Before Review
Vision Transformer(ViT) 논문입니다. 요즘 비디오 분야에서도 Transformer 기반의 백본이 활발하게 연구가 되는 추세입니다. 저도 관련해서 계속 follow-up을 하고 있는데 제가 ViT에 대한 detail을 생각보다 모르고 있어서 이번 기회에 한번 정리하게 되었습니다.
리뷰 시작하도록 하겠습니다.
Preliminaries
Vision Transformer는 CNN의 구조와 많이 비교 됩니다. Inductive Bias 관점에서 많이 비교가 되는데 바로 이 Inductive Bias가 무엇인지 조금 자세하게 설명해보도록 하겠습니다.
Inductive Bias
일반적인 기계학습 알고리즘은 훈련 데이터를 이용하여 가능한 모든 가설(모델) 중에서 한 가지 가설(모델)을 선택하는 것이라 볼 수 있습니다.. 그리고 훈련 데이터로부터 일반화된 능력을 가지는 가설(모델)을 구성하는 것이 우리의 학습과정입니다.
그런데 이러한 과정은 귀납적 사고와 유사합니다. 귀납적 사고란 몇가지 사실로 부터 일반화된 규칙을 도출하는 것입니다. 우리의 기계학습 역시 몇 가지 데이터 샘플로부터 데이터 전체를 설명하는 일반적인 패턴을 찾는 것이 목적이기 때문에 귀납적 과정이라 볼 수 있습니다.
한가지 예시를 들어 설명하도록 하겠습니다.
예를 들어, 좌표평면에서 열 개의 훈련 샘플 (x_i,y_i)\, (1\le i \le 10)이 주어 질 때,
\mathcal X = \mathcal Y = \mathbb R에 대해 가설 f:\mathcal X \to \mathcal Y을 선택하는 경우, 열 점을 모두 지나는 함수는 무수히 많습니다. 그런데 이때 비슷한 샘플들은 비슷한 출력값을 가져야 한다고 여긴다면 비교적 평활한 곡선을 선호하는 편향을 가진다고 할 수 있습니다. 무슨 소리인지 조금 애매하니 아래의 그림을 같이 보도록 하겠습니다.
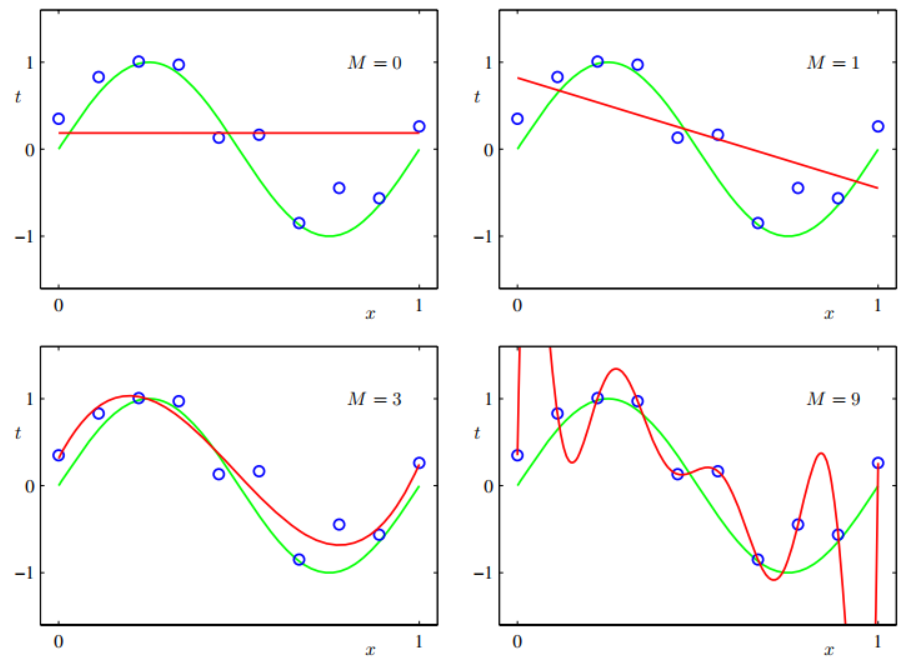
파란색 점이 저희의 학습 샘플이라 가정하겠습니다. 초록색 라인은 우리가 근사하고 싶은 함수의 모형이라 생각하면 됩니다. 이때 학습 샘플을 바탕으로 모집단의 분포를 나타내는 함수를 근사 시키고 싶을 때 우리의 선택지는 다양하겠죠. 상수함수로 근사 시킬 수 있을 것이고 일차함수 삼차 함수 등등 저희의 가설 공간은 무한합니다.
하지만 여기서 상수 함수(M=0)와 일차 함수(M=1)는 너무 간단해서 데이터를 설명하는 데 조금 부족함이 있어 보입니다.
삼차 다항함수(M=3)로 근사 시키면은 어느정도 잘 들어맞는 것을 확인할 수 있습니다. 다만 완전하게 파란색 샘플에 대응되지는 않네요.
마지막으로 고차 다항함수(M=9)로 근사 시키면 모든 파란색점에 들어맞는 것을 확인할 수 있습니다.
그렇다면 정말 고차 다항함수(M=9)로 근사시키는 것이 가장 좋다고 얘기할 수 있을까요? 그렇지 않습니다. 고차 다항함수(M=9)로 근사시키면 당장 저희희 학습 샘플인 파란색 점들을 잘 설명할 수는 있지만 그외의 다른 데이터들을 전혀 설명할 수 없습니다. 그나마 삼차함수(M=3)으로 근사 시킨다면 당장 파란색 샘플들에 대해서는 조금 엇나가지만 전체적인 그래프의 모습을 비슷하게 가져가기 때문에 더욱 일반적인 모델이라고 생각할 수 있습니다.
