용하여 계산합니다.
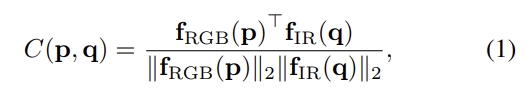
위의 식1을 통해 구한 유사도를 기반으로 soft max함수를 이용하여 RGB-to-IR의 매칭 확률을 구합니다.
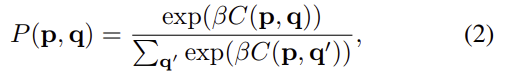
각 RGB feature에 대한 matching 확률은 argmax_{p}P(\mathbf{p,q})로 구할 수 있습니다. 이는 유사한 영역에 대해 신뢰할 수 있는 cross-modal간의 매칭을 제공하기는 하지만, 이는 배경이 복잡하거나 이미지별 detail(texture나 occlusion)에 의해 크게 영향을 받고, RGB와 IR사이의 변화는 더 큰 영향을 준다는 문제가 있습니다. 게다가 다른 배경에서 촬영되는 사람에 경우 배경을 매칭할 수 없다는 문제가 있습니다. 이를 해결하기 위해 매칭 확률을 이용하여 IR과 RGB의 전경만을 고려하는 align IR,RGB feature를 이용하였다고 합니다.
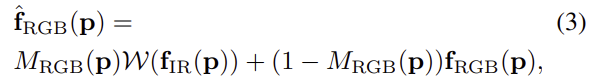
여기서 \mathcal{W}는 soft warping operator로 매칭 확률을 이용하여 feature를 모아주는 역할을 하며 아래의 식4로 정의가 됩니다.
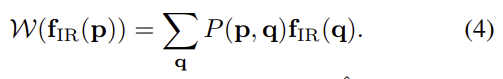
사람 마스크는 사람에 대한 feature \hat{\mathbf{f}}_{RGB}에서 확률적으로 IR feature를 모아 재구성되고, 나머지는 원래의 RGB feature \mathbf{f}_{RGB}에서 나온다. align feature는 IC와 DT loss로 학습이 되며, 이를 통해 모달리티에 상관 없는 feature를 추출할 수 있도록 모델이 학습됩니다.
사람에 대한 마스크는 아래의 식 6으로 정의가 되며, 식 6에서의 f는 min-max normalization을 의미합니다.
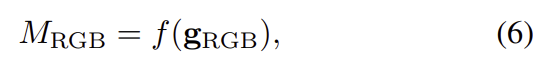
여기서 \mathbf{g}_{RGB}는 activation map을 의미하며 아래의 식으로 구할 수 있습니다.

이렇듯 CMAlign 모듈은 cross-modal의 픽셀 수준에서 두 모달리티간의 불일치를 완화하는 데 도움이 된다고 합니다.
2. Loss
해당 논문은 학습을 위해 세가지 loss를 결합하여 학습을 진행합니다.
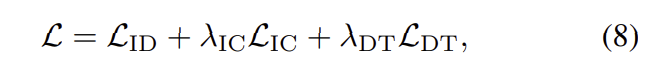
각각 ID, ID consistency loss(IC), dense triplet loss(DT)로, 가중합으로 결합이 되며, 각각에 대해서 자세히 알아보도록 하겠습니다.
- ID loss
우선 ID loss는 re-ID에서 대부분 사용하는 loss 입니다. RGB 와 IR 이미지로부터 각각 추출한 image-level의 representation을 classifier(BNlayer와 softmax, FClayer로 구성됨)에 입력으로 넣어 cross-entropy를 계산합니다. 이후 hard triplet term을 이용하여 image-level의 표현을 학습합니다.
- ID Consistency loss(\mathcal{L}_{IC})
cross-modal의 차이를 고려하여 설계한 loss term이라 합니다. 간단하게 설명하면, ID loss와 동일한 방식으로 loss를 계산하며, 이때 ID loss와의 차이는 재구성된 feature ϕ(\hat{\mathbf{f}}_{RGB}), ϕ(\hat{\mathbf{f}}_{IR})를 이용한다는 것입니다. 이 loss를 통해 동일한 id에 대해, 다른 modality에서 촬영된 영상을 일관되게 동일한 id로 예측할 수 있도록 하며, 학습에 추가적인 샘플을 제공하여 더욱 discriminative한 특징을 학습할 수 있도록 한다고 합니다.
