
이번에 소개드릴 논문은 요새 self-supervised learning에서 핫한 Masked Autoencoder입니다. 근데 이제 Multi-modal과 Multi-task를 곁들인.
혹시 Masked Autoencoder(MAE)에 대해서 아직 잘 모르시는 분들은 저희 연구실의 미래 홍주영 연구원과 임근택 연구원이 작성한 MAE 논문 리뷰를 먼저 읽고 제 리뷰를 읽어주시면 감사하겠습니다.(JY리뷰, GT리뷰)
Intro
일단 기존 MAE는 Self-supervised Learning 방법론 중 하나로 Self-supervised Learning은 Downstream task에 사용하기 위해 GT없이 pre-trained model(보통 encoder)를 만드는 것을 목표로 합니다. 이는 기존의 다양한 downstream task에서 학습을 할 때 ImageNet pretrained weight를 활용하고 있지만, 이러한 ImageNet pretrained weight은 GT label이 있는 데이터에 대해 지도 학습을 통하여 취득하였기 때문에 다양한 한계를 직면합니다. (예, ImageNet보다 더 방대한 양의 데이터가 있음에도 그에 대한 label이 없어 pretrained model을 만들 때 사용하지 못한다거나, 특정 task에서는 RGB이미지가 아닌 다른 도메인의 입력을 활용할 경우 해당 도메인에 대한 pretrained weight를 구하기가 쉽지 않음).
따라서 MAE와 같은 Self-supervised Learning은 Label이 없이 영상 데이터만 있더라도 모델이 좋은 feature representation을 가질 수 있다는 점에서 상당히 각광받고 있지만, MAE는 RGB 도메인에 대해서만 다루고 있었습니다. 제가 리뷰할 논문 MultiMAE는 기존 MAE 논문의 이러한 한계점을 지적하며 Multi-modal에 대한 Self-supervised Learning을 하고자 합니다.
논문에서 다루고자 하는 입력 모달리티는 크게 3가지로 RGB, Depth, Semantic Segmentation입니다. 이는 저자의 주장으로는 생물학적 시스템 관점에서 더 신뢰성있고 좋은 표현력을 개발하기 위해서는 이러한 multi-modal의 학습을 진행해야한다고 합니다.
게다가 저자는 단순히 서로 다른 모달리티(multi-modality)를 입력으로 활용하는 것 뿐만 아니라, 각 모달리티에 따른 다른 모달리티의 출력을 내는 과정(multi-task)를 하는 것이 상당히 중요하다고 합니다. 이러한 multi-task learning은 단순히 하나의 pretraining objectiveness를 가졌을 때 보다 상대적으로 더 다양한 downstream task에 좋은 영향을 끼칠 수 있기 때문입니다. 실제로 multi task pretraining 방법론들은 downstream task에서 좋은 성능을 보여주었다는 이전 연구들도 존재로 합니다.
그럼 MultiMAE 논문에서 제안하는 Contribution들에 대해서 간략하게 정리하고 넘어가겠습니다.
논문에서 하고자 하는 것은 Multi modality(RGB, Depth, Segmentation)을 입력으로 넣고 이 세가지 모달리티를 reconstruction하는 Multi-task learning을 수행합니다. 그래서 단순히 RGB 이미지 뿐만 아니라, 해당 영상의 Depth, Segmentation label들까지 함께 필요한 실정이죠. 하지만 RGB 영상에 대응되는 Depth, Segmentation GT를 활용한다는 것은 Self-supervise Learning의 목적과는 부합하지 않게 됩니다.
그래서 논문에서는 밑에서 자세하게 설명드리겠지만, 사전학습된 Depth와 Segmentation model을 통한 Pseudo Label을 취득하여 Self-supervised Learning을 수행하였다고 합니다.
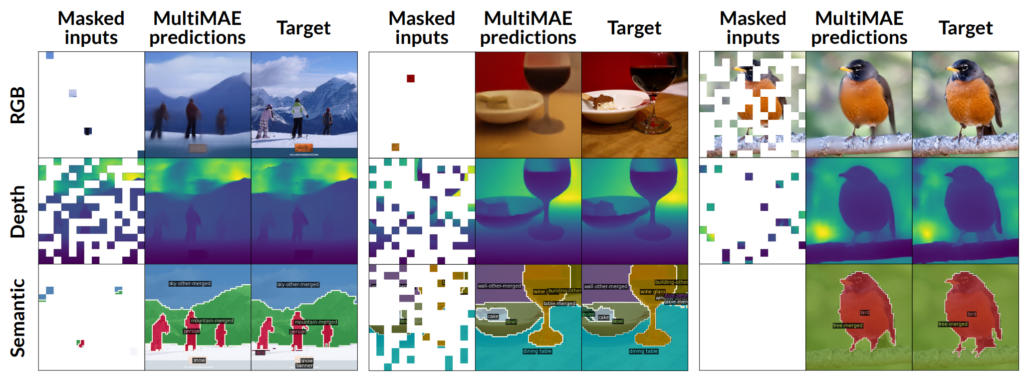
즉 MultiMAE는 기존의 MAE처럼 RGB 이미지를 입력으로 RGB 영상만을 reconstruction하는 것이 아닌, 어떠한 입력 모달리티로부터 어떠한 테스크에 대한 출력값을 예측하도록 학습이 진행됩니다.