저희의 가설 공간은 무한하기 때문에 모든 경우를 다 고려할 수 없습니다. 이럴 때 필요한 것이 귀납적 편향인데 위의 예시와 같이 적당히 데이터의 분포를 보고 “아 삼차함수(M=3)로 근사 시켜야 겠다.” 라는 제한을 가하는 것이 귀납적 편향이죠. 사람이 모델에 제한을 가하는 것입니다.
일반적으로 귀납적 학습을 할 때는 이러한 편향이 아예 존재하지 않는다면 좋은 알고리즘을 만들어내기 힘들다고 보면 됩니다.
뭔가 Inductive Bias라는 것을 설명하기 위해 서론이 조금 길어졌는데 본격적으로 Vision Domain 에서의 얘기를 해보도록 하겠습니다. 일단 Convolution 연산과 Transformer 연산 간의 구조적 차이를 살펴보고 Inductive Bias의 차이를 살펴보도록 하겠습니다. 기본적으로 Transformer의 연산은 Fully Connected Layer의 구조와 동일합니다.
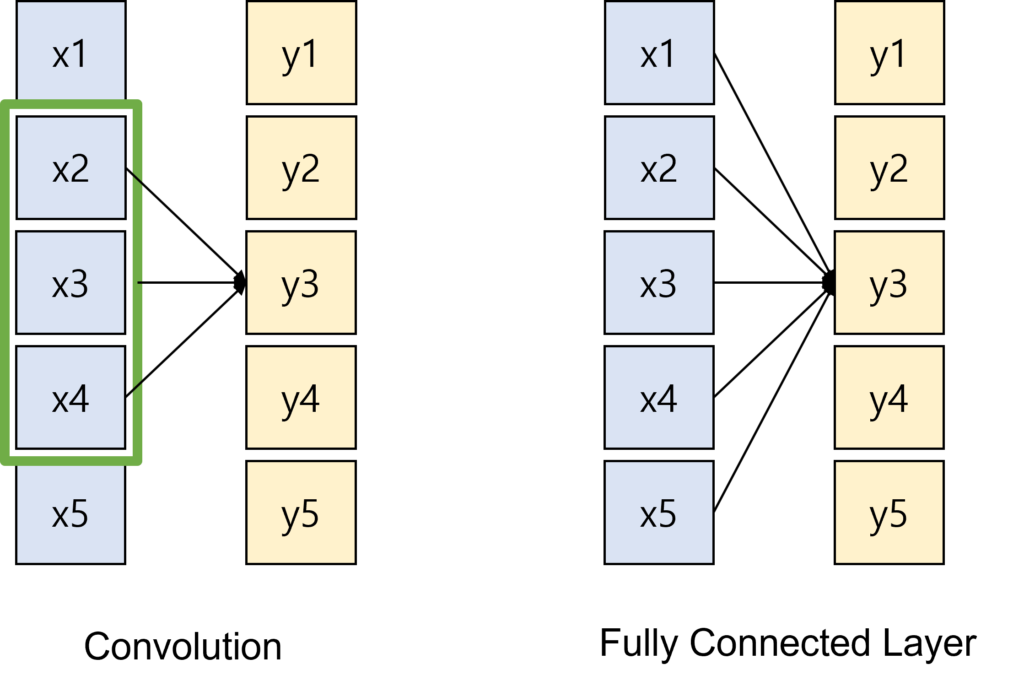
위의 그림을 보면 Convolution과 Fully Connected Layer 간의 차이점을 나타내고 있습니다.
우선, Convolution은 고정된 크기를 가진 격자(Kernel)이 움직이면서 동일한 가중치를 가지고 모든 입력에 대해 연산이 진행됩니다. 이때 출력으로 나오는 값은 고정된 영역만을 입력으로 받아서 값이 계산이 됩니다. 이미지 정보는 인접 픽셀간의 locality가 존재한다는 것을 미리 알고 있기 때문에 Convolution 연산 역시 인접 픽셀간의 패턴을 추출하기 위한 목적으로 설계되었습니다. 사람이 이러한 가정을 깔고 모델을 설계한 것이죠.
Fully Connected Layer는 모든 입력이 하나의 출력에 관여합니다. 그리고 연산을 진행할 때 모든 입력은 독립적으로 고려 됩니다. 모든 입력이 독립적으로 고려되기 때문에 우리는 어떠한 가정도 하지 않게 됩니다.
Convolution이 Computer Vision에서 좋은 성과를 거둔 이유는 바로 이렇게 Locality에 대한 Inductive Bias가 존재하기 때문입니다. Fully Connected Layer의 연산 구조를 그대로 가져가는 Transformer는 Locality에 대한 Inductive Bias가 거의 없다고 보시면 됩니다.
Generalization
그렇다면 Inductive Bias가 큰 것이 좋은지 작은 것이 좋은 지에 대해 궁금할 수 있습니다.
Inductive Bias가 크면 작은 데이터 셋에 대해서도 좋은 성능을 보일 수 있습니다. 하지만 데이터 셋이 Web-Scale 수준으로 커져 버리면 Generalization이 떨어져 성능을 저해할 수 있습니다.
반대라 Inductive Bias가 작으면 작은 데이터셋에는 좋은 성능을 보일 수 없을 수도 있습니다. 아직 충분한 패턴을 학습하지 못했기 때문입니다. 하지만 데이터셋이 커지면 커질 수록 Generalization이 강해져 더 높은 성능에 도달 할 수 있음을 기대할 수 있습니다.
결국 Inductive Bias는 Generalization과 trade-off 관계에 있다고 볼 수 있습니다.
요즘 나오는 연구들을 보면 Inductive Bias를 줄이고 Large-Scale의 데이터를 때려 박아서 Generalization을 높이는 방향으로 학습을 하는 것 같습니다. 서론이 길어졌지만 Inductive Bias 개념은 Vision Transformer 논문 뿐만 아니라 다른 논문에서도 계속 등장하는 개념이기 때문에 좀 자세하게 정리해봤습니다.
이제 진짜 논문 리뷰 시작하도록 하겠습니다.
