
오늘은 저희가 작년 다크데이터 2차년도에서 수행한 연구 결과와 아주 비슷한 결의 논문을 리뷰하려고 합니다. 최근 제가 리뷰한 논문이 2021-2022년도인 것을 감안하면 이들과 비교했을 때, Semi-Learning 의 대표주자였던 MixMatch와 Active Learning을 단순히 결합하였다는 것 외에는 다소 Contribution이 약하지 않나 라는 생각은 들었습니다.
그럼에도 불구하고 해당 논문을 읽게된 이유는, 저자들은 어떤 성능을 냈고 어떤 문제점이 있었는지에 대한 분석이 궁금했고 그와 동시에 이 연구에 대해 어떻게 셀링을 하는지 라이팅 측면에서도 인사이트를 얻을 수 있지 않을까 였습니다.
Consistency-based Semi-supervised Active Learning: Towards Minimizing Labeling Cost

Background
제 리뷰를 관심있게 읽으시는 분들이라면 “너가 항상 리뷰하던 Self / Active 말고 갑자기 Semi?” 라고 생각이 드실 것 같습니다. 우선 Semi-supervised learning에 대한 것과 해당 논문에서 사용한 Semi-Supervised Learning의 대표적인 방법론인 MixMatch 을 아주 아주 가볍게 다뤄보겠습니다. (이에 대해 아시는 분들은 다음 파트로 넘어가시면 됩니다. )
#Semi-supervised Learning
Semi-supervised Learning을 직역하면 준지도학습입니다. 준? 뭔가 완전하지는 않은 Supervised Learning 이라는 어감이 드는데요. 그런 어감에 맞게 Semi- 는 labeled 와 unlabeled 데이터 둘 다 사용하는 학습법입니다. 이 때 labeled 데이터셋은 극 소량이죠.
active learning 과 초기 세팅과 비슷하다고 할 수 있습니다. 게다가 해당 연구의 등장 목적 역시 ‘데이터 라벨링 작업에 소요되는 비용을 어떻게 하면 줄일 수 있을까’ 에서 시작된 것 역시 동일합니다. 대신 준지도학습은 이렇게 적은 Labeled 데이터가 있을 때 어떻게 해야 효과적으로 Unlabeled 데이터를 사용해야 성능을 높일 수 있을까에 대한 연구라고 할 수 있습니다. 따라서 이런 준지도학습에서는 Unlabeled 또는 Labeled 중 하나의 정보를 사용하여 나머지 데이터셋에서의 성능을 높이는 것을 목표로 합니다.
직관적으로 생각해본다면, Unlabeled dataset을 사용하여 비지도학습을 진행하면서 소량의 Labeled로 결과를 보정하거나 Labeled 을 부여하는 식으로 학습이 진행될 것 같지 않나요? 그렇다고 할 수 있긴 하지만 이 분야의 연구도 워낙 많아서… 정확히 이런 방법이 있습니다! 라고 하나로 콕 집는 것은 어려울 것 같습니다.
그렇다면 저자가 사용한 대표적인 Semi-supervised Learning 방법론 중 하나인 Mix-Match란 무엇일까요?
#Mix-Match
- Paper: [NeurIPS 2019] Mixmatch: A holistic approach to semi-supervised learning
이 방법론에서 가장 중요한 개념은 Consistency 입니다. 일관성이라고 직역할 수 있는데요. Consistency 란 하나의 입력에 대해 서로 다른 augmentation을 적용한 것들에 대한 모델 예측값에 대한 일관성을 의미합니다.
우선 Labeled data에 대해 augmentation을 진행하여 더 많은 데이터를 만듭니다. 그 다음 Unlabeled data에 대해 augmentation을 k번 적용하여 k개의 데이터를 만듭니다.
이렇게 만들어진 k개의 unlabeled 데이터를 모델에 태워서 나온 예측값의 평균을 sharpening이라는 기법을 적용하는데요. sharpening은 하나의 클래스에 대한 확률값을 높이고 나머지 클래스에 대한 확률을 줄여서 Entropy를 줄이는 기법입니다. 이 과정을 통해 모델은 다양한 augmentation이 적용된 이미지들에 대해 일관성있는 pseudo-label 예측을 할 수 있도록 학습이 됩니다.