그럼 방법론의 디테일한 부분들을 아래에서 더 다뤄보겠습니다.
Multi-modal Encoder
먼저 MultiMAE는 당연히 Encoder가 기존 ViT와 동일한 구조를 가지고 있습니다. ViT는 맨 처음 영상을 16×16 패치 단위로 잘라서 토큰을 만드는데 이렇게 토큰을 만드는 레이어를 patch projection layer라고 합니다. 당연히 기존 ViT는 RGB 이미지를 활용하기 때문에, 이러한 patch projection layer가 한 개 존재합니다. 하지만 MultiMAE는 3가지 모달리티를 활용하기 때문에 각 모달리티에 따른 개별적인 patch projection layer들이 존재합니다.
또한 저자는 학습된 임베딩을 가지는 추가적인 global 토큰이라는 것을 추가했다고 합니다. 이는 기존 ViT에서의 Class-token가 유사한 것으로 볼 수 있는데, 이처럼 projection layer의 개수가 모달리티의 개수만큼 더 있는 것을 제외한 모든 레이어들은 standard ViT와 동일하기 때문에 weight를 이전해주는 작업이 상당히 수월하다고 주장합니다.
Positional, modality and class embeddings
이미 모든 모달리티의 입력들(RGB, Depth, Segmentation)들은 모두 2D 정보로 구성이 되어있기 때문에, 저자는 patch projection layer를 처리한 다음 모두 동일하게 2D sine-cosine positional embedding 기법을 적용했다고 합니다.
또한 저자는 굳이 modality를 구분해주는 특정 임베딩을 따로 추가해주지는 않다고 합니다. 이는 이미 각 모달리티 별로 독립된 patch projection layer의 bias가 그 역할을 수행해줄 수 있다고 판단하였기 때문입니다.
Decoders
encoder를 통해 타고나온 token들은 이제 decoder를 통해서 reconstruction 과정을 수행해야만 합니다. 각각의 task마다 reconstruction을 다르게 해야하기 때문에, 각 task에 맞게 독립적인 디코더를 활용했습니다. 각각의 디코더는 전체 visible token의 세팅을 입력으로 받아서 reconstruction을 진행합니다.
즉 Depth reconstruction을 한다고 했을 때 Depth image에서만 visible token을 가져다가 reconstruction하는 것이 아닌, RGB, Segmentation에서의 Visible token도 모두 활용해서 Decoder의 입력으로 사용한다는 것이지요.
저자는 각각의 모달리티로부터 인코딩된 토큰들을 합치기 위하여, 각각의 디코더마다 하나의 cross-attention 레이어를 추가하였다고 합니다. 이 cross-attention layer는 모든 인코딩된 코드들을 key와 value로 놓고, 다른 모달리티에서 인코딩된 토큰들은 query로 두었다고 합니다.
또한 이 cross attention 단계 이전에는 Sine-cosine positional embedding과 학습된 modality embedding을 token들에게 적용하는 과정을 수행합니다. 그리고 기존 MAE와 동일하게, visible token이 아닌, masked token들에 대해서만 reconsturction loss를 계산하게 됩니다.
위에서도 간략하게 설명했다시피, 각 task의 개수에 따라서 decoder의 개수도 선형적으로 증가하게 됩니다. 따라서 저자는 사전 학습의 효율성을 높이기 위하여 상당히 얕은 구조의 디코더를 활용했다고 합니다.(단일 cross-attention layer와 MLP, 그리고 다음에 2개의 transformer block구조를 가지게 됩니다.)
인코더와 비교하였을 때 디코더의 경우에는 전체 계산 코스트를 조금 상승 시키긴 하지만, 기존 MAE와 동일하게 디코더를 깊게 쌓든 얕게 쌓든 ImageNet-1K fine-tuning한 것 기준 유사한 성능을 보여주기 때문에, 얕게 쌓는 것이 큰 문제는 없다고 합니다.