Introduction
Transformer가 NLP 분야에서 성공적으로 자리 잡고 Computer Vision 진영에서는 Self-Attention을 Convolution과 접목하려는 시도가 많았습니다. 본 논문에서 소개할 Vision Transformer 이전에도 당연히 Attention을 활용한 많은 연구가 있었지만 뭔가 애매했습니다. 성능이 아쉽거나, 연산량이 너무 많은 경우가 대다수 였습니다.
이에 구글 연구진은 NLP의 Transformer의 구조를 거의 그대로 차용할 수 있는 구조를 제안합니다. Transformer 구조의 장점은 모델의 확장성이 좋다는 것이죠. ViT 이전의 Vision 분야 attention 모델들은 꽤 효과적임에도 불구하고 복잡한 패턴 때문에 모델의 확장성이 좋지 않았습니다.
Transformer의 구조를 가지고 탄생한 Vision Transformer는 CNN과는 다른 특성을 가지고 있습니다. 제가 위에서 설명한 Inductive Bias 관점에서 CNN과 다르죠. 일단 그에 대한 자세한 얘기는 ViT의 구조를 알아보면서 천천히 얘기하도록 하겠습니다.
이번 논문은 사실 Transformer를 이미지 도메인에 성공적으로 장착 시켰다는 점에서 의의가 있다고 볼 수 있습니다. 이에 따라 Intro는 별로 얘기할 게 없으니 바로 Method로 넘어가도록 하겠습니다.
Method
Vision Transformer
집중해서 봐야 되는 부분은 이미지 데이터가 어떻게 처리돼서 Transformer Encoder로 들어가는지 확인하면 됩니다. Transformer의 입력으로 들어가기 위해서는 Token의 Sequence 형태로 들어가야 합니다. NLP 에서 이 Token 들은 단어들이 Word Embedding을 거쳐서 나온 벡터 입니다. 이미지도 이와 비슷한 형태로 처리하기 위해 이미지를 patch 단위로 분할 시킵니다.
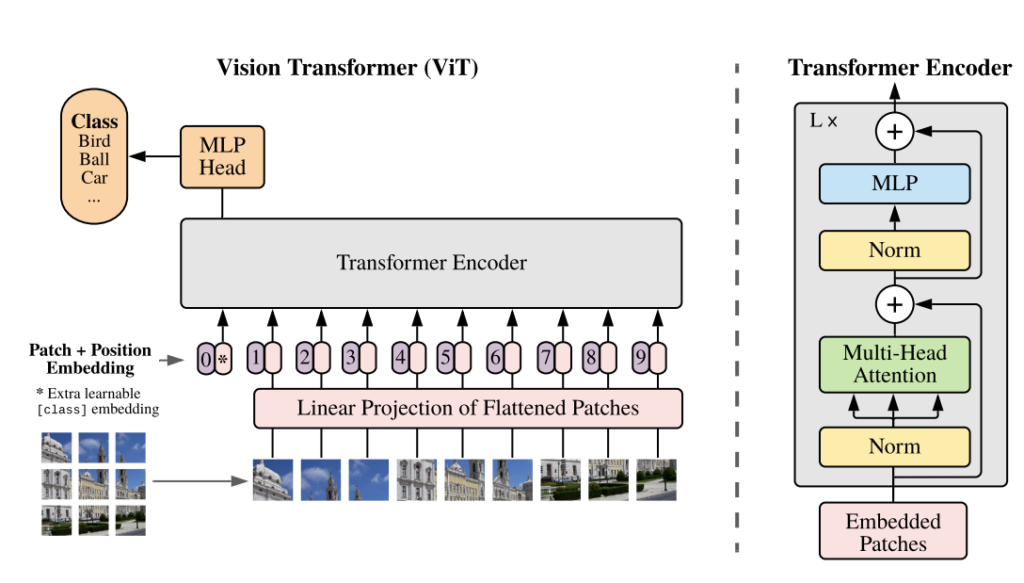
위의 그림을 보면 왼쪽 아래에 landmark 사진이 9등분으로 분할된 것을 확인할 수 있습니다. 이렇게 Patch들의 사이즈는 모두 동일하게 가져가고 분할된 Patch를 Flatten 시켜 1D vector의 형태로 만듭니다. 1D vector는 다시 Linear Layer를 거쳐 고정된 차원(D)을 가지는 vector로 projection 됩니다. NLP transformer에서 token을 만드는 거랑 똑같은 개념이라고 보시면 됩니다.
패치 크기가 P 일 때 이미지 데이터 하나 x_{p}\in \textbf{R}^{H\times W\times C} 는 1차원의 벡터로 flatten 되어 x_{p}\in \textbf{R}^{N\times (P^{2}\cdot C)} 시퀀스가 됩니다.
예를 들어 H=W=224 라 가정하고 P=16이라 할 때,
Patch의 갯수는 N=H/P=14, N=W/P=14인 14 \times 14 = 196가 되겠네요.
그리고 패치 자체의 차원은 16 \times 16 \times 3 =768 의 차원으로 flatten 됩니다.
즉, 이미지 한장은 196 \times 768 의 차원을 가지는 패치 임베딩 행렬로 분할 된다고 보시면 됩니다.
Vision Transformer는 BERT와 동일하게 ‘Class Token’을 사용합니다. 시퀀스 가장 앞에 learnable embedding vector를 추가하는 것입니다. 참고로 이 learnable embedding vector는 Pytorch에서 그냥 nn.Parameter로 생성해주면 됩니다. BERT에서도 이 ‘Class Token’을 이용하여 Classification을 수행한 것처럼 ViT 에서도 이 Token의 Representation을 가지고 Classification을 수행합니다.
즉, ‘Class Token’이 Encoder를 거치고 나오면 이미지 전체를 설명하는 representation vector가 되는 것입니다. MLP Head를 붙이면 이제 Classification으로 지도학습이 가능하겠네요. 그럼 ViT 인코더에 들어가는 임베딩 행렬의 크기는 (196+1) \times 768이 되겠네요.