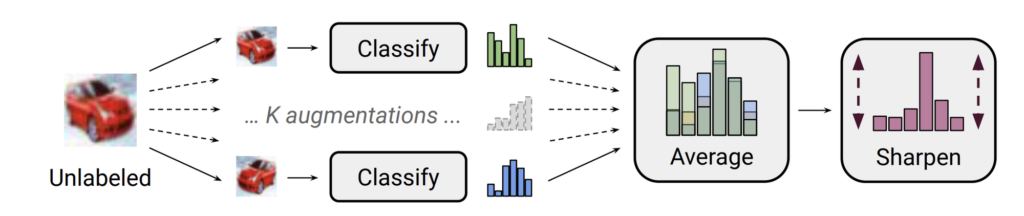
이제 labeled, unlabeled 로부터 augmentation된 데이터들을 모두 섞어서 labeled 끼리는 mixup을 수행합니다. mixup은 아래 이미지와 같다고 보면 됩니다. 고양이가 labeled, 강아지가 unlabeled 에 대해 앞서 모델로 만들어진 pseudo-label 이라고 했을 때 둘을 섞어 새로운 데이터를 생성함으로써 unseen data에 대해서도 모델이 잘 적응할 수 있도록 제안된 방법입니다. 이를 통해 소량의 데이터셋에 대한 overfitting 까지 예방할 수 있습니다.

이렇게 생성된 데이터를 이용하여 Supervised loss + Consistency loss를 계산하여 모델을 업데이트하는 방식이 Mixmatch 입니다. 이를 확장한 연구가 fixmatch 인데요, 이에 대한 자세한 리뷰는 조원 연구원의 리뷰를 참고해주시기 바랍니다.
mixmatch 알고리즘을 아래와 같이 정리하여 나타낼 수 있으며, 이를 끝으로 아주아주 간단하게 알아본 mixmatch 설명이었습니다.

Introduction
기존의 연구들은 Labeled data만 사용하고, Unlabeled dataset을 고려하지 않습니다. 보통 Labeled 데이터셋은 극 소량이기 때문에, 적은 양의 labeled 만을 사용하면 보통의 모델은 실제 boundary에 근접하기는 커녕 전혀 다른 경향의 boundary를 찾거나 소량의 데이터셋에 편향되기 마련입니다. 이를 Active Learning에서는 Cold-start 문제라고 부릅니다.
저자는 이 cold-start를 극복하거나 다루기 위해 그동안 사용해오지 않은 Unlabeled dataset을 사용하고자 하였습니다. 아마 그동안 다양한 Semi-SL 방법론들이 발전해왔기도 했고, Active Learning에서 labeled를 늘리는 것은 불가능한 문제이기 때문에 둘을 결합하는 방법을 생각해낸 게 아닌가 싶습니다. 따라서 저자는 Semi-SL방식으로 Unlabeled 데이터 만으로 구체화된 지식 위에 추가로 수집된 Labeled 데이터를 반영할 수 있는 “Semi-SL과 Active Learning 을 결합하는 새로운 Active Learning 방법론” 제안합니다.
Consistency-based Semi-supervised AL
그동안 Semi-SL과 AL을 결합하는 연구가 없던 것은 아니지만, 보통 Semi-SL 모델과 AL 모델을 분리하여 결합하는 방법론을 제시하곤 했습니다. 그러나 저자가 제안하는 Consistency-based Semi-Supervised AL에서는 하나의 모델 안에서 Semi-SL과 AL이 동시에 이뤄집니다.
보통 Active Learning 은 데이터를 선별하는 Selection model과 Target Task model로 구성되어 있습니다. Selection model은 말 그대로 가치있는 데이터 혹은 라벨링이 필요한 데이터를 선별하는 모델입니다. 그리고 Target-Task model은 그 다음 하위 태스크를 수행하는 모델이죠. 가령 Classification, Object detection, Segmentation etc. 가 있죠. 방법론에 따라 Selection model과 Target-task model이 하나로 통합되어 있는 경우도 있고 분리되어 있는 경우도 있죠.
여기서 저자가 Semi-SL과 AL을 동시에 수행했다는 얘기는 Selection model과 Target-Task model은 하나이며, 이 모델을 Semi-SL 방식과 Target-Task 학습 방식을 동시에 사용하여 학습시킨다는 말입니다. 다시 말해, 이 모델을 업데이트하는 objective를 Semi-supervised learning 에 대한 loss와 Active Learning Loss를 동시에 사용한다는 얘기죠. L_u는 Unlabeled data에 대한 Loss로 semi-supervised learning 에 대한 Loss 이고, L_l은 Target-Task model 여기서는 Classification이므로 Cross Entropy Loss가 됩니다. 그리고 최종 Objective는 L_u + L_l로 구성되어 이 Loss를 최소화하는 방향으로 모델을 학습하는 것이 바로 저자가 제안하는 방법론입니다.