- Dense Triplet loss(\mathcal{L}_{DT})
앞의 ID, IC loss는 이미지 레벨의 항으로, 이미지가 occlusion되어있거나 misaligned 되어있어도 이를 고려하지 않는다는 문제가 있다고 합니다. 이에, dense triple loss를 제안하여 이러한 문제를 해결하고자 하였습니다. 서로 다른 original feature와 reconstructed feature를 local하게 비교하여 이미지 레벨의 표현이 discriminative해지도록 하고, 동시에 픽셀 레벨의 cross-modal 불일치를 완화하도록 합니다.
간단한 방법은 local feature간의 L2 distance를 계산하는 방식이지만, 이는 occlueded 영역을 고려하지 못합니다. 이에 해당 논문에서는 RGB와 IR에서 모두 볼 수 있는 사람의 영역을 강조하도록 co-attention map을 이용하였습니다. 이는 RGB 영상에서는 A_{RGB}라 하며, 아래의 식과 같이 정의가 됩니다.
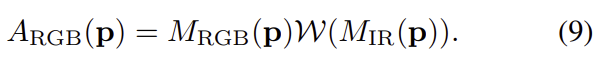
co-attention map A_{RGB}는 RGB 사람 mask M_{RGB}(\mathbf{p})와 와핑된 IR 이미지의 교차영역을 의미합니다. IR 에 대한 co-attention 영역도 유사하게 구하며 아래의 그림2이 co-attention map의 예시입니다.

학습을 위해, anchor와 다른 모달리티에서 촬영된 이미지들을 이용하며 DT loss는 아래의 식으로 정의가 됩니다.
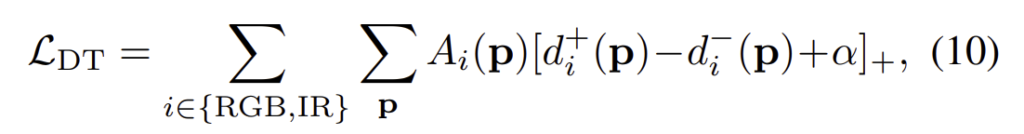
이때 \alpha는 사전에 정의된 margin이고, d_i( )는 local distance를 의미합니다.
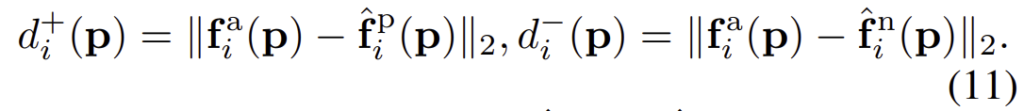
Experimental
Dataset
마찬가지로 cross-modal re-ID에서 많이 사용되는 두 데이터셋인 RegDB와 SYSU-MM01을 이용하였다고 합니다.
- RegDB
- 10개의 visible, 10개의 thermal 카메라로 촬영.
- 412 identity(사람) 포함.
- SYSU-MM01
- 4개의 visible 카메라와 2개의 thermal 카메라로 촬영.
- 일부 사람이 실내와 실외에서 모두 촬영되어 challenging함.