다음으로는 Positional Embedding이 더해집니다. NLP Transformer 처럼 위치 정보를 알려주기 위해 learnable positional embedding을 더해준다고 하네요. 역시나 nn.Paramter로 (196+1) \times 768 의 차원을 가지는 행렬을 선언해주면 됩니다.

위의 코드 처럼 Random으로 초기화하고 학습 때 update 되는 tensor들이라 보시면 됩니다.
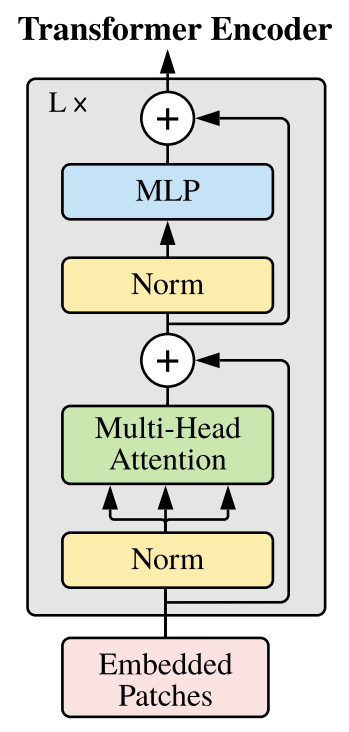
Embedded Patch 들이 준비 되면 그 다음에는 L개의 연속적인 Transformer Block을 태워주면 됩니다. Encoding Layer를 여러개 거쳐서 나온 Class Token에 대한 Representation을 가지고 MLP head를 통과 시켜 Classification Task를 수행하면 됩니다.
Inductive Bias
아까 위에서는 CNN과 Fully Connected Layer와의 Inductive Bias 비교를 진행했습니다. 이제는 CNN과 Vision Transformer를 비교해보도록 하겠습니다.
Vision Transformer는 연산 과정이 Fully Connected Layer와 동일하지만 그렇다고 해서 Inductive Bias가 아예 없는 것은 아닙니다. 이유가 뭘까요? 일단 Patch 끼리 순서를 부여했습니다. Positional Embedding이 적용되기 때문에 모든 패치가 독립적이지 않습니다. 따라서 Locality를 가정했다고 볼 수 있습니다. 하지만 CNN에 비해 Inductive Bias가 강하다고는 볼 수 없지요. 뒤에 실험 파트에서도 확인하겠지만 ViT는 작은 데이터 셋에서는 학습이 어려운 한계점이 존재합니다. 이미지 데이터에 대한 Inductive Bias가 작아서 Generality를 가질려면 데이터 셋이 많아야 한다는 것입니다.
본 논문에서는 ImageNet1K가 아닌 ImageNet21K나 JFT와 같은 Large-Dataset에서는 ViT의 성능이 Convolution이 좋기 때문에 의미가 Generalization 관점에서는 더 우수하다고 주장하지만 이는 계속 두고 봐야 할 문제라고 생각합니다.
Experiments
실험 시에 Vision Transformer는 Large-scale 데이터 셋에서 사전 학습을 하고 fine-tuning을 진행합니다. 사전 학습된 MLP head를 제거하고 zero-initialized 된 Linear Layer를 새롭게 붙여 진행합니다. 이때 fine-tuning 시에 사용되는 이미지의 해상도가 사전 학습 때 사용했던 해상도와 달라지면 사전 학습 때 사용했던 패치의 갯수와 달라지게 됩니다. 이렇게 되면 사전 학습 시킨 positional embedding이 의미가 없어지기 때문에 사전 학습 때 사용했던 해상도와 fine-tuning 때 사용하는 해상도 대비 상대적인 비율을 가지고 positional embedding tensor를 보간 처리 해줍니다.
Setup
Vision Transformer는 Class와 이미지의 개수가 각각 다른 3가지의 데이터 셋을 가지고 사전 학습을 진행합니다.

저는 ImageNet-1K도 대용량이라 생각 했는데 아니라고 하더군요. 이 세가지의 데이터 셋을 가지고 사전 학습을 진행하고 downstream task에 대해서 benchmarking 하기 위해 ImageNet, ImageNet-ReaL, CIFAR-10/100, Oxford-IIIT Pets, Oxford Flowers-102 같은 데이터 셋을 사용하였습니다.
Model variants
모델 구조에 따른 ViT 정의 입니다. BERT와는 다르게 ViT-Huge라는 대용량 모델까지 정의를 해주었습니다. 예를 들어 ViT-L/16이라는 의미는 ViT-Large 모델을 가져가면서 패치 사이즈는 16 \times 16 로 사용했다는 의미입니다. 이때 패치 사이즈가 작아질 수록 입력 시퀀스의 길이는 길어지므로 모델의 연산량이 더 많아진다고 보면 됩니다.
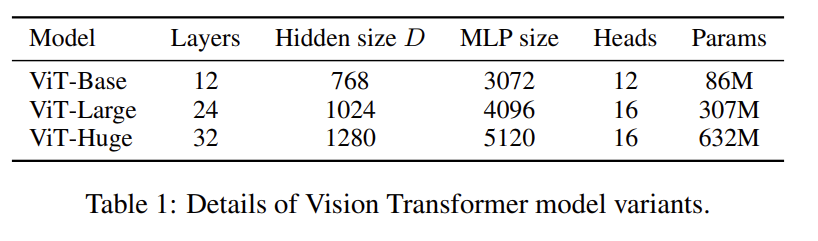
CNN 계열의 비교 baseline으로는 ResNet 계열의 모델이 사용됩니다. 완전히 ResNet 그대로 사용한 것은 아니고 몇 가지 수정 사항이 있는데 modified 된 model을 BiT라고 하는 거 같습니다.
Comparison to state of the Art
Image Classification Benchmark
BiT-L 과 Noisy Student라고 하는 CNN 계열 SOTA 모델과의 벤치마킹입니다.