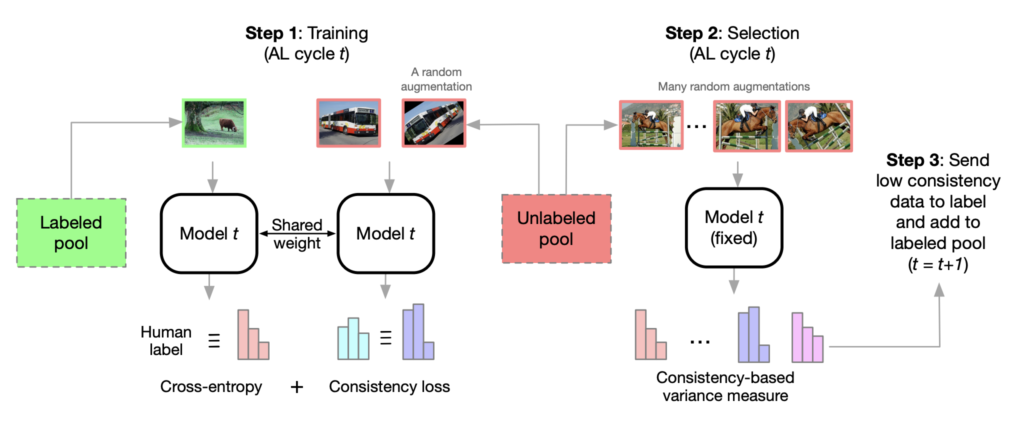
위에 그림이 바로 저자가 제안하는 Consistency-based Semi-supervised AL 의 프레임워크입니다. 저자는 Semi-supervised Learning 방법론으로는 Consistency-based Semi-supervised의 대표라고 불릴 수 있는 MixMatch를 사용하였습니다. MixMatch란 기존 Self-Learning에서의 Contrastive 기반의 연구와 비슷한 방식이라고 볼 수있는데요. 이 연구들은 “Consistency”에 집중합니다. 하나의 이미지에 대해 서로 다른 augmentation을 적용합니다. 하나는 weakly aug. 나머지 하나는 strong aug. 를 적용한 뒤 이 둘에 대해 모델이 일관된 예측을 발생할 수 있도록 모델이 학습됩니다.
두 개의 변형이 서로 비슷하다 일관된다 라는 예측을 할 수 있도록 Consistency loss를 사용하며 이 loss 수식은 다음과 같습니다.
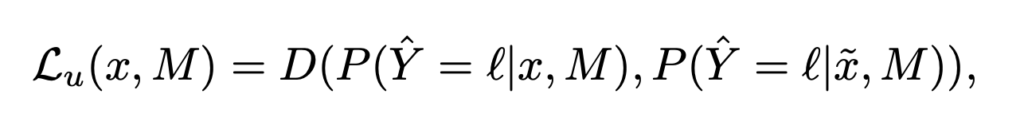
수식에 따라 x, \tilde{x} 가 각각 augmentation을 적용한 것이라고 했을 때 두 입력에 대한 모델의 출력 사이의 거리를 consistency loss라고 정의할 수 있습니다. 여기서 D는 KL divergence 또는 L2 norm을 사용하였습니다.
그리고 다음으로 중요한 것은 Selection Criteria 역시 이 Consistency loss를 기준으로 데이터를 선별하였습니다. 모델을 업데이트 학습 방법에만 Semi-Supervised Learning을 적용한 것이 아닌, 데이터의 가치를 판단하는 기준으로서도 이 Consistency를 사용하였다고 합니다.
보통 Uncertainty를 데이터 가치의 척도로 사용하곤 하는데요. 대표적으로 Entropy가 있습니다. 데이터의 엔트로피가 높다는 것은 모델로 하여금 이 데이터가 어떤 클래스에 속할 지 확신도가 낮다고 해석할 수 있습니다. 따라서 이런 불확실성이 높은 데이터를 선별해서 사람에게 라벨링 하도록 시키자는 것이 목적이라고 할 수 있습니다.
그러나 데이터의 분포를 벗어난 데이터 즉 OOD 샘플은 높은 불확실성을 가지곤 하는ㄷ테, 이런 데이터를 우선적으로 선별하여 모델을 학습할 경우 성능이 저하되곤 합니다. 뿐만 아니라 딥러닝 모델은 학습 데이터와 전혀 다른 데이터 분포를 가지는 샘플에 대해 예측을 잘 못하고 있음에도 불구하고 굉장히 높은 Confident를 가지는 경우가 있다고 연구가 발표되기도 하였습니다.