Multi-modal masking strategies
사실 MAE 방법론들 성공의 핵심은 바로 마스킹을 어떻게 적용할지에 대한 전략 방식입니다. 기존에 Self-supervised Learning 방법론들 중에서는 이미 MAE 이전에도 RGB 영상을 reconstruction해서 모델의 feature representation을 향상시키고자 하는 연구들이 많이 존재했습니다.
하지만 해당 연구들이 실패했던 이유들은 바로 영상에서 masking한 영역이 너무 적거나, 혹은 덩어리 채로 날려버리고 이를 복원하는 식으로 진행했기 때문입니다. MAE의 경우에는 영상의 75% 영역에 대해서 랜덤하게 마스킹을 하는 것이 가장 좋은 성능을 달성했다고 하며, 동일한 75% 영역의 마스킹을 할지라도 일정한 간격으로 uniform하게 마스킹하는 등마스킹 전략을 어떻게 세우냐에 따라서 성능이 차이가 나기도 했습니다.
사설이 조금 길었는데, 결과적으로 MultiMAE에서는 먼저 고정적으로 98개의 visible token만을 사용하고 그 외에는 모두 masking했다고 합니다. 이 98개 개수의 기준은 모든 모달리티의 영상 해상도가 224×224라고 했을 때, 각 모달리티 영상에서 1/6 수준에 해당하는 토큰들을 모두 합친 것이라고 말합니다.
(즉 224×224 이미지에 대해 16×16패치를 토큰으로 잡으면 총 196개의 토큰이 생기고 이 토큰을 1/6하면 32.666667개가 나오며, 총 3개의 모달리티 입력을 가지고 있으므로 32.666667*3 = 98개가 나오는 것이죠.)
자 그러면 reconstruction을 하기 위해 encoder의 입력으로 들어가는 토큰의 개수는 98개인 것을 잘 알았습니다. 그러면 각 모달리티 별로 몇 개의 visible token들을 선택하면 될까요? 가장 단순하게 생각하면 각 모달리티 별로 모두 동등하게 약 33개씩 선택하면 될까요?
저자는 각 모달리티 별로 동등하게 선택하게 될 경우 대부분의 모달리티들이 모두 유사한 정도의 표현력을 가지게 될 것이라고 주장합니다. 즉 하나 혹은 더 많은 모달리티가 매우 적게 혹은 전혀 visible sample들이 선택되지 않는 경우가 매우 귀하다는 것이죠.
따라서 저자는 보다 다양한 샘플링하는 방법을 위하여 조금 새로운 샘플링 전략을 제안합니다. 이것은 크게 2가지 단계로 구성되는데, 먼저 첫째는 각 모달리티 별로 토큰을 몇개 뽑을지 개수를 정하는 것이며, 둘째는 개수가 정해졌을 때 각 모달리티별로 랜덤하게 샘플링한다고 합니다. 결국에는 기존 MAE처럼 랜덤하게 visible token을 뽑긴 하지만, 각 모달리티 별로 몇 개씩 선택할 것인지 그 개수를 정하는 것이 MultiMAE에서 중요하겠네요.
Number of tokens per modality
그래서 논문에서는 어떻게 모달리티 별 토큰 수를 정하였는가?에 대한 답은 바로 symmetric Dirichlet distribution입니다. 발음을 어떻게 읽어야하는지 모르겠지만.. 디리클레 분포?라고 읽는 것 같긴 합니다.
이 디리클레 분포의 경우에는 이제 \lambda_{RGB} + \lambda_{D} + \lambda_{S} = 1, \lambda >= 0 라고 합니다. 여기서 이 \labmda 가 각 모달리티 별 샘플링할 토큰의 개수의 비율이라고 보시면 될 것 같습니다.
각 모달리티 별로 람다를 다 더했을 때 1이라면, 각각의 람다들은 전체 개수 98개 중에 비율을 의미합니다. 이러한 디레클레 분포의 샘플링 과정에서 중요한 것이 바로 concentration parameter \alpha > 0입니다. 만약 \alpha ==1 인 경우에는, symetric Dirichlet distribution에 해당하며, 이는 simplex에 대한 균등 분포를 가지는 것과 동일하다고 볼 수 있습니다.
여기서 simplex란 대충 삼각형 구조의 다면체?를 지칭한다고 보시면 될 것 같은데, 현재 MultiMAE에서 학습시키고자 하는 modality가 3개이기 때문에 각 모달리티의 중심을 각 삼각형의 꼭지점으로 놓았을 때 그때의 확률분포를 생각하시면 좋을 것 같습니다.