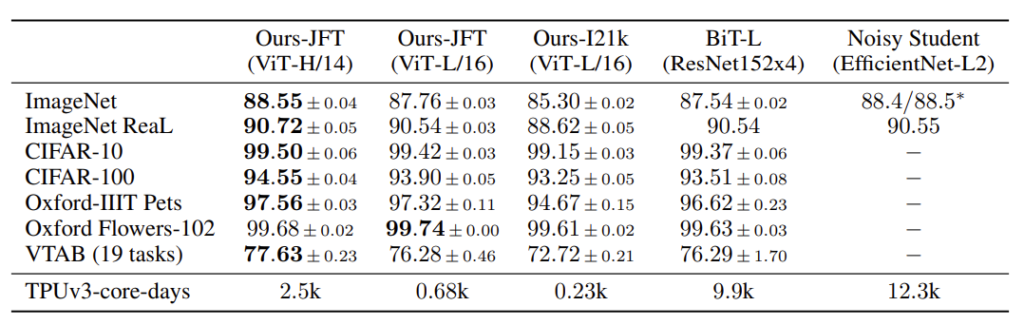
ViT-Huge/14가 대부분의 지표에서 좋은 성능을 보여주고 있습니다. ViT-L/16 같은 경우는 사전 학습 시간이 BiT-L이나 보다 적게 걸림에도 불구하고 더 좋은 성능을 보여주고 있습니다. 위의 벤치마킹에서 BiT-L이나 Noisy Student는 JFT로 사전 학습 되었습니다.
ViT-L/16의 경우 JFT보다 데이터의 양이 조금 적은 ImageNet-21K로 사전 학습 하는 경우 성능 하락이 발생하는 것을 볼 수 있습니다. 뒤의 실험에서 한번 더 다루겠지만 ViT는 대용량의 사전 학습 데이터가 아니면 학습하기 어려운 단점이 존재하는 건 분명한 것 같습니다.
VTAB performance
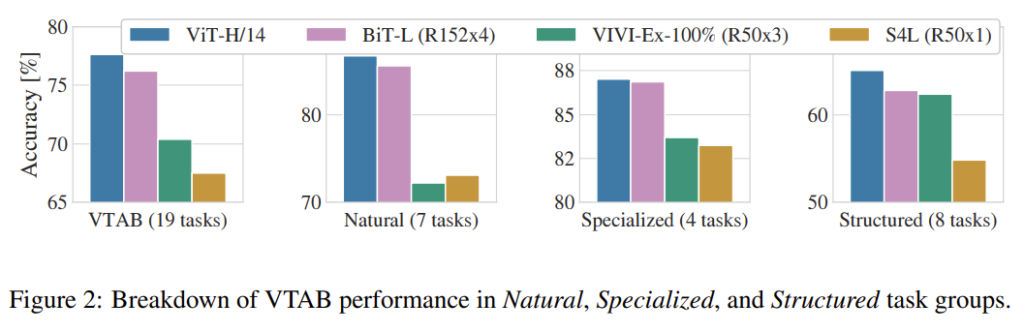
VTAB performance는 각 task당 1000개의 training examples를 사용하여 적은 데이터를 다양한 task에 전이한 성능을 평가하는 방법입니다. 각 task는 크게 Natural, Specialized, Structured의 세 그룹으로 나뉘어 있습니다. Natural은 흔히 접할 수 있는 데이터 imagNet, Cifar등의 데이터이며 Specialized는 의학, 위성 사진 등의 특수 분야의 데이터이고 Structured는 최적화를 위한 위치 정보의 데이터 같은 구조에 대한 데이터로 이루어져 있습니다.
결국 데이터의 특성에 따라 정확도가 달라질 수 있으니 이에 대한 검증 실험이라 보시면 됩니다. ViT는 데이터의 특성에 관계 없이 CNN baseline에 비해 더 좋은 정확도를 보여주고 있습니다.
Pretraining Data Requirements
앞선 실험 결과를 보면 Vision Transformer가 CNN 보다 더 좋아 보이지만 이는 JFT-300M이라는 대용량의 데이터셋으로 사전 학습을 해야 한다는 점이 존재합니다. 사전 학습 데이터가 작아지면 ViT는 강력해지지 않죠. 이에 저자는 datasize가 얼마나 중요한지 분석하기 위해 두 가지 실험을 진행했습니다.
Pretraing ViT models on datasets of increasing size
사전 학습 데이터의 사이즈를 ImageNet1K -> ImageNet21K -> JFT300M 이 순서로 늘려가면서 진행한 실험입니다. 여기서 small dataset에서 성능을 boosting 하기 위해 몇 가지 regularization(weight decay, dropout, label smoothing)을 진행했다고 합니다.
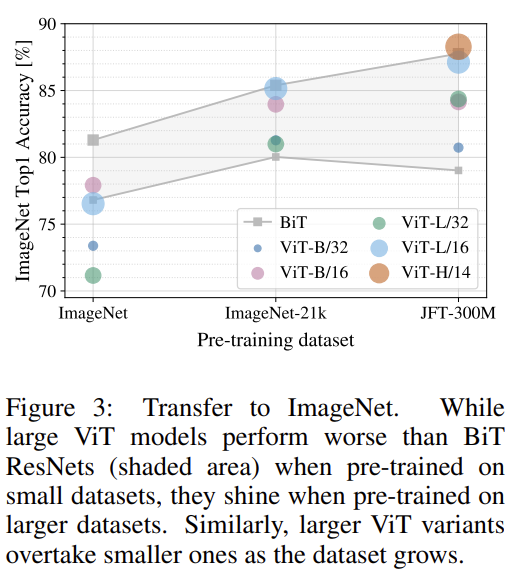
ImageNet-1K과 같이 작은 데이터 셋에 대해서는 ViT가 영 힘을 못쓰고 있습니다. 또한 동일한 패치 사이즈 일 때 더 큰 모델인 ViT-Large가 ViT-Base보다 성능이 낮은 것을 보아 ViT를 제대로 학습 시키기 위해서는 사전 학습의 데이터 사이즈가 중요한 것을 볼 수 있습니다. 이러한 경향은 ImaegNet-21K 에서도 비슷하게 확인할 수 있습니다. JFT-300M 정도는 되어야 Larger model에 대한 full benefit을 가져갈 수 있네요.