따라서 저자는 Consistency loss가 높은 데이터를 고 가치의 데이터로 선정하고자 하였습니다. 보통 이렇게 선별되는 데이터는 weakly, strong aug에 대해 일관되지 예측을 하는 경우가 되겠죠. 따라서 이를 고려한 inconsistency를 정량화한 수식은 다음과 같습니다.
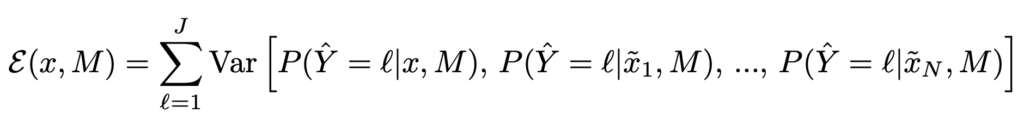
이제 이 모든 과정을 아래 알고리즘과 같이 정리하며 해당 프레임 워크에 대한 설명을 마치겠습니다.

Experiments
저자가 실험을 통해 보이고 싶은 결과는 다음 세 가지 입니다.
- Selection Metric으로서의 Consistency 의 성능 비교
- unlabeled dataset을 함께 사용했을 때의 성능 향상 결과
- 제안된 일관성 기반 연구의 몇 가지 중요한 특성에 대한 정성적 분석
[1] Comparison with selection baselines under SSL
우선 selection metric으로서의 consistency가 효과적인지를 알아봅시다.
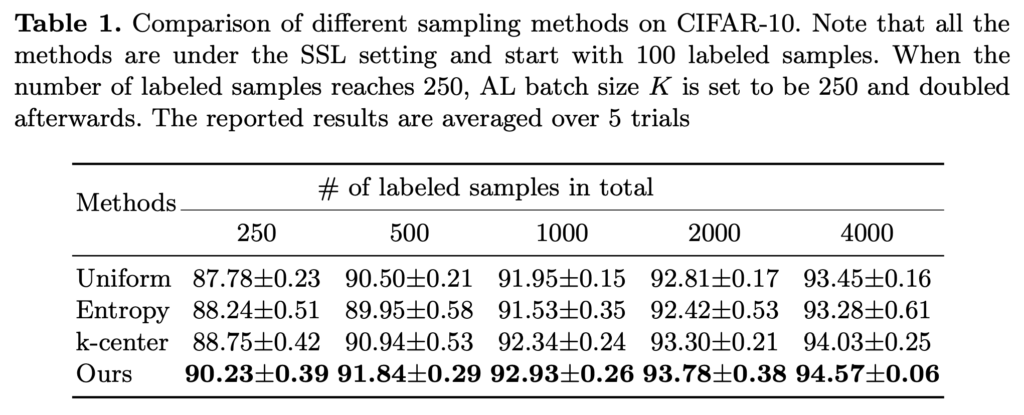
이를 비교하기 위해 저자는 가장 나이브한 Selection metric 3가지와 비교하였습니다. uniform은 쉽게 말해 랜덤 샘플링이라고 생각하시면 좋을 것 같습니다. entropy는 불확실성 척도의 대표적인 것으로 cross entopy 할 때 그 entropy 맞습니다. 그리고 데이터의 분포를 고려하여 데이터를 선별할 수 있는 k-center(선택된 샘플과 가장 가까운 labeled 샘플의 거리를 최대화하는 k개 선택) 까지 이 3가지를 함께 비교하였습니다.
아래 그림 1을 통해 해당 방법론이 다른 샘플링 방법에 비해 높은 격차로 성능이 우수한 것을 알 수 있엇습니다.
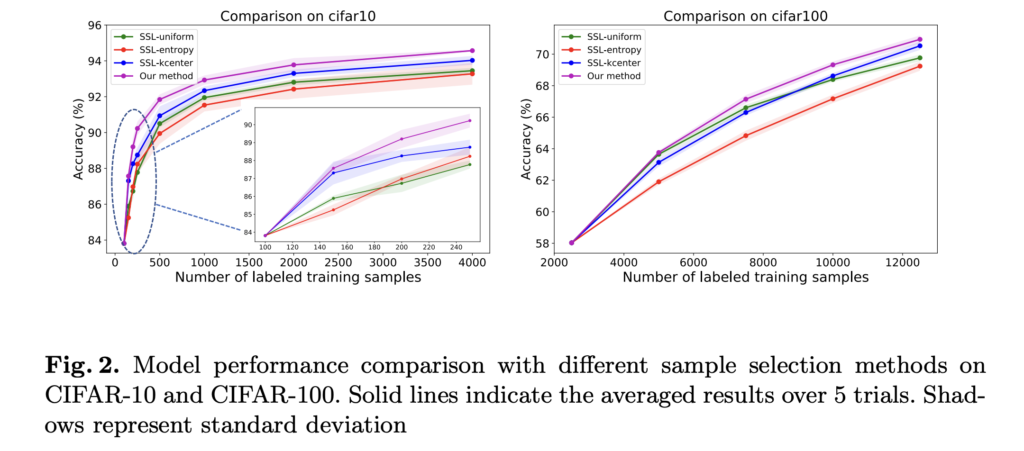
특히, 0.5%라는 극히 소량의 데이터셋을 사용했을 때 다른 방법론에 비해 우세한 결과 역시 알 수 있었습니다.