디리클레 분포에 대한 설명을 그림을 보면서 다시 하면, 그림 2에서와 같이 3개의 토픽에 대해 각 토픽이 선택될 확률을 계산할 경우 \alpha 값에 따라 어떤 토픽이 선택될지 달라집니다. 좌측과 같이 \alpha 값이 큰 경우( \alpha == 4) 중앙에 진한 영역(high probability)가 몰리는 것을 볼 수 있는데, 이는 각 토픽의 정중앙부에 높은 확률값이 분포됨으로써 균등한 샘플링이 될 가능성이 있다는 것이죠.
반면에 우측과 같이 \alpha 값이 상대적으로 작아지는 경우( \alpha==2 ), 진한 영역이 점차 넓어짐으로써 각 토픽의 중심으로 뻗어나가는 경향을 보입니다. 이러한 경향성은 \alpha 값이 0에 가까울수록 더 크게 나타날 것이며, 그렇게 되면 특정 토픽에 편향되어 샘플링 될 확률이 높아지겠죠.
자 그러면 \alpha ==1 이었을 때 symmetric Dirichlet distribution이라는 것을 알았으니, \alpha < 1 and \alpha >1 인 상황은 어떨까요? 위에 그림 2를 통해 설명했다시피 \alpha 값이 1보다 작은 경우에는 대부분의 토큰들이 균등하게 샘플링되는 것이 아닌, 특정 모달리티에 편향돼서 샘플링될 가능성이 높습니다.
반면 \alpha 값이 1보다 더 커지면 커질수록, 각각의 모달리티가 모두 비슷한 개수로 샘플링이 될 가능성이 높아지게 되는 것이죠. 저자는 모델이 특정 모달리티에 편향되어 샘플링이 되는 것을 원치 않았기에, 당연히 \alpha 값을 1보다 더 작게 설정하지는 않았습니다. 다만 저 위에서 설명했다시피 각 모달리티 별로 동등한 크기를 가지는 것은 또 지양하기 때문에, 저자는 적당한 중용책으로 \alpha 를 1로 하는 symmetric Dirichlet distribution을 샘플링 방법으로 활용한 것이죠.
이렇게 각 모달리티 별로 몇 개의 token들을 샘플링 해야 하는지 개수를 정했다면, 그 다음엔 정해진 개수에 따라서 random sampling을 진행하면 끝이 납니다.
Pseudo labeled multi-task training dataset
해당 섹션의 내용은 인트로에서 잠깐 언급했다시피, 결국 multi-task learning을 하기 위해서는 RGB 영상에 대응되는 다야한 모달리티의 입력 영상(Depth, Segmentation)이 필요로 하는데, 이 데이터들을 어디서 취득하냐는 내용입니다. 결론부터 말씀드리면 이미 잘 사전 학습된 모델을 가져다가 써, pseudo label을 학습 데이터로 활용합니다.
Depth의 경우에는 Omnidata라는 데이터 셋으로 사전 학습된 DPT-Hybrid 모델을 활용합니다. 저자는 pseudo label의 부정확한 부분들(outlier)를 제거하기 위하여 전체 값들 중 상위, 하위 10% 값들을 모두 무시한 체 정규화를 진행하였습니다.(standarized depth map)
이러한 standarized depth value들은 각 영상 별로 서로 다른 depth range, scale 등에서 따로 Omnidata depth parameterization을 사용하지 않고도 모델 학습에 활용할 수 있다고 합니다. 대충 이게 무슨 의미냐면, 결국 Depth Estimation에서 가장 중요한 점 중 하나는 모델이 추정한 상대적인 깊이 추정 결과를 실제 각 카메라에 맞는 절대적인 값으로 바꾸어야만 합니다.
하지만 이미지넷과 같이 매 영상마다 서로 다른 카메라로 촬영된 영상들에 대해서는 이러한 절대적인 scale 및 depth range를 취득할 수 없기 때문에, 사전 학습된 DPT 모델의 추정값을 정규화함으로써 상대적인 Depth map만을 활용한다는 것으로 저는 이해하였습니다. 참고로 Depth map의 경우에는 Reconstruction 당시에 MSE Loss를 활용한 RGB와 달리 L1 loss로 regression 합니다.