Training ViT on random subsets of JFT300M dataset
다음으로 JFT dataset을 9M, 30M, 90M 그리고 300M 이렇게 해서 subset에 대한 실험을 진행했습니다. 이 실험을 진행할 때는 small dataset에 대해서는 regularization을 하지 않고 모든 데이터 셋에 대해서 동일한 조건으로 실험을 진행했습니다. Regularization effect가 아니라 모델의 intrinsic property에 집중하기 위함이라 볼 수 있습니다. 또한 연산량을 줄이기 위해 full fine tuning 이 아니라 few-shot linear accuracy를 가지고 비교했다고 합니다.
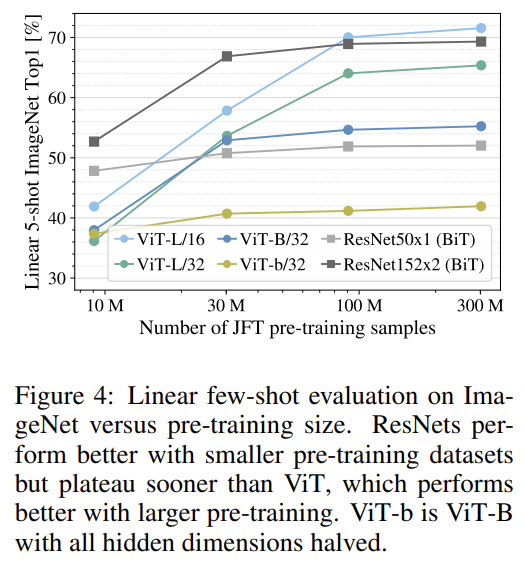
결과를 놓고 보면 Vision Transformer는 데이터가 작은(9M) 상황에서는 ResNet에 비해 Overfitting 되는 경향을 보여주고 있습니다. 90M 정도 되면 결과가 반대의 양상을 보여주네요.
정리하면 small dataset에서는 inductive bias가 강한 CNN 방법론이 성능이 높은 반면 large dataset에서는 inductive bias가 작은 ViT가 더 좋게 나타나고 있습니다. 저자는 ViT가 small dataset에서도 전이 학습이 잘 되게 하는 것이 future work의 방향이라고 하네요.
Scaling Study
다음 분석은 data size가 아닌 model의 performance와 pre-training cost간의 trade-off 관계를 다루는 실험입니다. 자세한 실험 세팅과 pre-training cost는 appendix에 있지만 그러한 detail을 알 필요까진 없을 거 같아 다루지 않겠습니다. 이 실험이 시사하는 몇 가지 분석만 정리하고 넘어가도록 하죠.
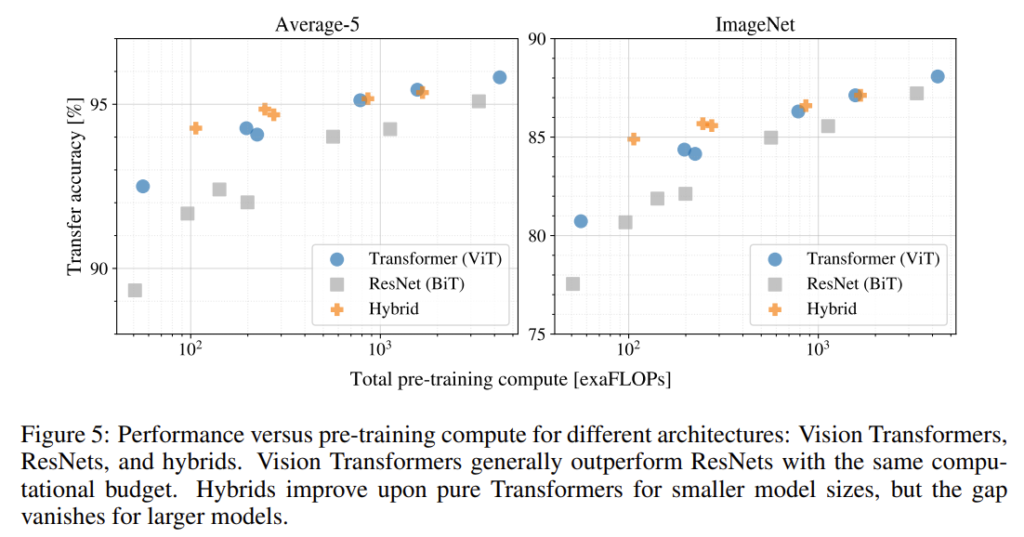
- Vision Transformer는 CNN 계열인 ResNet 대비 training cost-Accuracy trade-off 관계가 더 좋다는 것입니다.
- Hybrid 방식이 vanilla ViT 보다 살짝 더 효율적이라는 것입니다. Hybrid 방식은 Patch를 Linear Projection 시키는 것이 아니라 CNN의 intermediate feature를 가지고 ViT에 태운 것이라 보면 됩니다. 계산량이 적은 영역에서는 Hybrid 방식이 vanilla ViT 모델보다 더 좋은 성능이 나온 것을 확인할 수 있었고 이는 convolutional local feature processing이 ViT의 성능 향상에 도움이 된다는 것을 보여주는 것 같습니다.
- 모델이 매우 커지면 성능이 어느 정도 saturation 되는 ResNet 대비 ViT는 saturation 되는 양상을 보이지 않습니다. 훨씬 더 큰 scale 에서 성능을 기대해볼 수 있다는 점을 시사하는 것 같네요.
Inspecting Vision Transformer
Vision Transformer 가 이미지 데이터를 어떻게 처리 하는지 확인하기 위한 실험 입니다. 사실 이쪽 내용은 읽어도 잘 이해가 가질 않아서 다른 블로그 글을 많이 참고 했습니다.