추가로 저자는 batch size 에 따른 trade-off 관계를 알 수 있었는데요. 경험적으로 batch size가 크면 성능이 저하되고, 작은 batch를 사용할 경우 계산 비용이 많아지지만 성능은 보장되는 것을 알 수 있었다고 합니다.
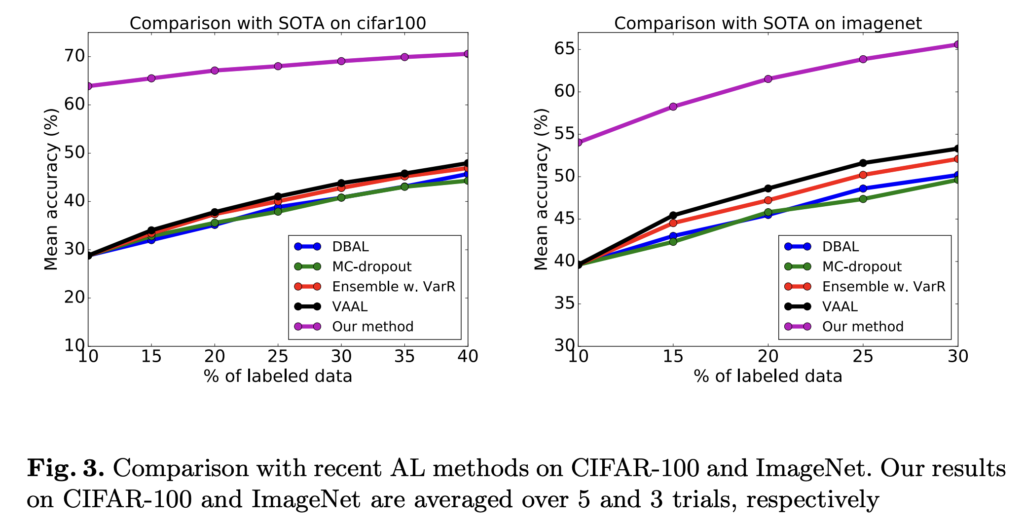
[2] Comparison with supervised AL methods
여기서부터는 기존 Activ eLearning 과의 성능을 비교한 결과를 보입니다. 이를 통해 Unlabeled 를 함께 사용하는 것이 효과적인 방법임을 알 수 있었다고 합니다.
Analyses of consistency-based selection
해당 파트에서는 consistency-based selection에 대한 3가지 중요한 속성에 대한 정성적 분석을 제시합니다
1. Uncertainty and overconfident mis-classification.
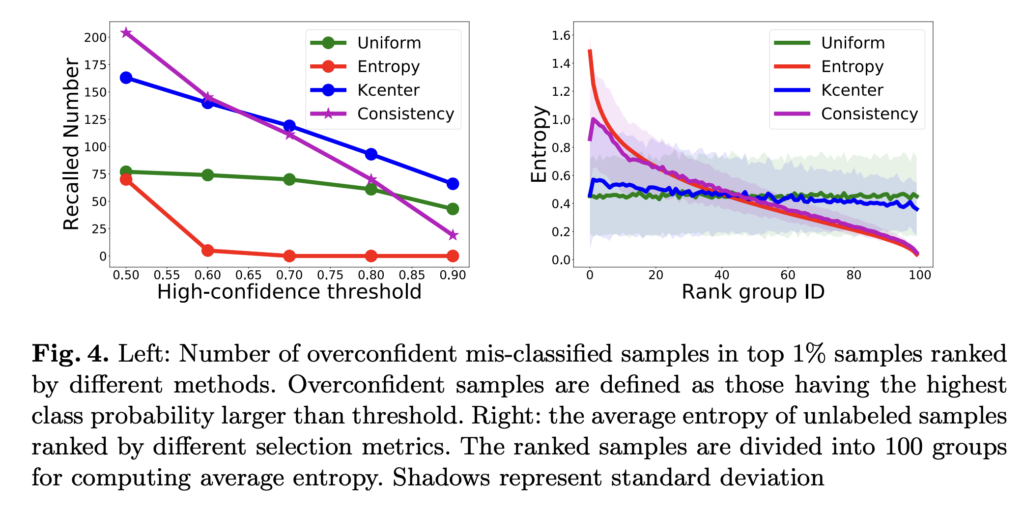
앞서 설명했듯, Uncertainty 기반의 데이터 선별 방법은 잘못된 예측임에도 불구하고 over-confident 하는 경향이 있습니다. 이런 불확실성 기반의 방법론은 잘못 분류된 것인지는 구별해내지 못합니다. 그러나 Consistency 기반은 이런 오분류를 감지하는데 더 우수하였음을 아래 그림(왼쪽) 을 통해 알 수 있었습니다. 또한 오른쪽 그림을 통해 불확실성과 비슷한 경향을 보이지만 항상 높지는 않은 것을 알 수 있습니다,.