Semantic Segmentation의 경우에는 Swin-S encoder 기반 Mask2Former를 활용, MS COCO dataset으로 사전 학습하여 pseudo label을 생성하였다고 합니다. 최종적으로 argmax를 적용하여 133개의 semantic classes를 취득하였습니다. 또한 RGB, Depth와 달리, Segmentation의 경우에는 입력 모달리티로 사용하기 위함보다는, downstream task의 성능 향상에 더 초점이 있다고 합니다. 이 말의 의도를 대충 파악해보면 일반적으로 RGB-Depth의 경우에는 RGB-D 센서를 통해 모델의 입력으로 제공을 해줄 수는 있지만, 센서 관점에서 Semantic Segmentation을 입력으로 주는 경우는 그리 많지 않으니, 모델의 입력 사용 관점 보다는 multi-task learning 관점에서 feature representation을 좋게 하여 downstream task에 더 긍정적인 영향을 줄 수 있더라 라고 이해하시면 될 것 같습니다.
또한 pseudo label을 제공하는 모델 자체가 MS COCO dataset으로 학습하였기 때문에, 아래 실험 섹션에서 downstream task로 사용한 데이터 셋 중 MS COCO dataset이 아닌 ADE20K 등 다른 데이터 셋을 활용합니다. 그리고 reconstruction loss 계산 시에는 cross-entropy loss를 활용하게 됩니다.
Experiments
자 그럼 이제 실험 섹션에 대해서 다루겠습니다. 일단 Downstream task로는 크게 Classification, Semantic Segmentation, Depth Estimation 3가지에 대하여 성능을 보여주고 있습니다. 일반적으로는 Depth Estimation이 아닌 Object Detection이 들어가는게 일반적이지만, 입력 domain으로 depth를 활용하기 때문에 Depth Estimation을 한 것이 아닌가 싶네요.
Classification은 ImageNet-1K 데이터 셋을 활용하였으며, 사전 학습이 다 진행된 후 supervised learning을 100 epoch만 돌려서 평가를 하였다고 합니다.
Semantic Segmentation의 경우에는 ADE20K, NYUv2, Hypersim 이렇게 총 3가지의 데이터 셋을 활용합니다. NYUv2와 Hypersim의 경우에는 RGB 영상 뿐만 아니라, GT Depth map까지 함께 제공하기 때문에 입력 영상으로 RGB 뿐만 아니라 Depth를 함께 제공하였을 경우에 대한 Semantic segmentation 결과도 함께 리포팅합니다.
Depth Estimation의 경우에는 NYUv2 데이터 셋과 Taskonomy Dataset을 활용해서 평가합니다.
Transfers with RGB-Only
먼저 아래 Table1은 다양한 Self-supervised Learning 방법론과 제안하는 MultiMAE에 대해 여러 Downstream task에서 성능을 나타낸 것입니다. 실험 세팅은 처음 Self-supervised Learning을 할 때에는 RGB-D-S를 모두 사용하지만, downstream task에 대해 fine-tuning할 때는 RGB dataset만을 활용한 결과입니다. C는 Classification, S는 Semantic Segmentation, D는 Depth Estimation으로 이해하시면 됩니다.
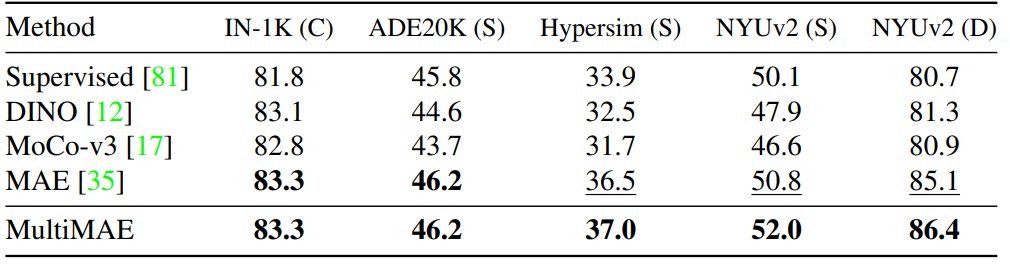
일단 Classification과 ADE20K semantic Segmentation에서는 MAE와 MultiMAE가 모두 동일한 성능을 보여주는? 다소 아쉬운 결과를 보여주고 있습니다. 하지만 그 외에 다른 데이터 셋, 특히 NYU dataset의 경우에는 나름 격차를 보이며 좋은 성능을 보여주고 있습니다.
Transfers using sensory depth
다음 결과는 fine-tuning할 때 RGB 데이터 뿐만 아니라 Real Depth map을 함께 사용하여 fine-tuning하였을 때의 정량적 결과입니다. 실제 RGB data와 GT Depth를 함께 제공하는 데이터 셋은 Hypersim과 NYUv2 데이터 셋 밖에 없어 이 두 데이터 셋에 대한 semantic segmentation 결과를 함께 나타낸 것입니다.