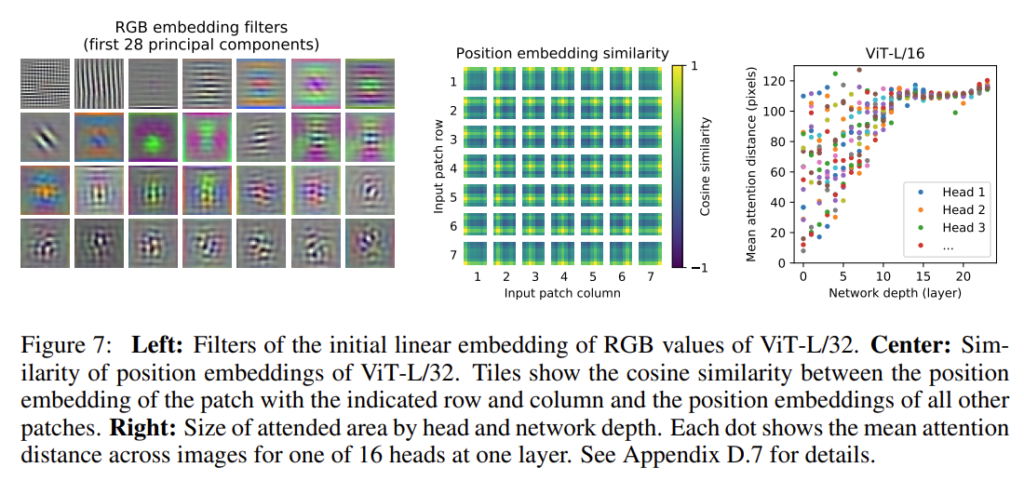
일단 위의 그림에서 가장 왼쪽 그림을 보면 embedding Layer를 시각화 했습니다. 처음에 봤을 때 이게 뭐지 싶었는데 12년도에 등장한 AlexNet 논문에 나온 그림을 보면 둘이 비슷한 것을 느낄 수 있습니다.

ViT도 CNN처럼 이미지 이해에 필요한 low-dimensional representation을 잘 학습 했다는 것을 알 수 있죠.
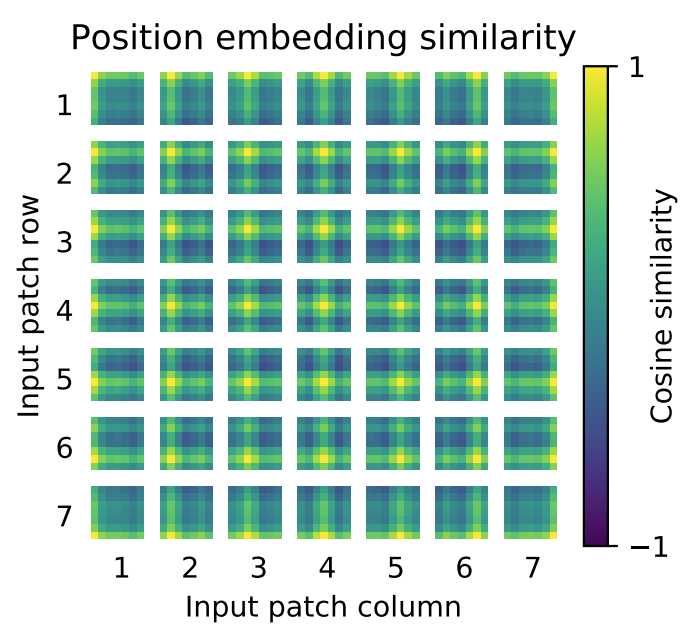
다음으로 위의 그림에서 가장 중앙 그림을 보면 positional embedding 유사도를 시각화 하였네요. 이 시각화는 정말로 Positional Embedding vector가 데이터의 위치를 잘 표현하도록 학습이 되었다는 점을 보여줍니다. 패치 마다 임베딩 벡터가 있을 것이고 모든 패치에 대응되는 벡터 끼리 유사도 행렬을 계산했을 때 패치의 위치와 유사도 행렬이 크게 activate 되는 부분이 일치하는 것은 positional embedding이 잘 학습 되었다고 볼 수 있겠죠.
마지막으로 가장 오른쪽의 그래프는 attention이 관심을 두는 위치의 distance를 나타냅니다. y축의 distance의 의미는 어떤 query 위치를 기준으로 의미 있는 영역까지의 평균 거리를 나타냅니다. 이 거리가 짧을수록 가까운 영역에 대하여 attention을 한다는 것이고 이 거리가 길수록 먼 영역에 대하여 attention을 한다는 것을 의미합니다.
low level layer에서는 distance가 다양하게 나타나고 있습니다. 즉, 가까운 곳에서 부터 먼 곳까지 모두 살펴보고 있습니다. 하지만 high level layer의 경우 distance가 대체적으로 큰 쪽으로 치우져 있는 것을 볼 수 있는데 이는 크게 크게 전체적으로 본다는 의미입니다.
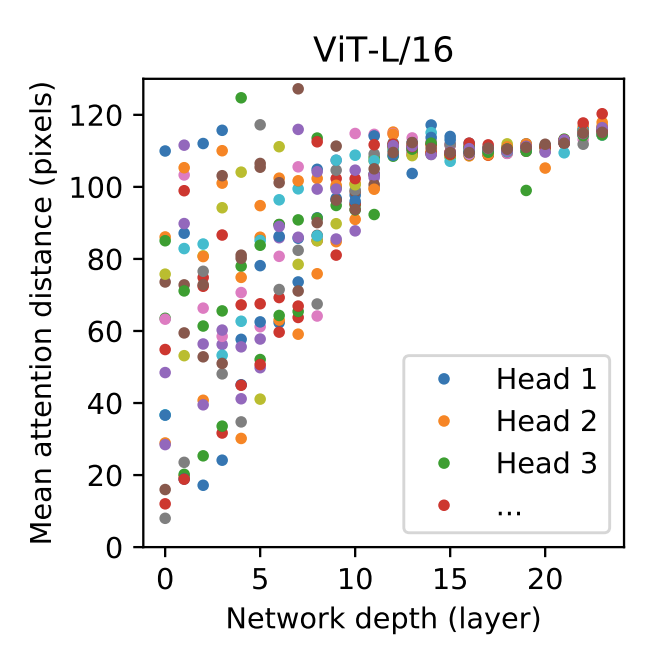
이러한 성질은 CNN의 Receptive Field와 비슷합니다. Vision Transformer 또한 그러한 성질을 가지는 것을 확인할 수 있었네요.