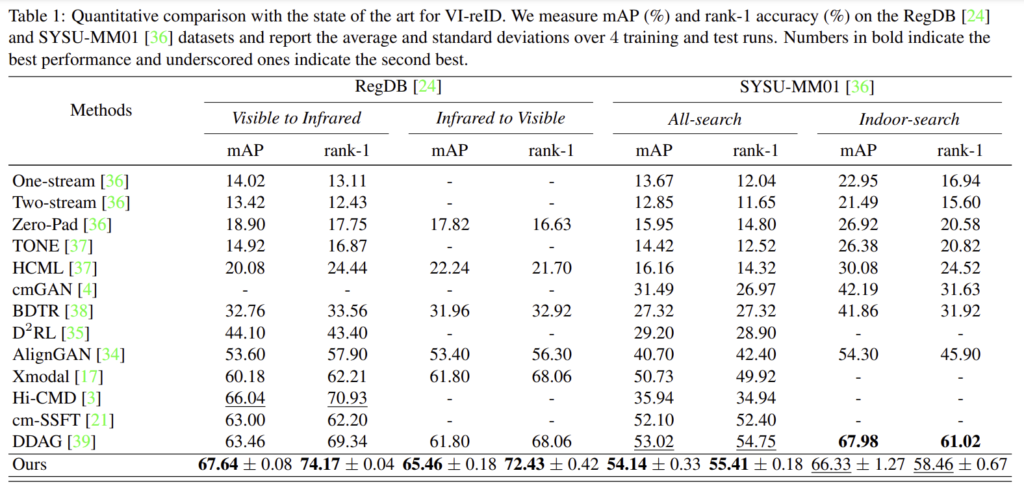
아래의 결과는 SOTA와의 비교 결과입니다.
이번에 리뷰한 논문의 DT loss와 관련된 설명 중 그림2를 보며, 학습을 할 때 동일한 위치에서 여러 시간에 촬영된 영상을 이용한다면, 이미지마다 다르게 나타나는 dynamic object에 대한 학습에 도움이 될 것이라는 생각이 들었습니다. 또한, 해당 논문은 전경을 이용하기 위해 뽑았다면, 위치인식에서는 전경을 제거하기 위해 이용해보면 효과가 있을 것이라 기대됩니다.
좋은 논문 리뷰 감사합니다.
해당 논문에서 제안한 CMAlign이 가장 흥미롭네요.
서로 다른 도메인에다가 다른 시점을 가졌기에 정렬 문제가 예민한 문제로 적용될거라고 생각합니다.
그렇기에 궁금한 점이 학습을 진행할 때는 유사한 시점을 가진 쌍을 이용할까요? 아니면 시점 상관없이 동일한 인물을 매칭하여 학습하나요?
그리고 p와 q에 대한 노테이션 정보가 있으면 좋겠습니다.
시점에 상관 없이 동일한 인물 쌍을 이용하여 학습을 진행합니다.
그림 2와 같이, 동일한 인물이 다른 상황, 다른 각도에서 촬영되었을 때 이를 고려하여 학습이 되도록 하겠다는 것이 attention의 목적입니다.
p와q에 대한 노테이션이 명시되어있지는 않지만 유추를 해보았을 때, feature extractor를 통해 추출된 각 feature를 의미하는 것으로 보입니다.
좋은 리뷰 감사합니다!
제가 잘 이해한 것인지는 모르겠는데 그림 2의 IR과 RGB 이미지에 대한 mask 시각화 결과를 보고 문득 생각이 들어 질문드립니다. 그림에서 IR과 RGB 이미지에 동시에 나타나는 이미지 영역을 강조한다고 하는데 만약 RGB에서 어두운 조도환경으로 인해 검출이 안된다던가 IR에서 낮에 높은 온도로 인해 주변 온도와 비슷한 상황에서 사람을 잘 검출하지 못하였을 경우에는 동시에 나타나는 부분이 없어 해당 영역이 강조되지 못하는데 이런 경우 해결책이 제시되어 있나요?
그러한 상황에 대한 분석 내용은 보지 못하였지만, 만일 배경과 사람 전경 부분을 구분하지 못한 경우는 그림2와 마찬가지로 가려진 영역으로 판단하지 않을까 하는 생각이 듭니다. 왜냐하면 그림2의 마스크와 attention 결과 역시 어떤 영역이 가려졌다는 지시를 주지 않았고, 저자들이 학습 과정에서 모델에게 준 정보는 id 정보와 이미지 정보뿐이라고 하였기 때문입니다. 질문하신 내용이 만일 전체적으로 RGB 와 Thermal에서 사람의 존재 자체를 구분하기 어려운 경우를 의미하시는 거라면 해당 태스크는 사람에 맞춰진 영역을 detection 된 결과를 기반으로 작동한다고 생각하면 해당 문제가 적용되지 않을 것이라 생각합니다.