보시면 MAE의 경우 RGB만으로 fine-tuning한 것과 RGB-D를 함께 fine-tuning한 것과 두 데이터 셋 모두 그럴듯한 성능 차이가 나지를 않습니다.(오히려 NYUv2의 경우에는 RGB-D를 함께 학습시킬 경우 Semantic Segmentation 결과가 감소하는 모습입니다.)
반면에 MultiMAE의 경우에는 Depth map을 단독 입력으로 fine-tuning한 결과가 MAE 대비 상당히 큰 폭의 성능을 보여주고 있으며 RGB-D를 함께 학습할 경우 매우 높은 정확도를 보여주고 있습니다. 저자는 이러한 경향성이, 기존 MAE의 경우에는 오직 RGB 영상만으로 self-supervised learning을 수행하였기 때문에 추가적인 Depth 정보에 대해 충분히 활용을 하지 못한 반면, 제안하는 방법론은 RGB뿐만 아니라 다양한 모달리티에 대해 학습을 하였기 때문에 fine-tuning 과정에서도 좋은 weight으로 학습을 시작할 수 있었다고 주장합니다.
Transfers with pseudo labels
일단 위에 table2의 내용은 상당히 인상적이고 MultiMAE의 장점을 잘 보여주었습니다. 그럼 sensor를 통해 취득한 Depth 정보가 아닌 Pseudo Depth를 활용하면 어떻게 될까요? 그 결과는 아래 표3과 같습니다.

이번엔 pseudo depth 및 pseudo segmentation은 GT가 아니기 때문인지 ADE20K dataset에 대한 성능도 함께 리포팅을 하였습니다. 일단 몇가지 결론부터 말씀드리면, 표 2에서의 경향성과 유사하게 pseudo Depth만을 fine-tuning 단계에서 학습시킬 시 MAE는 성능이 크게 감소하는 반면, MultiMAE는 좋은 성능을 유지하고 있습니다. 이는 MultiMAE가 Depth input에 대하여 좋은 feature representation을 가지는 weight을 보유하고 있다고 볼 수 있습니다.
하지만 아쉬운 점은 바로 RGB-pD의 성능입니다. 실제 real Depth를 사용한 것과 달리, pseudo Depth+RGB의 조합으로 Segmentation 모델을 학습시킨 결과가 실제 RGB만을 활용한 성능과 비교하였을 때 엄청 큰 폭의 성능 향상을 보이지는 못했습니다.
물론 유의미한 성능 향상이 있는 것은 맞지만, Real Depth 값을 활용하였을 때의 성능 향상 폭이 너무나 큰 나머지 pseudo Depth의 경우에는 조금 아쉽게 느껴지네요. 또한 저자는 fine-tuning 단계에서 pseudo Segmentation label까지 함께 사용한 결과를 함께 리포팅합니다.
사실 Segmentation을 예측하는 것이 실험 분야인데, 입력으로 Segmentation넣고 Segmentation을 예측하는? 그런 실험을 진행한 것이 쉽게 납득이 가지는 않지만, Pseudo Segmentation이기 때문에 GT는 아니므로 괜찮다는? 뭐 그런 느낌으로 실험을 한 것 같습니다.
결과적으로 Segmentation 역시 RGB만 사용하는 것보다는 유의미한 성능 향상을 보여주고 있습니다. 게다가 RGB-pD-pS를 모두 사용하게 된 경우에는 더더욱 큰 폭의 성능 향상을 보여주고 있구요. 따라서 저자는 MultiMAE는 RGB only setting에서 좋은 성능을 보여주는 MAE와 달리 상당히 유의미한 결과를 나타내고 있다는 것을 실험적으로 증명합니다.
Ablation study
이번 실험에서 보이고자 하는 것은 간단합니다. 기존 MAE가 RGB 모달리티를 입력으로 하여 RGB 영상을 reconstruction 하였고, MultiMAE가 RGB-Depth-Segmentation 3가지를 사용했다면, RGB-D, RGB-S 등으로 학습하였을 때의 downstream task 성능을 보이고자 하는 것입니다.