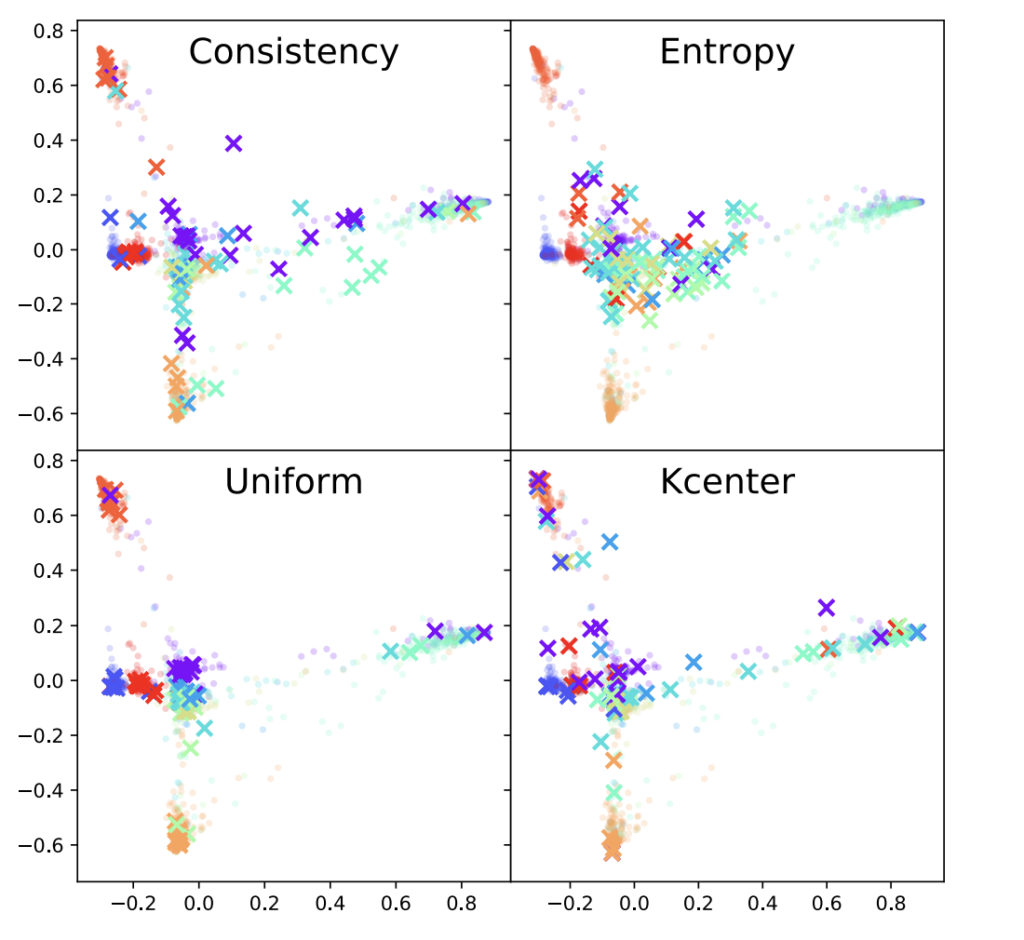
2. Sample Diversity
신기하게도 consistency 만을 고려하였음에도 불구하고 diversity만을 고려하는 k-center와 비슷한 분포를 보임을 알 수 있습니다. 이를 토대로 해당 방법론이 불확실성 말고도 전체 분포도 고려할 수 있는 적합한 샘플링 방법임을 주장합니다,.