Self-Supervision
Transformer가 NLP 분야를 지배하는 이유는 Transformer 자체의 구조도 있지만 이를 활용한 Self-Supervised Learning이 성공 했기 때문입니다. 저자도 BERT와 비슷하게 masked patch prediction task를 가지고 self-supervised learning 실험을 간단하게 진행했다고 합니다.
비교적 작은 모델인 ViT-Base/16을 가지고 79.9%의 정확도를 달성했습니다. 79.9%라는 정확도는 scratch로 학습한 성능 보다 2% 더 앞서지만 Supervised Learning에 비해서는 4% 정도 부족하다고 합니다. 이 부분 역시 future work라 볼 수 있습니다.
Vision Domain에서 Transformer를 가지고 Self-Supervised Learning을 연구하는 것은 뜨거운 연구 주제이니 관심 있으시면 22년도~23년도 관련 논문들을 follow-up 하면 될 것 같습니다.
Conclusion
사실 ViT에 대해서 그동안 아는 척을 했던 것 같습니다. 생각보다 제가 몰랐던 디테일이 굉장히 많았습니다. Inductive Bias라는 개념 역시 이번에 이해하게 됐네요.
저의 관심 연구를 follow-up 하는 것도 중요하지만 Computer Vision에서 중요하게 다뤄지는 Backbone 에 대한 이해 역시 시야를 넓혀주는데 중요한 것 같습니다.
리뷰 읽어주셔서 감사합니다.
좋은 리뷰 감사합니다.
제가 그동안 읽은 inductive bias 에 대한 설명 중 제일 이해가 잘 되는 글이었습니다.
그런데 그림 3에서 BiT 선이 두 개인거 같은데 이게 무슨 차이일까요? 만일 맨 위에가 BiT라면 BiT 즉 CNN 기반의 방법론이 ImageNet-1K 와 같이 (상대적으로) 작은 데이터셋으로 사전학습한 결과가 더 좋은 것 같은데, 데이터가 적어서 그렇다는 것 말고 추가 분석은 없나요
아 그 부분 설명이 누락됐네요. BiT에서 아래에 있는 성능은 가벼운 모델이고 위에 있는 모델은 무거운 모델입니다. JFT-300M 기준으로 무거운 모델끼리 비교했을 때 ViT가 미세하게 더 우수한 성능을 보여주고 있다고 보시면 됩니다.
리뷰 잘 읽었습니다.
특히 Inductive Bias 부분이 인상깊었습니다. 종종 찾아와서 해당 내용을 참고할 듯 합니다.
리뷰 내용중에
‘Generalization 관점에서는 더 우수하다고 주장하지만 이는 계속 두고 봐야 할 문제라고 생각합니다.’
라고 말씀해 주신 부분중에서, ‘계속 두고 봐야 할 문제’ 라는게 어떤 의미인 지 알 수 있을까요??
막힘없이 술술 리뷰를 읽다가 해당 부분에 물음표가 하나 박혀서 그냥 의문이 들어 질문 드립니다.
ConvNext 논문을 보면 CNN이 더 우수하다는 주장도 있기 때문에 ViT가 무조건적으로 Generalization 면에서 좋다라고 주장하기는 조금 애매한감이 있어 그렇게 서술했습니다.
ConvNext 논문은 신정민 연구원이 잘 정리했기 때문에 궁금하시면 한번 읽어보시길 바랍니다.
안녕하세요 근택님, 좋은 리뷰 감사합니다.
최근 상인님의 deepcluster 리뷰를 보던 중 inductive bias에 대한 언급이 나와 자세히 이해해보고자 inductive bias 설명의 본고장이라고 불리우는 근택님의 해당 리뷰를 들리게 되었습니다. 더구나 ViT에 대해 잘 모르고 있었는데 친절하게 설명해주셔서 큰 틀을 빠르고 효율적이게 잘 이해할 수 있었던 것 같았습니다.
질문사항이 하나 있습니다!
우선 figure 7의 실험 이미지 3번째에서 low level layer에서는 distance가 다양하고, high level layer에서는 distance가 대체적으로 커서 크게크게 전체적으로 보기때문에 CNN의 receptive field 성질과 비슷하다고 해주셨습니다. 혹시 ‘비슷’하다고 워딩을 쓰신 이유가 ViT가 low level layer에서 완전하게 distance가 작은 feature만을 보지 않고 ‘두루두루’ 보기 때문인 걸까요?
유사하다라고 하기엔 ViT의 low level layer에서 attention distance가 다양하게 나타나고 있던 것이 제가 알고 있는 CNN의 receptive field와는 조금 다르지 않나라고 생각이 듭니다. CNN의 low level layer에서의 receptive field는 dilated conv가 아닌 이상 넓은 영역을 보지 않고, local한 영역의 detail한 feature를 보는 것으로 알고 있습니다.
그렇다면 단순히 해당 figure의 형태 또한 inductive bias의 관점에서 ViT가 learnable positional embedding 행렬 형태를 가지기 때문에(attention 형태를 가지기 때문에) CNN의 kernel 구조로 인한 인접정보 반영 정도보다는 ViT의 inductive bias가 약해서 low level 단에서 CNN과 비교했을 때보다 더 두루두루 보는 것으로 이해해도 될까요?
감사합니다!