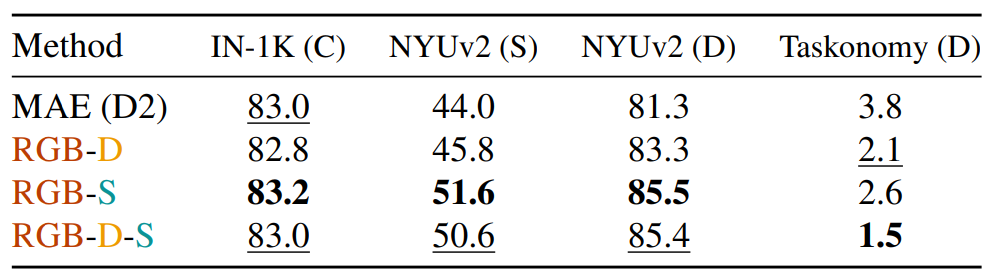
결과부터 바로 살펴보시면 흥미롭게도 RGB랑 Segmentation으로 self-supervised learning을 한 경우 Taskonomy Dataset을 제외한 모든 데이터 셋에서 좋은 성능을 보여주고 있습니다. 이러한 결과만 놓고 보면 RGB-D-S보다 RGB-S가 성능적인 측면에서도 더 좋고, self-supervised learning 시에도 Depth domain이 사라졌으니 연산량 측면에서도 더 좋은 것이 아닌가?라는 생각이 들 수 있습니다.
저자도 이를 의식했는지, 비록 RGB-S가 성능 향상이 조금 더 있지만, Taskonomy dataset에서는 성능 감소가 크게 일어나는 것을 보아, RGB-D-S와 같이 다양한 모달리티와 task를 섞어서 학습하는 것이 효율적으로 성능을 향상시킬 수 있다고 주장합니다. 실제로 ImageNet은 0.2%, NYUv2는 0.1로 유의미한 차이라고 보기는 어려울 것 같긴 합니다만 조금 아쉬운 결과네요.
Cross-modal exchange of information
여기서 소개드릴 내용은 MultiMAE의 입력을 어떻게 변경하면 Reconstruction 결과가 어떤식으로 바뀌는지를 분석한 것입니다.
정성적 결과들을 나열하면서 간략하게 소개드리고 리뷰 마무리 짓겠습니다.
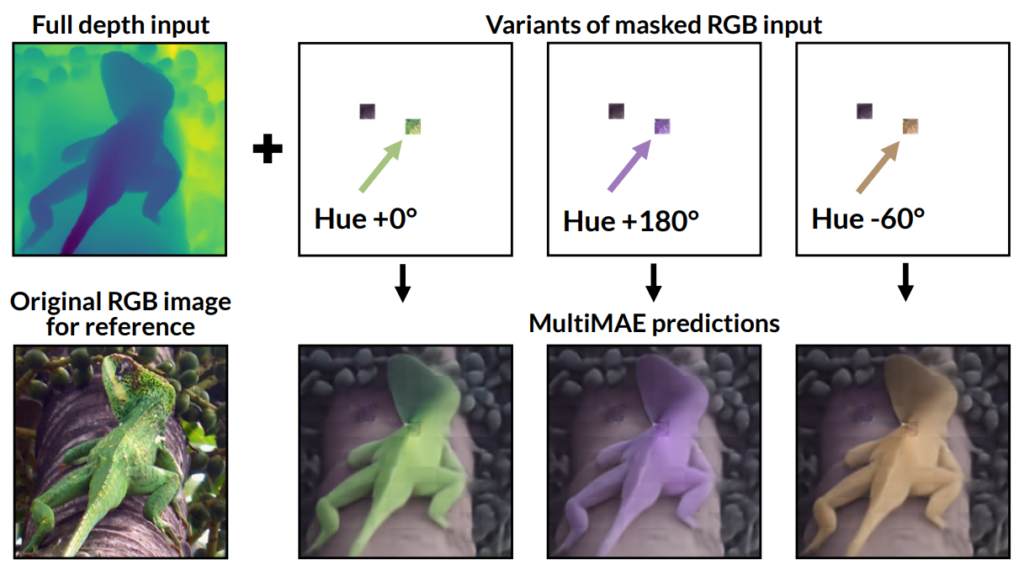
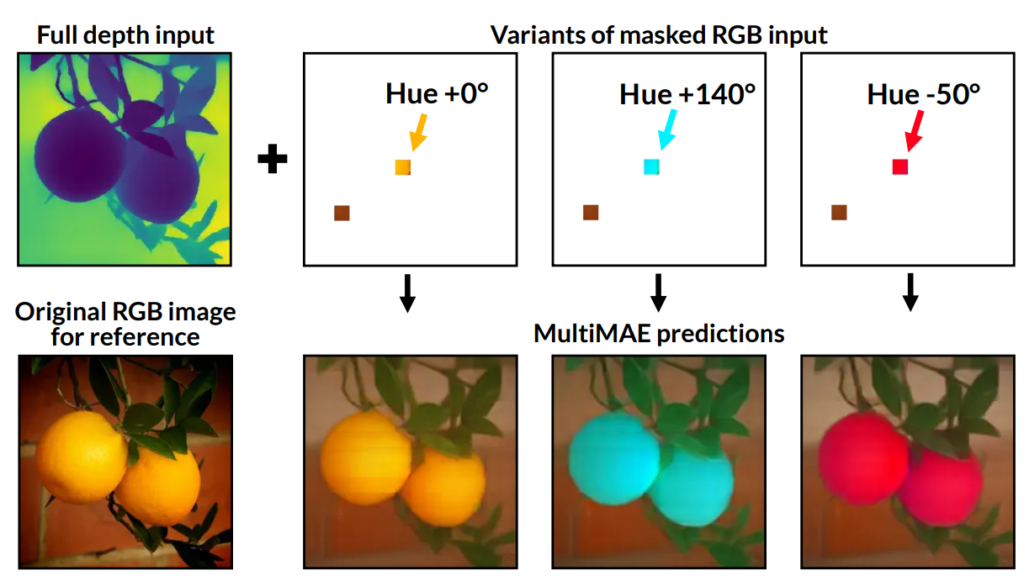