When can we start learning-based AL selection?
저는 이 부분이 굉장히 인상적이었는데요. 결국 cold-start를 어떻게 다루느냐가 AL의 핵심 방법론이라고 할 수 있기 때문입니다.
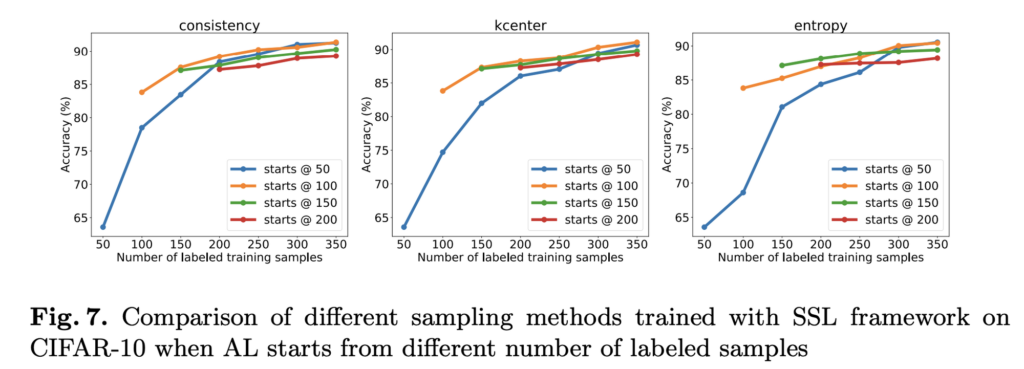
이를 위해 우선 저자는 언제 Cold-start가 발생하는지를 알아보았습니다. cold-start란 너무 적은 초기 라벨셋이 있을 때 모델이 편향된 학습을 하여 라벨이 추가되도 성능이 크게 향상되지 않는 현상을 의미한다고 하였습니다. 아래 그림을 통해 초기 데이터셋 크기에 따른 성능 비교를 수행하였습니다.
아래 그림 consistency 중 시작점이 50일때와 100일 때를 비교해봅시다. 150개의 라벨 데이터가 추가되었을 대 성능은 100에서 출발한 성능이 더 좋습니다. 그에 반해 오히려 초기 셋을 더 키운 200에서는 성능 향상이 크지도, 그리고 높은 성능을 달성하지도 않은 것을 알 수 있습니다. 이를 통해 너무 무지막지하게 초기 라벨 데이터셋 크기를 높이는 것도 좋지 않은데, 이를 추가되는 데이터 크기가 제한되었기 때문이라고 말합니다.
따라서 제안하는 모델은 충분히 작은 초기 데이터셋 크기를 가지는 것이 좋지만 50이라는 너무 작은 셋에서는 효과적이지 않았다는 결론을 내립니다.
Weaknesses of our method
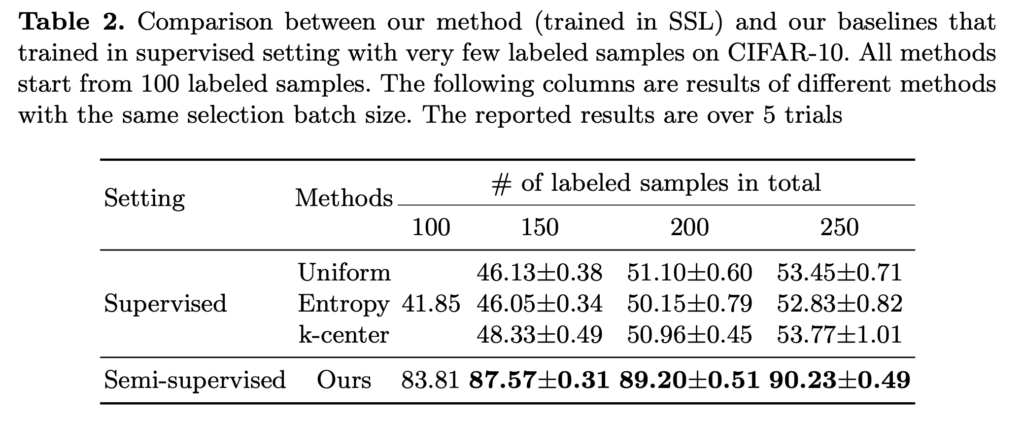
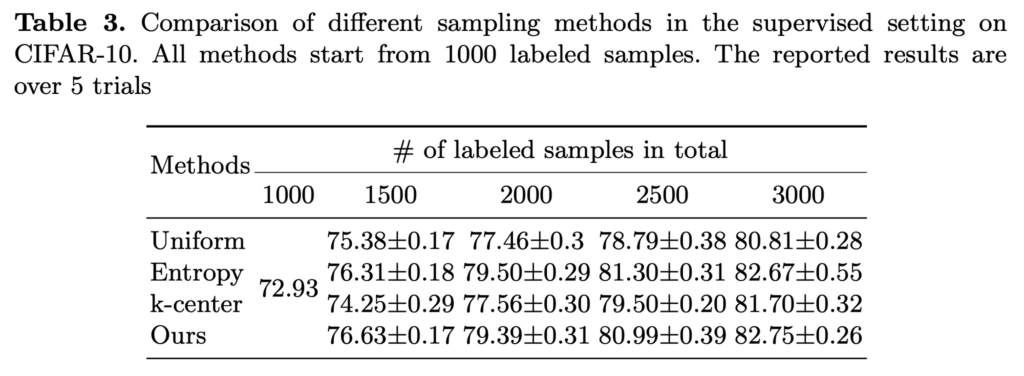
사실 제게 익숙한 AL 연구는 초기 데이터셋이 1000 으로 저자가 제안하는 100/150/200 보다는 꽤 큰 수치로 시작합니다. 사실 CIFAR-10의 데이터가 5만개인걸 고려하면 1000개도 충분히 작은 수치입니다. (2%니까요) 그래서 이렇게 1000개로 시작했을 때의 성능이 궁금했는데.. 여기서 이실직고를 합니다.
결론부터 말하자면 1000개라는 초기 셋으로 시작하면 성능이 그렇게 유의미하지는 않습니다. 아래 테이블을 보면… 알 수 있죠? 따라서 저자가 이 파트를 마무리하며 말하길 “task target loss와 강한 상관관계를 가지는 consistency 라는 방법을 제안하긴 했지만, 정확한 최적의 start size를 결정하진 못했다” 라면서 초기데이터셋 크기와 샘플링을 별개의 문제로 이야기하며 마무리를 짓습니다.