그림3을 살펴보시면, MultiMAE의 입력으로 사용할 RGB영상과 Depth 영상에 대해서 Full Depth image에 RGB patch를 색을 달리하여 넣어줄 경우 서로 다른 색상의 물체를 reconstruction 하는 것을 볼 수 있습니다. Depth map을 통해서 물체의 외형을 잘 판단함과 동시에 RGB의 패치 색상에 맞추어 대상의 semantic한 정보를 상당히 잘 구축하는 것이 재밌는 결과물인 듯 합니다.

그림 4는 단일 modality 영상을 넣었을 때 그 외에 다른 모달리티 결과로 reconstruction한 결과를 의미합니다. 아무래도 영상 전체를 모두 visible token으로 입력 넣다 보니 학습 때 98개의 token만 보던 것과 달리 약 2배 이상의 데이터를 입력 받아도 나름 그럴 듯하게 reconstruction하는 것을 볼 수 있습니다.(물론 semantic segmentation을 통해 reconstruction하는 것은 영 그럴 듯하게 나오지는 않네요)
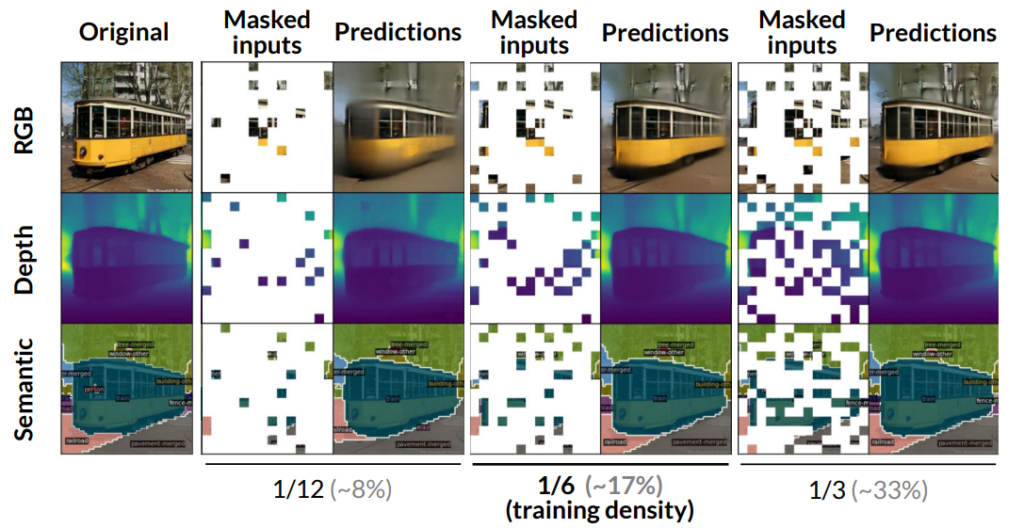
그림 5는 visible patch를 얼마나 적은 혹은 많은 비율로 했을 때 reconstruction 결과를 나타낸 것입니다. 해당 사진에 대해서는 크게 내용은 없고, 한번 참고해서 보시면 좋을 듯 합니다.
결론
MAE가 핫하긴 핫하다지만, MAE를 두고 Self-supervised Learning + Multi Modal + Multi Task라는 요새 핫한 키워드를 다 묶어서 글을 쓰니 좋은 논문이 나오네요 허허. 누구나 한번쯤은 해볼법한 생각이면서도 이렇게 흥미로운 결과를 제시했다는 점에서 좋은 논문이었던 것 같습니다.