그렇다면 이 초기 데이터셋 크기 변동에 대한 실험 결과가 궁금해지기도 하는데 약간의 아쉬움과 호기심이 남습니다.
Conclusion
SSL과 AL을 결합한 방법론을 제안했다는 점에서 큰 contribution이 있던 방법론인 것 같습니다. 초반에 제안된 연구라서 그런지 다소 나이브한 방법론들과 비교했다는 점에서 조금 아쉽지만 엄청나게 작은 초기 데이터셋 크기를 사용했다는 점에서는 유의미한 방법론인 것 같습니다. 다만 결국 Cold-start 문제에 대한 명쾌한 답변을 내리지 못한 것은 다소 아쉬움이 있고, 이를 어떻게 개선해나갈지 어떤 차이가 있는지를 조금 더 연구해봐야겠습니다.
리뷰 잘 읽었습니다.
Consistency Loss를 계산하기 위해 들어가는 입력은 무엇인가요? Labeled Pool 에서 Classification Loss 같은 경우는 SoftMax를 통과한 확률 분포가 들어갈 거 같은데 Consistency Loss는 Unlabed Pool에서 들어가는 거 같은데 정확한 입력값이 무엇인지 궁금합니다.
consistency loss란 이미지에 대한 왜곡/변형에도 모델이 얼마나 일관된 예측을 할 수 있는 지를 고려한 수식입니다. 따라서 해당 Loss를 사용하면 Unlabeled 이미지에 대해서 서로 다른 Augmentation을 준 이미지들을 입력으로 넣고, 모델의 출력 사이의 거리를 구할 수 있습니다.
좋은 리뷰 감사합니다.
실험파트에서 궁금한 것이 있습니다.
Uncertainty and overconfident mis-classification 분석의 경우, 그림4의 캡션에 의하면 왼쪽 그래프는 오분류된 결과들의 수와 그에 대한 threshold라고 하는데, 그렇다면 저자들이 주장하는 오분류일 경우 낮은 confidence를 갖는 다는 것을 보여주는 것으로 이해하면 될까요?? 만약 그렇다면 결과적으로 보았을 때, Entropy가 더 좋은 것으로 보아야 하는지 궁금합니다.
아뇨! entropy의 경우 over-confident에서 틀린 경우가 더 많은 반면, consistency는 상대적으로 강인하다고 보면 됩니다. 따라서 오분류의 경우에 대해서는 consistency 가 더 좋다 라고 보시면 됩니다~!